Лекция №10 Информационное обеспечение ИС Моделирование данных. Метод IDEFI. Отображение модели данных в инструментальном средств
- Лекция №10 Информационное обеспечение ИС Моделирование данных. Метод IDEFI. Отображение модели данных в инструментальном средств

Содержание
- 2. Моделирование данных Одной из основных частей информационного обеспечения является информационная база. Информационная база (ИБ) представляет собой
- 3. Базовые понятия ERD Сущность (Entity) — множество экземпляров реальных или абстрактных объектов, обладающих общими атрибутами или
- 4. Метод IDEFI Наиболее распространенными методами для построения ERD-диаграмм являются метод Баркера и метод IDEFI: Метод Баркера
- 5. Метод IDEFI В методе IDEFIX сущность является независимой от идентификаторов или просто независимой, если каждый экземпляр
- 6. Метод IDEFI Каждой сущности присваиваются уникальные имя и номер, разделяемые косой чертой "/" и помещаемые над
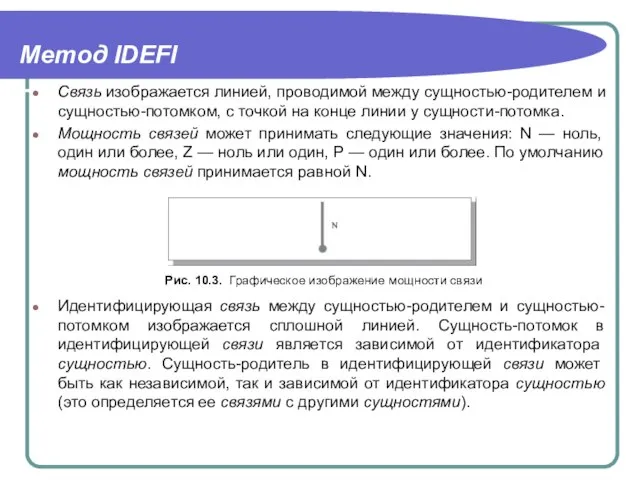
- 7. Метод IDEFI Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком, с точкой на конце линии у
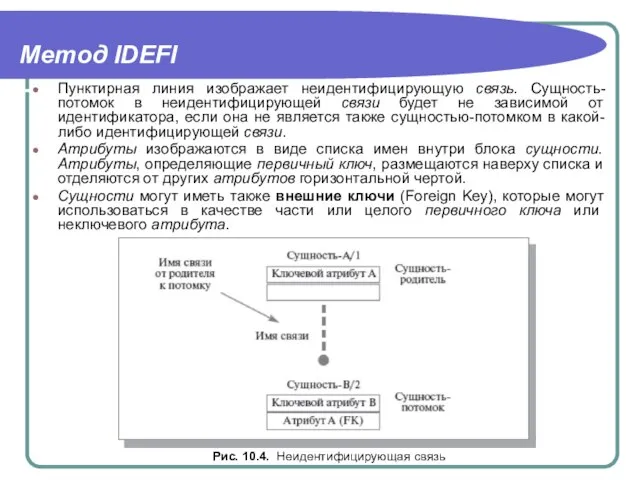
- 8. Метод IDEFI Пунктирная линия изображает неидентифицирующую связь. Сущность-потомок в неидентифицирующей связи будет не зависимой от идентификатора,
- 9. Отображение модели данных в инструментальном средстве ERwin ERwin имеет два уровня представления модели — логический и
- 10. Документирование модели Многие СУБД имеют ограничение на именование объектов (например, ограничение на длину имени таблицы или
- 11. Масштабирование Создание модели данных, как правило, начинается с разработки логической модели. После описания логической модели проектировщик
- 12. Для переключения между логической и физической моделью данных служит список выбора в центральной части панели инструментов
- 13. Интерфейс ERwin. Уровни отображения модели На логическом уровне палитра инструментов имеет следующие кнопки: кнопку указателя (режим
- 14. Уровни логической модели Различают три уровня логической модели, отличающихся по глубине представления информации о данных: диаграмма
- 15. Сущности и атрибуты Основные компоненты диаграммы ERwin — это сущности, атрибуты и связи. Каждая сущность является
- 16. Связи Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой. Имя
- 17. Типы сущностей и иерархия наследования Характеристическая — зависимая дочерняя сущность, которая связана только с одной родительской
- 18. Типы сущностей и иерархия наследования Иерархия наследования представляет собой особый тип объединения сущностей, которые разделяют общие
- 19. Типы сущностей и иерархия наследования Рис. 10.9. Иерархия наследования. Полная категория Иерархии категорий делятся на два
- 20. Ключи Первичный ключ (primary key) — это атрибут или группа атрибутов, однозначно идентифицирующая экземпляр сущности. атрибуты
- 21. Нормализация данных Нормализация данных — процесс проверки и реорганизации сущностей и атрибутов с целью удовлетворения требований
- 22. Домены Домен можно определить как совокупность значений, из которых берутся значения атрибутов. Каждый атрибут может быть
- 23. Создание физической модели данных Физическая модель содержит всю информацию, необходимую для реализации конкретной БД. Различают два
- 24. Правила валидации и значения по умолчанию ERwin поддерживает правила валидации для колонок, а также значение, присваиваемое
- 25. Индексы В БД данные обычно хранятся в том порядке, в котором их ввели в таблицу. Многие
- 26. Триггеры и хранимые процедуры Триггеры и хранимые процедуры – это именованные блоки кода SQL, которые заранее
- 27. Проектирование хранилищ данных В хранилища данных помещают данные, которые редко меняются. Хранилища ориентированы на выполнение аналитических
- 28. Прямое и обратное проектирование Прямым проектированием называется процесс генерации физической схемы БД из логической модели. При
- 30. Скачать презентацию
Слайд 2Моделирование данных
Одной из основных частей информационного обеспечения является информационная база.
Информационная база (ИБ)
Моделирование данных
Одной из основных частей информационного обеспечения является информационная база.
Информационная база (ИБ)

Слайд 3Базовые понятия ERD
Сущность (Entity) — множество экземпляров реальных или абстрактных объектов, обладающих
Базовые понятия ERD
Сущность (Entity) — множество экземпляров реальных или абстрактных объектов, обладающих

Слайд 4Метод IDEFI
Наиболее распространенными методами для построения ERD-диаграмм являются метод Баркера и метод
Метод IDEFI
Наиболее распространенными методами для построения ERD-диаграмм являются метод Баркера и метод

Слайд 5Метод IDEFI
В методе IDEFIX сущность является независимой от идентификаторов или просто независимой,
Метод IDEFI
В методе IDEFIX сущность является независимой от идентификаторов или просто независимой,

Слайд 6Метод IDEFI
Каждой сущности присваиваются уникальные имя и номер, разделяемые косой чертой "/"
Метод IDEFI
Каждой сущности присваиваются уникальные имя и номер, разделяемые косой чертой "/"

Слайд 7Метод IDEFI
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком, с точкой на
Метод IDEFI
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком, с точкой на
Слайд 8Метод IDEFI
Пунктирная линия изображает неидентифицирующую связь. Сущность-потомок в неидентифицирующей связи будет не
Метод IDEFI
Пунктирная линия изображает неидентифицирующую связь. Сущность-потомок в неидентифицирующей связи будет не
Слайд 9Отображение модели данных в инструментальном средстве ERwin
ERwin имеет два уровня представления модели
Отображение модели данных в инструментальном средстве ERwin
ERwin имеет два уровня представления модели

Слайд 10Документирование модели
Многие СУБД имеют ограничение на именование объектов (например, ограничение на длину
Документирование модели
Многие СУБД имеют ограничение на именование объектов (например, ограничение на длину

Слайд 11Масштабирование
Создание модели данных, как правило, начинается с разработки логической модели.
После описания
Масштабирование
Создание модели данных, как правило, начинается с разработки логической модели.
После описания

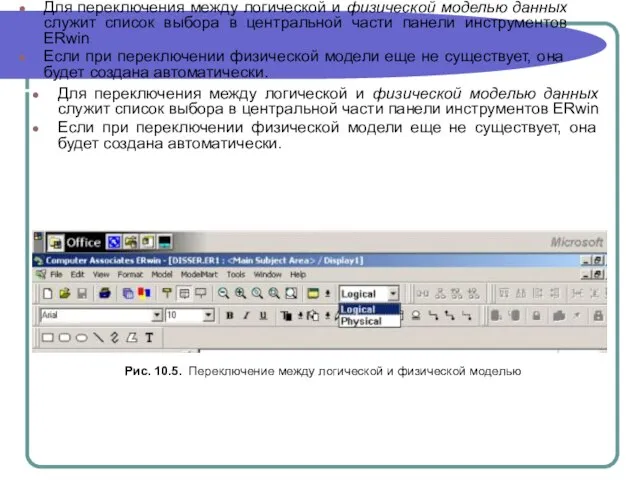
Слайд 12Для переключения между логической и физической моделью данных служит список выбора в
Для переключения между логической и физической моделью данных служит список выбора в
Слайд 13Интерфейс ERwin. Уровни отображения модели
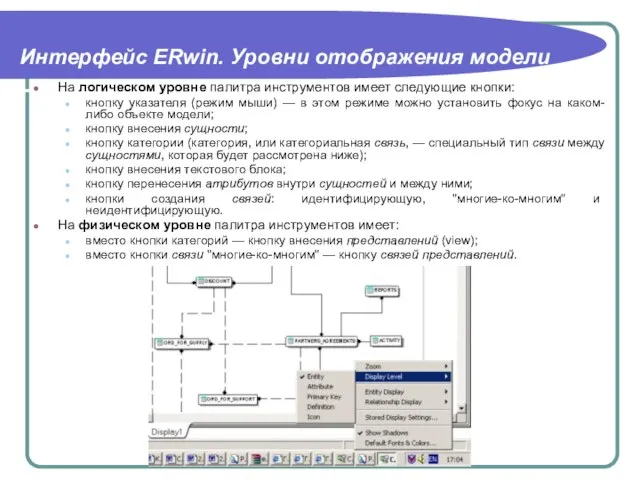
На логическом уровне палитра инструментов имеет следующие кнопки:
кнопку
Интерфейс ERwin. Уровни отображения модели
На логическом уровне палитра инструментов имеет следующие кнопки:
кнопку
Слайд 14Уровни логической модели
Различают три уровня логической модели, отличающихся по глубине представления информации
Уровни логической модели
Различают три уровня логической модели, отличающихся по глубине представления информации

Слайд 15Сущности и атрибуты
Основные компоненты диаграммы ERwin — это сущности, атрибуты и связи.
Сущности и атрибуты
Основные компоненты диаграммы ERwin — это сущности, атрибуты и связи.

Слайд 16Связи
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или
Связи
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или

Слайд 17Типы сущностей и иерархия наследования
Характеристическая — зависимая дочерняя сущность, которая связана только
Типы сущностей и иерархия наследования
Характеристическая — зависимая дочерняя сущность, которая связана только

Слайд 18Типы сущностей и иерархия наследования
Иерархия наследования представляет собой особый тип объединения сущностей,
Типы сущностей и иерархия наследования
Иерархия наследования представляет собой особый тип объединения сущностей,
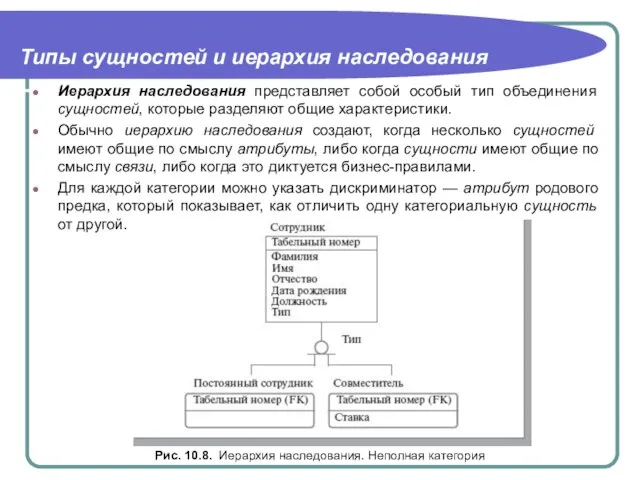
Слайд 19Типы сущностей и иерархия наследования
Рис. 10.9. Иерархия наследования. Полная категория
Иерархии категорий делятся
Типы сущностей и иерархия наследования
Рис. 10.9. Иерархия наследования. Полная категория
Иерархии категорий делятся

Слайд 20Ключи
Первичный ключ (primary key) — это атрибут или группа атрибутов, однозначно
Ключи
Первичный ключ (primary key) — это атрибут или группа атрибутов, однозначно

Слайд 21Нормализация данных
Нормализация данных — процесс проверки и реорганизации сущностей и атрибутов с
Нормализация данных
Нормализация данных — процесс проверки и реорганизации сущностей и атрибутов с

Слайд 22Домены
Домен можно определить как совокупность значений, из которых берутся значения атрибутов.
Каждый
Домены
Домен можно определить как совокупность значений, из которых берутся значения атрибутов.
Каждый

Слайд 23Создание физической модели данных
Физическая модель содержит всю информацию, необходимую для реализации конкретной
Создание физической модели данных
Физическая модель содержит всю информацию, необходимую для реализации конкретной

Слайд 24Правила валидации и значения по умолчанию
ERwin поддерживает правила валидации для колонок,
Правила валидации и значения по умолчанию
ERwin поддерживает правила валидации для колонок,

Слайд 25Индексы
В БД данные обычно хранятся в том порядке, в котором их ввели
Индексы
В БД данные обычно хранятся в том порядке, в котором их ввели

Слайд 26Триггеры и хранимые процедуры
Триггеры и хранимые процедуры – это именованные блоки кода
Триггеры и хранимые процедуры
Триггеры и хранимые процедуры – это именованные блоки кода

Слайд 27Проектирование хранилищ данных
В хранилища данных помещают данные, которые редко меняются. Хранилища ориентированы
Проектирование хранилищ данных
В хранилища данных помещают данные, которые редко меняются. Хранилища ориентированы

Слайд 28Прямое и обратное проектирование
Прямым проектированием называется процесс генерации физической схемы БД из
Прямое и обратное проектирование
Прямым проектированием называется процесс генерации физической схемы БД из

 Технологическое оборудование подготовки сырья
Технологическое оборудование подготовки сырья  Русский лес
Русский лес ГОТЫ И ЭМО – ДОРОГА В НИКУДА.
ГОТЫ И ЭМО – ДОРОГА В НИКУДА. СПИСОК ИСТОЧНИКОВ
СПИСОК ИСТОЧНИКОВ Май 2012
Май 2012 Основные компоненты содержания школьного образования по инфор-матике. Примерная программа курса информатики для 5-11классов.
Основные компоненты содержания школьного образования по инфор-матике. Примерная программа курса информатики для 5-11классов. Ответственность за преступления
Ответственность за преступления Групповой проект
Групповой проект Політична система суспільства та соціально-політичні механізми здійснення влади
Політична система суспільства та соціально-політичні механізми здійснення влади Гражданский бюджет города Сатпаев на 2012-2014 годы
Гражданский бюджет города Сатпаев на 2012-2014 годы Обеспечение доверия электронных государственных услуг на основе сервисов доверенной третьей стороны
Обеспечение доверия электронных государственных услуг на основе сервисов доверенной третьей стороны Математическая игра "Путешествие по станциям"
Математическая игра "Путешествие по станциям" Аттестация педагогических работников государственных и муниципальных образовательных учреждений с 1 января 2011г.
Аттестация педагогических работников государственных и муниципальных образовательных учреждений с 1 января 2011г. Ибн-Сина. Пути познания
Ибн-Сина. Пути познания Вышивание
Вышивание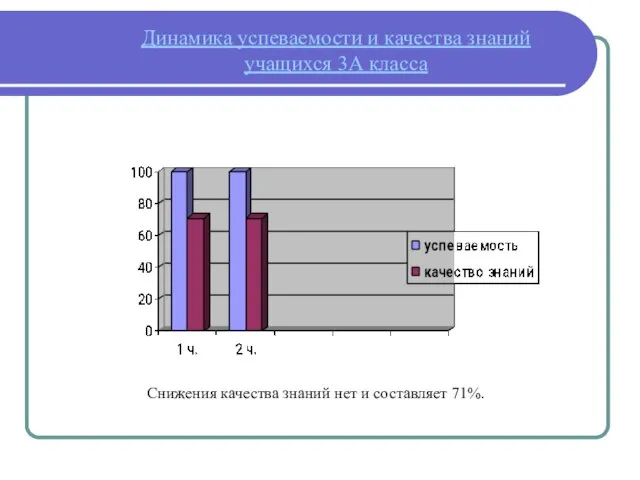 Динамика успеваемости и качества знаний учащихся
Динамика успеваемости и качества знаний учащихся Древний Киев (4 класс)
Древний Киев (4 класс) Программа обучения оператора участка измельчения руды. Теория процесса дробления руды
Программа обучения оператора участка измельчения руды. Теория процесса дробления руды Техническое оснащение кондитерского цеха
Техническое оснащение кондитерского цеха Спасибо за мир!
Спасибо за мир! Презентация на тему Награды Великой Отечественной войны
Презентация на тему Награды Великой Отечественной войны Стандартизация, основные понятия и определения
Стандартизация, основные понятия и определения Mariana Trench
Mariana Trench Николай Федорович Ватутин
Николай Федорович Ватутин заповедники россии
заповедники россии Презентация на тему Русская архитектура в XVII веке
Презентация на тему Русская архитектура в XVII веке  Рисование в нетрадиционной технике
Рисование в нетрадиционной технике A real professional. What does it mean?
A real professional. What does it mean?