Разработка ИТ и систем для стимулирования устойчивого развития личности, как одна из основ развития цифрового Казахстана
- Разработка ИТ и систем для стимулирования устойчивого развития личности, как одна из основ развития цифрового Казахстана

Содержание
- 2. Группы проекта Мусабаев Р.Р.: Уалиева И.М., Красовицкий А.М., Мейрамбеккызы Ж., Аманбай А., Козбагаров О.Б., Төлеу А.,
- 3. Цель проекта Разработка методических и технологических основ применения информационной системы социального доверия с целью стимулирования устойчивого
- 4. Задача. Создание необходимых технических и экспертно-аналитических условий для разработки информационной системы оценки влияния открытых текстовых информационных
- 5. Using Centroid Keywords and WMD for Single Document Extractive Summarization - Использование центроидных ключевых слов и
- 6. Лаборатория «Анализа и моделирования информационных процессов» 2. Cosine distance to C: Косинусное расстояние до С Centroid
- 7. Лаборатория «Анализа и моделирования информационных процессов» Table 2: ROUGE-1 evaluation scores for our system, top 7
- 8. Word mover’s distance Пример: Идея: Расстояние между текстами, D – это минимальная потраченная работа для транспортировки
- 9. Группировка новостных публикаций по инфоповодам с помощью методов кластеризации Постановка задачи: Разработать подходы к группировке текстовой
- 10. Комбинированный подход: Мера Жаккара + WMD Мера Жаккара : Мера, основанная на Word Mover’s Distance: Разработанная
- 11. Комбинированный подход: Мера Жаккара + WMD Лаборатория «Анализа и моделирования информационных процессов»
- 12. Светло-зеленым цветом - новости раздела финансы Темно-зеленым – спорт (футбол) синие - происшествия оранжевые - политика
- 13. Применимость разработанного подхода к “большим данным” Время вычисления матрицы дистанций WMD 822 x 822 составило около
- 14. Виды представления публикаций Лаборатория «Анализа и моделирования информационных процессов»
- 15. Первые k предложения новостной публикации Лаборатория «Анализа и моделирования информационных процессов»
- 16. Комбинированный подход: Мера Жаккара + Word’s Average Мера Жаккара : Мера, основанная на евклидовом расстоянии: Функция
- 17. Комбинированный подход: Мера Жаккара + Word’s Average Лаборатория «Анализа и моделирования информационных процессов»
- 18. Применимость разработанного подхода к “большим данным” Рассмотрен корпус из 10 000 новостей. Время вычисления матрицы евклидова
- 19. Технологии создания декларативных средств для кластеризации документов СМИ (на основе методов семантического анализа текстов) Задачи исследования
- 20. Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла устойчивых фразеологических и терминологических
- 21. Гибридный алгоритм №5 выявления наименований понятий в текстах документов Лаборатория «Анализа и моделирования информационных процессов»
- 22. Кол. Документов в массиве = 3 004 документов Всего слов в массиве документов= 523 810 слов
- 23. Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для автоматической кластеризации текстовых документов
- 24. Автоматическое формирование тематических словарей социально-значимых понятий Распознавание социально значимых тем во множестве разнотематических новостных данных. Какие
- 25. Алгоритм выявления социально значимых новостей из кластеров новостных статей Лаборатория «Анализа и моделирования информационных процессов» Самые
- 26. Лаборатория «Анализа и моделирования информационных процессов» Матрица смежности слов I ФОРМИРОВАНИЕ ТЕМАТИЧЕСКИХ СЛОВАРЕЙ НА ОСНОВЕ CO-OCCURRENCE
- 27. Метод декомпозиций в кластеризации Лаборатория «Анализа и моделирования информационных процессов» Мотивация Кластеризация на больших наборах данных.
- 28. Оценки качества алгоритмов кластеризации Оценка на известных наборах данных c (частичной/полной) классификацией. Если данные размечены, например
- 29. Идея нашего метода Получать кластеризацию на сравнительно небольших подмножествах (выборках) исходных данных – окнах используя k-means++
- 30. Параллельная декомпозиция Phase 1 Win 1,…, win n независимые выборки(окна) из полного набора данных SSD 1,…,SSD
- 31. Последовательная декомпозиция Phase 2 Используется предыдущий алгоритм для инициализации Добавление следующего окна win n+l вносит вклад
- 32. Результаты экспериментов на синтетических наборах данных и данных UCI** Лаборатория «Анализа и моделирования информационных процессов»
- 33. Обобщение метода декомпозиций на другие алгоритмы кластеризации Заменить k-means++ любым кластерным алгоритмом для которого критерий SSD
- 35. Скачать презентацию
Слайд 2Группы проекта
Мусабаев Р.Р.: Уалиева И.М., Красовицкий А.М., Мейрамбеккызы Ж., Аманбай А., Козбагаров
Группы проекта
Мусабаев Р.Р.: Уалиева И.М., Красовицкий А.М., Мейрамбеккызы Ж., Аманбай А., Козбагаров

Слайд 3Цель проекта
Разработка методических и технологических основ применения информационной системы социального доверия с
Цель проекта
Разработка методических и технологических основ применения информационной системы социального доверия с

Слайд 4Задача. Создание необходимых технических и экспертно-аналитических условий для разработки информационной системы оценки
Задача. Создание необходимых технических и экспертно-аналитических условий для разработки информационной системы оценки

Слайд 5Using Centroid Keywords and WMD for Single Document Extractive Summarization - Использование
Using Centroid Keywords and WMD for Single Document Extractive Summarization - Использование

Слайд 6Лаборатория «Анализа и моделирования информационных процессов»
2. Cosine distance to C: Косинусное расстояние
Лаборатория «Анализа и моделирования информационных процессов»
2. Cosine distance to C: Косинусное расстояние

Слайд 7Лаборатория «Анализа и моделирования информационных процессов»
Table 2: ROUGE-1 evaluation scores for our
Лаборатория «Анализа и моделирования информационных процессов»
Table 2: ROUGE-1 evaluation scores for our

Слайд 8Word mover’s distance
Пример:
Идея: Расстояние между текстами, D – это минимальная потраченная работа
Word mover’s distance
Пример:
Идея: Расстояние между текстами, D – это минимальная потраченная работа

Слайд 9Группировка новостных публикаций по инфоповодам с помощью методов кластеризации
Постановка задачи:
Разработать подходы к
Группировка новостных публикаций по инфоповодам с помощью методов кластеризации
Постановка задачи:
Разработать подходы к

Слайд 10Комбинированный подход: Мера Жаккара + WMD
Мера Жаккара :
Мера, основанная на Word Mover’s Distance:
Разработанная
Комбинированный подход: Мера Жаккара + WMD
Мера Жаккара :
Мера, основанная на Word Mover’s Distance:
Разработанная

Слайд 11Комбинированный подход: Мера Жаккара + WMD
Лаборатория «Анализа и моделирования информационных процессов»
Комбинированный подход: Мера Жаккара + WMD
Лаборатория «Анализа и моделирования информационных процессов»
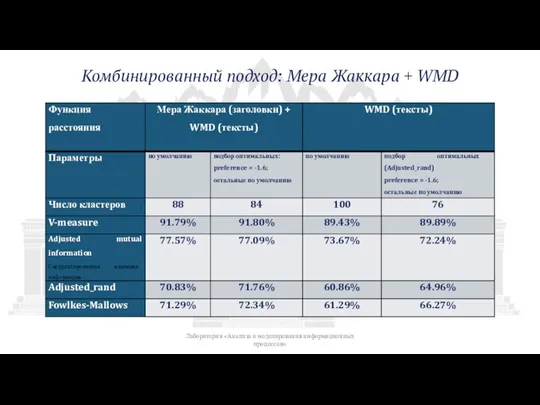
Слайд 12Светло-зеленым цветом - новости раздела финансы
Темно-зеленым – спорт (футбол)
синие - происшествия
оранжевые
Светло-зеленым цветом - новости раздела финансы
Темно-зеленым – спорт (футбол)
синие - происшествия
оранжевые
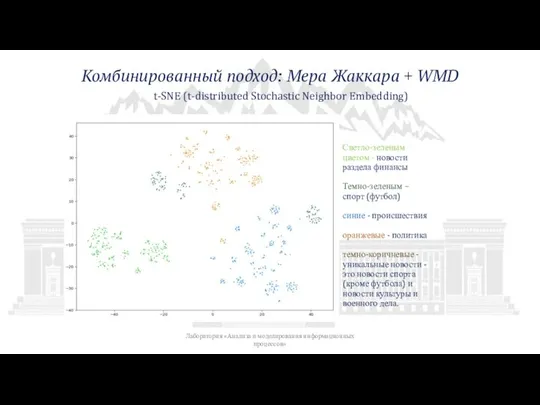
Слайд 13Применимость разработанного
подхода к “большим данным”
Время вычисления матрицы дистанций WMD 822 x
Применимость разработанного
подхода к “большим данным”
Время вычисления матрицы дистанций WMD 822 x

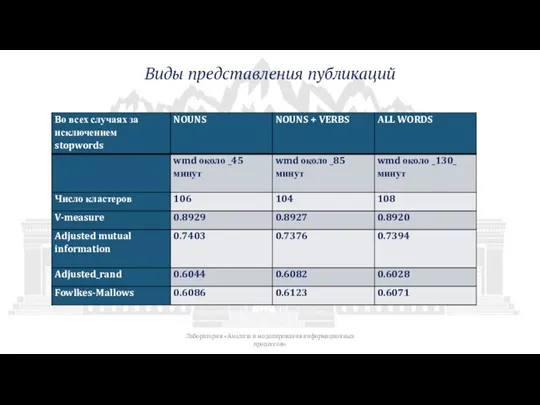
Слайд 14Виды представления публикаций
Лаборатория «Анализа и моделирования информационных процессов»
Виды представления публикаций
Лаборатория «Анализа и моделирования информационных процессов»
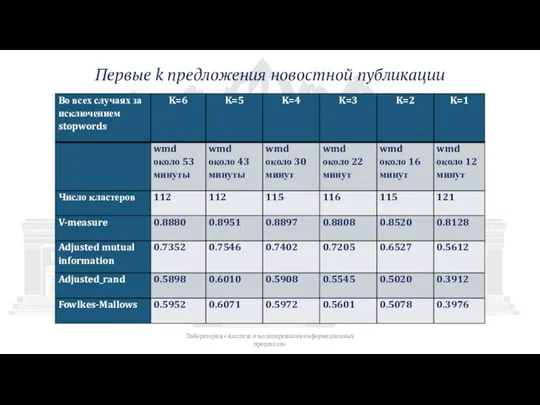
Слайд 15Первые k предложения новостной публикации
Лаборатория «Анализа и моделирования информационных процессов»
Первые k предложения новостной публикации
Лаборатория «Анализа и моделирования информационных процессов»
Слайд 16Комбинированный подход: Мера Жаккара + Word’s Average
Мера Жаккара :
Мера, основанная на евклидовом расстоянии:
Функция
Комбинированный подход: Мера Жаккара + Word’s Average
Мера Жаккара :
Мера, основанная на евклидовом расстоянии:
Функция

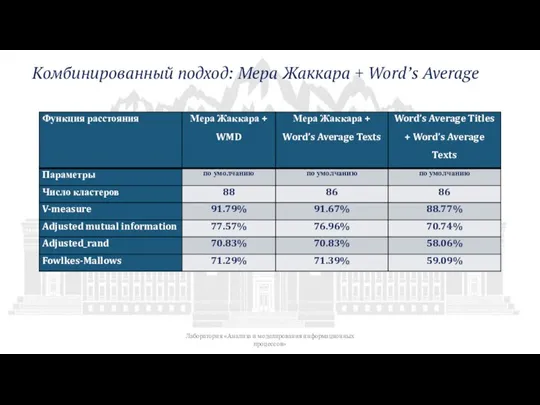
Слайд 17Комбинированный подход: Мера Жаккара + Word’s Average
Лаборатория «Анализа и моделирования информационных
Комбинированный подход: Мера Жаккара + Word’s Average
Лаборатория «Анализа и моделирования информационных
Слайд 18Применимость разработанного подхода к “большим данным”
Рассмотрен корпус из 10 000 новостей. Время
Применимость разработанного подхода к “большим данным”
Рассмотрен корпус из 10 000 новостей. Время

Слайд 19Технологии создания декларативных средств для кластеризации документов СМИ (на основе методов семантического
Технологии создания декларативных средств для кластеризации документов СМИ (на основе методов семантического

Слайд 20Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла
Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла

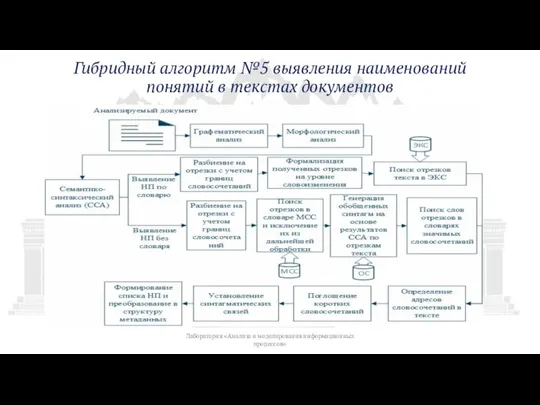
Слайд 21Гибридный алгоритм №5 выявления наименований понятий в текстах документов
Лаборатория «Анализа и моделирования
Гибридный алгоритм №5 выявления наименований понятий в текстах документов
Лаборатория «Анализа и моделирования
Слайд 22Кол. Документов в массиве = 3 004 документов
Всего слов в массиве документов=
Кол. Документов в массиве = 3 004 документов
Всего слов в массиве документов=

Слайд 23Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для
Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для

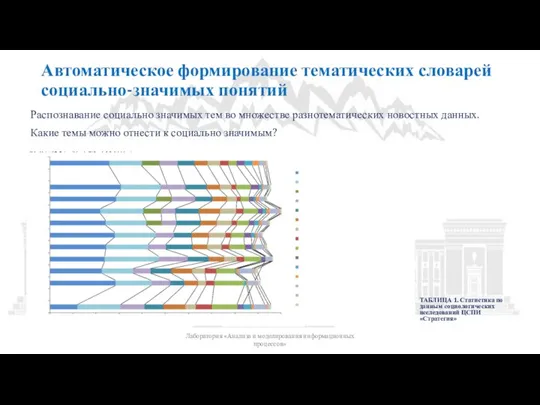
Слайд 24Автоматическое формирование тематических словарей социально-значимых понятий
Распознавание социально значимых тем во множестве разнотематических
Автоматическое формирование тематических словарей социально-значимых понятий
Распознавание социально значимых тем во множестве разнотематических
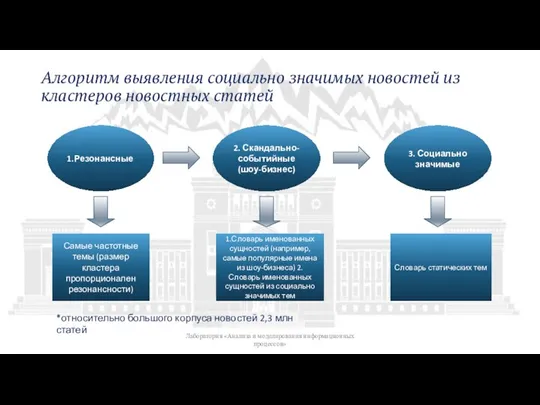
Слайд 25Алгоритм выявления социально значимых новостей из кластеров новостных статей
Лаборатория «Анализа и моделирования
Алгоритм выявления социально значимых новостей из кластеров новостных статей
Лаборатория «Анализа и моделирования
Слайд 26Лаборатория «Анализа и моделирования информационных процессов»
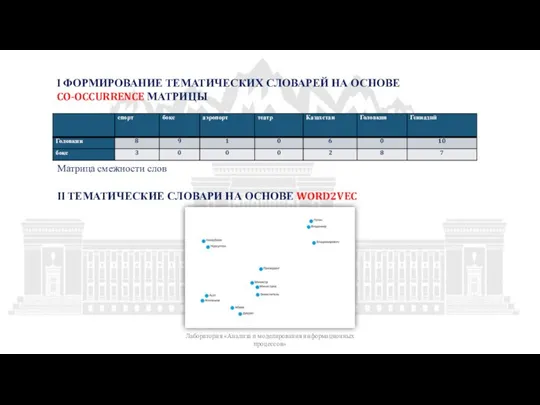
Матрица смежности слов
I ФОРМИРОВАНИЕ ТЕМАТИЧЕСКИХ СЛОВАРЕЙ НА
Лаборатория «Анализа и моделирования информационных процессов»
Матрица смежности слов
I ФОРМИРОВАНИЕ ТЕМАТИЧЕСКИХ СЛОВАРЕЙ НА
Слайд 27Метод декомпозиций в кластеризации
Лаборатория «Анализа и моделирования информационных процессов»
Мотивация
Кластеризация на больших наборах
Метод декомпозиций в кластеризации
Лаборатория «Анализа и моделирования информационных процессов»
Мотивация
Кластеризация на больших наборах

Слайд 28Оценки качества алгоритмов кластеризации
Оценка на известных наборах данных c (частичной/полной) классификацией. Если
Оценки качества алгоритмов кластеризации
Оценка на известных наборах данных c (частичной/полной) классификацией. Если

Слайд 29Идея нашего метода
Получать кластеризацию на сравнительно небольших подмножествах (выборках) исходных данных –
Идея нашего метода
Получать кластеризацию на сравнительно небольших подмножествах (выборках) исходных данных –

Слайд 30Параллельная
декомпозиция
Phase 1
Win 1,…, win n независимые выборки(окна) из полного набора данных
SSD
Параллельная
декомпозиция
Phase 1
Win 1,…, win n независимые выборки(окна) из полного набора данных
SSD

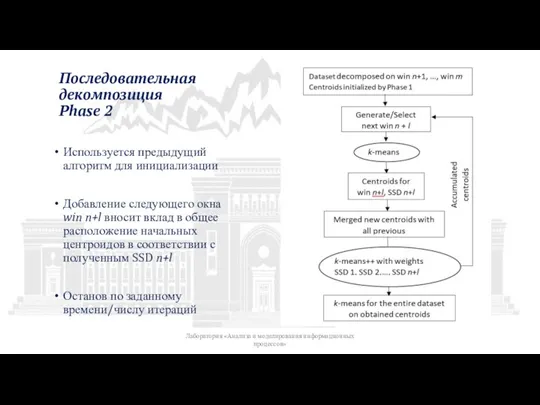
Слайд 31Последовательная
декомпозиция
Phase 2
Используется предыдущий алгоритм для инициализации
Добавление следующего окна win n+l вносит
Последовательная
декомпозиция
Phase 2
Используется предыдущий алгоритм для инициализации
Добавление следующего окна win n+l вносит
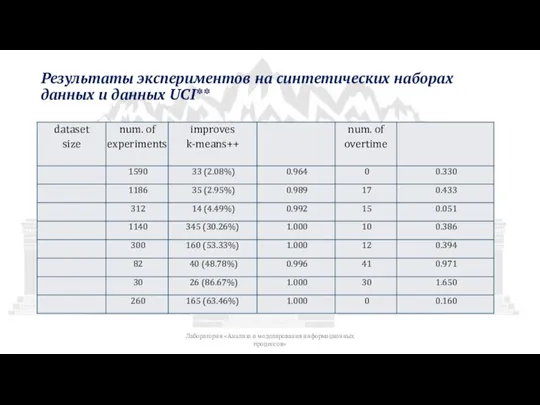
Слайд 32Результаты экспериментов на синтетических наборах данных и данных UCI**
Лаборатория «Анализа и
Результаты экспериментов на синтетических наборах данных и данных UCI**
Лаборатория «Анализа и
Слайд 33Обобщение метода декомпозиций на другие алгоритмы кластеризации
Заменить k-means++ любым кластерным алгоритмом для
Обобщение метода декомпозиций на другие алгоритмы кластеризации
Заменить k-means++ любым кластерным алгоритмом для

 numPy
numPy Введение в программу CorelDRAW
Введение в программу CorelDRAW измерение1
измерение1 Обобщенная модель нейрона. Персептрон (структура, алгоритмы обучения). Решение задачи распознавания образов с помощью НС
Обобщенная модель нейрона. Персептрон (структура, алгоритмы обучения). Решение задачи распознавания образов с помощью НС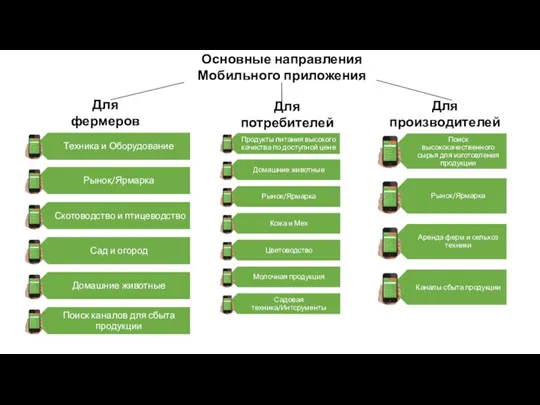 Основные направления мобильного приложения
Основные направления мобильного приложения Тестирование ЭВМ
Тестирование ЭВМ База данных. Подготовка к ЕГЭ
База данных. Подготовка к ЕГЭ Информационное моделирование. Модели объектов и их назначение
Информационное моделирование. Модели объектов и их назначение Решение прикладных задач и разработка приложений на языке Python
Решение прикладных задач и разработка приложений на языке Python Классификация и применение нейросетей
Классификация и применение нейросетей Карта социологических организаций и информационных ресурсов России
Карта социологических организаций и информационных ресурсов России Маскируемые подсистемы
Маскируемые подсистемы DeLion Re:start - изменить образ жизни
DeLion Re:start - изменить образ жизни Network services
Network services Риски и возможности интернета
Риски и возможности интернета Персональный компьютер (часть 1)
Персональный компьютер (часть 1) Устройство компьютера
Устройство компьютера Start. Pfyznbt 3
Start. Pfyznbt 3 Подготовка материалов на конкурс в облачной среде МойОфис
Подготовка материалов на конкурс в облачной среде МойОфис Технология работы с инфоповодами
Технология работы с инфоповодами Все, все про Майнкрафт
Все, все про Майнкрафт MeSH Медицинский предметный указатель
MeSH Медицинский предметный указатель База данных. MySQL (Занятие 10)
База данных. MySQL (Занятие 10) Авито для вашего бизнеса
Авито для вашего бизнеса Шаблон презентации по информатике
Шаблон презентации по информатике Программное обеспечение astraia
Программное обеспечение astraia Организация хранения информации в компьютере
Организация хранения информации в компьютере Zoom регистрация
Zoom регистрация