Статистические методы в искусственном интеллекте. Предсказание. Наивный Байесовский алгоритм и реализация Байесовского выражения
- Статистические методы в искусственном интеллекте. Предсказание. Наивный Байесовский алгоритм и реализация Байесовского выражения

Содержание
- 2. Представьте себе следующую ситуацию: вы работаете над задачей классификации, уже создали набор гипотез и сформировали признаки.
- 3. Содержание Что такое наивный байесовский алгоритм? Как он работает? Положительные и отрицательные. 4 приложения наивного байесовского
- 4. Что такое наивный байесовский алгоритм? Наивный байесовский алгоритм – это алгоритм классификации, основанный на теореме Байеса
- 5. Теорема Байеса позволяет рассчитать апостериорную вероятность P(c|x) на основе P(c), P(x) и P(x|c). P(c|x) – апостериорная
- 6. Как работает наивный байесовский алгоритм? Давайте рассмотрим пример. Ниже представлен обучающий набор данных, содержащий один признак
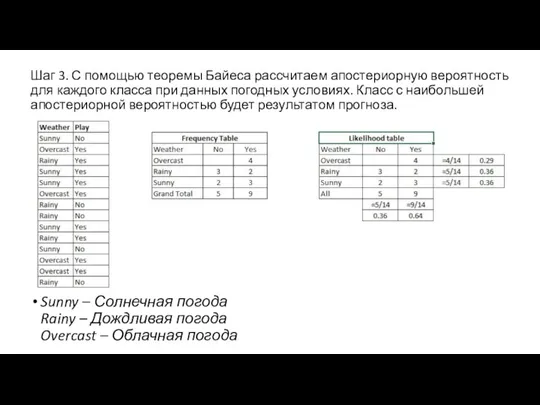
- 7. Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого класса при данных погодных условиях.
- 8. Задача. Состоится ли матч при солнечной погоде (sunny)? Мы можем решить эту задачу с помощью описанного
- 9. Положительные и отрицательные стороны наивного байесовского алгоритма Положительные стороны: Классификация, в том числе многоклассовая, выполняется легко
- 10. Отрицательные стороны: Если в тестовом наборе данных присутствует некоторое значение категорийного признака, которое не встречалось в
- 11. 4 приложения наивного байесовского алгоритма Классификация в режиме реального времени. НБА очень быстро обучается, поэтому его
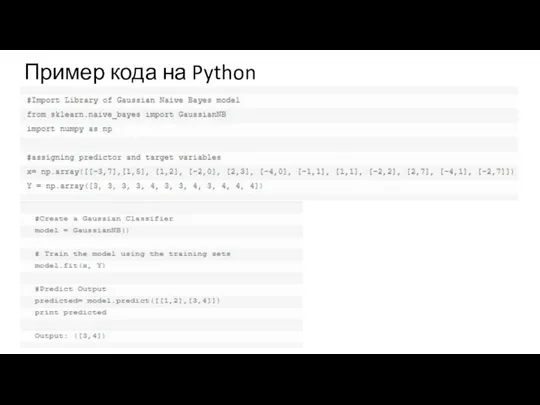
- 12. Как создать базовую модель на основе наивного байесовского алгоритма с помощью Python? В этом нам поможет
- 13. Пример кода на Python
- 14. Пример: Байесовский классификатор относится к разряду машинного обучения. Суть такова: система, перед которой стоит задача определить,
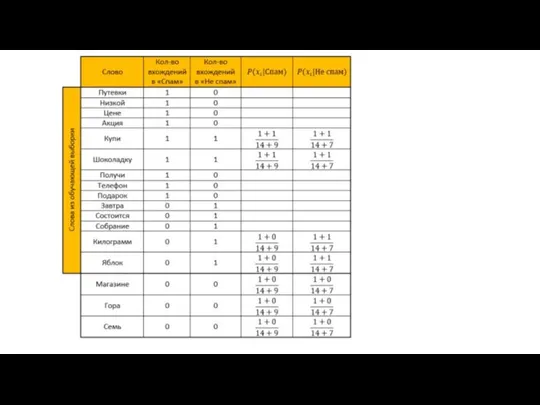
- 15. Необходимо рассчитать оценку для каждого класса (спам/не спам) и выбрать ту, которая получилась максимальной. Для этого
- 16. Когда объем текста очень большой, приходится работать с очень маленькими числами. Для того чтобы этого избежать,
- 17. *Во время выполнения подсчетов вам может встретиться слово, которого не было на этапе обучения системы. Это
- 18. От теории к практике Пусть наша система обучалась на следующих письмам, заранее известных где «спам», а
- 19. Задание: определить, к какой категории отнести следующее письмо: «В магазине гора яблок. Купи семь килограмм и
- 21. Оценка для категории «Спам»: Оценка для категории «Не спам»: Ответ: оценка «Не спам» больше оценки «Спам».
- 22. То же самое рассчитаем и с помощью функции, преобразованной по свойству логарифма: Оценка для категории «Спам»:
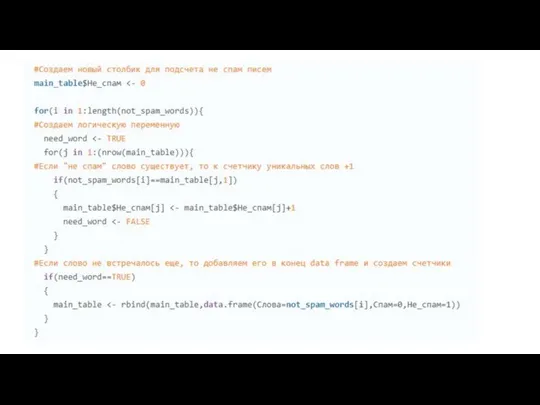
- 23. Реализация на языке программирования R
- 28. #Используем ту же логическую переменную, чтобы не создавать новую need_word for(j in 1:nrow(main_table)) { #Если слово
- 31. Скачать презентацию
Слайд 2Представьте себе следующую ситуацию: вы работаете над задачей классификации, уже создали набор
Представьте себе следующую ситуацию: вы работаете над задачей классификации, уже создали набор

Слайд 3Содержание
Что такое наивный байесовский алгоритм?
Как он работает?
Положительные и отрицательные.
4 приложения наивного байесовского
Содержание
Что такое наивный байесовский алгоритм?
Как он работает?
Положительные и отрицательные.
4 приложения наивного байесовского

Слайд 4Что такое наивный байесовский алгоритм?
Наивный байесовский алгоритм – это алгоритм классификации, основанный
Что такое наивный байесовский алгоритм?
Наивный байесовский алгоритм – это алгоритм классификации, основанный

Слайд 5Теорема Байеса позволяет рассчитать апостериорную вероятность P(c|x) на основе P(c), P(x) и P(x|c).
P(c|x) – апостериорная вероятность данного класса c (т.е. данного
Теорема Байеса позволяет рассчитать апостериорную вероятность P(c|x) на основе P(c), P(x) и P(x|c).
P(c|x) – апостериорная вероятность данного класса c (т.е. данного

Слайд 6Как работает наивный байесовский алгоритм?
Давайте рассмотрим пример. Ниже представлен обучающий набор данных,
Как работает наивный байесовский алгоритм?
Давайте рассмотрим пример. Ниже представлен обучающий набор данных,

Слайд 7Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого класса
Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого класса
Слайд 8Задача. Состоится ли матч при солнечной погоде (sunny)?
Мы можем решить эту задачу
Задача. Состоится ли матч при солнечной погоде (sunny)?
Мы можем решить эту задачу

Слайд 9Положительные и отрицательные стороны наивного байесовского алгоритма
Положительные стороны:
Классификация, в том числе многоклассовая,
Положительные и отрицательные стороны наивного байесовского алгоритма
Положительные стороны:
Классификация, в том числе многоклассовая,

Слайд 10Отрицательные стороны:
Если в тестовом наборе данных присутствует некоторое значение категорийного признака, которое
Отрицательные стороны:
Если в тестовом наборе данных присутствует некоторое значение категорийного признака, которое

Слайд 114 приложения наивного байесовского алгоритма
Классификация в режиме реального времени. НБА очень быстро обучается,
4 приложения наивного байесовского алгоритма
Классификация в режиме реального времени. НБА очень быстро обучается,

Слайд 12Как создать базовую модель на основе наивного байесовского алгоритма с помощью Python?
В
Как создать базовую модель на основе наивного байесовского алгоритма с помощью Python?
В

Слайд 13Пример кода на Python
Пример кода на Python
Слайд 14Пример:
Байесовский классификатор относится к разряду машинного обучения. Суть такова: система, перед которой
Пример:
Байесовский классификатор относится к разряду машинного обучения. Суть такова: система, перед которой

Слайд 15Необходимо рассчитать оценку для каждого класса (спам/не спам) и выбрать ту, которая
Необходимо рассчитать оценку для каждого класса (спам/не спам) и выбрать ту, которая

Слайд 16Когда объем текста очень большой, приходится работать с очень маленькими числами. Для
Когда объем текста очень большой, приходится работать с очень маленькими числами. Для

Слайд 17*Во время выполнения подсчетов вам может встретиться слово, которого не было на
*Во время выполнения подсчетов вам может встретиться слово, которого не было на

Слайд 18От теории к практике
Пусть наша система обучалась на следующих письмам, заранее известных
От теории к практике
Пусть наша система обучалась на следующих письмам, заранее известных

Слайд 19Задание: определить, к какой категории отнести следующее письмо:
«В магазине гора яблок. Купи семь
Задание: определить, к какой категории отнести следующее письмо: «В магазине гора яблок. Купи семь

Слайд 21Оценка для категории «Спам»:
Оценка для категории «Не спам»:
Ответ: оценка «Не спам» больше оценки
Оценка для категории «Спам»:
Оценка для категории «Не спам»:
Ответ: оценка «Не спам» больше оценки

Слайд 22То же самое рассчитаем и с помощью функции, преобразованной по свойству логарифма:
Оценка
То же самое рассчитаем и с помощью функции, преобразованной по свойству логарифма: Оценка

Слайд 23Реализация на языке программирования R
Реализация на языке программирования R




Слайд 28#Используем ту же логическую переменную, чтобы не создавать новую
need_word <- TRUE
#Используем ту же логическую переменную, чтобы не создавать новую
need_word <- TRUE


 Информационные технологии комплектации заказов в логистике
Информационные технологии комплектации заказов в логистике Microprocessor-Based Systems
Microprocessor-Based Systems Цвета. Урок 10
Цвета. Урок 10 Форма В MS ACCESS. Тема 6.4
Форма В MS ACCESS. Тема 6.4 Наследование классов. Пример лабораторной 2
Наследование классов. Пример лабораторной 2 OSINT Разведка по открытым источникам. Рекогносцировка
OSINT Разведка по открытым источникам. Рекогносцировка Обучающая презентация
Обучающая презентация Устройство ПК
Устройство ПК Устройства образующие типовой компьютер
Устройства образующие типовой компьютер Добавление и форматирование текста
Добавление и форматирование текста Базы данных. Онлайн формат
Базы данных. Онлайн формат История и возможности социальной сети
История и возможности социальной сети Школа программирования
Школа программирования Программирование баз данных
Программирование баз данных Создание графических объектов в текстовом редакторе
Создание графических объектов в текстовом редакторе Жанровый состав
Жанровый состав Программный продукт для гидродинамического моделирования TEMPEST (ROXAR)
Программный продукт для гидродинамического моделирования TEMPEST (ROXAR) Zetron Telekom (Call center)
Zetron Telekom (Call center) Информационные процессы. Обработка информации. 7 класс
Информационные процессы. Обработка информации. 7 класс Открытка. Поздравляю
Открытка. Поздравляю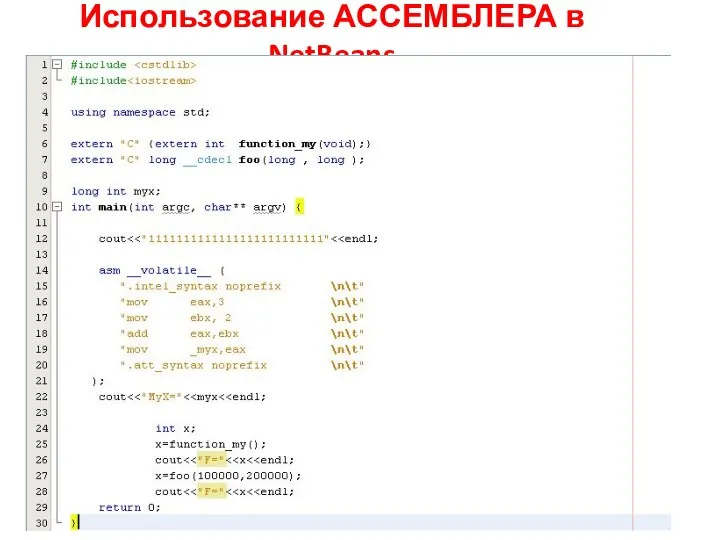 Использование ассемблера в NetBeans
Использование ассемблера в NetBeans Textovye_redaktory
Textovye_redaktory Регистрация магазина на Etsy
Регистрация магазина на Etsy Методология разработки программного модуля
Методология разработки программного модуля Умные таблицы Excel 2007-2013
Умные таблицы Excel 2007-2013 Интернет сервисы, используемые банком при проверке сведений, полученных от клиентов при идентификации
Интернет сервисы, используемые банком при проверке сведений, полученных от клиентов при идентификации Как с помощью продукции повседневного ухода за собой получить доход в интернете
Как с помощью продукции повседневного ухода за собой получить доход в интернете Функціональний опис та моделювання систем. Лекція 4
Функціональний опис та моделювання систем. Лекція 4