- Основы проектирования баз данных (лекция 6)

Содержание
- 2. База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде
- 3. Типы баз данных: Реляционные базы данных. Данные в реляционной базе организованы в виде таблиц, состоящих из
- 4. Создание базы данных и таблиц Выделение сущностей и их атрибутов, которые будут храниться в базе данных,
- 5. На первом этапе происходит выделение сущностей. Сущность (entity) представляет тип объектов, которые должны храниться в базе
- 6. Восходящий и нисходящий подходы к выделению сущностей и атрибутов Том посещает курс по математике, который преподает
- 8. Атомизация атрибутов При определении атрибутов происходит разделение сложных комплексных элементов на более простые. Так, в случае
- 9. Домен Каждый атрибут имеет домен (domain). Домен представляет набор допустимых значений для одного или нескольких атрибутов.
- 10. Имя. Домен представляет все возможные имена, которые могут использоваться. Каждое имя представляет строку длиной максимум 20
- 11. Определитель NULL При определении атрибутов и их домена необходимо проанализировать, а может ли у атрибута отсутствовать
- 12. Ключи Ключи представляют способ идентификации строк в таблице. С помощью ключей можно связывать строки между различными
- 13. Базы данных могут содержать таблицы, которые связаны между собой различными связями. Связь (relationship) представляет ассоциацию между
- 14. Связи между таблицами бывают следующих типов: Один к одному (объекту одной сущности можно сопоставить только один
- 15. Нормализация Нормализация представляет процесс разделения данных по отдельным связанным таблицам. Нормализация устраняет избыточность данных (data redundancy)
- 16. Нормализация предполагает применение нормальных форм к структуре данных. Каждая нормальная форма (за исключением первой) подразумевает, что
- 17. Вторая нормальная форма (2NF) предполагает, что каждый столбец, не являющийся ключом, должен зависеть от первичного ключа.
- 18. Пятая нормальная форма (5NF) разделяет таблицы на более малые таблицы для устранения избыточности данных. Разбиение идет
- 19. Первая нормальная форма Первая нормальная форма предполагает, что таблица не должна содержать повторяющихся столбцов или таких
- 20. Том посещает курс по математике, который преподает профессор Смит. Сэм посещает курс по математике, которые преподает
- 21. Таблица StudentCourses
- 22. Таблица Emails Таблица StudentCourses
- 23. Вторая нормальная форма Во второй нормальной форме каждый столбец в таблице, который не является ключом, должен
- 24. Таблица Students Таблица Courses Таблица StudentCourses
- 25. Третья нормальная форма Третья нормальная форма предполагает, что каждый столбец, не являющийся ключом, должен зависеть только
- 27. Скачать презентацию
Слайд 2База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся
База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся

Слайд 3Типы баз данных:
Реляционные базы данных. Данные в реляционной базе организованы в виде
Типы баз данных:
Реляционные базы данных. Данные в реляционной базе организованы в виде

Слайд 4Создание базы данных и таблиц
Выделение сущностей и их атрибутов, которые будут храниться
Создание базы данных и таблиц
Выделение сущностей и их атрибутов, которые будут храниться

Слайд 5На первом этапе происходит выделение сущностей. Сущность (entity) представляет тип объектов, которые
На первом этапе происходит выделение сущностей. Сущность (entity) представляет тип объектов, которые

Слайд 6Восходящий и нисходящий подходы к выделению сущностей и атрибутов
Том посещает курс по
Восходящий и нисходящий подходы к выделению сущностей и атрибутов
Том посещает курс по

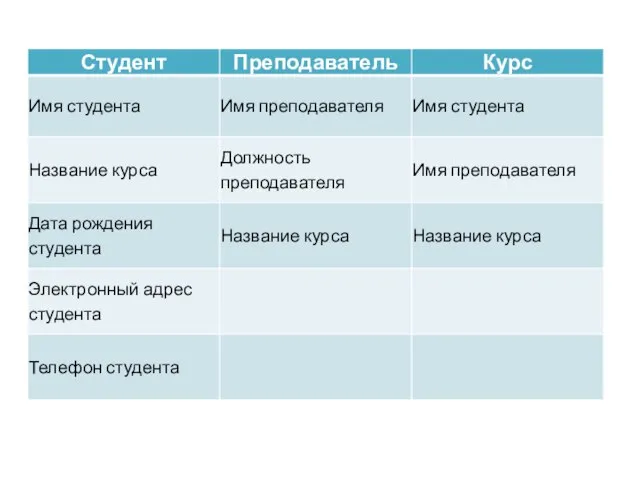
Слайд 8Атомизация атрибутов
При определении атрибутов происходит разделение сложных комплексных элементов на более простые.
Атомизация атрибутов
При определении атрибутов происходит разделение сложных комплексных элементов на более простые.

Слайд 9Домен
Каждый атрибут имеет домен (domain). Домен представляет набор допустимых значений для одного
Домен
Каждый атрибут имеет домен (domain). Домен представляет набор допустимых значений для одного

Слайд 10Имя. Домен представляет все возможные имена, которые могут использоваться. Каждое имя представляет
Имя. Домен представляет все возможные имена, которые могут использоваться. Каждое имя представляет

Слайд 11Определитель NULL
При определении атрибутов и их домена необходимо проанализировать, а может ли
Определитель NULL
При определении атрибутов и их домена необходимо проанализировать, а может ли

Слайд 12Ключи
Ключи представляют способ идентификации строк в таблице. С помощью ключей можно связывать
Ключи
Ключи представляют способ идентификации строк в таблице. С помощью ключей можно связывать

Слайд 13Базы данных могут содержать таблицы, которые связаны между собой различными связями. Связь
Базы данных могут содержать таблицы, которые связаны между собой различными связями. Связь

Слайд 14Связи между таблицами бывают следующих типов:
Один к одному (объекту одной сущности можно
Связи между таблицами бывают следующих типов:
Один к одному (объекту одной сущности можно

Слайд 15Нормализация
Нормализация представляет процесс разделения данных по отдельным связанным таблицам. Нормализация устраняет избыточность
Нормализация
Нормализация представляет процесс разделения данных по отдельным связанным таблицам. Нормализация устраняет избыточность

Слайд 16Нормализация предполагает применение нормальных форм к структуре данных.
Каждая нормальная форма (за
Нормализация предполагает применение нормальных форм к структуре данных.
Каждая нормальная форма (за

Слайд 17Вторая нормальная форма (2NF) предполагает, что каждый столбец, не являющийся ключом, должен
Вторая нормальная форма (2NF) предполагает, что каждый столбец, не являющийся ключом, должен

Слайд 18Пятая нормальная форма (5NF) разделяет таблицы на более малые таблицы для устранения
Пятая нормальная форма (5NF) разделяет таблицы на более малые таблицы для устранения

Слайд 19Первая нормальная форма
Первая нормальная форма предполагает, что таблица не должна содержать повторяющихся
Первая нормальная форма
Первая нормальная форма предполагает, что таблица не должна содержать повторяющихся

Слайд 20Том посещает курс по математике, который преподает профессор Смит.
Сэм посещает курс по
Том посещает курс по математике, который преподает профессор Смит.
Сэм посещает курс по

Слайд 21Таблица StudentCourses
Таблица StudentCourses
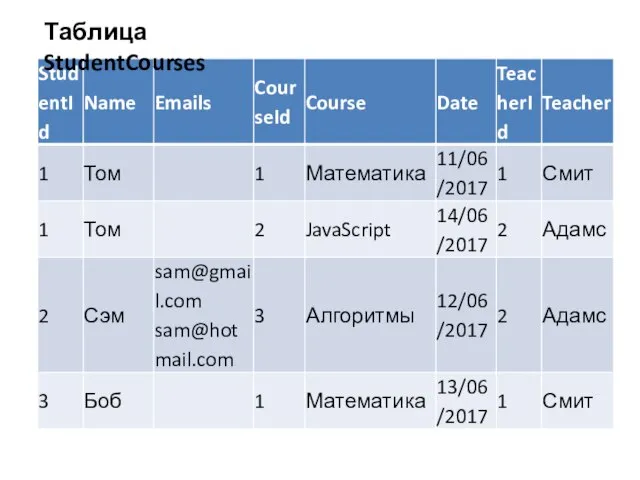
Слайд 22Таблица Emails
Таблица StudentCourses
Таблица Emails
Таблица StudentCourses
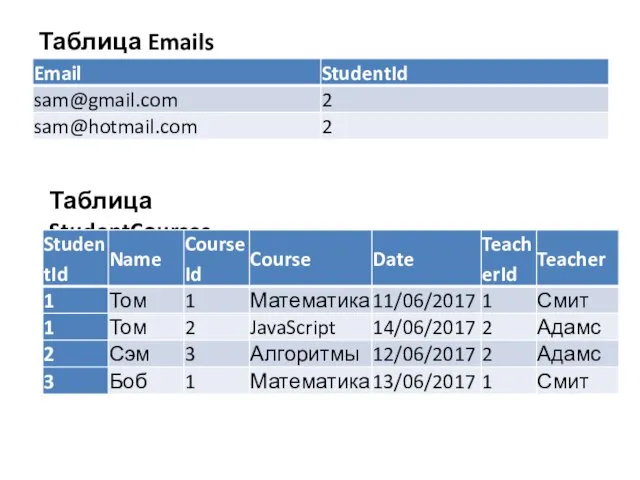
Слайд 23Вторая нормальная форма
Во второй нормальной форме каждый столбец в таблице, который не
Вторая нормальная форма
Во второй нормальной форме каждый столбец в таблице, который не

Слайд 24Таблица Students
Таблица Courses
Таблица StudentCourses
Таблица Students
Таблица Courses
Таблица StudentCourses
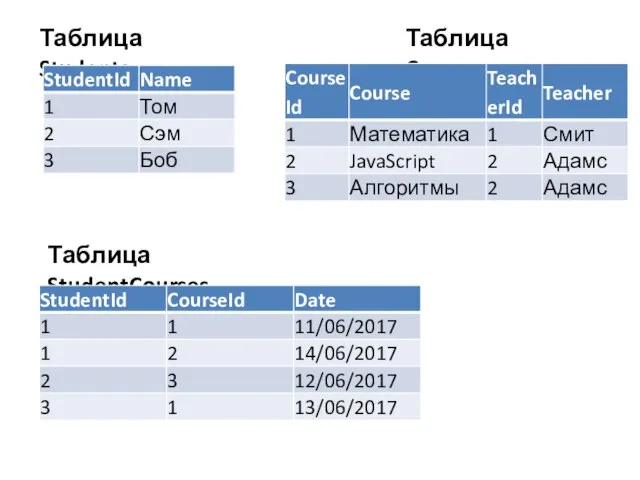
Слайд 25Третья нормальная форма
Третья нормальная форма предполагает, что каждый столбец, не являющийся ключом,
Третья нормальная форма
Третья нормальная форма предполагает, что каждый столбец, не являющийся ключом,

 1666246426895__a84q6r
1666246426895__a84q6r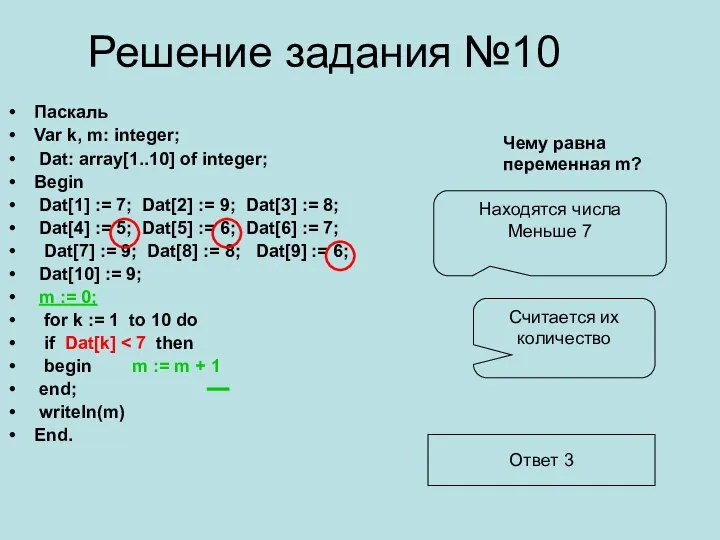 Решение задания №10. Паскаль
Решение задания №10. Паскаль Одномерные массивы. Урок информатики в 11а классе
Одномерные массивы. Урок информатики в 11а классе Презентация на тему Основы HTML
Презентация на тему Основы HTML  Инструкция по получению электроной почты студента
Инструкция по получению электроной почты студента Уроки безопасности в Интернете
Уроки безопасности в Интернете Работа в Excel
Работа в Excel Кодирование графической информации. Флажковая азбука
Кодирование графической информации. Флажковая азбука Электронная рабочая тетрадь. Создание, понятие, структура
Электронная рабочая тетрадь. Создание, понятие, структура Базы данных
Базы данных Операционные системы: виды, назначение. Антивирусное ПО: виды назначение
Операционные системы: виды, назначение. Антивирусное ПО: виды назначение Windows 11 – операционная система 2021
Windows 11 – операционная система 2021 /Мой первый код благотворительный проект игровое программирование для школьников 8-12 лет
/Мой первый код благотворительный проект игровое программирование для школьников 8-12 лет Nodejs intro
Nodejs intro Мобильное Электронное Образование в ДОУ – доступность качественного образования
Мобильное Электронное Образование в ДОУ – доступность качественного образования Инстаграм-программа Sprechen Sie Deutsch? (Разговариваете ли вы на немецком?)
Инстаграм-программа Sprechen Sie Deutsch? (Разговариваете ли вы на немецком?) Анти - вирусы и вирусы
Анти - вирусы и вирусы Программное обеспечение
Программное обеспечение Продвижение учреждения дополнительного образования в социальных сетях
Продвижение учреждения дополнительного образования в социальных сетях Основы программирования на Python
Основы программирования на Python Информационно-технологическая архитектура ИС
Информационно-технологическая архитектура ИС Системы счисления. Непозиционные системы счисления
Системы счисления. Непозиционные системы счисления Цвет в компьютерной графики
Цвет в компьютерной графики Синтаксис оператора
Синтаксис оператора Поиск информации в Интернет. Занятие №7
Поиск информации в Интернет. Занятие №7 Разработка автоматизированной информационной системы для строительного магазина
Разработка автоматизированной информационной системы для строительного магазина Управление собой и другими людьми. 4 класс
Управление собой и другими людьми. 4 класс Информатика. Техника безопасности. Информация и знания
Информатика. Техника безопасности. Информация и знания