- Базы данных

Содержание
- 2. Основные темы лекций по курсу СУБД 1. Основные понятия баз данных. Этапы развития СУБД. Требования к
- 3. Темы лекций 1. Язык PL/SQL, его структура, основные операторы. 2. Курсоры, операторы работы с курсором, оператор
- 4. Литература Дейт К. Введение в системы баз данных. – 8 изд., Вильямс, 2005 Кузнецов С.Д. Базы
- 5. PL/SQL (Procedural Language) — процедурное расширение языка SQL PL/SQL - Procedural Language. Как видно из его
- 6. PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к конфигурированию языка 3GL. В
- 7. Модель клиент — сервер PL/SQL в среде клиент /сервер
- 8. Многие приложения для работы с базами данных создаются с использованием модели клиент /сервер. Сама программа размещается
- 9. Блок PL/SQL Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из блоков, которые могут
- 10. Допустимы следующие виды блоков: Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются только один раз
- 11. Лексические единицы Набор символов PL/SQL При работе с PL/SQL допускается использование символов из определенного набора знаков.
- 12. 2. Операторы сравнения 1. Арифметические операторы
- 13. Идентификаторы Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов следует руководствоваться следующими
- 14. Типы данных Тип Подтип NUMBER DECIMAL, REAL, FLOAT, NUMERIC (precision, scale) INTEGER, SMALLINT, CHAR (length) VARCHAR2
- 15. Записи PL/SQL Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно работать с несколькими
- 16. Чтобы присвоить одной записи значение другой они должны быть одного типа. Хотя записи имеют одинаковые имена
- 17. Управляющие структуры PL/SQL Структуры управления являются основой любого языка программирования, поскольку большинство реальных приложений должно уметь
- 18. Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации, когда требуется проверить выполнение
- 19. Пример DECLARE V_num1 NUMBER; V_num2 NUMBER; V_REZ VARCHAR2(7); BEGIN ….. IF V _num1 THEN V_REZ :=
- 20. Пример IF quantity > 15 THEN …; -- скидка 15% ELSIF quantity > 10 THEN …;
- 21. Циклы Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того же участка программы
- 22. Конструкция LOOP-EXIT WHEN-END LOOP Оператор EXIT WHEN условие эквивалентен оператору : IF условие THEN EXIT; END
- 23. Конструкция WHILE-LOOP-END LOOP Пример: DECLARE V_Counter INTEGER BEGIN WHILE V_Counter INSERT INTO temp_table VALUES (V_Counter, ‘LOOP
- 24. Конструкция FOR-IN [REVERSE] -LOOP-END LOOP Пример: BEGIN FOR V_Counter IN 1..50 LOOP INSERT INTO temp_table VALUES
- 25. Присваивание переменным значений базы данных В зависимости от числа возвращаемых запросом строк используются два метода. SELECT
- 26. Курсоры Курсор - это указатель на контекстную область с помощью которого программа PL/SQL может управлять контекстной
- 27. Явное объявление курсора производится в секции DECLARE, причем указанный в определении SQL-оператор может содержать команды select.
- 28. Обработка явных курсоров 1) Объявление курсора При объявлении курсора ему назначается имя и ставится в соответствие
- 29. 2) Открытие курсора для запроса Синтаксис открытия курсора таков: OPEN имя_курсора; где имя_курсора - предварительно объявленный
- 30. 3) Выбор результатов в переменные PL/SQL Производится считывание строк из курсора. Частью оператора FETCH является список
- 31. 4) Закрытие курсора Когда выбран весь активный набор, курсор следует закрыть. Это означает, что программа закончила
- 32. Курсорные атрибуты В PL/SQL существует 4 атрибута, которые применимы к курсорам: %FOUND – это логический атрибут.
- 33. Неявно объявляемые курсоры Оператор select указывается в теле блока, и PL/SQL берет на себя всю заботу
- 34. Пример явного(explicit) курсора DECLARE /*Выходные переменные для хранения результатов запроса */ v_StudentID students. Id%TYPE; v_FirstName students.
- 35. Пример неявного(implicit) курсора BEGIN UPDATE rooms SET number_seats = 100 WHERE room_id = 999; /* Если
- 36. Пример CURSOR ordercursor IS select id, customerid, orderdate from orders; DECLARE CURSOR ordercursor (ordernumber NUMBER) IS
- 37. Оператор GOTO GOTO - оператор безусловного перехода Обработка ошибок (блок EXCEPTION) PL/SQL имеет встроенные исключительные ситуации
- 38. Процедуры Создание процедуры Синтаксис оператора CREATE OR REPLACE PROCEDURE таков: CREATE [OR REPLACE] PROCEDURE имя_процедуры [(аргумент
- 39. Тело процедуры Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений, выполняемый раздел и раздел
- 40. Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время разработки процедур эта операция
- 41. Значения параметров по умолчанию Как и переменные, формальные параметры процедуры или функции могут иметь значения по
- 42. Удаление процедур Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления процедуры выглядит следующим
- 43. Пример процедуры CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS last VARCHAR2(50); first VARCHAR2(50); BEGIN SELECT lastname,
- 44. Функции Создание функций Функции очень похожи на процедуры. Как те, так и другие принимают аргументы, которые
- 45. Описание функций Синтаксис для создания хранимой функции очень похож на синтаксис для создания процедуры: CREATE [OR
- 46. Оператор RETURN Внутри тела функции оператор RETURN применяется для возврата управления программой и результата выполнения функции
- 47. Свойства функций Многие из свойств функций аналогичны свойствам процедур: Функции могут возвращать более одного значения при
- 48. CREATE OR REPLACE FUNCTION AlmostFull( p_Department classes.department%TYPE, p_Course classes.course%TYPE) RETURN BOOLEAN IS V_CurrentStudents NUMBER; V_MaxStudents NUMBER;
- 49. Пример функции CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2) RETURN INTEGER AS custid INTEGER;
- 50. Агрегирующие функции Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти функции можно применять
- 51. MAX COUNT
- 52. AVG MIN SUM
- 53. Модули (Пакеты) Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном месте. Модуль состоит
- 54. CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS} описание_процедуры описание_функции объявление_переменной определение_типа объявление_исключительной_ситуации объявление_курсора END [имя_модуля]; где
- 55. Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений, за исключением объявлений процедуры
- 56. Тело модуля Тело модуля (package body) - это объект словаря данных, хранящийся отдельно от заголовка модуля.
- 57. Модули и области действия Любой объект, объявленный в заголовке модуля, находится в области действия и видим
- 58. Инициализация модуля При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль считывается с диска
- 59. CREATE OR REPLACE PACKAGE Random AS PROCEDURE ChangeSeed (p_NewSeed IN NUMBER); FUNCION Rand RETURN NUMBER; PROCEDURE
- 60. PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS BEGIN v_Seed := p_NewSeed; END ChangeSeed; FUNCTION Rand RETURN NUMBER IS
- 61. CREATE OR REPLACE PACKAGE ClassPackege AS PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE, p_Department IN classes.departmen%TYPE, p_Courses
- 62. FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS BEGIN --Возвращает случайное целое число в диапазоне от 1
- 63. Пример модуля (пакета) CREATE OR REPLACE PACKAGE customermanager IS PROCEDURE newcustomer (company IN VARCHAR2 DEFAULT null,
- 64. Триггеры Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с разделом объявлений, выполняемым
- 65. CREATE [OR REPLACE] TRIGGER имя_триггера {BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу [FOR EACH ROW [WHEN
- 66. Триггеры можно использовать для: Реализации сложных ограничений целостности данных, которые невозможно осуществить через описательные ограничения, устанавливаемые
- 67. Элементы триггера Обязательными элементами триггера являются его имя, активизирующее событие и тело. Условие WHEN необязательно. Имена
- 68. Удаление и запрещение триггеров Триггеры, как и процедуры, и модули, и функции, можно удалять. Синтаксис таков:
- 69. Порядок активизации триггера Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков: 1. Выполняется операторный
- 70. CREATE [OR REPLACE] TRIGGER classesBEstatement BEFORE UPDATE ON classes BEGIN INSERT INTO temp_table (num_col, char_col) VALUES
- 71. CREATE [OR REPLACE] TRIGGER classesBERow BEFORE UPDATE ON classes FOR EACH ROW BEGIN INSERT INTO temp_table
- 72. Ограничения, налагаемые на триггеры Тело триггера является блоком PL/SQL. Любой оператор, выполнение которого разрешено в блоке
- 73. Использование :old и :new в строковых триггерах Строковый триггер срабатывает один раз для каждой строки, обрабатываемой
- 75. Доступ к значениям столбцов Доступ к значениям столбцов в триггере осуществляется с помощью корреляционных имен: :NEW.имя_столбца
- 76. Примеры триггеров 1) CREATE TRIGGER deletecustomer BEFORE DELETE ON customer FOR EACH ROW BEGIN INSERT INTO
- 77. Примеры триггеров 3) CREATE TRIGGER updatestockquantity AFTER INSERT OR DELETE OR UPDATE OF quantity ON item
- 78. Параллельные архитектуры серверов баз данных Три основные архитектурные направления: Симметричные многопроцессорные системы (SMP) - форма сильносвязанных
- 79. Зеркалирование (software mirroring)
- 80. Тиражирование (replication) данных
- 81. Распределенные системы баз данных Ядром системы управления распределенными информационными ресурсами являются распределенная база данных и система
- 82. Правила К. Дейта для распределенных баз данных Локальная автономность Никакой конкретный сервис не должен возлагаться на
- 83. Модели распределенных баз данных Однородные системы, если СУБД –одинаковые, иначе – неоднородные системы
- 84. Фрагментация и тиражирование Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх» Проектирование «сверху вниз»
- 85. Модели тиражирования данных
- 86. Интеграция распределенных баз данных «снизу-вверх» Проектирование распределенных баз данных «снизу вверх» - объединение схем уже существующих
- 87. Доступ к базам данных Системы прозрачного доступа к БД представляют собой популярное решение. В простых двухзвенных
- 88. Доступ к базам данных Использование MW доступа к БД широко применяется в корпоративных системах поддержки принятия
- 89. Архитектура ODBC(OPEN DATABASE CONNECTIVITY) SQL - приложение Администратор ODBC Драйверы ODBC для различных СУБД локальные или
- 90. Существует 4 важных этапа (шага) процедуры запроса данных через ODBC API. Шаг 1 - установление соединения.
- 91. Недостатки реляционных СУБД ∙ Слабое представление сущностей реального мира · Семантическая перегрузка · Слабая поддержка ограничений
- 92. Манифест систем объектно-ориентированных баз данных Обязательные свойства: золотые правила Система объектно-ориентированных баз данных должна удовлетворять двум
- 93. Объектно-ориентированная база данных (ООБД) Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в
- 94. обязательные характеристики ООБД В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая ООБД: Поддержка сложных
- 95. объектно-ориентированные системы управления базами данных (ООСУБД) Результатом совмещения возможностей (особенностей) баз данных и возможностей объектно-ориентированных языков
- 96. Объектная модель данных В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется следующими свойствами. ▪
- 97. Объект, тип Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация определяет внешние характеристики
- 98. Идентификатор объекта Как это следует из модели данных, каждый объект в базе данных уникален. Существует несколько
- 99. Новые типы данных Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и
- 100. Оптимизация ядра СУБД Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями для него являются кэширование
- 101. Язык СУБД и запросы Общепризнанны две группы вариантов языков запросов. Язык OQL (Object Query Language) для
- 102. Транзакции Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках сеанса работы с
- 103. Блокировки Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения одновременного изменения данных.
- 104. Перемещение объектов Миграция объектов: постоянное их перемещение, например в другую базу данных. В качестве примера можно
- 105. db4o db4o — встраиваемая объектно-ориентированная СУБД с открытым исходным кодом, позволяющая .NET и Java разработчикам перманентно
- 106. репликации db4o db4o поддерживает ACID-транзакционность и репликации с помощью db4o Replication System (dRS) — специальной репликационной
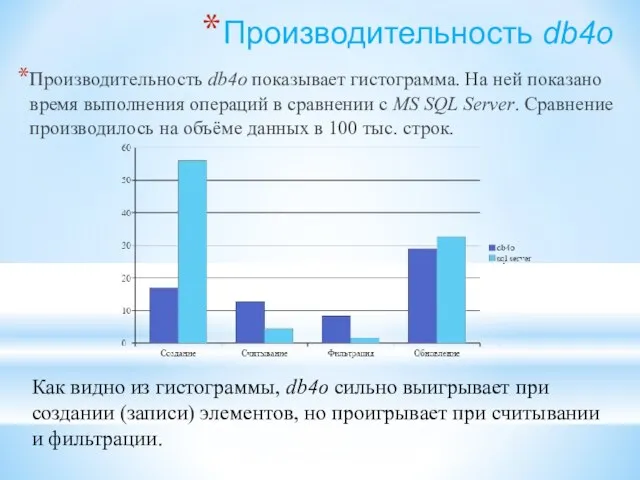
- 107. Производительность db4o Производительность db4o показывает гистограмма. На ней показано время выполнения операций в сравнении с MS
- 108. Objectivity/DB Objectivity/DB — объектно-ориентированная база данных, использующая иерархии, ассоциативные массивы, хеш-таблицы а также STL-контейнеры для манипулирования
- 109. Использование Объектно-ориентированных баз данных Объектно-ориентированные базы данных хорошо подходят в том случае, когда объектная схема данных
- 110. Объектно-реляционные базы данных В настоящее время применяется множество объектно-ориентированных языков программирования, а том числе C++ и
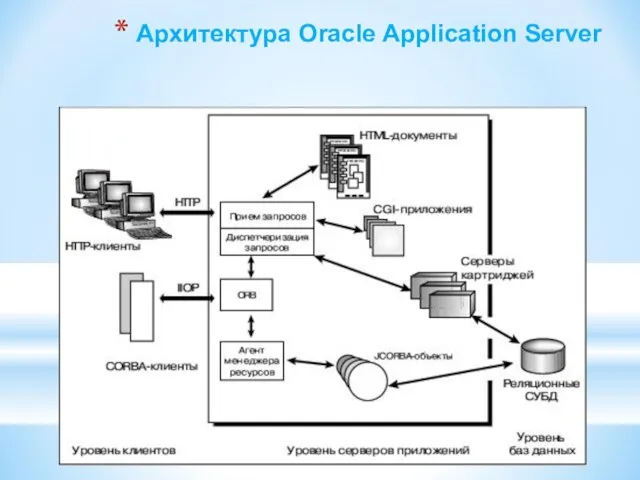
- 111. Архитектура Oracle Application Server
- 112. СУБД Oracle9i СУБД Oracle9i быстро превратилась в СУБД для всех типов данных – от простых до
- 113. Объектно-реляционная архитектура СУБД Oracle9i Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками для создания их
- 114. Объектно-ориентированная разработка приложений СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих связывания для различных
- 115. Объектные типы данных Объектный тип данных — это тип, определяемый пользователем, и задающий как структуру (атрибуты),
- 116. Наследование Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе. Наследование типов позволяет
- 117. Типы-коллекции Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные элементы. Каждый элемент
- 118. Большие объекты СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения проблем хранения изображений,
- 119. Связывания для языков программирования Полная поддержка объектно-реляционной системы типов Oracle доступна в связываниях для ряда языков
- 120. Поддержка XML, дуализм XML/SQL Сервер Oracle поддерживает не только реляционную, объектную, многомерную модель данных, но и
- 121. Поддержка OLAP Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для аналитических систем более
- 122. Oracle 10g Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа - систем распределенных вычислений
- 123. Oracle Database 10g Oracle Database 10g предназначена для эффективного развертывания на базе различных типов оборудования, от
- 124. Oracle Application Server 10g Oracle Application Server 10g - это основанная на стандартах интегрированная программная платформа,
- 125. Oracle Enterprise Manager 10g Oracle Enterprise Manager 10g - это первое в отрасли программное обеспечение, разработанное
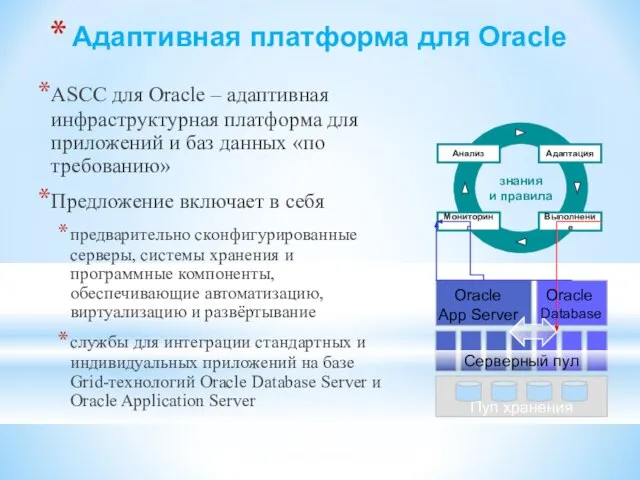
- 126. Адаптивная платформа для Oracle ASCC для Oracle – адаптивная инфраструктурная платформа для приложений и баз данных
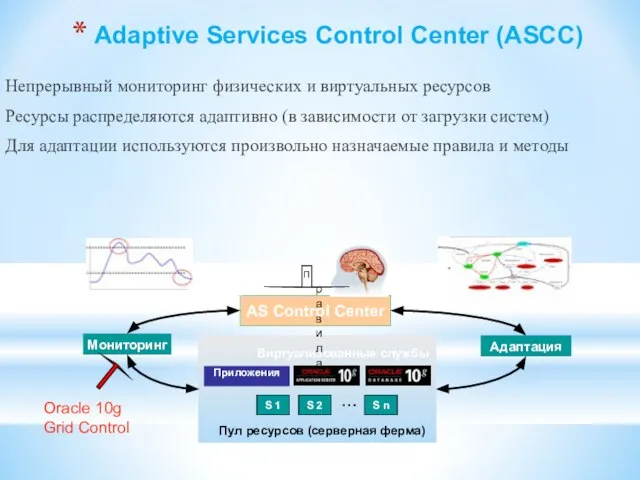
- 127. Adaptive Services Control Center (ASCC) Непрерывный мониторинг физических и виртуальных ресурсов Ресурсы распределяются адаптивно (в зависимости
- 128. Сценарий: управление загрузкой на базе правил AS1 БД RAC резерв Серверы ASCC (анализ, адаптация) время отклика
- 129. Сценарий: преодоление сбоя AS1 RAC DB AS3 Серверы ASCC (анализ, адаптация) GCC AS2 Client Клиент (мониторинг)
- 130. Недостатки SQL-хранилищ Скорость работы. При высокой загруженности ресурса и достаточно большом количестве записей в базе данных
- 131. Нереляционный подход к организации БД - NoSQL NoSQL хранилища данных имеют максимально упрощённую структуру «ключ —
- 132. Теорема CAP (Эрик Брюер) В распределенной вычислительной системе невозможно обеспечить более двух из трёх следующих свойств:
- 133. Пусть распределенная система состоит из N серверов, каждый из которых обрабатывает запросы некоторого числа клиентских приложений.
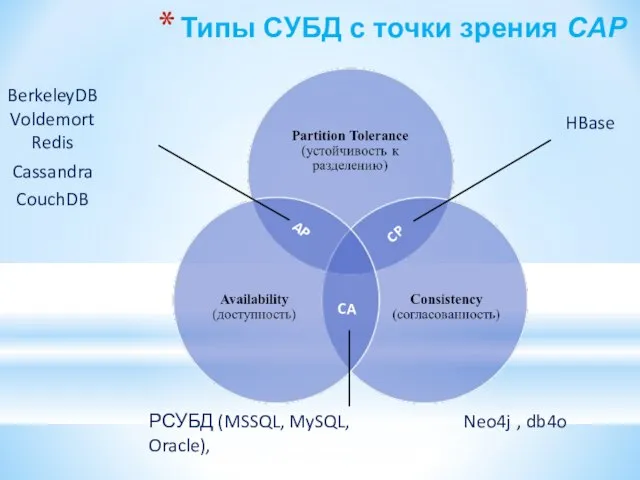
- 134. Классификация распределенных систем по видам выполняемых требований CAP CA — система, во всех узлах которой данные
- 135. Типы СУБД с точки зрения CAP
- 136. BASE (Basically Available, Soft State, Eventually consistent) В любом из трех случаев не обязательно будет выполнено
- 137. Масштабируемость Одной из основных проблем реляционных баз данных, решение которых может быть достигнуто с помощью технологий
- 138. Репликация В распределенных базах данных репликация состоит в хранении одних и тех же данных на нескольких
- 139. Шардинг (Sharding) Другим подходом к горизонтальному масштабированию является шардинг (Sharding). Он представляет собой разбиение данных в
- 140. Шардинг (Sharding) В распределенных системах оба исходных набора данных хранятся на множестве узлов, и для осуществления
- 141. Консистентное хеширование Для многих NoSQL-СУБД шардинг представляет собой одну из ключевых возможностей. При этом важной задачей
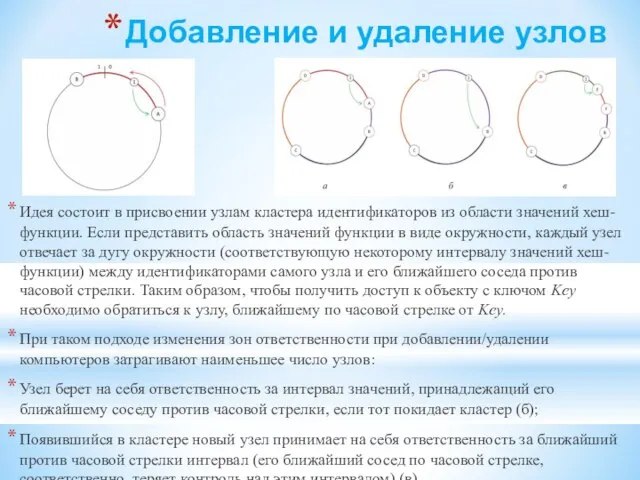
- 142. Добавление и удаление узлов Идея состоит в присвоении узлам кластера идентификаторов из области значений хеш-функции. Если
- 143. MapReduce Одним из наиболее популярных подходов к распределенной обработке данных является модель MapReduce, разработанная Google. Использование
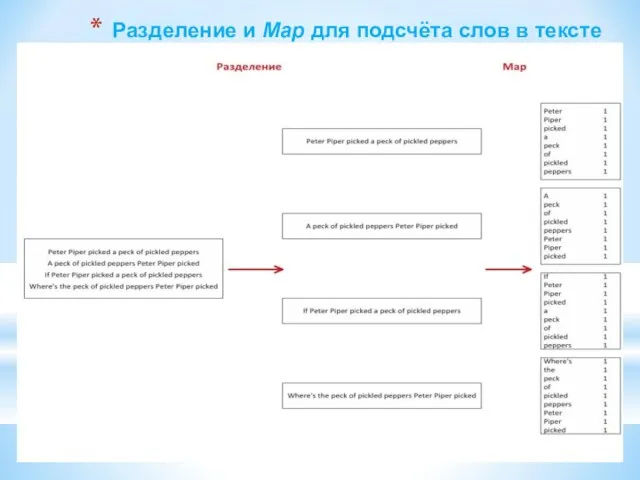
- 144. Разделение и Map для подсчёта слов в тексте
- 145. Группировка и Reduce для подсчёта слов в тексте
- 146. Внедрение модели MapReduce Модель MapReduce, предоставляющая широкие возможности для распределенной обработки данных, внедрена в ряд NoSQL-баз
- 147. Классификация NoSQL В зависимости от направленности и способов обработки данных можно различать такие нереляционные хранилища как:
- 148. Хранилища типа «ключ-значение» Хранилища «ключ-значение» («Key-Value») — базы данных, построенные на основе простой модели ассоциативного массива,
- 149. BerkeleyDB Oracle BerkeleyDB (BDB) — высокопроизводительная встраиваемая база данных, реализованная в виде библиотеки. BDB может обслуживать
- 150. Dynamo и Voldemort В основу СУБД от Amazon положен принцип «сбой оборудования - стандартный режим работы
- 151. Redis Redis — сетевое журналируемое хранилище данных типа «ключ-значение» с открытым исходным кодом. Redis хранит таблицы
- 152. Применение хранилищ типа «ключ-значение» Хранилища типа «ключ-значение» отлично подходят для таких типов данных, доступ к которым
- 153. Колоночные хранилища Идея хранить и обрабатывать данные по колонкам (столбцам), зародилась в области бизнес-аналитики для создания
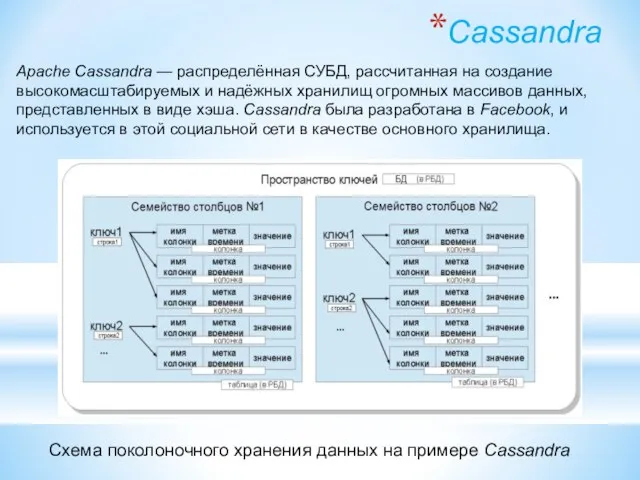
- 154. Cassandra Схема поколоночного хранения данных на примере Cassandra Apache Cassandra — распределённая СУБД, рассчитанная на создание
- 155. Особенности Cassandra Столбец в Cassandra состоит из пары имя-значение, где имя также является ключом. Каждая такая
- 156. Google BigTable Google BigTable — распределённое хранилище, разработанное Google специально для манипулирования огромным объёмом структурированных данных,
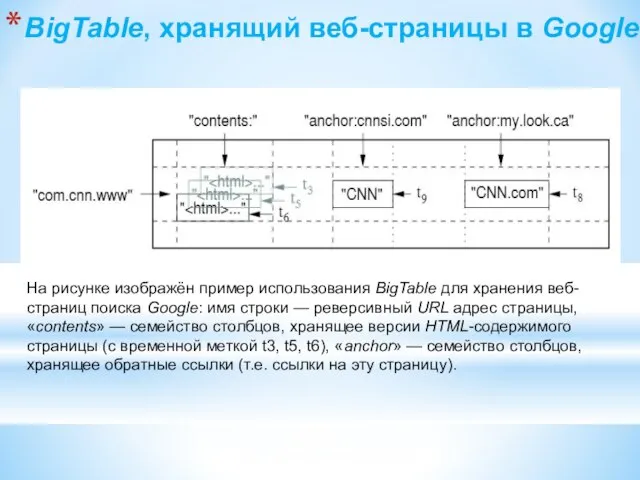
- 157. BigTable, хранящий веб-страницы в Google На рисунке изображён пример использования BigTable для хранения веб-страниц поиска Google:
- 158. HBase Apache HBase — нереляционная распределённая база данных с открытым исходным кодом; написана на Java; является
- 159. Таблица HBase Таблицы HBase состоят из регионов — наборов строк в семействах столбцов. Каждый регион может
- 160. Использование колоночных хранилищ Реляционные хранилища считают базовой единицей хранения данных строку, и это обеспечивает им хорошую
- 161. Использование колоночных хранилищ Ещё одна интересная возможность — создание временных столбцов (например, у Cassandra). Такие столбцы
- 162. Документно-ориентированные хранилища Центральным понятием этого подхода является «документ». Он инкапсулирует данные, как правило, в виде одного
- 163. MongoDB СУБД MongoDB управляет наборами JSON-подобных документов, хранимых в двоичном виде в формате BSON. Инстанс MongoDB
- 164. Основные возможности MongoDB Достаточно гибкий язык для формирования запросов Динамические запросы Полная поддержка индексов Профилирование запросов
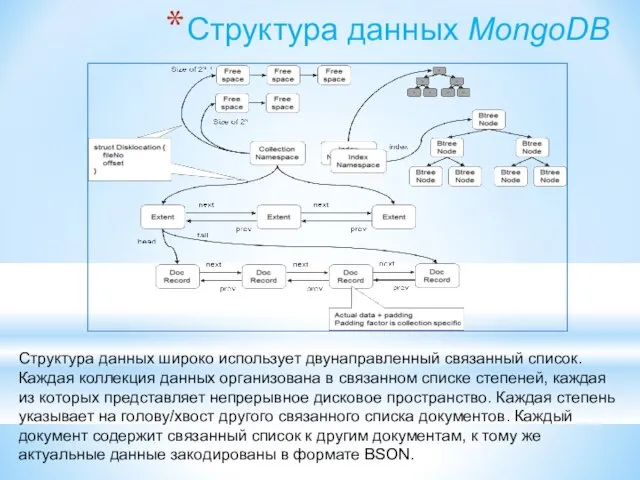
- 165. Структура данных MongoDB Структура данных широко использует двунаправленный связанный список. Каждая коллекция данных организована в связанном
- 166. Модификация данных Модификация данных происходит на месте. В случае если модификация увеличивает размер записи вне его
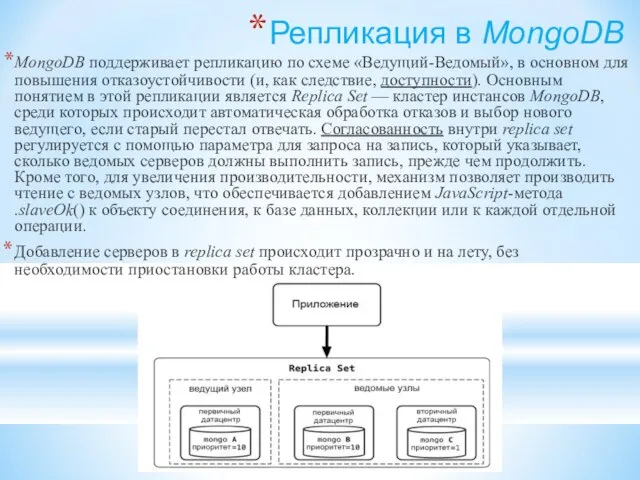
- 167. Репликация в MongoDB MongoDB поддерживает репликацию по схеме «Ведущий-Ведомый», в основном для повышения отказоустойчивости (и, как
- 168. CouchDB CouchDB — NoSQL-СУБД, разработанная Apache. Позволяет использовать в качестве полей документа скалярные значения (числа, строки),
- 169. Особенности CouchDB Запросы могут выполняться параллельно к множеству узлов - для этого используется MapReduce. Также CouchDB
- 170. Масштабируемость Масштабируемость достигается посредством так называемой инкрементальной репликации — изменения документа периодически копируются между серверами. В
- 171. Использование документно-ориентированные хранилищ Документно-ориентированные хранилища представляют собой очень удобную прослойку между схемами хранилищ «ключ-значение» и реляционными
- 172. Хранилища графов Базы данных на основе графов позволяют хранить сущности и связи между ними. Сущности в
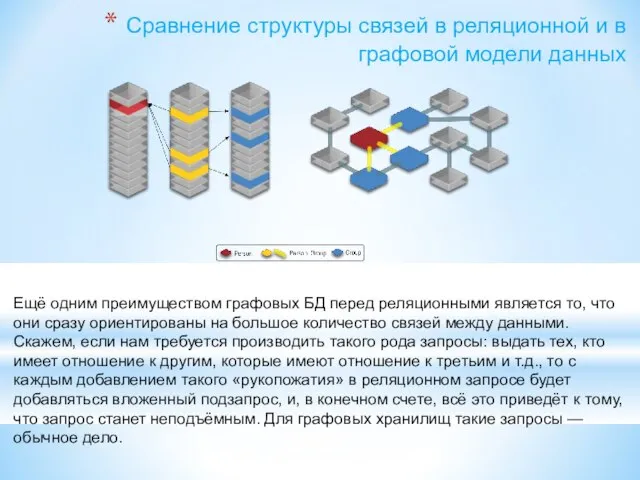
- 173. Сравнение структуры связей в реляционной и в графовой модели данных Ещё одним преимуществом графовых БД перед
- 174. Neo4j — графовая база данных Neo4j — графовая база данных с открытым исходным кодом, поддерживаемая комнапией
- 175. HyperGraphDB HyperGraphDB — это расшириемая портативная распределённая встраиваемая система хранения данных с открытым исходным кодом. Это
- 176. Использование хранилищ графов Хранилища графов подходят для хранения плотно связанных данных, когда основной упор делается не
- 177. Достоинства и недостатки NoSQL Можно сделать вывод о том, что NoSQL не является «панацеей» — у
- 178. NoSQL или SQL? Возникает вопрос: что лучше использовать — NoSQL или SQL? Широко распространенная и хорошо
- 179. Выбор решения Можно предложить подход при выборе типа хранилища для конкретного проекта. На рисунке показано относительное
- 180. Hadoop— проект фонда Apache Software FoundationHadoop— проект фонда Apache Software Foundation, свободно распространяемыйHadoop— проект фонда Apache
- 181. SQL и NoSQL Одно приложение — много СУБД
- 182. Классификация облачных инфраструктур Origins of the Terms • Both first commonly used in the context of
- 183. Облачные СУБД СУБД, предоставляемая по подписке со всеми подобающими характеристиками — DBaaS (database as a service)
- 184. Требования к облачным СУБД Модель аренды ресурсов с оплатой по мере использования, характерная для облаков, дает
- 185. Новые архитектуры баз данных Многозвенные архитектуры: а — классическая трехзвенная, б — пятизвенная, в — четырехзвенная,
- 186. Новые уровни данных Традиционная трехзвенная архитектура была преобразована в пятиуровневую: презентационный уровень, приложение, база данных, менеджер
- 187. Уровень менеджера записей Менеджер записей расширяет функциональность файловой системы, предоставляя более мелкодисперсный доступ к данным. В
- 188. Уровень баз данных Этот уровень находится поверх менеджера записей, отвечая за обработку запросов и транзакций, а
- 189. Пятизвенная архитектура В такой архитектуре каждый уровень представляет собой отдельный сервис. Самый известный пример — это
- 190. Четырехзвенная разделенная архитектура с файловым уровнем Один из способов уменьшить трафик между уровнями — объединить базу
- 191. Интеграция SQL и NoSQL Одно приложение — много СУБД SQL и NoSQL во многом можно противопоставить
- 192. Big Data definitions Простое определение: Большие Данные те, что слишком велики и сложны, чтобы их можно
- 193. How useful is Big Data ? Большие должны быть доступны для поисковых систем, проанализированы в центрах
- 194. Большие данные – горячая тема, потому что технологии сделали возможным анализ ВСЕХ доступных данных Эффективно с
- 195. Обвал данных Каждый день в мире производится 2,5 квинтильона (1018) байтов данных. 90% данных созданы за
- 196. Прогноз роста данных до 2015 года Прогноз роста данных до 2015 года
- 197. Первый взгляд на большие данные
- 198. Инженерный взгляд хранилища системы хранения данных облака EMC оборот Oracle IBM Amazon один админ на 10000
- 200. BI / Reporting Стратегия IBM Big Data : приблизить аналитику к данным IBM Big Data Platform
- 201. Изменение парадигмы ИТ Структурирует данные для ответа на вопрос ИТ Обеспечивает платформу для креативного анализа Бизнес
- 202. Вступление в эру Big Data We are BIG! Сравнительная диаграмма обрабатываемых данных наглядно показывает, что исследования
- 203. CERN “Big Data” Physics Data on CASTOR/EOS LHC experiments produce ~10GB/s 25PB/year User Data on AFS
- 204. В эксперименте ATLAS на Большом адронном коллайдере разработана платформа для управления вычислительными ресурсами PanDA Workload Management
- 205. Интеграция технологий распределенных вычислений для управления большими данными PanDa, как платформа, обеспечивающая прозрачность процесса хранения, обработки
- 206. 8/6/13 Big Data Workshop Пример использования системы PanDA (суперкомпьтер Titan в Oak Ridge) Конфигурация суперкомпьютера Titan
- 207. Ресурсы, доступные с помощью платформы PanDA OLCF Проекты с суперкомпьютерными центрами НИЦ КИ, ННГУ, Острава (Чехия)
- 208. Data Mining to deal with Big Data Data Mining (DM) - “Это технология, которая предназначена для
- 210. Скачать презентацию

Слайд 3Темы лекций
1. Язык PL/SQL, его структура, основные операторы.
2. Курсоры, операторы работы с курсором,
Темы лекций
1. Язык PL/SQL, его структура, основные операторы.
2. Курсоры, операторы работы с курсором,

Слайд 4Литература
Дейт К. Введение в системы баз данных. – 8 изд., Вильямс, 2005
Кузнецов
Литература
Дейт К. Введение в системы баз данных. – 8 изд., Вильямс, 2005
Кузнецов

Слайд 5PL/SQL (Procedural Language) — процедурное расширение языка SQL
PL/SQL - Procedural Language. Как
PL/SQL (Procedural Language) — процедурное расширение языка SQL
PL/SQL - Procedural Language. Как

Слайд 6PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к
PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к

Слайд 7Модель клиент — сервер
PL/SQL в среде клиент /сервер
Модель клиент — сервер
PL/SQL в среде клиент /сервер
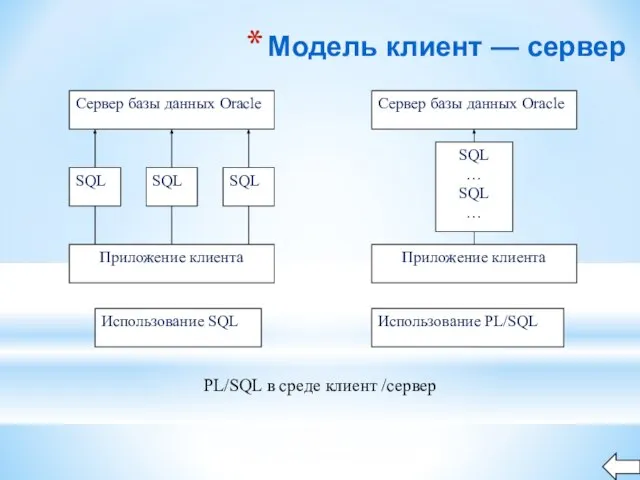
Слайд 8Многие приложения для работы с базами данных создаются с использованием модели клиент
Многие приложения для работы с базами данных создаются с использованием модели клиент

Слайд 9Блок PL/SQL
Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из
Блок PL/SQL
Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из

Слайд 10Допустимы следующие виды блоков:
Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются
Допустимы следующие виды блоков:
Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются

Слайд 11Лексические единицы
Набор символов PL/SQL
При работе с PL/SQL допускается использование символов из
Лексические единицы
Набор символов PL/SQL
При работе с PL/SQL допускается использование символов из

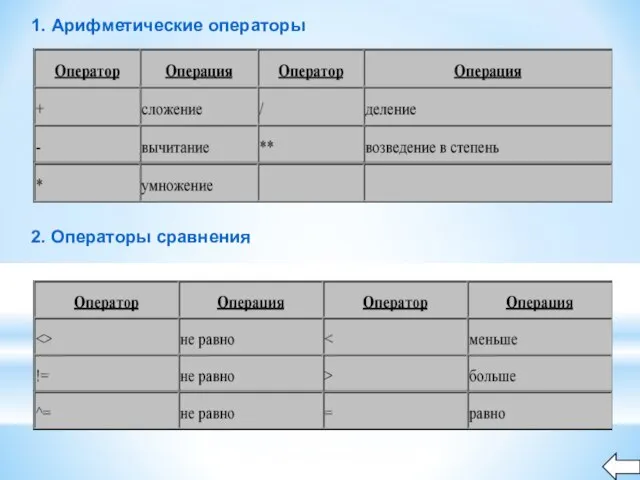
Слайд 122. Операторы сравнения
1. Арифметические операторы
2. Операторы сравнения
1. Арифметические операторы
Слайд 13Идентификаторы
Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов
Идентификаторы
Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов

Слайд 14Типы данных
Тип Подтип
NUMBER DECIMAL, REAL, FLOAT, NUMERIC
(precision, scale) INTEGER, SMALLINT,
CHAR
Типы данных
Тип Подтип
NUMBER DECIMAL, REAL, FLOAT, NUMERIC
(precision, scale) INTEGER, SMALLINT,
CHAR

Слайд 15Записи PL/SQL
Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно
Записи PL/SQL
Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно

Слайд 16Чтобы присвоить одной записи значение другой они должны быть одного типа.
Хотя
Чтобы присвоить одной записи значение другой они должны быть одного типа.
Хотя

Слайд 17Управляющие структуры PL/SQL
Структуры управления являются основой любого языка программирования, поскольку большинство реальных
Управляющие структуры PL/SQL
Структуры управления являются основой любого языка программирования, поскольку большинство реальных

Слайд 18Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации,
Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации,

Слайд 19Пример
DECLARE
V_num1 NUMBER;
V_num2 NUMBER;
V_REZ VARCHAR2(7);
BEGIN
…..
IF V _num1 <
Пример
DECLARE
V_num1 NUMBER;
V_num2 NUMBER;
V_REZ VARCHAR2(7);
BEGIN
…..
IF V _num1 <

Слайд 20Пример
IF quantity > 15
THEN …; -- скидка 15%
ELSIF quantity
Пример
IF quantity > 15
THEN …; -- скидка 15%
ELSIF quantity

Слайд 21Циклы
Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того
Циклы
Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того

Слайд 22Конструкция LOOP-EXIT WHEN-END LOOP
Оператор EXIT WHEN условие эквивалентен оператору : IF
Конструкция LOOP-EXIT WHEN-END LOOP
Оператор EXIT WHEN условие эквивалентен оператору : IF

Слайд 23Конструкция WHILE-LOOP-END LOOP
Пример:
DECLARE
V_Counter INTEGER
BEGIN
WHILE V_Counter <= 50 LOOP
Конструкция WHILE-LOOP-END LOOP
Пример:
DECLARE
V_Counter INTEGER
BEGIN
WHILE V_Counter <= 50 LOOP

Слайд 24Конструкция FOR-IN [REVERSE] -LOOP-END LOOP
Пример: BEGIN
FOR V_Counter IN 1..50 LOOP
Конструкция FOR-IN [REVERSE] -LOOP-END LOOP
Пример: BEGIN
FOR V_Counter IN 1..50 LOOP
![Конструкция FOR-IN [REVERSE] -LOOP-END LOOP Пример: BEGIN FOR V_Counter IN 1..50 LOOP](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381638/slide-23.jpg)
Слайд 25Присваивание переменным значений базы данных
В зависимости от числа возвращаемых запросом строк используются
Присваивание переменным значений базы данных
В зависимости от числа возвращаемых запросом строк используются

Слайд 26Курсоры
Курсор - это указатель на контекстную область с помощью которого программа PL/SQL
Курсоры
Курсор - это указатель на контекстную область с помощью которого программа PL/SQL

Слайд 27Явное объявление курсора производится в секции DECLARE, причем указанный в определении SQL-оператор
Явное объявление курсора производится в секции DECLARE, причем указанный в определении SQL-оператор

Слайд 28Обработка явных курсоров
1) Объявление курсора
При объявлении курсора ему назначается имя и
Обработка явных курсоров
1) Объявление курсора
При объявлении курсора ему назначается имя и

Слайд 292) Открытие курсора для запроса
Синтаксис открытия курсора таков:
OPEN имя_курсора;
где имя_курсора -
2) Открытие курсора для запроса
Синтаксис открытия курсора таков:
OPEN имя_курсора;
где имя_курсора -

Слайд 303) Выбор результатов в переменные PL/SQL
Производится считывание строк из курсора. Частью
Производится считывание строк из курсора. Частью

Слайд 314) Закрытие курсора
Когда выбран весь активный набор, курсор следует закрыть.
Это
4) Закрытие курсора
Когда выбран весь активный набор, курсор следует закрыть.
Это

Слайд 32Курсорные атрибуты
В PL/SQL существует 4 атрибута, которые применимы к курсорам:
%FOUND – это
Курсорные атрибуты
В PL/SQL существует 4 атрибута, которые применимы к курсорам:
%FOUND – это

Слайд 33Неявно объявляемые курсоры
Оператор select указывается в теле блока, и PL/SQL берет на
Неявно объявляемые курсоры
Оператор select указывается в теле блока, и PL/SQL берет на

Слайд 34Пример явного(explicit) курсора
DECLARE
/*Выходные переменные для хранения результатов запроса */
v_StudentID students. Id%TYPE;
Пример явного(explicit) курсора
DECLARE
/*Выходные переменные для хранения результатов запроса */
v_StudentID students. Id%TYPE;

Слайд 35Пример неявного(implicit) курсора
BEGIN
UPDATE rooms
SET number_seats = 100
WHERE room_id =
Пример неявного(implicit) курсора
BEGIN
UPDATE rooms
SET number_seats = 100
WHERE room_id =

Слайд 36Пример
CURSOR ordercursor IS select id, customerid, orderdate from orders;
DECLARE
CURSOR ordercursor (ordernumber NUMBER)
Пример
CURSOR ordercursor IS select id, customerid, orderdate from orders;
DECLARE
CURSOR ordercursor (ordernumber NUMBER)

Слайд 37Оператор GOTO
GOTO <метка> - оператор безусловного перехода
Обработка ошибок (блок EXCEPTION)
PL/SQL имеет встроенные
Оператор GOTO
GOTO <метка> - оператор безусловного перехода
Обработка ошибок (блок EXCEPTION)
PL/SQL имеет встроенные

Слайд 38Процедуры
Создание процедуры
Синтаксис оператора CREATE OR REPLACE PROCEDURE таков:
CREATE [OR REPLACE] PROCEDURE
Процедуры
Создание процедуры
Синтаксис оператора CREATE OR REPLACE PROCEDURE таков:
CREATE [OR REPLACE] PROCEDURE

Слайд 39Тело процедуры
Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений,
Тело процедуры
Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений,

Слайд 40Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время
Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время

Слайд 41Значения параметров по умолчанию
Как и переменные, формальные параметры процедуры или функции могут
Значения параметров по умолчанию
Как и переменные, формальные параметры процедуры или функции могут

Слайд 42Удаление процедур
Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления
Удаление процедур
Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления

Слайд 43Пример процедуры
CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS
last VARCHAR2(50);
first VARCHAR2(50);
BEGIN
Пример процедуры
CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS
last VARCHAR2(50);
first VARCHAR2(50);
BEGIN

Слайд 44Функции
Создание функций
Функции очень похожи на процедуры. Как те, так и другие принимают
Функции
Создание функций
Функции очень похожи на процедуры. Как те, так и другие принимают

Слайд 45Описание функций
Синтаксис для создания хранимой функции очень похож на синтаксис для создания
Описание функций
Синтаксис для создания хранимой функции очень похож на синтаксис для создания

Слайд 46Оператор RETURN
Внутри тела функции оператор RETURN применяется для возврата управления программой
Оператор RETURN
Внутри тела функции оператор RETURN применяется для возврата управления программой

Слайд 47Свойства функций
Многие из свойств функций аналогичны свойствам процедур:
Функции могут возвращать более
Свойства функций
Многие из свойств функций аналогичны свойствам процедур:
Функции могут возвращать более

Слайд 48CREATE OR REPLACE FUNCTION AlmostFull(
p_Department classes.department%TYPE,
p_Course classes.course%TYPE)
RETURN BOOLEAN IS
V_CurrentStudents NUMBER;
V_MaxStudents NUMBER;
V_ReturnValue BOOLEAN;
V_FullPercent
p_Department classes.department%TYPE,
p_Course classes.course%TYPE)
RETURN BOOLEAN IS
V_CurrentStudents NUMBER;
V_MaxStudents NUMBER;
V_ReturnValue BOOLEAN;
V_FullPercent

Слайд 49Пример функции
CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2)
RETURN INTEGER AS
Пример функции
CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2)
RETURN INTEGER AS

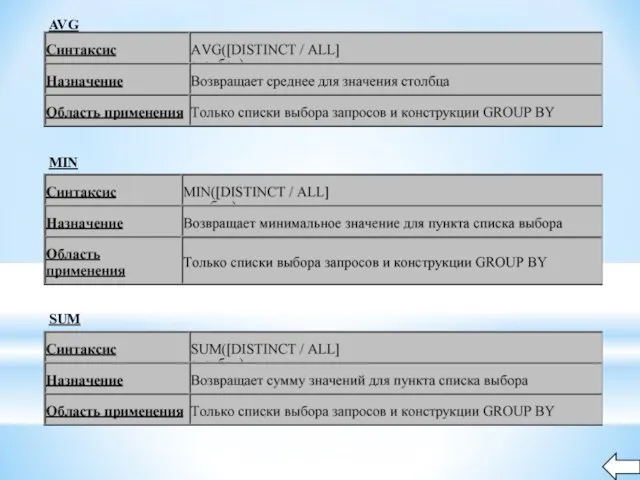
Слайд 50Агрегирующие функции
Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти
Агрегирующие функции
Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти

Слайд 51MAX
COUNT
MAX
COUNT

Слайд 52AVG
MIN
SUM
AVG
MIN
SUM
Слайд 53Модули (Пакеты)
Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном
Модули (Пакеты)
Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном

Слайд 54CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS}
описание_процедуры
описание_функции
объявление_переменной
определение_типа
объявление_исключительной_ситуации
объявление_курсора
описание_процедуры описание_функции объявление_переменной определение_типа объявление_исключительной_ситуации объявление_курсора
![CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS} описание_процедуры описание_функции объявление_переменной определение_типа объявление_исключительной_ситуации](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381638/slide-53.jpg)
Слайд 55Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений,
Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений,

Слайд 56Тело модуля
Тело модуля (package body) - это объект словаря данных, хранящийся
Тело модуля
Тело модуля (package body) - это объект словаря данных, хранящийся

Слайд 57Модули и области действия
Любой объект, объявленный в заголовке модуля, находится в области
Модули и области действия
Любой объект, объявленный в заголовке модуля, находится в области

Слайд 58Инициализация модуля
При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль
Инициализация модуля
При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль

Слайд 59CREATE OR REPLACE PACKAGE Random AS
PROCEDURE ChangeSeed (p_NewSeed IN NUMBER);
FUNCION Rand RETURN
PROCEDURE ChangeSeed (p_NewSeed IN NUMBER);
FUNCION Rand RETURN

Слайд 60PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS
BEGIN
v_Seed := p_NewSeed;
END ChangeSeed;
FUNCTION Rand RETURN NUMBER IS
PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS
BEGIN
v_Seed := p_NewSeed;
END ChangeSeed;
FUNCTION Rand RETURN NUMBER IS

Слайд 61CREATE OR REPLACE PACKAGE ClassPackege AS
PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE,
p_Department IN
CREATE OR REPLACE PACKAGE ClassPackege AS
PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE,
p_Department IN

Слайд 62FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS
BEGIN
--Возвращает случайное целое число в
FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS
BEGIN
--Возвращает случайное целое число в

Слайд 63Пример модуля (пакета)
CREATE OR REPLACE PACKAGE customermanager IS
PROCEDURE newcustomer (company IN VARCHAR2
Пример модуля (пакета)
CREATE OR REPLACE PACKAGE customermanager IS
PROCEDURE newcustomer (company IN VARCHAR2

Слайд 64Триггеры
Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с
Триггеры
Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с

Слайд 65CREATE [OR REPLACE] TRIGGER имя_триггера
{BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу
[FOR EACH
CREATE [OR REPLACE] TRIGGER имя_триггера
{BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу
[FOR EACH
![CREATE [OR REPLACE] TRIGGER имя_триггера {BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381638/slide-64.jpg)
Слайд 66Триггеры можно использовать для:
Реализации сложных ограничений целостности данных, которые невозможно осуществить
Триггеры можно использовать для:
Реализации сложных ограничений целостности данных, которые невозможно осуществить

Слайд 67Элементы триггера
Обязательными элементами триггера являются его имя, активизирующее событие и тело.
Элементы триггера
Обязательными элементами триггера являются его имя, активизирующее событие и тело.

Слайд 68Удаление и запрещение триггеров
Триггеры, как и процедуры, и модули, и функции, можно
Удаление и запрещение триггеров
Триггеры, как и процедуры, и модули, и функции, можно

Слайд 69Порядок активизации триггера
Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков:
Порядок активизации триггера
Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков:

Слайд 70CREATE [OR REPLACE] TRIGGER classesBEstatement
BEFORE UPDATE ON classes
BEGIN
INSERT INTO temp_table
BEFORE UPDATE ON classes
BEGIN
INSERT INTO temp_table
![CREATE [OR REPLACE] TRIGGER classesBEstatement BEFORE UPDATE ON classes BEGIN INSERT INTO](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381638/slide-69.jpg)
Слайд 71CREATE [OR REPLACE] TRIGGER classesBERow
BEFORE UPDATE ON classes FOR EACH ROW
CREATE [OR REPLACE] TRIGGER classesBERow
BEFORE UPDATE ON classes FOR EACH ROW
![CREATE [OR REPLACE] TRIGGER classesBERow BEFORE UPDATE ON classes FOR EACH ROW](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381638/slide-70.jpg)
Слайд 72Ограничения, налагаемые на триггеры
Тело триггера является блоком PL/SQL.
Любой оператор, выполнение
Ограничения, налагаемые на триггеры
Тело триггера является блоком PL/SQL.
Любой оператор, выполнение

Слайд 73Использование :old и :new в строковых триггерах
Строковый триггер срабатывает один раз для
Использование :old и :new в строковых триггерах
Строковый триггер срабатывает один раз для


Слайд 75Доступ к значениям столбцов
Доступ к значениям столбцов в триггере осуществляется с помощью
Доступ к значениям столбцов
Доступ к значениям столбцов в триггере осуществляется с помощью

Слайд 76Примеры триггеров
1) CREATE TRIGGER deletecustomer
BEFORE DELETE ON customer
FOR EACH
Примеры триггеров
1) CREATE TRIGGER deletecustomer
BEFORE DELETE ON customer
FOR EACH

Слайд 77Примеры триггеров
3) CREATE TRIGGER updatestockquantity
AFTER INSERT OR DELETE OR UPDATE
Примеры триггеров
3) CREATE TRIGGER updatestockquantity
AFTER INSERT OR DELETE OR UPDATE

Слайд 78Параллельные архитектуры серверов баз данных
Три основные архитектурные направления:
Симметричные многопроцессорные системы
Параллельные архитектуры серверов баз данных
Три основные архитектурные направления:
Симметричные многопроцессорные системы

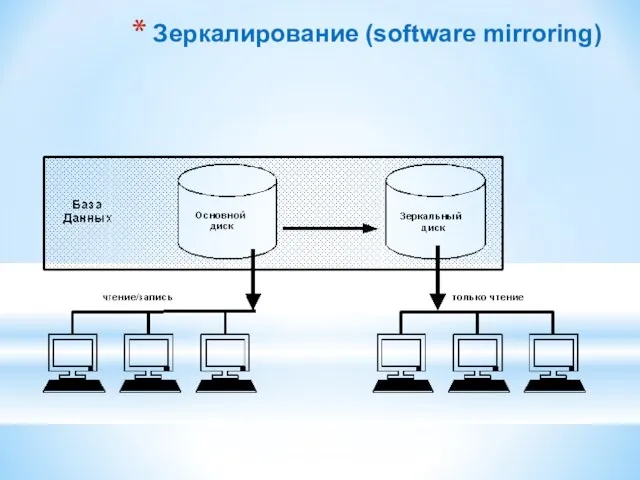
Слайд 79Зеркалирование (software mirroring)
Зеркалирование (software mirroring)
Слайд 80Тиражирование (replication) данных
Тиражирование (replication) данных
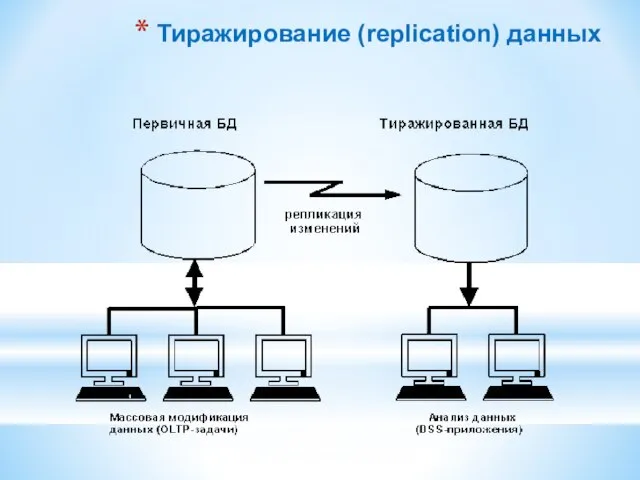
Слайд 81Распределенные системы баз данных
Ядром системы управления распределенными информационными ресурсами являются распределенная база
Распределенные системы баз данных
Ядром системы управления распределенными информационными ресурсами являются распределенная база

Слайд 82Правила К. Дейта для распределенных баз данных
Локальная автономность
Никакой конкретный сервис не должен
Правила К. Дейта для распределенных баз данных
Локальная автономность
Никакой конкретный сервис не должен

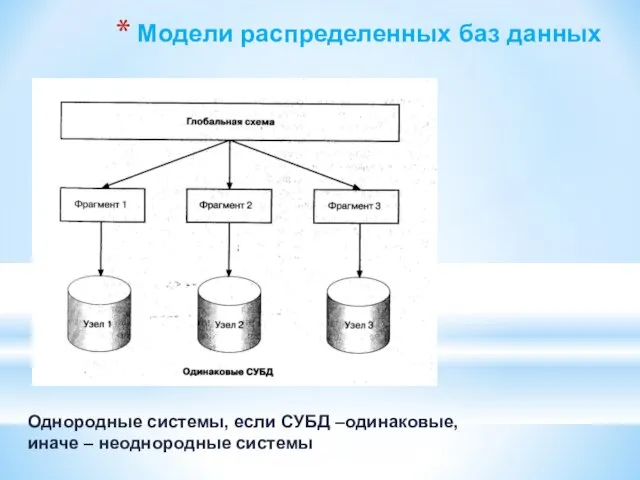
Слайд 83Модели распределенных баз данных
Однородные системы, если СУБД –одинаковые,
иначе – неоднородные системы
Модели распределенных баз данных
Однородные системы, если СУБД –одинаковые,
иначе – неоднородные системы
Слайд 84Фрагментация и тиражирование
Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх»
Проектирование
Фрагментация и тиражирование
Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх»
Проектирование

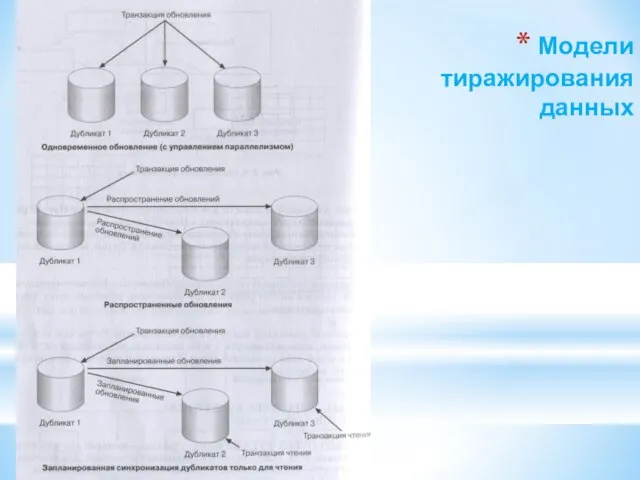
Слайд 85Модели тиражирования данных
Модели тиражирования данных
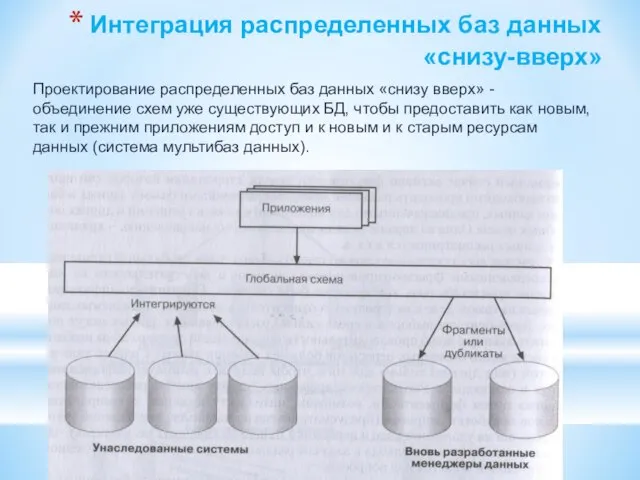
Слайд 86Интеграция распределенных баз данных «снизу-вверх»
Проектирование распределенных баз данных «снизу вверх» - объединение
Интеграция распределенных баз данных «снизу-вверх»
Проектирование распределенных баз данных «снизу вверх» - объединение
Слайд 87Доступ к базам данных
Системы прозрачного доступа к БД представляют собой популярное решение.
Доступ к базам данных
Системы прозрачного доступа к БД представляют собой популярное решение.

Слайд 88Доступ к базам данных
Использование MW доступа к БД широко применяется в корпоративных
Доступ к базам данных
Использование MW доступа к БД широко применяется в корпоративных

Слайд 89Архитектура ODBC(OPEN DATABASE CONNECTIVITY)
SQL - приложение
Администратор ODBC
Драйверы ODBC для различных
Архитектура ODBC(OPEN DATABASE CONNECTIVITY)
SQL - приложение Администратор ODBC Драйверы ODBC для различных

Слайд 90Существует 4 важных этапа (шага) процедуры запроса данных через ODBC API.
Шаг
Шаг

Слайд 91Недостатки реляционных СУБД
∙ Слабое представление сущностей реального мира
· Семантическая перегрузка
Недостатки реляционных СУБД
∙ Слабое представление сущностей реального мира
· Семантическая перегрузка

Слайд 92Манифест систем объектно-ориентированных баз данных
Обязательные свойства: золотые правила
Система объектно-ориентированных баз данных должна
Манифест систем объектно-ориентированных баз данных
Обязательные свойства: золотые правила
Система объектно-ориентированных баз данных должна

Слайд 93Объектно-ориентированная база данных (ООБД)
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные
Объектно-ориентированная база данных (ООБД)
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные

Слайд 94обязательные характеристики ООБД
В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая
обязательные характеристики ООБД
В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая

Слайд 95объектно-ориентированные системы управления базами данных (ООСУБД)
Результатом совмещения возможностей (особенностей) баз данных и
объектно-ориентированные системы управления базами данных (ООСУБД)
Результатом совмещения возможностей (особенностей) баз данных и

Слайд 96Объектная модель данных
В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется
Объектная модель данных
В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется

Слайд 97Объект, тип
Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация
Объект, тип
Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация

Слайд 98Идентификатор объекта
Как это следует из модели данных, каждый объект в базе данных
Идентификатор объекта
Как это следует из модели данных, каждый объект в базе данных

Слайд 99Новые типы данных
Одним из принципиальных отличий объектных баз данных от реляционных является
Новые типы данных
Одним из принципиальных отличий объектных баз данных от реляционных является

Слайд 100Оптимизация ядра СУБД
Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями
Оптимизация ядра СУБД
Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями

Слайд 101Язык СУБД и запросы
Общепризнанны две группы вариантов языков запросов.
Язык OQL (Object
Язык СУБД и запросы
Общепризнанны две группы вариантов языков запросов.
Язык OQL (Object

Слайд 102Транзакции
Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках
Транзакции
Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках

Слайд 103Блокировки
Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения
Блокировки
Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения

Слайд 104Перемещение объектов
Миграция объектов: постоянное их перемещение, например в другую базу данных. В
Перемещение объектов
Миграция объектов: постоянное их перемещение, например в другую базу данных. В

Слайд 105db4o
db4o — встраиваемая объектно-ориентированная СУБД с открытым исходным кодом, позволяющая .NET и
db4o
db4o — встраиваемая объектно-ориентированная СУБД с открытым исходным кодом, позволяющая .NET и

Слайд 106репликации db4o
db4o поддерживает ACID-транзакционность и репликации с помощью db4o Replication System (dRS)
репликации db4o
db4o поддерживает ACID-транзакционность и репликации с помощью db4o Replication System (dRS)

Слайд 107Производительность db4o
Производительность db4o показывает гистограмма. На ней показано время выполнения операций в
Производительность db4o
Производительность db4o показывает гистограмма. На ней показано время выполнения операций в
Слайд 108Objectivity/DB
Objectivity/DB — объектно-ориентированная база данных, использующая иерархии, ассоциативные массивы, хеш-таблицы а также
Objectivity/DB
Objectivity/DB — объектно-ориентированная база данных, использующая иерархии, ассоциативные массивы, хеш-таблицы а также

Слайд 109Использование Объектно-ориентированных баз данных
Объектно-ориентированные базы данных хорошо подходят в том случае, когда
Использование Объектно-ориентированных баз данных
Объектно-ориентированные базы данных хорошо подходят в том случае, когда

Слайд 110Объектно-реляционные базы данных
В настоящее время применяется множество объектно-ориентированных языков программирования, а том
Объектно-реляционные базы данных
В настоящее время применяется множество объектно-ориентированных языков программирования, а том

Слайд 111Архитектура Oracle Application Server
Архитектура Oracle Application Server
Слайд 112СУБД Oracle9i
СУБД Oracle9i быстро превратилась в СУБД для всех типов данных –
СУБД Oracle9i
СУБД Oracle9i быстро превратилась в СУБД для всех типов данных –

Слайд 113Объектно-реляционная архитектура СУБД Oracle9i
Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками
Объектно-реляционная архитектура СУБД Oracle9i
Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками

Слайд 114Объектно-ориентированная разработка приложений
СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих
Объектно-ориентированная разработка приложений
СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих

Слайд 115Объектные типы данных
Объектный тип данных — это тип, определяемый пользователем, и задающий
Объектные типы данных
Объектный тип данных — это тип, определяемый пользователем, и задающий

Слайд 116Наследование
Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе.
Наследование
Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе.

Слайд 117Типы-коллекции
Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные
Типы-коллекции
Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные

Слайд 118Большие объекты
СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения
Большие объекты
СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения

Слайд 119Связывания для языков программирования
Полная поддержка объектно-реляционной системы типов Oracle доступна в
Связывания для языков программирования
Полная поддержка объектно-реляционной системы типов Oracle доступна в

Слайд 120Поддержка XML, дуализм XML/SQL
Сервер Oracle поддерживает не только реляционную, объектную, многомерную
Поддержка XML, дуализм XML/SQL
Сервер Oracle поддерживает не только реляционную, объектную, многомерную

Слайд 121Поддержка OLAP
Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для
Поддержка OLAP
Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для

Слайд 122Oracle 10g
Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа -
Oracle 10g
Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа -

Слайд 123Oracle Database 10g
Oracle Database 10g предназначена для эффективного развертывания на базе различных
Oracle Database 10g
Oracle Database 10g предназначена для эффективного развертывания на базе различных

Слайд 124Oracle Application Server 10g
Oracle Application Server 10g - это основанная на
Oracle Application Server 10g
Oracle Application Server 10g - это основанная на

Слайд 125Oracle Enterprise Manager 10g
Oracle Enterprise Manager 10g - это первое в
Oracle Enterprise Manager 10g
Oracle Enterprise Manager 10g - это первое в

Слайд 126Адаптивная платформа для Oracle
ASCC для Oracle – адаптивная инфраструктурная платформа для приложений
Адаптивная платформа для Oracle
ASCC для Oracle – адаптивная инфраструктурная платформа для приложений
Слайд 127Adaptive Services Control Center (ASCC)
Непрерывный мониторинг физических и виртуальных ресурсов
Ресурсы распределяются адаптивно
Adaptive Services Control Center (ASCC)
Непрерывный мониторинг физических и виртуальных ресурсов
Ресурсы распределяются адаптивно
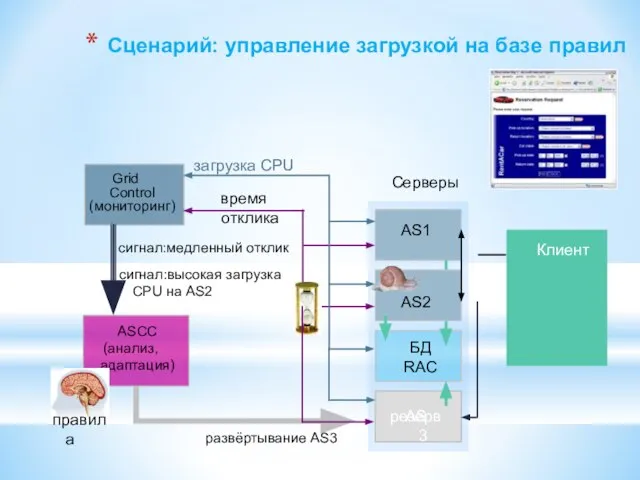
Слайд 128Сценарий: управление загрузкой на базе правил
AS1
БД
RAC
резерв
Серверы
ASCC
(анализ, адаптация)
время отклика
AS3
AS2
Клиент
загрузка CPU
сигнал:высокая загрузка CPU
Сценарий: управление загрузкой на базе правил
AS1
БД
RAC
резерв
Серверы
ASCC
(анализ, адаптация)
время отклика
AS3
AS2
Клиент
загрузка CPU
сигнал:высокая загрузка CPU
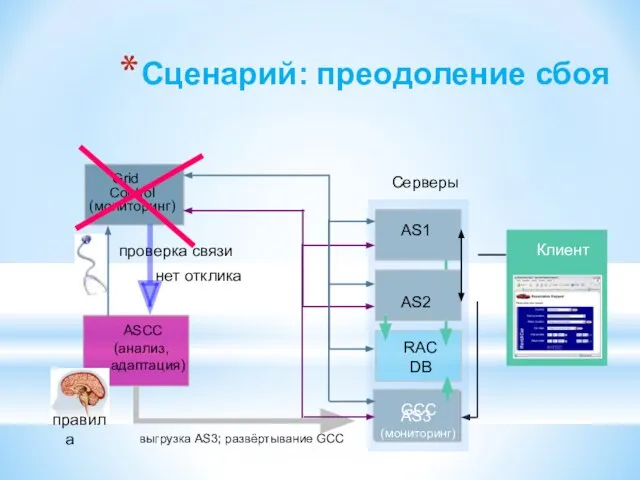
Слайд 129Сценарий: преодоление сбоя
AS1
RAC
DB
AS3
Серверы
ASCC
(анализ, адаптация)
GCC
AS2
Client
Клиент
(мониторинг)
Сценарий: преодоление сбоя
AS1
RAC
DB
AS3
Серверы
ASCC
(анализ, адаптация)
GCC
AS2
Client
Клиент
(мониторинг)
Слайд 130Недостатки SQL-хранилищ
Скорость работы. При высокой загруженности ресурса и достаточно большом количестве записей
Недостатки SQL-хранилищ
Скорость работы. При высокой загруженности ресурса и достаточно большом количестве записей

Слайд 131Нереляционный подход к организации БД - NoSQL
NoSQL хранилища данных имеют максимально упрощённую
Нереляционный подход к организации БД - NoSQL
NoSQL хранилища данных имеют максимально упрощённую

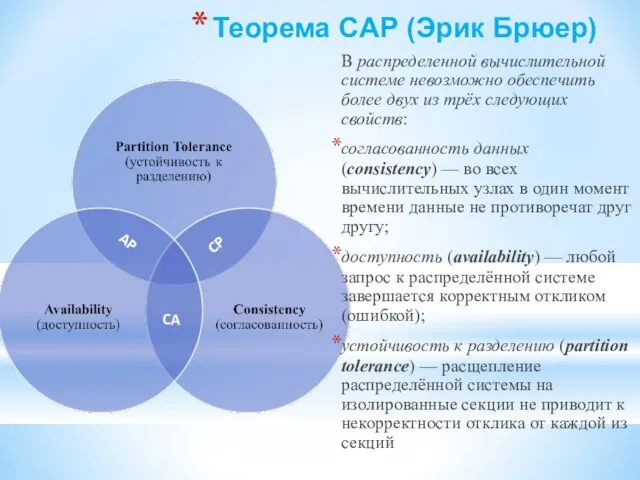
Слайд 132Теорема CAP (Эрик Брюер)
В распределенной вычислительной системе невозможно обеспечить более двух
Теорема CAP (Эрик Брюер)
В распределенной вычислительной системе невозможно обеспечить более двух
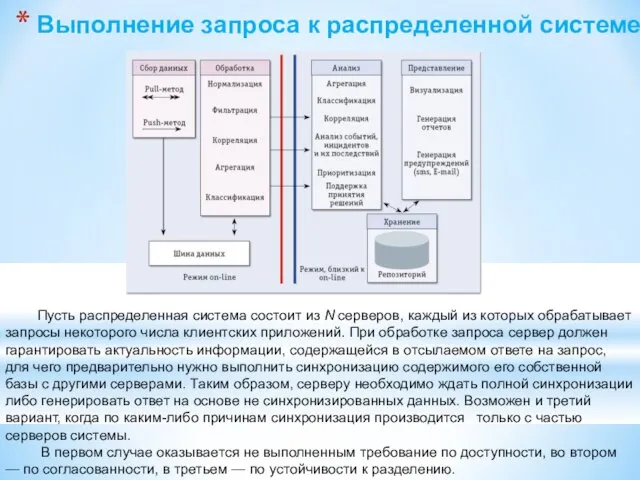
Слайд 133Пусть распределенная система состоит из N серверов, каждый из которых обрабатывает запросы
Пусть распределенная система состоит из N серверов, каждый из которых обрабатывает запросы
Слайд 134Классификация распределенных систем по видам выполняемых требований CAP
CA — система, во всех
Классификация распределенных систем по видам выполняемых требований CAP
CA — система, во всех

Слайд 135Типы СУБД с точки зрения CAP
Типы СУБД с точки зрения CAP
Слайд 136BASE (Basically Available, Soft State, Eventually consistent)
В любом из трех случаев не
BASE (Basically Available, Soft State, Eventually consistent)
В любом из трех случаев не

Слайд 137Масштабируемость
Одной из основных проблем реляционных баз данных, решение которых может быть достигнуто
Масштабируемость
Одной из основных проблем реляционных баз данных, решение которых может быть достигнуто

Слайд 138Репликация
В распределенных базах данных репликация состоит в хранении одних и тех же
Репликация
В распределенных базах данных репликация состоит в хранении одних и тех же

Слайд 139Шардинг (Sharding)
Другим подходом к горизонтальному масштабированию является шардинг (Sharding). Он представляет собой
Шардинг (Sharding)
Другим подходом к горизонтальному масштабированию является шардинг (Sharding). Он представляет собой

Слайд 140Шардинг (Sharding)
В распределенных системах оба исходных набора данных хранятся на множестве узлов,
Шардинг (Sharding)
В распределенных системах оба исходных набора данных хранятся на множестве узлов,

Слайд 141Консистентное хеширование
Для многих NoSQL-СУБД шардинг представляет собой одну из ключевых возможностей. При
Консистентное хеширование
Для многих NoSQL-СУБД шардинг представляет собой одну из ключевых возможностей. При

Слайд 142Добавление и удаление узлов
Идея состоит в присвоении узлам кластера идентификаторов из области
Добавление и удаление узлов
Идея состоит в присвоении узлам кластера идентификаторов из области
Слайд 143MapReduce
Одним из наиболее популярных подходов к распределенной обработке данных является модель MapReduce,
MapReduce
Одним из наиболее популярных подходов к распределенной обработке данных является модель MapReduce,

Слайд 144Разделение и Map для подсчёта слов в тексте
Разделение и Map для подсчёта слов в тексте
Слайд 145Группировка и Reduce для подсчёта слов в тексте
Группировка и Reduce для подсчёта слов в тексте

Слайд 146Внедрение модели MapReduce
Модель MapReduce, предоставляющая широкие возможности для распределенной обработки данных, внедрена
Внедрение модели MapReduce
Модель MapReduce, предоставляющая широкие возможности для распределенной обработки данных, внедрена

Слайд 147Классификация NoSQL
В зависимости от направленности и способов обработки данных можно различать
Классификация NoSQL
В зависимости от направленности и способов обработки данных можно различать

Слайд 148Хранилища типа «ключ-значение»
Хранилища «ключ-значение» («Key-Value») — базы данных, построенные на основе простой
Хранилища типа «ключ-значение»
Хранилища «ключ-значение» («Key-Value») — базы данных, построенные на основе простой

Слайд 149BerkeleyDB
Oracle BerkeleyDB (BDB) — высокопроизводительная встраиваемая база данных, реализованная в виде библиотеки. BDB
BerkeleyDB
Oracle BerkeleyDB (BDB) — высокопроизводительная встраиваемая база данных, реализованная в виде библиотеки. BDB

Слайд 150Dynamo и Voldemort
В основу СУБД от Amazon положен принцип «сбой оборудования -
Dynamo и Voldemort
В основу СУБД от Amazon положен принцип «сбой оборудования -

Слайд 151Redis
Redis — сетевое журналируемое хранилище данных типа «ключ-значение» с открытым исходным кодом. Redis
Redis
Redis — сетевое журналируемое хранилище данных типа «ключ-значение» с открытым исходным кодом. Redis

Слайд 152Применение хранилищ типа «ключ-значение»
Хранилища типа «ключ-значение» отлично подходят для таких типов данных,
Применение хранилищ типа «ключ-значение»
Хранилища типа «ключ-значение» отлично подходят для таких типов данных,

Слайд 153Колоночные хранилища
Идея хранить и обрабатывать данные по колонкам (столбцам), зародилась в области
Колоночные хранилища
Идея хранить и обрабатывать данные по колонкам (столбцам), зародилась в области

Слайд 154Cassandra
Схема поколоночного хранения данных на примере Cassandra
Apache Cassandra — распределённая СУБД, рассчитанная на
Cassandra
Схема поколоночного хранения данных на примере Cassandra
Apache Cassandra — распределённая СУБД, рассчитанная на
Слайд 155Особенности Cassandra
Столбец в Cassandra состоит из пары имя-значение, где имя также является
Особенности Cassandra
Столбец в Cassandra состоит из пары имя-значение, где имя также является

Слайд 156Google BigTable
Google BigTable — распределённое хранилище, разработанное Google специально для манипулирования огромным
Google BigTable
Google BigTable — распределённое хранилище, разработанное Google специально для манипулирования огромным

Слайд 157BigTable, хранящий веб-страницы в Google
На рисунке изображён пример использования BigTable для хранения
BigTable, хранящий веб-страницы в Google
На рисунке изображён пример использования BigTable для хранения
Слайд 158HBase
Apache HBase — нереляционная распределённая база данных с открытым исходным кодом; написана
HBase
Apache HBase — нереляционная распределённая база данных с открытым исходным кодом; написана

Слайд 159Таблица HBase
Таблицы HBase состоят из регионов — наборов строк в семействах столбцов.
Таблица HBase
Таблицы HBase состоят из регионов — наборов строк в семействах столбцов.

Слайд 160Использование колоночных хранилищ
Реляционные хранилища считают базовой единицей хранения данных строку, и это
Использование колоночных хранилищ
Реляционные хранилища считают базовой единицей хранения данных строку, и это

Слайд 161Использование колоночных хранилищ
Ещё одна интересная возможность — создание временных столбцов (например, у
Использование колоночных хранилищ
Ещё одна интересная возможность — создание временных столбцов (например, у

Слайд 162Документно-ориентированные хранилища
Центральным понятием этого подхода является «документ». Он инкапсулирует данные, как правило,
Документно-ориентированные хранилища
Центральным понятием этого подхода является «документ». Он инкапсулирует данные, как правило,

Слайд 163MongoDB
СУБД MongoDB управляет наборами JSON-подобных документов, хранимых в двоичном виде в формате
MongoDB
СУБД MongoDB управляет наборами JSON-подобных документов, хранимых в двоичном виде в формате

Слайд 164Основные возможности MongoDB
Достаточно гибкий язык для формирования запросов
Динамические запросы
Полная поддержка индексов
Профилирование запросов
Быстрые
Основные возможности MongoDB
Достаточно гибкий язык для формирования запросов
Динамические запросы
Полная поддержка индексов
Профилирование запросов
Быстрые

Слайд 165Структура данных MongoDB
Структура данных широко использует двунаправленный связанный список. Каждая коллекция данных
Структура данных MongoDB
Структура данных широко использует двунаправленный связанный список. Каждая коллекция данных
Слайд 166Модификация данных
Модификация данных происходит на месте. В случае если модификация увеличивает размер
Модификация данных
Модификация данных происходит на месте. В случае если модификация увеличивает размер

Слайд 167Репликация в MongoDB
MongoDB поддерживает репликацию по схеме «Ведущий-Ведомый», в основном для
Репликация в MongoDB
MongoDB поддерживает репликацию по схеме «Ведущий-Ведомый», в основном для
Слайд 168CouchDB
CouchDB — NoSQL-СУБД, разработанная Apache. Позволяет использовать в качестве полей документа скалярные
CouchDB
CouchDB — NoSQL-СУБД, разработанная Apache. Позволяет использовать в качестве полей документа скалярные

Слайд 169Особенности CouchDB
Запросы могут выполняться параллельно к множеству узлов - для этого
Особенности CouchDB
Запросы могут выполняться параллельно к множеству узлов - для этого

Слайд 170Масштабируемость
Масштабируемость достигается посредством так называемой инкрементальной репликации — изменения документа периодически копируются
Масштабируемость
Масштабируемость достигается посредством так называемой инкрементальной репликации — изменения документа периодически копируются

Слайд 171Использование документно-ориентированные хранилищ
Документно-ориентированные хранилища представляют собой очень удобную прослойку между схемами хранилищ
Использование документно-ориентированные хранилищ
Документно-ориентированные хранилища представляют собой очень удобную прослойку между схемами хранилищ

Слайд 172Хранилища графов
Базы данных на основе графов позволяют хранить сущности и связи между
Хранилища графов
Базы данных на основе графов позволяют хранить сущности и связи между

Слайд 173Сравнение структуры связей в реляционной и в графовой модели данных
Ещё одним преимуществом
Сравнение структуры связей в реляционной и в графовой модели данных
Ещё одним преимуществом
Слайд 174Neo4j — графовая база данных
Neo4j — графовая база данных с открытым исходным
Neo4j — графовая база данных
Neo4j — графовая база данных с открытым исходным

Слайд 175HyperGraphDB
HyperGraphDB — это расшириемая портативная распределённая встраиваемая система хранения данных с открытым
HyperGraphDB
HyperGraphDB — это расшириемая портативная распределённая встраиваемая система хранения данных с открытым

Слайд 176Использование хранилищ графов
Хранилища графов подходят для хранения плотно связанных данных, когда основной
Использование хранилищ графов
Хранилища графов подходят для хранения плотно связанных данных, когда основной

Слайд 177Достоинства и недостатки NoSQL
Можно сделать вывод о том, что NoSQL не является
Достоинства и недостатки NoSQL
Можно сделать вывод о том, что NoSQL не является

Слайд 178NoSQL или SQL?
Возникает вопрос: что лучше использовать — NoSQL или
NoSQL или SQL?
Возникает вопрос: что лучше использовать — NoSQL или

Слайд 179Выбор решения
Можно предложить подход при выборе типа хранилища для конкретного проекта. На
Выбор решения
Можно предложить подход при выборе типа хранилища для конкретного проекта. На

Слайд 180Hadoop— проект фонда Apache Software FoundationHadoop— проект фонда Apache Software Foundation, свободно
Hadoop— проект фонда Apache Software FoundationHadoop— проект фонда Apache Software Foundation, свободно

Слайд 181SQL и NoSQL
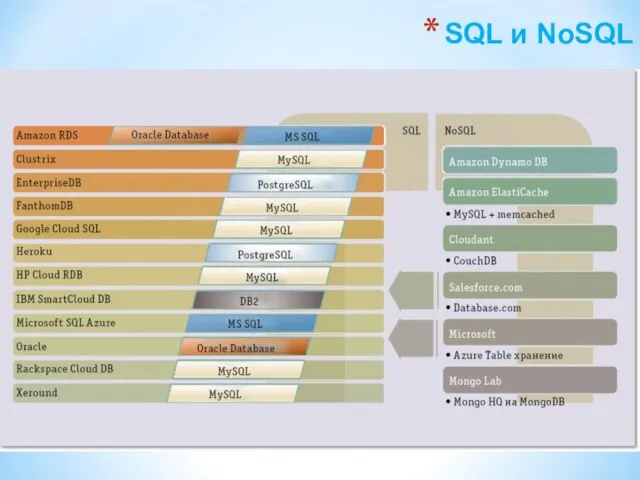
Одно приложение — много СУБД
SQL и NoSQL
Одно приложение — много СУБД
Слайд 182Классификация облачных инфраструктур
Origins of the Terms
• Both first commonly used in the
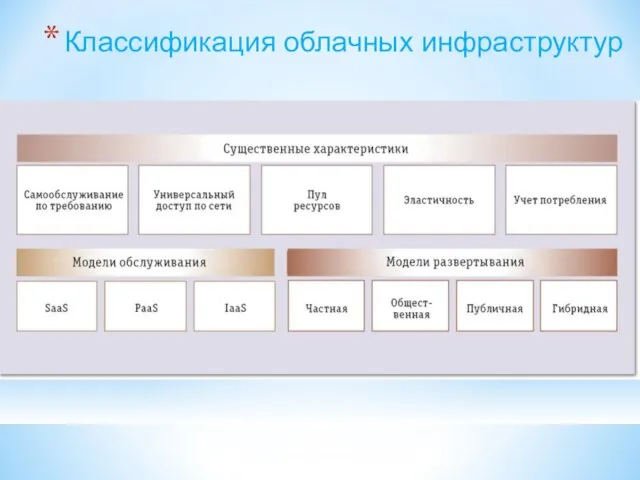
Классификация облачных инфраструктур
Origins of the Terms
• Both first commonly used in the
Слайд 183Облачные СУБД
СУБД, предоставляемая по подписке со всеми подобающими характеристиками — DBaaS (database as
Облачные СУБД
СУБД, предоставляемая по подписке со всеми подобающими характеристиками — DBaaS (database as

Слайд 184Требования к облачным СУБД
Модель аренды ресурсов с оплатой по мере использования, характерная
Требования к облачным СУБД
Модель аренды ресурсов с оплатой по мере использования, характерная

Слайд 185Новые архитектуры баз данных
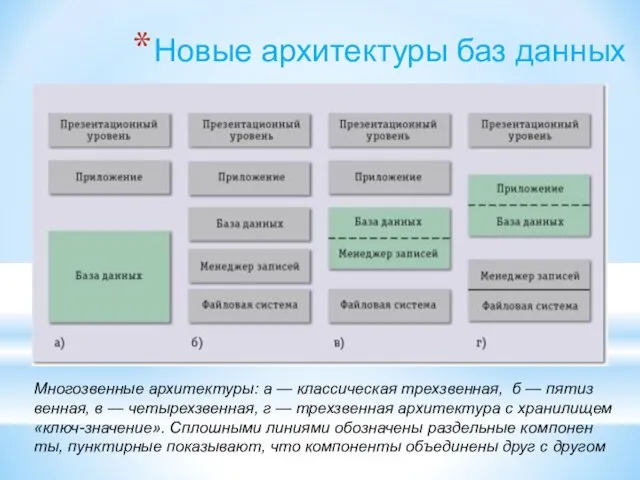
Многозвенные архитектуры: а — классическая трехзвенная, б — пятизвенная,
Новые архитектуры баз данных
Многозвенные архитектуры: а — классическая трехзвенная, б — пятизвенная,
Слайд 186Новые уровни данных
Традиционная трехзвенная архитектура была преобразована в пятиуровневую: презентационный уровень, приложение,
Новые уровни данных
Традиционная трехзвенная архитектура была преобразована в пятиуровневую: презентационный уровень, приложение,

Слайд 187Уровень менеджера записей
Менеджер записей расширяет функциональность файловой системы, предоставляя более мелкодисперсный доступ
Уровень менеджера записей
Менеджер записей расширяет функциональность файловой системы, предоставляя более мелкодисперсный доступ

Слайд 188Уровень баз данных
Этот уровень находится поверх менеджера записей, отвечая за обработку
Уровень баз данных
Этот уровень находится поверх менеджера записей, отвечая за обработку

Слайд 189Пятизвенная архитектура
В такой архитектуре каждый уровень представляет собой отдельный сервис. Самый
Пятизвенная архитектура
В такой архитектуре каждый уровень представляет собой отдельный сервис. Самый

Слайд 190Четырехзвенная разделенная
архитектура с файловым уровнем
Один из способов уменьшить трафик между
Четырехзвенная разделенная
архитектура с файловым уровнем
Один из способов уменьшить трафик между

Слайд 191Интеграция SQL и NoSQL
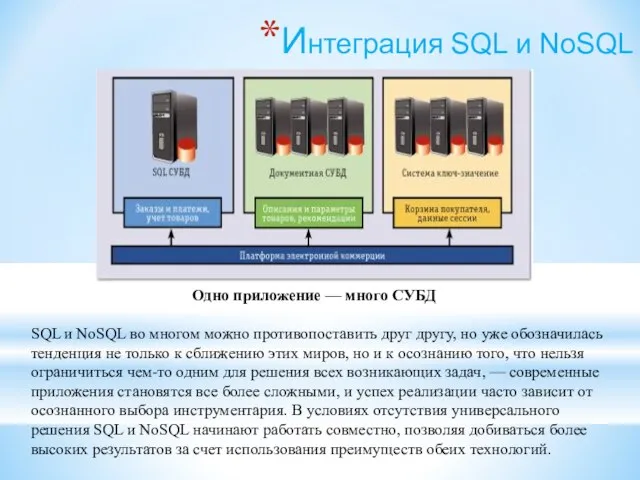
Одно приложение — много СУБД
SQL и NoSQL во многом
Интеграция SQL и NoSQL
Одно приложение — много СУБД
SQL и NoSQL во многом
Слайд 192Big Data definitions
Простое определение: Большие Данные те, что слишком велики и сложны,
Big Data definitions
Простое определение: Большие Данные те, что слишком велики и сложны,

Слайд 193How useful is Big Data ?
Большие должны быть доступны для поисковых систем,
How useful is Big Data ?
Большие должны быть доступны для поисковых систем,

Слайд 194Большие данные – горячая тема, потому что технологии сделали возможным анализ ВСЕХ
Большие данные – горячая тема, потому что технологии сделали возможным анализ ВСЕХ
Слайд 195Обвал данных
Каждый день в мире производится 2,5 квинтильона (1018) байтов данных. 90%
Обвал данных
Каждый день в мире производится 2,5 квинтильона (1018) байтов данных. 90%

Слайд 196Прогноз роста данных до 2015 года
Прогноз роста данных до 2015 года
Прогноз роста данных до 2015 года
Прогноз роста данных до 2015 года
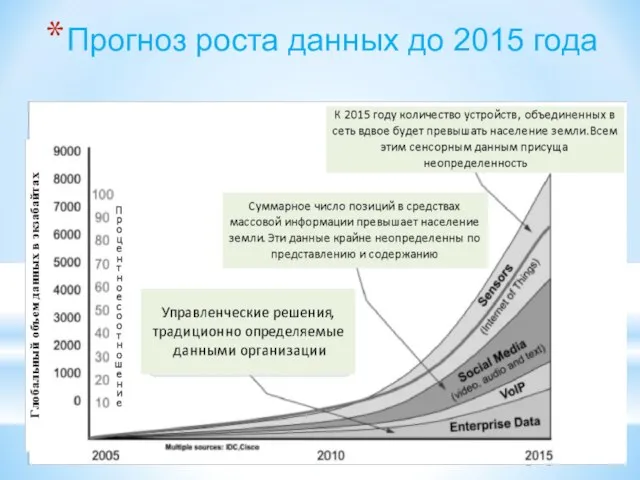
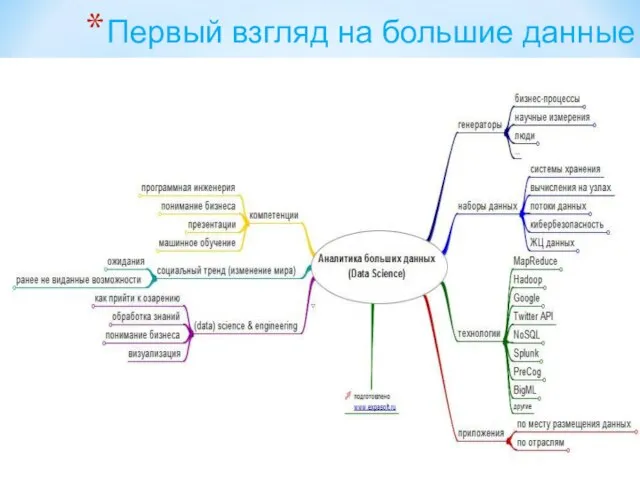
Слайд 197Первый взгляд на большие данные
Первый взгляд на большие данные
Слайд 198Инженерный взгляд
хранилища
системы хранения данных
облака
EMC
оборот
Oracle
IBM
Amazon
один
Инженерный взгляд
хранилища
системы хранения данных
облака
EMC
оборот
Oracle
IBM
Amazon
один
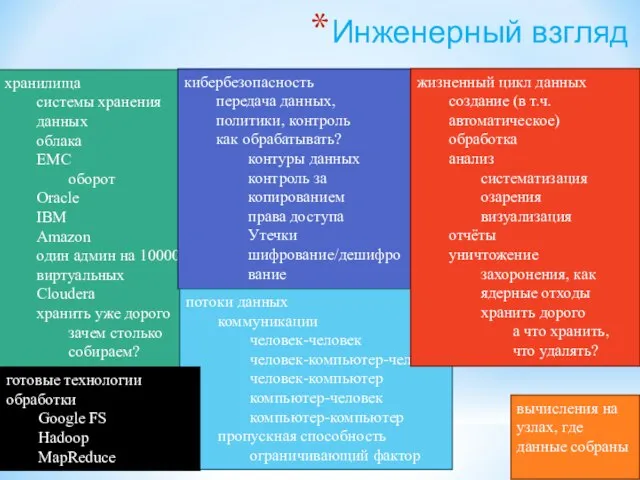

Слайд 200BI / Reporting
Стратегия IBM Big Data : приблизить аналитику к данным
IBM Big
BI / Reporting
Стратегия IBM Big Data : приблизить аналитику к данным
IBM Big

Слайд 201Изменение парадигмы
ИТ
Структурирует данные для ответа на вопрос
ИТ
Обеспечивает платформу для креативного анализа
Бизнес
Исследует что
Изменение парадигмы
ИТ
Структурирует данные для ответа на вопрос
ИТ
Обеспечивает платформу для креативного анализа
Бизнес
Исследует что
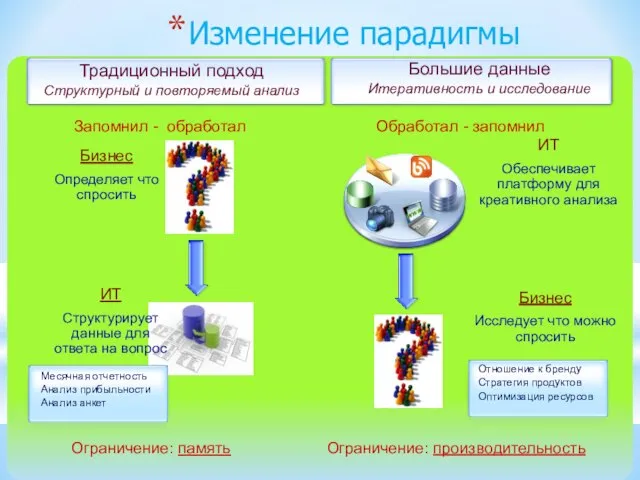
Слайд 202Вступление в эру Big Data
We are BIG!
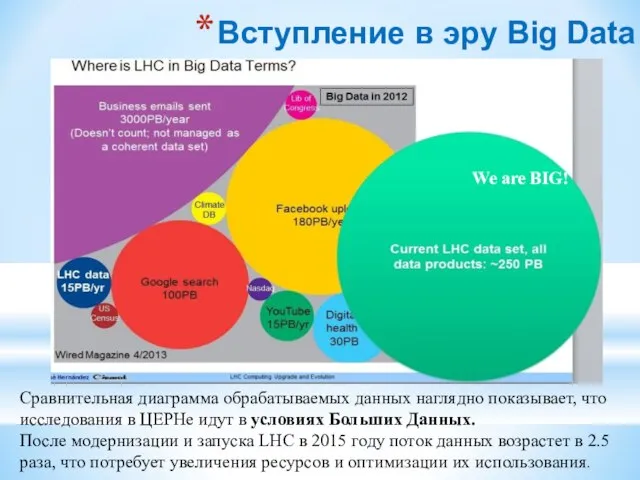
Сравнительная диаграмма обрабатываемых данных наглядно показывает,
Вступление в эру Big Data
We are BIG!
Сравнительная диаграмма обрабатываемых данных наглядно показывает,
Слайд 203CERN “Big Data”
Physics Data on CASTOR/EOS
LHC experiments produce ~10GB/s 25PB/year
User Data on
CERN “Big Data”
Physics Data on CASTOR/EOS
LHC experiments produce ~10GB/s 25PB/year
User Data on

Слайд 204В эксперименте ATLAS на Большом адронном коллайдере разработана платформа для управления вычислительными
В эксперименте ATLAS на Большом адронном коллайдере разработана платформа для управления вычислительными

Слайд 205 Интеграция технологий распределенных вычислений для управления большими данными
PanDa, как платформа,
Интеграция технологий распределенных вычислений для управления большими данными
PanDa, как платформа,

Слайд 2068/6/13
Big Data Workshop
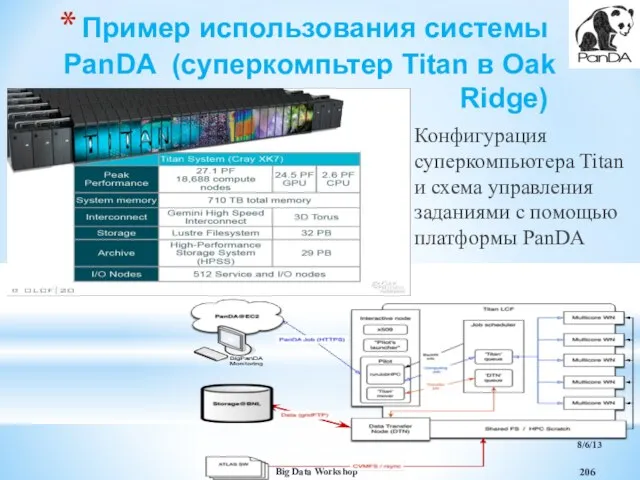
Пример использования системы PanDA (суперкомпьтер Titan в Oak Ridge)
Конфигурация
8/6/13
Big Data Workshop
Пример использования системы PanDA (суперкомпьтер Titan в Oak Ridge)
Конфигурация
Слайд 207Ресурсы, доступные с помощью платформы PanDA
OLCF
Проекты с суперкомпьютерными центрами НИЦ КИ, ННГУ,
Ресурсы, доступные с помощью платформы PanDA
OLCF
Проекты с суперкомпьютерными центрами НИЦ КИ, ННГУ,

Слайд 208Data Mining to deal with Big Data
Data Mining (DM) - “Это
Data Mining to deal with Big Data
Data Mining (DM) - “Это

 Графич дизайн (1)
Графич дизайн (1) Образование и наука конца XIX в.-начало XX в
Образование и наука конца XIX в.-начало XX в Я і мае сябры. На вуліцы. (Тэма 16)
Я і мае сябры. На вуліцы. (Тэма 16) Путешествие в лес
Путешествие в лес ИСПАНИЯ
ИСПАНИЯ Система GPS-мониторинга автотранспортаBenish GPS Ukraine
Система GPS-мониторинга автотранспортаBenish GPS Ukraine Презентация на тему Цивилизация Инков
Презентация на тему Цивилизация Инков Презентация по физике на тему _Перемещение при прямолинейном равномерном движении_ (9 класс) (1)
Презентация по физике на тему _Перемещение при прямолинейном равномерном движении_ (9 класс) (1) Презентация на тему Происхождение и развитие человека (6 класс)
Презентация на тему Происхождение и развитие человека (6 класс) Партизаны и народные герои Отечественной войны 1812 г.
Партизаны и народные герои Отечественной войны 1812 г. prezent_nachni_s_sebya
prezent_nachni_s_sebya Заболевания, связанные с железами внутренней секреции
Заболевания, связанные с железами внутренней секреции Виды подач
Виды подач Презентация на тему Правила поведения на водоемах
Презентация на тему Правила поведения на водоемах  Стресс. Последствия влияния стресса на человека
Стресс. Последствия влияния стресса на человека Презентация на тему Древняя Русь (4 класс)
Презентация на тему Древняя Русь (4 класс)  Когда был принят Государственный флаг Республики Адыгея?
Когда был принят Государственный флаг Республики Адыгея? «Инженеры будущего 2011»
«Инженеры будущего 2011» Почему их так назвали?
Почему их так назвали? Presentation Title
Presentation Title  ВСЕГО ЛИШЬ ОДИН МИФ ОБ АВТОРСКОМ ПРАВЕ В ИНТЕРНЕТЕ Александр ЛЯХОВ 15.06.2011
ВСЕГО ЛИШЬ ОДИН МИФ ОБ АВТОРСКОМ ПРАВЕ В ИНТЕРНЕТЕ Александр ЛЯХОВ 15.06.2011 Формирование Универсальных Учебных Действий
Формирование Универсальных Учебных Действий Методические аспекты оценки эффективности применения ОПН для повышения грозоупорности ВЛ
Методические аспекты оценки эффективности применения ОПН для повышения грозоупорности ВЛ Государственная Дума Федерального собрания РФ второго созыва (16.01.1996 - 24.12.1999)
Государственная Дума Федерального собрания РФ второго созыва (16.01.1996 - 24.12.1999) На земле Эллады
На земле Эллады Rights of Persons with
Rights of Persons with Горькая правда о пиве
Горькая правда о пиве Организация систем хранения данных на базе вычислительных кластеров
Организация систем хранения данных на базе вычислительных кластеров