- Разработка системы классификации обращений клиентов в техподдержку приложения

Содержание
- 2. Постановка задачи Разработать интеллектуальную автоматизированную систему для классификации пользовательских обращений в техническую поддержку приложения, включающую в
- 3. Цели и задачи Провести исследование предметной области – задачи обработки данных на естественном языке Проанализировать исходный
- 4. План разработки Создание программного модуля предобработки обращений Тестирование и доработка модуля предобработки Обучение модели-классификатора Тестирование классификатора
- 5. Концепция и предполагаемые результаты
- 6. Концепция и предполагаемые результаты
- 7. Исходные данные Формат: Таблица Excel с размеченными данными Поля: Header – заголовок Body – само обращение
- 8. Проблемы датасета Малый объем данных Дисбаланс классов Множество слов с одной и более опечатками рекаищиты, тноефона,
- 9. Методы решения проблем Для исправления опечаток в словах был использован модуль PyEnchant, а также ряд составленных
- 10. Полученные результаты Изначальное количество словоформ: Число Количество словоформ после предобработки: число Число уникальных обращений после предобработки:
- 12. Скачать презентацию
Слайд 2Постановка задачи
Разработать интеллектуальную автоматизированную систему для классификации пользовательских обращений в техническую поддержку
Постановка задачи
Разработать интеллектуальную автоматизированную систему для классификации пользовательских обращений в техническую поддержку

Слайд 3Цели и задачи
Провести исследование предметной области – задачи обработки данных на естественном
Цели и задачи
Провести исследование предметной области – задачи обработки данных на естественном

Слайд 4План разработки
Создание программного модуля предобработки обращений
Тестирование и доработка модуля предобработки
Обучение модели-классификатора
Тестирование классификатора
План разработки
Создание программного модуля предобработки обращений
Тестирование и доработка модуля предобработки
Обучение модели-классификатора
Тестирование классификатора

Слайд 5Концепция и предполагаемые результаты
Концепция и предполагаемые результаты
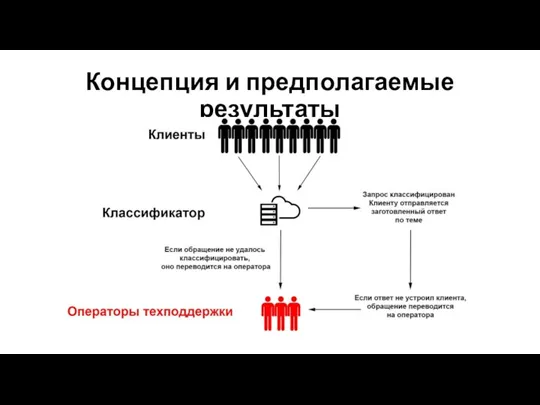
Слайд 6Концепция и предполагаемые результаты
Концепция и предполагаемые результаты

Слайд 7Исходные данные
Формат:
Таблица Excel с размеченными данными
Поля:
Header – заголовок
Body – само обращение
Class –
Исходные данные
Формат:
Таблица Excel с размеченными данными
Поля:
Header – заголовок
Body – само обращение
Class –

Слайд 8Проблемы датасета
Малый объем данных
Дисбаланс классов
Множество слов с одной и более опечатками
рекаищиты, тноефона,
Проблемы датасета
Малый объем данных
Дисбаланс классов
Множество слов с одной и более опечатками
рекаищиты, тноефона,

Слайд 9Методы решения проблем
Для исправления опечаток в словах был использован модуль PyEnchant, а
Методы решения проблем
Для исправления опечаток в словах был использован модуль PyEnchant, а

Слайд 10Полученные результаты
Изначальное количество словоформ:
Число
Количество словоформ после предобработки:
число
Число уникальных обращений после предобработки:
2176
Ключевые термины
Полученные результаты
Изначальное количество словоформ:
Число
Количество словоформ после предобработки:
число
Число уникальных обращений после предобработки:
2176
Ключевые термины

 Урок информатики в 7 классе
Урок информатики в 7 классе Программирование на языке С++
Программирование на языке С++ Распространение информации
Распространение информации Виды ссылок в ЭТ
Виды ссылок в ЭТ Интерактивные технологии. Облака слов. Форсайт-игра
Интерактивные технологии. Облака слов. Форсайт-игра Способы подключения к Интернету
Способы подключения к Интернету Компьютерная графика
Компьютерная графика Безопасный интернет. Интернет: вред и польза
Безопасный интернет. Интернет: вред и польза Компьютерная графика
Компьютерная графика RFID технология: Открытая библиотека
RFID технология: Открытая библиотека Списки. Срезы списков
Списки. Срезы списков Информационная безопасность
Информационная безопасность Применение технологии формирующего оценивания Цепочка заметок на уроке информатики
Применение технологии формирующего оценивания Цепочка заметок на уроке информатики Основы работы в QlikView
Основы работы в QlikView Редактор электронных таблиц MS Excel. Тема 3
Редактор электронных таблиц MS Excel. Тема 3 Презентация "Моделирование и формализация. Разработка и исследование математических моделей на компьютере" - скачать презен
Презентация "Моделирование и формализация. Разработка и исследование математических моделей на компьютере" - скачать презен Цвет в компьютерной графике
Цвет в компьютерной графике Как ИКТ помогают в ведении бизнеса
Как ИКТ помогают в ведении бизнеса Информатика. Представление чисел в ЭВМ. Лекция 4
Информатика. Представление чисел в ЭВМ. Лекция 4 2 ой раздел вводного экскурса в геоквантуме
2 ой раздел вводного экскурса в геоквантуме Программное обеспечение конроллеров. Алгоблоки
Программное обеспечение конроллеров. Алгоблоки Форсаж 2018
Форсаж 2018 Жанры тележурналистики
Жанры тележурналистики Умный город
Умный город Аналитика сайтов ЛПУ Хабаровского края
Аналитика сайтов ЛПУ Хабаровского края Организационная структура управления УГИБДД МВД по РД
Организационная структура управления УГИБДД МВД по РД Научная добросовестность и качество поиска и использования интеллектуальных ресурсов
Научная добросовестность и качество поиска и использования интеллектуальных ресурсов Language-Integrated Query (LINQ)
Language-Integrated Query (LINQ)