- Технология CUDA

Содержание
- 2. Этапы эволюции графических процессоров (1) ГПУ 1го поколения (середина 90х) – «ответ» на возрастающее потребление вычислительных
- 3. ГПУ 2го поколения (2001-2005). Возможность программирования ГПУ. Изначально фиксированный алгоритм вычисления освещенности и преобразования координат вершин
- 4. ГПУ 3го поколения (c 2005) характеризуются расширенными возможностями программирования. Появляются операции ветвления и циклов, что позволяет
- 5. OpenGLv2.0: поддержка высокоуровневого шейдерного языка GLSL. Производительность ГПУ на реальных задачах достигает сотен Гфлопс. Поддержка целочисленных
- 6. Почему ГПУ ? (1) Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно отличается от традиционного программирования
- 7. Средства программирования ГПУ Шейдерные языки (OpenGL, OpenAL) позволяют лаконично описывать некоторые алгоритмы. Специализированные средства от производителей
- 8. Технология CUDA: зачем? (1) CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose computing on Graphics
- 9. Технология CUDA: зачем? (2) Современные видеочипы содержат сотни математических исполнитель-ных блоков, эта мощь может использоваться для
- 10. Технология CUDA: зачем? (3) Именно поэтому компания NVIDIA выпустила платформу CUDA — Cи-подобный язык программирования со
- 11. CUDA: общие положения (1) GPU (device) – сопроцессор для CPU (хоста) У GPU есть собственная память
- 12. CUDA: общие положения (2) Общая схема кода: Выделяется общая память на ГПУ Копируются необходимые данные из
- 13. CUDA: Основы создания программ (1) Первый шаг при переносе существующего приложения на CUDA – определение участков
- 14. CUDA: Основы создания программ (2) Каждый SM состоит из восьми и более ядер — потоковых процессоров,
- 15. CUDA: Модель памяти (1) Модель памяти в CUDA отличается возможностью побайтной адресации, с поддержкой gather и
- 16. CUDA: Модель памяти (2) Память констант: область памяти (64 килобайт), доступная только для чтения всеми МП.
- 17. CUDA: спецификаторы Спецификаторы функций __device__ (выполняется на ГПУ, вызывается из ГПУ) __global__ (выполняется на ГПУ, вызывается
- 18. CUDA: добавленные типы и функции Добавленные типы: 1\2\3\4-мерные векторы базовых типов. Специальные переменные: gridDim (размер сетки);
- 19. __global__ void kernel (float *a, float *b, float *c) { // глобальный индекс нити Int idx
- 20. Resumé Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора к CPU. Cuda-код задействует
- 22. Скачать презентацию

Слайд 3ГПУ 2го поколения (2001-2005). Возможность программирования ГПУ. Изначально фиксированный алгоритм вычисления освещенности
ГПУ 2го поколения (2001-2005). Возможность программирования ГПУ. Изначально фиксированный алгоритм вычисления освещенности

Слайд 4ГПУ 3го поколения (c 2005) характеризуются расширенными возможностями программирования. Появляются операции ветвления
ГПУ 3го поколения (c 2005) характеризуются расширенными возможностями программирования. Появляются операции ветвления

Слайд 5OpenGLv2.0: поддержка высокоуровневого шейдерного языка GLSL. Производительность ГПУ на реальных задачах достигает
OpenGLv2.0: поддержка высокоуровневого шейдерного языка GLSL. Производительность ГПУ на реальных задачах достигает

Слайд 6Почему ГПУ ? (1)
Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно отличается
Почему ГПУ ? (1)
Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно отличается

Слайд 7Средства программирования ГПУ
Шейдерные языки (OpenGL, OpenAL) позволяют лаконично описывать некоторые алгоритмы.
Специализированные средства
Средства программирования ГПУ
Шейдерные языки (OpenGL, OpenAL) позволяют лаконично описывать некоторые алгоритмы.
Специализированные средства

Слайд 8Технология CUDA: зачем? (1)
CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose computing
Технология CUDA: зачем? (1)
CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose computing

Слайд 9Технология CUDA: зачем? (2)
Современные видеочипы содержат сотни математических исполнитель-ных блоков, эта
Технология CUDA: зачем? (2)
Современные видеочипы содержат сотни математических исполнитель-ных блоков, эта

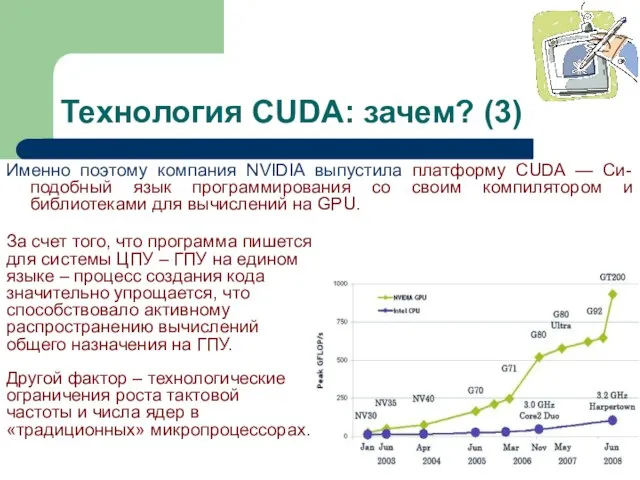
Слайд 10Технология CUDA: зачем? (3)
Именно поэтому компания NVIDIA выпустила платформу CUDA —
Технология CUDA: зачем? (3)
Именно поэтому компания NVIDIA выпустила платформу CUDA —
Слайд 11CUDA: общие положения (1)
GPU (device) – сопроцессор для CPU (хоста)
У
CUDA: общие положения (1)
GPU (device) – сопроцессор для CPU (хоста)
У

Слайд 12CUDA: общие положения (2)
Общая схема кода:
Выделяется общая память на ГПУ
Копируются необходимые данные
CUDA: общие положения (2)
Общая схема кода:
Выделяется общая память на ГПУ
Копируются необходимые данные

Слайд 13CUDA: Основы создания программ (1)
Первый шаг при переносе существующего приложения на
CUDA: Основы создания программ (1)
Первый шаг при переносе существующего приложения на

Слайд 14CUDA: Основы создания программ (2)
Каждый SM состоит из восьми и более ядер
CUDA: Основы создания программ (2)
Каждый SM состоит из восьми и более ядер

Слайд 15CUDA: Модель памяти (1)
Модель памяти в CUDA отличается возможностью побайтной адресации, с
CUDA: Модель памяти (1)
Модель памяти в CUDA отличается возможностью побайтной адресации, с

Слайд 16CUDA: Модель памяти (2)
Память констант: область памяти (64 килобайт), доступная только для
CUDA: Модель памяти (2)
Память констант: область памяти (64 килобайт), доступная только для

Слайд 17CUDA:
спецификаторы
Спецификаторы функций
__device__ (выполняется на ГПУ, вызывается из ГПУ)
__global__ (выполняется на ГПУ, вызывается
CUDA:
спецификаторы
Спецификаторы функций
__device__ (выполняется на ГПУ, вызывается из ГПУ)
__global__ (выполняется на ГПУ, вызывается

Слайд 18CUDA:
добавленные типы и функции
Добавленные типы: 1\2\3\4-мерные векторы базовых типов.
Специальные переменные:
gridDim (размер сетки);
CUDA:
добавленные типы и функции
Добавленные типы: 1\2\3\4-мерные векторы базовых типов.
Специальные переменные:
gridDim (размер сетки);

Слайд 19__global__ void kernel (float *a, float *b, float *c)
{
// глобальный индекс нити
Int
__global__ void kernel (float *a, float *b, float *c)
{
// глобальный индекс нити
Int

Слайд 20Resumé
Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора к
Resumé
Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора к

 7-1-2
7-1-2 Презентация на тему Блок схемы
Презентация на тему Блок схемы  #VKLIVE: прямые трансляции с мобильного устройства
#VKLIVE: прямые трансляции с мобильного устройства Математические технологии моделирования вирусной динамики
Математические технологии моделирования вирусной динамики Web-страницы. Язык HTML и др. Тема 1
Web-страницы. Язык HTML и др. Тема 1 Файлы и файловая система
Файлы и файловая система Общее и частное наследование. Права доступа. Язык С++. (Лекция 8)
Общее и частное наследование. Права доступа. Язык С++. (Лекция 8) Что такое интернет
Что такое интернет Сравнительный анализ сайтов
Сравнительный анализ сайтов Логические операции
Логические операции IKT pagrindai
IKT pagrindai Вася на Сене
Вася на Сене Основные технические элементы компьютерного симулятора
Основные технические элементы компьютерного симулятора Системный блок
Системный блок Исполнитель Робот
Исполнитель Робот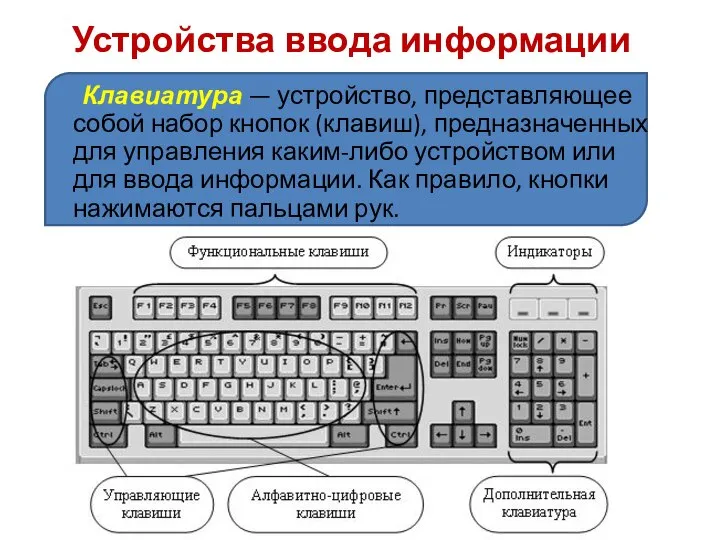 Устройства ввода информации
Устройства ввода информации Совершенствование внеурочной учебной деятельности учащихся средствами информационных технологий
Совершенствование внеурочной учебной деятельности учащихся средствами информационных технологий Информационные процессы
Информационные процессы Помощь сетевекам при работе в интернете. Боли разных целевых аудиторий
Помощь сетевекам при работе в интернете. Боли разных целевых аудиторий Исполнитель Водолей
Исполнитель Водолей Информатика и я
Информатика и я Анализ телеграм-канала Шум и я
Анализ телеграм-канала Шум и я Каблуки - красота или здоровье?
Каблуки - красота или здоровье? Использование пакета Microsoft Office
Использование пакета Microsoft Office Время думать. Информатика
Время думать. Информатика Виды серверного ПО
Виды серверного ПО Planning the Post Sprawl Era
Planning the Post Sprawl Era Казка Фантастичний біном
Казка Фантастичний біном