- Лямбда-архитектура

Содержание
- 2. На этом уровне компенсируется разница в актуальности данных, а в отдельные представления реального времени добавляется информация
- 3. В основе Лямбда-архитектуры лежит несколько принципов: система не восприимчива к единичной потере данных и/или повреждению данных
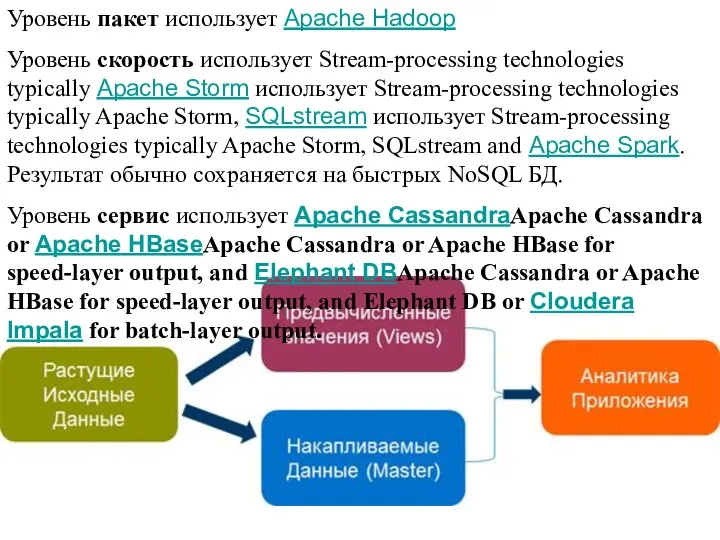
- 4. Уровень пакет использует Apache Hadoop Уровень скорость использует Stream-processing technologies typically Apache Storm использует Stream-processing technologies
- 5. Новые данные поступают на оба уровня: Пакетный и Ускорения (A). Мастер (B) представляет собой хранилище неизменяемой
- 6. На данный момент существуют различные вариации технологических компонент для Лямбда-архитектуры. Например, проект Lambdoop, который объединяет компоненты
- 9. Скачать презентацию
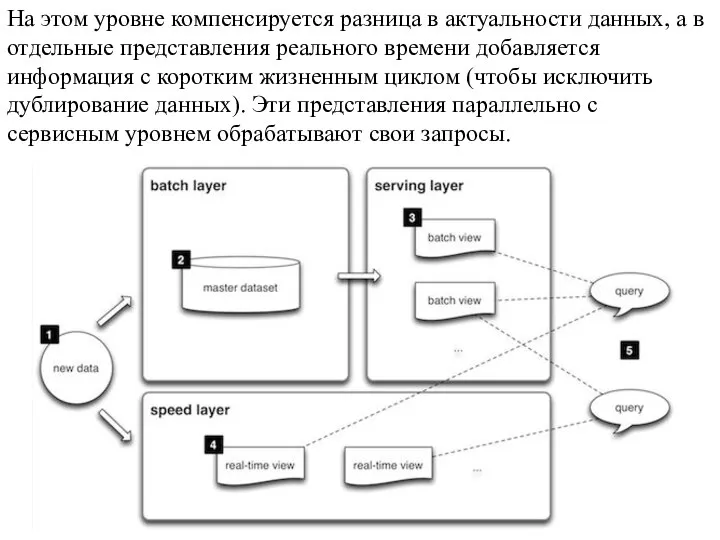
Слайд 3В основе Лямбда-архитектуры лежит несколько принципов:
система не восприимчива к единичной потере данных
В основе Лямбда-архитектуры лежит несколько принципов:
система не восприимчива к единичной потере данных

Слайд 4Уровень пакет использует Apache Hadoop
Уровень скорость использует Stream-processing technologies typically Apache
Уровень пакет использует Apache Hadoop
Уровень скорость использует Stream-processing technologies typically Apache
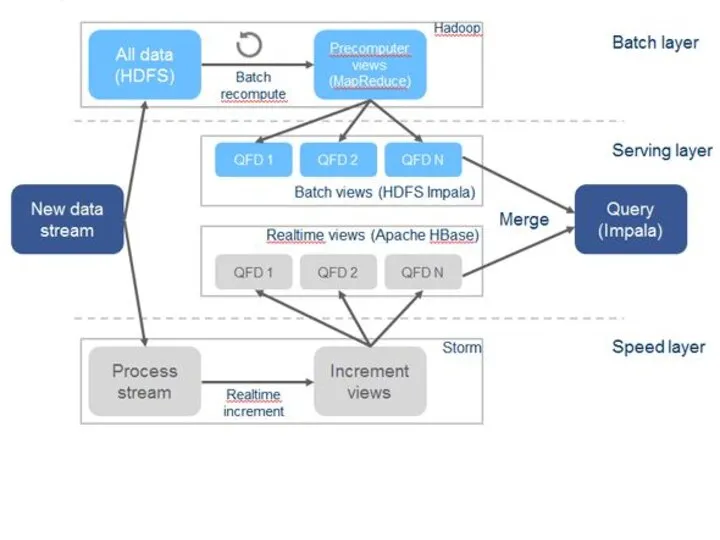
Слайд 5Новые данные поступают на оба уровня: Пакетный и Ускорения (A). Мастер (B)
Новые данные поступают на оба уровня: Пакетный и Ускорения (A). Мастер (B)

Слайд 6На данный момент существуют различные вариации технологических компонент для Лямбда-архитектуры.
Например, проект
На данный момент существуют различные вариации технологических компонент для Лямбда-архитектуры.
Например, проект

 Системы счисления
Системы счисления Как работать с 1с не в локальной сети
Как работать с 1с не в локальной сети Комплексное продвижение групп ВКонтакте
Комплексное продвижение групп ВКонтакте Средства массовой информации, которыми я интересуюсь
Средства массовой информации, которыми я интересуюсь Оформление библиографического описания
Оформление библиографического описания Основы передачи дискретных сообщений. Лекция 3
Основы передачи дискретных сообщений. Лекция 3 Место и роль ПКП
Место и роль ПКП Общая постановка и алгоритм решения задач динамического программирования. Тема 1.5
Общая постановка и алгоритм решения задач динамического программирования. Тема 1.5 ShotOut 3D
ShotOut 3D Человек и информация
Человек и информация Моделирование в среде графического редактора (урок информатики)
Моделирование в среде графического редактора (урок информатики) Циклы по переменной. Программирование на языке Python
Циклы по переменной. Программирование на языке Python Видеоблогинг. Мастер-класс
Видеоблогинг. Мастер-класс Пэкмен. Обзор. Скайрим – моя жизнь
Пэкмен. Обзор. Скайрим – моя жизнь Процесс разработки программного обеспечения
Процесс разработки программного обеспечения Операционная система
Операционная система Вещественные числа
Вещественные числа Adobe Photoshop
Adobe Photoshop Региональная геоинформационная система Новосибирской области
Региональная геоинформационная система Новосибирской области Разработка программного модуля для визуализации и аналитики данных
Разработка программного модуля для визуализации и аналитики данных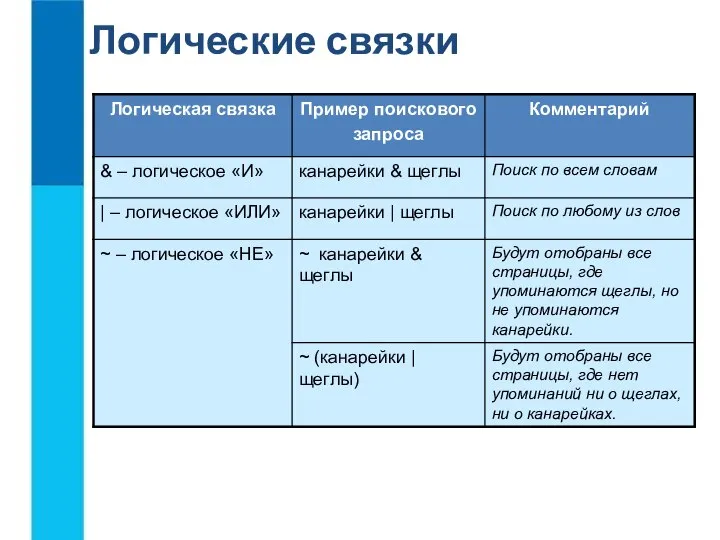 Круги Эйлера
Круги Эйлера Instrukcja instalacji programu Maestro System operacyjny Windows
Instrukcja instalacji programu Maestro System operacyjny Windows Градиент, фон, фильтр
Градиент, фон, фильтр Текстовый процессор Writer
Текстовый процессор Writer Буккроссинг - новое увлечение современных людей
Буккроссинг - новое увлечение современных людей Операторы цикла
Операторы цикла Интерактивный тест по информатике
Интерактивный тест по информатике Импорт документов. Платежное поручение с автоопределением формата
Импорт документов. Платежное поручение с автоопределением формата