- «Есть ли жизнь после MPI?»

Содержание
- 2. Абрамов С.М.†, Климов А.В. ‡, Лацис А.О. ‡, Московский А.А. † †ИПС имени А.К.Айламазяна РАН ‡ИПМ
- 3. Переславль-Залесский. Институт программных систем имени А.К.Айламазяна Российской академии наук * СКИФ-ГРИД © 2009 Все права защищены
- 4. Переславль-Залесский Красивый старинный (860 лет) город России на берегу Плещеева озера Центр Золотого кольца Родина Св.Александра
- 5. ИПС имени А.К.Айламазяна РАН, Переславль-Залесский * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 6. Основание Института Основан в 1984 году по постановлению ВПК для развития информатики и вычислительной техники в
- 7. 2009: Организационная структура института Исследовательский центр искусственного интеллекта Исследовательский центр медицинской информатики Исследовательский центр мультипроцессорных систем
- 8. Университет города Переславля имени А.К.Айламазяна * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 9. Программы «СКИФ» и «СКИФ-ГРИД» Заказчики-координаторы НАН Беларуси Агентство «Роснаука» Головные исполнители Объединенный институт проблем информатики НАН
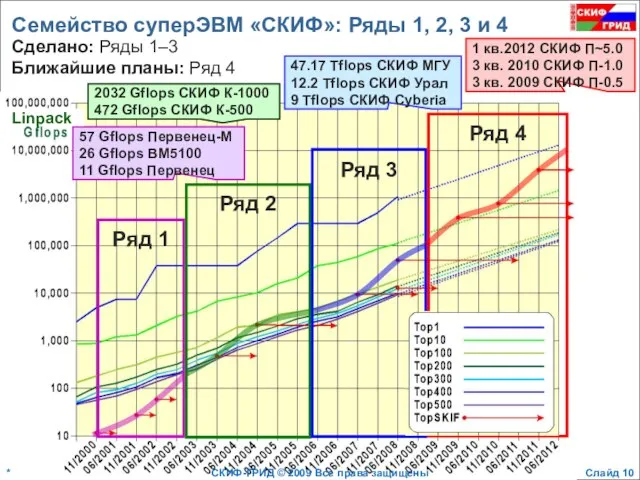
- 10. Семейство суперЭВМ «СКИФ»: Ряды 1, 2, 3 и 4 2032 Gflops СКИФ К-1000 472 Gflops СКИФ
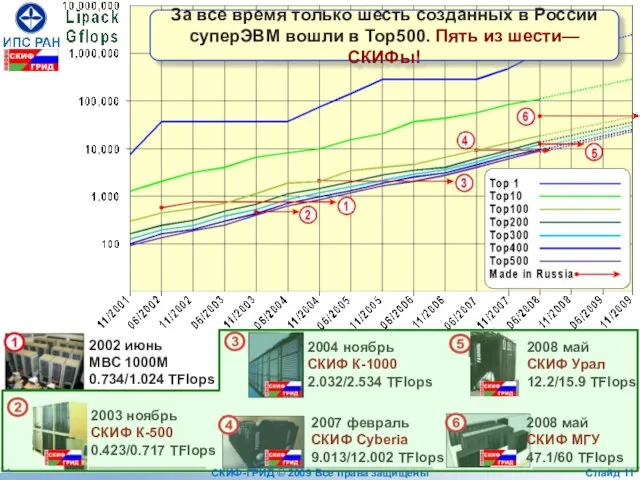
- 11. 2002 июнь МВС 1000M 0.734/1.024 TFlops 2003 ноябрь СКИФ К-500 0.423/0.717 TFlops 2004 ноябрь СКИФ К-1000
- 12. Что затрудняет эффективное использование MPI в суперЭВМ ближайшего будущего? * СКИФ-ГРИД © 2009 Все права защищены
- 13. Проблемы MPI Рост числа процессоров (и ядер) в суперЭВМ будет продолжаться Сегодня 1 Pflops ≈ 20,000
- 14. Т-система: автоматическое динамическое распараллеливание программ * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 15. Т-система (неформально) Функциональная модель + императивное описание тела функции Арность и коарность функций Готовые и неготовые
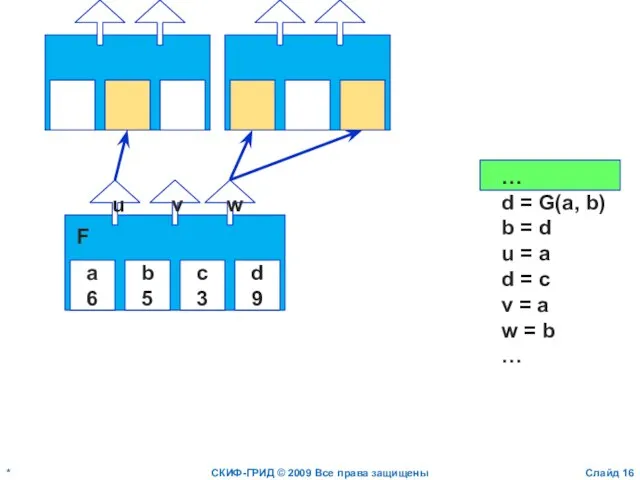
- 16. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b 5 c 3 d 9
- 17. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b 5 c 3 d u
- 18. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b c 3 d u v
- 19. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b c 3 d u v
- 20. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b c 3 d 3 u
- 21. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b c 3 d 3 u
- 22. * СКИФ-ГРИД © 2009 Все права защищены Слайд a 6 b c 3 d 3 u
- 23. * СКИФ-ГРИД © 2009 Все права защищены Слайд 6 6 5 G
- 24. T-System History Mid-80-ies Basic ideas of T-System 1990-ies First implementation of T-System 2001-2002, “SKIF” GRACE —
- 25. Open TS Overview
- 26. Comparison: T-System and MPI Sequential Parallel
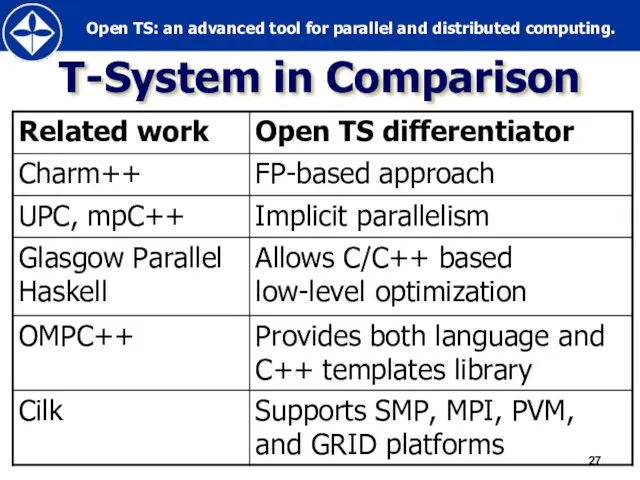
- 27. T-System in Comparison
- 28. Open TS: an Outline High-performance computing “Automatic dynamic parallelization” Combining functional and imperative approaches, high-level parallel
- 29. Т-Approach “Pure” functions (tfunctions) invocations produce grains of parallelism T-Program is Functional – on higher level
- 30. Т++ Keywords tfun — Т-function tval — Т-variable tptr — Т-pointer tout — Output parameter (like
- 31. Short Introduction (Sample Programs)
- 32. #include int fib (int n) { return n } int main (int argc, char **argv) {
- 33. #include tfun int fib (int n) { return n } tfun int main (int argc, char
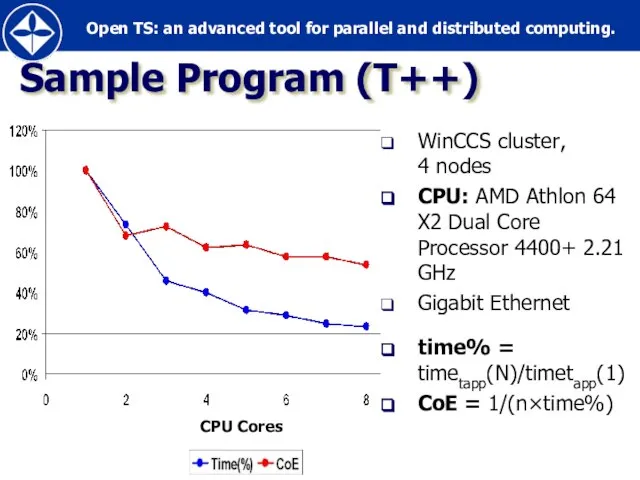
- 34. Sample Program (T++) WinCCS cluster, 4 nodes CPU: AMD Athlon 64 X2 Dual Core Processor 4400+
- 35. Approximate calculation of Pi (C++) #include #include #include double isum(double begin, double finish, double d) {
- 36. Approximate calculation of Pi (T++) #include #include #include tfun double isum(double begin, double finish, double d)
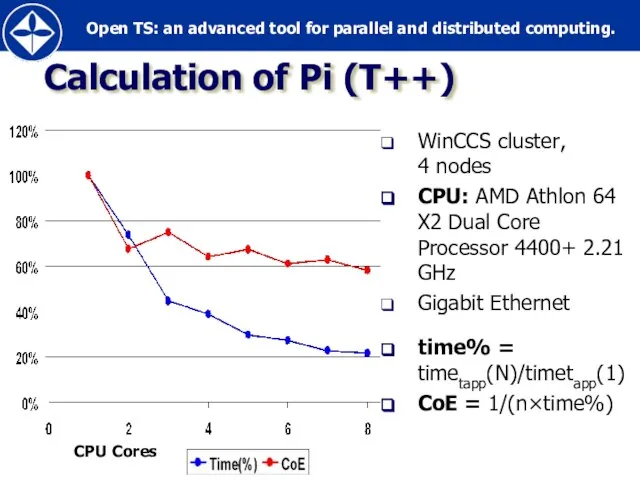
- 37. Calculation of Pi (T++) WinCCS cluster, 4 nodes CPU: AMD Athlon 64 X2 Dual Core Processor
- 38. Map-Reduce ----- Original Message ----- From: Alexy Maykov Sent: Monday, October 02, 2006 11:58 PM Subject:
- 39. Map-Reduce (C++) #include #include #include #include #include using namespace std; int fib (int n) { return
- 40. Map-Reduce (C++) #include #include #include #include #include using namespace std; int fib (int n) { return
- 41. Map-Reduce (C++) #include #include #include #include #include using namespace std; int fib (int n) { return
- 42. Map-Reduce (C++) #include #include #include #include #include using namespace std; int fib (int n) { return
- 43. Map-Reduce (C++) #include #include #include #include #include using namespace std; int fib (int n) { return
- 44. Map-Reduce (T++) #include #include #include #include #include using namespace std; tfun int fib (int n) {
- 45. Map-Reduce (T++): “Laziness”
- 46. Map-Reduce (T++) WinCCS cluster, 4 nodes CPU: AMD Athlon 64 X2 Dual Core Processor 4400+ 2.21
- 47. Inside OpenTS
- 48. Open TS: Environment Supports more then 1,000,000 threads per core
- 49. Supermemory Utilization: non-ready values, resource and status information, etc. Object-Oriented Distributed shared memory (OO DSM) Global
- 50. Multithreading & Communications Lightweight threads PIXELS (1 000 000 threads) Asynchronous communications A thread “A” asks
- 51. Open TS applications (selected)
- 52. MultiGen Chelyabinsk State University Level 0 Level 1 Level 2 Multi-conformation model К0 К11 К12 К21
- 53. MultiGen: Speedup National Cancer Institute USA Reg.No. NCI-609067 (AIDS drug lead) TOSLAB company (Russia-Belgium) Reg.No. TOSLAB
- 54. Aeromechanics Institute of Mechanics, MSU
- 55. Belocerkovski’s approach flow presented as a collection of small elementary whirlwind (colours: clockwise and contra-clockwise rotation)
- 56. Creating space-born radar image from hologram Space Research Institute Development
- 57. Simulating broadband radar signal Graphical User Interface Non-PSI RAS development team (Space research institute of Khrunichev
- 58. Landsat Image Classification Computational “web-service”
- 59. Open TS vs. MPI case study
- 60. Applications Popular and widely used Developed by independent teams (MPI experts) PovRay – Persistence of Vision
- 61. T-PovRay vs. MPI PovRay: code complexity ~7—15 times
- 62. T-PovRay vs. MPI PovRay: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE, LAM 7.1.1
- 63. T-PovRay vs MPI PovRay: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE, LAM 7.1.1
- 64. ALCMD/MPI vs ALCMD/OpenTS MP_Lite component of ALCMD rewritten in T++ Fortran code is left intact
- 65. ALCMD/MPI vs ALCMD/OpenTS : code complexity ~7 times
- 66. ALCMD/MPI vs ALCMD/OpenTS: performance 16 dual Athlon 1800, AMD Athlon MP 1800+ RAM 1GB, FastEthernet, LAM
- 67. ALCMD/MPI vs ALCMD/OpenTS: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE, LAM 7.1.1, Lennard-Jones
- 68. ALCMD/MPI vs ALCMD/OpenTS: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, InfiniBand,MVAMPICH 0.9.4, Lennard-Jones MD,512000
- 69. ALCMD/MPI vs ALCMD/OpenTS: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE, LAM 7.1.1, Lennard-Jones
- 70. ALCMD/MPI vs ALCMD/OpenTS: performance 2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, InfiniBand,MVAMPICH 0.9.4, Lennard-Jones MD,512000
- 71. Porting OpenTS to MS Windows CCS
- 72. 2006: contract with Microsoft “Porting OpenTS to Windows Compute Cluster Server” OpenTS@WinCCS inherits all basic features
- 73. OpenTS@WinCCS AMD64 and x86 platforms are currently supported Integration into Microsoft Visual Studio 2005 Two ways
- 74. Installer of OpenTS for Windows XP/2003/WCCS
- 75. OpenTS integration into Microsoft Visual Studio 2005
- 76. Open TS “Gadgets”
- 77. Web-services, Live documents tfun int fib (int n) { return n } twsgen Perl script
- 78. Trace visualizer Collect trace of T-program execution Visualize performance metrics of OpenTS runtime
- 79. Fault-tolerance Recalculation based fault-tolerance (+) Very simple (in comparison with full transactional model) (+) Efficient (only
- 80. Some other Gadgets Other T-languages: T-Refal, T-Fortan Memoization Automatically choosing between call-style and fork-style of function
- 81. Full / Empty Bit (FEB) и Т-Система * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 82. FEB Модель вычисления: «общая память» легковесные нити FEB — бит синхронизации на каждое слово Тонкости: фьючеры
- 83. Монотонные объекты, как безопасное расширение функциональной модели * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 84. Идеи расширения Монотонные объекты — обладают свойством Черча-Россера Типичная жизнь монотонного объекта: Создание и инициализация объекта
- 85. Библиотеки односторонних обменов — SHMEM, Gasnet, ARMCI * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 86. Основные черты технологии SHMEM «Чужие» данные не обрабатываются на месте, а копируются предварительно туда, где они
- 87. Технология SHMEM Рассчитана на полностью однородные многопроцессорные вычислители (общность системы команд, машинного представления чисел, одинаковая операционная
- 88. SHMEM: Односторонние обмены put --- односторонняя запись в чужую память get --- одностороннее чтение из чужой
- 89. SHMEM: Операции синхронизации Возможность выполнить барьерную синхронизацию всех или лишь указанных процессов. При выполнении синхронизации гарантируется,
- 90. Ожидание переменной shmem_wait( &var, value ) — на «==» ожидание &var == value shmem_int_wait_until( &var, SHMEM_CMP_GT,
- 91. Модели PGAS (Partitioned Global Address Space), DSM (Distributed Shared Memory), языки Co-Array Fortran, UPC… * СКИФ-ГРИД
- 92. Модель памяти Разделяемая (shared) память Любой процесс может использовать ее или указывать на нее Приватная память
- 93. Что такое UPC Unified Parallel C Расширение ANSI C примитивами задания явного параллелизма Основан на «distributed
- 94. Модель исполнения Несколько процессов (нитей 0..THREADS-1) работают независимо MYTHREAD определяет номер процесса THREADS — число процессов
- 95. Пример 1 //vect_add.c #include #define N 100*THREADS shared int a[N], b[N], c[N]; void main(){ int i;
- 96. Вместо заключения * СКИФ-ГРИД © 2009 Все права защищены Слайд
- 98. Скачать презентацию

Слайд 3Переславль-Залесский.
Институт программных систем
имени А.К.Айламазяна
Российской академии наук
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Переславль-Залесский.
Институт программных систем
имени А.К.Айламазяна
Российской академии наук
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 4Переславль-Залесский
Красивый старинный (860 лет)
город России на берегу Плещеева озера
Центр Золотого кольца
Родина
Переславль-Залесский
Красивый старинный (860 лет)
город России на берегу Плещеева озера
Центр Золотого кольца
Родина
Слайд 5ИПС имени А.К.Айламазяна РАН,
Переславль-Залесский
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
ИПС имени А.К.Айламазяна РАН,
Переславль-Залесский
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 6Основание Института
Основан в 1984 году по постановлению ВПК для развития информатики и
Основание Института
Основан в 1984 году по постановлению ВПК для развития информатики и

Слайд 72009: Организационная структура института
Исследовательский центр искусственного интеллекта
Исследовательский центр медицинской информатики
Исследовательский центр мультипроцессорных
2009: Организационная структура института
Исследовательский центр искусственного интеллекта
Исследовательский центр медицинской информатики
Исследовательский центр мультипроцессорных

Слайд 8Университет города Переславля
имени А.К.Айламазяна
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Университет города Переславля
имени А.К.Айламазяна
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 9Программы «СКИФ» и «СКИФ-ГРИД»
Заказчики-координаторы
НАН Беларуси
Агентство «Роснаука»
Головные исполнители
Объединенный институт проблем
информатики НАН Беларуси
Институт
Программы «СКИФ» и «СКИФ-ГРИД»
Заказчики-координаторы
НАН Беларуси
Агентство «Роснаука»
Головные исполнители
Объединенный институт проблем
информатики НАН Беларуси
Институт

Слайд 10Семейство суперЭВМ «СКИФ»: Ряды 1, 2, 3 и 4
2032 Gflops СКИФ К-1000
472
Семейство суперЭВМ «СКИФ»: Ряды 1, 2, 3 и 4
2032 Gflops СКИФ К-1000
472
Слайд 112002 июнь
МВС 1000M
0.734/1.024 TFlops
2003 ноябрь
СКИФ К-500
0.423/0.717 TFlops
2004 ноябрь
СКИФ К-1000
2.032/2.534 TFlops
2007 февраль
СКИФ Cyberia
9.013/12.002
2002 июнь
МВС 1000M
0.734/1.024 TFlops
2003 ноябрь
СКИФ К-500
0.423/0.717 TFlops
2004 ноябрь
СКИФ К-1000
2.032/2.534 TFlops
2007 февраль
СКИФ Cyberia
9.013/12.002
Слайд 12Что затрудняет эффективное использование MPI в суперЭВМ ближайшего будущего?
*
СКИФ-ГРИД © 2009 Все
Что затрудняет эффективное использование MPI в суперЭВМ ближайшего будущего?
*
СКИФ-ГРИД © 2009 Все

Слайд 13Проблемы MPI
Рост числа процессоров (и ядер) в суперЭВМ будет продолжаться
Сегодня 1 Pflops
Проблемы MPI
Рост числа процессоров (и ядер) в суперЭВМ будет продолжаться
Сегодня 1 Pflops

Слайд 14Т-система: автоматическое динамическое распараллеливание программ
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Т-система: автоматическое динамическое распараллеливание программ
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 15Т-система (неформально)
Функциональная модель + императивное описание тела функции
Арность и коарность функций
Готовые и
Т-система (неформально)
Функциональная модель + императивное описание тела функции
Арность и коарность функций
Готовые и

Слайд 16*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
5
c
3
d
9
u
v
w
F
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
5
c
3
d
9
u
v
w
F
…
d = G(a, b)
b = d
u
Слайд 17*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
5
c
3
d
u
v
w
F
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
5
c
3
d
u
v
w
F
…
d = G(a, b)
b = d
u
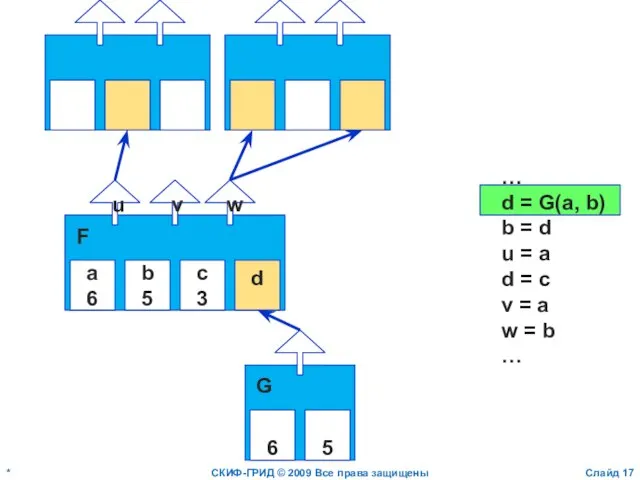
Слайд 18*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
u
v
w
F
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
u
v
w
F
…
d = G(a, b)
b = d
u
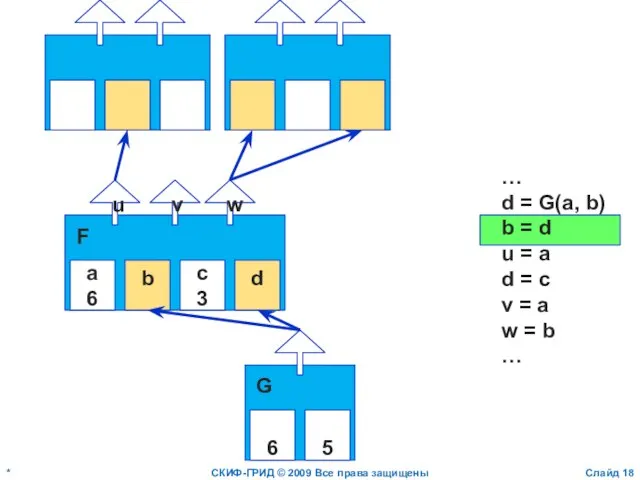
Слайд 19*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
u
v
w
F
6
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
u
v
w
F
6
…
d = G(a, b)
b = d
u
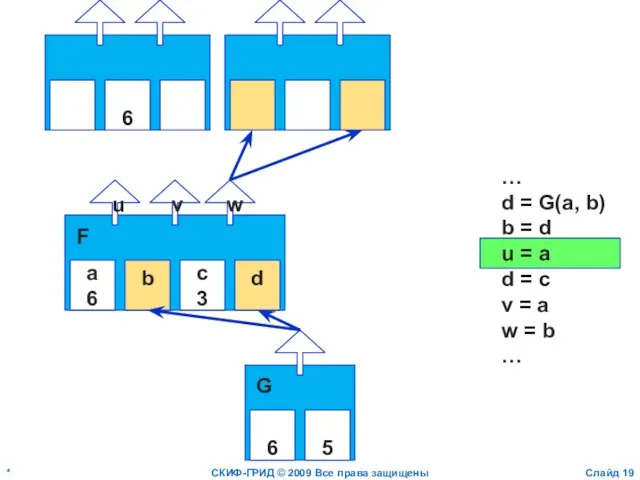
Слайд 20*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
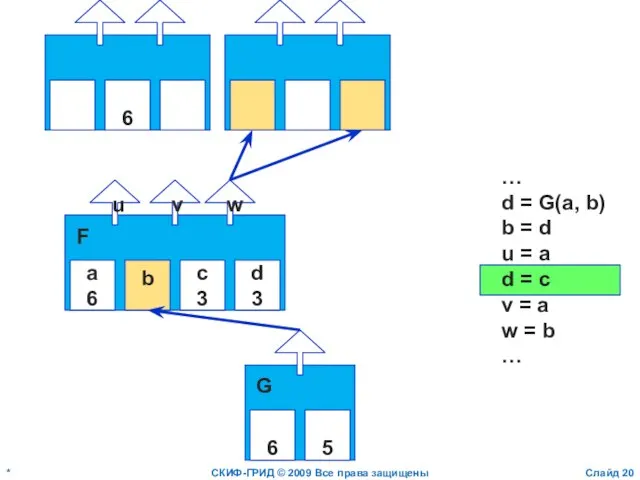
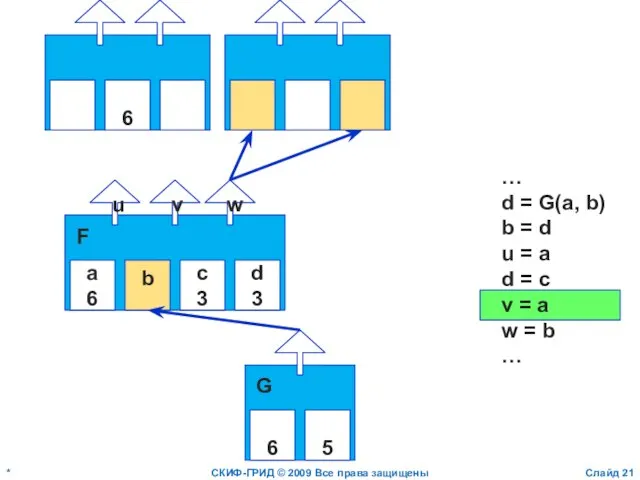
Слайд 21*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
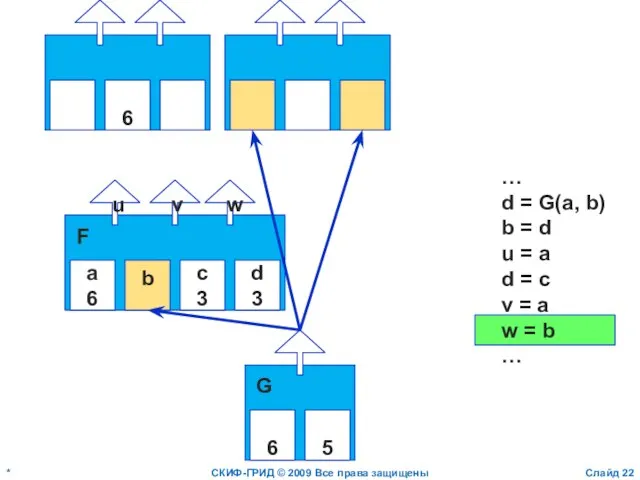
Слайд 22*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
a
6
b
c
3
d
3
u
v
w
F
6
…
d = G(a, b)
b = d
u
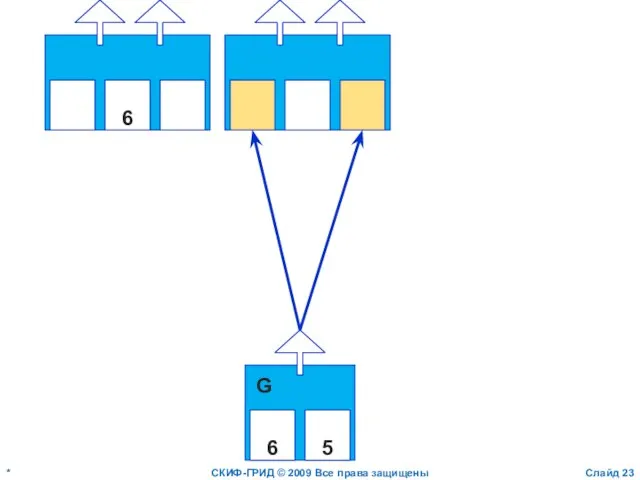
Слайд 23*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
6
6
5
G
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
6
6
5
G
Слайд 24T-System History
Mid-80-ies
Basic ideas of T-System
1990-ies
First implementation of T-System
2001-2002, “SKIF”
GRACE — Graph
T-System History
Mid-80-ies
Basic ideas of T-System
1990-ies
First implementation of T-System
2001-2002, “SKIF”
GRACE — Graph

Слайд 25
Open TS Overview
Open TS Overview

Слайд 26Comparison: T-System and MPI
Sequential
Parallel
Comparison: T-System and MPI
Sequential
Parallel
Слайд 27T-System in Comparison
T-System in Comparison
Слайд 28Open TS: an Outline
High-performance computing
“Automatic dynamic parallelization”
Combining functional and imperative approaches,
Open TS: an Outline
High-performance computing
“Automatic dynamic parallelization”
Combining functional and imperative approaches,

Слайд 29Т-Approach
“Pure” functions (tfunctions) invocations produce grains of parallelism
T-Program is
Functional – on higher
Т-Approach
“Pure” functions (tfunctions) invocations produce grains of parallelism
T-Program is
Functional – on higher

Слайд 30Т++ Keywords
tfun — Т-function
tval — Т-variable
tptr — Т-pointer
tout — Output parameter (like &)
tdrop — Make ready
twait — Wait
Т++ Keywords
tfun — Т-function
tval — Т-variable
tptr — Т-pointer
tout — Output parameter (like &)
tdrop — Make ready
twait — Wait

Слайд 31Short Introduction
(Sample Programs)
Short Introduction
(Sample Programs)

Слайд 32#include
int fib (int n) {
return n < 2 ? n :
#include
int fib (int n) {
return n < 2 ? n :

Слайд 33#include
tfun int fib (int n) {
return n < 2 ? n
#include
tfun int fib (int n) {
return n < 2 ? n

Слайд 34Sample Program (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core Processor
Sample Program (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core Processor
Слайд 35Approximate calculation of Pi (C++)
#include
#include
#include
double
isum(double begin, double finish, double
Approximate calculation of Pi (C++)
#include
#include
#include
double
isum(double begin, double finish, double

Слайд 36Approximate calculation of Pi (T++)
#include
#include
#include
tfun double
isum(double begin, double finish,
Approximate calculation of Pi (T++)
#include
#include
#include
tfun double
isum(double begin, double finish,

Слайд 37Calculation of Pi (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core
Calculation of Pi (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core
Слайд 38Map-Reduce
----- Original Message -----
From: Alexy Maykov
Sent: Monday, October 02, 2006 11:58 PM
Subject:
Map-Reduce
----- Original Message ----- From: Alexy Maykov Sent: Monday, October 02, 2006 11:58 PM Subject:
Слайд 39Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{
Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{

Слайд 40Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{
Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{

Слайд 41Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{
Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{

Слайд 42Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{
Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{

Слайд 43Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{
Map-Reduce (C++)
#include
#include
#include
#include
#include
using namespace std;
int fib (int n)
{

Слайд 44Map-Reduce (T++)
#include
#include
#include
#include
#include
using namespace std;
tfun int fib (int
Map-Reduce (T++)
#include
#include
#include
#include
#include
using namespace std;
tfun int fib (int

Слайд 45Map-Reduce (T++): “Laziness”
Map-Reduce (T++): “Laziness”
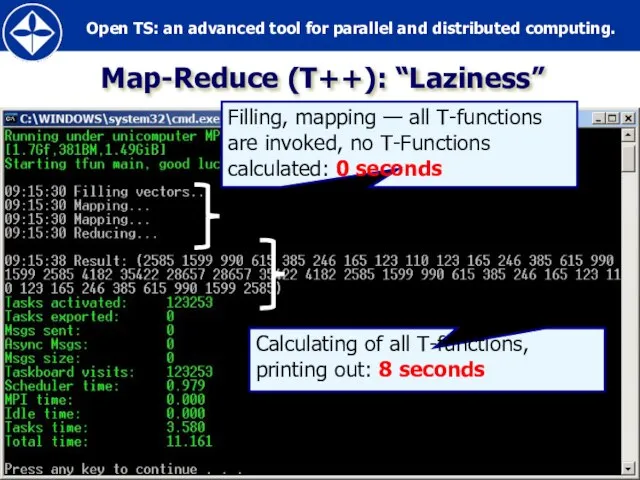
Слайд 46Map-Reduce (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core Processor 4400+
Map-Reduce (T++)
WinCCS cluster,
4 nodes
CPU: AMD Athlon 64 X2 Dual Core Processor 4400+
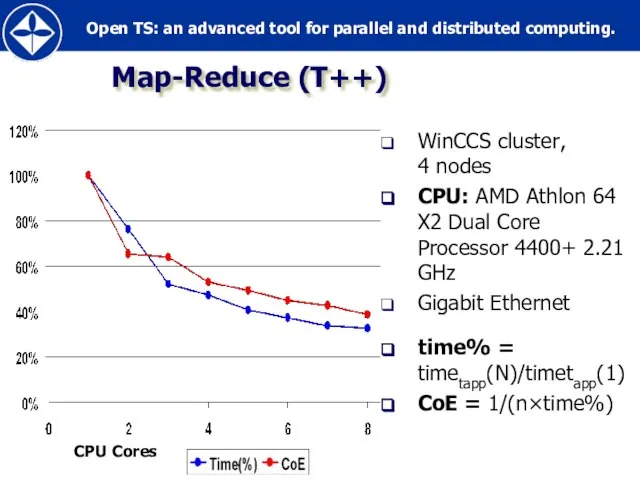
Слайд 47Inside OpenTS
Inside OpenTS

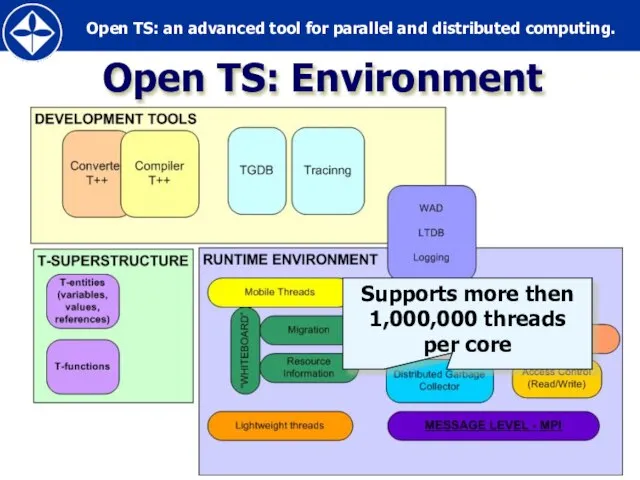
Слайд 48Open TS: Environment
Supports more then 1,000,000 threads per core
Open TS: Environment
Supports more then 1,000,000 threads per core
Слайд 49Supermemory
Utilization: non-ready values, resource and status information, etc.
Object-Oriented Distributed shared memory (OO
Supermemory
Utilization: non-ready values, resource and status information, etc.
Object-Oriented Distributed shared memory (OO

Слайд 50Multithreading & Communications
Lightweight threads
PIXELS (1 000 000 threads)
Asynchronous communications
A thread “A”
Multithreading & Communications
Lightweight threads
PIXELS (1 000 000 threads)
Asynchronous communications
A thread “A”

Слайд 51Open TS applications
(selected)
Open TS applications
(selected)

Слайд 52MultiGen
Chelyabinsk State University
Level 0
Level 1
Level 2
Multi-conformation model
К0
К11
К12
К21
К22
MultiGen
Chelyabinsk State University
Level 0
Level 1
Level 2
Multi-conformation model
К0
К11
К12
К21
К22

Слайд 53MultiGen: Speedup
National Cancer Institute USA
Reg.No. NCI-609067
(AIDS drug lead)
TOSLAB company (Russia-Belgium)
Reg.No. TOSLAB A2-0261
(antiphlogistic
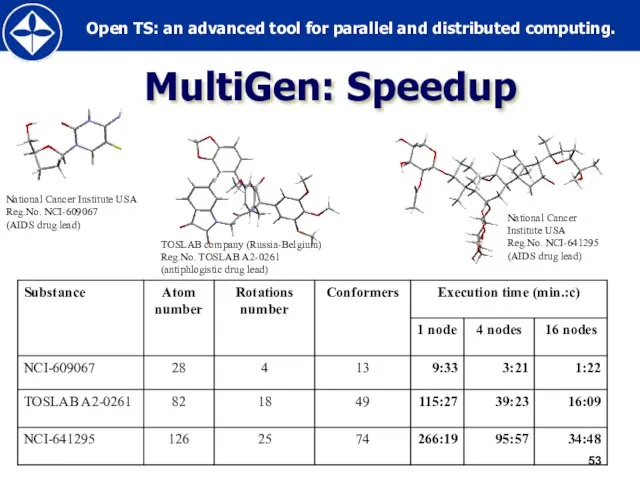
MultiGen: Speedup
National Cancer Institute USA
Reg.No. NCI-609067
(AIDS drug lead)
TOSLAB company (Russia-Belgium)
Reg.No. TOSLAB A2-0261
(antiphlogistic
Слайд 54Aeromechanics
Institute of Mechanics, MSU
Aeromechanics
Institute of Mechanics, MSU

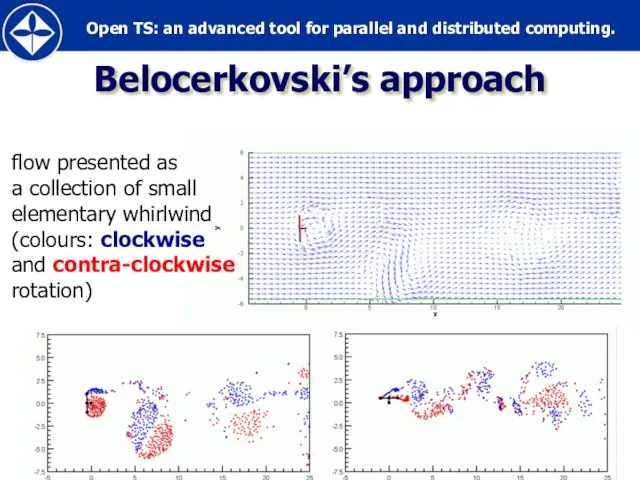
Слайд 55Belocerkovski’s approach
flow presented as
a collection of small
elementary whirlwind
(colours: clockwise
and contra-clockwise
rotation)
Belocerkovski’s approach
flow presented as
a collection of small
elementary whirlwind
(colours: clockwise
and contra-clockwise
rotation)
Слайд 56Creating space-born radar image from hologram
Space Research Institute Development
Creating space-born radar image from hologram
Space Research Institute Development

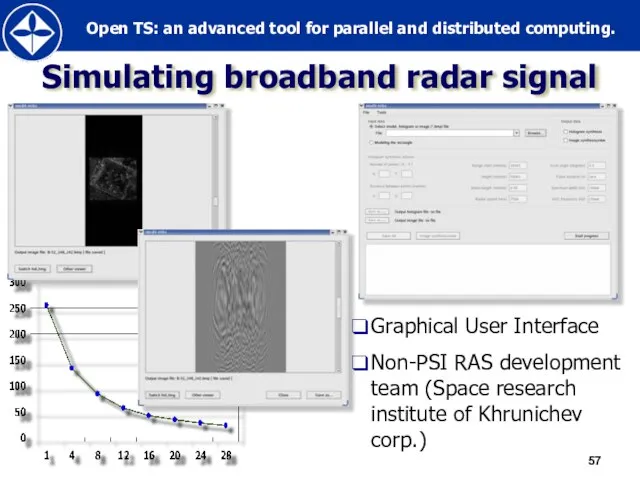
Слайд 57Simulating broadband radar signal
Graphical User Interface
Non-PSI RAS development team (Space research institute
Simulating broadband radar signal
Graphical User Interface
Non-PSI RAS development team (Space research institute
Слайд 58Landsat Image Classification
Computational “web-service”
Landsat Image Classification
Computational “web-service”

Слайд 59Open TS vs. MPI case study
Open TS vs. MPI case study

Слайд 60Applications
Popular and widely used
Developed by independent teams (MPI experts)
PovRay – Persistence
Applications
Popular and widely used
Developed by independent teams (MPI experts)
PovRay – Persistence

Слайд 61T-PovRay vs. MPI PovRay:
code complexity
~7—15 times
T-PovRay vs. MPI PovRay:
code complexity
~7—15 times

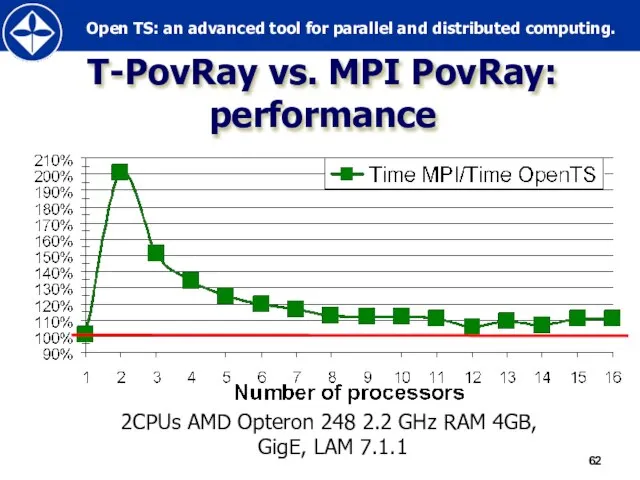
Слайд 62T-PovRay vs. MPI PovRay:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
T-PovRay vs. MPI PovRay:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
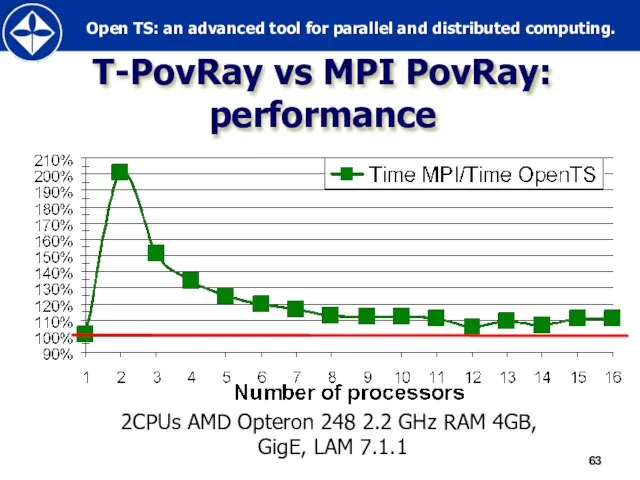
Слайд 63T-PovRay vs MPI PovRay:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
T-PovRay vs MPI PovRay:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
Слайд 64ALCMD/MPI vs ALCMD/OpenTS
MP_Lite component of ALCMD rewritten in T++
Fortran code is
ALCMD/MPI vs ALCMD/OpenTS
MP_Lite component of ALCMD rewritten in T++
Fortran code is

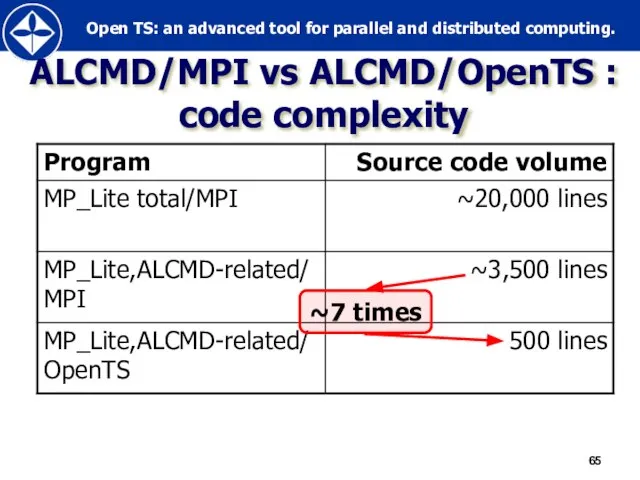
Слайд 65ALCMD/MPI vs ALCMD/OpenTS :
code complexity
~7 times
ALCMD/MPI vs ALCMD/OpenTS :
code complexity
~7 times
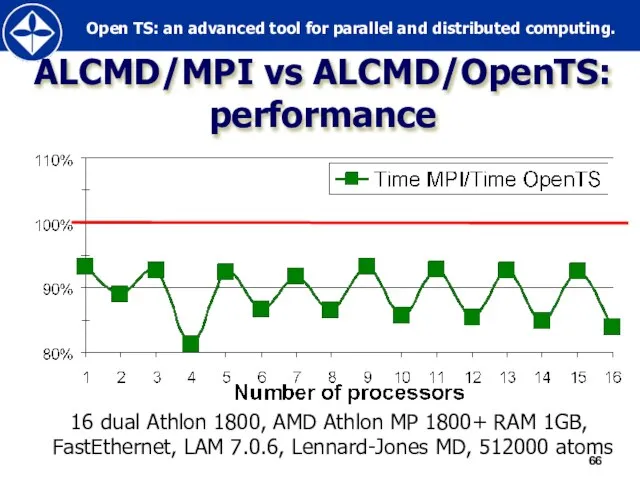
Слайд 66ALCMD/MPI vs ALCMD/OpenTS:
performance
16 dual Athlon 1800, AMD Athlon MP 1800+ RAM
ALCMD/MPI vs ALCMD/OpenTS:
performance
16 dual Athlon 1800, AMD Athlon MP 1800+ RAM
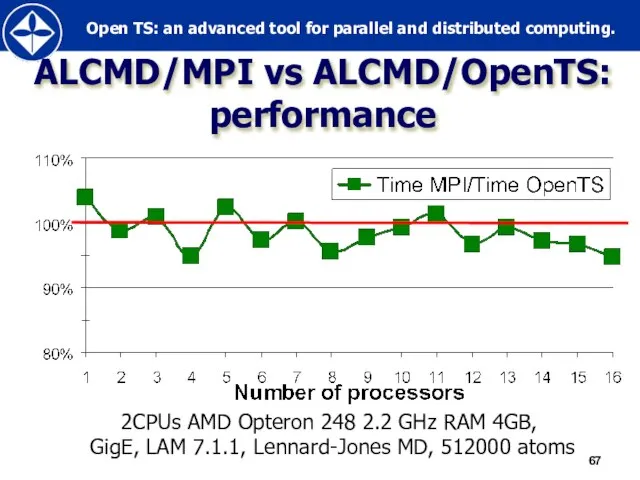
Слайд 67ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
GigE,
ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE,
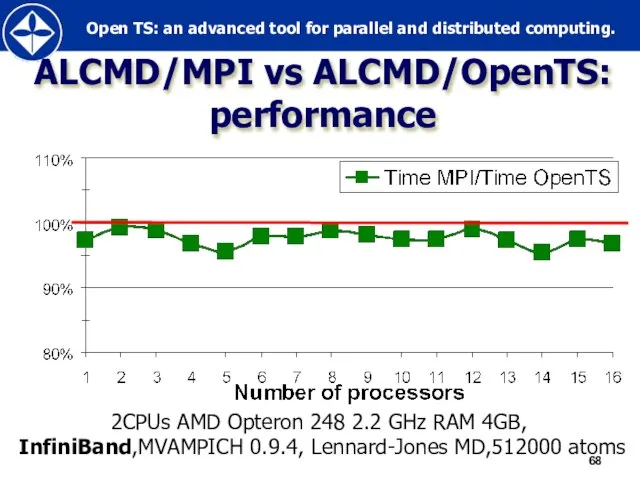
Слайд 68ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
InfiniBand,MVAMPICH
ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, InfiniBand,MVAMPICH
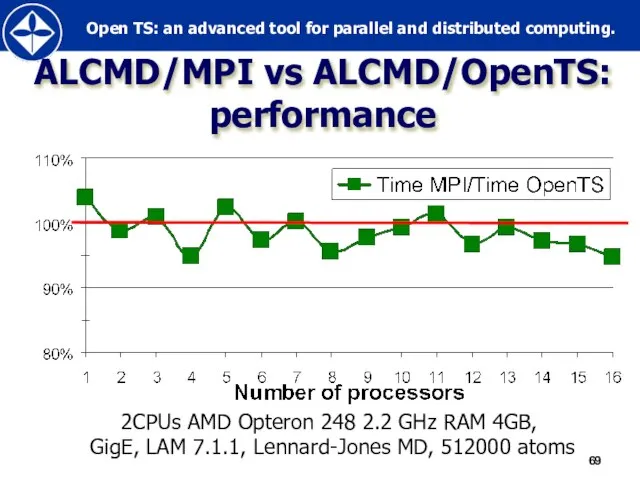
Слайд 69ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
GigE,
ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, GigE,
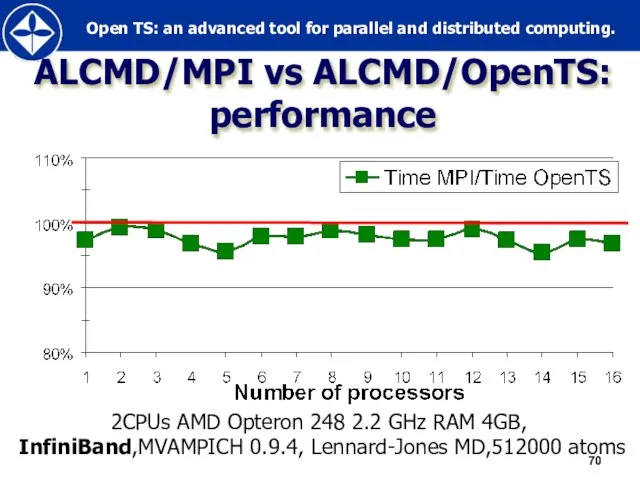
Слайд 70ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB,
InfiniBand,MVAMPICH
ALCMD/MPI vs ALCMD/OpenTS:
performance
2CPUs AMD Opteron 248 2.2 GHz RAM 4GB, InfiniBand,MVAMPICH
Слайд 71Porting OpenTS
to MS Windows CCS
Porting OpenTS
to MS Windows CCS

Слайд 722006: contract with Microsoft “Porting OpenTS to Windows Compute Cluster Server”
OpenTS@WinCCS
inherits all
2006: contract with Microsoft “Porting OpenTS to Windows Compute Cluster Server”
OpenTS@WinCCS
inherits all

Слайд 73OpenTS@WinCCS
AMD64 and x86 platforms are currently supported
Integration into Microsoft Visual Studio 2005
Two
OpenTS@WinCCS
AMD64 and x86 platforms are currently supported
Integration into Microsoft Visual Studio 2005
Two

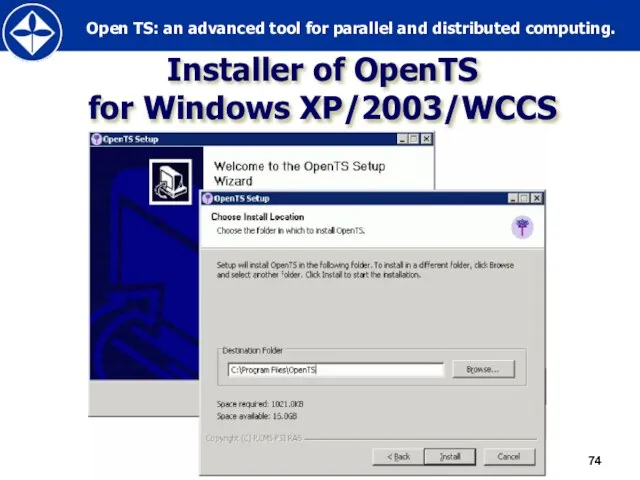
Слайд 74Installer of OpenTS
for Windows XP/2003/WCCS
Installer of OpenTS
for Windows XP/2003/WCCS
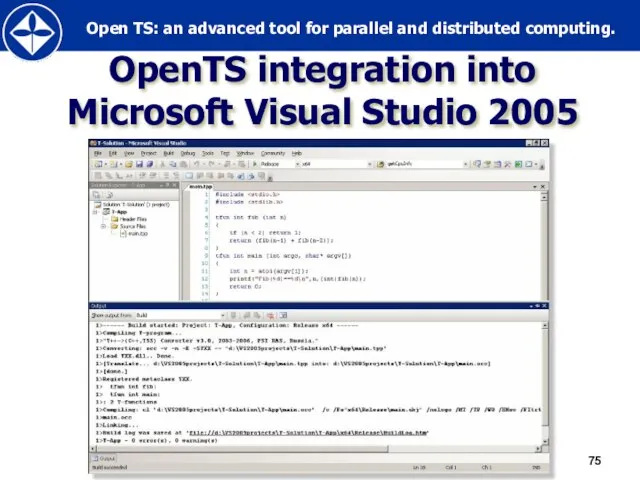
Слайд 75OpenTS integration into Microsoft Visual Studio 2005
OpenTS integration into Microsoft Visual Studio 2005
Слайд 76Open TS “Gadgets”
Open TS “Gadgets”

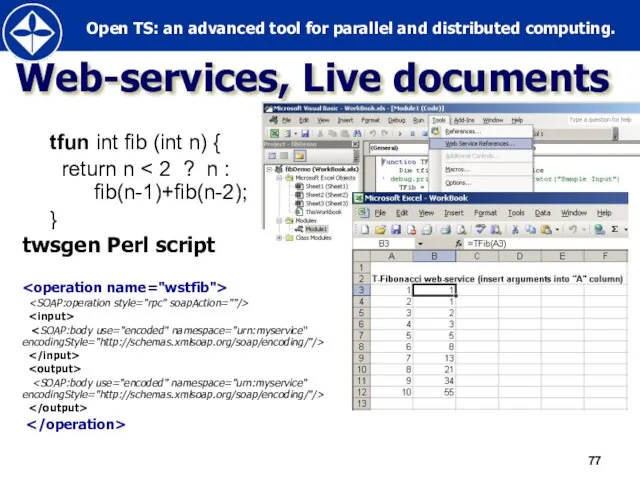
Слайд 77Web-services, Live documents
tfun int fib (int n) {
return n < 2
Web-services, Live documents
tfun int fib (int n) {
return n < 2
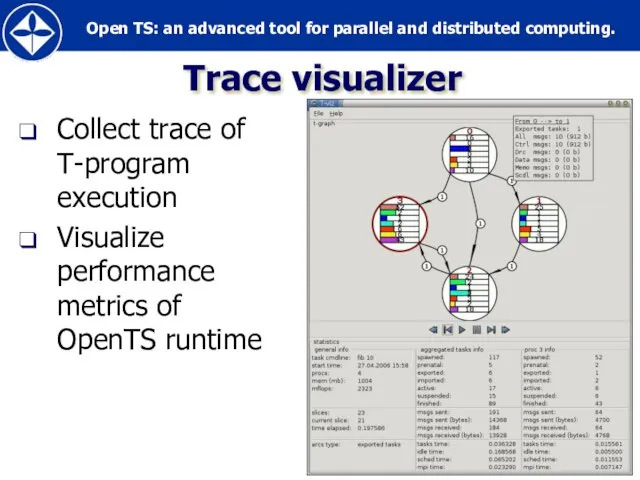
Слайд 78Trace visualizer
Collect trace of T-program execution
Visualize performance metrics of OpenTS runtime
Trace visualizer
Collect trace of T-program execution
Visualize performance metrics of OpenTS runtime
Слайд 79Fault-tolerance
Recalculation based fault-tolerance
(+) Very simple (in comparison with full transactional model)
(+) Efficient (only minimal
Fault-tolerance
Recalculation based fault-tolerance
(+) Very simple (in comparison with full transactional model)
(+) Efficient (only minimal

Слайд 80Some other Gadgets
Other T-languages: T-Refal, T-Fortan
Memoization
Automatically choosing between call-style and fork-style of
Some other Gadgets
Other T-languages: T-Refal, T-Fortan
Memoization
Automatically choosing between call-style and fork-style of

Слайд 81Full / Empty Bit (FEB) и
Т-Система
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Full / Empty Bit (FEB) и
Т-Система
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 82FEB
Модель вычисления:
«общая память»
легковесные нити
FEB — бит синхронизации на каждое слово
Тонкости: фьючеры
Аппаратная реализация:
FEB
Модель вычисления:
«общая память»
легковесные нити
FEB — бит синхронизации на каждое слово
Тонкости: фьючеры
Аппаратная реализация:

Слайд 83Монотонные объекты, как безопасное расширение функциональной модели
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Монотонные объекты, как безопасное расширение функциональной модели
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 84Идеи расширения
Монотонные объекты — обладают свойством Черча-Россера
Типичная жизнь монотонного объекта:
Создание и инициализация
Идеи расширения
Монотонные объекты — обладают свойством Черча-Россера
Типичная жизнь монотонного объекта:
Создание и инициализация

Слайд 85Библиотеки односторонних обменов — SHMEM, Gasnet, ARMCI
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Библиотеки односторонних обменов — SHMEM, Gasnet, ARMCI
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

Слайд 86Основные черты технологии SHMEM
«Чужие» данные не обрабатываются на месте, а копируются предварительно
Основные черты технологии SHMEM
«Чужие» данные не обрабатываются на месте, а копируются предварительно

Слайд 87Технология SHMEM
Рассчитана на полностью однородные многопроцессорные вычислители (общность системы команд, машинного представления
Технология SHMEM
Рассчитана на полностью однородные многопроцессорные вычислители (общность системы команд, машинного представления

Слайд 88SHMEM: Односторонние обмены
put --- односторонняя запись в чужую память
get --- одностороннее чтение
SHMEM: Односторонние обмены
put --- односторонняя запись в чужую память
get --- одностороннее чтение

Слайд 89SHMEM: Операции синхронизации
Возможность выполнить барьерную синхронизацию всех или лишь указанных процессов.
При выполнении
SHMEM: Операции синхронизации
Возможность выполнить барьерную синхронизацию всех или лишь указанных процессов.
При выполнении

Слайд 90Ожидание переменной
shmem_wait( &var, value ) — на «==»
ожидание &var == value
shmem_int_wait_until( &var,
Ожидание переменной
shmem_wait( &var, value ) — на «==»
ожидание &var == value
shmem_int_wait_until( &var,

Слайд 91Модели PGAS (Partitioned Global Address Space),
DSM (Distributed Shared Memory),
языки Co-Array Fortran, UPC…
*
СКИФ-ГРИД ©
Модели PGAS (Partitioned Global Address Space),
DSM (Distributed Shared Memory),
языки Co-Array Fortran, UPC…
*
СКИФ-ГРИД ©

Слайд 92Модель памяти
Разделяемая (shared) память
Любой процесс может использовать ее или указывать на нее
Приватная
Модель памяти
Разделяемая (shared) память
Любой процесс может использовать ее или указывать на нее
Приватная

Слайд 93Что такое UPC
Unified Parallel C
Расширение ANSI C примитивами задания явного параллелизма
Основан на
Что такое UPC
Unified Parallel C
Расширение ANSI C примитивами задания явного параллелизма
Основан на

Слайд 94Модель исполнения
Несколько процессов (нитей 0..THREADS-1) работают независимо
MYTHREAD определяет номер процесса
THREADS — число
Модель исполнения
Несколько процессов (нитей 0..THREADS-1) работают независимо
MYTHREAD определяет номер процесса
THREADS — число

Слайд 95Пример 1
//vect_add.c
#include
#define N 100*THREADS
shared int a[N], b[N], c[N];
void main(){
int i;
for(i=0; i![Пример 1 //vect_add.c #include #define N 100*THREADS shared int a[N], b[N], c[N];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/389499/slide-94.jpg)
Пример 1
//vect_add.c
#include
#define N 100*THREADS
shared int a[N], b[N], c[N];
void main(){
int i;
for(i=0; i
Слайд 96Вместо заключения
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд
Вместо заключения
*
СКИФ-ГРИД © 2009 Все права защищены
Слайд

 Гестационнный сахарный диабет
Гестационнный сахарный диабет Будова Атома
Будова Атома  Презентация на тему Алтай
Презентация на тему Алтай Понятие и формы реализации права
Понятие и формы реализации права Самоуправление
Самоуправление Наш Пушкин
Наш Пушкин Обзор программ CCNA v.4.0
Обзор программ CCNA v.4.0 Переборные алгоритмы
Переборные алгоритмы Конструирование из строительного материала в младшей группе
Конструирование из строительного материала в младшей группе  Фонари
Фонари Омонимы и омографы
Омонимы и омографы Соломинки. Делаем своими руками
Соломинки. Делаем своими руками Инструкция по оформлению витрин ППО рекламной продукцией A1
Инструкция по оформлению витрин ППО рекламной продукцией A1 Выбирай банк смолоду
Выбирай банк смолоду Расчет электрических цепей
Расчет электрических цепей РОЗНИЧНАЯ ТОРГОВЛЯ
РОЗНИЧНАЯ ТОРГОВЛЯ мужчины и женщины - такие похожие и такие разные?
мужчины и женщины - такие похожие и такие разные? Игрушки и сувениры из Сергиева Посада и англоязычных стран
Игрушки и сувениры из Сергиева Посада и англоязычных стран Потому что знает:выйти из нее можно только одним способом.И нормальному человеку он не годится.
Потому что знает:выйти из нее можно только одним способом.И нормальному человеку он не годится. Выдающиеся деятели культуры. Генри Мур (1898-1986)
Выдающиеся деятели культуры. Генри Мур (1898-1986) И.Бунин Современная политическая ситуация в России: основные проблемы
И.Бунин Современная политическая ситуация в России: основные проблемы Видеопрезентация рисунков учеников 2а класса
Видеопрезентация рисунков учеников 2а класса Субъекты и участники обязательного медицинского страхования: понятие и различие правового статуса
Субъекты и участники обязательного медицинского страхования: понятие и различие правового статуса ЧТО ИЗУЧАЮТ СИНТАКСИС И ПУНКТУАЦИЯ
ЧТО ИЗУЧАЮТ СИНТАКСИС И ПУНКТУАЦИЯ Интерференция света
Интерференция света  Единый государственный экзамен: проблемы содержания и организации
Единый государственный экзамен: проблемы содержания и организации Теория организации. Классические виды организационных структур. (Тема 2)
Теория организации. Классические виды организационных структур. (Тема 2) КООРДИНАЦИЯ МЕЖДУНАРОДНОГО СОТРУДНИЧЕСТВА МЕЖДУ РОССИЙСКОЙ ТП И ЕВРОПЕЙСКИМИ СТИ В ОБЛАСТИ АЭРОНАВТИКИ
КООРДИНАЦИЯ МЕЖДУНАРОДНОГО СОТРУДНИЧЕСТВА МЕЖДУ РОССИЙСКОЙ ТП И ЕВРОПЕЙСКИМИ СТИ В ОБЛАСТИ АЭРОНАВТИКИ