- Администрирование БД Системные и пользовательские БД SQL Server 2000

Содержание
- 2. Архитектура базы данных На физическом уровне каждая БД SQL Server 2000 хранится как минимум в двух
- 3. Архитектура БД SQL Server 2000 хранит информацию о расположении всех файлов БД в двух местах: в
- 4. Файлы БД Каждый файл данных имеет логическое имя, используемое при обработке операторов Transact-SQL и физическое имя,
- 5. Файлы БД Дополнительными свойствами файла являются идентификатор начальный размер, величина приращения при увеличении и максимальный размер.
- 6. Выделение пространства для таблиц и индексов Для обеспечения хранения информации необходимо выделить свободное место в файле
- 7. Выделение пространства для таблиц и индексов При создании новой таблицы или индекса SQL Server находит смешанный
- 8. Таблица Index Allocation Map При размещении страницы объекта в однородном или смешанном экстенте используется таблица IAM,
- 9. Хранение страниц индексов и страниц данных При отсутствии индекса SQL Server хранит данные на любой незаполненной
- 10. Кластерный индекс Для кластерного индекса сервер физически сортирует страницы в файле данных исходя из значений ключа
- 11. Некластерный индекс Уровень листьев (нижний уровень) некластерного индекса содержит указатель, с помощью которого SQL Server определяет,
- 12. Файлы журнала транзакций Каждая БД содержит хотя бы один файл журнала транзакций. Журнал транзакций хранит записи
- 13. Структура файла транзакций Файл журнала транзакций содержит последовательность записей. Каждая запись имеет порядковый номер в журнале
- 14. Принцип работы журнала транзакций SQL Server 2000 использует буферный кэш – хранящуюся в оперативной памяти структуру,
- 15. Процесс контрольной точки Процесс контрольной точки используется для оптимизации использования буферного кэша, уменьшения простоя в случае
- 16. Процесс контрольной точки Записи с номерами транзакций меньше minLSN не являются активными. Для уменьшения дискового пространства
- 17. Потоки операционной системы SQL Server использует рабочий поток и поток отложенной записи для периодического обращения к
- 18. Модели восстановления В SQL Server 2000 существует три модели восстановления: простая (Simple model) отдельных операций (Full
- 19. Модель восстановления отдельных операций Данная модель позволяет восстановить БД до того состояния, в котором она была
- 20. Модель восстановления результатов импорта При использовании данной модели регистрируются все операции, кроме широкомасштабных. Хранимой информации о
- 21. Простая модель При использовании простой модели восстановления в журнал транзакций записываются все операции, в том числе
- 22. Выбор модели восстановления С помощью MS SQL Server Enterprise Manager для выбранной БД можно установить режим
- 23. Системные таблицы SQL Server SQL Server использует системные таблицы для управления работой СУБД и связанными с
- 24. Системный каталог Системный каталог включает в себя системные таблицы, используемые СУБД для управления системой. Системный каталог
- 25. Таблицы системного каталога
- 26. Каталог базы данных Каталог базы данных состоит из системных таблиц, используемых для управления отдельной БД. В
- 27. Системные хранимые процедуры Системные хранимые процедуры – процедуры составленные из операторов T-SQL, поставляемые вместе с SQL
- 28. Использование системных хранимых процедур
- 29. Системные функции Системные функции – набор встроенных функций, позволяющих обращаться к системным таблицам при помощи операторов
- 31. Скачать презентацию

Слайд 3Архитектура БД
SQL Server 2000 хранит информацию о расположении всех файлов БД в
Архитектура БД
SQL Server 2000 хранит информацию о расположении всех файлов БД в

Слайд 4Файлы БД
Каждый файл данных имеет логическое имя, используемое при обработке операторов Transact-SQL
Файлы БД
Каждый файл данных имеет логическое имя, используемое при обработке операторов Transact-SQL

Слайд 5Файлы БД
Дополнительными свойствами файла являются идентификатор начальный размер, величина приращения при увеличении
Файлы БД
Дополнительными свойствами файла являются идентификатор начальный размер, величина приращения при увеличении

Слайд 6Выделение пространства для таблиц и индексов
Для обеспечения хранения информации необходимо выделить свободное
Выделение пространства для таблиц и индексов
Для обеспечения хранения информации необходимо выделить свободное

Слайд 7Выделение пространства для таблиц и индексов
При создании новой таблицы или индекса SQL
Выделение пространства для таблиц и индексов
При создании новой таблицы или индекса SQL

Слайд 8Таблица Index Allocation Map
При размещении страницы объекта в однородном или смешанном экстенте
Таблица Index Allocation Map
При размещении страницы объекта в однородном или смешанном экстенте

Слайд 9Хранение страниц индексов и страниц данных
При отсутствии индекса SQL Server хранит данные
Хранение страниц индексов и страниц данных
При отсутствии индекса SQL Server хранит данные

Слайд 10Кластерный индекс
Для кластерного индекса сервер физически сортирует страницы в файле данных исходя
Кластерный индекс
Для кластерного индекса сервер физически сортирует страницы в файле данных исходя

Слайд 11Некластерный индекс
Уровень листьев (нижний уровень) некластерного индекса содержит указатель, с помощью которого
Некластерный индекс
Уровень листьев (нижний уровень) некластерного индекса содержит указатель, с помощью которого

Слайд 12Файлы журнала транзакций
Каждая БД содержит хотя бы один файл журнала транзакций.
Журнал транзакций
Файлы журнала транзакций
Каждая БД содержит хотя бы один файл журнала транзакций.
Журнал транзакций

Слайд 13Структура файла транзакций
Файл журнала транзакций содержит последовательность записей.
Каждая запись имеет порядковый номер
Структура файла транзакций
Файл журнала транзакций содержит последовательность записей.
Каждая запись имеет порядковый номер

Слайд 14Принцип работы журнала транзакций
SQL Server 2000 использует буферный кэш – хранящуюся в
Принцип работы журнала транзакций
SQL Server 2000 использует буферный кэш – хранящуюся в

Слайд 15Процесс контрольной точки
Процесс контрольной точки используется для оптимизации использования буферного кэша, уменьшения
Процесс контрольной точки
Процесс контрольной точки используется для оптимизации использования буферного кэша, уменьшения

Слайд 16Процесс контрольной точки
Записи с номерами транзакций меньше minLSN не являются активными. Для
Процесс контрольной точки
Записи с номерами транзакций меньше minLSN не являются активными. Для

Слайд 17Потоки операционной системы
SQL Server использует рабочий поток и поток отложенной записи для
Потоки операционной системы
SQL Server использует рабочий поток и поток отложенной записи для

Слайд 18Модели восстановления
В SQL Server 2000 существует три модели восстановления:
простая (Simple model)
отдельных операций
Модели восстановления
В SQL Server 2000 существует три модели восстановления:
простая (Simple model)
отдельных операций

Слайд 19Модель восстановления отдельных операций
Данная модель позволяет восстановить БД до того состояния, в
Модель восстановления отдельных операций
Данная модель позволяет восстановить БД до того состояния, в

Слайд 20Модель восстановления результатов импорта
При использовании данной модели регистрируются все операции, кроме широкомасштабных.
Модель восстановления результатов импорта
При использовании данной модели регистрируются все операции, кроме широкомасштабных.

Слайд 21Простая модель
При использовании простой модели восстановления в журнал транзакций записываются все операции,
Простая модель
При использовании простой модели восстановления в журнал транзакций записываются все операции,

Слайд 22Выбор модели восстановления
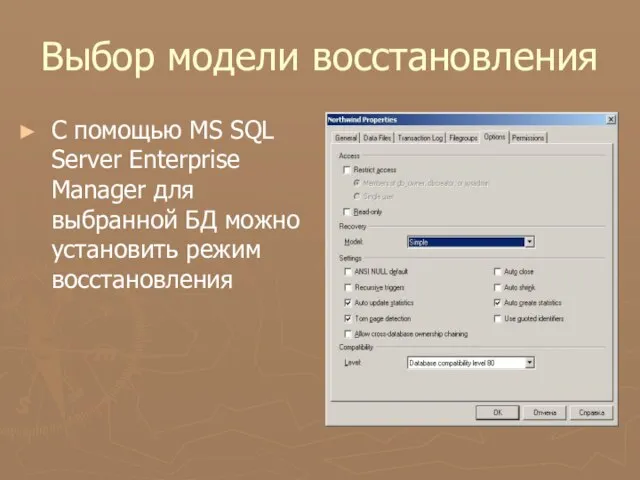
С помощью MS SQL Server Enterprise Manager для выбранной БД
Выбор модели восстановления
С помощью MS SQL Server Enterprise Manager для выбранной БД
Слайд 23Системные таблицы SQL Server
SQL Server использует системные таблицы для управления работой СУБД
Системные таблицы SQL Server
SQL Server использует системные таблицы для управления работой СУБД

Слайд 24Системный каталог
Системный каталог включает в себя системные таблицы, используемые СУБД для управления
Системный каталог
Системный каталог включает в себя системные таблицы, используемые СУБД для управления

Слайд 25Таблицы системного каталога
Таблицы системного каталога

Слайд 26Каталог базы данных
Каталог базы данных состоит из системных таблиц, используемых для управления
Каталог базы данных
Каталог базы данных состоит из системных таблиц, используемых для управления

Слайд 27Системные хранимые процедуры
Системные хранимые процедуры – процедуры составленные из операторов T-SQL, поставляемые
Системные хранимые процедуры
Системные хранимые процедуры – процедуры составленные из операторов T-SQL, поставляемые

Слайд 28Использование системных хранимых процедур
Использование системных хранимых процедур

Слайд 29Системные функции
Системные функции – набор встроенных функций, позволяющих обращаться к системным таблицам
Системные функции
Системные функции – набор встроенных функций, позволяющих обращаться к системным таблицам

 Презентация на тему Страхование ответственности
Презентация на тему Страхование ответственности  Помощь людям в период гражданской нестабильности. Иррегулярные подразделения
Помощь людям в период гражданской нестабильности. Иррегулярные подразделения Военная техника
Военная техника Группа компаний «МАГНОЛИЯ»
Группа компаний «МАГНОЛИЯ» Административное право
Административное право Презентация на тему Животные жарких стран
Презентация на тему Животные жарких стран  Генетически обусловленные нарушения кожных покровов у человека
Генетически обусловленные нарушения кожных покровов у человека Архитектура Коношского района
Архитектура Коношского района Тенденции развития здравоохранения в России Государство определяет развитие … В России зафиксирован естественный прирост насел
Тенденции развития здравоохранения в России Государство определяет развитие … В России зафиксирован естественный прирост насел Учебно-методический пакет Давайте,ребята,учиться считать!
Учебно-методический пакет Давайте,ребята,учиться считать! Внедрение систем управления рисками на предприятиях в основных секторах экономики как один из факторов стабильного вхождения РФ
Внедрение систем управления рисками на предприятиях в основных секторах экономики как один из факторов стабильного вхождения РФ  Innovations and perfomance managment
Innovations and perfomance managment  Правовые основы информатизации в здравоохранении и смежных с ним сфер деятельности
Правовые основы информатизации в здравоохранении и смежных с ним сфер деятельности интернет
интернет Два вида природных ресурсов
Два вида природных ресурсов Культура речи. Правильное употребление глаголов. Глагол в словосочетании и предложении.
Культура речи. Правильное употребление глаголов. Глагол в словосочетании и предложении. Наноэлектроника и миниатюризация
Наноэлектроника и миниатюризация Ф.С.Рокото. Портрет неизвестной в розовом платье
Ф.С.Рокото. Портрет неизвестной в розовом платье Презентация на тему День птиц
Презентация на тему День птиц Лекция 6
Лекция 6 Презентация на тему Организация работы по воспитанию навыков безопасного поведения у детей дошкольного возраста
Презентация на тему Организация работы по воспитанию навыков безопасного поведения у детей дошкольного возраста С любовью к родному городу
С любовью к родному городу Современные технологии организации школьного питания
Современные технологии организации школьного питания Презентация на тему Придаточные предложения
Презентация на тему Придаточные предложения «Решение задач части В»(В1, В4)
«Решение задач части В»(В1, В4) Map-Reduce и параллельные аналитические базы данных
Map-Reduce и параллельные аналитические базы данных Español rioplatense
Español rioplatense Сертификат. Чернышова Татьяна Васильевна
Сертификат. Чернышова Татьяна Васильевна