- Базы данных

Содержание
- 2. Основные темы лекций по курсу СУБД 1. Основные понятия баз данных. Этапы развития СУБД. Требования к
- 3. Темы лекций 1. Язык PL/SQL, его структура, основные операторы. 2. Курсоры, операторы работы с курсором, оператор
- 4. Литература Дейт К. Введение в системы баз данных. – 8 издание, М., Вильямс, 2005 Т. Конноли,
- 5. PL/SQL (Procedural Language) — процедурное расширение языка SQL PL/SQL - Procedural Language. Как видно из его
- 6. PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к конфигурированию языка 3GL. В
- 7. Модель клиент — сервер PL/SQL в среде клиент /сервер
- 8. Многие приложения для работы с базами данных создаются с использованием модели клиент /сервер. Сама программа размещается
- 9. Блок PL/SQL Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из блоков, которые могут
- 10. Допустимы следующие виды блоков: Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются только один раз
- 11. Лексические единицы Набор символов PL/SQL При работе с PL/SQL допускается использование символов из определенного набора знаков.
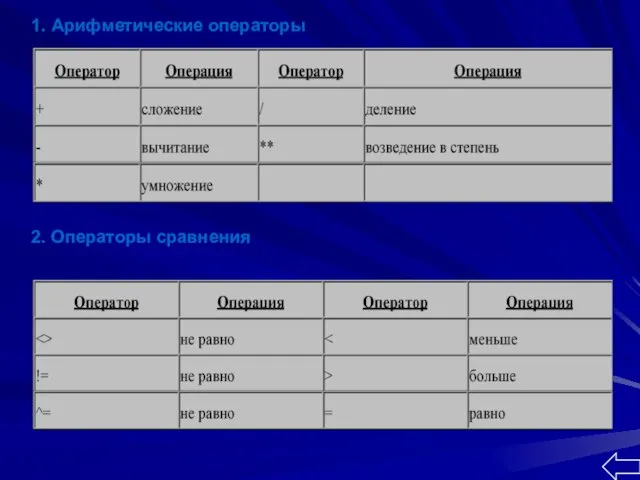
- 12. 2. Операторы сравнения 1. Арифметические операторы
- 13. Идентификаторы Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов следует руководствоваться следующими
- 14. Типы данных Тип Подтип NUMBER DECIMAL, REAL, FLOAT, NUMERIC (precision, scale) INTEGER, SMALLINT, CHAR (length) VARCHAR2
- 15. Записи PL/SQL Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно работать с несколькими
- 16. Чтобы присвоить одной записи значение другой они должны быть одного типа. Хотя записи имеют одинаковые имена
- 17. Управляющие структуры PL/SQL Структуры управления являются основой любого языка программирования, поскольку большинство реальных приложений должно уметь
- 18. Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации, когда требуется проверить выполнение
- 19. Пример DECLARE V_num1 NUMBER; V_num2 NUMBER; V_REZ VARCHAR2(7); BEGIN ….. IF V _num1 THEN V_REZ :=
- 20. Пример IF quantity > 15 THEN …; -- скидка 15% ELSIF quantity > 10 THEN …;
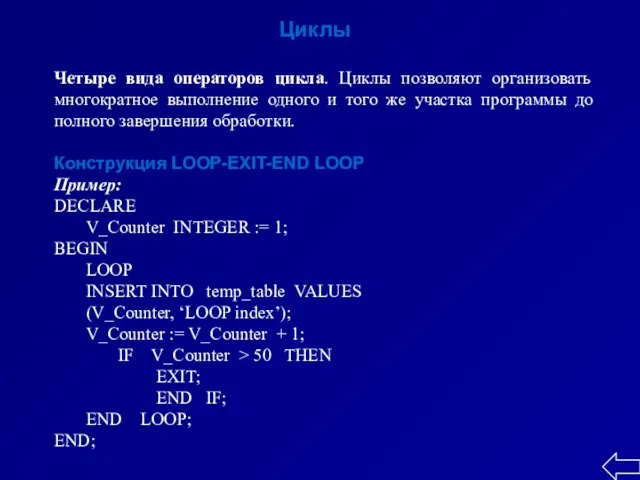
- 21. Циклы Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того же участка программы
- 22. Конструкция LOOP-EXIT WHEN-END LOOP Оператор EXIT WHEN условие эквивалентен оператору : IF условие THEN EXIT; END
- 23. Конструкция WHILE-LOOP-END LOOP Пример: DECLARE V_Counter INTEGER BEGIN WHILE V_Counter INSERT INTO temp_table VALUES (V_Counter, ‘LOOP
- 24. Конструкция FOR-IN [REVERSE] -LOOP-END LOOP Пример: BEGIN FOR V_Counter IN 1..50 LOOP INSERT INTO temp_table VALUES
- 25. Присваивание переменным значений базы данных В зависимости от числа возвращаемых запросом строк используются два метода. SELECT
- 26. Курсоры Курсор - это указатель на контекстную область с помощью которого программа PL/SQL может управлять контекстной
- 27. Явно объявляемые курсоры Явное объявление курсора производится в секции DECLARE, причем указанный в определении SQL-оператор может
- 28. 1) Объявление курсора При объявлении курсора ему назначается имя и ставится в соответствие некоторый оператор SELECT.
- 29. 2) Открытие курсора для запроса Синтаксис открытия курсора таков: OPEN имя_курсора; где имя_курсора - предварительно объявленный
- 30. 3) Выбор результатов в переменные PL/SQL Производится считывание строк из курсора. Частью оператора FETCH является список
- 31. 4) Закрытие курсора Когда выбран весь активный набор, курсор следует закрыть. Это означает, что программа закончила
- 32. Курсорные атрибуты В PL/SQL существует 4 атрибута, которые применимы к курсорам: %FOUND – это логический атрибут.
- 33. Неявно объявляемые курсоры Оператор select указывается в теле блока, и PL/SQL берет на себя всю заботу
- 34. Пример явного(explicit) курсора DECLARE /*Выходные переменные для хранения результатов запроса */ v_StudentID students. Id%TYPE; v_FirstName students.
- 35. Пример неявного(implicit) курсора BEGIN UPDATE rooms SET number_seats = 100 WHERE room_id = 999; /* Если
- 36. Примеры CURSOR ordercursor IS select id, customerid, orderdate from orders; DECLARE CURSOR ordercursor (ordernumber NUMBER) IS
- 37. Оператор GOTO GOTO - оператор безусловного перехода Обработка ошибок (блок EXCEPTION) PL/SQL имеет встроенные исключительные ситуации
- 38. Процедуры Создание процедуры Синтаксис оператора CREATE OR REPLACE PROCEDURE таков: CREATE [OR REPLACE] PROCEDURE имя_процедуры [(аргумент
- 39. Тело процедуры Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений, выполняемый раздел и раздел
- 40. Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время разработки процедур эта операция
- 41. Значения параметров по умолчанию Как и переменные, формальные параметры процедуры или функции могут иметь значения по
- 42. Удаление процедур Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления процедуры выглядит следующим
- 43. Пример процедуры CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS last VARCHAR2(50); first VARCHAR2(50); BEGIN SELECT lastname,
- 44. Функции Создание функций Функции очень похожи на процедуры. Как те, так и другие принимают аргументы, которые
- 45. Описание функций Синтаксис для создания хранимой функции очень похож на синтаксис для создания процедуры: CREATE [OR
- 46. Оператор RETURN Внутри тела функции оператор RETURN применяется для возврата управления программой и результата выполнения функции
- 47. Свойства функций Многие из свойств функций аналогичны свойствам процедур: Функции могут возвращать более одного значения при
- 48. CREATE OR REPLACE FUNCTION AlmostFull( p_Department classes.department%TYPE, p_Course classes.course%TYPE) RETURN BOOLEAN IS V_CurrentStudents NUMBER; V_MaxStudents NUMBER;
- 49. Пример функции CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2) RETURN INTEGER AS custid INTEGER;
- 50. Агрегирующие функции Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти функции можно применять
- 51. MAX COUNT
- 52. AVG MIN SUM
- 53. Модули (Пакеты) Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном месте. Модуль состоит
- 54. Описание модуля CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS} описание_процедуры описание_функции объявление_переменной определение_типа объявление_исключительной_ситуации объявление_курсора END
- 55. Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений, за исключением объявлений процедуры
- 56. Тело модуля Тело модуля (package body) - это объект словаря данных, хранящийся отдельно от заголовка модуля.
- 57. Модули и области действия Любой объект, объявленный в заголовке модуля, находится в области действия и видим
- 58. Инициализация модуля При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль считывается с диска
- 59. Пример модуля генерации случайных чисел CREATE OR REPLACE PACKAGE Random AS PROCEDURE ChangeSeed (p_NewSeed IN NUMBER);
- 60. PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS BEGIN v_Seed := p_NewSeed; END ChangeSeed; FUNCTION Rand RETURN NUMBER IS
- 61. CREATE OR REPLACE PACKAGE ClassPackege AS PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE, p_Department IN classes.departmen%TYPE, p_Courses
- 62. FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS BEGIN --Возвращает случайное целое число в диапазоне от 1
- 63. Пример модуля (пакета) CREATE OR REPLACE PACKAGE customermanager IS PROCEDURE newcustomer (company IN VARCHAR2 DEFAULT null,
- 64. Триггеры Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с разделом объявлений, выполняемым
- 65. Создание триггеров CREATE [OR REPLACE] TRIGGER имя_триггера {BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу [FOR EACH
- 66. Триггеры можно использовать для: Реализации сложных ограничений целостности данных, которые невозможно осуществить через описательные ограничения, устанавливаемые
- 67. Элементы триггера Обязательными элементами триггера являются его имя, активизирующее событие и тело. Условие WHEN необязательно. Имена
- 68. Удаление и запрещение триггеров Триггеры, как и процедуры, и модули, и функции, можно удалять. Синтаксис таков:
- 69. Порядок активизации триггера Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков: 1. Выполняется операторный
- 70. CREATE [OR REPLACE] TRIGGER classesBEstatement BEFORE UPDATE ON classes BEGIN INSERT INTO temp_table (num_col, char_col) VALUES
- 71. CREATE [OR REPLACE] TRIGGER classesBERow BEFORE UPDATE ON classes FOR EACH ROW BEGIN INSERT INTO temp_table
- 72. Ограничения, налагаемые на триггеры Тело триггера является блоком PL/SQL. Любой оператор, выполнение которого разрешено в блоке
- 73. Использование :old и :new в строковых триггерах Строковый триггер срабатывает один раз для каждой строки, обрабатываемой
- 75. Доступ к значениям столбцов Доступ к значениям столбцов в триггере осуществляется с помощью корреляционных имен: :NEW.имя_столбца
- 76. Примеры триггеров: 1) CREATE TRIGGER deletecustomer BEFORE DELETE ON customer FOR EACH ROW BEGIN INSERT INTO
- 77. Примеры триггеров: 3) CREATE TRIGGER updatestockquantity AFTER INSERT OR DELETE OR UPDATE OF quantity ON item
- 78. Параллельные архитектуры серверов баз данных Три основные архитектурные направления: ∙ Симметричные многопроцессорные системы (SMP) - форма
- 79. Группы требований, определяющих качества современной СУБД ∙ масштабируемость; ∙ производительность; ∙ возможность смешанной загрузки разными типами
- 80. Группы требований, определяющих качества современной СУБД Постоянная доступность данных реализуется с помощью механизмов: ∙ оперативное администрирование;
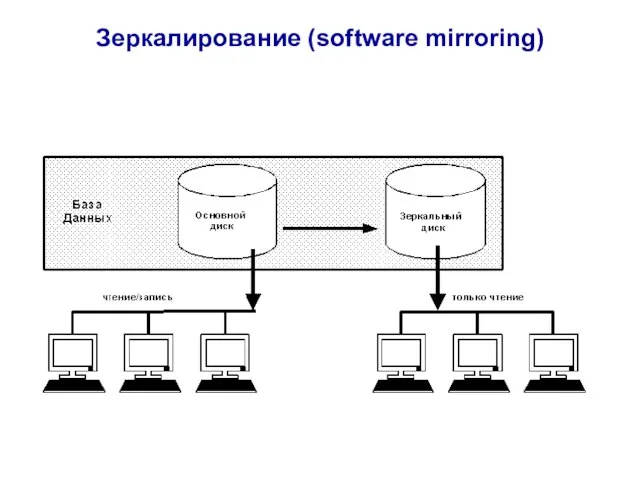
- 81. Зеркалирование (software mirroring)
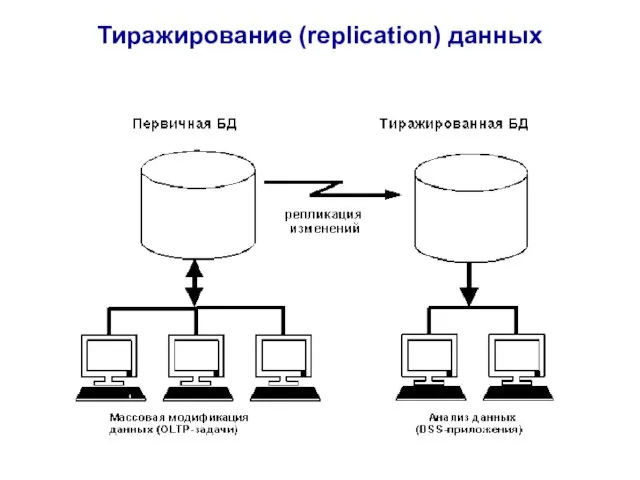
- 82. Тиражирование (replication) данных
- 83. Распределенные системы баз данных Ядром системы управления распределенными информационными ресурсами являются распределенная база данных и система
- 84. Правила К. Дейта для распределенных баз данных: Локальная автономность Никакой конкретный сервис не должен возлагаться на
- 85. Модели распределенных баз данных Однородные системы, если СУБД –одинаковые, иначе – неоднородные системы
- 86. Фрагментация и тиражирование Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх» Проектирование «сверху вниз»
- 87. Модели тиражирования данных
- 88. Интеграция распределенных баз данных «снизу-вверх» Проектирование распределенных баз данных «снизу вверх» - объединение схем уже существующих
- 89. Средства защиты информации Можно назвать следующие основные направления борьбы с потенциальными угрозами конфиденциальности и целостности данных:
- 90. Ключевые механизмы безопасности: ∙ идентификация и аутентификация; ∙ управление доступом (системные привилегии, объектные привилегии); ∙ механизм
- 91. Некоторые определения Объект - пассивная единица информационного обмена, используется как синоним понятия данные. Субъект - активная
- 92. Аутентификация/авторизация при помощи паролей 1. Профили пользователей. 2. Профили процессов. Подобный метод реализован в технологии аутентификации
- 93. Инкапсуляция передаваемой информации в специальных протоколах обмена 1. Инфраструктуры с открытыми ключами. Использование подобных методов в
- 94. Ограничение информационных потоков Firewalls. Метод подразумевает создание между локальной и глобальной сетями специальных промежуточных серверов, которые
- 95. Метки безопасности Для реализации принудительного управления доступом с субъектами и объектами ассоциируются метки безопасности. Метка субъекта
- 96. Принудительное управление доступом Принудительное управление доступом основано на сопоставлении меток безопасности субъекта и объекта. Субъект может
- 97. Промежуточное программное обеспечение (Middleware) В распределенной неоднородной среде ППО играет роль «информационной шины», надстроенной над сетевым
- 98. Типы ППО
- 99. Промежуточное программное обеспечение баз данных ППО баз данных обеспечивает доступ к локальному или удаленному ресурсу данных
- 100. Доступ к базам данных Системы прозрачного доступа к БД представляют собой наиболее развитый сектор рынка ППО.
- 101. Доступ к базам данных Использование MW доступа к БД широко применяется в корпоративных системах поддержки принятия
- 102. Архитектура ODBC(OPEN DATABASE CONNECTIVITY) SQL - приложение Администратор ODBC Драйверы ODBC для различных СУБД локальные или
- 103. Существует 4 важных этапа (шага) процедуры запроса данных через ODBC API. Шаг 1 - установление соединения.
- 104. Недостатки реляционных СУБД ∙ Слабое представление сущностей реального мира ∙ Семантическая перегрузка ∙ Слабая поддержка ограничений
- 105. Манифест систем объектно-ориентированных баз данных Обязательные свойства: золотые правила Система объектно-ориентированных баз данных должна удовлетворять двум
- 106. Преимущества и недостатки ООСУБД Преимущества: ∙ Улучшенные возможности моделирования ∙ Расширяемость ∙ Устранение проблемы несоответствия ∙
- 107. Объектная модель данных В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется следующими свойствами. ▪
- 108. Объект, тип Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация определяет внешние характеристики
- 109. Идентификатор объекта Как это следует из модели данных, каждый объект в базе данных уникален. Существует несколько
- 110. Новые типы данных Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и
- 111. Оптимизация ядра СУБД Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями для него являются кэширование
- 112. Язык СУБД и запросы Общепризнанны две группы вариантов языков запросов. Язык OQL (Object Query Language) для
- 113. Транзакции Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках сеанса работы с
- 114. Блокировки Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения одновременного изменения данных.
- 115. Перемещение объектов Миграция объектов: постоянное их перемещение, например в другую базу данных. В качестве примера можно
- 116. Основы объектно-ориентированного программирования Рассмотрим объект Student. Студент имеет атрибуты, т.е. свойства: имя (first_name), фамилию (last_name), профилирующую
- 117. Абстракция Как было показано на примере программных модулей, атрибуты и методы объекта достаточно точно реализуют абстрактное
- 118. Объектно-реляционные базы данных В настоящее время применяется множество объектно-ориентированных языков программирования, а том числе C++ и
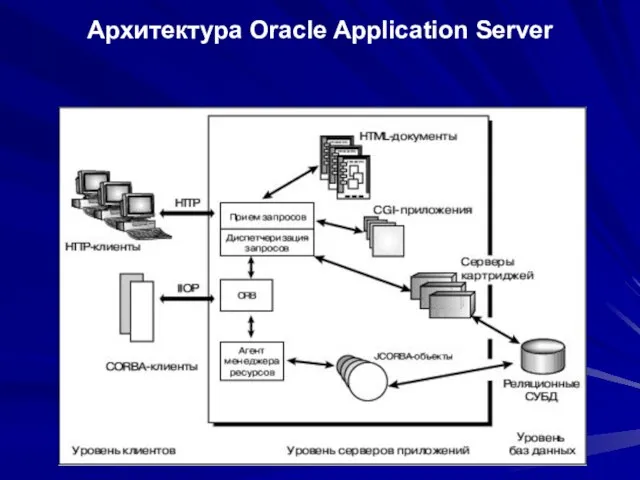
- 119. Архитектура Oracle Application Server
- 120. СУБД Oracle9i СУБД Oracle9i быстро превратилась в СУБД для всех типов данных – от простых до
- 121. Объектно-реляционная архитектура СУБД Oracle9i Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками для создания их
- 122. Объектно-ориентированная разработка приложений СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих связывания для различных
- 123. Объектные типы данных Объектный тип данных — это тип, определяемый пользователем, и задающий как структуру (атрибуты),
- 124. Объектные типы Корпорация Oracle расширила SQL, чтобы позволить пользователям: ∙ определять свои собственные типы (которые представляют
- 125. СУБД Oracle9i позволяет пользователям рассматривать объектные данные как реляционные. Например, пользователи могут использовать SQL для запросов
- 126. Наследование Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе. Наследование типов позволяет
- 127. Иерархия типов Корневой тип иерархии создается с помощью оператора CREATE TYPE, в котором должен быть указано
- 128. Типы-коллекции Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные элементы. Каждый элемент
- 129. Большие объекты СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения проблем хранения изображений,
- 130. Связывания для языков программирования Полная поддержка объектно-реляционной системы типов Oracle доступна в связываниях для ряда языков
- 131. Надежность и масштабируемость Real Application Cluster (RAC) Достижением Oracle 9i в области обеспечения высокой надежности и
- 132. Поддержка XML, дуализм XML/SQL Сервер Oracle поддерживает не только реляционную, объектную, многомерную модель данных, но и
- 133. Поддержка OLAP Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для аналитических систем более
- 134. Механизм Oracle Streams В СУБД Oracle существует много различных вариантов передачи данных и сообщений о событиях
- 135. Oracle 10g Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа - систем распределенных вычислений
- 136. Oracle Database 10g Oracle Database 10g предназначена для эффективного развертывания на базе различных типов оборудования, от
- 137. Oracle Application Server 10g Oracle Application Server 10g - это основанная на стандартах интегрированная программная платформа,
- 138. Oracle Enterprise Manager 10g Oracle Enterprise Manager 10g - это первое в отрасли программное обеспечение, разработанное
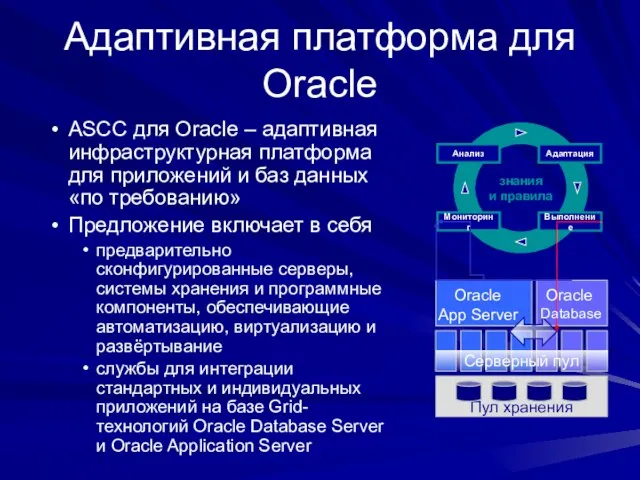
- 139. Адаптивная платформа для Oracle Серверный пул Oracle App Server Oracle Database Пул хранения ASCC для Oracle
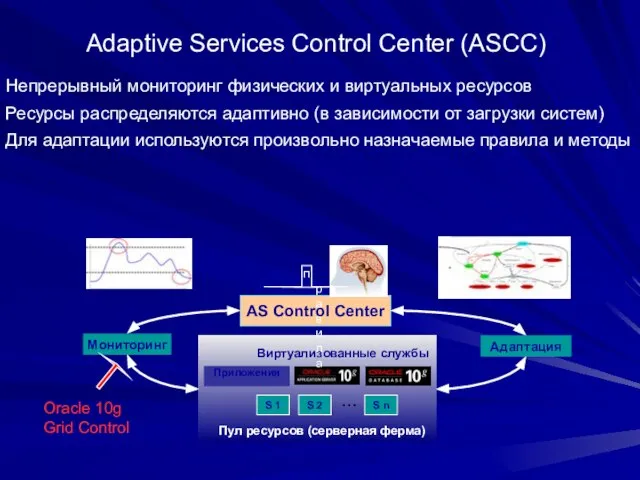
- 140. Adaptive Services Control Center (ASCC) Непрерывный мониторинг физических и виртуальных ресурсов Ресурсы распределяются адаптивно (в зависимости
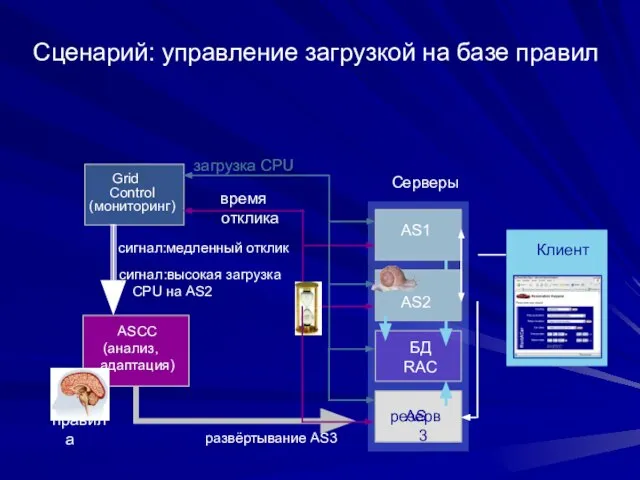
- 141. Сценарий: управление загрузкой на базе правил AS1 БД RAC резерв Серверы ASCC (анализ, адаптация) время отклика
- 143. Скачать презентацию

Слайд 3Темы лекций
1. Язык PL/SQL, его структура, основные операторы.
2. Курсоры, операторы работы с курсором,
Темы лекций
1. Язык PL/SQL, его структура, основные операторы.
2. Курсоры, операторы работы с курсором,

Слайд 4Литература
Дейт К. Введение в системы баз данных. – 8 издание, М., Вильямс,
Литература
Дейт К. Введение в системы баз данных. – 8 издание, М., Вильямс,

Слайд 5PL/SQL (Procedural Language) — процедурное расширение языка SQL
PL/SQL - Procedural Language. Как
PL/SQL (Procedural Language) — процедурное расширение языка SQL
PL/SQL - Procedural Language. Как

Слайд 6PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к
PL/SQL уникален тем, что соединяет гибкость SQL с мощью и способностью к

Слайд 7Модель клиент — сервер
PL/SQL в среде клиент /сервер
Модель клиент — сервер
PL/SQL в среде клиент /сервер

Слайд 8Многие приложения для работы с базами данных создаются с использованием модели клиент
Многие приложения для работы с базами данных создаются с использованием модели клиент

Слайд 9Блок PL/SQL
Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из
Блок PL/SQL
Базовой единицей PL/SQL является блок (block). Все программы PL/SQL состоят из

Слайд 10Допустимы следующие виды блоков:
Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются
Допустимы следующие виды блоков:
Анонимные (непоименованные) блоки создаются, как правило, динамически и выполняются

Слайд 11Лексические единицы
Набор символов PL/SQL
При работе с PL/SQL допускается использование символов из
Лексические единицы
Набор символов PL/SQL
При работе с PL/SQL допускается использование символов из

Слайд 122. Операторы сравнения
1. Арифметические операторы
2. Операторы сравнения
1. Арифметические операторы
Слайд 13Идентификаторы
Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов
Идентификаторы
Идентификаторы используются для именования переменных, курсоров, типов и подпрограмм. При выборе идентификаторов

Слайд 14Типы данных
Тип Подтип
NUMBER DECIMAL, REAL, FLOAT, NUMERIC
(precision, scale) INTEGER, SMALLINT,
CHAR
Типы данных
Тип Подтип
NUMBER DECIMAL, REAL, FLOAT, NUMERIC
(precision, scale) INTEGER, SMALLINT,
CHAR

Слайд 15Записи PL/SQL
Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно
Записи PL/SQL
Записи (records) PL/SQL аналогичны структурам языка С. С помощью записи можно

Слайд 16Чтобы присвоить одной записи значение другой они должны быть одного типа.
Хотя
Чтобы присвоить одной записи значение другой они должны быть одного типа.
Хотя

Слайд 17Управляющие структуры PL/SQL
Структуры управления являются основой любого языка программирования, поскольку большинство реальных
Управляющие структуры PL/SQL
Структуры управления являются основой любого языка программирования, поскольку большинство реальных

Слайд 18Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации,
Три типа условного оператора IF. При написании компьютерных программ неоднократно возникают ситуации,

Слайд 19Пример
DECLARE
V_num1 NUMBER;
V_num2 NUMBER;
V_REZ VARCHAR2(7);
BEGIN
…..
IF V _num1 <
Пример
DECLARE
V_num1 NUMBER;
V_num2 NUMBER;
V_REZ VARCHAR2(7);
BEGIN
…..
IF V _num1 <

Слайд 20Пример
IF quantity > 15
THEN …; -- скидка 15%
ELSIF quantity
Пример
IF quantity > 15
THEN …; -- скидка 15%
ELSIF quantity

Слайд 21Циклы
Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того
Циклы
Четыре вида операторов цикла. Циклы позволяют организовать многократное выполнение одного и того
Слайд 22Конструкция LOOP-EXIT WHEN-END LOOP
Оператор EXIT WHEN условие эквивалентен оператору : IF
Конструкция LOOP-EXIT WHEN-END LOOP
Оператор EXIT WHEN условие эквивалентен оператору : IF

Слайд 23Конструкция WHILE-LOOP-END LOOP
Пример:
DECLARE
V_Counter INTEGER
BEGIN
WHILE V_Counter <= 50 LOOP
Конструкция WHILE-LOOP-END LOOP
Пример:
DECLARE
V_Counter INTEGER
BEGIN
WHILE V_Counter <= 50 LOOP

Слайд 24Конструкция FOR-IN [REVERSE] -LOOP-END LOOP
Пример: BEGIN
FOR V_Counter IN 1..50 LOOP
Конструкция FOR-IN [REVERSE] -LOOP-END LOOP
Пример: BEGIN
FOR V_Counter IN 1..50 LOOP
![Конструкция FOR-IN [REVERSE] -LOOP-END LOOP Пример: BEGIN FOR V_Counter IN 1..50 LOOP](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381639/slide-23.jpg)
Слайд 25Присваивание переменным значений базы данных
В зависимости от числа возвращаемых запросом строк используются
Присваивание переменным значений базы данных
В зависимости от числа возвращаемых запросом строк используются

Слайд 26Курсоры
Курсор - это указатель на контекстную область с помощью которого программа PL/SQL
Курсоры
Курсор - это указатель на контекстную область с помощью которого программа PL/SQL

Слайд 27Явно объявляемые курсоры
Явное объявление курсора производится в секции DECLARE, причем указанный в
Явно объявляемые курсоры
Явное объявление курсора производится в секции DECLARE, причем указанный в

Слайд 281) Объявление курсора
При объявлении курсора ему назначается имя и ставится в
1) Объявление курсора
При объявлении курсора ему назначается имя и ставится в

Слайд 292) Открытие курсора для запроса
Синтаксис открытия курсора таков:
OPEN имя_курсора;
где имя_курсора -
2) Открытие курсора для запроса
Синтаксис открытия курсора таков:
OPEN имя_курсора;
где имя_курсора -

Слайд 303) Выбор результатов в переменные PL/SQL
Производится считывание строк из курсора. Частью
Производится считывание строк из курсора. Частью

Слайд 314) Закрытие курсора
Когда выбран весь активный набор, курсор следует закрыть.
Это
4) Закрытие курсора
Когда выбран весь активный набор, курсор следует закрыть.
Это

Слайд 32Курсорные атрибуты
В PL/SQL существует 4 атрибута, которые применимы к курсорам:
%FOUND – это
Курсорные атрибуты
В PL/SQL существует 4 атрибута, которые применимы к курсорам:
%FOUND – это

Слайд 33Неявно объявляемые курсоры
Оператор select указывается в теле блока, и PL/SQL берет на
Неявно объявляемые курсоры
Оператор select указывается в теле блока, и PL/SQL берет на

Слайд 34Пример явного(explicit) курсора
DECLARE
/*Выходные переменные для хранения результатов запроса */
v_StudentID students. Id%TYPE;
Пример явного(explicit) курсора
DECLARE
/*Выходные переменные для хранения результатов запроса */
v_StudentID students. Id%TYPE;

Слайд 35Пример неявного(implicit) курсора
BEGIN
UPDATE rooms
SET number_seats = 100
WHERE room_id =
Пример неявного(implicit) курсора
BEGIN
UPDATE rooms
SET number_seats = 100
WHERE room_id =

Слайд 36Примеры
CURSOR ordercursor IS select id, customerid, orderdate from orders;
DECLARE
CURSOR ordercursor (ordernumber NUMBER)
Примеры
CURSOR ordercursor IS select id, customerid, orderdate from orders;
DECLARE
CURSOR ordercursor (ordernumber NUMBER)

Слайд 37Оператор GOTO
GOTO <метка> - оператор безусловного перехода
Обработка ошибок (блок EXCEPTION)
PL/SQL имеет встроенные
Оператор GOTO
GOTO <метка> - оператор безусловного перехода
Обработка ошибок (блок EXCEPTION)
PL/SQL имеет встроенные

Слайд 38Процедуры
Создание процедуры
Синтаксис оператора CREATE OR REPLACE PROCEDURE таков:
CREATE [OR REPLACE] PROCEDURE
Процедуры
Создание процедуры
Синтаксис оператора CREATE OR REPLACE PROCEDURE таков:
CREATE [OR REPLACE] PROCEDURE

Слайд 39Тело процедуры
Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений,
Тело процедуры
Тело (body) процедуры - это блок PL/SQL, содержащий раздел объявлений,

Слайд 40Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время
Для изменения текста процедуры необходимо удалить и повторно создать ее. Во время

Слайд 41Значения параметров по умолчанию
Как и переменные, формальные параметры процедуры или функции могут
Значения параметров по умолчанию
Как и переменные, формальные параметры процедуры или функции могут

Слайд 42Удаление процедур
Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления
Удаление процедур
Процедуры и функции, как и таблицы, могут быть удалены. Синтаксис удаления

Слайд 43Пример процедуры
CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS
last VARCHAR2(50);
first VARCHAR2(50);
BEGIN
Пример процедуры
CREATE PROCEDURE deletecustomer (custid IN INTEGER) AS
last VARCHAR2(50);
first VARCHAR2(50);
BEGIN

Слайд 44Функции
Создание функций
Функции очень похожи на процедуры. Как те, так и другие принимают
Функции
Создание функций
Функции очень похожи на процедуры. Как те, так и другие принимают

Слайд 45Описание функций
Синтаксис для создания хранимой функции очень похож на синтаксис для создания
Описание функций
Синтаксис для создания хранимой функции очень похож на синтаксис для создания

Слайд 46Оператор RETURN
Внутри тела функции оператор RETURN применяется для возврата управления программой
Оператор RETURN
Внутри тела функции оператор RETURN применяется для возврата управления программой

Слайд 47Свойства функций
Многие из свойств функций аналогичны свойствам процедур:
Функции могут возвращать более
Свойства функций
Многие из свойств функций аналогичны свойствам процедур:
Функции могут возвращать более

Слайд 48CREATE OR REPLACE FUNCTION AlmostFull(
p_Department classes.department%TYPE,
p_Course classes.course%TYPE)
RETURN BOOLEAN IS
V_CurrentStudents NUMBER;
V_MaxStudents NUMBER;
V_ReturnValue BOOLEAN;
V_FullPercent
p_Department classes.department%TYPE,
p_Course classes.course%TYPE)
RETURN BOOLEAN IS
V_CurrentStudents NUMBER;
V_MaxStudents NUMBER;
V_ReturnValue BOOLEAN;
V_FullPercent

Слайд 49Пример функции
CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2)
RETURN INTEGER AS
Пример функции
CREATE FUNCTION findcustid (last IN VARCHAR2, first IN VARCHAR2)
RETURN INTEGER AS

Слайд 50Агрегирующие функции
Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти
Агрегирующие функции
Групповые функции обрабатывают по несколько строк, но возвращают один результат. Эти

Слайд 51MAX
COUNT
MAX
COUNT

Слайд 52AVG
MIN
SUM
AVG
MIN
SUM

Слайд 53Модули (Пакеты)
Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном
Модули (Пакеты)
Модуль - это конструкция PL/SQL, позволяющая хранить связанные объекты в одном

Слайд 54Описание модуля
CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS}
описание_процедуры
описание_функции
объявление_переменной
определение_типа
объявление_исключительной_ситуации
Описание модуля
CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS}
описание_процедуры
описание_функции
объявление_переменной
определение_типа
объявление_исключительной_ситуации
![Описание модуля CREATE [OR REPLACE] PACKAGE имя_модуля {IS |AS} описание_процедуры описание_функции объявление_переменной](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381639/slide-53.jpg)
Слайд 55Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений,
Для заголовка модуля верны те же синтаксические правила, установленные для раздела объявлений,

Слайд 56Тело модуля
Тело модуля (package body) - это объект словаря данных, хранящийся
Тело модуля
Тело модуля (package body) - это объект словаря данных, хранящийся

Слайд 57Модули и области действия
Любой объект, объявленный в заголовке модуля, находится в области
Модули и области действия
Любой объект, объявленный в заголовке модуля, находится в области

Слайд 58Инициализация модуля
При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль
Инициализация модуля
При вызове первый раз модуль конкретизируется (instrantiated). Это значит, что модуль

Слайд 59Пример модуля генерации случайных чисел
CREATE OR REPLACE PACKAGE Random AS
PROCEDURE ChangeSeed (p_NewSeed
Пример модуля генерации случайных чисел
CREATE OR REPLACE PACKAGE Random AS
PROCEDURE ChangeSeed (p_NewSeed

Слайд 60PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS
BEGIN
v_Seed := p_NewSeed;
END ChangeSeed;
FUNCTION Rand RETURN NUMBER IS
PROCEDURE ChangeSeed(p_NewSeed IN NUMBER) IS
BEGIN
v_Seed := p_NewSeed;
END ChangeSeed;
FUNCTION Rand RETURN NUMBER IS

Слайд 61CREATE OR REPLACE PACKAGE ClassPackege AS
PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE,
p_Department IN
CREATE OR REPLACE PACKAGE ClassPackege AS
PROCEDURE AddStudent(p_StudentId IN Students. Id %TYPE,
p_Department IN

Слайд 62FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS
BEGIN
--Возвращает случайное целое число в
FUNCTION RandMax(p_MaxVal IN NUMBER) RETURN NUMBER IS
BEGIN
--Возвращает случайное целое число в

Слайд 63Пример модуля (пакета)
CREATE OR REPLACE PACKAGE customermanager IS
PROCEDURE newcustomer (company IN VARCHAR2
Пример модуля (пакета)
CREATE OR REPLACE PACKAGE customermanager IS
PROCEDURE newcustomer (company IN VARCHAR2

Слайд 64Триггеры
Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с
Триггеры
Триггеры так же, как процедуры и функции, являются именованными блоками PL/SQL с

Слайд 65Создание триггеров
CREATE [OR REPLACE] TRIGGER имя_триггера
{BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу
[FOR
Создание триггеров
CREATE [OR REPLACE] TRIGGER имя_триггера
{BEFORЕ | AFTER} активизирующее событие ON ссылка_на_таблицу
[FOR
![Создание триггеров CREATE [OR REPLACE] TRIGGER имя_триггера {BEFORЕ | AFTER} активизирующее событие](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381639/slide-64.jpg)
Слайд 66Триггеры можно использовать для:
Реализации сложных ограничений целостности данных, которые невозможно осуществить
Триггеры можно использовать для:
Реализации сложных ограничений целостности данных, которые невозможно осуществить

Слайд 67Элементы триггера
Обязательными элементами триггера являются его имя, активизирующее событие и тело.
Элементы триггера
Обязательными элементами триггера являются его имя, активизирующее событие и тело.

Слайд 68Удаление и запрещение триггеров
Триггеры, как и процедуры, и модули, и функции, можно
Удаление и запрещение триггеров
Триггеры, как и процедуры, и модули, и функции, можно

Слайд 69Порядок активизации триггера
Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков:
Порядок активизации триггера
Триггер активизируется при выполнении оператора DML. Алгоритм выполнения DMLоператора таков:

Слайд 70CREATE [OR REPLACE] TRIGGER classesBEstatement
BEFORE UPDATE ON classes
BEGIN
INSERT INTO temp_table
BEFORE UPDATE ON classes
BEGIN
INSERT INTO temp_table
![CREATE [OR REPLACE] TRIGGER classesBEstatement BEFORE UPDATE ON classes BEGIN INSERT INTO](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381639/slide-69.jpg)
Слайд 71CREATE [OR REPLACE] TRIGGER classesBERow
BEFORE UPDATE ON classes FOR EACH ROW
CREATE [OR REPLACE] TRIGGER classesBERow
BEFORE UPDATE ON classes FOR EACH ROW
![CREATE [OR REPLACE] TRIGGER classesBERow BEFORE UPDATE ON classes FOR EACH ROW](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/381639/slide-70.jpg)
Слайд 72Ограничения, налагаемые на триггеры
Тело триггера является блоком PL/SQL.
Любой оператор, выполнение
Ограничения, налагаемые на триггеры
Тело триггера является блоком PL/SQL.
Любой оператор, выполнение

Слайд 73Использование :old и :new в строковых триггерах
Строковый триггер срабатывает один раз для
Использование :old и :new в строковых триггерах
Строковый триггер срабатывает один раз для


Слайд 75Доступ к значениям столбцов
Доступ к значениям столбцов в триггере осуществляется с помощью
Доступ к значениям столбцов
Доступ к значениям столбцов в триггере осуществляется с помощью

Слайд 76Примеры триггеров:
1) CREATE TRIGGER deletecustomer
BEFORE DELETE ON customer
FOR EACH
Примеры триггеров:
1) CREATE TRIGGER deletecustomer
BEFORE DELETE ON customer
FOR EACH

Слайд 77Примеры триггеров:
3) CREATE TRIGGER updatestockquantity
AFTER INSERT OR DELETE OR UPDATE
Примеры триггеров:
3) CREATE TRIGGER updatestockquantity
AFTER INSERT OR DELETE OR UPDATE

Слайд 78Параллельные архитектуры серверов баз данных
Три основные архитектурные направления:
∙ Симметричные многопроцессорные
Параллельные архитектуры серверов баз данных
Три основные архитектурные направления:
∙ Симметричные многопроцессорные

Слайд 79Группы требований, определяющих качества современной СУБД
∙ масштабируемость;
∙ производительность;
∙ возможность смешанной
Группы требований, определяющих качества современной СУБД
∙ масштабируемость;
∙ производительность;
∙ возможность смешанной

Слайд 80Группы требований, определяющих качества современной СУБД
Постоянная доступность данных реализуется с помощью механизмов:
Группы требований, определяющих качества современной СУБД
Постоянная доступность данных реализуется с помощью механизмов:

Слайд 81Зеркалирование (software mirroring)
Зеркалирование (software mirroring)
Слайд 82Тиражирование (replication) данных
Тиражирование (replication) данных
Слайд 83Распределенные системы баз данных
Ядром системы управления распределенными информационными ресурсами являются распределенная база
Распределенные системы баз данных
Ядром системы управления распределенными информационными ресурсами являются распределенная база

Слайд 84Правила К. Дейта для распределенных баз данных:
Локальная автономность
Никакой конкретный сервис не должен
Правила К. Дейта для распределенных баз данных:
Локальная автономность
Никакой конкретный сервис не должен

Слайд 85Модели распределенных баз данных
Однородные системы, если СУБД –одинаковые,
иначе – неоднородные системы
Модели распределенных баз данных
Однородные системы, если СУБД –одинаковые,
иначе – неоднородные системы
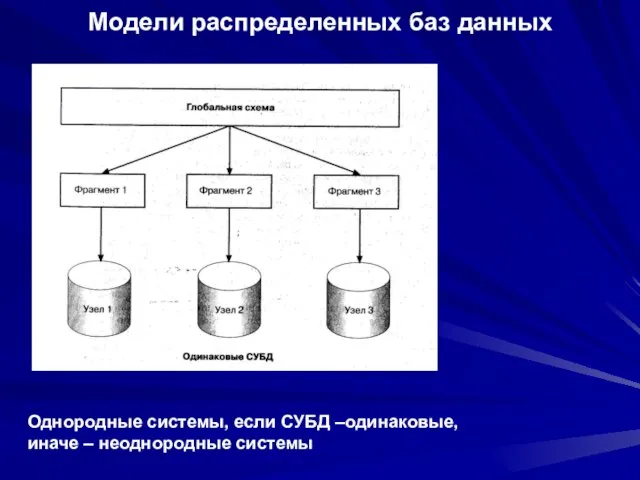
Слайд 86Фрагментация и тиражирование
Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх»
Проектирование
Фрагментация и тиражирование
Методы проектирования распределенных баз данных «сверху вниз» и «снизу вверх»
Проектирование

Слайд 87Модели тиражирования данных
Модели тиражирования данных
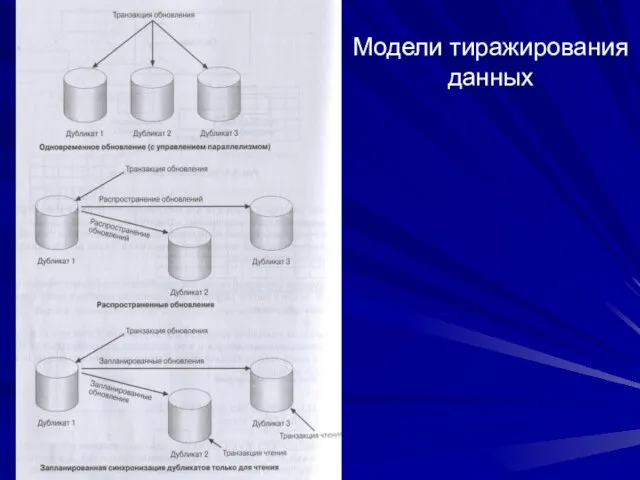
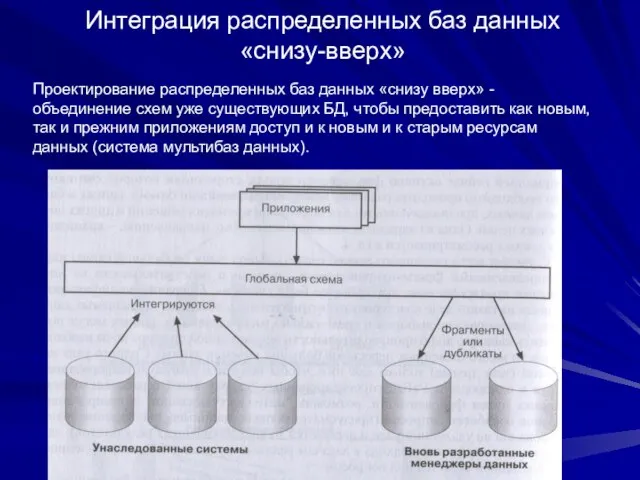
Слайд 88Интеграция распределенных баз данных «снизу-вверх»
Проектирование распределенных баз данных «снизу вверх» - объединение
Интеграция распределенных баз данных «снизу-вверх»
Проектирование распределенных баз данных «снизу вверх» - объединение
Слайд 89Средства защиты информации
Можно назвать следующие основные направления борьбы с потенциальными угрозами конфиденциальности
Средства защиты информации
Можно назвать следующие основные направления борьбы с потенциальными угрозами конфиденциальности

Слайд 90Ключевые механизмы безопасности:
∙ идентификация и аутентификация;
∙ управление доступом (системные привилегии, объектные
Ключевые механизмы безопасности:
∙ идентификация и аутентификация;
∙ управление доступом (системные привилегии, объектные

Слайд 91Некоторые определения
Объект - пассивная единица информационного обмена, используется как синоним понятия данные.
Некоторые определения
Объект - пассивная единица информационного обмена, используется как синоним понятия данные.

Слайд 92Аутентификация/авторизация при помощи паролей
1. Профили пользователей.
2. Профили процессов. Подобный метод реализован
Аутентификация/авторизация при помощи паролей
1. Профили пользователей.
2. Профили процессов. Подобный метод реализован

Слайд 93Инкапсуляция передаваемой информации в специальных протоколах обмена
1. Инфраструктуры с открытыми ключами. Использование
Инкапсуляция передаваемой информации в специальных протоколах обмена
1. Инфраструктуры с открытыми ключами. Использование

Слайд 94Ограничение информационных потоков
Firewalls. Метод подразумевает создание между локальной и глобальной сетями специальных
Ограничение информационных потоков
Firewalls. Метод подразумевает создание между локальной и глобальной сетями специальных

Слайд 95Метки безопасности
Для реализации принудительного управления доступом с субъектами и объектами ассоциируются метки
Метки безопасности
Для реализации принудительного управления доступом с субъектами и объектами ассоциируются метки

Слайд 96Принудительное управление доступом
Принудительное управление доступом основано на сопоставлении меток безопасности субъекта и
Принудительное управление доступом
Принудительное управление доступом основано на сопоставлении меток безопасности субъекта и

Слайд 97Промежуточное программное обеспечение (Middleware)
В распределенной неоднородной среде ППО играет роль «информационной шины»,
Промежуточное программное обеспечение (Middleware)
В распределенной неоднородной среде ППО играет роль «информационной шины»,

Слайд 98Типы ППО
Типы ППО
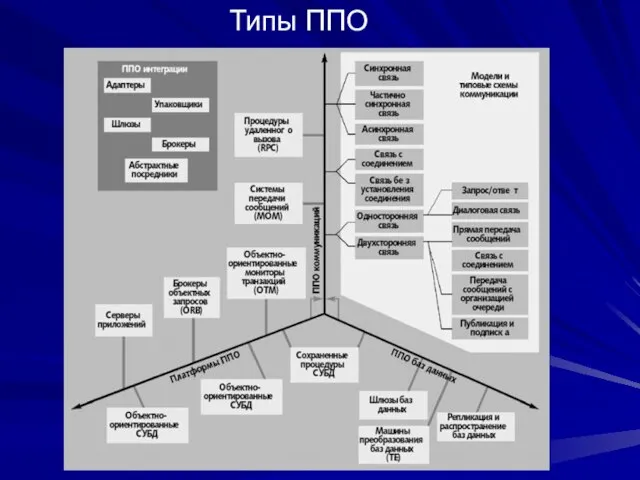
Слайд 99Промежуточное программное обеспечение баз данных
ППО баз данных обеспечивает доступ к локальному
Промежуточное программное обеспечение баз данных
ППО баз данных обеспечивает доступ к локальному

Слайд 100Доступ к базам данных
Системы прозрачного доступа к БД представляют собой наиболее развитый
Доступ к базам данных
Системы прозрачного доступа к БД представляют собой наиболее развитый

Слайд 101Доступ к базам данных
Использование MW доступа к БД широко применяется в корпоративных
Доступ к базам данных
Использование MW доступа к БД широко применяется в корпоративных

Слайд 102Архитектура ODBC(OPEN DATABASE CONNECTIVITY)
SQL - приложение
Администратор ODBC
Драйверы ODBC для различных
Архитектура ODBC(OPEN DATABASE CONNECTIVITY)
SQL - приложение Администратор ODBC Драйверы ODBC для различных

Слайд 103Существует 4 важных этапа (шага) процедуры запроса данных через ODBC API.
Шаг
Шаг

Слайд 104Недостатки реляционных СУБД
∙ Слабое представление сущностей реального мира
∙ Семантическая перегрузка
Недостатки реляционных СУБД
∙ Слабое представление сущностей реального мира
∙ Семантическая перегрузка

Слайд 105Манифест систем объектно-ориентированных баз данных
Обязательные свойства: золотые правила
Система объектно-ориентированных баз данных должна
Манифест систем объектно-ориентированных баз данных
Обязательные свойства: золотые правила
Система объектно-ориентированных баз данных должна

Слайд 106Преимущества и недостатки ООСУБД
Преимущества:
∙ Улучшенные возможности моделирования
∙ Расширяемость
∙ Устранение
Преимущества и недостатки ООСУБД
Преимущества:
∙ Улучшенные возможности моделирования
∙ Расширяемость
∙ Устранение

Слайд 107Объектная модель данных
В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется
Объектная модель данных
В соответствии со стандартом ODMG 2.0 объектная модель данных характеризуется

Слайд 108Объект, тип
Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация
Объект, тип
Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация

Слайд 109Идентификатор объекта
Как это следует из модели данных, каждый объект в базе данных
Идентификатор объекта
Как это следует из модели данных, каждый объект в базе данных

Слайд 110Новые типы данных
Одним из принципиальных отличий объектных баз данных от реляционных является
Новые типы данных
Одним из принципиальных отличий объектных баз данных от реляционных является

Слайд 111Оптимизация ядра СУБД
Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями для
Оптимизация ядра СУБД
Ядро ООСУБД оптимизировано для операций с объектами. Естественными операциями для

Слайд 112Язык СУБД и запросы
Общепризнанны две группы вариантов языков запросов.
Язык OQL (Object Query
Язык СУБД и запросы
Общепризнанны две группы вариантов языков запросов.
Язык OQL (Object Query

Слайд 113Транзакции
Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках
Транзакции
Короткие транзакции характеризуются малым временем выполнения; они могут существовать только в рамках

Слайд 114Блокировки
Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения
Блокировки
Назначение блокировок — гарантировать монопольность использования объекта конкретным пользователем с целью предотвращения

Слайд 115Перемещение объектов
Миграция объектов: постоянное их перемещение, например в другую базу данных. В
Перемещение объектов
Миграция объектов: постоянное их перемещение, например в другую базу данных. В

Слайд 116Основы объектно-ориентированного программирования
Рассмотрим объект Student. Студент имеет атрибуты, т.е. свойства: имя (first_name),
Основы объектно-ориентированного программирования
Рассмотрим объект Student. Студент имеет атрибуты, т.е. свойства: имя (first_name),

Слайд 117Абстракция
Как было показано на примере программных модулей, атрибуты и методы объекта достаточно
Абстракция
Как было показано на примере программных модулей, атрибуты и методы объекта достаточно

Слайд 118Объектно-реляционные базы данных
В настоящее время применяется множество объектно-ориентированных языков программирования, а том
Объектно-реляционные базы данных
В настоящее время применяется множество объектно-ориентированных языков программирования, а том

Слайд 119Архитектура Oracle Application Server
Архитектура Oracle Application Server
Слайд 120СУБД Oracle9i
СУБД Oracle9i быстро превратилась в СУБД для всех типов данных –
СУБД Oracle9i
СУБД Oracle9i быстро превратилась в СУБД для всех типов данных –

Слайд 121Объектно-реляционная архитектура СУБД Oracle9i
Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками
Объектно-реляционная архитектура СУБД Oracle9i
Сервер Oracle9i с объектно-реляционной технологией может быть "подогнан" разработчиками

Слайд 122Объектно-ориентированная разработка приложений
СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих
Объектно-ориентированная разработка приложений
СУБД Oracle9i предлагает большой набор интерфейсов прикладного программирования (API), реализующих

Слайд 123Объектные типы данных
Объектный тип данных — это тип, определяемый пользователем, и задающий
Объектные типы данных
Объектный тип данных — это тип, определяемый пользователем, и задающий

Слайд 124Объектные типы
Корпорация Oracle расширила SQL, чтобы позволить пользователям:
∙ определять свои собственные
Объектные типы
Корпорация Oracle расширила SQL, чтобы позволить пользователям:
∙ определять свои собственные

Слайд 125СУБД Oracle9i позволяет пользователям рассматривать объектные данные как реляционные. Например, пользователи могут
СУБД Oracle9i позволяет пользователям рассматривать объектные данные как реляционные. Например, пользователи могут

Слайд 126Наследование
Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе.
Наследование
Наследование типов (Type inheritance) – это фундаментальная концепция в любой объектно-ориентированной системе.

Слайд 127Иерархия типов
Корневой тип иерархии создается с помощью оператора CREATE TYPE, в котором
Иерархия типов
Корневой тип иерархии создается с помощью оператора CREATE TYPE, в котором

Слайд 128Типы-коллекции
Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные
Типы-коллекции
Коллекции – это типы данных SQL, составляющие элементы которых представляют собой множественные

Слайд 129Большие объекты
СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения
Большие объекты
СУБД Oracle9i предоставляет типы LOB (large object, большой объект) для решения

Слайд 130Связывания для языков программирования
Полная поддержка объектно-реляционной системы типов Oracle доступна в связываниях
Связывания для языков программирования
Полная поддержка объектно-реляционной системы типов Oracle доступна в связываниях

Слайд 131Надежность и масштабируемость
Real Application Cluster (RAC)
Достижением Oracle 9i в области обеспечения высокой
Надежность и масштабируемость
Real Application Cluster (RAC)
Достижением Oracle 9i в области обеспечения высокой

Слайд 132Поддержка XML, дуализм XML/SQL
Сервер Oracle поддерживает не только реляционную, объектную, многомерную модель
Поддержка XML, дуализм XML/SQL
Сервер Oracle поддерживает не только реляционную, объектную, многомерную модель

Слайд 133Поддержка OLAP
Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для
Поддержка OLAP
Реляционная модель удобна для представления данных в информационно-управляющих системах, однако для

Слайд 134Механизм Oracle Streams
В СУБД Oracle существует много различных вариантов передачи данных и
Механизм Oracle Streams
В СУБД Oracle существует много различных вариантов передачи данных и

Слайд 135Oracle 10g
Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа -
Oracle 10g
Oracle первой предложила СУБД, предназначенную для корпоративных сетей нового типа -

Слайд 136Oracle Database 10g
Oracle Database 10g предназначена для эффективного развертывания на базе различных
Oracle Database 10g
Oracle Database 10g предназначена для эффективного развертывания на базе различных

Слайд 137Oracle Application Server 10g
Oracle Application Server 10g - это основанная на стандартах
Oracle Application Server 10g
Oracle Application Server 10g - это основанная на стандартах

Слайд 138Oracle Enterprise Manager 10g
Oracle Enterprise Manager 10g - это первое в отрасли
Oracle Enterprise Manager 10g
Oracle Enterprise Manager 10g - это первое в отрасли

Слайд 139Адаптивная платформа для Oracle
Серверный пул
Oracle
App Server
Oracle
Database
Пул хранения
ASCC для Oracle –
Адаптивная платформа для Oracle
Серверный пул
Oracle
App Server
Oracle
Database
Пул хранения
ASCC для Oracle –
Слайд 140Adaptive Services Control Center (ASCC)
Непрерывный мониторинг физических и виртуальных ресурсов
Ресурсы распределяются адаптивно
Adaptive Services Control Center (ASCC)
Непрерывный мониторинг физических и виртуальных ресурсов
Ресурсы распределяются адаптивно
Слайд 141Сценарий: управление загрузкой на базе правил
AS1
БД
RAC
резерв
Серверы
ASCC
(анализ, адаптация)
время отклика
AS3
AS2
Клиент
загрузка CPU
сигнал:высокая загрузка CPU
Сценарий: управление загрузкой на базе правил
AS1
БД
RAC
резерв
Серверы
ASCC
(анализ, адаптация)
время отклика
AS3
AS2
Клиент
загрузка CPU
сигнал:высокая загрузка CPU
 Тандырная это – приготовление шашлыков в тандыре
Тандырная это – приготовление шашлыков в тандыре Лист. Внешнее и внутреннее строение
Лист. Внешнее и внутреннее строение Архитектура и дизайн
Архитектура и дизайн Международное гуманитарное право.
Международное гуманитарное право. Метод фундаментального проектирования Мэтчетта
Метод фундаментального проектирования Мэтчетта Контроль, согласование и утверждение КТД
Контроль, согласование и утверждение КТД Москва (2 класс)
Москва (2 класс) Подготовка дела к судебному разбирательству как обязательная стадия гражданского судопроизводства
Подготовка дела к судебному разбирательству как обязательная стадия гражданского судопроизводства Презентация на тему Вспоминаем Юрия Гагарина 55 лет со дня первого полета человека в Космос
Презентация на тему Вспоминаем Юрия Гагарина 55 лет со дня первого полета человека в Космос  История учения о личности преступника. Тема 2
История учения о личности преступника. Тема 2 Sonder для рассылки
Sonder для рассылки Сертификация
Сертификация Бизнес-партнерство с Rama Yoga
Бизнес-партнерство с Rama Yoga Презентация на тему Движущие силы антропогенеза
Презентация на тему Движущие силы антропогенеза  Геометрия вокруг нас
Геометрия вокруг нас БЮДЖЕТИРОВАНИЕ В 1С
БЮДЖЕТИРОВАНИЕ В 1С Мошенничества с инвестициями
Мошенничества с инвестициями Природное и общественное. Отличия человека от животного
Природное и общественное. Отличия человека от животного Жарқын болашаққа жол
Жарқын болашаққа жол Раскадровка. Для чего нужна раскадровка
Раскадровка. Для чего нужна раскадровка Культурное наследие регионов России
Культурное наследие регионов России Презентация на тему Дисграфия
Презентация на тему Дисграфия Профессиональные функции и умения старшего воспитателя ДОУ
Профессиональные функции и умения старшего воспитателя ДОУ Иллюзии зрения
Иллюзии зрения Презентация на тему Развитие метапредметных компетенций учащихся
Презентация на тему Развитие метапредметных компетенций учащихся Образец презентации к отчету ИР БкЮ-100
Образец презентации к отчету ИР БкЮ-100 Презентация на тему Роль права в жизни государства (9 класс)
Презентация на тему Роль права в жизни государства (9 класс) Классификация элементарных частиц
Классификация элементарных частиц