- 2b8483313b22fe88

Содержание
- 2. Цели Разработка фреймворка для создания обученных моделей, способных на дообучение под игрока (саморазвитие в процессе игровой
- 3. Задачи Изучить варианты применения ml в игровой сфере (ml-agents) Изучить доступные библиотеки для работы с ML
- 4. Образ результата Фреймворк, который позволит внедрять агентов с саморазвитием в проекты на .NET без необходимости разбираться
- 5. Научная новизна Идея заключается в том, чтобы обучаемые объекты (агенты) могли продолжать свое развитие после внедрения
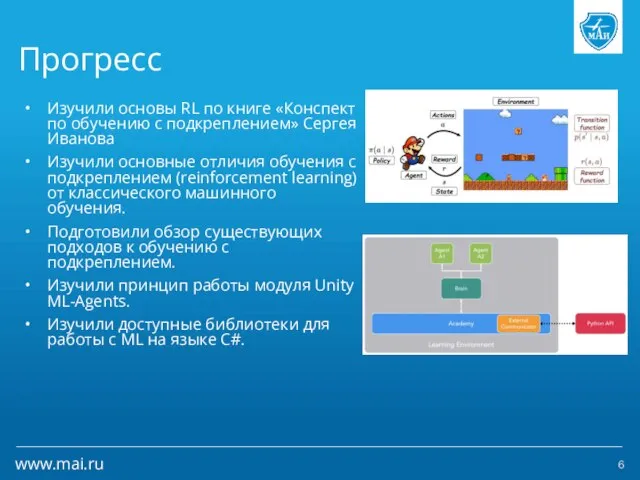
- 6. Прогресс Изучили основы RL по книге «Конспект по обучению с подкреплением» Сергея Иванова Изучили основные отличия
- 7. Титульник
- 9. Скачать презентацию
Слайд 2Цели
Разработка фреймворка для создания обученных моделей, способных на дообучение под игрока (саморазвитие
Цели
Разработка фреймворка для создания обученных моделей, способных на дообучение под игрока (саморазвитие

Слайд 3Задачи
Изучить варианты применения ml в игровой сфере (ml-agents)
Изучить доступные библиотеки для работы
Задачи
Изучить варианты применения ml в игровой сфере (ml-agents)
Изучить доступные библиотеки для работы

Слайд 4Образ результата
Фреймворк, который позволит внедрять агентов с саморазвитием в проекты на .NET
Образ результата
Фреймворк, который позволит внедрять агентов с саморазвитием в проекты на .NET

Слайд 5Научная новизна
Идея заключается в том, чтобы обучаемые объекты (агенты) могли продолжать свое
Научная новизна
Идея заключается в том, чтобы обучаемые объекты (агенты) могли продолжать свое

Слайд 6Прогресс
Изучили основы RL по книге «Конспект по обучению с подкреплением» Сергея Иванова
Изучили
Прогресс
Изучили основы RL по книге «Конспект по обучению с подкреплением» Сергея Иванова
Изучили
Слайд 7Титульник
Титульник

 1
1 The Phantom of the Opera
The Phantom of the Opera Methods of legal research: scientific method
Methods of legal research: scientific method  Педагогическая этика общения Воспитатель – ребёнок Консультация для воспитателей
Педагогическая этика общения Воспитатель – ребёнок Консультация для воспитателей Управление качеством в проекте
Управление качеством в проекте Общие требования к разработке бизнес-планов для получения государственного финансирования
Общие требования к разработке бизнес-планов для получения государственного финансирования Инертные газы
Инертные газы Б - Д
Б - Д Информмационные технрлогии в гостинечном бизнесе
Информмационные технрлогии в гостинечном бизнесе Карелия. Пояс – часть костюма
Карелия. Пояс – часть костюма Предлагаемый пофазный разъезд на перекрестке просп. Ленина - ул. Тухачевского
Предлагаемый пофазный разъезд на перекрестке просп. Ленина - ул. Тухачевского Трудовой договор
Трудовой договор ВОСПИТАТЕЛЬНАЯ ПРОГРАММА УЧРЕЖДЕНИЯ ОТДЫХА И ОЗДОРОВЛЕНИЯ ДЕТЕЙ
ВОСПИТАТЕЛЬНАЯ ПРОГРАММА УЧРЕЖДЕНИЯ ОТДЫХА И ОЗДОРОВЛЕНИЯ ДЕТЕЙ Понятие коммуникационного процесса. Модель коммуникации лассуэла
Понятие коммуникационного процесса. Модель коммуникации лассуэла Грейфер для сноса зданий
Грейфер для сноса зданий Презентация на тему Арарат
Презентация на тему Арарат Художественная культура Древнего Рима
Художественная культура Древнего Рима Шоколадная мастерская Оксаны Кочуровой
Шоколадная мастерская Оксаны Кочуровой Австралийский рогозуб
Австралийский рогозуб Тенденции развития сельской школы
Тенденции развития сельской школы Лабораторія інженерно-транспортних та технічних досліджень ДніпроНДІСЕ
Лабораторія інженерно-транспортних та технічних досліджень ДніпроНДІСЕ Кафе Линкор. Прайс
Кафе Линкор. Прайс Определение износа объекта недвижимости
Определение износа объекта недвижимости «…В отличие от любой иной революции, ядро трансформации, которую мы переживаем теперь, связано с технологиями обработки информаци
«…В отличие от любой иной революции, ядро трансформации, которую мы переживаем теперь, связано с технологиями обработки информаци Организационное стимулирование. Условия для внедрения мотивации персонала
Организационное стимулирование. Условия для внедрения мотивации персонала Презентация на тему Как отвечать на детские вопросы
Презентация на тему Как отвечать на детские вопросы Показ части фильма “Чемпионы 2”
Показ части фильма “Чемпионы 2” Моя малая родина частица огромной страны
Моя малая родина частица огромной страны