- Chapter_5-alternative-approaches

Содержание
- 2. Background Required to Understand this Chapter Advanced Computer Architecture. Smruti R. Sarangi Chapter 4
- 3. Contents Advanced Computer Architecture. Smruti R. Sarangi Simpler Version of an OOO Processor Compiler based Techniques
- 4. Aggressive Speculation Branch prediction is one form of speculation If we detect that a branch has
- 5. Types of Aggressive Speculation Advanced Computer Architecture. Smruti R. Sarangi
- 6. Address Speculation: Predict the memory address of a load or store Predict last address scheme Use
- 7. Stride based Address Pattern Advanced Computer Architecture. Smruti R. Sarangi
- 8. Predicting the Stride Last address (A): The memory address computed the last time the instruction with
- 9. Load-Store Dependence Speculation Advanced Computer Architecture. Smruti R. Sarangi Predict a collision (same memory address) between
- 10. Collision History Table Loads show consistent behavior They are either colliding or non-colliding Advanced Computer Architecture.
- 11. Using the CHT When we compute the address of a load We access the CHT If
- 12. Store Sets Advanced Computer Architecture. Smruti R. Sarangi Explicitly remember load-store dependences PC ? Store set
- 13. Basic Idea For every load, we have an associated store set Stores that have forwarded values
- 14. Load Latency Speculation A load might hit in the L1 cache (2 cycles) or might go
- 15. Make a guess Advanced Computer Architecture. Smruti R. Sarangi For load instructions, predict if it will
- 16. Advanced Computer Architecture. Smruti R. Sarangi Constants Value prediction: Why are values predictable?
- 17. Value Predictor Advanced Computer Architecture. Smruti R. Sarangi
- 18. Using an additional predictor for confidence First, use the confidence table to find out if it
- 19. Contents Advanced Computer Architecture. Smruti R. Sarangi Simpler Version of an OOO Processor Compiler based Techniques
- 20. Replay Flushing the pipeline for every misspeculation is not a wise thing Instead, flush a part
- 21. Forward Slice of Instruction I0 Advanced Computer Architecture. Smruti R. Sarangi A forward slice contains an
- 22. Non-Selective Replay Trivial Solution: Flush the pipeline between the dispatch and execute stages Smarter Solution It
- 23. Example Let us say that instructions 2, 3, and 4 had one operand waking up in
- 24. Instruction Window Entry When an operand becomes ready, we set its timer to n Every cycle
- 25. More about Non-Selective Replay We attach the expected latency with each instruction packet as it flows
- 26. Two methods of replaying Method 1: Keep instructions that have been issued in the issue queue
- 27. Two methods of replaying - II Move the instructions to a dedicated replay queue after issue
- 28. Orphan Instructions Assume that the load instruction misses in the L1 cache The add, sub, and
- 29. Orphan Instructions - II Keep track of squashed instructions. Re-broadcast tags of orphan instructions. ? We
- 30. Delayed Selective Replay Let us now propose an idea to replay only those instructions that are
- 31. Delayed Selective Replay - II When an instruction finishes execution ? Check if its poison bit
- 32. Orphan Instructions We can always wait for the instruction to reach the head of the ROB.
- 33. Token Based Selective Replay Let us use a pattern found in most programs: Most of the
- 34. After Predicting a d-cache Miss Instructions that are predicted to miss, will have a non-deterministic execution
- 35. Structure of the Rename Table If an instruction is a token head, we save the id
- 36. While reading the rename table ... Read the tokenVecs of the source operands Merge the tokenVecs
- 37. After execution After the token head instruction completes execution, see if it took additional cycles (verification
- 38. Instructions in S2 Assume an instruction that was not predicted to miss actually misses No token
- 39. Contents Advanced Computer Architecture. Smruti R. Sarangi Simpler Version of an OOO Processor Compiler based Techniques
- 40. A Simpler Design Physical Register File (PRF) based design Advanced Computer Architecture. Smruti R. Sarangi Fast
- 41. Let us now look at a different kind of OOO processor Instead of having a physical
- 42. Changes to renaming Entry in the RAT table ROB id ROB/RF bit ROB/RF bit ? 1
- 43. Changes to Dispatch and Wakeup Each entry in the IW now stores the values of the
- 44. Changes to Wakeup, Bypass, Reg. Write and Commit We can follow the same speculative wakeup strategy
- 45. PRF based design vs ARF based design points in the PRF based design A value resides
- 46. Contents Advanced Computer Architecture. Smruti R. Sarangi Simpler Version of an OOO Processor Compiler based Techniques
- 47. Compiler based Optimizations Can the compiler optimize the code? Advanced Computer Architecture. Smruti R. Sarangi
- 48. Constant Folding Advanced Computer Architecture. Smruti R. Sarangi We can directly replace a with 10, b
- 49. Strength Reduction Advanced Computer Architecture. Smruti R. Sarangi slow fast
- 50. Common Subexpression Elimination Each line in the second example corresponds to one line of assembly code.
- 51. Dead Code Elimination Advanced Computer Architecture. Smruti R. Sarangi Dead code
- 52. Silent Stores Silent stores write the same value that is already present Advanced Computer Architecture. Smruti
- 53. Advanced Computer Architecture. Smruti R. Sarangi Loop Based Optimizations
- 54. Loop Invariant based Code Motion There is no point setting (val = 5) repeatedly. Advanced Computer
- 55. Induction Variable based Optimization Advanced Computer Architecture. Smruti R. Sarangi Original Induction variable Replace a multiply
- 56. Loop Fusion Advanced Computer Architecture. Smruti R. Sarangi Original Optimized Fuse the loops Loop fusion reduces
- 57. Loop Unrolling - I Advanced Computer Architecture. Smruti R. Sarangi Original loop Assembly code
- 58. Advanced Computer Architecture. Smruti R. Sarangi Loop Unrolling - II Advantage: fewer total instructions and specifically
- 59. Advanced Computer Architecture. Smruti R. Sarangi Software Pipelining
- 60. Advanced Computer Architecture. Smruti R. Sarangi L S I
- 61. Visualization of the Execution Process Advanced Computer Architecture. Smruti R. Sarangi We can create our loops
- 62. Can we execute instructions in this order? Advanced Computer Architecture. Smruti R. Sarangi I0 ? S1
- 63. Advantages of Software Pipelining Consider this order: I0 ? S1 ? L2 ? I1 ? S2
- 64. Different Loop Iterators: Group of 3 iterations Advanced Computer Architecture. Smruti R. Sarangi
- 65. Code with Different Loop Iterators Advanced Computer Architecture. Smruti R. Sarangi Unroll the loop 3 times
- 66. Advanced Computer Architecture. Smruti R. Sarangi If we had 32 registers, we could do this very
- 67. Epilogue and Prologue Advanced Computer Architecture. Smruti R. Sarangi
- 68. Solution without Unrolling Advanced Computer Architecture. Smruti R. Sarangi i = -1; t = B[0]; .loop
- 69. Unrolling and Mixing Advanced Computer Architecture. Smruti R. Sarangi
- 70. Contents Advanced Computer Architecture. Smruti R. Sarangi Simpler Version of an OOO Processor Compiler based Techniques
- 71. . Sounds like a promising idea … Less hardware ? less power, less complexity Modern software
- 72. VLIW Processors VLIW (Very Long Instruction Word) processors were the first designs in this space. Bundle
- 73. If Statements: Predicated Execution Use predicated execution (remember GPUs). Advanced Computer Architecture. Smruti R. Sarangi If
- 74. Curious Case of Memory Instructions We can have multiple memory instructions in a bundle The addresses
- 75. VLIW vs EPIC Advanced Computer Architecture. Smruti R. Sarangi Given that VLIW processors do not necessarily
- 76. Intel Itanium Processor Unique collaboration between Intel and HP Aim: EPIC processor Designed to leverage the
- 77. Fetch Stage Each bundle contains 3 instructions The decoupling buffer can hold 8 such bundles Advanced
- 78. Branch Predictors Itanium has four types of branch predictors Compiler directed Four special registers: Target Address
- 79. Branch Predictors – II Multi-way Branches Compilers ensure that (typically) the last instruction in a bundle
- 80. This part of the pipeline Itanium has 9 issue ports: 2 for memory, 2 for integer,
- 81. Register Remapping Stage Large 128-entry register file. Advanced Computer Architecture. Smruti R. Sarangi 32 static registers
- 82. Example: Function foo calls function bar Advanced Computer Architecture. Smruti R. Sarangi We deliberately create an
- 83. Register Stack Frame The in and local registers are preserved across function calls. The out registers
- 84. Binary Search Advanced Computer Architecture. Smruti R. Sarangi No processing done after receiving the return value.
- 85. Register Stack Frame The in and local registers are preserved across function calls. The out registers
- 86. Support for Software Pipelining and Overflows Main Problem: We run out of registers Itanium has a
- 87. High Performance Execution Engine Advanced Computer Architecture. Smruti R. Sarangi Scoreboard Simple mechanism for OOO execution
- 88. Conditions: Instruction I Advanced Computer Architecture. Smruti R. Sarangi WAW Hazards Check all the earlier entries
- 89. Conditions: II Instructions wait in the scoreboard until they are safe No hazards Advanced Computer Architecture.
- 90. Predication If we flush the pipeline upon a branch misprediction It would be quite unfair Let
- 91. Code without Predication Count the number of branch instructions. Advanced Computer Architecture. Smruti R. Sarangi /*
- 92. Predicated Instructions The comparison generates predicates (flags) po ? number is odd, pe ? number is
- 93. Advanced Computer Architecture. Smruti R. Sarangi Pipeline
- 94. Load Boosting Boost a load and some instructions that use its value to a point before
- 95. Advanced Computer Architecture. Smruti R. Sarangi A host of compiler optimizations can be used to speed
- 97. Скачать презентацию
Слайд 2Background Required to Understand this Chapter
Advanced Computer Architecture. Smruti R. Sarangi
Chapter 4
Background Required to Understand this Chapter
Advanced Computer Architecture. Smruti R. Sarangi
Chapter 4

Слайд 3Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Слайд 4Aggressive Speculation
Branch prediction is one form
of speculation
If we detect that
Aggressive Speculation
Branch prediction is one form
of speculation
If we detect that

Слайд 5Types of Aggressive Speculation
Advanced Computer Architecture. Smruti R. Sarangi
Types of Aggressive Speculation
Advanced Computer Architecture. Smruti R. Sarangi

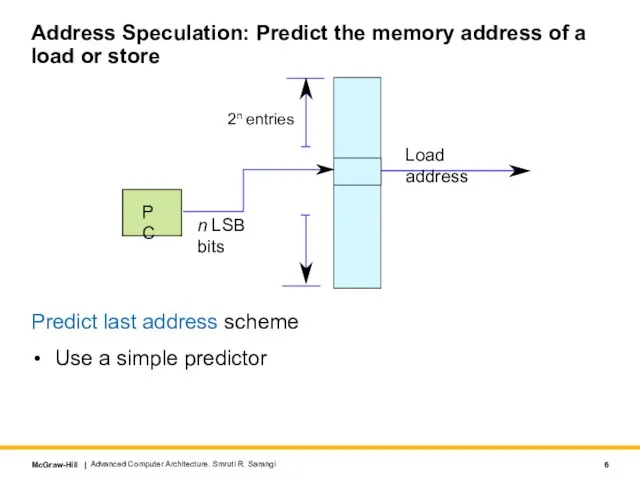
Слайд 6Address Speculation: Predict the memory address of a load or store
Predict last
Address Speculation: Predict the memory address of a load or store
Predict last
Слайд 7Stride based Address Pattern
Advanced Computer Architecture. Smruti R. Sarangi
Stride based Address Pattern
Advanced Computer Architecture. Smruti R. Sarangi

Слайд 8Predicting the Stride
Last address (A): The memory address computed the last time
Predicting the Stride
Last address (A): The memory address computed the last time

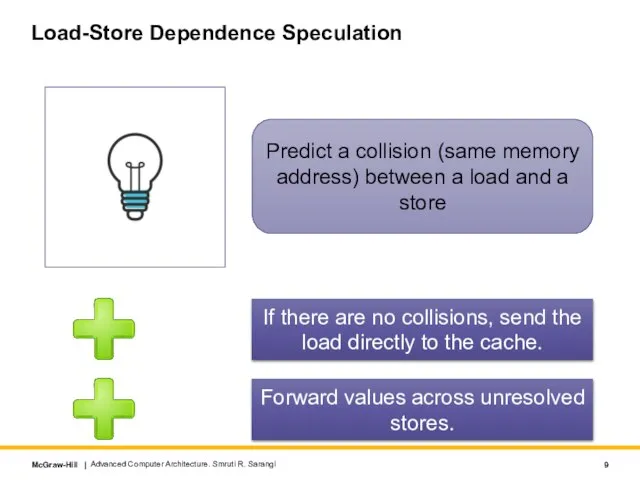
Слайд 9Load-Store Dependence Speculation
Advanced Computer Architecture. Smruti R. Sarangi
Predict a collision (same memory
Load-Store Dependence Speculation
Advanced Computer Architecture. Smruti R. Sarangi
Predict a collision (same memory
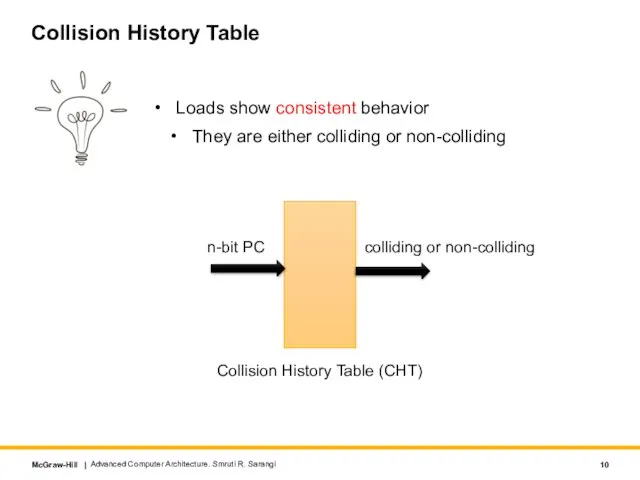
Слайд 10Collision History Table
Loads show consistent behavior
They are either colliding or non-colliding
Advanced Computer
Collision History Table
Loads show consistent behavior
They are either colliding or non-colliding
Advanced Computer
Слайд 11Using the CHT
When we compute the address of a load
We access the
Using the CHT
When we compute the address of a load
We access the

Слайд 12Store Sets
Advanced Computer Architecture. Smruti R. Sarangi
Explicitly remember load-store dependences
PC ? Store
Store Sets
Advanced Computer Architecture. Smruti R. Sarangi
Explicitly remember load-store dependences
PC ? Store
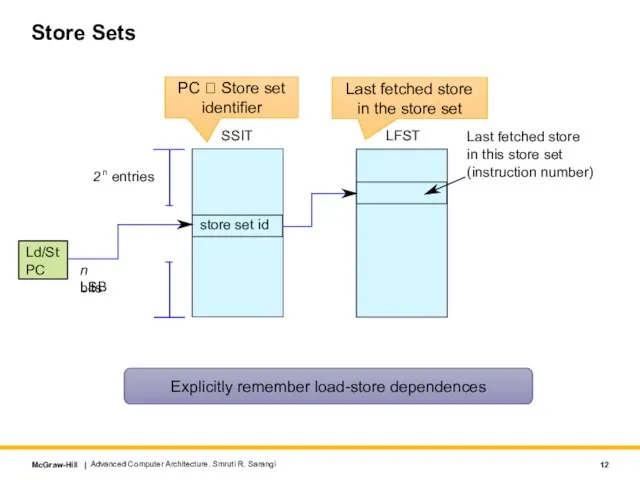
Слайд 13Basic Idea
For every load, we have an associated store set
Stores that have
Basic Idea
For every load, we have an associated store set
Stores that have

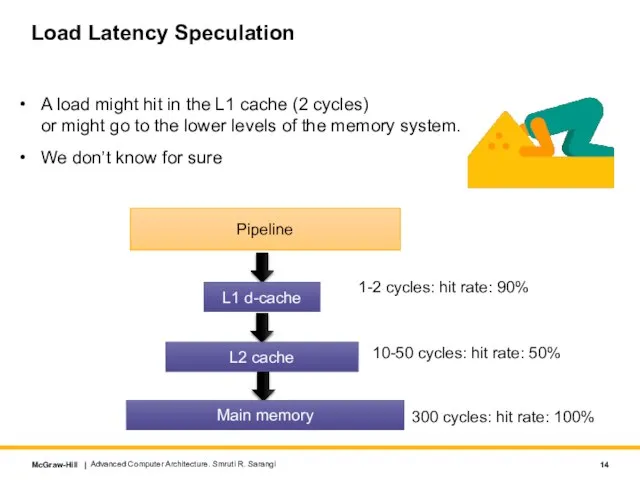
Слайд 14Load Latency Speculation
A load might hit in the L1 cache (2 cycles)
or
Load Latency Speculation
A load might hit in the L1 cache (2 cycles) or
Слайд 15Make a guess
Advanced Computer Architecture. Smruti R. Sarangi
For load instructions, predict if
Make a guess
Advanced Computer Architecture. Smruti R. Sarangi
For load instructions, predict if

Слайд 16Advanced Computer Architecture. Smruti R. Sarangi
Constants
Value prediction: Why are values predictable?
Advanced Computer Architecture. Smruti R. Sarangi
Constants
Value prediction: Why are values predictable?
Слайд 17Value Predictor
Advanced Computer Architecture. Smruti R. Sarangi
Value Predictor
Advanced Computer Architecture. Smruti R. Sarangi
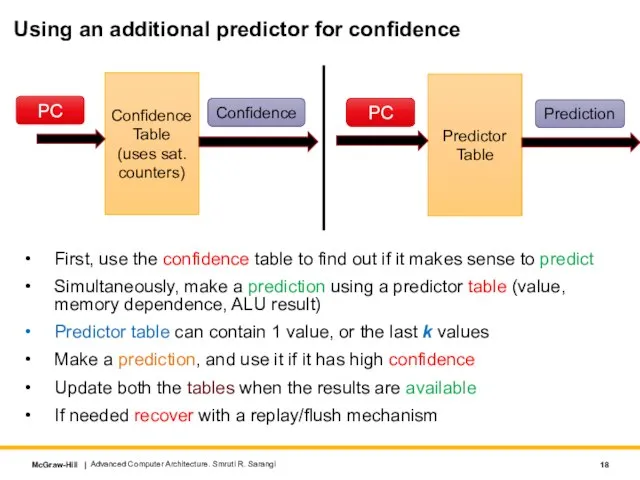
Слайд 18Using an additional predictor for confidence
First, use the confidence table to find
Using an additional predictor for confidence
First, use the confidence table to find
Слайд 19Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Слайд 20Replay
Flushing the pipeline for every misspeculation is not a wise thing
Instead, flush
Replay
Flushing the pipeline for every misspeculation is not a wise thing
Instead, flush

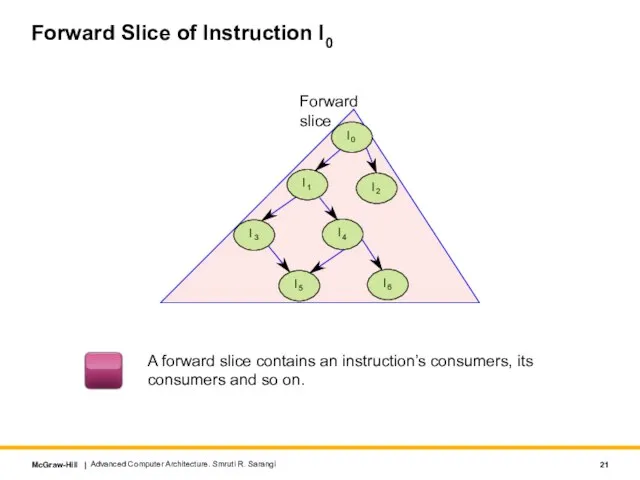
Слайд 21Forward Slice of Instruction I0
Advanced Computer Architecture. Smruti R. Sarangi
A forward slice
Forward Slice of Instruction I0
Advanced Computer Architecture. Smruti R. Sarangi
A forward slice
Слайд 22Non-Selective Replay
Trivial Solution: Flush the pipeline between the dispatch and execute stages
Non-Selective Replay
Trivial Solution: Flush the pipeline between the dispatch and execute stages

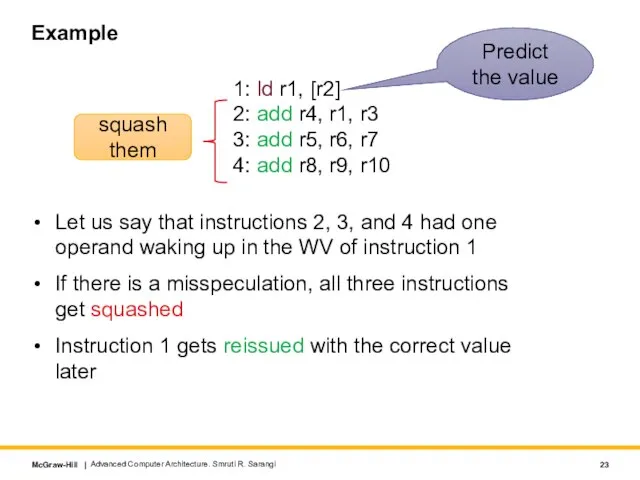
Слайд 23Example
Let us say that instructions 2, 3, and 4 had one operand
Example
Let us say that instructions 2, 3, and 4 had one operand
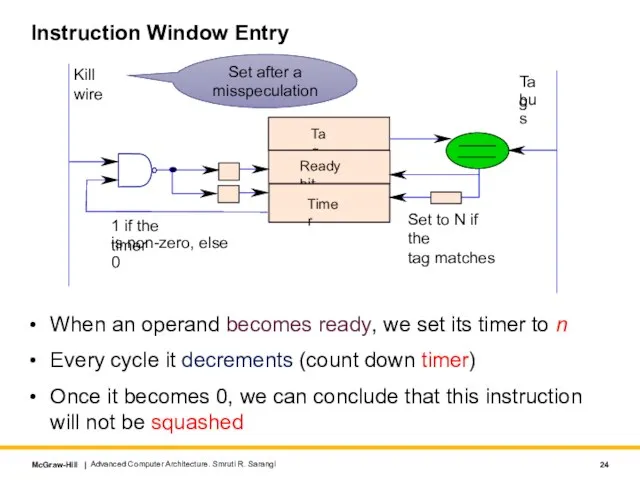
Слайд 24Instruction Window Entry
When an operand becomes ready, we set its timer to
Instruction Window Entry
When an operand becomes ready, we set its timer to
Слайд 25More about Non-Selective Replay
We attach the expected latency with each instruction packet
More about Non-Selective Replay
We attach the expected latency with each instruction packet

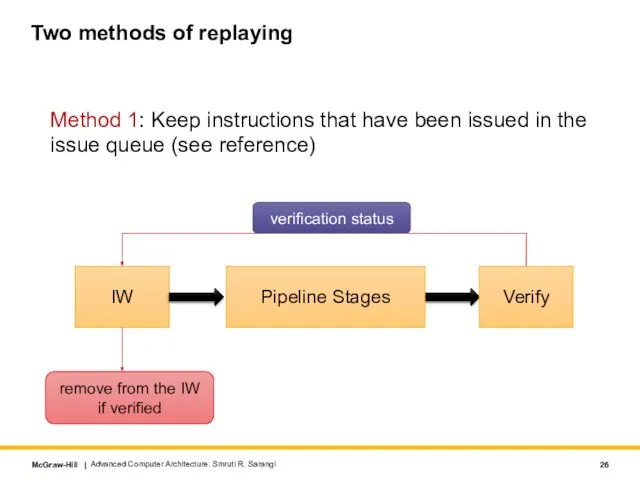
Слайд 26Two methods of replaying
Method 1: Keep instructions that have been issued in
Two methods of replaying
Method 1: Keep instructions that have been issued in
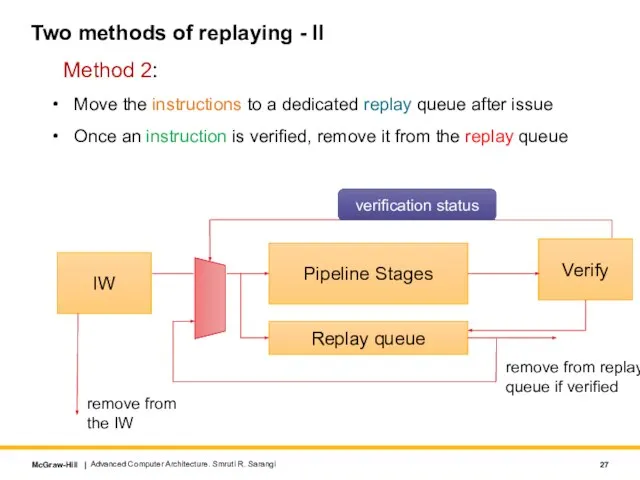
Слайд 27Two methods of replaying - II
Move the instructions to a dedicated replay
Two methods of replaying - II
Move the instructions to a dedicated replay
Слайд 28Orphan Instructions
Assume that the load instruction misses in the L1 cache
The add,
Orphan Instructions
Assume that the load instruction misses in the L1 cache
The add,

Слайд 29Orphan Instructions - II
Keep track of squashed instructions.
Re-broadcast tags of orphan
Orphan Instructions - II
Keep track of squashed instructions.
Re-broadcast tags of orphan

Слайд 30Delayed Selective Replay
Let us now propose an idea to replay only those
Delayed Selective Replay
Let us now propose an idea to replay only those

Слайд 31Delayed Selective Replay - II
When an instruction finishes execution ?
Check if its
Delayed Selective Replay - II
When an instruction finishes execution ?
Check if its

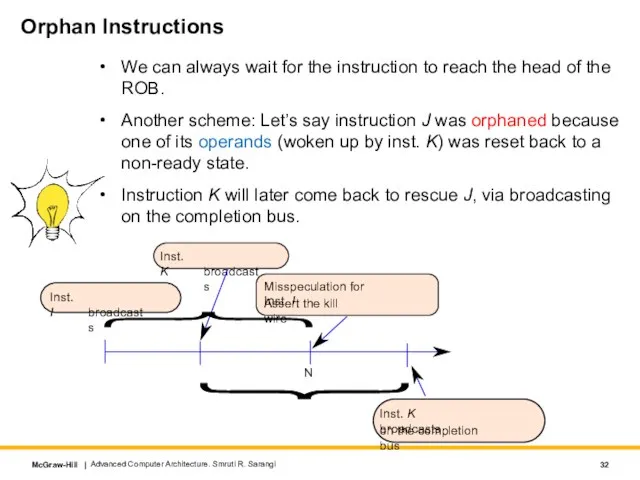
Слайд 32Orphan Instructions
We can always wait for the instruction to reach the head
Orphan Instructions
We can always wait for the instruction to reach the head
Слайд 33Token Based Selective Replay
Let us use a pattern found in most programs:
Most
Token Based Selective Replay
Let us use a pattern found in most programs:
Most

Слайд 34After Predicting a d-cache Miss
Instructions that are predicted to miss, will have
After Predicting a d-cache Miss
Instructions that are predicted to miss, will have

Слайд 35Structure of the Rename Table
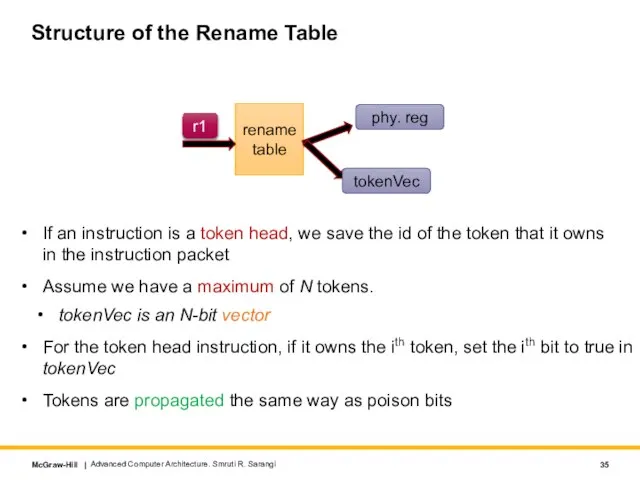
If an instruction is a token head, we
Structure of the Rename Table
If an instruction is a token head, we
Слайд 36While reading the rename table ...
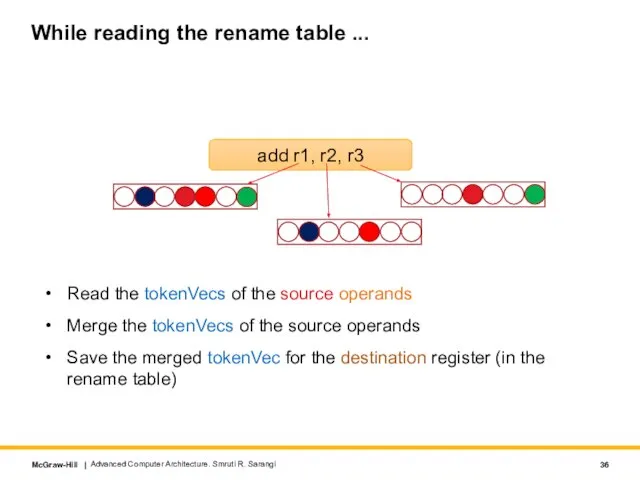
Read the tokenVecs of the source operands
Merge
While reading the rename table ...
Read the tokenVecs of the source operands
Merge
Слайд 37After execution
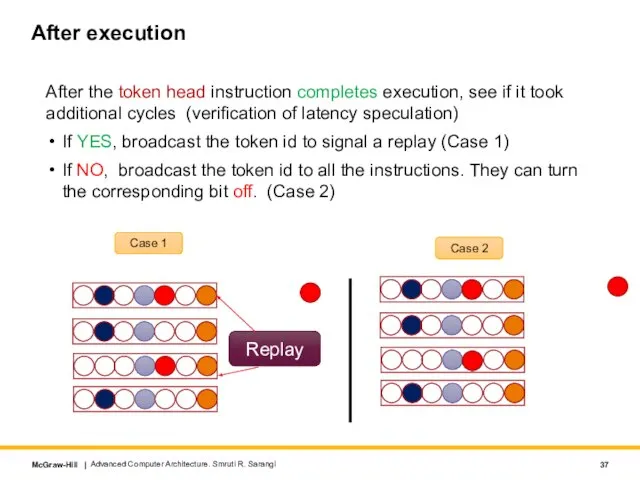
After the token head instruction completes execution, see if it took
After execution
After the token head instruction completes execution, see if it took
Слайд 38Instructions in S2
Assume an instruction that was not predicted to miss actually
Instructions in S2
Assume an instruction that was not predicted to miss actually

Слайд 39Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Слайд 40A Simpler Design
Physical Register File (PRF) based design
Advanced Computer Architecture. Smruti R.
A Simpler Design
Physical Register File (PRF) based design
Advanced Computer Architecture. Smruti R.
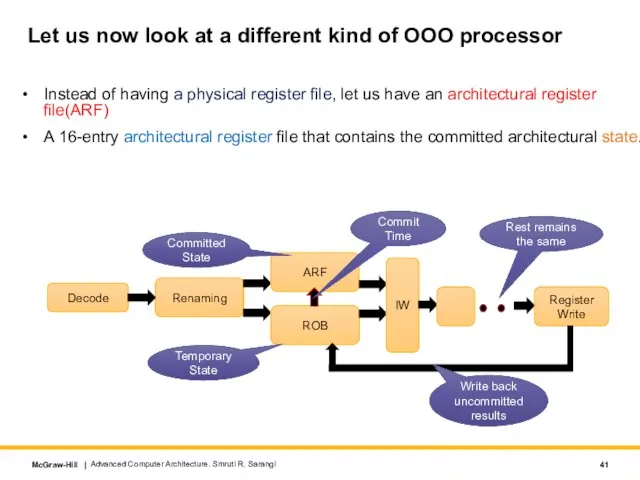
Слайд 41Let us now look at a different kind of OOO processor
Instead of
Let us now look at a different kind of OOO processor
Instead of
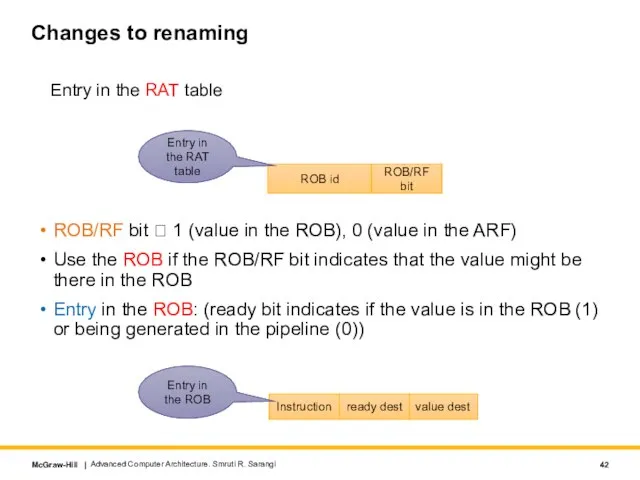
Слайд 42Changes to renaming
Entry in the RAT table
ROB id
ROB/RF bit
ROB/RF bit ? 1
Changes to renaming
Entry in the RAT table
ROB id
ROB/RF bit
ROB/RF bit ? 1
Слайд 43Changes to Dispatch and Wakeup
Each entry in the IW now stores the
Changes to Dispatch and Wakeup
Each entry in the IW now stores the

Слайд 44Changes to Wakeup, Bypass, Reg. Write and Commit
We can follow the same
Changes to Wakeup, Bypass, Reg. Write and Commit
We can follow the same

Слайд 45PRF based design vs ARF based design
points in the PRF
PRF based design vs ARF based design
points in the PRF

Слайд 46Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Слайд 47Compiler based Optimizations
Can the compiler optimize the code?
Advanced Computer Architecture. Smruti
Compiler based Optimizations
Can the compiler optimize the code?
Advanced Computer Architecture. Smruti

Слайд 48Constant Folding
Advanced Computer Architecture. Smruti R. Sarangi
We can directly replace a with
Constant Folding
Advanced Computer Architecture. Smruti R. Sarangi
We can directly replace a with

Слайд 49Strength Reduction
Advanced Computer Architecture. Smruti R. Sarangi
slow
fast
Strength Reduction
Advanced Computer Architecture. Smruti R. Sarangi
slow
fast

Слайд 50Common Subexpression Elimination
Each line in the second example corresponds to one line
Common Subexpression Elimination
Each line in the second example corresponds to one line

Слайд 51Dead Code Elimination
Advanced Computer Architecture. Smruti R. Sarangi
Dead code
Dead Code Elimination
Advanced Computer Architecture. Smruti R. Sarangi
Dead code

Слайд 52Silent Stores
Silent stores write the same value that is already present
Advanced Computer
Silent Stores
Silent stores write the same value that is already present
Advanced Computer

Слайд 53Advanced Computer Architecture. Smruti R. Sarangi
Loop Based Optimizations
Advanced Computer Architecture. Smruti R. Sarangi
Loop Based Optimizations

Слайд 54Loop Invariant based Code Motion
There is no point setting (val = 5)
Loop Invariant based Code Motion
There is no point setting (val = 5)

Слайд 55Induction Variable based Optimization
Advanced Computer Architecture. Smruti R. Sarangi
Original
Induction
variable
Replace
a multiply
with an add
Optimized
An
Induction Variable based Optimization
Advanced Computer Architecture. Smruti R. Sarangi
Original
Induction
variable
Replace
a multiply
with an add
Optimized
An

Слайд 56Loop Fusion
Advanced Computer Architecture. Smruti R. Sarangi
Original
Optimized
Fuse the loops
Loop fusion reduces the
Loop Fusion
Advanced Computer Architecture. Smruti R. Sarangi
Original
Optimized
Fuse the loops
Loop fusion reduces the

Слайд 57Loop Unrolling - I
Advanced Computer Architecture. Smruti R. Sarangi
Original loop
Assembly code
Loop Unrolling - I
Advanced Computer Architecture. Smruti R. Sarangi
Original loop
Assembly code

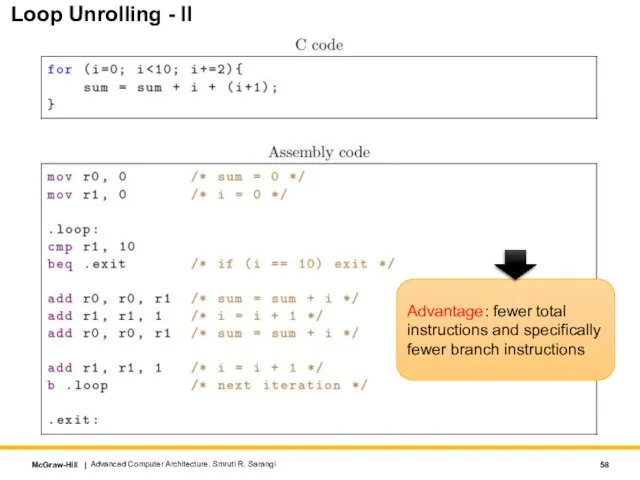
Слайд 58Advanced Computer Architecture. Smruti R. Sarangi
Loop Unrolling - II
Advantage: fewer total instructions
Advanced Computer Architecture. Smruti R. Sarangi
Loop Unrolling - II
Advantage: fewer total instructions
Слайд 59Advanced Computer Architecture. Smruti R. Sarangi
Software Pipelining
Advanced Computer Architecture. Smruti R. Sarangi
Software Pipelining

Слайд 60Advanced Computer Architecture. Smruti R. Sarangi
L
S
I
Advanced Computer Architecture. Smruti R. Sarangi
L
S
I

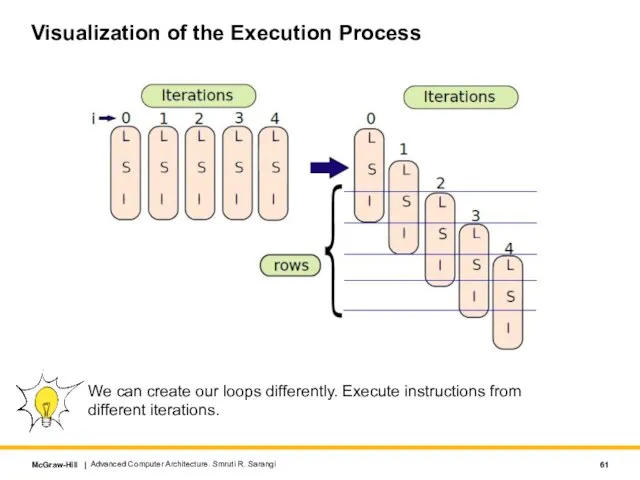
Слайд 61Visualization of the Execution Process
Advanced Computer Architecture. Smruti R. Sarangi
We can create
Visualization of the Execution Process
Advanced Computer Architecture. Smruti R. Sarangi
We can create
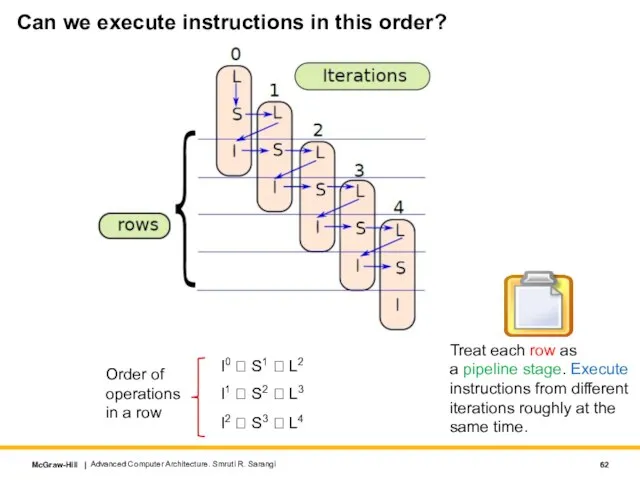
Слайд 62Can we execute instructions in this order?
Advanced Computer Architecture. Smruti R.
Can we execute instructions in this order?
Advanced Computer Architecture. Smruti R.
Слайд 63Advantages of Software Pipelining
Consider this order:
I0 ? S1 ? L2 ?
Advantages of Software Pipelining
Consider this order:
I0 ? S1 ? L2 ?

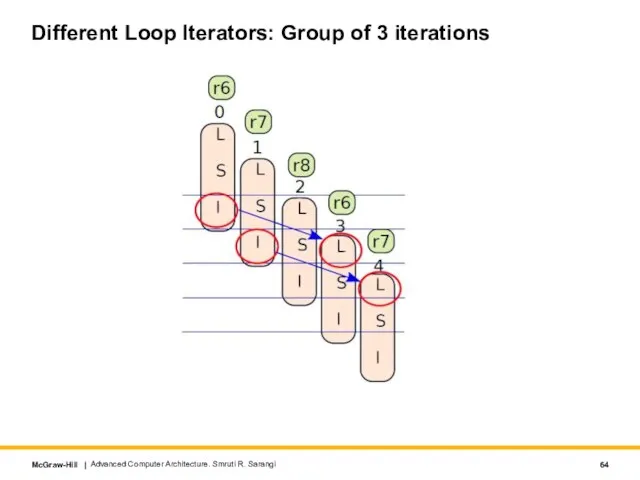
Слайд 64Different Loop Iterators: Group of 3 iterations
Advanced Computer Architecture. Smruti R. Sarangi
Different Loop Iterators: Group of 3 iterations
Advanced Computer Architecture. Smruti R. Sarangi
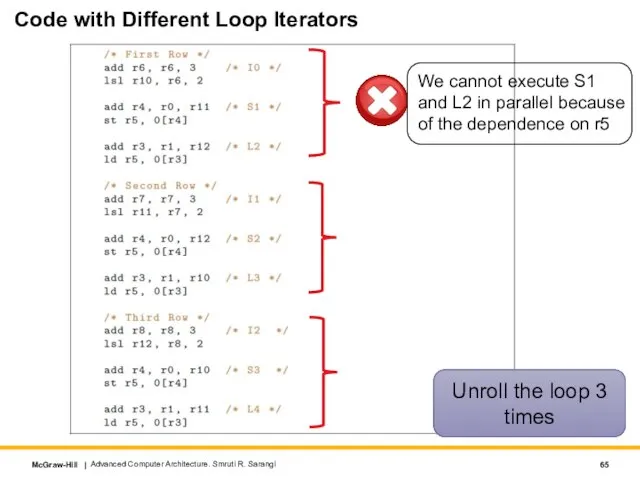
Слайд 65Code with Different Loop Iterators
Advanced Computer Architecture. Smruti R. Sarangi
Unroll the loop
Code with Different Loop Iterators
Advanced Computer Architecture. Smruti R. Sarangi
Unroll the loop
Слайд 66Advanced Computer Architecture. Smruti R. Sarangi
If we had 32 registers, we could
Advanced Computer Architecture. Smruti R. Sarangi
If we had 32 registers, we could

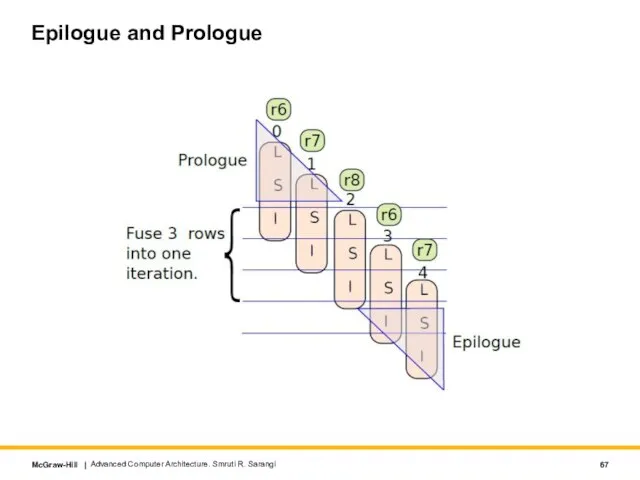
Слайд 67Epilogue and Prologue
Advanced Computer Architecture. Smruti R. Sarangi
Epilogue and Prologue
Advanced Computer Architecture. Smruti R. Sarangi
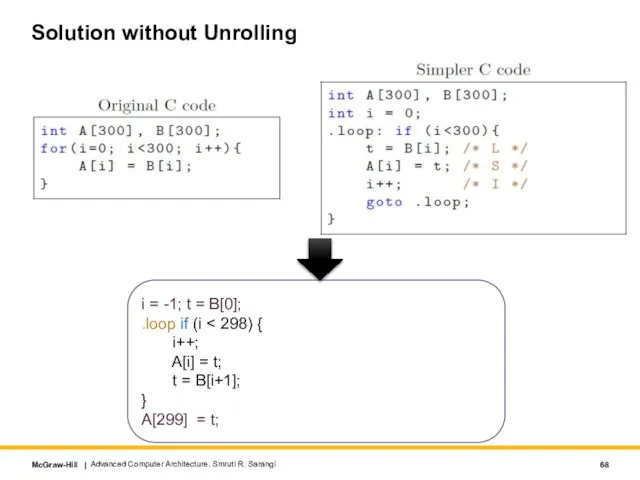
Слайд 68Solution without Unrolling
Advanced Computer Architecture. Smruti R. Sarangi
i = -1; t =
Solution without Unrolling
Advanced Computer Architecture. Smruti R. Sarangi
i = -1; t =
Слайд 69Unrolling and Mixing
Advanced Computer Architecture. Smruti R. Sarangi
Unrolling and Mixing
Advanced Computer Architecture. Smruti R. Sarangi

Слайд 70Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based
Contents
Advanced Computer Architecture. Smruti R. Sarangi
Simpler Version of an OOO Processor
Compiler based

Слайд 71.
Sounds like a promising idea …
Less hardware ? less power, less complexity
Modern
.
Sounds like a promising idea …
Less hardware ? less power, less complexity
Modern
Слайд 72VLIW Processors
VLIW (Very Long Instruction Word) processors were the first designs in
VLIW Processors
VLIW (Very Long Instruction Word) processors were the first designs in
Слайд 73If Statements: Predicated Execution
Use predicated execution (remember GPUs).
Advanced Computer Architecture. Smruti R.
If Statements: Predicated Execution
Use predicated execution (remember GPUs).
Advanced Computer Architecture. Smruti R.
Слайд 74Curious Case of Memory Instructions
We can have multiple memory instructions in a
Curious Case of Memory Instructions
We can have multiple memory instructions in a

Слайд 75VLIW vs EPIC
Advanced Computer Architecture. Smruti R. Sarangi
Given that VLIW processors do
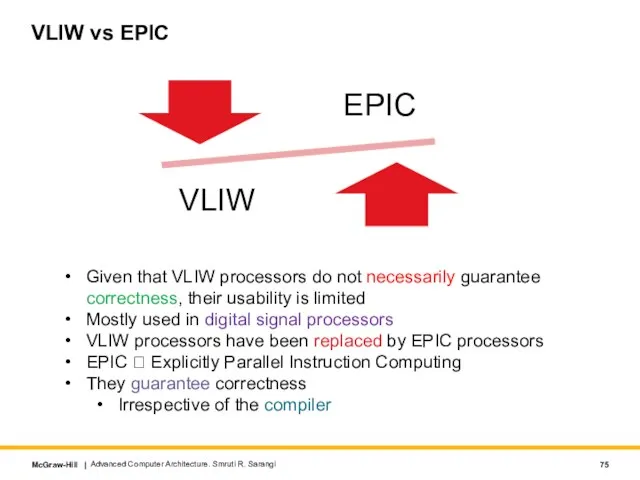
VLIW vs EPIC
Advanced Computer Architecture. Smruti R. Sarangi
Given that VLIW processors do
Слайд 76Intel Itanium Processor
Unique collaboration between Intel and HP
Aim:
EPIC processor
Designed to leverage
Intel Itanium Processor
Unique collaboration between Intel and HP
Aim:
EPIC processor
Designed to leverage

Слайд 77Fetch Stage
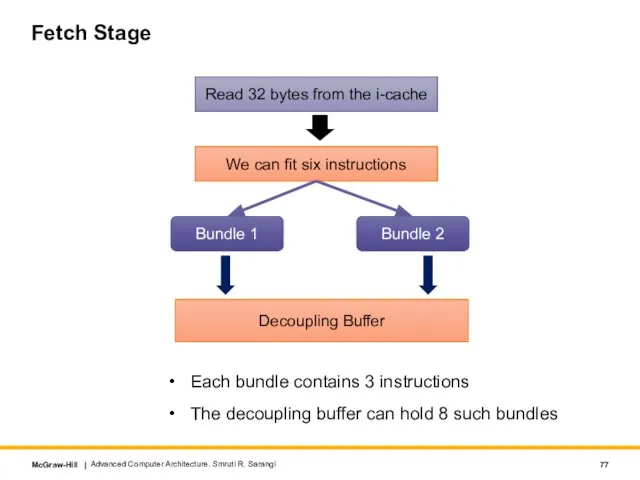
Each bundle contains 3 instructions
The decoupling buffer can hold 8 such
Fetch Stage
Each bundle contains 3 instructions
The decoupling buffer can hold 8 such
Слайд 78Branch Predictors
Itanium has four types of branch predictors
Compiler directed
Four special registers: Target
Branch Predictors
Itanium has four types of branch predictors
Compiler directed
Four special registers: Target

Слайд 79Branch Predictors – II
Multi-way Branches
Compilers ensure that (typically) the last instruction
Branch Predictors – II
Multi-way Branches
Compilers ensure that (typically) the last instruction

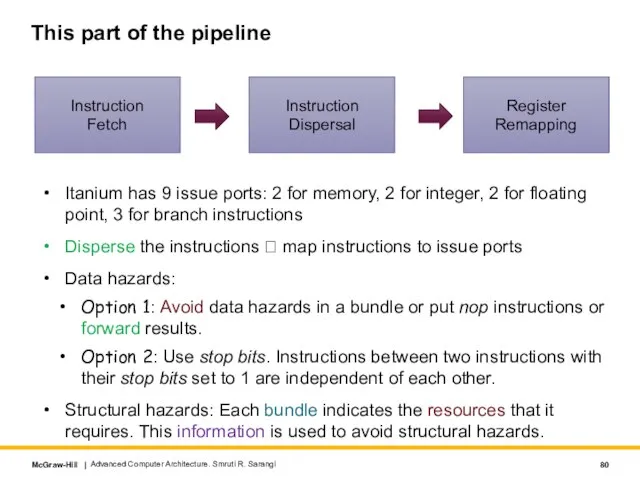
Слайд 80This part of the pipeline
Itanium has 9 issue ports: 2 for memory,
This part of the pipeline
Itanium has 9 issue ports: 2 for memory,
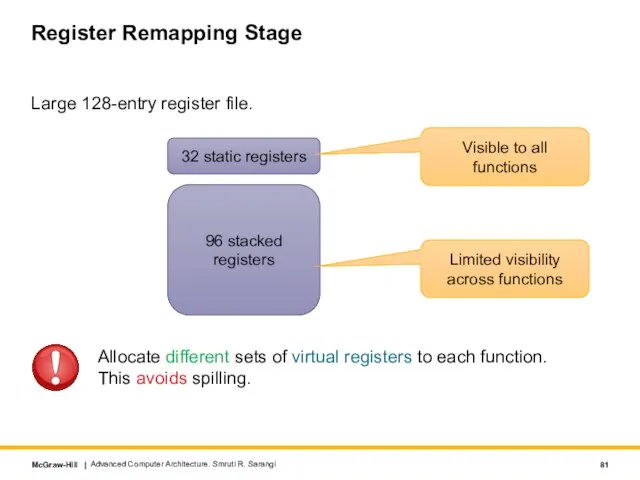
Слайд 81Register Remapping Stage
Large 128-entry register file.
Advanced Computer Architecture. Smruti R. Sarangi
32 static
Register Remapping Stage
Large 128-entry register file.
Advanced Computer Architecture. Smruti R. Sarangi
32 static
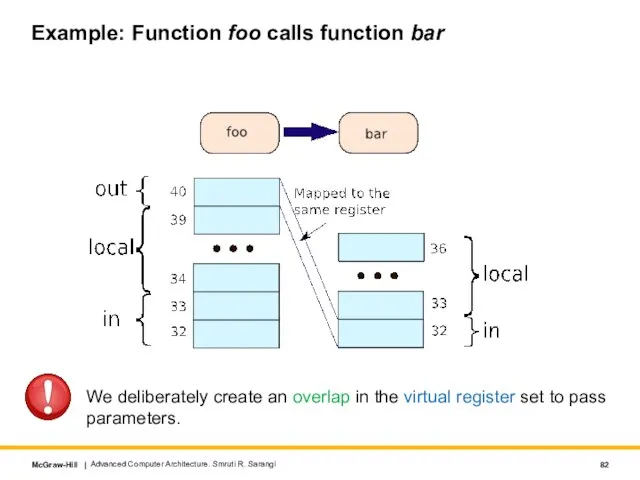
Слайд 82Example: Function foo calls function bar
Advanced Computer Architecture. Smruti R. Sarangi
We deliberately
Example: Function foo calls function bar
Advanced Computer Architecture. Smruti R. Sarangi
We deliberately
Слайд 83Register Stack Frame
The in and local registers are preserved across function calls.
The
Register Stack Frame
The in and local registers are preserved across function calls.
The

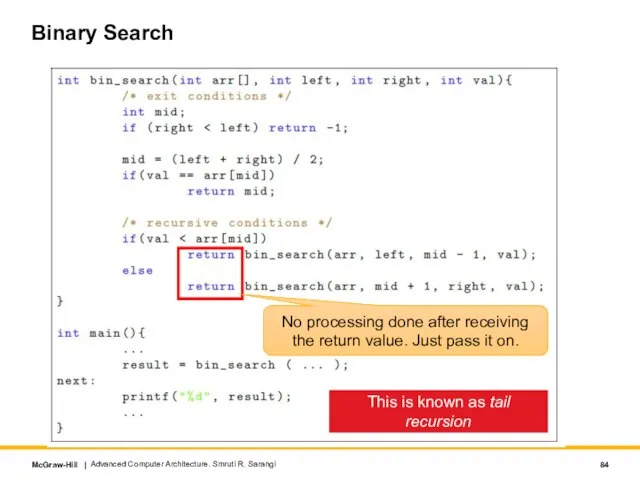
Слайд 84Binary Search
Advanced Computer Architecture. Smruti R. Sarangi
No processing done after receiving the
Binary Search
Advanced Computer Architecture. Smruti R. Sarangi
No processing done after receiving the
Слайд 85Register Stack Frame
The in and local registers are preserved across function calls.
The
Register Stack Frame
The in and local registers are preserved across function calls.
The

Слайд 86Support for Software Pipelining and Overflows
Main Problem: We run out of registers
Support for Software Pipelining and Overflows
Main Problem: We run out of registers

Слайд 87High Performance Execution Engine
Advanced Computer Architecture. Smruti R. Sarangi
Scoreboard
Simple mechanism for OOO
High Performance Execution Engine
Advanced Computer Architecture. Smruti R. Sarangi
Scoreboard
Simple mechanism for OOO
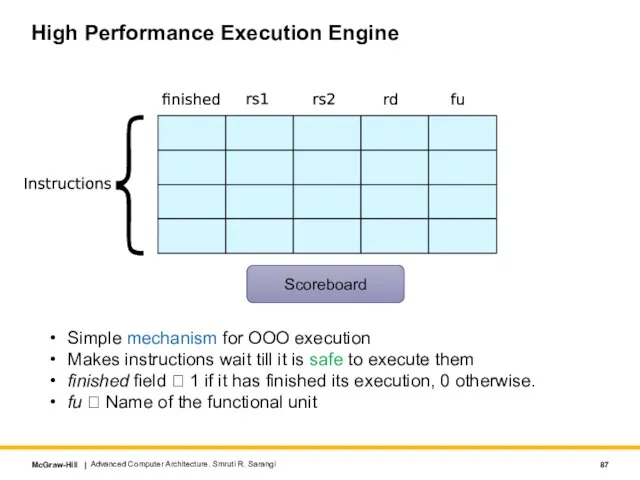
Слайд 88Conditions: Instruction I
Advanced Computer Architecture. Smruti R. Sarangi
WAW Hazards
Check all the
Conditions: Instruction I
Advanced Computer Architecture. Smruti R. Sarangi
WAW Hazards
Check all the

Слайд 89Conditions: II
Instructions wait in the scoreboard until they are safe
No hazards
Advanced Computer
Conditions: II
Instructions wait in the scoreboard until they are safe
No hazards
Advanced Computer

Слайд 90Predication
If we flush the pipeline upon a branch misprediction
It would be quite
Predication
If we flush the pipeline upon a branch misprediction
It would be quite

Слайд 91Code without Predication
Count the number of branch instructions.
Advanced Computer Architecture. Smruti R.
Code without Predication
Count the number of branch instructions.
Advanced Computer Architecture. Smruti R.

Слайд 92Predicated Instructions
The comparison generates predicates (flags)
po ? number is odd, pe ?
Predicated Instructions
The comparison generates predicates (flags)
po ? number is odd, pe ?

Слайд 93Advanced Computer Architecture. Smruti R. Sarangi
Pipeline
Advanced Computer Architecture. Smruti R. Sarangi
Pipeline
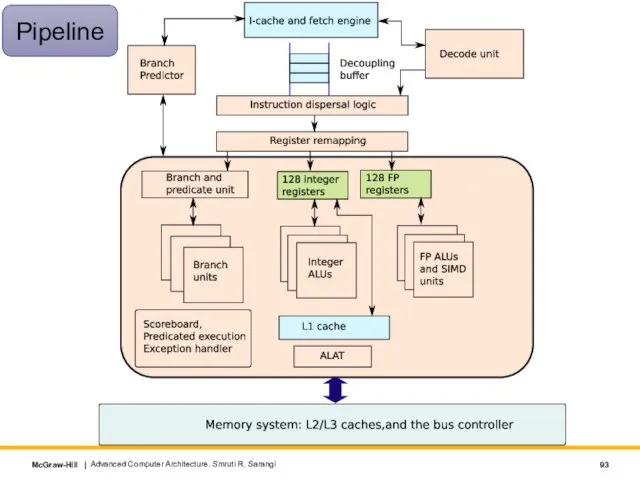
Слайд 94Load Boosting
Boost a load and some instructions that use its value to
Load Boosting
Boost a load and some instructions that use its value to

Слайд 95Advanced Computer Architecture. Smruti R. Sarangi
A host of compiler optimizations can be
Advanced Computer Architecture. Smruti R. Sarangi
A host of compiler optimizations can be

 Руководство по тестированию в Agile
Руководство по тестированию в Agile Федеральное агентство по техническому регулированию
Федеральное агентство по техническому регулированию Качество. Безопасность. Инновации
Качество. Безопасность. Инновации Education in England
Education in England Игры с числами
Игры с числами Четырехполюсники. Коэффициенты передачи
Четырехполюсники. Коэффициенты передачи Презентация на тему Рекомендации родителям по укреплению здоровья детей
Презентация на тему Рекомендации родителям по укреплению здоровья детей Развитие футбола. Проект для вовлечение молодёжи в занятия футболом
Развитие футбола. Проект для вовлечение молодёжи в занятия футболом Вегетативные органы растений 6 класс
Вегетативные органы растений 6 класс Society in the 1920 s
Society in the 1920 s  Презентация_шаблон
Презентация_шаблон Презентация на тему ЕГЭ Сочинение-рассуждение
Презентация на тему ЕГЭ Сочинение-рассуждение Презентация на тему Образ святого Александра Невского в культуре и литературе
Презентация на тему Образ святого Александра Невского в культуре и литературе  Виды ипотечных сделок
Виды ипотечных сделок Факторы принятия автократами решений в условиях институциональных ограничений
Факторы принятия автократами решений в условиях институциональных ограничений Административное право как отрасль права
Административное право как отрасль права Системи Підтримки Прийняття Рішень типу“Ситуаційні Центри”Огляд ІПММС НАНУ,2011р.
Системи Підтримки Прийняття Рішень типу“Ситуаційні Центри”Огляд ІПММС НАНУ,2011р. Очистка поверхностных вод Минско-Вилейской системы
Очистка поверхностных вод Минско-Вилейской системы Доливо-Добровольский Михаил Осипович
Доливо-Добровольский Михаил Осипович xxx Обновленная очищающая линия Lumene 2011 Май 2011.
xxx Обновленная очищающая линия Lumene 2011 Май 2011. Презентация на тему Формирование самооценки
Презентация на тему Формирование самооценки Связи с общественностью как эффективная модель коммуникативного взаимодействия организации с целевыми аудиториями
Связи с общественностью как эффективная модель коммуникативного взаимодействия организации с целевыми аудиториями Вспоминайте нас
Вспоминайте нас Irish Whiskey
Irish Whiskey  Презентация на тему В гости к весне
Презентация на тему В гости к весне Подготовка к глобальной империи
Подготовка к глобальной империи Приготовление изделий из слоёного теста. 7 класс
Приготовление изделий из слоёного теста. 7 класс Архитектура Древней Греции
Архитектура Древней Греции