- Multiple Imputations. Основы теории

Содержание
- 2. ВВЕДЕНИЕ
- 3. Проблема missing data В любом исследовании неизбежно часть данных, которые планировалось собрать, не будут собраны Пациенты
- 4. Проблема missing data Рассмотрим исследование средства для снижения веса 100 участников принимают его в течение года
- 5. Проблема missing data В конце исследования у нас есть данные только тех, кто похудел. Если судить
- 6. Missing Mechanisms Missing Completely at Random (MCAR): вероятность, что у конкретного пациента будет missing значение не
- 7. Missing Mechanisms Пример со средством для снижения веса – MNAR MCAR и MAR – не очень
- 8. Imputation Methods Большое разнообразие: LOCF, worst case, среднее по группе и проч. Multiple Imputation – надежный
- 9. План семинара Основы теории Реализация метода MI в SAS: процедуры MI и MIANALYZE MI и ADaM-датасеты
- 10. MULTIPLE IMPUTATIONS – ОСНОВЫ ТЕОРИИ
- 11. Идея multiple imputation Основная идея – давайте построим модель для предсказания отсутствующих данных Мы же строим
- 12. Пример моделирования Пример: допустим мы измеряем рост пациентов, и у нескольких рост не был измерен Построим
- 13. Пример моделирования
- 14. Проблема простого моделирования Хорошая идея, но вот проблема. Imputed рост будет использован затем в каком-то анализе,
- 15. Решение – multiple imputation
- 16. Решение – multiple imputation Применим генератор случайных чисел и сделаем для каждого пациента несколько предсказаний Проведем
- 17. Дональд Рубин Почетный профессор Гарвардского университета, создал основы метода multiple imputation
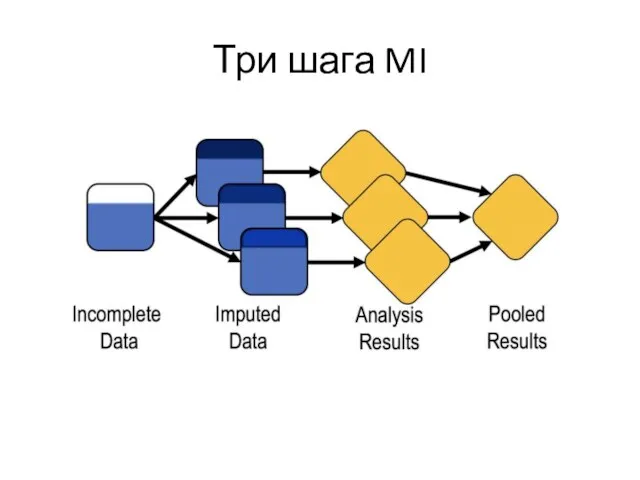
- 18. Три шага MI Шаг 1 – impute несколько раз В SAS реализуется PROC MI Есть несколько
- 19. Три шага MI Шаг 2: провести анализ каждого набора предсказаний Применяем совершенно любые процедуры SAS BY
- 20. Три шага MI Шаг 3:сводим вместе результаты нескольких анализов В SAS реализуется PROC MIANALYZE Конкретный синтаксис
- 21. Три шага MI
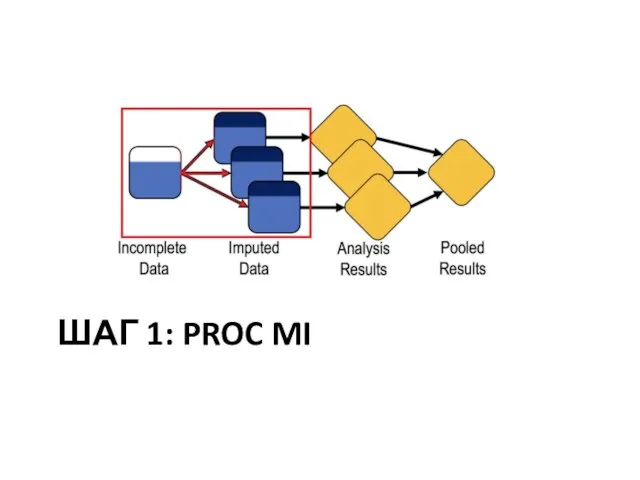
- 22. ШАГ 1: PROC MI
- 23. PROC MI В этом разделе мы изучим, как вызывать PROC MI. У этой процедуры сложный синтаксис.
- 24. MI: основные вопросы Чтобы корректно провести MI, надо ответить на такие вопросы: Какие переменные мы хотим
- 25. Выбор переменных Очевидно, мы хотим “impute” study endpoints. Но если наш endpoint не собирается непосредственно, а
- 26. Выбор факторов Общий совет: чем больше, тем лучше. Факторы, которые потом включаются в модель анализа Факторы,
- 27. Выбор факторов Факторы, которые могут быть коррелированы с переменной, которую мы пытаемся “impute” Другие endpoints Может
- 28. Выбор факторов Факторы, которые могут быть связаны с вероятностью иметь missing значение Completed/Discontinued Причина discontinuation или
- 29. Факторы и “imputed” переменные За один раз можно “impute” несколько переменных Более того, факторы тоже могут
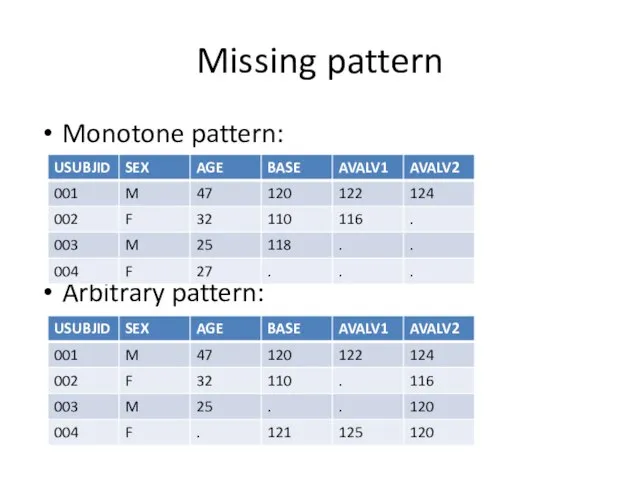
- 30. Missing pattern Прежде, чем разбираться с выбором метода imputation, надо ввести понятие missing pattern: monotone или
- 31. Missing pattern Monotone pattern: Arbitrary pattern:
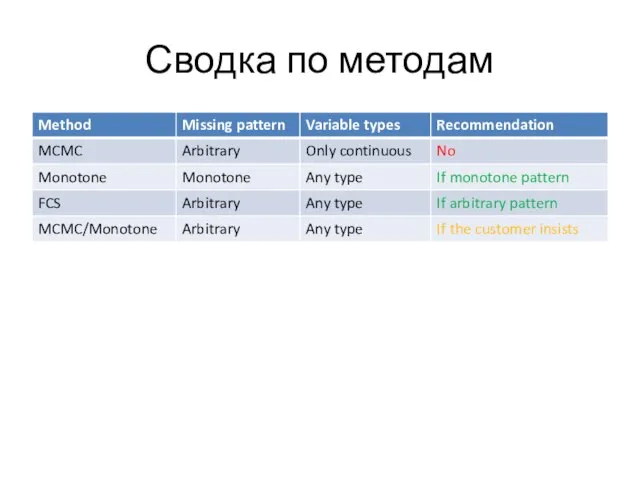
- 32. Методы imputation Основные методы: MCMC (Monte-Carlo Markov Chain) Monotone FCS (Fully Conditioned Specifications) Гибридный метод MCMC/Monotone
- 33. Метод MCMC Подразумевает, что все переменные (“imputed” и факторы) вместе имеют многомерное нормальное распределение Т.о. как
- 34. А.А. Марков и казино Монте-Карло
- 35. Метод Monotone “Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными Missing pattern: monotone Не итеративный
- 36. Метод FCS “Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными Missing pattern: arbitrary Самый гибкий
- 37. Гибридный метод MCMC/Monotone Устаревший метод! Применялся до создания FCS И тем не менее, есть заказчики-ретрограды, которые
- 38. Сводка по методам
- 39. Типы моделей Методы Monotone и FCS поддерживают несколько разных типов моделей Reg: линейная регрессия Regpmm (regression
- 40. Типы моделей Выбор типа модели определяется типом “imputed” переменной: Непрерывная: reg или regpmm. Рекомендация: Переменная с
- 41. Сколько imputations делать 50 почти всегда подойдет Если очень много данных, это может быть долго, можно
- 42. Синтаксис PROC MI proc mi ...; var var1 var2 var3 var4 ...; class var1 var2 ...;
- 43. Опции PROC MI data= - входной датасет out= - выходной датасет nimpute= - к-во imputations Если
- 44. Операторы var и class В операторе var перечисляются все переменные – те, что мы хотим “impute”
- 45. Оператор MCMC MCMC Опции: chain=single или chain=multiple Нет рекомендаций, оставляем по умолчанию Impute=monotone Impute только до
- 46. Операторы Monotone и FCS MONOTONE (imputed = factors) FCS такой же синтаксис MONOTONE reg (avalv2 =
- 47. Операторы Monotone и FCS Упрощенный вариант: FCS REG (avalv1 avalv2); Все переменные imputed по очереди MONOTONE:
- 48. Дополнительные опции PROC MI minimum=, maximum=, round= Задается минимальное или максимальное значение для imputed переменной и
- 49. Дополнительные опции PROC MI Пример: PROC MI minimum=. . . 1 1 maximum=. . . 100
- 50. Гибридный метод MCMC/Monotone Два вызова PROC MI: proc mi data=... out=mono ...; var ...; mcmc impute=monotone;
- 51. Гибридный метод MCMC/Monotone Что делать в первом шаге гибридного метода, если есть категориальные факторы? Опустить Бинарные
- 52. Пример PROC MI proc mi data=... out=... nimpute=50 seed=45780; var weight base chg4 chg8 chg12; monotone
- 53. Пример PROC MI proc mi data=… out=… nimpute=50 seed=122001; var trtp disstab skinclass base chg12 chg24;
- 54. Пример PROC MI proc mi data=... out=... nimpute=50 seed=2031602; var trtpn sitegr1 base chg5-chg7; class trtpn
- 55. Пример PROC MI proc mi data=.. out=... nimpute=50 round=1 seed=45779; by trtpn; var weight base chg4
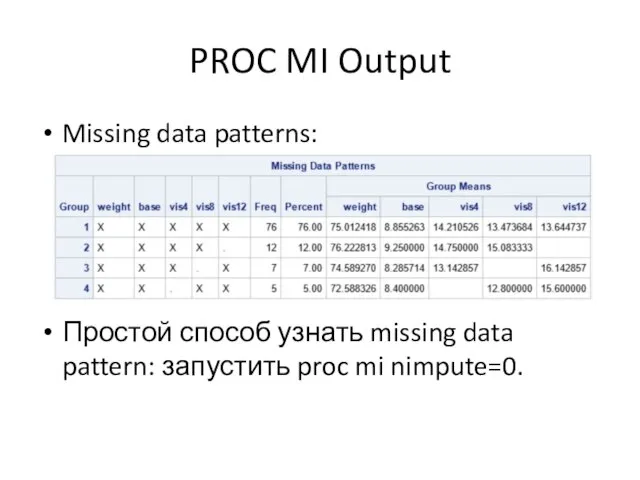
- 56. PROC MI Output Missing data patterns: Простой способ узнать missing data pattern: запустить proc mi nimpute=0.
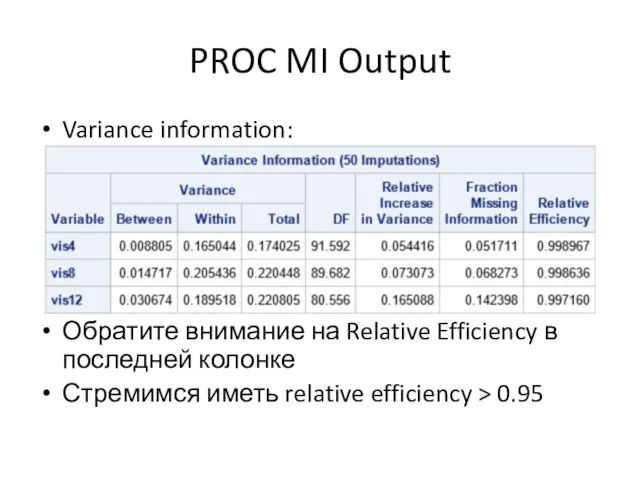
- 57. PROC MI Output Variance information: Обратите внимание на Relative Efficiency в последней колонке Стремимся иметь relative
- 58. Relative Efficiency “Relative” to infinite number of imputations Что делать, если RE Увеличить nimpute Но если
- 59. ШАГ 2: АНАЛИЗ
- 60. Анализ multiple imputed data Применяем любые процедуры С оператором BY _IMPUTATION_ Сохраняем результаты в датасеты с
- 61. ШАГ 3: PROC MIANALYZE
- 62. PROC MIANALYZE На входе этого шага мы имеем результаты анализа каждого из наборов multiple imputed данных
- 63. Обработка результатов PROC MIXED PROC MIXED реализует mixed model, но также ANOVA, ANCOVA Обычно обрабатываем результаты
- 64. Обработка результатов PROC MIXED proc mianalyze parms=LSMeans; class trtpn; modeleffects trtpn; run; В опции parms указываем
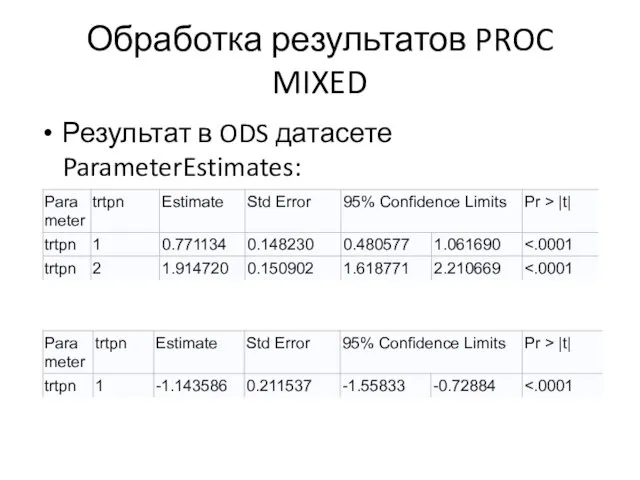
- 65. Обработка результатов PROC MIXED Результат в ODS датасете ParameterEstimates:
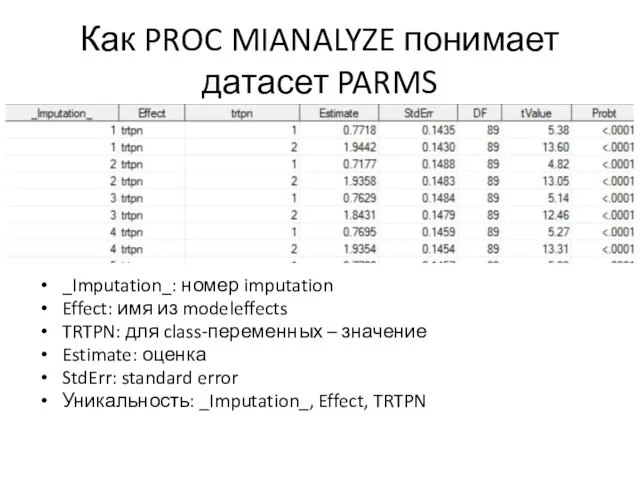
- 66. Как PROC MIANALYZE понимает датасет PARMS _Imputation_: номер imputation Effect: имя из modeleffects TRTPN: для class-переменных
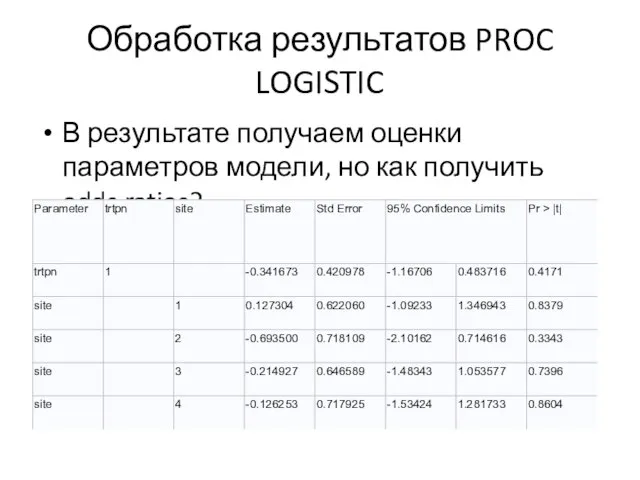
- 67. Обработка результатов PROC LOGISTIC proc logistic data=…; by _imputation_; class trtpn site / param=ref; model avalc
- 68. Обработка результатов PROC LOGISTIC В результате получаем оценки параметров модели, но как получить odds ratios?
- 69. Обработка результатов PROC LOGISTIC Нужно экспоненциировать (функция exp) оценку параметра и доверительные пределы Не забываем в
- 70. MIANALYZE: Общий случай Если процедура не имеет в MIANALYZE специальной поддержки, то обрабатываем результаты так: Входной
- 71. MIANALYZE: Wilcoxon test Пример применения общего случая для обработки результата Wilcoxon test: proc npar1way data=… wilcoxon;
- 72. MIANALYZE: Wilcoxon test Делаем data step и добавляем в датасет WilcoxonTest переменную StdErr, равную 1 на
- 73. MIANALYZE: binomial proportion Другой пример общего случая: обработать пропорции пациентов, которые достигли какого-то response. Пропорция (или
- 74. MIANALYZE: binomial proportion proc freq data=…; by trtpn _imputation_; tables avalc / binomial; run; Сохраняем ODS
- 75. MIANALYZE: binomial proportion После этого: proc mianalyze data=…; by trtpn; modeleffects _BIN_; stderr E_BIN; run; Для
- 76. MIANALYZE: прочие случаи Обработка следующих типов анализа затруднена тем, что статистики не имеют нормального распределения: Chi-square
- 77. MIANALYZE: прочие случаи Общий подход: Применить преобразование, которое переводит распределение нужной статистики к нормальному Применить proc
- 78. MI: пример См. пример кода
- 79. MULTIPLE IMPUTATION AND ADAM DATASETS
- 80. Multiple Imputation and ADaM Datasets Должны ли мы сохранять результат PROC MI в датасет или делать
- 81. Создание датасета с результатами MI Рекомендация: создать один датасет без MI и другой, отдельный, с MI
- 82. Создание датасета с MI Если в imputation model участвуют данные с других визитов или endpoints, датасет
- 83. Создание датасета с MI (продолжение) PROC MI никак не обозначает, какие данные были известны, а какие
- 84. Использование датасета с MI В программе таблицы выполняем шаги 2 (анализ) и 3 (PROC MIANALYZE) Перед
- 85. Пример программы для MI датасета Пример кода
- 86. MISSING NOT AT RANDOM
- 87. Missing Not at Random Что, если наши данные Missing Not at Random (MNAR)? Напомним, это означает,
- 88. Missing Not at Random До сих пор мы моделировали отсутствующие данные на основе наблюдаемых Т.е. полагали,
- 89. Sensitivity to MAR И что же делать? Нужно провести sensitivity analysis, проверяющий “sensitivity” результатов анализа к
- 90. Pattern-Mixture Models Pattern-Mixture Models – широкий класс подходов, мы будем рассматривать нужный нам частный случай Основная
- 91. У кого данные могут быть хуже? У всех пациентов с missing data У всех, кто принимал
- 92. Насколько хуже могут быть данные? Рассмотрим два подхода: Control-based imputation Penalization
- 93. Control-Based Imputation Предполагаем, что состояние выбывших пациентов, принимавших тестовое лекарство аналогично состоянию не выбывших пациентов из
- 94. Penalization Предполагаем, что missing данные хуже на какую-то величину в абсолютном или процентном выражении Из результата
- 95. Tipping-point Analysis Идея такая: провести анализ с penalization несколько раз, постепенно увеличивая penalization factor, и посмотреть,
- 96. Two-dimensional Tipping-Point Перебирают комбинации разных penalization factors для тестового и контрольного лекарства Смотрят, при каких комбинация
- 97. MNAR: РЕАЛИЗАЦИЯ В SAS
- 98. MNAR Statement Для реализации основных видов анализа MNAR в PROC MI есть оператор MNAR Он такой
- 99. Control-Based Imputation proc mi data=… out=… nimpute=…; var …; class trtpn …; fcs reg(resp); mnar model
- 100. Control-Based Imputation Что если стоит такая задача: Применить control-based imputation для пациентов из тестовой группы, которые
- 101. Penalization proc mi data=… out=… nimpute=… seed=…; var trtpn resp …; class trtpn …; fcs reg(resp);
- 102. Tipping-point analysis Tipping-point analysis можно реализовать так: Делаем макрос, в нем в цикле вызываем PROC MI
- 103. 2-dimensional tipping-point analysis Для реализации 2-dimensional tipping-point analysis можно задавать две опции ADJUST с разными условиями:
- 104. Tipping-point – вопросы времени выполнения PROC MI может работать относительно долго При tipping-point анализе, особенно 2-dimensional,
- 105. Tipping-point – вопросы времени выполнения Можно рассмотреть вариант с «ручным» penalization Вы вызываете PROC MI один
- 106. Penalization c бинарными переменными Метод penalization наиболее понятен для непрерывных переменных, но также применим к бинарным
- 107. Penalization c бинарными переменными Для imputation бинарных переменных PROC MI использует логистическую регрессию Вспомним, как она
- 108. Penalization c бинарными переменными Т.о. MI работает так: P-step: Подобрать коэффициенты модели для моделирования log odds
- 109. Penalization c бинарными переменными Оператор MNAR может вставить penalization между шагами 2 и 3, т.е. ухудшить
- 110. Penalization c бинарными переменными Проблема: log odds сложно интерпретировать: Уменьшение log odds на X означает уменьшение
- 111. Penalization c бинарными переменными Возможен альтернативный подход к penalization без оператора MNAR При этом подходе penalization
- 112. Penalization c бинарными переменными Схема этого процесса: Запускаем PROC MI без оператора MNAR. Используем опцию details,
- 114. Скачать презентацию

Слайд 3Проблема missing data
В любом исследовании неизбежно часть данных, которые планировалось собрать, не
Проблема missing data
В любом исследовании неизбежно часть данных, которые планировалось собрать, не

Слайд 4Проблема missing data
Рассмотрим исследование средства для снижения веса
100 участников принимают его в
Проблема missing data
Рассмотрим исследование средства для снижения веса
100 участников принимают его в

Слайд 5Проблема missing data
В конце исследования у нас есть данные только тех, кто
Проблема missing data
В конце исследования у нас есть данные только тех, кто

Слайд 6Missing Mechanisms
Missing Completely at Random (MCAR): вероятность, что у конкретного пациента будет
Missing Mechanisms
Missing Completely at Random (MCAR): вероятность, что у конкретного пациента будет

Слайд 7Missing Mechanisms
Пример со средством для снижения веса – MNAR
MCAR и MAR –
Missing Mechanisms
Пример со средством для снижения веса – MNAR
MCAR и MAR –

Слайд 8Imputation Methods
Большое разнообразие: LOCF, worst case, среднее по группе и проч.
Multiple Imputation
Imputation Methods
Большое разнообразие: LOCF, worst case, среднее по группе и проч.
Multiple Imputation

Слайд 9План семинара
Основы теории
Реализация метода MI в SAS: процедуры MI и MIANALYZE
MI и
План семинара
Основы теории
Реализация метода MI в SAS: процедуры MI и MIANALYZE
MI и

Слайд 10MULTIPLE IMPUTATIONS – ОСНОВЫ ТЕОРИИ
MULTIPLE IMPUTATIONS – ОСНОВЫ ТЕОРИИ

Слайд 11Идея multiple imputation
Основная идея – давайте построим модель для предсказания отсутствующих данных
Мы
Идея multiple imputation
Основная идея – давайте построим модель для предсказания отсутствующих данных
Мы

Слайд 12Пример моделирования
Пример: допустим мы измеряем рост пациентов, и у нескольких рост не
Пример моделирования
Пример: допустим мы измеряем рост пациентов, и у нескольких рост не

Слайд 13Пример моделирования
Пример моделирования

Слайд 14Проблема простого моделирования
Хорошая идея, но вот проблема. Imputed рост будет использован затем
Проблема простого моделирования
Хорошая идея, но вот проблема. Imputed рост будет использован затем

Слайд 15Решение – multiple imputation
Решение – multiple imputation

Слайд 16Решение – multiple imputation
Применим генератор случайных чисел и сделаем для каждого пациента
Решение – multiple imputation
Применим генератор случайных чисел и сделаем для каждого пациента

Слайд 17Дональд Рубин
Почетный профессор Гарвардского университета, создал основы метода multiple imputation
Дональд Рубин
Почетный профессор Гарвардского университета, создал основы метода multiple imputation

Слайд 18Три шага MI
Шаг 1 – impute несколько раз
В SAS реализуется PROC MI
Есть
Три шага MI
Шаг 1 – impute несколько раз
В SAS реализуется PROC MI
Есть

Слайд 19Три шага MI
Шаг 2: провести анализ каждого набора предсказаний
Применяем совершенно любые процедуры
Три шага MI
Шаг 2: провести анализ каждого набора предсказаний
Применяем совершенно любые процедуры

Слайд 20Три шага MI
Шаг 3:сводим вместе результаты нескольких анализов
В SAS реализуется PROC MIANALYZE
Конкретный
Три шага MI
Шаг 3:сводим вместе результаты нескольких анализов
В SAS реализуется PROC MIANALYZE
Конкретный

Слайд 21Три шага MI
Три шага MI
Слайд 22ШАГ 1: PROC MI
ШАГ 1: PROC MI
Слайд 23PROC MI
В этом разделе мы изучим, как вызывать PROC MI. У этой
PROC MI
В этом разделе мы изучим, как вызывать PROC MI. У этой

Слайд 24MI: основные вопросы
Чтобы корректно провести MI, надо ответить на такие вопросы:
Какие переменные
MI: основные вопросы
Чтобы корректно провести MI, надо ответить на такие вопросы:
Какие переменные

Слайд 25Выбор переменных
Очевидно, мы хотим “impute” study endpoints.
Но если наш endpoint не собирается
Выбор переменных
Очевидно, мы хотим “impute” study endpoints.
Но если наш endpoint не собирается

Слайд 26Выбор факторов
Общий совет: чем больше, тем лучше.
Факторы, которые потом включаются в модель
Выбор факторов
Общий совет: чем больше, тем лучше.
Факторы, которые потом включаются в модель

Слайд 27Выбор факторов
Факторы, которые могут быть коррелированы с переменной, которую мы пытаемся “impute”
Другие
Выбор факторов
Факторы, которые могут быть коррелированы с переменной, которую мы пытаемся “impute”
Другие

Слайд 28Выбор факторов
Факторы, которые могут быть связаны с вероятностью иметь missing значение
Completed/Discontinued
Причина discontinuation
Выбор факторов
Факторы, которые могут быть связаны с вероятностью иметь missing значение
Completed/Discontinued
Причина discontinuation

Слайд 29Факторы и “imputed” переменные
За один раз можно “impute” несколько переменных
Более того, факторы
Факторы и “imputed” переменные
За один раз можно “impute” несколько переменных
Более того, факторы

Слайд 30Missing pattern
Прежде, чем разбираться с выбором метода imputation, надо ввести понятие missing
Missing pattern
Прежде, чем разбираться с выбором метода imputation, надо ввести понятие missing

Слайд 31Missing pattern
Monotone pattern:
Arbitrary pattern:
Missing pattern
Monotone pattern:
Arbitrary pattern:
Слайд 32Методы imputation
Основные методы:
MCMC (Monte-Carlo Markov Chain)
Monotone
FCS (Fully Conditioned Specifications)
Гибридный метод MCMC/Monotone
При выборе
Методы imputation
Основные методы:
MCMC (Monte-Carlo Markov Chain)
Monotone
FCS (Fully Conditioned Specifications)
Гибридный метод MCMC/Monotone
При выборе

Слайд 33Метод MCMC
Подразумевает, что все переменные (“imputed” и факторы) вместе имеют многомерное нормальное
Метод MCMC
Подразумевает, что все переменные (“imputed” и факторы) вместе имеют многомерное нормальное

Слайд 34А.А. Марков и казино Монте-Карло
А.А. Марков и казино Монте-Карло

Слайд 35Метод Monotone
“Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными
Missing pattern: monotone
Не
Метод Monotone
“Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными
Missing pattern: monotone
Не

Слайд 36Метод FCS
“Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными
Missing pattern: arbitrary
Самый
Метод FCS
“Imputed” переменная и факторы могут быть непрерывными, бинарными, категориальными
Missing pattern: arbitrary
Самый

Слайд 37Гибридный метод MCMC/Monotone
Устаревший метод!
Применялся до создания FCS
И тем не менее, есть заказчики-ретрограды,
Гибридный метод MCMC/Monotone
Устаревший метод!
Применялся до создания FCS
И тем не менее, есть заказчики-ретрограды,

Слайд 38Сводка по методам
Сводка по методам
Слайд 39Типы моделей
Методы Monotone и FCS поддерживают несколько разных типов моделей
Reg: линейная регрессия
Regpmm
Типы моделей
Методы Monotone и FCS поддерживают несколько разных типов моделей
Reg: линейная регрессия
Regpmm

Слайд 40Типы моделей
Выбор типа модели определяется типом “imputed” переменной:
Непрерывная: reg или regpmm. Рекомендация:
Переменная
Типы моделей
Выбор типа модели определяется типом “imputed” переменной:
Непрерывная: reg или regpmm. Рекомендация:
Переменная

Слайд 41Сколько imputations делать
50 почти всегда подойдет
Если очень много данных, это может быть
Сколько imputations делать
50 почти всегда подойдет
Если очень много данных, это может быть

Слайд 42Синтаксис PROC MI
proc mi ...;
var var1 var2 var3 var4 ...;
class
Синтаксис PROC MI
proc mi ...;
var var1 var2 var3 var4 ...;
class

Слайд 43Опции PROC MI
data= - входной датасет
out= - выходной датасет
nimpute= - к-во imputations
Если
Опции PROC MI
data= - входной датасет
out= - выходной датасет
nimpute= - к-во imputations
Если

Слайд 44Операторы var и class
В операторе var перечисляются все переменные – те, что
Операторы var и class
В операторе var перечисляются все переменные – те, что

Слайд 45Оператор MCMC
MCMC <опции>
Опции:
chain=single или chain=multiple
Нет рекомендаций, оставляем по умолчанию
Impute=monotone
Impute только до достижения
Оператор MCMC
MCMC <опции>
Опции:
chain=single или chain=multiple
Нет рекомендаций, оставляем по умолчанию
Impute=monotone
Impute только до достижения

Слайд 46Операторы Monotone и FCS
MONOTONE <тип модели> (imputed = factors)
FCS такой же синтаксис
MONOTONE
Операторы Monotone и FCS
MONOTONE <тип модели> (imputed = factors)
FCS такой же синтаксис
MONOTONE

Слайд 47Операторы Monotone и FCS
Упрощенный вариант:
FCS REG (avalv1 avalv2);
Все переменные imputed по очереди
MONOTONE:
Операторы Monotone и FCS
Упрощенный вариант:
FCS REG (avalv1 avalv2);
Все переменные imputed по очереди
MONOTONE:

Слайд 48Дополнительные опции PROC MI
minimum=, maximum=, round=
Задается минимальное или максимальное значение для imputed
Дополнительные опции PROC MI
minimum=, maximum=, round=
Задается минимальное или максимальное значение для imputed

Слайд 49Дополнительные опции PROC MI
Пример:
PROC MI minimum=. . . 1 1 maximum=. .
Дополнительные опции PROC MI
Пример:
PROC MI minimum=. . . 1 1 maximum=. .

Слайд 50Гибридный метод MCMC/Monotone
Два вызова PROC MI:
proc mi data=... out=mono ...;
var ...;
Гибридный метод MCMC/Monotone
Два вызова PROC MI:
proc mi data=... out=mono ...;
var ...;

Слайд 51Гибридный метод MCMC/Monotone
Что делать в первом шаге гибридного метода, если есть категориальные
Гибридный метод MCMC/Monotone
Что делать в первом шаге гибридного метода, если есть категориальные

Слайд 52Пример PROC MI
proc mi data=... out=... nimpute=50 seed=45780;
var weight base chg4
Пример PROC MI
proc mi data=... out=... nimpute=50 seed=45780;
var weight base chg4

Слайд 53Пример PROC MI
proc mi data=… out=… nimpute=50 seed=122001;
var trtp disstab skinclass
Пример PROC MI
proc mi data=… out=… nimpute=50 seed=122001;
var trtp disstab skinclass

Слайд 54Пример PROC MI
proc mi data=... out=... nimpute=50
seed=2031602;
var trtpn sitegr1 base
Пример PROC MI
proc mi data=... out=... nimpute=50
seed=2031602;
var trtpn sitegr1 base

Слайд 55Пример PROC MI
proc mi data=.. out=... nimpute=50 round=1
seed=45779;
by trtpn;
var
Пример PROC MI
proc mi data=.. out=... nimpute=50 round=1
seed=45779;
by trtpn;
var

Слайд 56PROC MI Output
Missing data patterns:
Простой способ узнать missing data pattern: запустить proc
PROC MI Output
Missing data patterns:
Простой способ узнать missing data pattern: запустить proc
Слайд 57PROC MI Output
Variance information:
Обратите внимание на Relative Efficiency в последней колонке
Стремимся иметь
PROC MI Output
Variance information:
Обратите внимание на Relative Efficiency в последней колонке
Стремимся иметь
Слайд 58Relative Efficiency
“Relative” to infinite number of imputations
Что делать, если RE < 0.95?
Увеличить
Relative Efficiency
“Relative” to infinite number of imputations
Что делать, если RE < 0.95?
Увеличить

Слайд 59ШАГ 2: АНАЛИЗ
ШАГ 2: АНАЛИЗ
Слайд 60Анализ multiple imputed data
Применяем любые процедуры
С оператором BY _IMPUTATION_
Сохраняем результаты в датасеты
Анализ multiple imputed data
Применяем любые процедуры
С оператором BY _IMPUTATION_
Сохраняем результаты в датасеты

Слайд 61ШАГ 3: PROC MIANALYZE
ШАГ 3: PROC MIANALYZE
Слайд 62PROC MIANALYZE
На входе этого шага мы имеем результаты анализа каждого из наборов
PROC MIANALYZE
На входе этого шага мы имеем результаты анализа каждого из наборов

Слайд 63Обработка результатов PROC MIXED
PROC MIXED реализует mixed model, но также ANOVA, ANCOVA
Обычно
Обработка результатов PROC MIXED
PROC MIXED реализует mixed model, но также ANOVA, ANCOVA
Обычно

Слайд 64Обработка результатов PROC MIXED
proc mianalyze parms=LSMeans;
class trtpn;
modeleffects trtpn;
run;
В опции parms
Обработка результатов PROC MIXED
proc mianalyze parms=LSMeans;
class trtpn;
modeleffects trtpn;
run;
В опции parms

Слайд 65Обработка результатов PROC MIXED
Результат в ODS датасете ParameterEstimates:
Обработка результатов PROC MIXED
Результат в ODS датасете ParameterEstimates:
Слайд 66Как PROC MIANALYZE понимает датасет PARMS
_Imputation_: номер imputation
Effect: имя из modeleffects
TRTPN: для
Как PROC MIANALYZE понимает датасет PARMS
_Imputation_: номер imputation
Effect: имя из modeleffects
TRTPN: для
Слайд 67Обработка результатов PROC LOGISTIC
proc logistic data=…;
by _imputation_;
class trtpn site /
Обработка результатов PROC LOGISTIC
proc logistic data=…;
by _imputation_;
class trtpn site /

Слайд 68Обработка результатов PROC LOGISTIC
В результате получаем оценки параметров модели, но как получить
Обработка результатов PROC LOGISTIC
В результате получаем оценки параметров модели, но как получить
Слайд 69Обработка результатов PROC LOGISTIC
Нужно экспоненциировать (функция exp) оценку параметра и доверительные пределы
Не
Обработка результатов PROC LOGISTIC
Нужно экспоненциировать (функция exp) оценку параметра и доверительные пределы
Не

Слайд 70MIANALYZE: Общий случай
Если процедура не имеет в MIANALYZE специальной поддержки, то обрабатываем
MIANALYZE: Общий случай
Если процедура не имеет в MIANALYZE специальной поддержки, то обрабатываем

Слайд 71MIANALYZE: Wilcoxon test
Пример применения общего случая для обработки результата Wilcoxon test:
proc npar1way
MIANALYZE: Wilcoxon test
Пример применения общего случая для обработки результата Wilcoxon test:
proc npar1way

Слайд 72MIANALYZE: Wilcoxon test
Делаем data step и добавляем в датасет WilcoxonTest переменную StdErr,
MIANALYZE: Wilcoxon test
Делаем data step и добавляем в датасет WilcoxonTest переменную StdErr,

Слайд 73MIANALYZE: binomial proportion
Другой пример общего случая: обработать пропорции пациентов, которые достигли какого-то
MIANALYZE: binomial proportion
Другой пример общего случая: обработать пропорции пациентов, которые достигли какого-то

Слайд 74MIANALYZE: binomial proportion
proc freq data=…;
by trtpn _imputation_;
tables avalc / binomial;
run;
Сохраняем
MIANALYZE: binomial proportion
proc freq data=…;
by trtpn _imputation_;
tables avalc / binomial;
run;
Сохраняем

Слайд 75MIANALYZE: binomial proportion
После этого:
proc mianalyze data=…;
by trtpn;
modeleffects _BIN_;
stderr E_BIN;
run;
Для
MIANALYZE: binomial proportion
После этого:
proc mianalyze data=…;
by trtpn;
modeleffects _BIN_;
stderr E_BIN;
run;
Для

Слайд 76MIANALYZE: прочие случаи
Обработка следующих типов анализа затруднена тем, что статистики не имеют
MIANALYZE: прочие случаи
Обработка следующих типов анализа затруднена тем, что статистики не имеют

Слайд 77MIANALYZE: прочие случаи
Общий подход:
Применить преобразование, которое переводит распределение нужной статистики к нормальному
Применить
MIANALYZE: прочие случаи
Общий подход:
Применить преобразование, которое переводит распределение нужной статистики к нормальному
Применить

Слайд 78MI: пример
См. пример кода
MI: пример
См. пример кода

Слайд 79MULTIPLE IMPUTATION AND ADAM DATASETS
MULTIPLE IMPUTATION AND ADAM DATASETS

Слайд 80Multiple Imputation and ADaM Datasets
Должны ли мы сохранять результат PROC MI в
Multiple Imputation and ADaM Datasets
Должны ли мы сохранять результат PROC MI в

Слайд 81Создание датасета с результатами MI
Рекомендация: создать один датасет без MI и другой,
Создание датасета с результатами MI
Рекомендация: создать один датасет без MI и другой,

Слайд 82Создание датасета с MI
Если в imputation model участвуют данные с других визитов
Создание датасета с MI
Если в imputation model участвуют данные с других визитов

Слайд 83Создание датасета с MI (продолжение)
PROC MI никак не обозначает, какие данные были
Создание датасета с MI (продолжение)
PROC MI никак не обозначает, какие данные были

Слайд 84Использование датасета с MI
В программе таблицы выполняем шаги 2 (анализ) и 3
Использование датасета с MI
В программе таблицы выполняем шаги 2 (анализ) и 3

Слайд 85Пример программы для MI датасета
Пример кода
Пример программы для MI датасета
Пример кода

Слайд 86MISSING NOT AT RANDOM
MISSING NOT AT RANDOM

Слайд 87Missing Not at Random
Что, если наши данные Missing Not at Random (MNAR)?
Напомним,
Missing Not at Random
Что, если наши данные Missing Not at Random (MNAR)?
Напомним,

Слайд 88Missing Not at Random
До сих пор мы моделировали отсутствующие данные на основе
Missing Not at Random
До сих пор мы моделировали отсутствующие данные на основе

Слайд 89Sensitivity to MAR
И что же делать?
Нужно провести sensitivity analysis, проверяющий “sensitivity” результатов
Sensitivity to MAR
И что же делать?
Нужно провести sensitivity analysis, проверяющий “sensitivity” результатов

Слайд 90Pattern-Mixture Models
Pattern-Mixture Models – широкий класс подходов, мы будем рассматривать нужный нам
Pattern-Mixture Models
Pattern-Mixture Models – широкий класс подходов, мы будем рассматривать нужный нам

Слайд 91У кого данные могут быть хуже?
У всех пациентов с missing data
У всех,
У кого данные могут быть хуже?
У всех пациентов с missing data
У всех,

Слайд 92Насколько хуже могут быть данные?
Рассмотрим два подхода:
Control-based imputation
Penalization
Насколько хуже могут быть данные?
Рассмотрим два подхода:
Control-based imputation
Penalization

Слайд 93Control-Based Imputation
Предполагаем, что состояние выбывших пациентов, принимавших тестовое лекарство аналогично состоянию
Control-Based Imputation
Предполагаем, что состояние выбывших пациентов, принимавших тестовое лекарство аналогично состоянию

Слайд 94Penalization
Предполагаем, что missing данные хуже на какую-то величину в абсолютном или процентном
Penalization
Предполагаем, что missing данные хуже на какую-то величину в абсолютном или процентном

Слайд 95Tipping-point Analysis
Идея такая: провести анализ с penalization несколько раз, постепенно увеличивая penalization
Tipping-point Analysis
Идея такая: провести анализ с penalization несколько раз, постепенно увеличивая penalization

Слайд 96Two-dimensional Tipping-Point
Перебирают комбинации разных penalization factors для тестового и контрольного лекарства
Смотрят, при
Two-dimensional Tipping-Point
Перебирают комбинации разных penalization factors для тестового и контрольного лекарства
Смотрят, при

Слайд 97MNAR: РЕАЛИЗАЦИЯ В SAS
MNAR: РЕАЛИЗАЦИЯ В SAS

Слайд 98MNAR Statement
Для реализации основных видов анализа MNAR в PROC MI есть оператор
MNAR Statement
Для реализации основных видов анализа MNAR в PROC MI есть оператор

Слайд 99Control-Based Imputation
proc mi data=… out=… nimpute=…;
var …;
class trtpn …;
fcs
Control-Based Imputation
proc mi data=… out=… nimpute=…;
var …;
class trtpn …;
fcs

Слайд 100Control-Based Imputation
Что если стоит такая задача:
Применить control-based imputation для пациентов из тестовой
Control-Based Imputation
Что если стоит такая задача:
Применить control-based imputation для пациентов из тестовой

Слайд 101Penalization
proc mi data=… out=… nimpute=… seed=…;
var trtpn resp …;
class trtpn
Penalization
proc mi data=… out=… nimpute=… seed=…;
var trtpn resp …;
class trtpn

Слайд 102Tipping-point analysis
Tipping-point analysis можно реализовать так:
Делаем макрос, в нем в цикле вызываем
Tipping-point analysis
Tipping-point analysis можно реализовать так:
Делаем макрос, в нем в цикле вызываем

Слайд 1032-dimensional tipping-point analysis
Для реализации 2-dimensional tipping-point analysis можно задавать две опции ADJUST
2-dimensional tipping-point analysis
Для реализации 2-dimensional tipping-point analysis можно задавать две опции ADJUST

Слайд 104Tipping-point – вопросы времени выполнения
PROC MI может работать относительно долго
При tipping-point анализе,
Tipping-point – вопросы времени выполнения
PROC MI может работать относительно долго
При tipping-point анализе,

Слайд 105Tipping-point – вопросы времени выполнения
Можно рассмотреть вариант с «ручным» penalization
Вы вызываете PROC
Tipping-point – вопросы времени выполнения
Можно рассмотреть вариант с «ручным» penalization
Вы вызываете PROC

Слайд 106Penalization c бинарными переменными
Метод penalization наиболее понятен для непрерывных переменных, но также
Penalization c бинарными переменными
Метод penalization наиболее понятен для непрерывных переменных, но также

Слайд 107Penalization c бинарными переменными
Для imputation бинарных переменных PROC MI использует логистическую регрессию
Вспомним,
Penalization c бинарными переменными
Для imputation бинарных переменных PROC MI использует логистическую регрессию
Вспомним,

Слайд 108Penalization c бинарными переменными
Т.о. MI работает так:
P-step:
Подобрать коэффициенты модели для моделирования log
Penalization c бинарными переменными
Т.о. MI работает так:
P-step:
Подобрать коэффициенты модели для моделирования log

Слайд 109Penalization c бинарными переменными
Оператор MNAR может вставить penalization между шагами 2 и
Penalization c бинарными переменными
Оператор MNAR может вставить penalization между шагами 2 и

Слайд 110Penalization c бинарными переменными
Проблема: log odds сложно интерпретировать:
Уменьшение log odds на X
Penalization c бинарными переменными
Проблема: log odds сложно интерпретировать:
Уменьшение log odds на X

Слайд 111Penalization c бинарными переменными
Возможен альтернативный подход к penalization без оператора MNAR
При этом
Penalization c бинарными переменными
Возможен альтернативный подход к penalization без оператора MNAR
При этом

Слайд 112Penalization c бинарными переменными
Схема этого процесса:
Запускаем PROC MI без оператора MNAR. Используем
Penalization c бинарными переменными
Схема этого процесса:
Запускаем PROC MI без оператора MNAR. Используем

 DIDO Wi Fi (Distributed Input Distributed Output)
DIDO Wi Fi (Distributed Input Distributed Output) Безопасность в интернете
Безопасность в интернете Рисуем супер-узоры
Рисуем супер-узоры +1_Основы программирования на VBA
+1_Основы программирования на VBA Информационные процессы в компьютере
Информационные процессы в компьютере Автоматизация проектирования технологических процессов
Автоматизация проектирования технологических процессов Самые популярные сообщения
Самые популярные сообщения Работа с двумерными массивами
Работа с двумерными массивами Компьютерные сети. Лекция №5. Уровень передачи данных или канальный уровень
Компьютерные сети. Лекция №5. Уровень передачи данных или канальный уровень Массивы данных
Массивы данных UI Performance
UI Performance презентация Этапы проектирования баз данных
презентация Этапы проектирования баз данных Руководство по оплате инвестиционных программ компании ICN Holding с использованием платежной системы Банка Авангард
Руководство по оплате инвестиционных программ компании ICN Holding с использованием платежной системы Банка Авангард Программирование линейных алгоритмов
Программирование линейных алгоритмов Презентация "Виртуальный читальный зал" - скачать презентации по Информатике
Презентация "Виртуальный читальный зал" - скачать презентации по Информатике Турнир по Call of duty mobile
Турнир по Call of duty mobile Формирование изображения на экране монитора. Обработка графической информации
Формирование изображения на экране монитора. Обработка графической информации Архитектура ПК
Архитектура ПК Google Планета Земля
Google Планета Земля Программирование линейных алгоритмов. Начала программирования
Программирование линейных алгоритмов. Начала программирования Web-квест (ход конём)
Web-квест (ход конём) Понятие информационной системы (ИС)
Понятие информационной системы (ИС) Компьютер – универсальное устройство обработки информации
Компьютер – универсальное устройство обработки информации Структуры данных
Структуры данных Работа с документами
Работа с документами Ассиметричное шифрование
Ассиметричное шифрование Растровая и векторная графика. Знаки и символы
Растровая и векторная графика. Знаки и символы Semantic Web
Semantic Web