- Математические методы в филологии

Содержание
- 2. Основные области применения количественных методов Корпусная лингвистика Сравнительно-историческое языкознание Социолингвистика Дискурс-анализ Стилистика (анализ лексики как основание
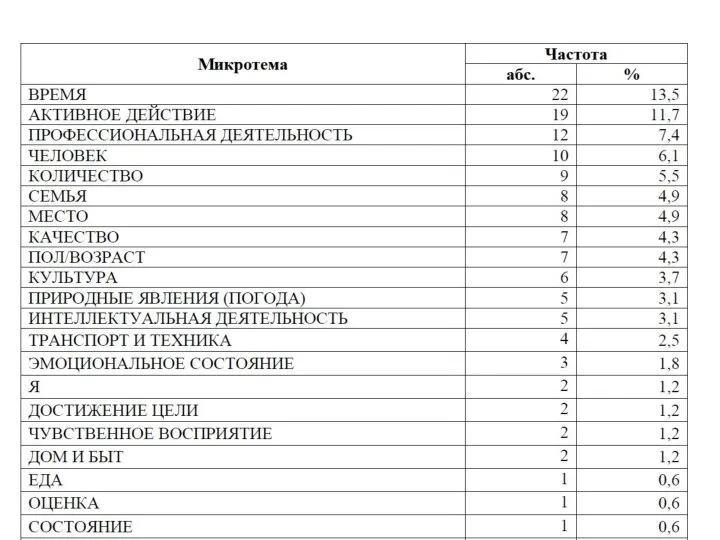
- 3. Контент-анализ как количественный метод анализа текстов Сущность контент-анализа заключается в том, чтобы по внешним — количественным
- 4. Контент-анализ как количественный метод анализа текстов Важнейшей категорией контент-анализа является концептуальная переменная — понятие, которое стоит
- 5. Этапы подготовки и проведения исследования выбор материала—корпуса языковых данных; выбор концептуальной переменной и определение ее значений
- 6. Этапы подготовки и проведения исследования 4) отбор кодировщиков (выбор программ) и формулировка инструкций по кодированию; существует
- 7. Проблема семантической достоверности Необходимо учитывать многозначность языковых выражений, являющихся значениями К-переменной. После этого тихо тлевшая война
- 8. Исследование политических метафор с помощью контент-анализа X. де Ландшер на материале голландского политического дискурса за период
- 9. Степень метафоричности дискурса Степень метафоричности для разных метафор может различаться, для общей оценки силы метафоры была
- 10. Тип метафорической модели Сила воздействия метафоры связана не только с новизной или общепринятостью, но и с
- 11. Результаты исследования Результаты кодирования и вычисленные переменные интенсивности и содержания были сопоставлены с имеющимися в статистических
- 12. Семантический анализ текста Семантическая структура устного спонтанного текста: социолингвистическое варьирование (Павлова Д.С., Ерофеева Е.В.) В рамках
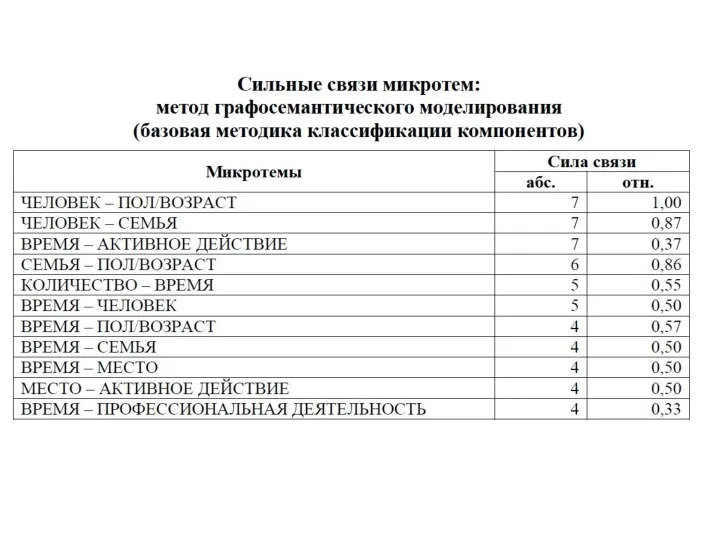
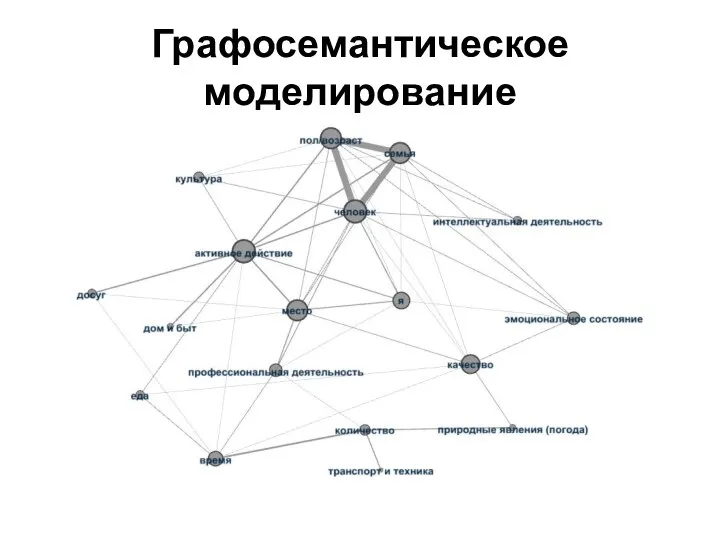
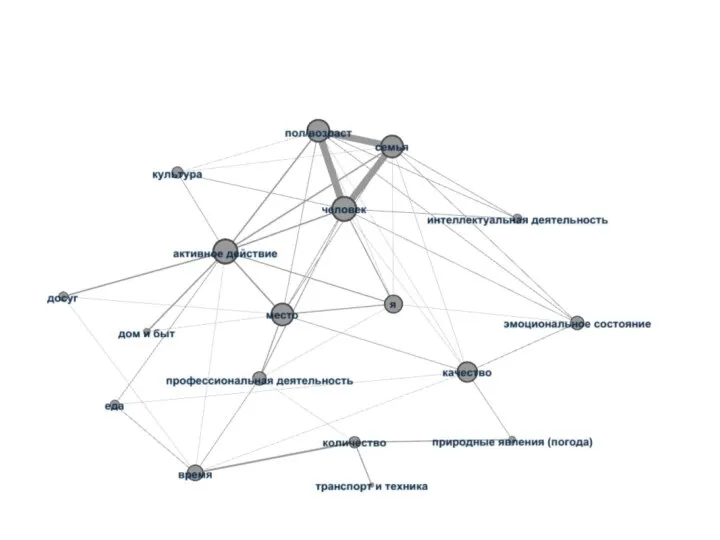
- 13. Графосемантическое моделирование «Графосемантическое моделирование представляет собой метод графической экспликации структурных связей между семантическими компонентами одного множества»
- 14. Алгоритм графосемантического моделирования 1) проведение компонентного анализа отобранного материала, т. е. выделение контекстов и компонентов из
- 15. Семантический анализ спонтанного монолога Контекст—синтагма (минимальное интонационное и синтаксическое целое); Компонент –знаменательное слово (исключаются дискурсивные слова,
- 16. Алгоритм анализа 1) Построение семантической классификации компонентов (один компонент может относиться к разным группам; например, слово
- 17. Состав микротемы «я» Местоимение я и его формы (мне, меня, мной и др.), местоимение мы и
- 20. Графосемантическое моделирование
- 22. Относительный объём микротем в текстах мужчин и женщин
- 23. Модель семантической структуры текстов мужчин
- 24. Модель семантической структуры текстов женщин
- 25. Относительный объём микротем в текстах информантов с высшим и средним образованием
- 27. Скачать презентацию
Слайд 2Основные области применения количественных методов
Корпусная лингвистика
Сравнительно-историческое языкознание
Социолингвистика
Дискурс-анализ
Стилистика (анализ лексики как
Основные области применения количественных методов
Корпусная лингвистика
Сравнительно-историческое языкознание
Социолингвистика
Дискурс-анализ
Стилистика (анализ лексики как

Слайд 3Контент-анализ как количественный метод анализа текстов
Сущность контент-анализа заключается в том, чтобы по
Контент-анализ как количественный метод анализа текстов
Сущность контент-анализа заключается в том, чтобы по

Слайд 4Контент-анализ как количественный метод анализа текстов
Важнейшей категорией контент-анализа является концептуальная переменная —
Контент-анализ как количественный метод анализа текстов
Важнейшей категорией контент-анализа является концептуальная переменная —

Слайд 5Этапы подготовки и проведения исследования
выбор материала—корпуса языковых данных;
выбор концептуальной переменной и
Этапы подготовки и проведения исследования
выбор материала—корпуса языковых данных;
выбор концептуальной переменной и

Слайд 6Этапы подготовки и проведения исследования
4) отбор кодировщиков (выбор программ) и формулировка инструкций
Этапы подготовки и проведения исследования
4) отбор кодировщиков (выбор программ) и формулировка инструкций

Слайд 7Проблема семантической достоверности
Необходимо учитывать многозначность языковых выражений, являющихся значениями К-переменной.
После этого тихо
Проблема семантической достоверности
Необходимо учитывать многозначность языковых выражений, являющихся значениями К-переменной.
После этого тихо

Слайд 8Исследование политических метафор с помощью контент-анализа
X. де Ландшер на материале голландского
Исследование политических метафор с помощью контент-анализа
X. де Ландшер на материале голландского

Слайд 9Степень метафоричности дискурса
Степень метафоричности для разных метафор может различаться, для общей оценки
Степень метафоричности дискурса
Степень метафоричности для разных метафор может различаться, для общей оценки

Слайд 10Тип метафорической модели
Сила воздействия метафоры связана не только с новизной или общепринятостью,
Тип метафорической модели
Сила воздействия метафоры связана не только с новизной или общепринятостью,

Слайд 11Результаты исследования
Результаты кодирования и вычисленные переменные интенсивности и содержания были сопоставлены с
Результаты исследования
Результаты кодирования и вычисленные переменные интенсивности и содержания были сопоставлены с

Слайд 12Семантический анализ текста
Семантическая структура устного спонтанного текста: социолингвистическое варьирование (Павлова Д.С., Ерофеева
Семантический анализ текста
Семантическая структура устного спонтанного текста: социолингвистическое варьирование (Павлова Д.С., Ерофеева

Слайд 13Графосемантическое моделирование
«Графосемантическое моделирование представляет собой метод графической экспликации структурных связей между семантическими
Графосемантическое моделирование
«Графосемантическое моделирование представляет собой метод графической экспликации структурных связей между семантическими

Слайд 14Алгоритм графосемантического моделирования
1) проведение компонентного анализа отобранного материала, т. е. выделение контекстов
Алгоритм графосемантического моделирования
1) проведение компонентного анализа отобранного материала, т. е. выделение контекстов

Слайд 15Семантический анализ
спонтанного монолога
Контекст—синтагма (минимальное интонационное и синтаксическое целое);
Компонент –знаменательное слово (исключаются
Семантический анализ
спонтанного монолога
Контекст—синтагма (минимальное интонационное и синтаксическое целое);
Компонент –знаменательное слово (исключаются

Слайд 16Алгоритм анализа
1) Построение семантической классификации компонентов (один компонент может относиться к разным
Алгоритм анализа
1) Построение семантической классификации компонентов (один компонент может относиться к разным

Слайд 17Состав микротемы «я»
Местоимение я и его формы (мне, меня, мной и др.),
Состав микротемы «я»
Местоимение я и его формы (мне, меня, мной и др.),

Слайд 20Графосемантическое моделирование
Графосемантическое моделирование
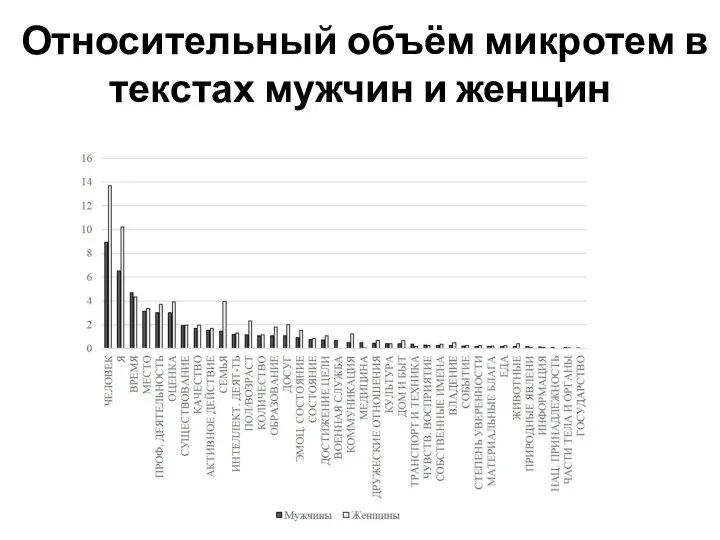
Слайд 22Относительный объём микротем в текстах мужчин и женщин
Относительный объём микротем в текстах мужчин и женщин
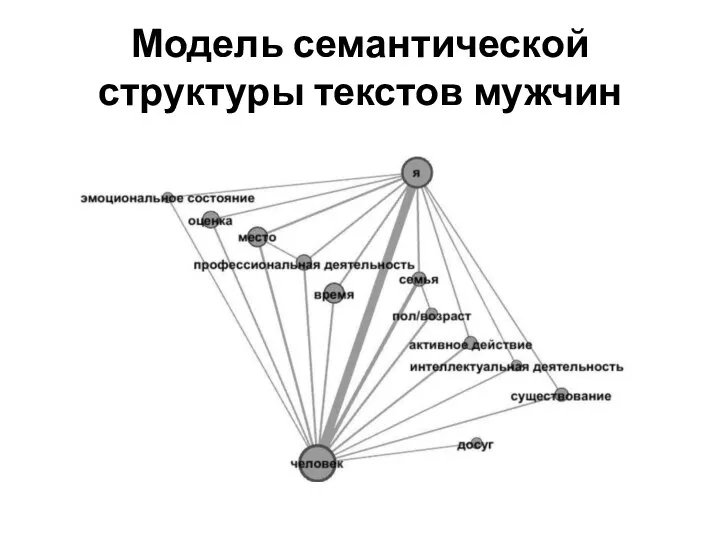
Слайд 23Модель семантической структуры текстов мужчин
Модель семантической структуры текстов мужчин
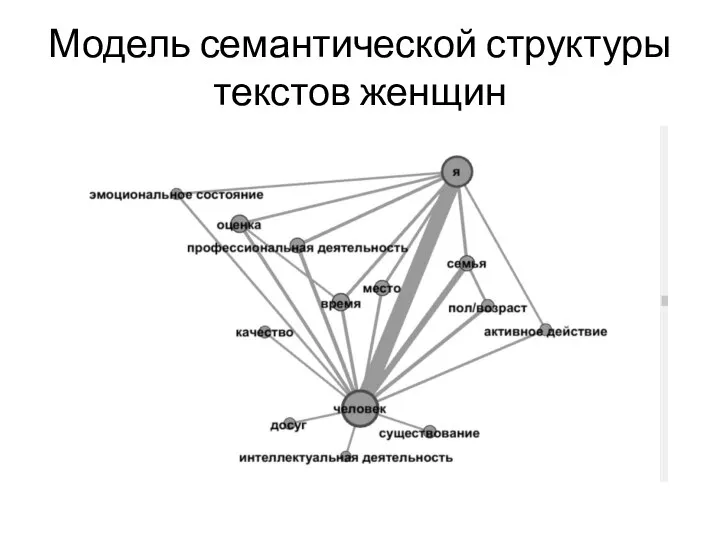
Слайд 24Модель семантической структуры текстов женщин
Модель семантической структуры текстов женщин
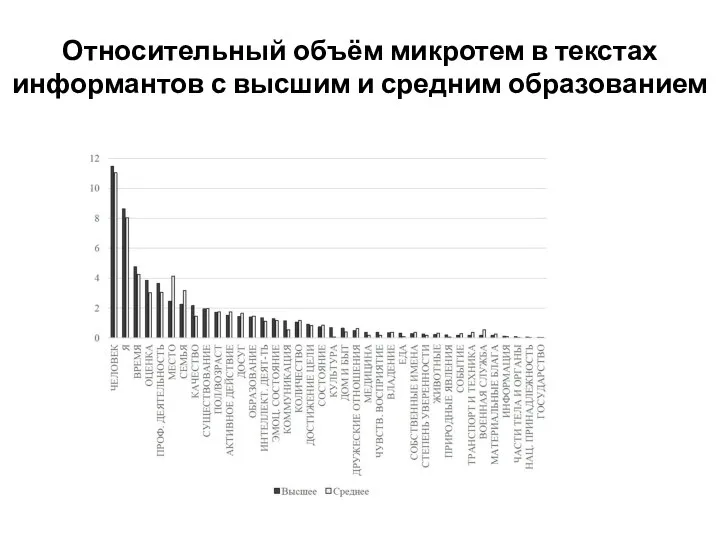
Слайд 25Относительный объём микротем в текстах информантов с высшим и средним образованием
Относительный объём микротем в текстах информантов с высшим и средним образованием
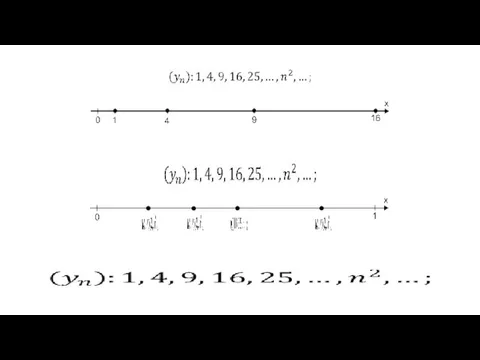 Пояснения к определению предела последовательности
Пояснения к определению предела последовательности Вычисление площадей с помощью интегралов
Вычисление площадей с помощью интегралов тригонометрические неравенства (1)
тригонометрические неравенства (1) Функция и график
Функция и график Методы оценки показателей качества результатов анализа в лаборатории, по приложению Б, РМГ 76-2014
Методы оценки показателей качества результатов анализа в лаборатории, по приложению Б, РМГ 76-2014 Сложение и вычитание смешанных чисел
Сложение и вычитание смешанных чисел Сумма углов треугольника
Сумма углов треугольника Степенная функция
Степенная функция attachment_642692504
attachment_642692504 Измерение объема жидких и сыпучих веществ с помощью условной меры масс
Измерение объема жидких и сыпучих веществ с помощью условной меры масс Операции с числовыми множествами. Формулы сокращённого умножения
Операции с числовыми множествами. Формулы сокращённого умножения МХСИ
МХСИ Выбор средств измерения для технологического процесса
Выбор средств измерения для технологического процесса Сложение и вычитание многочленов
Сложение и вычитание многочленов Презентация на тему Математика - царица наук
Презентация на тему Математика - царица наук  15 задание. Виды. Делимость. Числовая последовательность. Конъюнкция. Множества
15 задание. Виды. Делимость. Числовая последовательность. Конъюнкция. Множества Разбор Мат.Вертикали. 6 класс
Разбор Мат.Вертикали. 6 класс Классическое определение вероятности
Классическое определение вероятности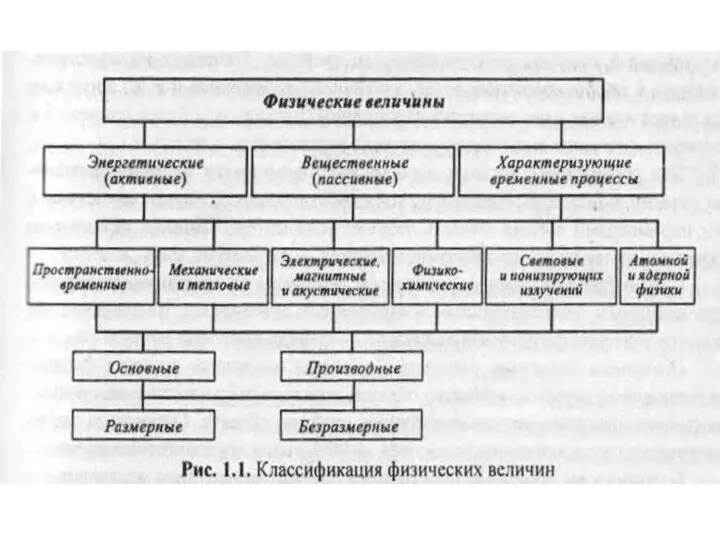 Физические величины
Физические величины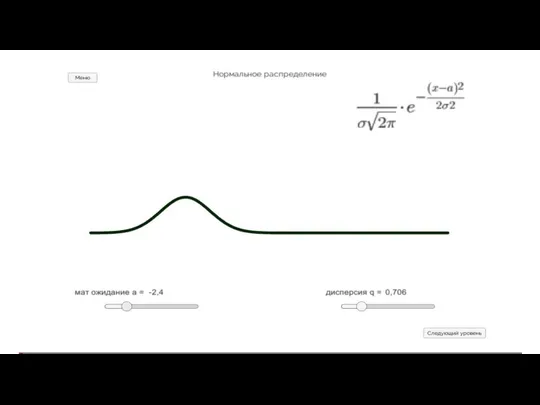 Критерий Пирсона
Критерий Пирсона Взятие Измаила в математических и исторических нюансах
Взятие Измаила в математических и исторических нюансах Презентация на тему Задачи на движение для учителя
Презентация на тему Задачи на движение для учителя  Масштаб задачи
Масштаб задачи Темір жолдың жылжымалы құрамын пайдалану, жөндеу және техникалық қызмет көрсету (түрлері бойынша)
Темір жолдың жылжымалы құрамын пайдалану, жөндеу және техникалық қызмет көрсету (түрлері бойынша) Назовите углы
Назовите углы Координатная плоскость. Построение точки по ее координатам. 6 класс
Координатная плоскость. Построение точки по ее координатам. 6 класс Двоичная арифметика
Двоичная арифметика О сохранении и нарушении равносильности при решении уравнений и неравенств
О сохранении и нарушении равносильности при решении уравнений и неравенств