- Data Scientist. Рекомендательные системы

Содержание
- 2. План работы: 1. Постановка задачи, исходные данные и что с ними нужно сделать. 2. Подсчет топ
- 3. Постановка задачи: Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей каждого пользователя. Представим
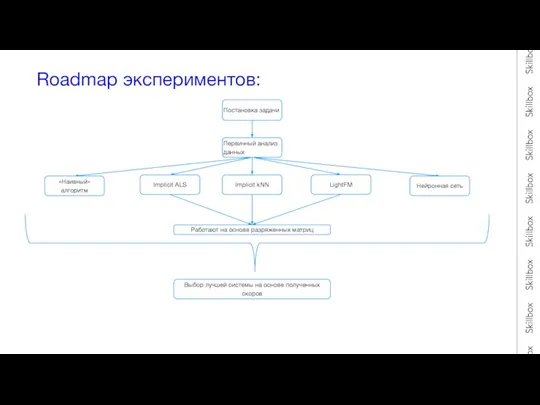
- 4. Roadmap экспериментов: Постановка задачи «Наивный» алгоритм Implicit ALS Implicit kNN LightFM Работают на основе разряженных матриц
- 5. Разбор алгоритмов: С ним все просто: мы группируем данные по пользователю и считаем кол-во купленных за
- 6. Разбор алгоритмов: Impllicit: Удобная и быстрая подготовка данных Возможность явно передать прямо в библ. модель кол-во
- 7. Несколько слов о разряженных матрицах. Ключевым элементов в работе вышеописанных библиотек является т н разряженная матрица
- 8. Алгоритм на основе нейронной сети. В качестве вишенки на торте и чего-то по-настоящему рабочего было решено
- 9. Архитектура нейросети: 2 входа отдельно для продуктовых и пользовательских признаков Превращаем данные в одномерный тензор Объединение
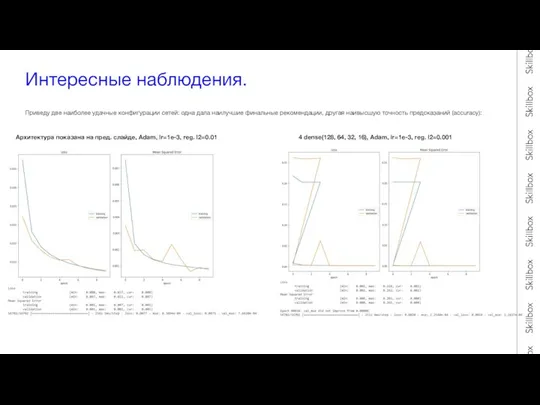
- 10. Интересные наблюдения. Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации, другая наивысшую точность
- 11. Формирование рекомендаций по предсказаниям нейросети: Вид итогового датафрейма, отсортированного по величине выхода сигмоиды: Как было сказано
- 13. Скачать презентацию

Слайд 3Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей
каждого
Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей
каждого

Слайд 4Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ данных
Нейронная
Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ данных
Нейронная
Слайд 5Разбор алгоритмов:
С ним все просто: мы группируем данные по пользователю и считаем
Разбор алгоритмов:
С ним все просто: мы группируем данные по пользователю и считаем

Слайд 6Разбор алгоритмов:
Impllicit:
Удобная и быстрая подготовка данных
Возможность явно передать прямо в библ. модель
Разбор алгоритмов:
Impllicit:
Удобная и быстрая подготовка данных
Возможность явно передать прямо в библ. модель

Слайд 7Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является т
Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является т

Слайд 8Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то по-настоящему
Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то по-настоящему

Слайд 9Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в одномерный
Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в одномерный

Слайд 10Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации,
Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации,
Слайд 11Формирование рекомендаций по предсказаниям нейросети:
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как
Формирование рекомендаций по предсказаниям нейросети:
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как

 Исследование цветозвукового фона стихотворений в среде Microsoft Excel
Исследование цветозвукового фона стихотворений в среде Microsoft Excel Пришвин М.М.
Пришвин М.М. Сутність маркетинговой деятельности
Сутність маркетинговой деятельности  Виды спорта Великобритании. Конные бега
Виды спорта Великобритании. Конные бега ВЫБОР ПРОФЕССИИ – ЭТО СЕРЬЁЗНО
ВЫБОР ПРОФЕССИИ – ЭТО СЕРЬЁЗНО ДЗ (2)
ДЗ (2)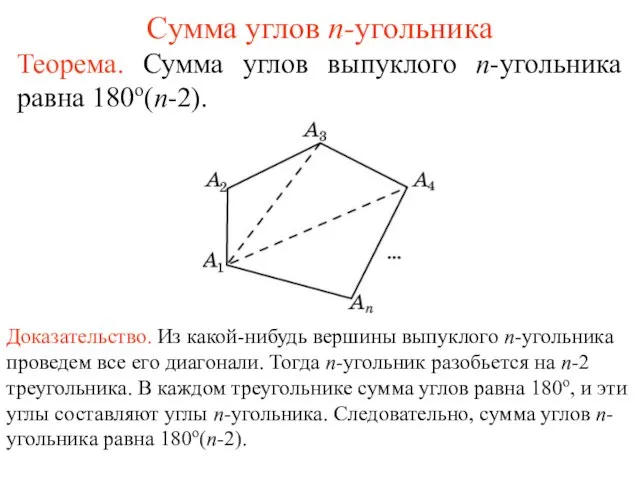 Сумма углов n-угольника
Сумма углов n-угольника Better Cotton (ВС/ТВС). Хлопок из устойчивых источников
Better Cotton (ВС/ТВС). Хлопок из устойчивых источников О моделировании инновационной обучающей среды университета
О моделировании инновационной обучающей среды университета Фармакоэпидемиология
Фармакоэпидемиология Свойства логарифмов
Свойства логарифмов  Характеристика направления «Экономика» (магистратура)
Характеристика направления «Экономика» (магистратура) Анатолий Аксаков Заместитель председателя Комитета Госдумы по кредитным организациям и финансовым рынкам Член Национального ба
Анатолий Аксаков Заместитель председателя Комитета Госдумы по кредитным организациям и финансовым рынкам Член Национального ба ВСЕРОССИЙСКИЙ КОНКУРС ПЕДАГОГИЧЕСКОГО МАСТЕРСТВА "ФОРМУЛА БУДУЩЕГО-2011": ИТОГИ, УРОКИ, ПЕРСПЕКТИВЫ
ВСЕРОССИЙСКИЙ КОНКУРС ПЕДАГОГИЧЕСКОГО МАСТЕРСТВА "ФОРМУЛА БУДУЩЕГО-2011": ИТОГИ, УРОКИ, ПЕРСПЕКТИВЫ Классики о книгах
Классики о книгах Теоремы синусов и косинусов
Теоремы синусов и косинусов  Бизнес-результаты ППФ страхование жизни
Бизнес-результаты ППФ страхование жизни Презентация на тему ЖУК-НОСОРОГ
Презентация на тему ЖУК-НОСОРОГ Задача на подбор сечения
Задача на подбор сечения Сетевые продажи
Сетевые продажи Подпрограмма «Развитие Москвы как Международного финансового центра»
Подпрограмма «Развитие Москвы как Международного финансового центра» О мерах по повышению эффективности международных контейнерных перевозок с использованием Транссибирской магистрали
О мерах по повышению эффективности международных контейнерных перевозок с использованием Транссибирской магистрали Черепаха на острове
Черепаха на острове Посёлок Котельное
Посёлок Котельное Сжатие текста Урок русского языка, 9 класс, подготовка к ГИА 9
Сжатие текста Урок русского языка, 9 класс, подготовка к ГИА 9 Роль отца в воспитании ребенка
Роль отца в воспитании ребенка Управление качеством
Управление качеством синтаксис (1)
синтаксис (1)