- Параллельное программирование. Программирование взаимодействующих процессов

Содержание
- 2. IV. Программирование взаимодействующих процессов Ниже приведены несколько примеров программирования взаимодействия параллельно исполняющихся процессов. Все они определяют
- 3. Асинхронное программирование Асинхронная модель вычислений наиболее пригодна для описания вычислений на мультипроцессоре и/или мультикомпьютере. Асинхронная программа
- 4. Асинхронная программа (А-программа) - это конечное множество А-блоков {Ak |k∈{1,2,...,т}} определенных над информационной IM и управляющей
- 5. Управляющий оператор c(ak) - оператор присваивания или процедура, меняющая значения ячеек управляющей памяти CM (например, чтобы
- 6. Таким образом, исполняющая система в зависимости от имеющихся в наличии свободных на этот момент ресурсов имеет
- 7. Выполнение А-блока Ak состоит в исполнении: процедуры ak с теми значениями, которые имеют переменные из in(ak)
- 8. П1
- 9. Программа примера П1 позволяет в некотором порядке уравнять значения переменных x, y, z, доведя их с
- 10. П2.Большая непроцедурность часто мешает эффективно выполнить программу и в таких случаях требуется уменьшать непроцедурность программы (представления
- 11. П3.Программа нижеследующего примера отличается от программы примера П2 тем, что в спусковые функции добавлены новые конъюнктивные
- 12. П4.В примерах П1 - П3 А-блоки не имели управляющего оператора (более точно, был пустой управляющий оператор).
- 13. Асинхронная программа, реализующая этот конвейер (в программе не показаны переменные, обрабатываемые этой программой, демонстрируется только конструирование
- 14. В этой программе операторы присваивания x:=1; y:=z:=0; значений управляющим переменным разрешают инициировать операцию f1 и запрещают
- 15. Некорректное вычисление данных Возникновение некорректных данных иллюстрирует следующий простой пример. Пусть необходимо начислить зарплату и вычислить
- 16. Пусть процессы P0, P1, P2, ... , Pn, Pn+1 выполняют эти операции. Для вычисления корректного результата
- 17. Следующий пример иллюстрирует этот тип ошибки. Пусть в банке А есть счет acc1, на котором находится
- 18. Первоначально А.acc1=500 тыс.руб. В.acc2=300 тыс.руб. Процесс P1 Процесс P2 А.acc1:=А.acc1 - 100; receive (x,A,y); x :=
- 19. В процессе P1 счет А.acc1 вначале уменьшается на 100 тыс. руб., а затем 100 тыс. руб.
- 20. Широко известным примером реализации модели асинхронного программирования является message passing interface (MPI). Этот метод программирования определяет
- 21. Предполагается, что программа определяется как система независимых, параллельно протекающих взаимодействующих процессов. Как обычно, здесь процесс -
- 22. В программе для использования MPI прежде всего следует описать каналы, например: ch queue ( ) Описание
- 23. Выражение должно вырабатывать значение переменной, описанной в определении канала. Например: send data (d+1, m, y); Переменные
- 24. Если канал предполагается неограниченным (асинхронный MPI), то оператор send может быть выполнен неограниченно много раз (не
- 25. П1.Одно из типичных межпроцессных взаимодействий определяет взаимодействия клиента и производителя. Производитель создает продукт и продает его
- 26. Producer :: var index, ...; do true → receive request (index, ... ); % ожидание запроса
- 27. В программе определены n+1 независимых параллельно протекающих процессов: один процесс-производитель Producer и n процессов-клиентов Client. Именно
- 28. Реализация управления взаимодействующими процессами Сети Петри описывали поведение процессов, но не определяли, как это поведение реализовать
- 29. Семафоры Семафоры являются тем базовым средством, с помощью которого можно реализовать в программе управление параллельно протекающими
- 30. Каждая из операций P и V является неделимой, т.е. если семафорная переменная изменяется одной из операций,
- 31. Понятно, что при доступе к семафору тоже возможна ситуация вечного ожидания - один из процессов постоянно
- 32. Задача взаимного исключения Взаимное исключение может быть реализовано с помощью семафоров следующим образом. Пусть для n
- 33. var mutex=1: semaphore; /* семафорная переменная mutex инициируется со значением 1 */ Proc(i) : repeat .
- 34. Программу процесса составляют операторы языка программирования, заключенные между операторами repeat и until. Логически программа процесса делится
- 35. Завершив выполнение критического интервала, процесс выполнит оператор V(mutex) и увеличит значение семафорной переменной mutex на единицу.
- 36. Задача производитель/потребитель с ограниченным буфером Накопительный буфер имеет два пограничных состояния, ограничивающих активность процессов-потребителей и процессов-производителей:
- 37. Заведем соответственно два семафора для описания этих состояний: b_empty - содержит количество свободных позиций для размещения
- 38. Producer: {repeat ... производится очередной элемент данных ... P(b_empty); /*число работающих процессов- производителей не должно превышать
- 39. Consumer: { repeat P(b_full); /*число работающих процессов-потребителей не должно превышать числа произведенных элементов в буфере*/ P(mutex);
- 40. Задача читатели-писатели Рассмотрим более сложный пример решения задачи программирования взаимодействия множества процессов с использованием семафоров. Пусть
- 41. Далее, процессы-писатели должны иметь преимущество при доступе к разделяемому объекту, поскольку они готовы записать новые данные.
- 42. Эта модельная задача может реально интерпретироваться. Такая схема взаимодействий должна быть реализована, если нужно, к примеру,
- 46. В программе не рассматриваются случаи аварийного завершения. Например, если последний процесс-читатель или последний процесс-писатель завершится аварийно
- 47. Критические интервалы Программируя межпроцессные взаимодействия с использованием семафоров легко допустить разнообразные неочевидные ошибки, в первую очередь
- 48. Только один процесс может исполнять оператор region с переменной x в качестве параметра. Таким образом, пока
- 49. Параллельная программа разделения множеств Определения MPI очевидны и просты. Так же просты и очевидны средства программирования
- 50. И это при том, что программа совершенно тривиальна, в ней попросту не на что смотреть! Это
- 51. На практике следует комбинировать и тестирование и формальное доказательство правильности. Следует также обратить внимание на опасную
- 52. Для параллельного асинхронного решения задачи используется следующий алгоритм. -1.Определяются два параллельно протекающих процесса Small и Large.
- 53. По завершении программы каждый элемент множества S должен оказаться не больше любого элемента множества Т, а
- 54. Программа состоит из двух параллельных процессов, P=[Small||Large].
- 55. Программу можно прокомментировать следующим образом. Определены два процесса Small и Large. Символ || разрешает параллельное исполнение
- 56. Оператор ! задает передачу данных (аналог оператора send), а оператор ? - их прием (аналог оператора
- 57. Обозначим S0 и T0 – начальные множества, а STerm и TTerm – заключительные их значения. При
- 58. Частичная корректность этой программы состоит в том, что если множества S0 и T0 конечны и непусты,
- 59. 4.2.3.Коммуникационно-замкнутые слои параллельной программы Это понятие вводится для упрощения верификации (доказательства правильности) параллельных программ. Основная идея
- 60. Каждая i-я строка изображает процесс Pi как последовательность операторов: Pi=Qi,1;Qi,2;...Qi,k. Параллельная программа Lj=[Q1,j||Q2,j||...||Qn,j] называется j-м слоем
- 61. Слой Lj называется коммуникационно-замкнутым, если при всех вычислениях Р взаимодействие процессов P1|| ...||Pn происходит только внутри
- 62. Если программа Р* безопасна, то вместо верификацию всей параллельной программы Р можно проводить ее послойную верификацию,
- 63. Рис. 4.4.
- 64. Процессы Small и Large разбиваются на коммуникационно-замкнутые слои совершенно естественно. Разбиение приведено на рис. 4.4. На
- 65. 4.2.4.Когерентность параллельных программ Для упрощения верификации параллельной программы уже при ее проектировании на нее можно наложить
- 66. В когерентной программе невозможна ситуация, когда в одном процессе выполняется оператор α! mx, а процесс-партнер не
- 67. Очевидно, что требование когерентности для этой программы выполняется тогда и только тогда, когда условия прекращения циклов
- 68. Рис. 4.5.
- 69. Таким образом, условие BS ≡ BL≡ И, или, что то же, mx ≤ x ≡ mn
- 70. 4.2.5.Анализ программы разделения множеств Для анализа программы используем “истории” взаимодействий. Вводятся вспомогательные переменные, которые хранят истории
- 71. Проведем анализ первого слоя :
- 72. Для того, чтобы процессы QSmall,1 и QLarge,1 завершились, необходимо и достаточно, чтобы множество S содержало хотя
- 73. Рассмотрим теперь второй слой: Перед i-м выполнением каждого цикла для процессов QSmall,2 и QLarge,2 истинны следующие
- 74. Как уже говорилось, требование когерентности в этой программе соответствует требованию общезначимости формулы mxi ≤ xi ≡
- 75. Учитывая, что min(Ti) ≥ min(Ti-1) и max(Si) ≤ max(Si-1), условия некорректного поведения параллельной программы разделения множеств
- 76. Поясним полученный результат. Исследуемая параллельная программа разделения множеств имеет целью собрать все минимальные элементы объединения двух
- 77. Рис. 4.6. Полученные выше условия некорректного поведения программы определены для (i-1)-го и i-го максимальных значений множества
- 78. Иными словами, если между упорядоченными по убыванию элементами множества S и упорядоченными по возрастанию элементами множества
- 80. Скачать презентацию
Слайд 2IV. Программирование взаимодействующих процессов
Ниже приведены несколько примеров программирования взаимодействия параллельно исполняющихся процессов.
IV. Программирование взаимодействующих процессов
Ниже приведены несколько примеров программирования взаимодействия параллельно исполняющихся процессов.

Слайд 3Асинхронное программирование
Асинхронная модель вычислений наиболее пригодна для описания вычислений на мультипроцессоре и/или
Асинхронное программирование
Асинхронная модель вычислений наиболее пригодна для описания вычислений на мультипроцессоре и/или

Слайд 4 Асинхронная программа (А-программа) - это конечное множество А-блоков {Ak |k∈{1,2,...,т}} определенных над
Асинхронная программа (А-программа) - это конечное множество А-блоков {Ak |k∈{1,2,...,т}} определенных над

Слайд 5Управляющий оператор c(ak) - оператор присваивания или процедура, меняющая значения ячеек управляющей
Управляющий оператор c(ak) - оператор присваивания или процедура, меняющая значения ячеек управляющей

Слайд 6Таким образом, исполняющая система в зависимости от имеющихся в наличии свободных на
Таким образом, исполняющая система в зависимости от имеющихся в наличии свободных на

Слайд 7Выполнение А-блока Ak состоит в исполнении:
процедуры ak с теми значениями, которые
Выполнение А-блока Ak состоит в исполнении:
процедуры ak с теми значениями, которые

Слайд 8П1
П1

Слайд 9 Программа примера П1 позволяет в некотором порядке уравнять значения переменных x, y,
Программа примера П1 позволяет в некотором порядке уравнять значения переменных x, y,

Слайд 10П2.Большая непроцедурность часто мешает эффективно выполнить программу и в таких случаях требуется
П2.Большая непроцедурность часто мешает эффективно выполнить программу и в таких случаях требуется

Слайд 11П3.Программа нижеследующего примера отличается от программы примера П2 тем, что в спусковые
П3.Программа нижеследующего примера отличается от программы примера П2 тем, что в спусковые

Слайд 12П4.В примерах П1 - П3 А-блоки не имели управляющего оператора (более точно,
П4.В примерах П1 - П3 А-блоки не имели управляющего оператора (более точно,
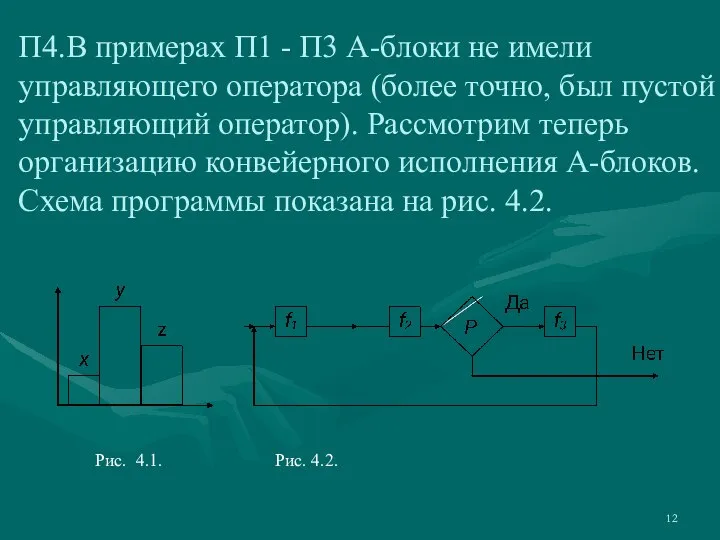
Слайд 13Асинхронная программа, реализующая этот конвейер (в программе не показаны переменные, обрабатываемые этой
Асинхронная программа, реализующая этот конвейер (в программе не показаны переменные, обрабатываемые этой

Слайд 14 В этой программе операторы присваивания x:=1; y:=z:=0; значений управляющим переменным разрешают инициировать
В этой программе операторы присваивания x:=1; y:=z:=0; значений управляющим переменным разрешают инициировать

Слайд 15Некорректное вычисление данных
Возникновение некорректных данных иллюстрирует следующий простой пример. Пусть необходимо начислить
Некорректное вычисление данных
Возникновение некорректных данных иллюстрирует следующий простой пример. Пусть необходимо начислить

Слайд 16Пусть процессы P0, P1, P2, ... , Pn, Pn+1 выполняют эти операции.
Пусть процессы P0, P1, P2, ... , Pn, Pn+1 выполняют эти операции.

Слайд 17 Следующий пример иллюстрирует этот тип ошибки. Пусть в банке А есть счет
Следующий пример иллюстрирует этот тип ошибки. Пусть в банке А есть счет

Слайд 18Первоначально
А.acc1=500 тыс.руб.
В.acc2=300 тыс.руб.
Процесс P1 Процесс P2
А.acc1:=А.acc1 - 100; receive (x,A,y);
x
А.acc1=500 тыс.руб.
В.acc2=300 тыс.руб.
Процесс P1 Процесс P2
А.acc1:=А.acc1 - 100; receive (x,A,y);
x

Слайд 19В процессе P1 счет А.acc1 вначале уменьшается на 100 тыс. руб., а
В процессе P1 счет А.acc1 вначале уменьшается на 100 тыс. руб., а

Слайд 20 Широко известным примером реализации модели асинхронного программирования является message passing interface (MPI).
Широко известным примером реализации модели асинхронного программирования является message passing interface (MPI).

Слайд 21 Предполагается, что программа определяется как система независимых, параллельно протекающих взаимодействующих процессов. Как
Предполагается, что программа определяется как система независимых, параллельно протекающих взаимодействующих процессов. Как

Слайд 22В программе для использования MPI прежде всего следует описать каналы, например:
ch queue
В программе для использования MPI прежде всего следует описать каналы, например:
ch queue

Слайд 23Выражение должно вырабатывать значение переменной, описанной в определении канала. Например:
send data (d+1,
Выражение должно вырабатывать значение переменной, описанной в определении канала. Например:
send data (d+1,

Слайд 24Если канал предполагается неограниченным (асинхронный MPI), то оператор send может быть выполнен
Если канал предполагается неограниченным (асинхронный MPI), то оператор send может быть выполнен

Слайд 25П1.Одно из типичных межпроцессных взаимодействий определяет взаимодействия клиента и производителя. Производитель создает
П1.Одно из типичных межпроцессных взаимодействий определяет взаимодействия клиента и производителя. Производитель создает

Слайд 26Producer :: var index, ...;
do true → receive request (index, ... );
Producer :: var index, ...;
do true → receive request (index, ... );

Слайд 27В программе определены n+1 независимых параллельно протекающих процессов: один процесс-производитель Producer и
В программе определены n+1 независимых параллельно протекающих процессов: один процесс-производитель Producer и

Слайд 28Реализация управления взаимодействующими процессами
Сети Петри описывали поведение процессов, но не определяли, как
Реализация управления взаимодействующими процессами
Сети Петри описывали поведение процессов, но не определяли, как

Слайд 29Семафоры
Семафоры являются тем базовым средством, с помощью которого можно реализовать в программе
Семафоры
Семафоры являются тем базовым средством, с помощью которого можно реализовать в программе

Слайд 30Каждая из операций P и V является неделимой, т.е. если семафорная переменная
Каждая из операций P и V является неделимой, т.е. если семафорная переменная

Слайд 31 Понятно, что при доступе к семафору тоже возможна ситуация вечного ожидания -
Понятно, что при доступе к семафору тоже возможна ситуация вечного ожидания -

Слайд 32Задача взаимного исключения
Взаимное исключение может быть реализовано с помощью семафоров следующим образом.
Пусть
Задача взаимного исключения
Взаимное исключение может быть реализовано с помощью семафоров следующим образом.
Пусть

Слайд 33 var mutex=1: semaphore;
/* семафорная переменная mutex инициируется со значением 1 */
Proc(i)
var mutex=1: semaphore;
/* семафорная переменная mutex инициируется со значением 1 */
Proc(i)

Слайд 34Программу процесса составляют операторы языка программирования, заключенные между операторами repeat и until.
Программу процесса составляют операторы языка программирования, заключенные между операторами repeat и until.

Слайд 35Завершив выполнение критического интервала, процесс выполнит оператор V(mutex) и увеличит значение семафорной
Завершив выполнение критического интервала, процесс выполнит оператор V(mutex) и увеличит значение семафорной

Слайд 36Задача производитель/потребитель с ограниченным буфером
Накопительный буфер имеет два пограничных состояния, ограничивающих активность
Задача производитель/потребитель с ограниченным буфером
Накопительный буфер имеет два пограничных состояния, ограничивающих активность

Слайд 37Заведем соответственно два семафора для описания этих состояний:
b_empty - содержит количество свободных
Заведем соответственно два семафора для описания этих состояний:
b_empty - содержит количество свободных

Слайд 38Producer:
{repeat
...
производится очередной элемент данных
...
P(b_empty); /*число работающих процессов- производителей не должно превышать
Producer:
{repeat
...
производится очередной элемент данных
...
P(b_empty); /*число работающих процессов- производителей не должно превышать

Слайд 39Consumer:
{ repeat
P(b_full); /*число работающих процессов-потребителей не должно превышать числа произведенных элементов в
Consumer:
{ repeat
P(b_full); /*число работающих процессов-потребителей не должно превышать числа произведенных элементов в

Слайд 40Задача читатели-писатели
Рассмотрим более сложный пример решения задачи программирования взаимодействия множества процессов с
Задача читатели-писатели
Рассмотрим более сложный пример решения задачи программирования взаимодействия множества процессов с

Слайд 41 Далее, процессы-писатели должны иметь преимущество при доступе к разделяемому объекту, поскольку
Далее, процессы-писатели должны иметь преимущество при доступе к разделяемому объекту, поскольку

Слайд 42 Эта модельная задача может реально интерпретироваться. Такая схема взаимодействий должна быть реализована,
Эта модельная задача может реально интерпретироваться. Такая схема взаимодействий должна быть реализована,




Слайд 46 В программе не рассматриваются случаи аварийного завершения. Например, если последний процесс-читатель или
В программе не рассматриваются случаи аварийного завершения. Например, если последний процесс-читатель или

Слайд 47Критические интервалы
Программируя межпроцессные взаимодействия с использованием семафоров легко допустить разнообразные неочевидные ошибки,
Критические интервалы
Программируя межпроцессные взаимодействия с использованием семафоров легко допустить разнообразные неочевидные ошибки,

Слайд 48Только один процесс может исполнять оператор region с переменной x в качестве
Только один процесс может исполнять оператор region с переменной x в качестве

Слайд 49Параллельная программа разделения множеств
Определения MPI очевидны и просты. Так же просты и
Параллельная программа разделения множеств
Определения MPI очевидны и просты. Так же просты и

Слайд 50И это при том, что программа совершенно тривиальна, в ней попросту не
И это при том, что программа совершенно тривиальна, в ней попросту не

Слайд 51На практике следует комбинировать и тестирование и формальное доказательство правильности. Следует также
На практике следует комбинировать и тестирование и формальное доказательство правильности. Следует также

Слайд 52Для параллельного асинхронного решения задачи используется следующий алгоритм.
-1.Определяются два параллельно протекающих
Для параллельного асинхронного решения задачи используется следующий алгоритм.
-1.Определяются два параллельно протекающих

Слайд 53По завершении программы каждый элемент множества S должен оказаться не больше любого
По завершении программы каждый элемент множества S должен оказаться не больше любого

Слайд 54 Программа состоит из двух параллельных процессов,
P=[Small||Large].
Программа состоит из двух параллельных процессов,
P=[Small||Large].
![Программа состоит из двух параллельных процессов, P=[Small||Large].](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1126960/slide-53.jpg)
Слайд 55Программу можно прокомментировать следующим образом. Определены два процесса Small и Large. Символ
Программу можно прокомментировать следующим образом. Определены два процесса Small и Large. Символ

Слайд 56Оператор ! задает передачу данных (аналог оператора send), а оператор ? -
Оператор ! задает передачу данных (аналог оператора send), а оператор ? -

Слайд 57Обозначим S0 и T0 – начальные множества, а STerm и TTerm –
Обозначим S0 и T0 – начальные множества, а STerm и TTerm –

Слайд 58Частичная корректность этой программы состоит в том, что если множества S0 и
Частичная корректность этой программы состоит в том, что если множества S0 и

Слайд 594.2.3.Коммуникационно-замкнутые слои параллельной программы
Это понятие вводится для упрощения верификации (доказательства правильности) параллельных
4.2.3.Коммуникационно-замкнутые слои параллельной программы
Это понятие вводится для упрощения верификации (доказательства правильности) параллельных

Слайд 60
Каждая i-я строка изображает процесс Pi как последовательность операторов: Pi=Qi,1;Qi,2;...Qi,k.
Параллельная программа
Каждая i-я строка изображает процесс Pi как последовательность операторов: Pi=Qi,1;Qi,2;...Qi,k.
Параллельная программа

Слайд 61Слой Lj называется коммуникационно-замкнутым, если при всех вычислениях Р взаимодействие процессов P1||
Слой Lj называется коммуникационно-замкнутым, если при всех вычислениях Р взаимодействие процессов P1||

Слайд 62 Если программа Р* безопасна, то вместо верификацию всей параллельной программы Р можно
Если программа Р* безопасна, то вместо верификацию всей параллельной программы Р можно

Слайд 63Рис. 4.4.
Рис. 4.4.
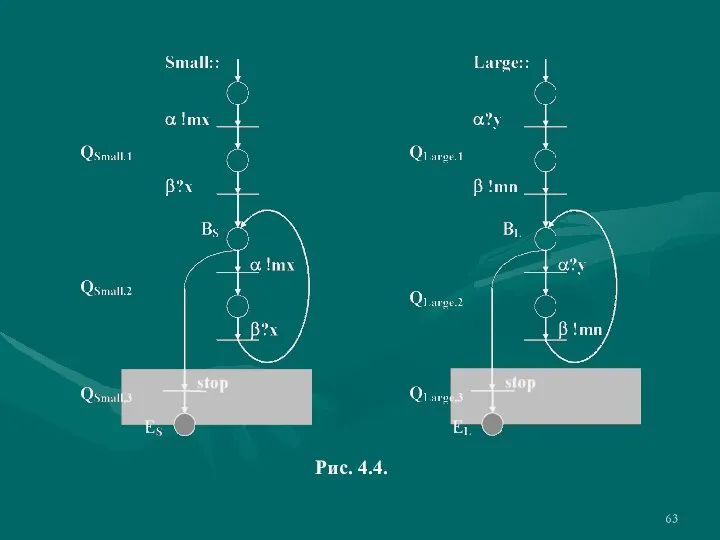
Слайд 64Процессы Small и Large разбиваются на коммуникационно-замкнутые слои совершенно естественно. Разбиение приведено
Процессы Small и Large разбиваются на коммуникационно-замкнутые слои совершенно естественно. Разбиение приведено

Слайд 654.2.4.Когерентность параллельных программ
Для упрощения верификации параллельной программы уже при ее проектировании на
4.2.4.Когерентность параллельных программ
Для упрощения верификации параллельной программы уже при ее проектировании на

Слайд 66В когерентной программе невозможна ситуация, когда в одном процессе выполняется оператор α!
В когерентной программе невозможна ситуация, когда в одном процессе выполняется оператор α!

Слайд 67 Очевидно, что требование когерентности для этой программы выполняется тогда и только тогда,
Очевидно, что требование когерентности для этой программы выполняется тогда и только тогда,

Слайд 68Рис. 4.5.
Рис. 4.5.
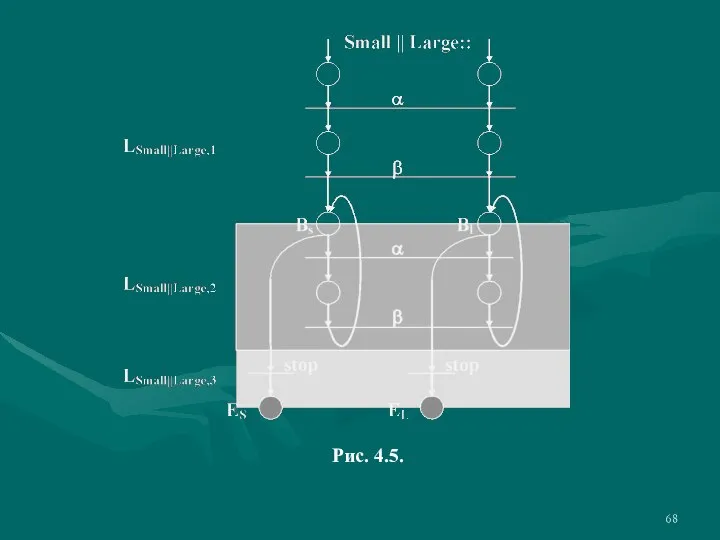
Слайд 69Таким образом, условие BS ≡ BL≡ И, или, что то же, mx
Таким образом, условие BS ≡ BL≡ И, или, что то же, mx

Слайд 704.2.5.Анализ программы разделения множеств
Для анализа программы используем “истории” взаимодействий. Вводятся вспомогательные переменные,
4.2.5.Анализ программы разделения множеств
Для анализа программы используем “истории” взаимодействий. Вводятся вспомогательные переменные,

Слайд 71Проведем анализ первого слоя :
Проведем анализ первого слоя :

Слайд 72Для того, чтобы процессы QSmall,1 и QLarge,1 завершились, необходимо и достаточно, чтобы
Для того, чтобы процессы QSmall,1 и QLarge,1 завершились, необходимо и достаточно, чтобы

Слайд 73Рассмотрим теперь второй слой:
Перед i-м выполнением каждого цикла для процессов QSmall,2 и
Рассмотрим теперь второй слой:
Перед i-м выполнением каждого цикла для процессов QSmall,2 и

Слайд 74Как уже говорилось, требование когерентности в этой программе соответствует требованию общезначимости формулы
Как уже говорилось, требование когерентности в этой программе соответствует требованию общезначимости формулы

Слайд 75Учитывая, что min(Ti) ≥ min(Ti-1) и max(Si) ≤ max(Si-1), условия некорректного поведения
Учитывая, что min(Ti) ≥ min(Ti-1) и max(Si) ≤ max(Si-1), условия некорректного поведения

Слайд 76Поясним полученный результат. Исследуемая параллельная программа разделения множеств имеет целью собрать все
Поясним полученный результат. Исследуемая параллельная программа разделения множеств имеет целью собрать все

Слайд 77
Рис. 4.6.
Полученные выше условия некорректного поведения программы определены для (i-1)-го и i-го
Рис. 4.6.
Полученные выше условия некорректного поведения программы определены для (i-1)-го и i-го

Слайд 78Иными словами, если между упорядоченными по убыванию элементами множества S и упорядоченными
Иными словами, если между упорядоченными по убыванию элементами множества S и упорядоченными

 Сортировка с помощью дерева двоичного поиска
Сортировка с помощью дерева двоичного поиска Базы данных (БД)
Базы данных (БД) Триколор - мультиплатформенный оператор цифровой среды
Триколор - мультиплатформенный оператор цифровой среды Презентация на тему Информатика как наука
Презентация на тему Информатика как наука  Классификация информационных технологий. Задание 2. Вариант 7
Классификация информационных технологий. Задание 2. Вариант 7 Интернет-мошенничество
Интернет-мошенничество Презентация на тему Информация
Презентация на тему Информация  Организация сетевого доступа. Тема 3
Организация сетевого доступа. Тема 3 Алгоритмизация и программирование
Алгоритмизация и программирование Лекция 1 - Основы программирования
Лекция 1 - Основы программирования Реализация на жесткой и программируемой логике
Реализация на жесткой и программируемой логике Exceptions in Java
Exceptions in Java Языки программирования и структуры данных. Основы трансляции языков программирования
Языки программирования и структуры данных. Основы трансляции языков программирования Информационный технологии
Информационный технологии ГИА составляется на основе стандарта основного общего образования, и сдать его успешно может любой выпускник IX класса
ГИА составляется на основе стандарта основного общего образования, и сдать его успешно может любой выпускник IX класса Позиционирование. Параметры блока
Позиционирование. Параметры блока Сервис постановки и достижения целей AchieveMe
Сервис постановки и достижения целей AchieveMe Smart Elections (Умные выборы)
Smart Elections (Умные выборы) Схемотехника аналоговых устройств
Схемотехника аналоговых устройств Раскрашивание контурного изображения в программе Photoshop
Раскрашивание контурного изображения в программе Photoshop Полезные ресурсы. Работа в Сanva
Полезные ресурсы. Работа в Сanva Привет из прошлого. Убираем складки
Привет из прошлого. Убираем складки Исполнитель Робот
Исполнитель Робот Зависимость от социальных сетей
Зависимость от социальных сетей 5-2-1-kompjuter-universalnaja-mashina-dlja-raboty-s-informaciej
5-2-1-kompjuter-universalnaja-mashina-dlja-raboty-s-informaciej Ветвление программы, циклы
Ветвление программы, циклы Машинное обучение: линейные модели final
Машинное обучение: линейные модели final Презентация на тему Кодирование целых чисел
Презентация на тему Кодирование целых чисел