- Копия SQL_SBORKA

Содержание
- 2. მონაცემთა ბაზები. საინფორმაციო სისტემები თემა 1. საინფორმაციო სისტემები
- 3. განსაზღვრებები მონაცემთა ბაზები (მბ) –რაიმე საგნობრივი სფეროს შესახებ მონაცემების საცავი, რომელიც ორგანიზებულია სპეციალური სტრუქტურის სახით. მნიშვნელოვანია:
- 4. საინფორმაციო სისტემების ტიპები ლოკალური საინფორმაციო სისტემები მბ და მბმს განთავსებულია ერთსა და იმავე კომპიუტერზე. ფაილ-სერვერული მბ
- 5. ლოკალური საინფორაციო სისტემა (ლსს) ავტონომიურობა (დამოუკიდებლობა) 1) მბ-სთან მუშაობს მხოლოდ ერთი ადამიანი 2) მომხმარებლების დიდი რაოდენობის
- 6. ფაილ-სერვერული სს-ები ერთსა და იმავე ბაზასთან ერთდროულად რამოდენიმე მომხმარებელი მუშაობს ძირითად სამუშაოს ასრულებენ სამუშაო სადგურები (სსადგ),
- 7. კლიენტ-სერვერული სს მბმს-კლიენტი მბმს-კლიენტი მბმს-კლიენტი ძირითად სამუშაოს ასრულეს სერვერი. სამუშაო სადგურები დაბალი სიმძლავრის შეიძლება იყვნენ მარტივია
- 8. მონაცემთა ბაზები. საინფორმაციო სისტემები თემა 2. მონაცემთა ბაზები
- 9. მონაცემთა ბაზების ტიპები ცხრილური მონაცემთა ბაზები მონაცემები ერთი ცხრილის სახით ქსელური მონაცემთა ბაზები კვანძების ერთობლივობა, სადაც
- 10. ცხრილური მონაცემთა ბაზები მოდელი – კართოთეკა მაგალითები: უბის წიგნაკი საბიბლიოთეკო კატალოგი მარტივი სტრუქტურა მბ-ის ყველა დანარჩენი
- 11. ცხრილური მონაცემთა ბაზები ველების რაოდენობა განისაზღვრება დამპროექტებლის მიერ და მომხმარებელს არ შეუძლია მათი შეცვლა. ნებისმიერ ველს
- 12. გასაღები ველი (ცხრილის გასაღები) გასაღები ველი (გასაღები) – ეს არის ველი (ან ველების კომბინაცია), რომელიც ცალსახად
- 13. ქსელური მონაცემთა ბაზა ქსელური მბ - ეს არის კვანძების ერთობლივობა, რომელშიც ყოველი შეიძლება დაკავშირებული იყოს ყოველთან.
- 14. იერარქიული მონაცემთა ბაზა იერარქიული მბ-ეს არის მრავალდონიანი სტრუქტურის სახით წარმოდგენილი მონაცემების ერთობლივობა პრაის-ლისტი: გამყიდველი (დონე1) საქონელი
- 15. იერარქიული მონაცემთა ბაზები ცხრილურ ფორმაზე დაყვანა: მონაცემების დუბლირება არ არსებობს ოპერატორის შეცდომებიდან დაცვის მექანიზმი (ფურცელაძე-პურსელაზე), უკეთესი
- 16. მონაცემთა ბაზები. საინფორმაციო სისტემები თემა 3. მონაცემთა რელაციური ბაზები
- 17. რელაციური მონაცემთა ბაზები 1970-იანი წწ. ე. კოდდი, ინგლისურიდან. relation – კავშირები. რელაციური მონაცემთა ბაზა – ეს
- 18. რელაციური მონაცემთა ბაზები არ ხდება ინფორმაციის დუბლირება; ფირმის მისამართის შეცვლისას, საკმარისია მისი შეცვლა მხოლოდ ცხრილში გამყიდველები;
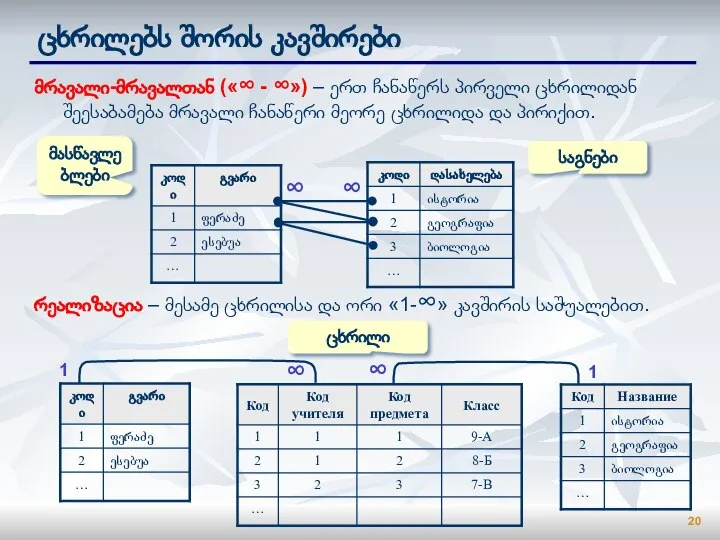
- 19. კავშირები ცხრილებს შორის ერთი-ერთთან («1-1») –ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება ზუსტად ერთი ჩანაწერი მეორე ცხრილიდან. გამოყენება:
- 20. ცხრილებს შორის კავშირები მრავალი-მრავალთან («∞ - ∞») – ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება მრავალი ჩანაწერი მეორე
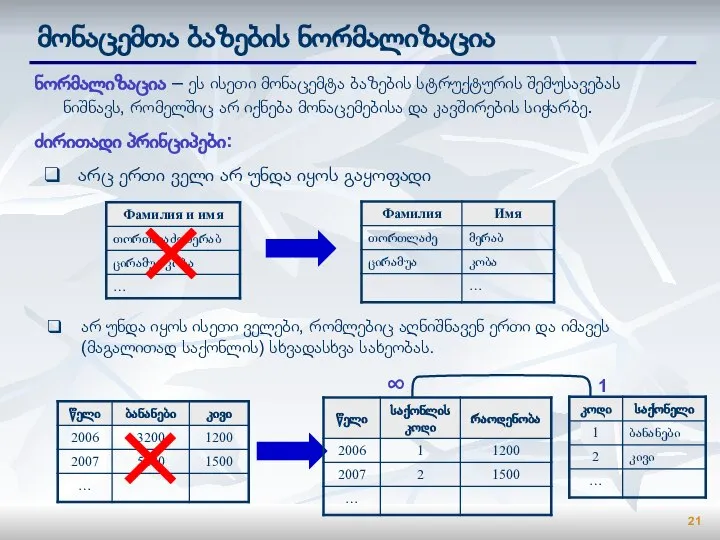
- 21. მონაცემთა ბაზების ნორმალიზაცია ნორმალიზაცია – ეს ისეთი მონაცემტა ბაზების სტრუქტურის შემუსავებას ნიშნავს, რომელშიც არ იქნება მონაცემებისა
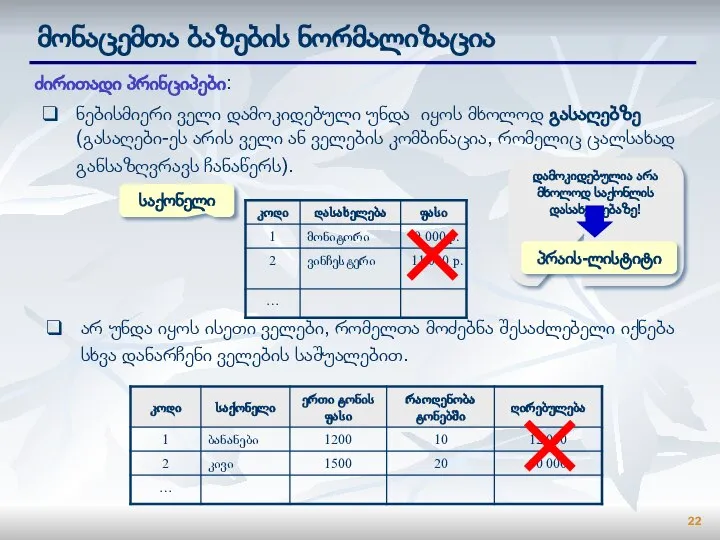
- 22. მონაცემთა ბაზების ნორმალიზაცია ძირითადი პრინციპები: ნებისმიერი ველი დამოკიდებული უნდა იყოს მხოლოდ გასაღებზე (გასაღები-ეს არის ველი ან
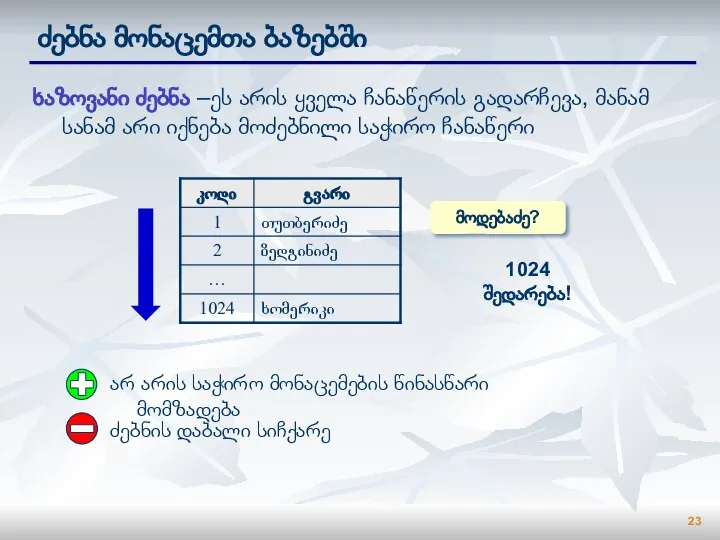
- 23. ძებნა მონაცემთა ბაზებში ხაზოვანი ძებნა –ეს არის ყველა ჩანაწერის გადარჩევა, მანამ სანამ არი იქნება მოძებნილი საჭირო
- 24. ორობითი ძებნა საძიებო არე გავყოთ ორ ტოლ ნაწილად. განვსაზღვროთ, თუ რომელ ნახევარშია ჩვენთვის საჭირო ობიექტი. ამ
- 25. ძებნა მონაცემთა ბაზებში ორობითი ძებნა მბ-ში–მოითხოვს წინასწარ დახარისხებას. Иванов? საჭიროა ჩანაწერების დახარისხება სასურველი ველის მიხედვით; შესაძლებელია
- 26. ძებნა ინდექსების მიხედვით ინდექსი–ეს არის დამხმარე ცხრილი, რომლის დანიშნულება მდგომარეობს არჩეული სვეტის მიხედვით ძირითად ცხრილში ძიების
- 27. ძებნა ინდექსების მიხედვით ძებნის ალგორითმი: ორობითი ძებნა ინდექსის მიხედვით–საჭირო ჩანწერების ნომრების მოძებნა; ძირითადი ცხრილიდან აღნიშნული ჩანაწერების
- 28. Access (Microsoft Office)-ის მონაცემტა ბაზები გაფართოება: *.mdb, ერთი ფაილი შემადგენლობა: ცხრილები; ფორმები –დიალოგური ფანჯრები მონაცემების შეტანისა
- 29. MySQL-ის ბრძანებები და ოპერატორები MySQL-ში გამოყენებული მონაცემთა ტიპები MySQL-ის მონაცემთა ბაზის შექმნა (CREATE DATABASE) MySQL-ის მონაცემთა
- 30. MySQL-ში გამოყენებული მონაცემთა ტიპები 1 მთელი რცხვები 2 წილადი რიცხვები 3 სტრიქონები 4 ბინარული მონაცემები 5
- 31. მთელი რიცხვები მონაცემების ტიპების განსაზღვრის ზოგადი სახე: პრეფიქსი INT [UNSIGNED] არა აუცილებელი ალამი UNSIGNED განსაზღვრავს იმას,
- 32. წილადი რიცხვები მათი ზოგადი სახე ასეთია: ტიპის სახელი[(length, decimals)] [UNSIGNED] აქ: length - ციფრებისათვის განკუთვნილი ადგილების
- 33. სტრიქონები სტრიქონები წარმოადგენენ სიმბოლოების მასივებს. როგორც წესი ტექსტურ ველებში ძიებისას SELECT-ის გამოყენებით არ ხდება რეგისტრის გათვალისწინება.
- 34. ბინარული მონაცემები ბინარული მონაცემები - ეს თითქმის იგივეა, რაც მონაცემები TEXT ფორმატი, მაგრამ ძიებისას მათში ხდება
- 35. თტარიღი და დრო MySQL-ის მიერ მხარდაჭერილია ველების რამოდენიმე ტიპი, რომლებიც გათვალისწინებული არიან თარიღებისა და დროის სხვა
- 36. CREATE DATABASE ოპერატორის სინტაქსი CREATE DATABASE [IF NOT EXISTS] db_name [CHARACTER SET charset] [COLLATE collation]; db_name
- 37. DROP DATABAS ოპერატორის სინტაქსი DROP DATABASE [IF EXISTS] db_name db_name - განსაზღვრავს იმ მონაცემთა ბაზის სახელს,
- 38. CREATE TABLE ოპერატორის სინტაქსი: CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)] [table_options] [select_statement] tbl_name -
- 39. create_definition (3-1) create_definition -განსაზღვრავს შესაქმნელი ცხრილის შიდა სტრუქტურას (ველების დასახელებები და ტიპები, გასაღებები, ინდექსები და ა.შ.)
- 40. create_definition (3-2) col_name - განსაზღვრავს სვეტის სახელს შესაქმნელ ცხრილში. Type - col_name სვეტისათვის განსაზღვრავს მონაცემების ტიპს.
- 41. create_definition (3-3) [NOT NULL | NULL] - მიუთითებს იმაზე, შეიძლება, რომ მოცემული სვეტი შეიცავდეს მნიშვნელობას NULL
- 42. ცხრილის შექმნის მაგალითები შემდეგი მაგალითი ქმნის 3 ველიან ცხრილს-users, სადაც პირველი ველი - ჩანაწერის უნიკალური იდენტიფიკატორია,
- 43. AUTO_INCREMENT შედგენილი გასაღების მეორადი სვეტისათვის MyISAM და BDB ცხრილებში, შედგენილი გასაღების მეორადი სვეტისათვის, AUTO_INCREMENT პარამეტრის განსაზღვრის
- 44. ცხრილის შექმნის მაგალითი AUTO_INCREMENT 1 CREATE TABLE 2 `users` ( 3 `category` ENUM(‘სახლი', ‘სამსახური', ‘სასწავლებელი') NOT
- 45. ახალი ჩანაწერების ჩასმა შექმნილ ცხრილში ჩავსვათ ახალი ჩანაწერები 01 INSERT INTO 02 `users` (`category`, `name`, `age`)
- 46. ჩანაწერების დათვალიერება დავათვალიეროთ users ცხრილის ყველა ჩანაწერი, category და id ველების მიხედვით მათი დალაგების გზით 1
- 47. მიღებული შედეგი შედეგად მივიღებთ: +----------+----+-------+---------------------+ | category | id | name |age | +----------+----+-------+---------------------+ | სახლი
- 48. პირველადი გასაღები [PRIMARY KEY]-განსაზღვრავს ცხრილის პირველად გასაღებს. ცხრილში მხოლოდ ერთი გასაღები ველის განსაზღვრაა შესაძლებელი. პირველად გასაღებ
- 49. ინდექსები ინდექსების სარგებლიანობის თვალსაჩინო მაგალითია წიგნი. წიგნში ინდექსის როლს ასრულებ სარჩევი. სარჩევის მიხედვით ჩვენ სწრაფად ვპოულობთ
- 50. ცხრილის ინდექსირების მაგალითი შემდეგ მაგალითში შევქმნათ ცხრილი users , name და age ველებით და მოვახდინოთ ცხრილის
- 51. გასაღები ველი UNIQUE UNIQUE - ეს გასაღები მიუთითებს იმაზე, რომ მოცემულ სვეტს შეუძლია მხოლოდ უნიკალური მნიშვნელობების
- 52. სრულტექსტოვანი ძიება FULLTEXT-განსაზღვრავს ველებს, რომელთა მიმართაც შემდგომში შესაძლებელია გამოყენებული იქნას სრულტექსტოვანი ძიება. სრულტექსტოვანი ძიება წარმოადგენს MySQL-ის
- 53. ცხრილების შესაძლო ტიპები MySQL-ში BDB - გვერდების ტრანზაქციისა და ბლოკირებების მხარდამჭერი ცხრილები. HEAP - ამ ტიპის
- 54. ველების პარამეტრები AUTO_INCREMENT- მოცემული ცხრილისათვის აყენებს შემდეგ მნიშვნელობას AUTO_INCREMENT. AVG_ROW_LENGTH -განსაზღვრავს მოცემული ცხრილისთვის სტრიქონის საშუალო სიგრძის
- 55. RAID_TYPE, UNION, INSERT_METHOD RAID_TYPE - RAID_TYPE ოპციის გამოყენებით, შესაძლებელია MyISAM მონაცემთა ფაილის დაშლა ნაკვეთებად, რათა დაძლეულ
- 56. DATA DIRECTORY, INDEX DIRECTORY DATA DIRECTORY=“კატალოგი" და INDEX DIRECTORY=“კატალოგი“ ოფციების გამოყენებით ცხრილების დამმუშავებელს შესაძლებელია მიეთითოს, თუ
- 57. მაგალითი ვთქვათ მოცემულია ცხრილი ქალაქების სახელწოდებებით: 1 CREATE TABLE 2 `city`( 3 `name` CHAR(200) NOT NULL
- 58. მაგალითი (გაგრძელება) 01 CREATE TABLE 02 `users`( 03 `id` INT(11) NOT NULL AUTO_INCREMENT, 04 `name` CHAR(200)
- 59. კიდევ ერთი მაგალითი 1 CREATE TABLE 2 `city_new` 3 SELECT 4 `id`, 5 `city_name` AS `name`
- 60. DROP TABLE ოპერატორის სინტაქსი DROP TABLE [IF EXISTS] tbl_name [, tbl_name,...] [RESTRICT | CASCADE] ეს ცხრილი
- 61. ცხრილის თვისებების შეცვლა ALTER TABLE ბრძანების სინტაქსი ALTER [IGNORE] TABLE tbl_name alter_specification [, alter_specification ...] Командаბრძანება
- 62. alter_specification შესაძლო სინტაქსები: ADD [COLUMN] create_definition [FIRST | AFTER column_name ] ADD [COLUMN] (create_definition, create_definition,...) ADD
- 63. ახალი ველის დამატება ADD [COLUMN] create_definition [FIRST | AFTER column_name ] გამოიყენება ცხრილში ახალი ველის დასამატებლად.
- 64. მაგალითი-(3-1) ვთქვათ მოცემულია ცხრილი users შემდეგი ველებით: name, age დავამატოთ ახალი ველი country სიის ბოლოში: 1
- 65. მაგალითი (3-2) დავამატოთ ახალი ველი id სიის დასაწყისში 1 ALTER TABLE 2 `users` 3 ADD 4
- 66. მაგალითი (3-3) დავამატოთ ახალი ველი city, country ველის წინ(ანუ. age ველის შემდეგ): 1 ALTER TABLE 2
- 67. ველების ჯგუფის დამატება ADD [COLUMN] (create_definition, create_definition,...) - ამატებს ცხრილში ერთ ველს ან ველების ჯგუფს. COLUMN-არააუცილებელი
- 68. მაგალითი (1) ცხრილში users დავამატოთ ახალი ველები city და country: 1 ALTER TABLE 2 `users` 3
- 69. ALTER TABLE ALTER TABLE table_name_old RENAME table_name_new table_name_old - ცხრილის ძველი სახელი, რომლის შეცვლაც გვჭირდე; table_name_new
- 70. INSERT INSERT ახორციელებს ახალი სტრიქონების ჩასმას ცხრილში ბრძანების სინტაქსი INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO] tbl_name
- 71. INSERT ბრძანების მუშაობის ზოგადი დებულებები tbl_name - განსაზღვრავს იმ ცხრილის სახელს, რომელშიც მოხდება ახალი სტრიქონის ჩამატება.
- 72. ცხრილში ჩანაწერის ჩასმის მაგალითები შემდეგი ბრძანება users ცხრილში დაამატებს ახალ ჩანაწერს, name, age, country, city ველებისათვის
- 73. INSERT ... SET ამ შემთხვევაში, ბრძანებაში, ცხრილში არსებულ ყოველ ველს, ენიჭება ”ველის სახელი =”მნიშვნელობას” სახის მნიშვნელობა.
- 74. INSERT ... SELECT ასეთი სინტაქსი ცხრილში ერთი მოქმედებით, დიდი რაოდენობის ჩაწერების დამატების საშუალებას იძლევა, თანაც სხვადასხვა
- 75. INSERT ... SELECT სინტაქსია თავისებურება იმ ცხრილის სახელი, რომელშიც ხდება ჩანაწერის ჩამატება, არ უნდა იყოს მითითებული
- 76. Синтаксис команды UPDATE ჩანაწერის განახლება ხორციელდება ბრძანებით UPDATE. ბრძანების სინტაქსი UPDATE [LOW_PRIORITY] [IGNORE] tbl_name SET col_name1=expr1
- 77. მაგალითები (2-1) შემდეგი მაგალითი ახორციელებს country ველის განახლებას users ცხრილის ყველა ჩანაწერებში: 1 UPDATE 2 `users`
- 78. მაგალითები (2-2) შემდეგი მაგალითი გაზრდის ყველა users ცხრილში დაფიქსირებული ყველა მომხმარებლის ასაკს ერთი წლით: 1 UPDATE
- 79. SELECT ჩანაწერების მოძებნა ხორციელდება ბრძანებით SELECT ბრძანების სინტაქსი SELECT * FROM table_name WHERE (გამოსახულება) [order by
- 80. SELECT-სრული სინტაქსი SELECT [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] [HIGH_PRIORITY] [DISTINCT | DISTINCTROW |
- 81. ANSI SQL ყველა პარამეტრები, რომლებიც იწყებიან SQL_, STRAIGHT_JOIN და HIGH_PRIORITY-ით, წარმოადგენენ MySQL-ის გაფართოებას ANSI SQL -ისათვის.
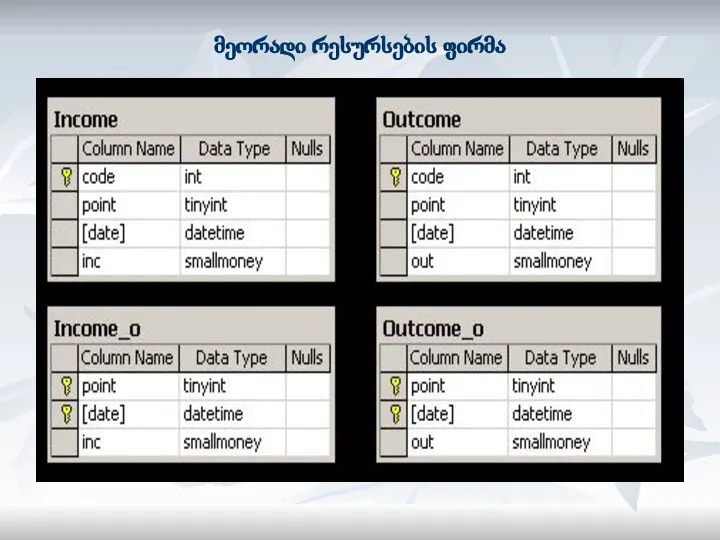
- 82. კომპიუტერული ფირმა
- 83. მეორადი რესურსების ფირმა
- 85. Скачать презентацию

Слайд 3განსაზღვრებები
მონაცემთა ბაზები (მბ) –რაიმე საგნობრივი სფეროს შესახებ მონაცემების საცავი, რომელიც ორგანიზებულია სპეციალური
განსაზღვრებები
მონაცემთა ბაზები (მბ) –რაიმე საგნობრივი სფეროს შესახებ მონაცემების საცავი, რომელიც ორგანიზებულია სპეციალური

Слайд 4საინფორმაციო სისტემების ტიპები
ლოკალური საინფორმაციო სისტემები მბ და მბმს განთავსებულია ერთსა და იმავე
საინფორმაციო სისტემების ტიპები
ლოკალური საინფორმაციო სისტემები მბ და მბმს განთავსებულია ერთსა და იმავე

Слайд 5ლოკალური საინფორაციო სისტემა (ლსს)
ავტონომიურობა (დამოუკიდებლობა)
1) მბ-სთან მუშაობს მხოლოდ ერთი ადამიანი
2) მომხმარებლების დიდი
ლოკალური საინფორაციო სისტემა (ლსს)
ავტონომიურობა (დამოუკიდებლობა)
1) მბ-სთან მუშაობს მხოლოდ ერთი ადამიანი
2) მომხმარებლების დიდი

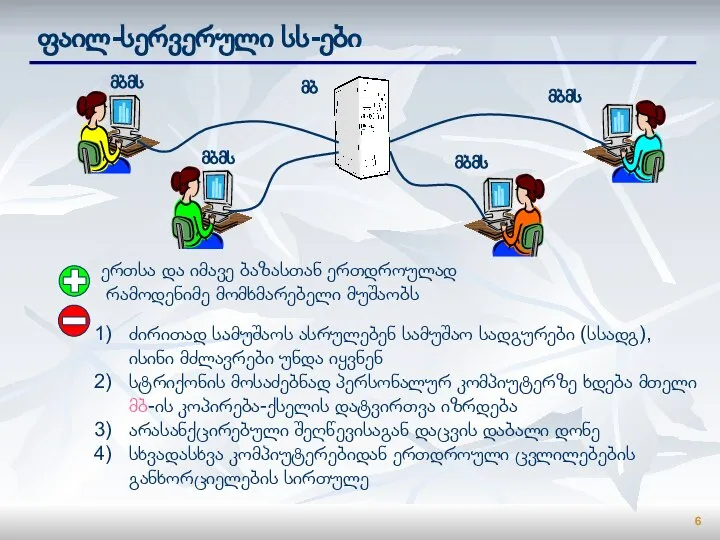
Слайд 6ფაილ-სერვერული სს-ები
ერთსა და იმავე ბაზასთან ერთდროულად
რამოდენიმე მომხმარებელი მუშაობს
ძირითად სამუშაოს ასრულებენ სამუშაო
ფაილ-სერვერული სს-ები
ერთსა და იმავე ბაზასთან ერთდროულად
რამოდენიმე მომხმარებელი მუშაობს
ძირითად სამუშაოს ასრულებენ სამუშაო
Слайд 7კლიენტ-სერვერული სს
მბმს-კლიენტი
მბმს-კლიენტი
მბმს-კლიენტი
ძირითად სამუშაოს ასრულეს სერვერი. სამუშაო სადგურები დაბალი სიმძლავრის შეიძლება იყვნენ
მარტივია მოდერნიზაცია
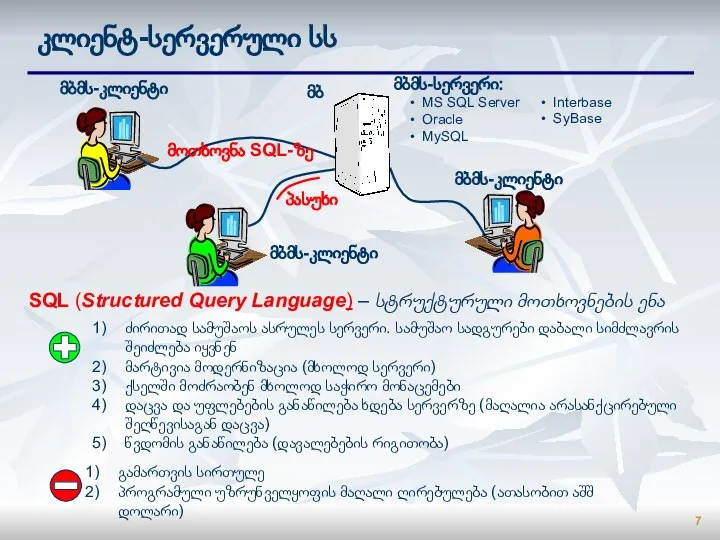
კლიენტ-სერვერული სს
მბმს-კლიენტი
მბმს-კლიენტი
მბმს-კლიენტი
ძირითად სამუშაოს ასრულეს სერვერი. სამუშაო სადგურები დაბალი სიმძლავრის შეიძლება იყვნენ
მარტივია მოდერნიზაცია
Слайд 8მონაცემთა ბაზები. საინფორმაციო სისტემები
თემა 2. მონაცემთა ბაზები
მონაცემთა ბაზები. საინფორმაციო სისტემები
თემა 2. მონაცემთა ბაზები

Слайд 9მონაცემთა ბაზების ტიპები
ცხრილური მონაცემთა ბაზები მონაცემები ერთი ცხრილის სახით
ქსელური მონაცემთა ბაზები
კვანძების
მონაცემთა ბაზების ტიპები
ცხრილური მონაცემთა ბაზები მონაცემები ერთი ცხრილის სახით
ქსელური მონაცემთა ბაზები
კვანძების

Слайд 10ცხრილური მონაცემთა ბაზები
მოდელი – კართოთეკა
მაგალითები:
უბის წიგნაკი
საბიბლიოთეკო კატალოგი
მარტივი სტრუქტურა
მბ-ის ყველა დანარჩენი ტიპები იყენებენ
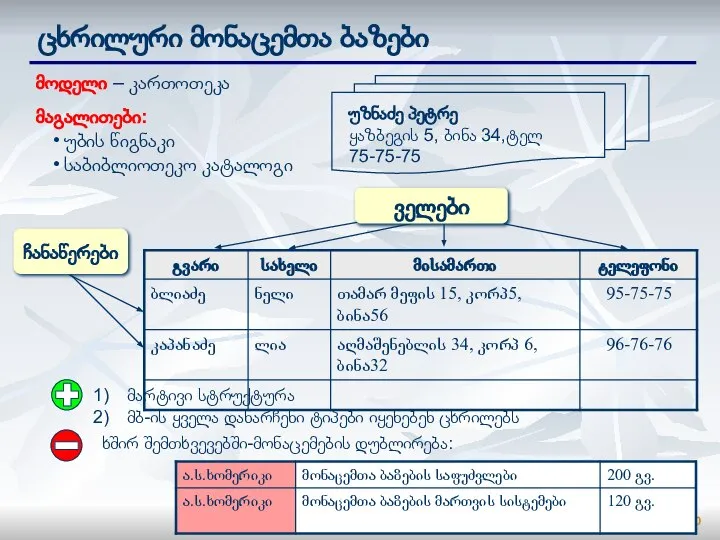
ცხრილური მონაცემთა ბაზები
მოდელი – კართოთეკა
მაგალითები:
უბის წიგნაკი
საბიბლიოთეკო კატალოგი
მარტივი სტრუქტურა
მბ-ის ყველა დანარჩენი ტიპები იყენებენ
Слайд 11ცხრილური მონაცემთა ბაზები
ველების რაოდენობა განისაზღვრება დამპროექტებლის მიერ და მომხმარებელს არ შეუძლია მათი
ცხრილური მონაცემთა ბაზები
ველების რაოდენობა განისაზღვრება დამპროექტებლის მიერ და მომხმარებელს არ შეუძლია მათი

Слайд 12გასაღები ველი (ცხრილის გასაღები)
გასაღები ველი (გასაღები) – ეს არის ველი (ან ველების
გასაღები ველი (ცხრილის გასაღები)
გასაღები ველი (გასაღები) – ეს არის ველი (ან ველების

Слайд 13ქსელური მონაცემთა ბაზა
ქსელური მბ - ეს არის კვანძების ერთობლივობა, რომელშიც ყოველი შეიძლება
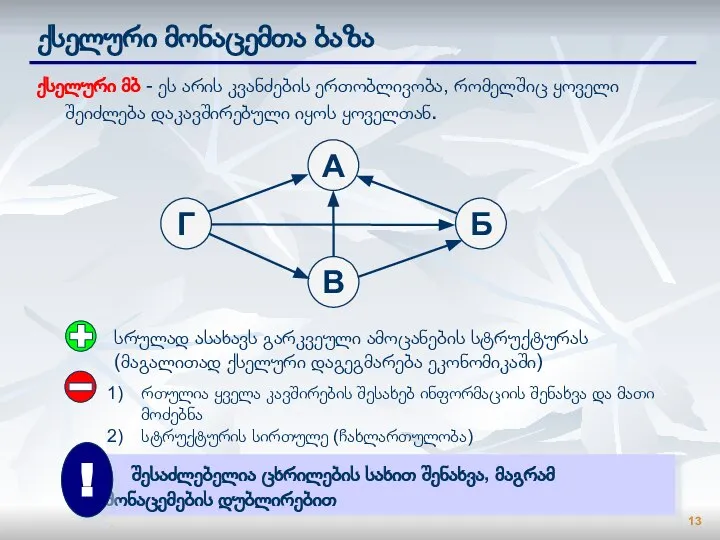
ქსელური მონაცემთა ბაზა
ქსელური მბ - ეს არის კვანძების ერთობლივობა, რომელშიც ყოველი შეიძლება
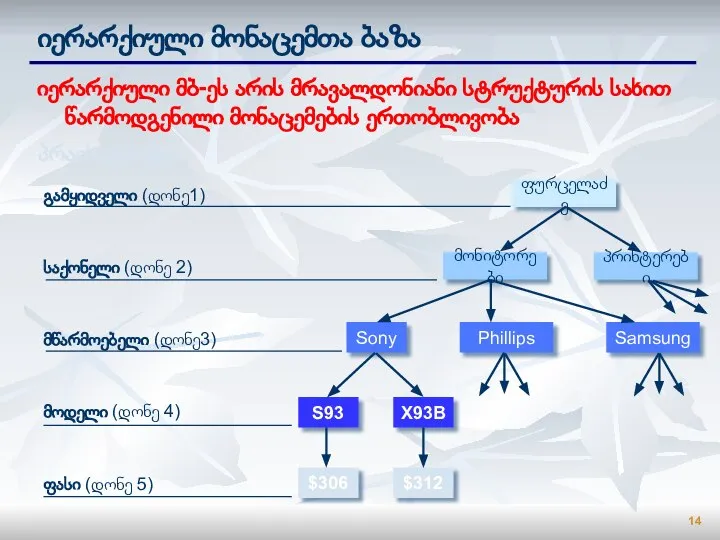
Слайд 14იერარქიული მონაცემთა ბაზა
იერარქიული მბ-ეს არის მრავალდონიანი სტრუქტურის სახით წარმოდგენილი მონაცემების ერთობლივობა
პრაის-ლისტი:
გამყიდველი (დონე1)
საქონელი
იერარქიული მონაცემთა ბაზა
იერარქიული მბ-ეს არის მრავალდონიანი სტრუქტურის სახით წარმოდგენილი მონაცემების ერთობლივობა
პრაის-ლისტი:
გამყიდველი (დონე1)
საქონელი
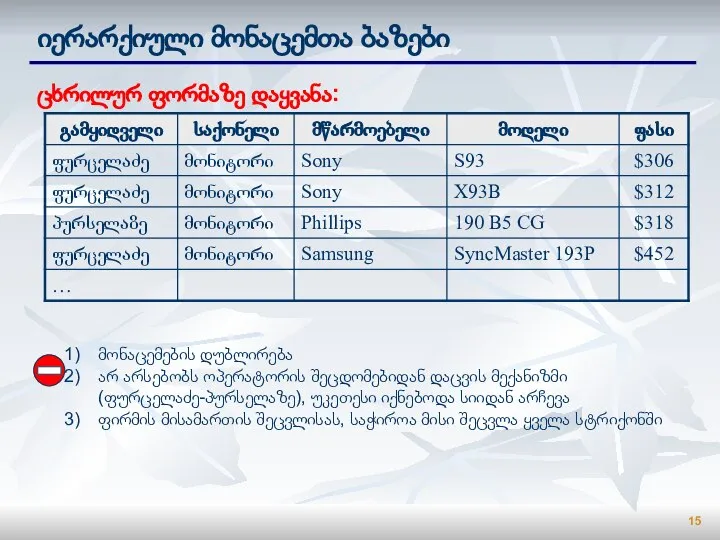
Слайд 15იერარქიული მონაცემთა ბაზები
ცხრილურ ფორმაზე დაყვანა:
მონაცემების დუბლირება
არ არსებობს ოპერატორის შეცდომებიდან დაცვის მექანიზმი (ფურცელაძე-პურსელაზე),
იერარქიული მონაცემთა ბაზები
ცხრილურ ფორმაზე დაყვანა:
მონაცემების დუბლირება
არ არსებობს ოპერატორის შეცდომებიდან დაცვის მექანიზმი (ფურცელაძე-პურსელაზე),
Слайд 16მონაცემთა ბაზები. საინფორმაციო სისტემები
თემა 3. მონაცემთა რელაციური ბაზები
მონაცემთა ბაზები. საინფორმაციო სისტემები
თემა 3. მონაცემთა რელაციური ბაზები

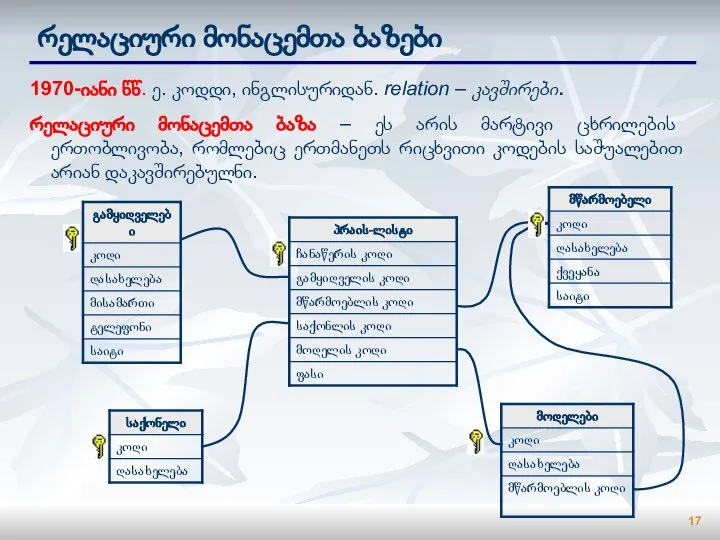
Слайд 17რელაციური მონაცემთა ბაზები
1970-იანი წწ. ე. კოდდი, ინგლისურიდან. relation – კავშირები.
რელაციური მონაცემთა ბაზა
რელაციური მონაცემთა ბაზები
1970-იანი წწ. ე. კოდდი, ინგლისურიდან. relation – კავშირები.
რელაციური მონაცემთა ბაზა
Слайд 18რელაციური მონაცემთა ბაზები
არ ხდება ინფორმაციის დუბლირება;
ფირმის მისამართის შეცვლისას, საკმარისია მისი შეცვლა
რელაციური მონაცემთა ბაზები
არ ხდება ინფორმაციის დუბლირება;
ფირმის მისამართის შეცვლისას, საკმარისია მისი შეცვლა

Слайд 19კავშირები ცხრილებს შორის
ერთი-ერთთან («1-1») –ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება ზუსტად ერთი ჩანაწერი
კავშირები ცხრილებს შორის
ერთი-ერთთან («1-1») –ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება ზუსტად ერთი ჩანაწერი
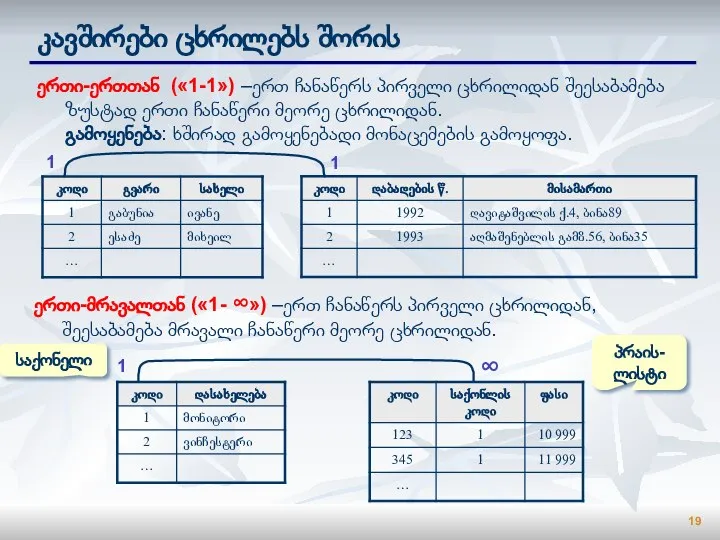
Слайд 20ცხრილებს შორის კავშირები
მრავალი-მრავალთან («∞ - ∞») – ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება
ცხრილებს შორის კავშირები
მრავალი-მრავალთან («∞ - ∞») – ერთ ჩანაწერს პირველი ცხრილიდან შეესაბამება
Слайд 21მონაცემთა ბაზების ნორმალიზაცია
ნორმალიზაცია – ეს ისეთი მონაცემტა ბაზების სტრუქტურის შემუსავებას ნიშნავს, რომელშიც
მონაცემთა ბაზების ნორმალიზაცია
ნორმალიზაცია – ეს ისეთი მონაცემტა ბაზების სტრუქტურის შემუსავებას ნიშნავს, რომელშიც
Слайд 22მონაცემთა ბაზების ნორმალიზაცია
ძირითადი პრინციპები:
ნებისმიერი ველი დამოკიდებული უნდა იყოს მხოლოდ გასაღებზე (გასაღები-ეს არის
მონაცემთა ბაზების ნორმალიზაცია
ძირითადი პრინციპები:
ნებისმიერი ველი დამოკიდებული უნდა იყოს მხოლოდ გასაღებზე (გასაღები-ეს არის
Слайд 23ძებნა მონაცემთა ბაზებში
ხაზოვანი ძებნა –ეს არის ყველა ჩანაწერის გადარჩევა, მანამ სანამ არი
ძებნა მონაცემთა ბაზებში
ხაზოვანი ძებნა –ეს არის ყველა ჩანაწერის გადარჩევა, მანამ სანამ არი
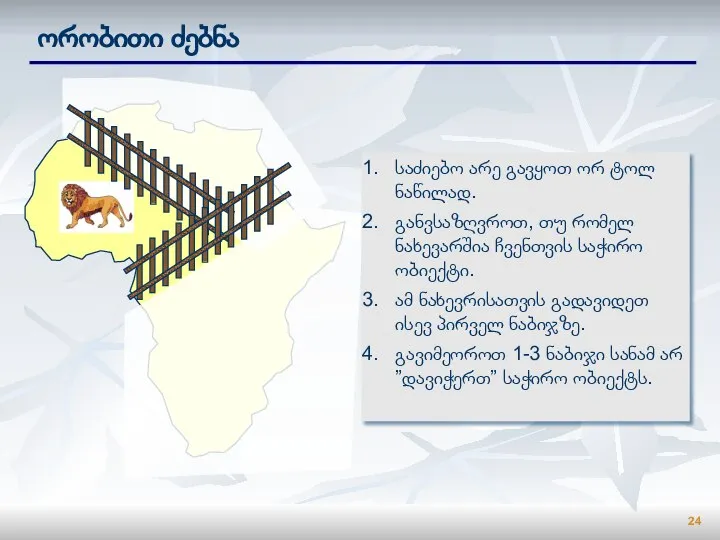
Слайд 24ორობითი ძებნა
საძიებო არე გავყოთ ორ ტოლ ნაწილად.
განვსაზღვროთ, თუ რომელ ნახევარშია ჩვენთვის საჭირო
ორობითი ძებნა
საძიებო არე გავყოთ ორ ტოლ ნაწილად.
განვსაზღვროთ, თუ რომელ ნახევარშია ჩვენთვის საჭირო
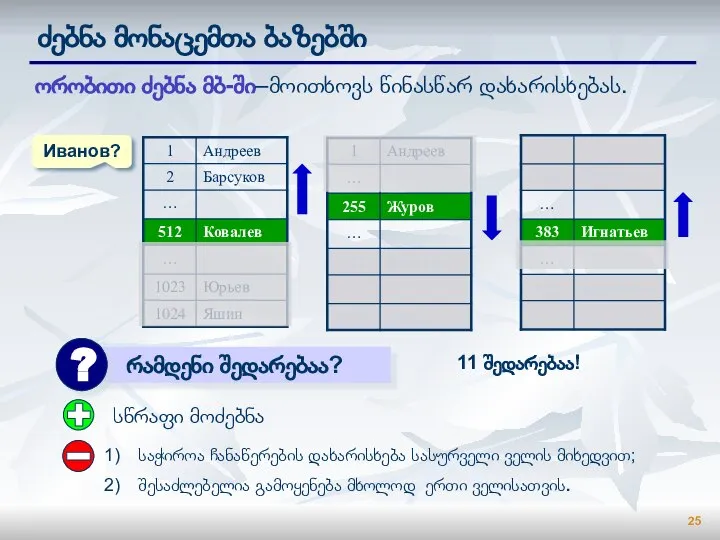
Слайд 25ძებნა მონაცემთა ბაზებში
ორობითი ძებნა მბ-ში–მოითხოვს წინასწარ დახარისხებას.
Иванов?
საჭიროა ჩანაწერების დახარისხება სასურველი ველის მიხედვით;
შესაძლებელია
ძებნა მონაცემთა ბაზებში
ორობითი ძებნა მბ-ში–მოითხოვს წინასწარ დახარისხებას.
Иванов?
საჭიროა ჩანაწერების დახარისხება სასურველი ველის მიხედვით;
შესაძლებელია
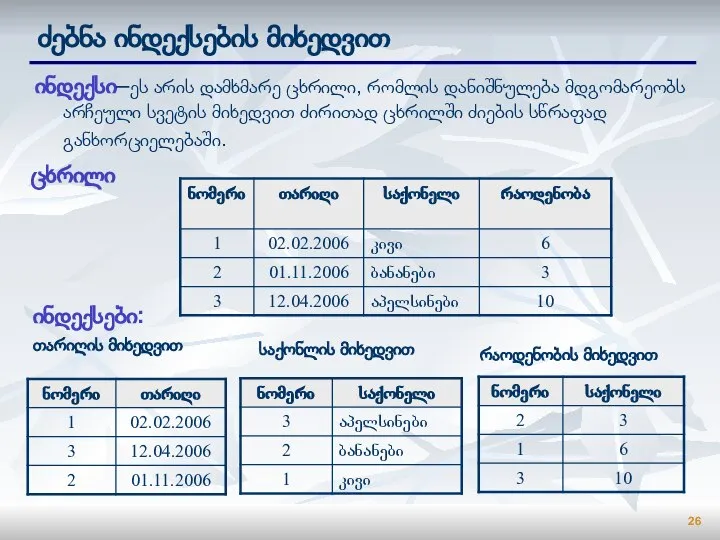
Слайд 26ძებნა ინდექსების მიხედვით
ინდექსი–ეს არის დამხმარე ცხრილი, რომლის დანიშნულება მდგომარეობს არჩეული სვეტის მიხედვით
ძებნა ინდექსების მიხედვით
ინდექსი–ეს არის დამხმარე ცხრილი, რომლის დანიშნულება მდგომარეობს არჩეული სვეტის მიხედვით
Слайд 27ძებნა ინდექსების მიხედვით
ძებნის ალგორითმი:
ორობითი ძებნა ინდექსის მიხედვით–საჭირო ჩანწერების ნომრების მოძებნა;
ძირითადი ცხრილიდან აღნიშნული
ძებნა ინდექსების მიხედვით
ძებნის ალგორითმი:
ორობითი ძებნა ინდექსის მიხედვით–საჭირო ჩანწერების ნომრების მოძებნა;
ძირითადი ცხრილიდან აღნიშნული

Слайд 28Access (Microsoft Office)-ის მონაცემტა ბაზები
გაფართოება: *.mdb, ერთი ფაილი
შემადგენლობა:
ცხრილები;
ფორმები –დიალოგური ფანჯრები მონაცემების შეტანისა
Access (Microsoft Office)-ის მონაცემტა ბაზები
გაფართოება: *.mdb, ერთი ფაილი
შემადგენლობა:
ცხრილები;
ფორმები –დიალოგური ფანჯრები მონაცემების შეტანისა

Слайд 29 MySQL-ის ბრძანებები და ოპერატორები
MySQL-ში გამოყენებული მონაცემთა ტიპები
MySQL-ის მონაცემთა ბაზის შექმნა
MySQL-ის ბრძანებები და ოპერატორები
MySQL-ში გამოყენებული მონაცემთა ტიპები
MySQL-ის მონაცემთა ბაზის შექმნა

Слайд 30
MySQL-ში გამოყენებული მონაცემთა ტიპები
1 მთელი რცხვები
2 წილადი რიცხვები
3 სტრიქონები
4
MySQL-ში გამოყენებული მონაცემთა ტიპები
1 მთელი რცხვები
2 წილადი რიცხვები
3 სტრიქონები
4

Слайд 31მთელი რიცხვები
მონაცემების ტიპების განსაზღვრის ზოგადი სახე:
პრეფიქსი INT [UNSIGNED]
არა აუცილებელი ალამი
მთელი რიცხვები
მონაცემების ტიპების განსაზღვრის ზოგადი სახე:
პრეფიქსი INT [UNSIGNED]
არა აუცილებელი ალამი
![მთელი რიცხვები მონაცემების ტიპების განსაზღვრის ზოგადი სახე: პრეფიქსი INT [UNSIGNED] არა აუცილებელი](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-30.jpg)
Слайд 32წილადი რიცხვები
მათი ზოგადი სახე ასეთია:
ტიპის სახელი[(length, decimals)] [UNSIGNED]
აქ:
length - ციფრებისათვის
წილადი რიცხვები
მათი ზოგადი სახე ასეთია:
ტიპის სახელი[(length, decimals)] [UNSIGNED]
აქ:
length - ციფრებისათვის
![წილადი რიცხვები მათი ზოგადი სახე ასეთია: ტიპის სახელი[(length, decimals)] [UNSIGNED] აქ: length](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-31.jpg)
Слайд 33
სტრიქონები
სტრიქონები წარმოადგენენ სიმბოლოების მასივებს.
როგორც წესი ტექსტურ ველებში ძიებისას SELECT-ის გამოყენებით არ
სტრიქონები
სტრიქონები წარმოადგენენ სიმბოლოების მასივებს.
როგორც წესი ტექსტურ ველებში ძიებისას SELECT-ის გამოყენებით არ

Слайд 34
ბინარული მონაცემები
ბინარული მონაცემები - ეს თითქმის იგივეა, რაც მონაცემები TEXT ფორმატი, მაგრამ
ბინარული მონაცემები
ბინარული მონაცემები - ეს თითქმის იგივეა, რაც მონაცემები TEXT ფორმატი, მაგრამ

Слайд 35
თტარიღი და დრო
MySQL-ის მიერ მხარდაჭერილია ველების რამოდენიმე ტიპი, რომლებიც გათვალისწინებული არიან თარიღებისა
თტარიღი და დრო
MySQL-ის მიერ მხარდაჭერილია ველების რამოდენიმე ტიპი, რომლებიც გათვალისწინებული არიან თარიღებისა

Слайд 36
CREATE DATABASE
ოპერატორის სინტაქსი
CREATE DATABASE [IF NOT EXISTS] db_name [CHARACTER SET charset]
CREATE DATABASE
ოპერატორის სინტაქსი
CREATE DATABASE [IF NOT EXISTS] db_name [CHARACTER SET charset]
![CREATE DATABASE ოპერატორის სინტაქსი CREATE DATABASE [IF NOT EXISTS] db_name [CHARACTER SET](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-35.jpg)
Слайд 37
DROP DATABAS
ოპერატორის სინტაქსი
DROP DATABASE [IF EXISTS] db_name
db_name - განსაზღვრავს იმ მონაცემთა ბაზის
DROP DATABAS
ოპერატორის სინტაქსი
DROP DATABASE [IF EXISTS] db_name
db_name - განსაზღვრავს იმ მონაცემთა ბაზის
![DROP DATABAS ოპერატორის სინტაქსი DROP DATABASE [IF EXISTS] db_name db_name - განსაზღვრავს](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-36.jpg)
Слайд 38
CREATE TABLE
ოპერატორის სინტაქსი:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)] [table_options]
CREATE TABLE
ოპერატორის სინტაქსი:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)] [table_options]
![CREATE TABLE ოპერატორის სინტაქსი: CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-37.jpg)
Слайд 39create_definition (3-1)
create_definition -განსაზღვრავს შესაქმნელი ცხრილის შიდა სტრუქტურას (ველების დასახელებები და ტიპები,
create_definition (3-1)
create_definition -განსაზღვრავს შესაქმნელი ცხრილის შიდა სტრუქტურას (ველების დასახელებები და ტიპები,

Слайд 40create_definition (3-2)
col_name - განსაზღვრავს სვეტის სახელს შესაქმნელ ცხრილში.
Type - col_name სვეტისათვის
create_definition (3-2)
col_name - განსაზღვრავს სვეტის სახელს შესაქმნელ ცხრილში.
Type - col_name სვეტისათვის

Слайд 41create_definition (3-3)
[NOT NULL | NULL] - მიუთითებს იმაზე, შეიძლება, რომ მოცემული სვეტი
create_definition (3-3)
[NOT NULL | NULL] - მიუთითებს იმაზე, შეიძლება, რომ მოცემული სვეტი
![create_definition (3-3) [NOT NULL | NULL] - მიუთითებს იმაზე, შეიძლება, რომ მოცემული](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-40.jpg)
Слайд 42ცხრილის შექმნის მაგალითები
შემდეგი მაგალითი ქმნის 3 ველიან ცხრილს-users, სადაც პირველი ველი -
ცხრილის შექმნის მაგალითები
შემდეგი მაგალითი ქმნის 3 ველიან ცხრილს-users, სადაც პირველი ველი -

Слайд 43AUTO_INCREMENT
შედგენილი გასაღების მეორადი სვეტისათვის
MyISAM და BDB ცხრილებში, შედგენილი გასაღების მეორადი
AUTO_INCREMENT
შედგენილი გასაღების მეორადი სვეტისათვის
MyISAM და BDB ცხრილებში, შედგენილი გასაღების მეორადი

Слайд 44ცხრილის შექმნის მაგალითი
AUTO_INCREMENT
1 CREATE TABLE
2 `users` (
3 `category` ENUM(‘სახლი', ‘სამსახური', ‘სასწავლებელი') NOT NULL,
4 `id`
ცხრილის შექმნის მაგალითი
AUTO_INCREMENT
1 CREATE TABLE
2 `users` (
3 `category` ENUM(‘სახლი', ‘სამსახური', ‘სასწავლებელი') NOT NULL,
4 `id`

Слайд 45ახალი ჩანაწერების ჩასმა
შექმნილ ცხრილში ჩავსვათ ახალი ჩანაწერები
01 INSERT INTO
02 `users` (`category`, `name`, `age`)
03
ახალი ჩანაწერების ჩასმა
შექმნილ ცხრილში ჩავსვათ ახალი ჩანაწერები
01 INSERT INTO
02 `users` (`category`, `name`, `age`)
03

Слайд 46ჩანაწერების დათვალიერება
დავათვალიეროთ users ცხრილის ყველა ჩანაწერი,
category და id ველების მიხედვით
ჩანაწერების დათვალიერება
დავათვალიეროთ users ცხრილის ყველა ჩანაწერი, category და id ველების მიხედვით

Слайд 47მიღებული შედეგი
შედეგად მივიღებთ:
+----------+----+-------+---------------------+
| category | id | name |age |
+----------+----+-------+---------------------+
მიღებული შედეგი
შედეგად მივიღებთ:
+----------+----+-------+---------------------+
| category | id | name |age |
+----------+----+-------+---------------------+

Слайд 48პირველადი გასაღები
[PRIMARY KEY]-განსაზღვრავს ცხრილის პირველად გასაღებს.
ცხრილში მხოლოდ ერთი გასაღები ველის განსაზღვრაა
პირველადი გასაღები
[PRIMARY KEY]-განსაზღვრავს ცხრილის პირველად გასაღებს.
ცხრილში მხოლოდ ერთი გასაღები ველის განსაზღვრაა
![პირველადი გასაღები [PRIMARY KEY]-განსაზღვრავს ცხრილის პირველად გასაღებს. ცხრილში მხოლოდ ერთი გასაღები ველის](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-47.jpg)
Слайд 49ინდექსები
ინდექსების სარგებლიანობის თვალსაჩინო მაგალითია წიგნი.
წიგნში ინდექსის როლს ასრულებ სარჩევი.
სარჩევის მიხედვით
ინდექსები
ინდექსების სარგებლიანობის თვალსაჩინო მაგალითია წიგნი.
წიგნში ინდექსის როლს ასრულებ სარჩევი.
სარჩევის მიხედვით

Слайд 50ცხრილის ინდექსირების მაგალითი
შემდეგ მაგალითში შევქმნათ ცხრილი users , name და age ველებით
ცხრილის ინდექსირების მაგალითი
შემდეგ მაგალითში შევქმნათ ცხრილი users , name და age ველებით

Слайд 51გასაღები ველი
UNIQUE
UNIQUE - ეს გასაღები მიუთითებს იმაზე, რომ მოცემულ სვეტს
გასაღები ველი
UNIQUE
UNIQUE - ეს გასაღები მიუთითებს იმაზე, რომ მოცემულ სვეტს

Слайд 52სრულტექსტოვანი ძიება
FULLTEXT-განსაზღვრავს ველებს, რომელთა მიმართაც შემდგომში შესაძლებელია გამოყენებული იქნას სრულტექსტოვანი ძიება.
სრულტექსტოვანი
სრულტექსტოვანი ძიება
FULLTEXT-განსაზღვრავს ველებს, რომელთა მიმართაც შემდგომში შესაძლებელია გამოყენებული იქნას სრულტექსტოვანი ძიება.
სრულტექსტოვანი

Слайд 53ცხრილების შესაძლო ტიპები MySQL-ში
BDB - გვერდების ტრანზაქციისა და ბლოკირებების მხარდამჭერი ცხრილები.
ცხრილების შესაძლო ტიპები MySQL-ში
BDB - გვერდების ტრანზაქციისა და ბლოკირებების მხარდამჭერი ცხრილები.

Слайд 54ველების პარამეტრები
AUTO_INCREMENT- მოცემული ცხრილისათვის აყენებს შემდეგ მნიშვნელობას AUTO_INCREMENT.
AVG_ROW_LENGTH -განსაზღვრავს მოცემული ცხრილისთვის
ველების პარამეტრები
AUTO_INCREMENT- მოცემული ცხრილისათვის აყენებს შემდეგ მნიშვნელობას AUTO_INCREMENT.
AVG_ROW_LENGTH -განსაზღვრავს მოცემული ცხრილისთვის

Слайд 55RAID_TYPE, UNION, INSERT_METHOD
RAID_TYPE - RAID_TYPE ოპციის გამოყენებით, შესაძლებელია MyISAM მონაცემთა ფაილის დაშლა
RAID_TYPE, UNION, INSERT_METHOD
RAID_TYPE - RAID_TYPE ოპციის გამოყენებით, შესაძლებელია MyISAM მონაცემთა ფაილის დაშლა

Слайд 56DATA DIRECTORY, INDEX DIRECTORY
DATA DIRECTORY=“კატალოგი" და INDEX DIRECTORY=“კატალოგი“ ოფციების გამოყენებით ცხრილების
DATA DIRECTORY, INDEX DIRECTORY
DATA DIRECTORY=“კატალოგი" და INDEX DIRECTORY=“კატალოგი“ ოფციების გამოყენებით ცხრილების

Слайд 57
მაგალითი
ვთქვათ მოცემულია ცხრილი ქალაქების სახელწოდებებით:
1 CREATE TABLE
2 `city`(
3 `name` CHAR(200) NOT
მაგალითი
ვთქვათ მოცემულია ცხრილი ქალაქების სახელწოდებებით:
1 CREATE TABLE
2 `city`(
3 `name` CHAR(200) NOT

Слайд 58მაგალითი (გაგრძელება)
01 CREATE TABLE
02 `users`(
03 `id` INT(11) NOT NULL AUTO_INCREMENT,
04 `name` CHAR(200) NOT NULL,
05 PRIMARY KEY(`id`)
06 )
07
მაგალითი (გაგრძელება)
01 CREATE TABLE
02 `users`(
03 `id` INT(11) NOT NULL AUTO_INCREMENT,
04 `name` CHAR(200) NOT NULL,
05 PRIMARY KEY(`id`)
06 )
07

Слайд 59კიდევ ერთი მაგალითი
1 CREATE TABLE
2 `city_new`
3 SELECT
4 `id`,
5 `city_name` AS `name`
6 FROM7 `users`
1 SELECT
2 *
3 FROM
4 `city_new`
+----+--------------+
|
კიდევ ერთი მაგალითი
1 CREATE TABLE
2 `city_new`
3 SELECT
4 `id`,
5 `city_name` AS `name`
6 FROM7 `users`
1 SELECT
2 *
3 FROM
4 `city_new`
+----+--------------+
|

Слайд 60 DROP TABLE
ოპერატორის სინტაქსი
DROP TABLE [IF EXISTS] tbl_name [, tbl_name,...] [RESTRICT |
DROP TABLE
ოპერატორის სინტაქსი
DROP TABLE [IF EXISTS] tbl_name [, tbl_name,...] [RESTRICT |
![DROP TABLE ოპერატორის სინტაქსი DROP TABLE [IF EXISTS] tbl_name [, tbl_name,...] [RESTRICT](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-59.jpg)
Слайд 61ცხრილის თვისებების შეცვლა
ALTER TABLE
ბრძანების სინტაქსი
ALTER [IGNORE] TABLE tbl_name alter_specification
ცხრილის თვისებების შეცვლა
ALTER TABLE
ბრძანების სინტაქსი
ALTER [IGNORE] TABLE tbl_name alter_specification
![ცხრილის თვისებების შეცვლა ALTER TABLE ბრძანების სინტაქსი ALTER [IGNORE] TABLE tbl_name alter_specification](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-60.jpg)
Слайд 62alter_specification
შესაძლო სინტაქსები:
ADD [COLUMN] create_definition [FIRST | AFTER column_name ]
ADD
alter_specification
შესაძლო სინტაქსები:
ADD [COLUMN] create_definition [FIRST | AFTER column_name ]
ADD
![alter_specification შესაძლო სინტაქსები: ADD [COLUMN] create_definition [FIRST | AFTER column_name ] ADD](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-61.jpg)
Слайд 63ახალი ველის დამატება
ADD [COLUMN] create_definition [FIRST | AFTER column_name ]
გამოიყენება
ახალი ველის დამატება
ADD [COLUMN] create_definition [FIRST | AFTER column_name ]
გამოიყენება
![ახალი ველის დამატება ADD [COLUMN] create_definition [FIRST | AFTER column_name ] გამოიყენება](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-62.jpg)
Слайд 64მაგალითი-(3-1)
ვთქვათ მოცემულია ცხრილი users შემდეგი ველებით: name, age
დავამატოთ ახალი ველი country
მაგალითი-(3-1)
ვთქვათ მოცემულია ცხრილი users შემდეგი ველებით: name, age
დავამატოთ ახალი ველი country

Слайд 65მაგალითი (3-2)
დავამატოთ ახალი ველი id სიის დასაწყისში
1 ALTER TABLE
2 `users`
3 ADD
4 `id` INT(11)
მაგალითი (3-2)
დავამატოთ ახალი ველი id სიის დასაწყისში
1 ALTER TABLE
2 `users`
3 ADD
4 `id` INT(11)

Слайд 66მაგალითი (3-3)
დავამატოთ ახალი ველი city, country ველის წინ(ანუ. age ველის შემდეგ):
1
მაგალითი (3-3)
დავამატოთ ახალი ველი city, country ველის წინ(ანუ. age ველის შემდეგ):
1

Слайд 67ველების ჯგუფის დამატება
ADD [COLUMN] (create_definition, create_definition,...) - ამატებს ცხრილში ერთ ველს ან
ველების ჯგუფის დამატება
ADD [COLUMN] (create_definition, create_definition,...) - ამატებს ცხრილში ერთ ველს ან
![ველების ჯგუფის დამატება ADD [COLUMN] (create_definition, create_definition,...) - ამატებს ცხრილში ერთ ველს](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-66.jpg)
Слайд 68მაგალითი (1)
ცხრილში users დავამატოთ ახალი ველები city და country:
1 ALTER TABLE
2 `users`
3 ADD
4 (
5 `city`
მაგალითი (1)
ცხრილში users დავამატოთ ახალი ველები city და country:
1 ALTER TABLE
2 `users`
3 ADD
4 (
5 `city`

Слайд 69ALTER TABLE
ALTER TABLE table_name_old RENAME table_name_new
table_name_old - ცხრილის ძველი სახელი, რომლის
ALTER TABLE
ALTER TABLE table_name_old RENAME table_name_new
table_name_old - ცხრილის ძველი სახელი, რომლის

Слайд 70
INSERT
INSERT ახორციელებს ახალი სტრიქონების ჩასმას ცხრილში
ბრძანების სინტაქსი
INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO]
INSERT
INSERT ახორციელებს ახალი სტრიქონების ჩასმას ცხრილში
ბრძანების სინტაქსი
INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO]

Слайд 71 INSERT
ბრძანების მუშაობის ზოგადი დებულებები
tbl_name - განსაზღვრავს იმ ცხრილის სახელს, რომელშიც
INSERT
ბრძანების მუშაობის ზოგადი დებულებები
tbl_name - განსაზღვრავს იმ ცხრილის სახელს, რომელშიც

Слайд 72ცხრილში ჩანაწერის ჩასმის
მაგალითები
შემდეგი ბრძანება users ცხრილში დაამატებს ახალ ჩანაწერს, name, age, country,
ცხრილში ჩანაწერის ჩასმის
მაგალითები
შემდეგი ბრძანება users ცხრილში დაამატებს ახალ ჩანაწერს, name, age, country,

Слайд 73INSERT ... SET
ამ შემთხვევაში, ბრძანებაში, ცხრილში არსებულ ყოველ ველს, ენიჭება ”ველის სახელი
INSERT ... SET
ამ შემთხვევაში, ბრძანებაში, ცხრილში არსებულ ყოველ ველს, ენიჭება ”ველის სახელი

Слайд 74INSERT ... SELECT
ასეთი სინტაქსი ცხრილში ერთი მოქმედებით, დიდი რაოდენობის ჩაწერების დამატების საშუალებას
INSERT ... SELECT
ასეთი სინტაქსი ცხრილში ერთი მოქმედებით, დიდი რაოდენობის ჩაწერების დამატების საშუალებას

Слайд 75INSERT ... SELECT
სინტაქსია თავისებურება
იმ ცხრილის სახელი, რომელშიც ხდება ჩანაწერის ჩამატება, არ უნდა
INSERT ... SELECT
სინტაქსია თავისებურება
იმ ცხრილის სახელი, რომელშიც ხდება ჩანაწერის ჩამატება, არ უნდა

Слайд 76
Синтаксис команды
UPDATE
ჩანაწერის განახლება ხორციელდება ბრძანებით UPDATE.
ბრძანების სინტაქსი
UPDATE [LOW_PRIORITY] [IGNORE] tbl_name
Синтаксис команды
UPDATE
ჩანაწერის განახლება ხორციელდება ბრძანებით UPDATE.
ბრძანების სინტაქსი
UPDATE [LOW_PRIORITY] [IGNORE] tbl_name
![Синтаксис команды UPDATE ჩანაწერის განახლება ხორციელდება ბრძანებით UPDATE. ბრძანების სინტაქსი UPDATE [LOW_PRIORITY]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-75.jpg)
Слайд 77მაგალითები (2-1)
შემდეგი მაგალითი ახორციელებს country ველის განახლებას users ცხრილის ყველა ჩანაწერებში:
1
მაგალითები (2-1)
შემდეგი მაგალითი ახორციელებს country ველის განახლებას users ცხრილის ყველა ჩანაწერებში:
1

Слайд 78მაგალითები (2-2)
შემდეგი მაგალითი გაზრდის ყველა users ცხრილში დაფიქსირებული ყველა მომხმარებლის ასაკს ერთი
მაგალითები (2-2)
შემდეგი მაგალითი გაზრდის ყველა users ცხრილში დაფიქსირებული ყველა მომხმარებლის ასაკს ერთი

Слайд 79
SELECT
ჩანაწერების მოძებნა ხორციელდება ბრძანებით SELECT
ბრძანების სინტაქსი
SELECT * FROM table_name WHERE (გამოსახულება)
SELECT
ჩანაწერების მოძებნა ხორციელდება ბრძანებით SELECT
ბრძანების სინტაქსი
SELECT * FROM table_name WHERE (გამოსახულება)

Слайд 80SELECT-სრული სინტაქსი
SELECT [STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] [HIGH_PRIORITY]
[DISTINCT
SELECT-სრული სინტაქსი
SELECT [STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] [HIGH_PRIORITY]
[DISTINCT
![SELECT-სრული სინტაქსი SELECT [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] [HIGH_PRIORITY]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1181724/slide-79.jpg)
Слайд 81ANSI SQL
ყველა პარამეტრები, რომლებიც იწყებიან SQL_, STRAIGHT_JOIN და HIGH_PRIORITY-ით, წარმოადგენენ
MySQL-ის გაფართოებას ANSI
ANSI SQL
ყველა პარამეტრები, რომლებიც იწყებიან SQL_, STRAIGHT_JOIN და HIGH_PRIORITY-ით, წარმოადგენენ
MySQL-ის გაფართოებას ANSI

Слайд 82კომპიუტერული ფირმა
კომპიუტერული ფირმა
Слайд 83მეორადი რესურსების ფირმა
მეორადი რესურსების ფირმა
 Нарративные стратегии в журналистике
Нарративные стратегии в журналистике TEO-STROY Система для управления строительной фирмой/студией ремонта
TEO-STROY Система для управления строительной фирмой/студией ремонта Разделение сети на подсети
Разделение сети на подсети Классификация ИТ
Классификация ИТ Типовые разветвляющиеся алгоритмы. Примеры
Типовые разветвляющиеся алгоритмы. Примеры Изучение лексики английского языка с помощью современных образовательных платформ
Изучение лексики английского языка с помощью современных образовательных платформ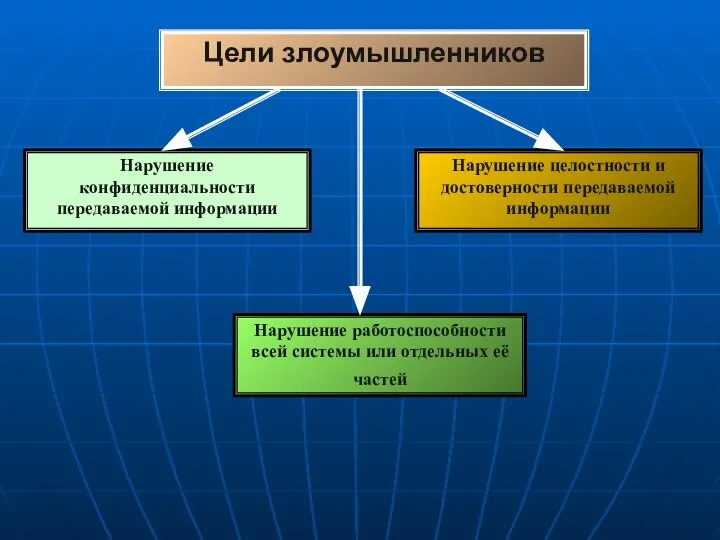 Цели злоумышленников
Цели злоумышленников Безопасный интернет
Безопасный интернет Лайфхаки, упрощающие жизнь 1С-никам
Лайфхаки, упрощающие жизнь 1С-никам Сакирдонов 2ИСиП1
Сакирдонов 2ИСиП1 Юные комики
Юные комики 2._
2._ Программное обеспечение персонально
Программное обеспечение персонально Технология создания моделей учащимися в исследовательских естественно-научных проектах
Технология создания моделей учащимися в исследовательских естественно-научных проектах Как получить информацию журналисту
Как получить информацию журналисту Преобразование вида и состава изображений (графическая работа)
Преобразование вида и состава изображений (графическая работа) Информационный сегмент
Информационный сегмент Безопасность в сети интернет
Безопасность в сети интернет Безопасность в сетях LTE
Безопасность в сетях LTE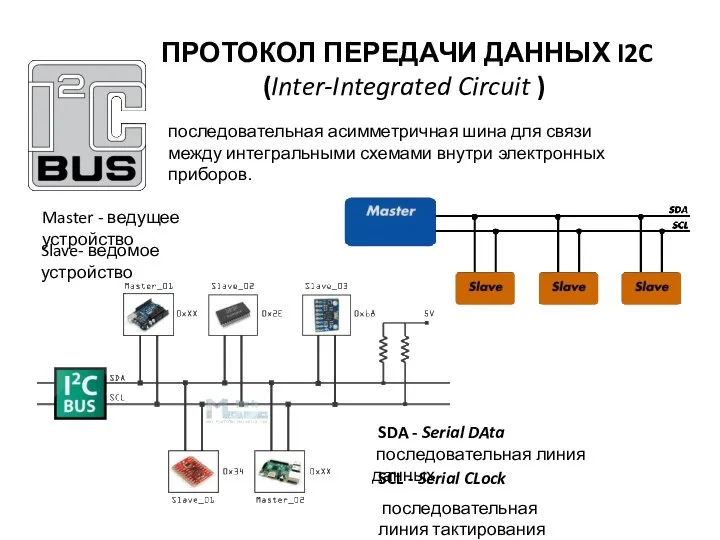 Протокол передачи данных I2C
Протокол передачи данных I2C Двумерные массивы: работа с диагоналями
Двумерные массивы: работа с диагоналями Разрешения на доступ к этой презентации
Разрешения на доступ к этой презентации Введение в информатику
Введение в информатику Тема: Основные понятия алгебры логики. Логические выражения и логические операции
Тема: Основные понятия алгебры логики. Логические выражения и логические операции Департамент по разработке решений в сфере закупок
Департамент по разработке решений в сфере закупок Графический интерфейс устройства. Шрифты и работа с текстом
Графический интерфейс устройства. Шрифты и работа с текстом Организация мероприятия InControl
Организация мероприятия InControl Работа в подсистеме конференция
Работа в подсистеме конференция