- Хорошевский В.Ф.(ВЦ РАН, Москва)

Содержание
- 2. План презентации Введение Цели и задачи работы Краткий обзор существующего положения Проекты извлечения информации из текстов
- 3. Введение Автоматическая обработка текстов на естественном языке (ЕЯ) - одно из приоритетных направлений в области новых
- 4. Введение Проект OntosMiner реализуется швейцарской фирмой Ontos AG и российской IT-фирмой АвиКомп Мотивация разработки: Создание многоплатформенного
- 5. Введение Проект OntosMiner Текущее состояние проекта: Разработан инструментарий для создания систем типа IE на базе среды
- 6. Введение Проект OntosMiner
- 7. Введение Проект OntosMiner
- 8. Цели и задачи настоящей работы Обсуждение метрик для оценки качества функционирования систем извлечения информации из текстов
- 9. Краткий обзор существующего положения Новые технологии и продукты (Прогноз Gartner Group 2005) Интеллектуальный анализ текстов Корпоративный
- 10. Проекты извлечения информации из текстов США Проект TIPSTER (1991 – 1998) Конференции TREC, MUC Программа TIDES
- 11. Проекты извлечения информации из текстов Проект TIPSTER – новые технологии обработки текстов (1991 – 1998). Управление
- 12. Проекты извлечения информации из текстов Программа TIDES (Translingual Information Detection, Extraction, and Summarization) – новая программа
- 13. Проекты извлечения информации из текстов Европа: Форум CLEF
- 14. Проекты извлечения информации из текстов Япония: Форум NTCIR
- 15. Проекты извлечения информации из текстов Россия: Инициатива РОМИП
- 16. Существующие метрики оценки систем типа IE Начало работам по метрикам оценки систем извлечения информации из текстов
- 17. Основные требования: Значения метрик должны быть максимальными для «хороших» систем и минимальными для «плохих», а их
- 18. Достоинства: Отвечают основному критерию, указанному выше и эффективно вычислимы, а также понятны эксперту. Недостатки: Не всегда
- 19. Предлагаемые метрики оценки систем типа IE Основные требования к системе метрик: Монотонность всех метрик и системы
- 20. Предлагаемые метрики оценки систем типа IE Параметры новой системы метрик Для существующих метрик оценки качества систем
- 21. Метрики оценки качества обработки объектов Оценка точности выделения объектов Правильно идентифицированным будем называть такой объект, который,
- 22. Метрики оценки качества обработки объектов Оценка точности выделения объектов Тогда, по аналогии, полностью неправильно идентифицированный объект
- 23. Метрики оценки качества обработки объектов Оценка точности выделения объектов Иначе обстоит дело с частично правильно идентифицированными
- 24. Метрики оценки качества обработки объектов Оценка точности выделения объектов где α(X) , ε(X) и δ(X) –
- 25. Метрики оценки качества обработки объектов Оценка точности выделения объектов С учетом введенных выше понятий
- 26. Метрики оценки качества обработки отношений Общие замечания Оценки точности выделения отношений, в отличие от объектов, в
- 27. Метрики оценки качества обработки отношений Оценка точности выделения отношений Правильно идентифицированным будем называть такое отношение, которое,
- 28. Метрики оценки качества обработки отношений Оценка точности выделения отношений Тогда полностью неправильно идентифицированное отношение можно фиксировать
- 29. Метрики оценки качества обработки отношений Оценка точности выделения отношений Для частично правильно идентифицированных отношений, как и
- 30. Метрики оценки качества обработки отношений Оценка точности выделения отношений – коэффициенты качества обработки всего отношения, его
- 31. Метрики оценки качества обработки отношений Оценка точности выделения отношений С учетом введенных выше понятий
- 32. Метрики оценки качества обработки объектов/отношений Оценка полноты выделения объектов/отношений В оценках полноты в классическом варианте участвуют
- 33. Интегральные оценки качества систем типа IE В предлагаемой системе метрик для точности и полноты введены по
- 34. Тестирование новой системы метрик Для тестирования новой системы метрик была проведена оценка качества процессора OntosMiner/Russian. Для
- 35. Тестирование новой системы метрик Для оценки результатов было решено использовать объекты типа Person, JobTitle/Title, Organization и
- 36. Тестирование новой системы метрик Классические оценки
- 37. Тестирование новой системы метрик Предлагаемые оценки (объекты)
- 38. Тестирование новой системы метрик Предлагаемые оценки (отношения)
- 39. Полученные результаты и дальнейшие исследования Анализ полученных результатов: Новые метрики более «чувствительны» к ошибкам в определении
- 41. Скачать презентацию
Слайд 2План презентации
Введение
Цели и задачи работы
Краткий обзор существующего положения
Проекты извлечения информации из текстов
Существующие
План презентации
Введение
Цели и задачи работы
Краткий обзор существующего положения
Проекты извлечения информации из текстов
Существующие

Слайд 3Введение
Автоматическая обработка текстов на естественном языке (ЕЯ) - одно из приоритетных направлений
Введение
Автоматическая обработка текстов на естественном языке (ЕЯ) - одно из приоритетных направлений

Слайд 4Введение
Проект OntosMiner
реализуется
швейцарской фирмой Ontos AG и российской IT-фирмой АвиКомп
Мотивация разработки:
Создание многоплатформенного
Введение
Проект OntosMiner
реализуется
швейцарской фирмой Ontos AG и российской IT-фирмой АвиКомп
Мотивация разработки:
Создание многоплатформенного

Слайд 5Введение
Проект OntosMiner
Текущее состояние проекта:
Разработан инструментарий для создания систем типа IE на базе
Введение
Проект OntosMiner
Текущее состояние проекта:
Разработан инструментарий для создания систем типа IE на базе

Слайд 6Введение
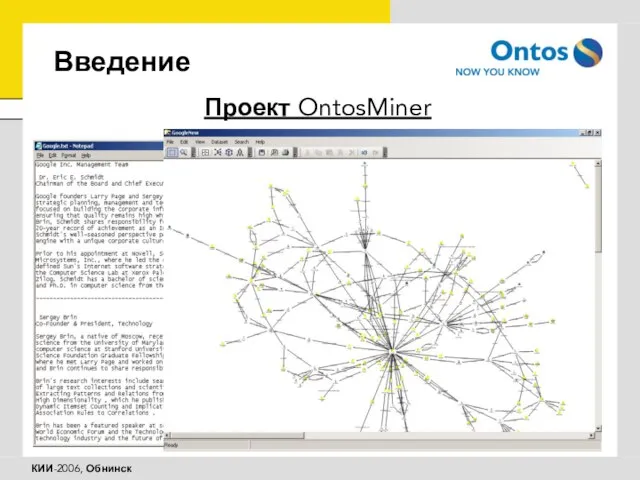
Проект OntosMiner
Введение
Проект OntosMiner
Слайд 7Введение
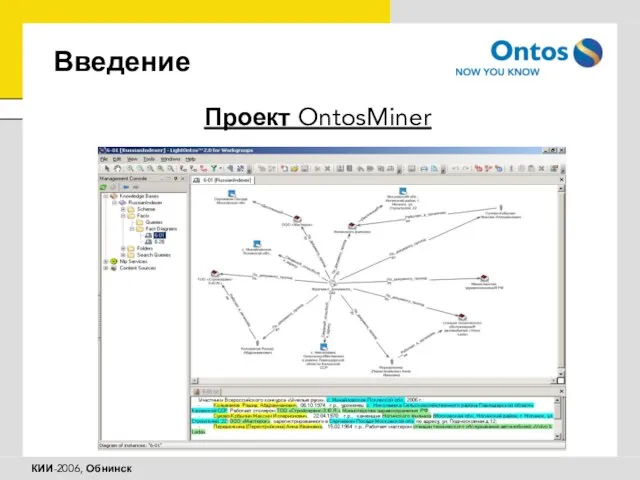
Проект OntosMiner
Введение
Проект OntosMiner
Слайд 8Цели и задачи настоящей работы
Обсуждение метрик для оценки качества функционирования систем извлечения
Цели и задачи настоящей работы
Обсуждение метрик для оценки качества функционирования систем извлечения

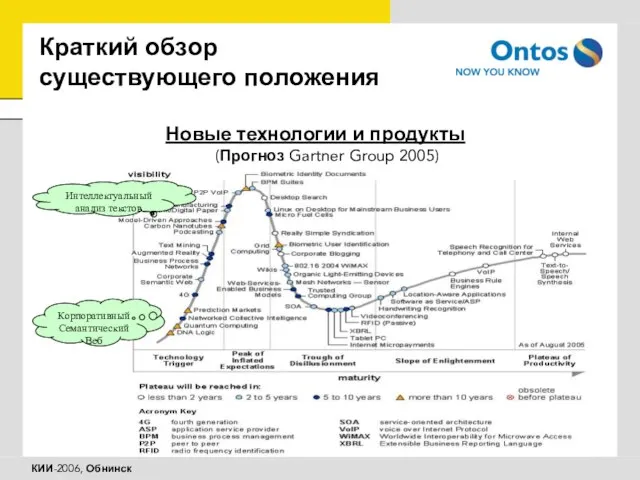
Слайд 9Краткий обзор существующего положения
Новые технологии и продукты
(Прогноз Gartner Group 2005)
Интеллектуальный анализ
Краткий обзор существующего положения
Новые технологии и продукты
(Прогноз Gartner Group 2005)
Интеллектуальный анализ
Слайд 10Проекты извлечения информации из текстов
США
Проект TIPSTER (1991 – 1998)
Конференции TREC, MUC
Программа TIDES
Проекты извлечения информации из текстов
США
Проект TIPSTER (1991 – 1998)
Конференции TREC, MUC
Программа TIDES

Слайд 11Проекты извлечения информации из текстов
Проект TIPSTER – новые технологии обработки текстов (1991
Проекты извлечения информации из текстов
Проект TIPSTER – новые технологии обработки текстов (1991

Слайд 12Проекты извлечения информации из текстов
Программа TIDES (Translingual Information Detection, Extraction, and Summarization)
Проекты извлечения информации из текстов
Программа TIDES (Translingual Information Detection, Extraction, and Summarization)

Слайд 13Проекты извлечения информации из текстов
Европа: Форум CLEF
Проекты извлечения информации из текстов
Европа: Форум CLEF
Слайд 14Проекты извлечения информации из текстов
Япония: Форум NTCIR
Проекты извлечения информации из текстов
Япония: Форум NTCIR
Слайд 15Проекты извлечения информации из текстов
Россия: Инициатива РОМИП
Проекты извлечения информации из текстов
Россия: Инициатива РОМИП
Слайд 16Существующие метрики оценки
систем типа IE
Начало работам по метрикам оценки систем извлечения
Существующие метрики оценки
систем типа IE
Начало работам по метрикам оценки систем извлечения

Слайд 17Основные требования:
Значения метрик должны быть максимальными для «хороших» систем и минимальными для
Основные требования:
Значения метрик должны быть максимальными для «хороших» систем и минимальными для

Слайд 18Достоинства:
Отвечают основному критерию, указанному выше и эффективно вычислимы, а также понятны эксперту.
Недостатки:
Не
Достоинства:
Отвечают основному критерию, указанному выше и эффективно вычислимы, а также понятны эксперту.
Недостатки:
Не

Слайд 19Предлагаемые метрики оценки систем типа IE
Основные требования к системе метрик:
Монотонность всех метрик
Предлагаемые метрики оценки систем типа IE
Основные требования к системе метрик:
Монотонность всех метрик

Слайд 20Предлагаемые метрики оценки систем типа IE
Параметры новой системы метрик
Для существующих метрик оценки
Предлагаемые метрики оценки систем типа IE
Параметры новой системы метрик
Для существующих метрик оценки

Слайд 21Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Правильно идентифицированным будем называть такой
Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Правильно идентифицированным будем называть такой

Слайд 22Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Тогда, по аналогии, полностью неправильно
Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Тогда, по аналогии, полностью неправильно

Слайд 23Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Иначе обстоит дело с частично
Метрики оценки качества обработки объектов
Оценка точности выделения объектов
Иначе обстоит дело с частично

Слайд 24Метрики оценки качества обработки объектов
Оценка точности выделения объектов
где
α(X) , ε(X) и δ(X)
Метрики оценки качества обработки объектов
Оценка точности выделения объектов
где
α(X) , ε(X) и δ(X)

Слайд 25Метрики оценки качества обработки объектов
Оценка точности выделения объектов
С учетом введенных выше понятий
Метрики оценки качества обработки объектов
Оценка точности выделения объектов
С учетом введенных выше понятий

Слайд 26Метрики оценки качества обработки отношений
Общие замечания
Оценки точности выделения отношений, в отличие от
Метрики оценки качества обработки отношений
Общие замечания
Оценки точности выделения отношений, в отличие от

Слайд 27Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Правильно идентифицированным будем называть такое
Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Правильно идентифицированным будем называть такое

Слайд 28Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Тогда полностью неправильно идентифицированное отношение
Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Тогда полностью неправильно идентифицированное отношение

Слайд 29Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Для частично правильно идентифицированных отношений,
Метрики оценки качества обработки отношений
Оценка точности выделения отношений
Для частично правильно идентифицированных отношений,

Слайд 30Метрики оценки качества обработки отношений
Оценка точности выделения отношений
– коэффициенты качества обработки всего
Метрики оценки качества обработки отношений
Оценка точности выделения отношений
– коэффициенты качества обработки всего

Слайд 31Метрики оценки качества обработки отношений
Оценка точности выделения отношений
С учетом введенных выше понятий
Метрики оценки качества обработки отношений
Оценка точности выделения отношений
С учетом введенных выше понятий

Слайд 32Метрики оценки качества обработки объектов/отношений
Оценка полноты выделения объектов/отношений
В оценках полноты в классическом
Метрики оценки качества обработки объектов/отношений
Оценка полноты выделения объектов/отношений
В оценках полноты в классическом

Слайд 33Интегральные оценки качества систем типа IE
В предлагаемой системе метрик для точности и
Интегральные оценки качества систем типа IE
В предлагаемой системе метрик для точности и

Слайд 34Тестирование новой системы метрик
Для тестирования новой системы метрик была проведена оценка качества
Тестирование новой системы метрик
Для тестирования новой системы метрик была проведена оценка качества

Слайд 35Тестирование новой системы метрик
Для оценки результатов было решено использовать объекты типа Person,
Тестирование новой системы метрик
Для оценки результатов было решено использовать объекты типа Person,

Слайд 36Тестирование новой системы метрик
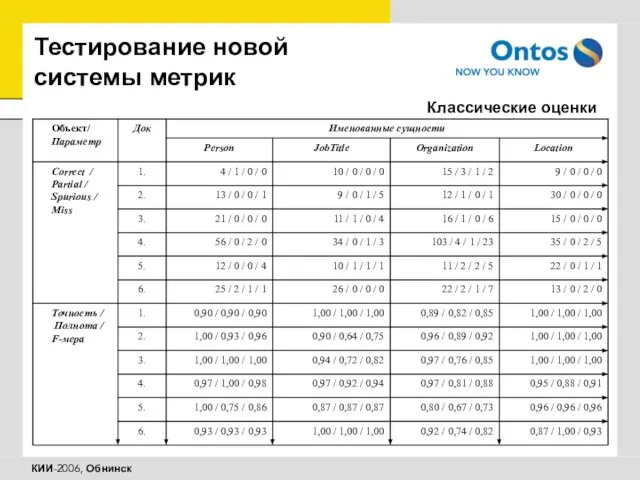
Классические оценки
Тестирование новой системы метрик
Классические оценки
Слайд 37Тестирование новой системы метрик
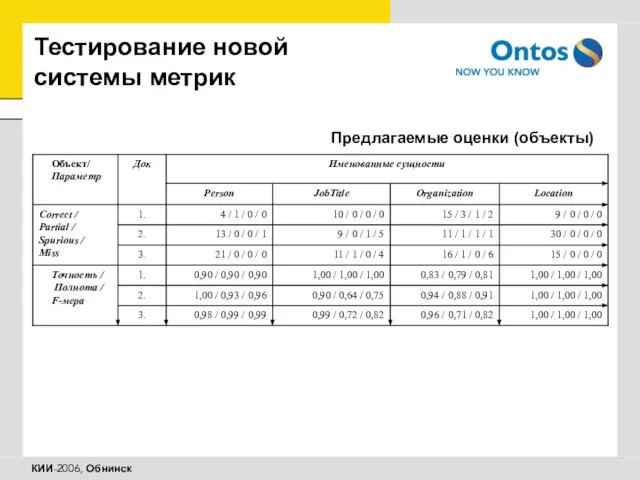
Предлагаемые оценки (объекты)
Тестирование новой системы метрик
Предлагаемые оценки (объекты)
Слайд 38Тестирование новой системы метрик
Предлагаемые оценки (отношения)
Тестирование новой системы метрик
Предлагаемые оценки (отношения)
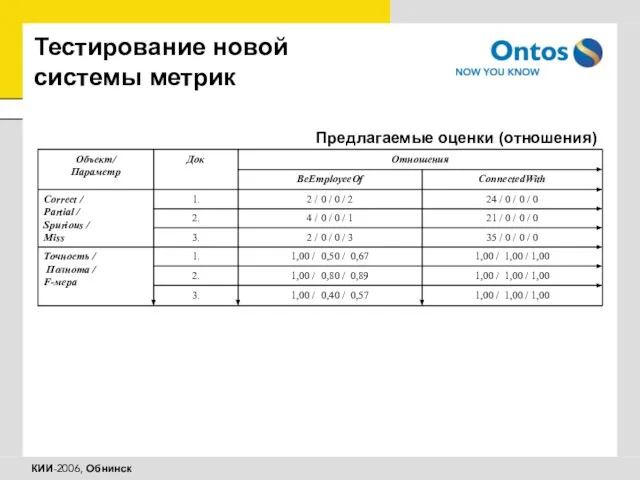
Слайд 39Полученные результаты и дальнейшие исследования
Анализ полученных результатов:
Новые метрики более «чувствительны» к
Полученные результаты и дальнейшие исследования
Анализ полученных результатов:
Новые метрики более «чувствительны» к

 Отношение к курению учащихся лицея
Отношение к курению учащихся лицея Формирование индивидуального стиля деятельности с учетом особенностей темперамента
Формирование индивидуального стиля деятельности с учетом особенностей темперамента О комплексе мер по профилактике травматизма обучающихся и воспитанников. Порядок расследования несчастных случаев с обучающимис
О комплексе мер по профилактике травматизма обучающихся и воспитанников. Порядок расследования несчастных случаев с обучающимис УПРАВЛЕНЧЕСКИЙКОНСАЛТИНГ
УПРАВЛЕНЧЕСКИЙКОНСАЛТИНГ Гармония пространства
Гармония пространства Что же такое «гражданский брак»?Почему дети нашего времени в своем большинстве появляются на свет «незаконнорожденными»?
Что же такое «гражданский брак»?Почему дети нашего времени в своем большинстве появляются на свет «незаконнорожденными»? Украшение и фантазия
Украшение и фантазия The Theory of Factor Proportions
The Theory of Factor Proportions Построение образовательного пространства обучения на системно-деятельностном подходе
Построение образовательного пространства обучения на системно-деятельностном подходе Рыбацкие ложки
Рыбацкие ложки PowerPoint Show by Andrew
PowerPoint Show by Andrew Организация проектной деятельности
Организация проектной деятельности Действительные и страдательные причастия 7 класс
Действительные и страдательные причастия 7 класс Беляковой от подружек
Беляковой от подружек Беспроводная передача электричества
Беспроводная передача электричества О заболеваниях мочеполовой системы не принято говорить вслух, но бросать эти недуги на самотек опасно для здоровья, поэтому в данн
О заболеваниях мочеполовой системы не принято говорить вслух, но бросать эти недуги на самотек опасно для здоровья, поэтому в данн Презентация на тему We like the place we live
Презентация на тему We like the place we live Уильям Шекспир
Уильям Шекспир Опоры самости
Опоры самости Презентация на тему сентиментализм
Презентация на тему сентиментализм  С чего начинается Родина. Праздничный концерт в Пычановском досуговом центре
С чего начинается Родина. Праздничный концерт в Пычановском досуговом центре Сергей Александрович Есенин
Сергей Александрович Есенин  Использование аппликативной техники при выполнении дизайн - проекта
Использование аппликативной техники при выполнении дизайн - проекта С мамой в спорте
С мамой в спорте Кто придумал первую ракету?
Кто придумал первую ракету? Развивайся!
Развивайся! Гончаров Александр Андреевич 11.09.1925 года рождения Ветеран великой Отечественной войны.
Гончаров Александр Андреевич 11.09.1925 года рождения Ветеран великой Отечественной войны. Алгоритм решения уравнений
Алгоритм решения уравнений