- Управление параллелизмом в СУБД. (Лекция 6)

Содержание
- 2. Под распределенной (Distributed DataBase - DDB) обычно понимают базу данных, декомпозированную и фрагментированную на несколько узлов
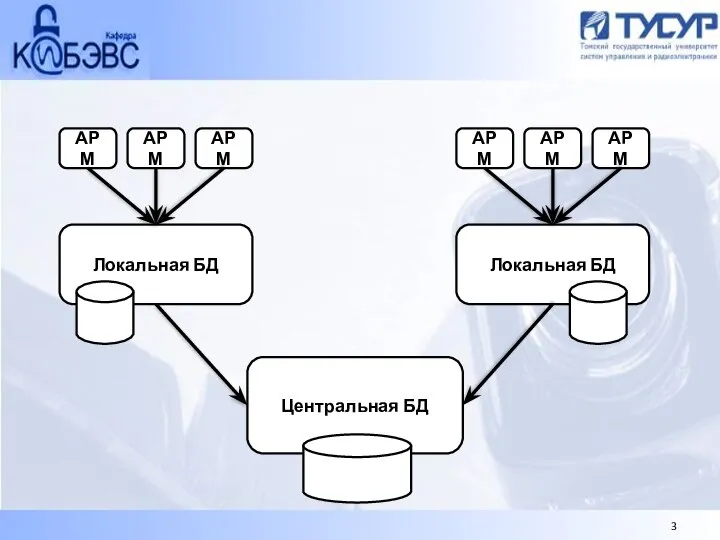
- 3. АРМ АРМ АРМ АРМ АРМ АРМ Локальная БД Локальная БД Центральная БД
- 4. Распределенная БД должна обладать: Локальными и глобальными (распределенными) средствами доступа к данным(СУБД). Единообразной логикой прикладных программ
- 5. Распределенная БД должна обладать: 6. Развитой системой управления резервным копированием и восстановления данных на случай сбоев.
- 6. Принципы построения распределенной БД: 1. Минимизация интенсивности обмена данными (сетевого трафика). 2. Оптимальным размещением серверных и
- 7. Критерии построения распределенной БД: 1. Всесторонний анализ информационных потребностей предметной области с выявлением объемов хранимых данных,
- 8. Распределенные архитектуры БД принято подразделять по типам на Системы не дублирующего разбиения (при большом объеме часто
- 9. Достаточные свойства для корректной работы распределенной БД
- 10. Локальная автономия Это качество означает, что управление данными на каждом из узлов распределенной системы выполняется локально.
- 11. Независимость узлов В идеальной системе все узлы равноправны и независимы, а расположенные на них базы являются
- 12. Непрерывные операции Это качество можно трактовать как возможность непрерывного доступа к данным (известное "24 часа в
- 13. Прозрачность расположения Это свойство означает полную прозрачность расположения данных. Пользователь, обращающийся к DDB, ничего не должен
- 14. Прозрачная фрагментация Это свойство трактуется как возможность распределенного (то есть на различных узлах) размещения данных, логически
- 15. Прозрачное тиражирование Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений объектов исходной базы
- 16. Обработка распределенных запросов Это свойство DDB трактуется как возможность выполнения операций выборки над распределенной базой данных,
- 17. Обработка распределенных транзакций Это качество DDB можно трактовать как возможность выполнения операций обновления распределенной базы данных
- 18. Прозрачность сети Доступ к любым базам данных может осуществляться по сети. Спектр поддерживаемых конкретной СУБД сетевых
- 19. Независимость от оборудования Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры любых
- 20. Независимость от операционных систем Это качество вытекает из предыдущего и означает многообразие операционных систем, управляющих узлами
- 21. Независимость от систем управления Это качество означает, что в распределенной системе могут мирно сосуществовать СУБД различных
- 23. Скачать презентацию
Слайд 2Под распределенной (Distributed DataBase - DDB) обычно понимают базу данных, декомпозированную и

Слайд 3АРМ
АРМ
АРМ
АРМ
АРМ
АРМ
Локальная БД
Локальная БД
Центральная БД
АРМ
АРМ
АРМ
АРМ
АРМ
АРМ
Локальная БД
Локальная БД
Центральная БД
Слайд 4Распределенная БД должна обладать:
Локальными и глобальными (распределенными) средствами доступа к данным(СУБД).
Единообразной логикой
Распределенная БД должна обладать:
Локальными и глобальными (распределенными) средствами доступа к данным(СУБД).
Единообразной логикой

Слайд 5Распределенная БД должна обладать:
6. Развитой системой управления резервным копированием и восстановления данных
Распределенная БД должна обладать:
6. Развитой системой управления резервным копированием и восстановления данных

Слайд 6Принципы построения распределенной БД:
1. Минимизация интенсивности обмена данными (сетевого трафика).
2. Оптимальным размещением
Принципы построения распределенной БД:
1. Минимизация интенсивности обмена данными (сетевого трафика).
2. Оптимальным размещением

Слайд 7Критерии построения распределенной БД:
1. Всесторонний анализ информационных потребностей предметной области с выявлением
Критерии построения распределенной БД:
1. Всесторонний анализ информационных потребностей предметной области с выявлением

Слайд 8Распределенные архитектуры БД принято подразделять по типам на
Системы не дублирующего разбиения (при
Распределенные архитектуры БД принято подразделять по типам на
Системы не дублирующего разбиения (при

Слайд 9Достаточные свойства для корректной работы распределенной БД

Слайд 10Локальная автономия
Это качество означает, что управление данными на каждом из узлов распределенной
Локальная автономия
Это качество означает, что управление данными на каждом из узлов распределенной

Слайд 11Независимость узлов
В идеальной системе все узлы равноправны и независимы, а расположенные на
Независимость узлов
В идеальной системе все узлы равноправны и независимы, а расположенные на

Слайд 12Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к данным (известное
Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к данным (известное

Слайд 13Прозрачность расположения
Это свойство означает полную прозрачность расположения данных. Пользователь, обращающийся к DDB,
Прозрачность расположения
Это свойство означает полную прозрачность расположения данных. Пользователь, обращающийся к DDB,

Слайд 14Прозрачная фрагментация
Это свойство трактуется как возможность распределенного (то есть на различных узлах)
Прозрачная фрагментация
Это свойство трактуется как возможность распределенного (то есть на различных узлах)

Слайд 15Прозрачное тиражирование
Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений
Прозрачное тиражирование
Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений

Слайд 16Обработка распределенных запросов
Это свойство DDB трактуется как возможность выполнения операций выборки над
Обработка распределенных запросов
Это свойство DDB трактуется как возможность выполнения операций выборки над

Слайд 17Обработка распределенных транзакций
Это качество DDB можно трактовать как возможность выполнения операций обновления
Обработка распределенных транзакций
Это качество DDB можно трактовать как возможность выполнения операций обновления

Слайд 18Прозрачность сети
Доступ к любым базам данных может осуществляться по сети. Спектр поддерживаемых
Прозрачность сети
Доступ к любым базам данных может осуществляться по сети. Спектр поддерживаемых

Слайд 19Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной системы могут
Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной системы могут

Слайд 20Независимость от операционных систем
Это качество вытекает из предыдущего и означает многообразие операционных
Независимость от операционных систем
Это качество вытекает из предыдущего и означает многообразие операционных

Слайд 21Независимость от систем управления
Это качество означает, что в распределенной системе могут мирно
Независимость от систем управления
Это качество означает, что в распределенной системе могут мирно

 Креатив и оптимизация: друзья или враги?
Креатив и оптимизация: друзья или враги? Экономика и финансы. Творческая школа Хорошие презентации
Экономика и финансы. Творческая школа Хорошие презентации Методы обработки информации
Методы обработки информации Устройство ПК
Устройство ПК 5 Типы данных
5 Типы данных Носители информации. Кодирование информации. Способы кодирования информации
Носители информации. Кодирование информации. Способы кодирования информации Operators and Expression / 1 of 25
Operators and Expression / 1 of 25 Компьютерное зрение
Компьютерное зрение Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий
Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий Редактирование текста
Редактирование текста Вход в личный кабинет
Вход в личный кабинет Дополнительные устройства компьютера
Дополнительные устройства компьютера Планерка. Семейство IG
Планерка. Семейство IG Шаблон паспорта проектной идеи
Шаблон паспорта проектной идеи Измерение текстовой информации
Измерение текстовой информации Комплектующие компьютера
Комплектующие компьютера Разработка архитектурного прототипа системы для репетиторства
Разработка архитектурного прототипа системы для репетиторства Делаем первый проект
Делаем первый проект Свинограм
Свинограм Базы данных
Базы данных Використання інформаційних технологій у вирішенні галузевих завдань
Використання інформаційних технологій у вирішенні галузевих завдань Эллиптическое шифрование
Эллиптическое шифрование Диаграммы и графики
Диаграммы и графики Базы данных
Базы данных Информационные технологии на уроках
Информационные технологии на уроках Медиация в моей жизни
Медиация в моей жизни Растровая и векторная графика
Растровая и векторная графика Признаки предметов
Признаки предметов