- Advanced Distributed

Содержание
- 2. Target Settings Process ‘group’-based systems Clouds/Datacenters Replicated servers Distributed databases Crash-stop/Fail-stop process failures
- 3. Group Membership Service Application Queries e.g., gossip, overlays, DHT’s, etc. Membership Protocol Group Membership List joins,
- 4. Two sub-protocols Application Process pi Group Membership List Unreliable Communication Almost-Complete list (focus of this talk)
- 5. Large Group: Scalability A Goal this is us (pi) 1000’s of processes Process Group “Members”
- 6. pj Group Membership Protocol Crash-stop Failures only
- 7. I. pj crashes Nothing we can do about it! A frequent occurrence Common case rather than
- 8. II. Distributed Failure Detectors: Desirable Properties Completeness = each failure is detected Accuracy = there is
- 9. Distributed Failure Detectors: Properties Completeness Accuracy Speed Time to first detection of a failure Scale Equal
- 10. What Real Failure Detectors Prefer Completeness Accuracy Speed Time to first detection of a failure Scale
- 11. Failure Detector Properties Completeness Accuracy Speed Time to first detection of a failure Scale Equal Load
- 12. Failure Detector Properties Completeness Accuracy Speed Time to first detection of a failure Scale Equal Load
- 13. Failure Detector Properties Completeness Accuracy Speed Time to first detection of a failure Scale Equal Load
- 14. Centralized Heartbeating … pi, Heartbeat Seq. l++ pi pj Heartbeats sent periodically If heartbeat not received
- 15. Ring Heartbeating pi, Heartbeat Seq. l++ pi … … pj
- 16. All-to-All Heartbeating pi, Heartbeat Seq. l++ … pi pj
- 17. Gossip-style Heartbeating Array of Heartbeat Seq. l for member subset pi
- 18. Gossip-Style Failure Detection 1 2 4 3 Protocol: Nodes periodically gossip their membership list On receipt,
- 19. Gossip-Style Failure Detection If the heartbeat has not increased for more than Tfail seconds, the member
- 20. Gossip-Style Failure Detection What if an entry pointing to a failed node is deleted right after
- 21. Multi-level Gossiping Network topology is hierarchical Random gossip target selection => core routers face O(N) load
- 22. Analysis/Discussion What happens if gossip period Tgossip is decreased? A single heartbeat takes O(log(N)) time to
- 23. Simulations As # members increases, the detection time increases As requirement is loosened, the detection time
- 24. Failure Detector Properties … Completeness Accuracy Speed Time to first detection of a failure Scale Equal
- 25. …Are application-defined Requirements Completeness Accuracy Speed Time to first detection of a failure Scale Equal Load
- 26. …Are application-defined Requirements Completeness Accuracy Speed Time to first detection of a failure Scale Equal Load
- 27. All-to-All Heartbeating pi, Heartbeat Seq. l++ … pi Every T units L=N/T
- 28. Gossip-style Heartbeating Array of Heartbeat Seq. l for member subset pi Every tg units =gossip period,
- 29. Worst case load L* as a function of T, PM(T), N Independent Message Loss probability pml
- 30. Heartbeating Optimal L is independent of N (!) All-to-all and gossip-based: sub-optimal L=O(N/T) try to achieve
- 31. SWIM Failure Detector Protocol pj
- 32. SWIM versus Heartbeating Process Load First Detection Time Constant Constant O(N) O(N) SWIM For Fixed :
- 33. SWIM Failure Detector
- 34. Accuracy, Load PM(T) is exponential in -K. Also depends on pml (and pf ) See paper
- 35. Prob. of being pinged in T’= E[T ] = Completeness: Any alive member detects failure Eventually
- 36. III. Dissemination HOW ?
- 37. Dissemination Options Multicast (Hardware / IP) unreliable multiple simultaneous multicasts Point-to-point (TCP / UDP) expensive Zero
- 38. Infection-style Dissemination pj K random processes
- 39. Infection-style Dissemination Epidemic style dissemination After protocol periods, processes would not have heard about an update
- 40. Suspicion Mechanism False detections, due to Perturbed processes Packet losses, e.g., from congestion Indirect pinging may
- 41. Suspicion Mechanism Alive Suspected Failed Dissmn (Suspect pj) Dissmn (Alive pj) Dissmn (Failed pj) pi ::
- 42. Suspicion Mechanism Distinguish multiple suspicions of a process Per-process incarnation number Inc # for pi can
- 43. Time-bounded Completeness Key: select each membership element once as a ping target in a traversal Round-robin
- 44. Results from an Implementation Current implementation Win2K, uses Winsock 2 Uses only UDP messaging 900 semicolons
- 45. Per-process Send and Receive Loads are independent of group size
- 46. Time to First Detection of a process failure T1 T1+T2+T3
- 47. T1 Time to First Detection of a process failure apparently uncorrelated to group size T1+T2+T3
- 48. Membership Update Dissemination Time is low at high group sizes T2 + T1+T2+T3
- 49. Excess time taken by Suspicion Mechanism T3 + T1+T2+T3
- 50. Benefit of Suspicion Mechanism: Per-process 10% synthetic packet loss
- 51. More discussion points It turns out that with a partial membership list that is uniformly random,
- 52. Reminder – Due this Sunday April 3rd at 11.59 PM Project Midterm Report due, 11.59 pm
- 54. Скачать презентацию
Слайд 2Target Settings
Process ‘group’-based systems
Clouds/Datacenters
Replicated servers
Distributed databases
Crash-stop/Fail-stop process failures
Target Settings
Process ‘group’-based systems
Clouds/Datacenters
Replicated servers
Distributed databases
Crash-stop/Fail-stop process failures

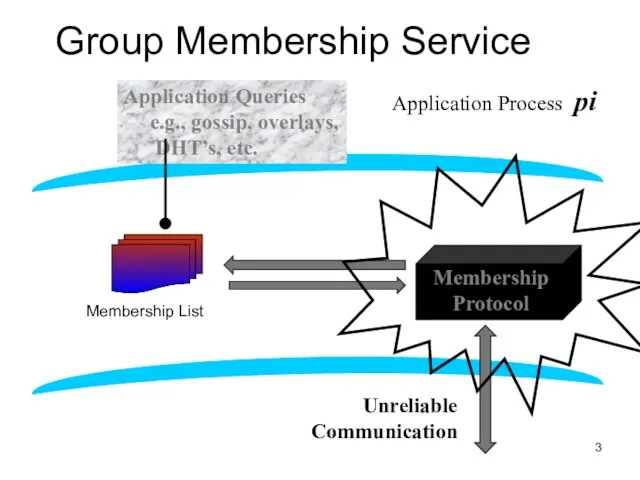
Слайд 3Group Membership Service
Application Queries
e.g., gossip, overlays, DHT’s, etc.
Membership
Protocol
Group
Membership List
joins,
Group Membership Service
Application Queries
e.g., gossip, overlays, DHT’s, etc.
Membership
Protocol
Group
Membership List
joins,
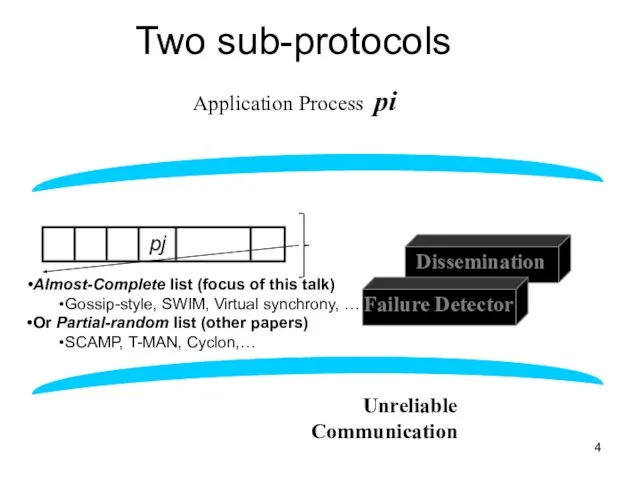
Слайд 4Two sub-protocols
Application Process pi
Group
Membership List
Unreliable
Communication
Almost-Complete list (focus of this talk)
Gossip-style,
Two sub-protocols
Application Process pi
Group
Membership List
Unreliable
Communication
Almost-Complete list (focus of this talk)
Gossip-style,
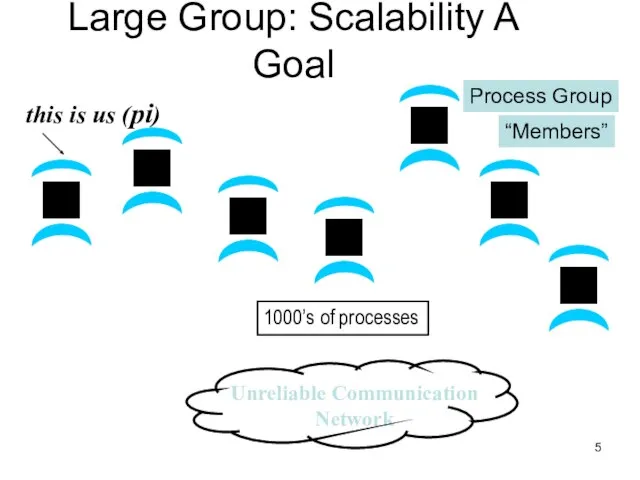
Слайд 5Large Group: Scalability A Goal
this is us (pi)
1000’s of processes
Process Group
“Members”
Large Group: Scalability A Goal
this is us (pi)
1000’s of processes
Process Group
“Members”
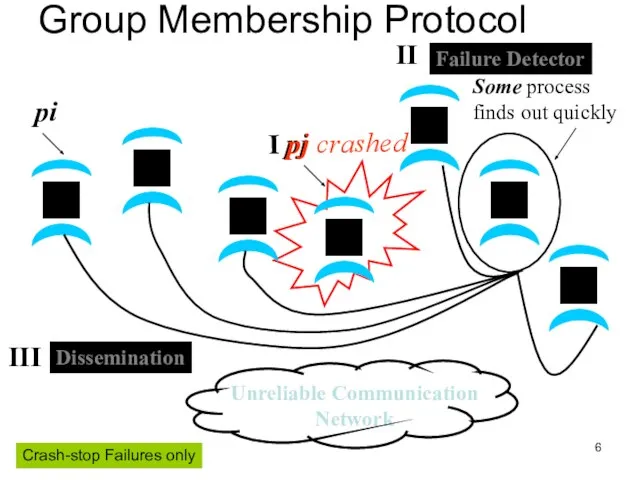
Слайд 6 pj
Group Membership Protocol
Crash-stop Failures only
pj
Group Membership Protocol
Crash-stop Failures only
Слайд 7I. pj crashes
Nothing we can do about it!
A frequent occurrence
Common
I. pj crashes
Nothing we can do about it!
A frequent occurrence
Common

Слайд 8II. Distributed Failure Detectors: Desirable Properties
Completeness = each failure is detected
Accuracy =
II. Distributed Failure Detectors: Desirable Properties
Completeness = each failure is detected
Accuracy =

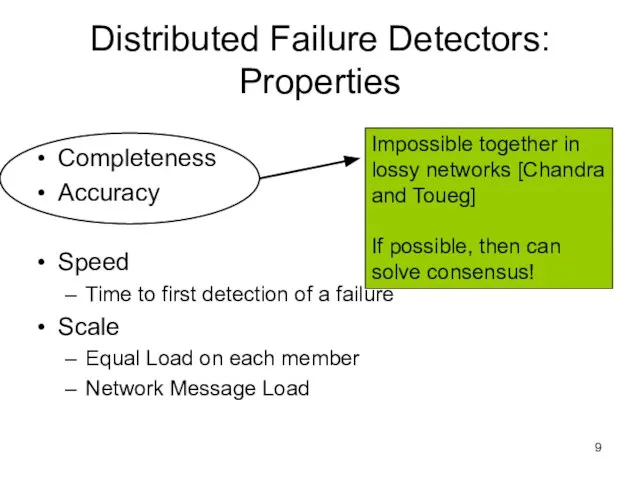
Слайд 9Distributed Failure Detectors: Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on
Distributed Failure Detectors: Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on
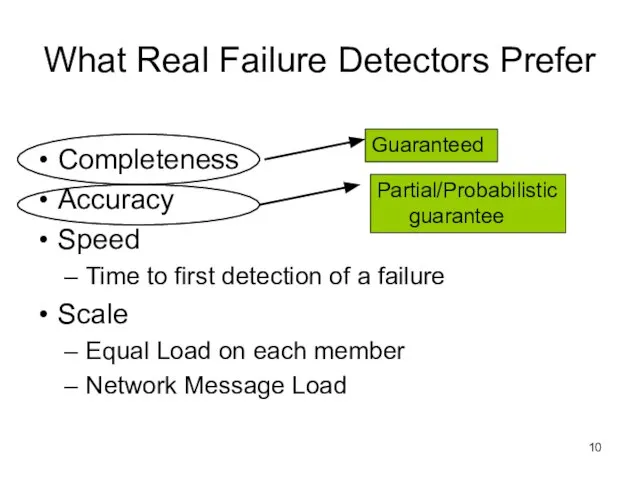
Слайд 10What Real Failure Detectors Prefer
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load
What Real Failure Detectors Prefer
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load
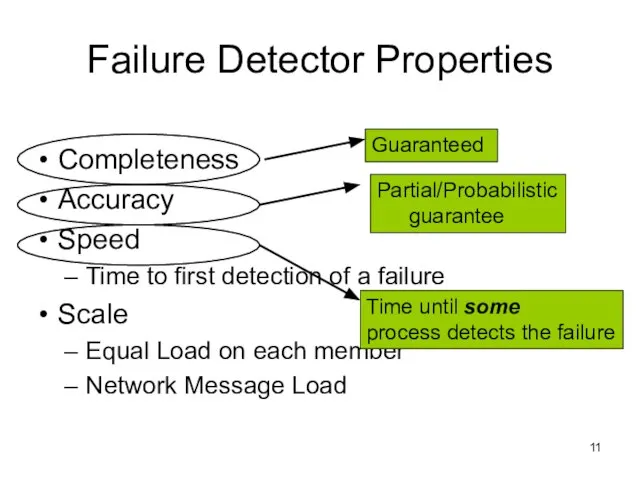
Слайд 11Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
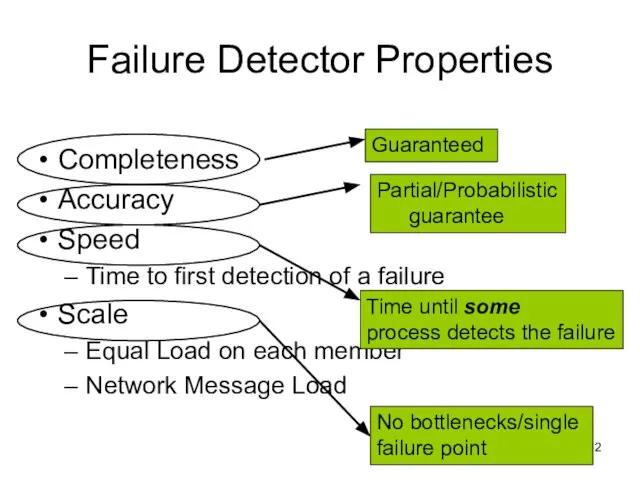
Слайд 12Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
Слайд 13Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
Failure Detector Properties
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
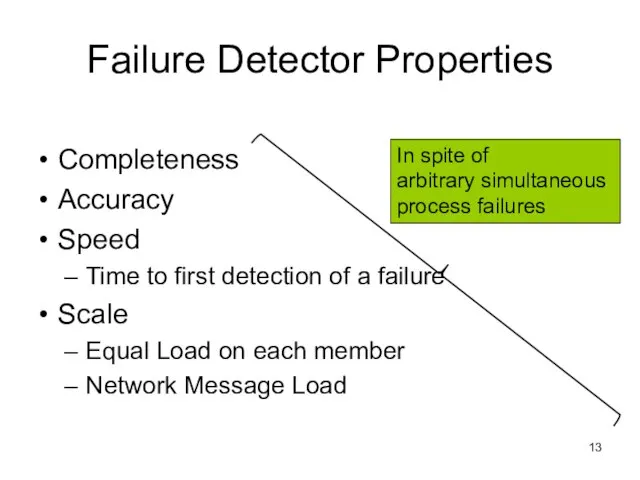
Слайд 14Centralized Heartbeating
…
pi, Heartbeat Seq. l++
pi
pj
Heartbeats sent periodically
If heartbeat not received from
Centralized Heartbeating
…
pi, Heartbeat Seq. l++
pi
pj
Heartbeats sent periodically
If heartbeat not received from
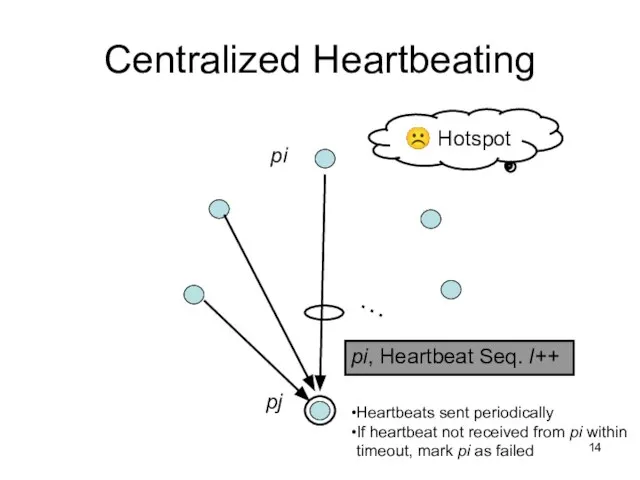
Слайд 15Ring Heartbeating
pi, Heartbeat Seq. l++
pi
…
…
pj
Ring Heartbeating
pi, Heartbeat Seq. l++
pi
…
…
pj
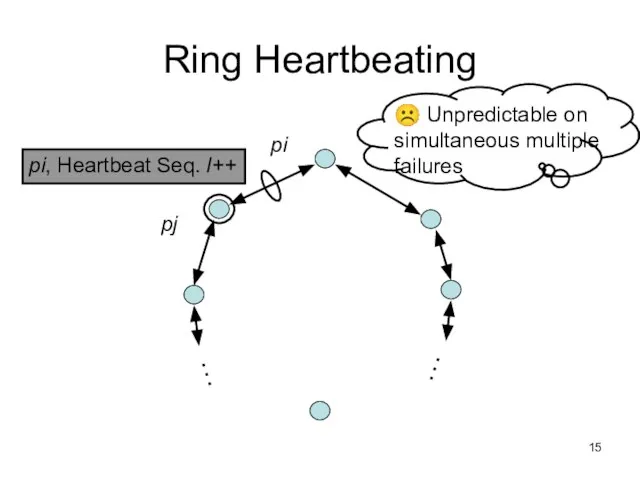
Слайд 16All-to-All Heartbeating
pi, Heartbeat Seq. l++
…
pi
pj
All-to-All Heartbeating
pi, Heartbeat Seq. l++
…
pi
pj
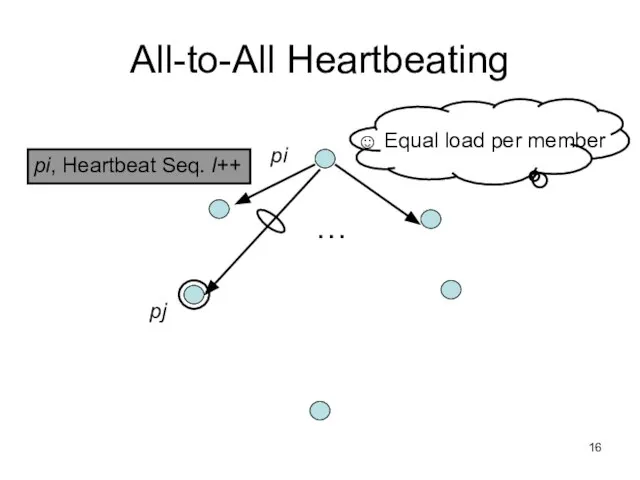
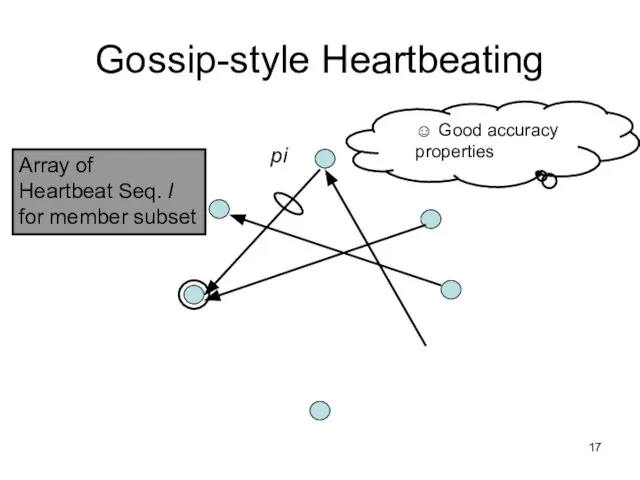
Слайд 17Gossip-style Heartbeating
Array of
Heartbeat Seq. l
for member subset
pi
Gossip-style Heartbeating
Array of
Heartbeat Seq. l
for member subset
pi
Слайд 18Gossip-Style Failure Detection
1
2
4
3
Protocol:
Nodes periodically gossip their membership list
On receipt, the local
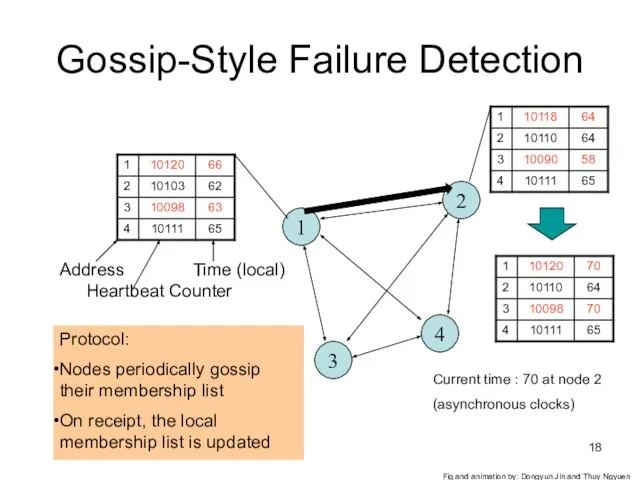
Gossip-Style Failure Detection
1
2
4
3
Protocol:
Nodes periodically gossip their membership list
On receipt, the local
Слайд 19Gossip-Style Failure Detection
If the heartbeat has not increased for more than Tfail
Gossip-Style Failure Detection
If the heartbeat has not increased for more than Tfail

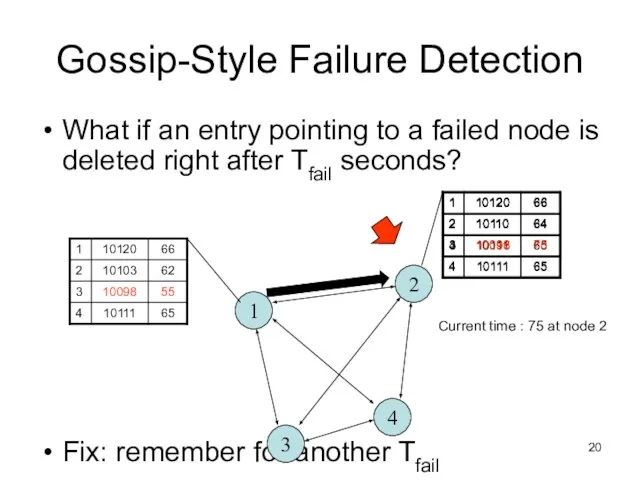
Слайд 20Gossip-Style Failure Detection
What if an entry pointing to a failed node is
Gossip-Style Failure Detection
What if an entry pointing to a failed node is
Слайд 21Multi-level Gossiping
Network topology is hierarchical
Random gossip target selection => core routers face
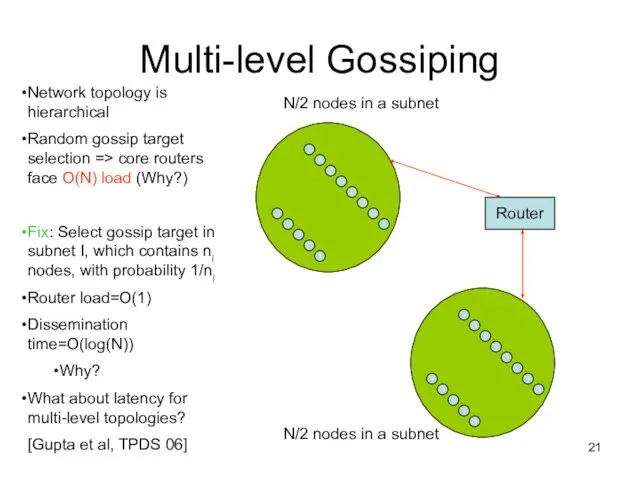
Multi-level Gossiping
Network topology is hierarchical
Random gossip target selection => core routers face
Слайд 22Analysis/Discussion
What happens if gossip period Tgossip is decreased?
A single heartbeat takes
Analysis/Discussion
What happens if gossip period Tgossip is decreased?
A single heartbeat takes

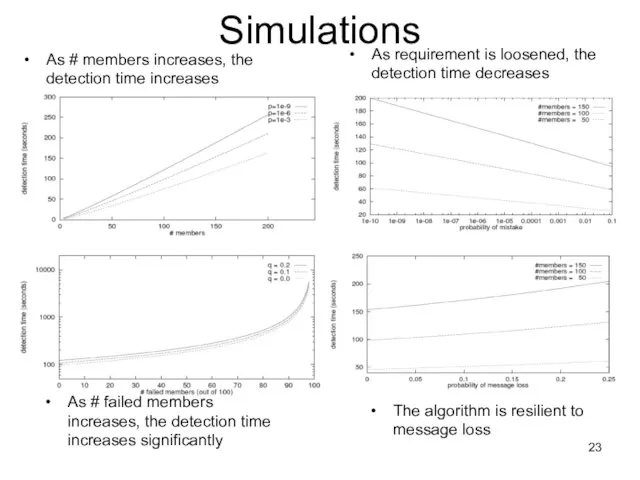
Слайд 23Simulations
As # members increases, the detection time increases
As requirement is loosened, the
Simulations
As # members increases, the detection time increases
As requirement is loosened, the
Слайд 24Failure Detector Properties …
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on
Failure Detector Properties …
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on

Слайд 25…Are application-defined Requirements
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
…Are application-defined Requirements
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
Слайд 26…Are application-defined Requirements
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
…Are application-defined Requirements
Completeness
Accuracy
Speed
Time to first detection of a failure
Scale
Equal Load on each
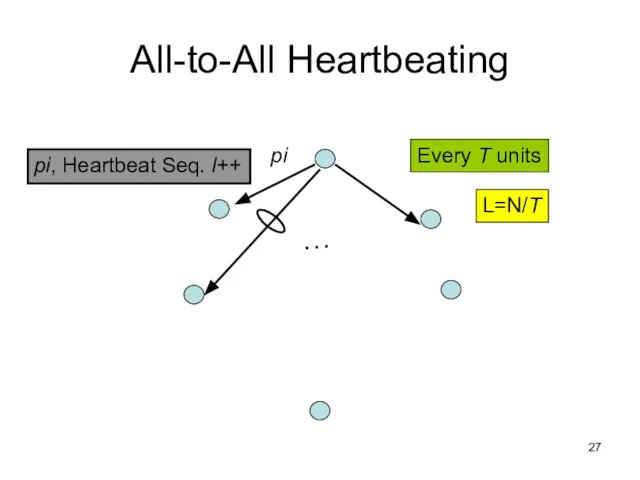
Слайд 27All-to-All Heartbeating
pi, Heartbeat Seq. l++
…
pi
Every T units
L=N/T
All-to-All Heartbeating
pi, Heartbeat Seq. l++
…
pi
Every T units
L=N/T
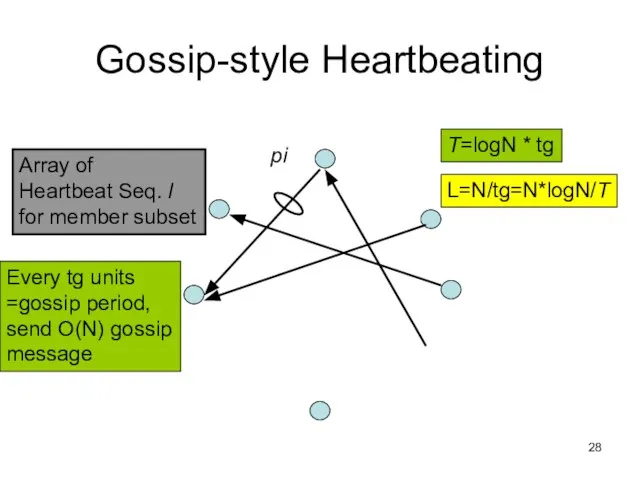
Слайд 28Gossip-style Heartbeating
Array of
Heartbeat Seq. l
for member subset
pi
Every tg units
=gossip period,
send O(N)
Gossip-style Heartbeating
Array of
Heartbeat Seq. l
for member subset
pi
Every tg units
=gossip period,
send O(N)
Слайд 29Worst case load L*
as a function of T, PM(T), N
Independent Message
as a function of T, PM(T), N
Independent Message

Слайд 30Heartbeating
Optimal L is independent of N (!)
All-to-all and gossip-based: sub-optimal
L=O(N/T)
try to achieve
Heartbeating
Optimal L is independent of N (!)
All-to-all and gossip-based: sub-optimal
L=O(N/T)
try to achieve

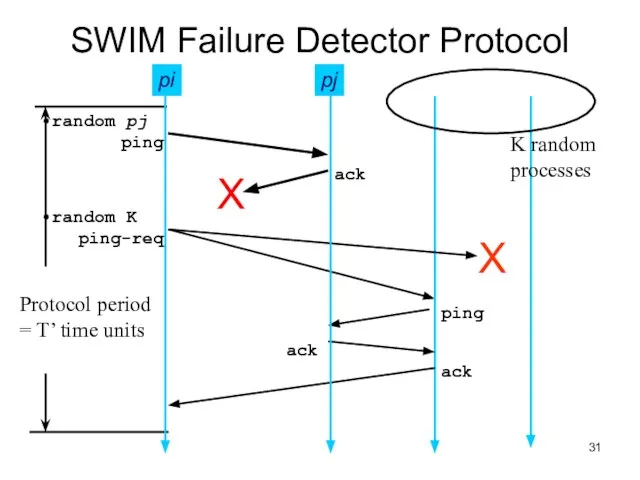
Слайд 31SWIM Failure Detector Protocol
pj
SWIM Failure Detector Protocol
pj
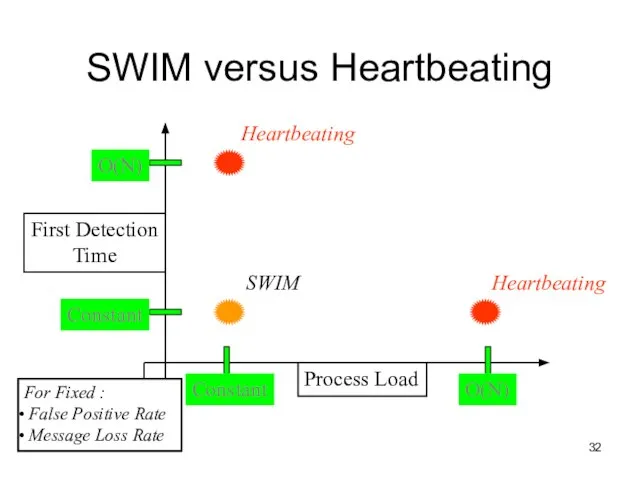
Слайд 32SWIM versus Heartbeating
Process Load
First Detection
Time
Constant
Constant
O(N)
O(N)
SWIM
For Fixed :
False Positive Rate
Message Loss
SWIM versus Heartbeating
Process Load
First Detection
Time
Constant
Constant
O(N)
O(N)
SWIM
For Fixed :
False Positive Rate
Message Loss
Слайд 33SWIM Failure Detector
SWIM Failure Detector

Слайд 34Accuracy, Load
PM(T) is exponential in -K. Also depends on pml (and pf
Accuracy, Load
PM(T) is exponential in -K. Also depends on pml (and pf

Слайд 35Prob. of being pinged in T’=
E[T ] =
Completeness: Any alive member
Prob. of being pinged in T’=
E[T ] =
Completeness: Any alive member
![Prob. of being pinged in T’= E[T ] = Completeness: Any alive](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/376450/slide-34.jpg)
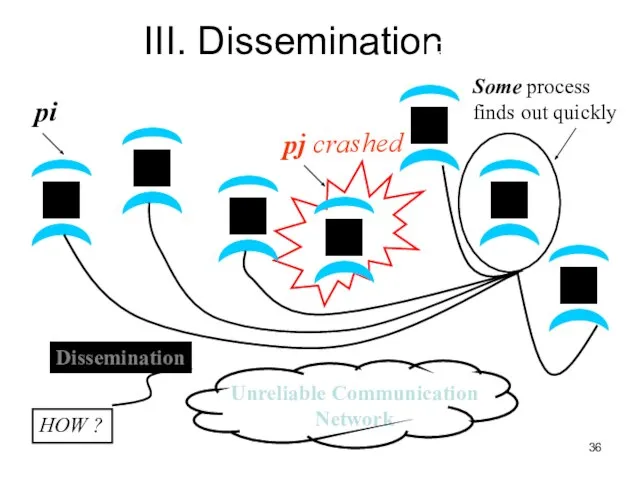
Слайд 36III. Dissemination
HOW ?
III. Dissemination
HOW ?
Слайд 37Dissemination Options
Multicast (Hardware / IP)
unreliable
multiple simultaneous multicasts
Point-to-point (TCP / UDP)
expensive
Zero extra
Dissemination Options
Multicast (Hardware / IP)
unreliable
multiple simultaneous multicasts
Point-to-point (TCP / UDP)
expensive
Zero extra

Слайд 38Infection-style Dissemination
pj
K random
processes
Infection-style Dissemination
pj
K random
processes
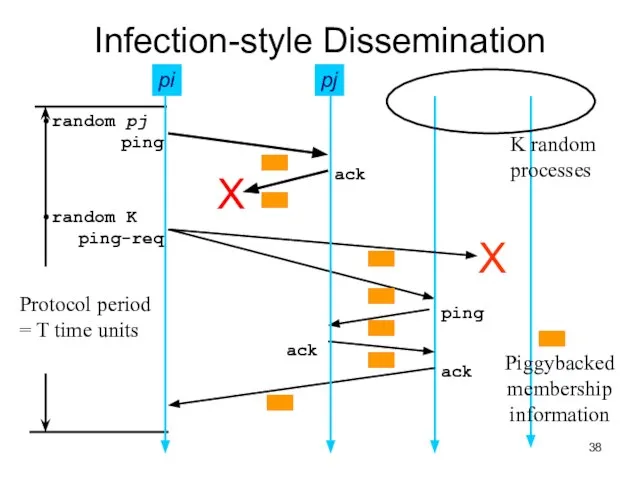
Слайд 39Infection-style Dissemination
Epidemic style dissemination
After protocol periods, processes would not have heard about
Infection-style Dissemination
Epidemic style dissemination
After protocol periods, processes would not have heard about

Слайд 40Suspicion Mechanism
False detections, due to
Perturbed processes
Packet losses, e.g., from congestion
Indirect pinging may
Suspicion Mechanism
False detections, due to
Perturbed processes
Packet losses, e.g., from congestion
Indirect pinging may

Слайд 41Suspicion Mechanism
Alive
Suspected
Failed
Dissmn (Suspect pj)
Dissmn (Alive pj)
Dissmn (Failed pj)
pi :: State Machine
Suspicion Mechanism
Alive
Suspected
Failed
Dissmn (Suspect pj)
Dissmn (Alive pj)
Dissmn (Failed pj)
pi :: State Machine
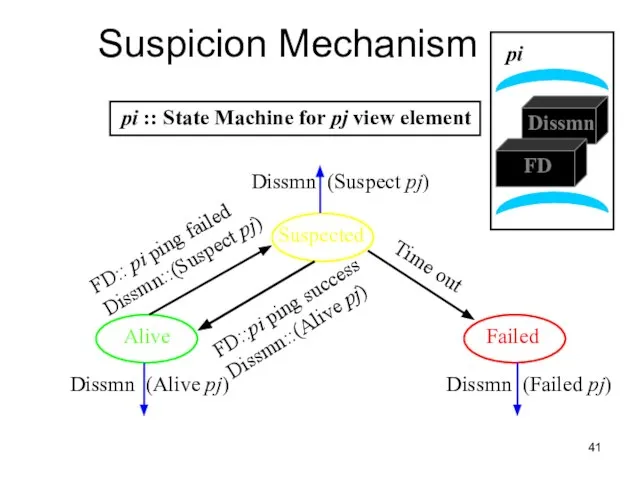
Слайд 42Suspicion Mechanism
Distinguish multiple suspicions of a process
Per-process incarnation number
Inc #
Suspicion Mechanism
Distinguish multiple suspicions of a process
Per-process incarnation number
Inc #

Слайд 43Time-bounded Completeness
Key: select each membership element once as a ping target in
Time-bounded Completeness
Key: select each membership element once as a ping target in

Слайд 44Results from an Implementation
Current implementation
Win2K, uses Winsock 2
Uses only UDP messaging
900 semicolons
Results from an Implementation
Current implementation
Win2K, uses Winsock 2
Uses only UDP messaging
900 semicolons

Слайд 45Per-process Send and Receive Loads
are independent of group size
Per-process Send and Receive Loads
are independent of group size
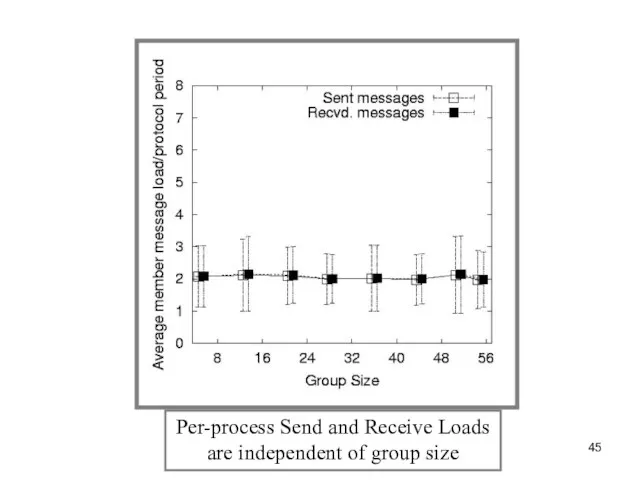
Слайд 46Time to First Detection of a process failure
T1
T1+T2+T3
Time to First Detection of a process failure
T1
T1+T2+T3
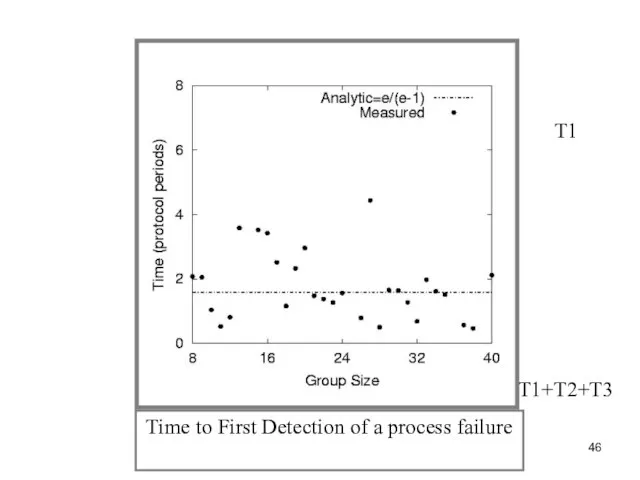
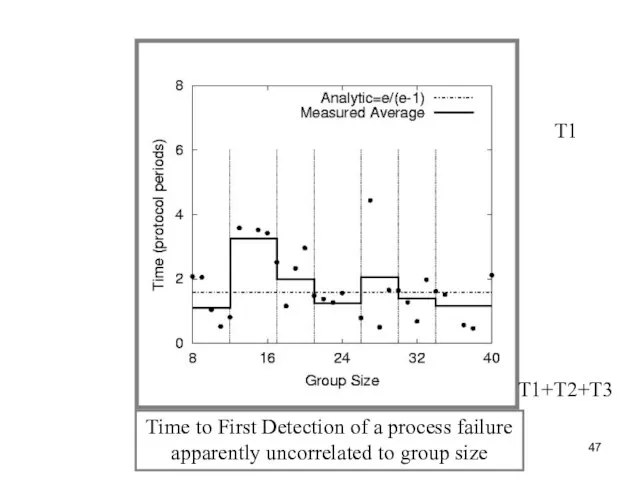
Слайд 47T1
Time to First Detection of a process failure
apparently uncorrelated to group
T1
Time to First Detection of a process failure
apparently uncorrelated to group
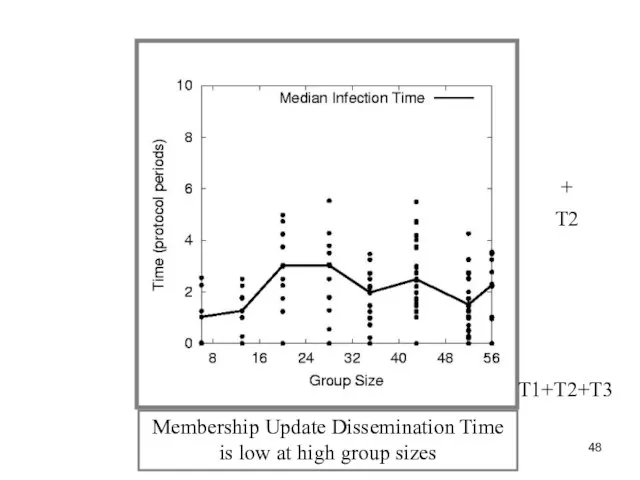
Слайд 48Membership Update Dissemination Time
is low at high group sizes
T2
+
T1+T2+T3
Membership Update Dissemination Time
is low at high group sizes
T2
+
T1+T2+T3
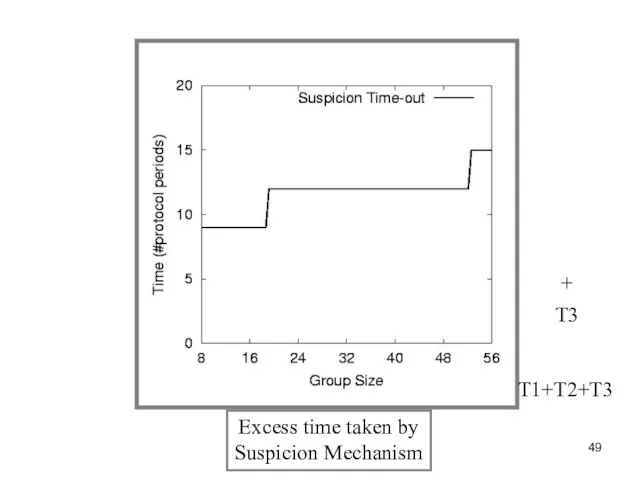
Слайд 49Excess time taken by
Suspicion Mechanism
T3
+
T1+T2+T3
Excess time taken by
Suspicion Mechanism
T3
+
T1+T2+T3
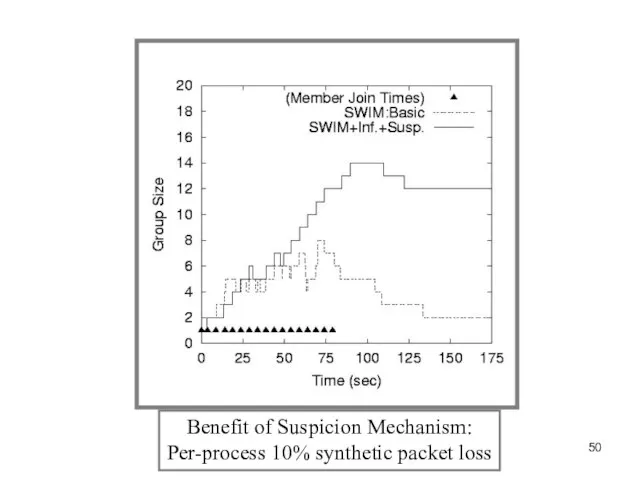
Слайд 50Benefit of Suspicion Mechanism:
Per-process 10% synthetic packet loss
Benefit of Suspicion Mechanism:
Per-process 10% synthetic packet loss
Слайд 51More discussion points
It turns out that with a partial membership list that
More discussion points
It turns out that with a partial membership list that

Слайд 52Reminder – Due this Sunday April 3rd at 11.59 PM
Project Midterm Report
Reminder – Due this Sunday April 3rd at 11.59 PM
Project Midterm Report

 Лепка
Лепка Природа в картинах русских художников
Природа в картинах русских художников Человек есть то, что он помнит.
Человек есть то, что он помнит. BearingPoint Компания моей мечты
BearingPoint Компания моей мечты Русскому языку можно учиться всю жизнь, да так до конца и не выучиться. Это стихия, и она, как любая стихия, необъятна... Существуют
Русскому языку можно учиться всю жизнь, да так до конца и не выучиться. Это стихия, и она, как любая стихия, необъятна... Существуют  Конвенция о правах инвалидов
Конвенция о правах инвалидов Обслуживание мультимедийных комплексов, установленных в аудиториях ПГУ
Обслуживание мультимедийных комплексов, установленных в аудиториях ПГУ Морские жители планеты Земля
Морские жители планеты Земля Состав правоотношения. Состав правоотношений
Состав правоотношения. Состав правоотношений Презентация
Презентация Австралийский Союз: специфика развития»
Австралийский Союз: специфика развития» http://bezpeka-service.com.ua/
http://bezpeka-service.com.ua/ Религия древних египтян
Религия древних египтян Анализ рынка: небольшие кафе-кондитерские
Анализ рынка: небольшие кафе-кондитерские Парки (продолженение)
Парки (продолженение) Лучше папы друга нет!
Лучше папы друга нет! Машиностроение Украины
Машиностроение Украины  Зарисовки фрагмента интерьера
Зарисовки фрагмента интерьера Транспортное хозяйство
Транспортное хозяйство Воинское воспитание как элемент подготовки кадета
Воинское воспитание как элемент подготовки кадета Практическая психология в учебно-воспитательном процессе
Практическая психология в учебно-воспитательном процессе Павидера ЕООД
Павидера ЕООД Строки Биографии ф. м. достоевского
Строки Биографии ф. м. достоевского Презентация на тему Рыба и морепродукты
Презентация на тему Рыба и морепродукты System Life Cycle Systems Development
System Life Cycle Systems Development СОВРЕМЕННЫЙ ОФИЦИАЛЬНЫЙ ПОРТАЛ ОРГАНОВ ГОСУДАРСТВЕННОЙ ВЛАСТИ СУБЪЕКТА РФ – УПРАВЛЕНЧЕСКИЕ ЗАДАЧИ И ТЕХНИЧЕСКИЕ АСПЕКТЫ РЕАЛИЗ
СОВРЕМЕННЫЙ ОФИЦИАЛЬНЫЙ ПОРТАЛ ОРГАНОВ ГОСУДАРСТВЕННОЙ ВЛАСТИ СУБЪЕКТА РФ – УПРАВЛЕНЧЕСКИЕ ЗАДАЧИ И ТЕХНИЧЕСКИЕ АСПЕКТЫ РЕАЛИЗ Религия как одна из форм культуры
Религия как одна из форм культуры