- Индуктивное моделирование

Содержание
- 2. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 3. Введение История ИМСОМ = Индуктивный Метод Самоорганизации Моделей Был разработан в в 70-80 годы акад. А.Г.
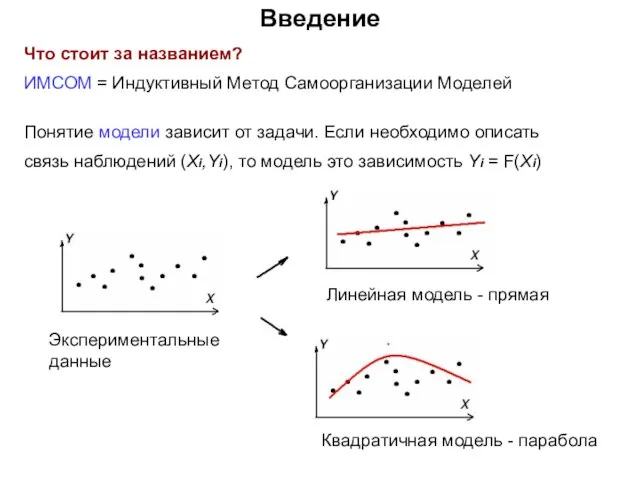
- 4. Введение Что стоит за названием? ИМСОМ = Индуктивный Метод Самоорганизации Моделей Понятие модели зависит от задачи.
- 5. Введение В чем индуктивность? Индукция = из частных случаев делают обобщенный вывод Дедукция = из общего
- 6. Введение В чем самоорганизация? Саморганизация системы – это изменение ее структуры/параметров под влиянием внешних условий Самоорганизация
- 7. Введение Возможности ИМСОМ позволяет выбрать модель оптимальной сложности из заданного класса моделей, чтобы описать ограниченный набор
- 8. Введение Терминология Термин ИМСОМ был почти сразу заменен авторами метода на термин МГУА МГУА = метод
- 9. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 10. Коллеги и соавторы Pavel Makagonov Titled Research Professor Mixteca University of Technology, Mexico Ex Vice-Director of
- 11. Коллеги и соавторы Xavier Blanco Titled Professor of French Philology Department Universidad Autonoma de Barcelona, Spain
- 12. Коллеги и соавторы Alexander Gelbukh Chief of NLP Laboratory Center for Computing Research National Polytechnic Institute,
- 13. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 14. Индуктивное Моделирование Классы и сложность модели ИМСОМ имеет дело с заранее фиксированным классом моделей. Класс моделей
- 15. Индуктивное моделирование Каноническая проблема Описание временного ряда некоторой формулой Пусть начальная информация задана ? Заданная информация
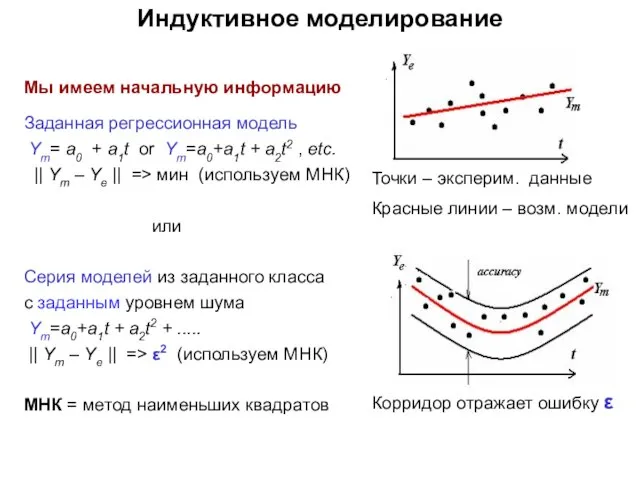
- 16. Индуктивное моделирование Мы имеем начальную информацию Заданная регрессионная модель Ym= a0 + a1t or Ym=a0+a1t +
- 17. Индуктивное моделирование Каноническая проблема Описание временного ряда некоторой формулой Пусть начальная информация отсутствует ? У нас
- 18. Индуктивное моделирование Принцип индуктивности ИМСОМ не может найти самую оптимальную модель среди всех возможных! Он ищет
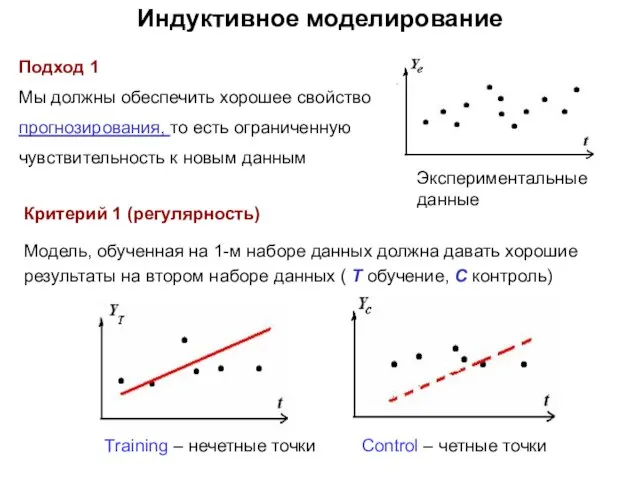
- 19. Индуктивное моделирование Подход 1 Мы должны обеспечить хорошее свойство прогнозирования, то есть ограниченную чувствительность к новым
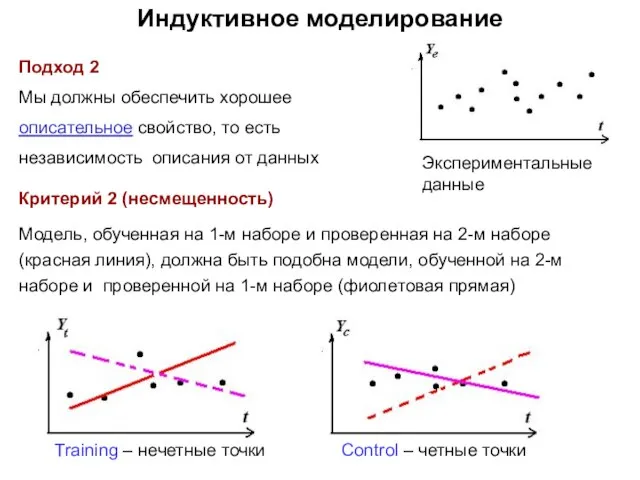
- 20. Индуктивное моделирование Подход 2 Мы должны обеспечить хорошее описательное свойство, то есть независимость описания от данных
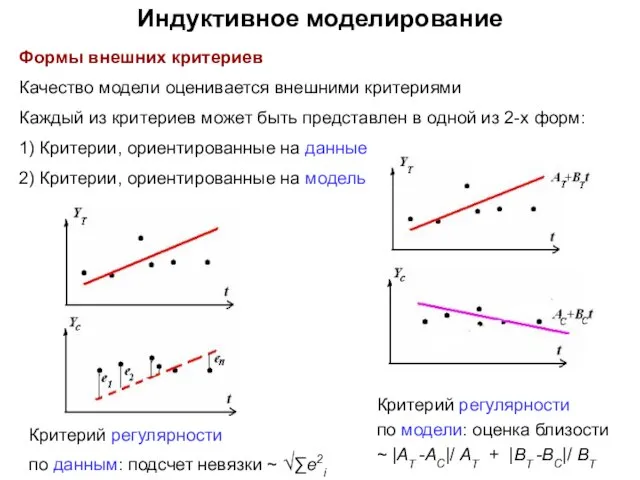
- 21. Индуктивное моделирование Формы внешних критериев Качество модели оценивается внешними критериями Каждый из критериев может быть представлен
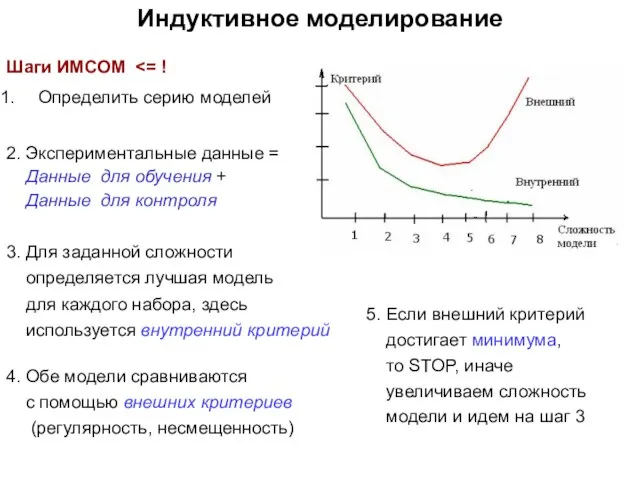
- 22. Индуктивное моделирование Шаги ИМСОМ Определить серию моделей 2. Экспериментальные данные = Данные для обучения + Данные
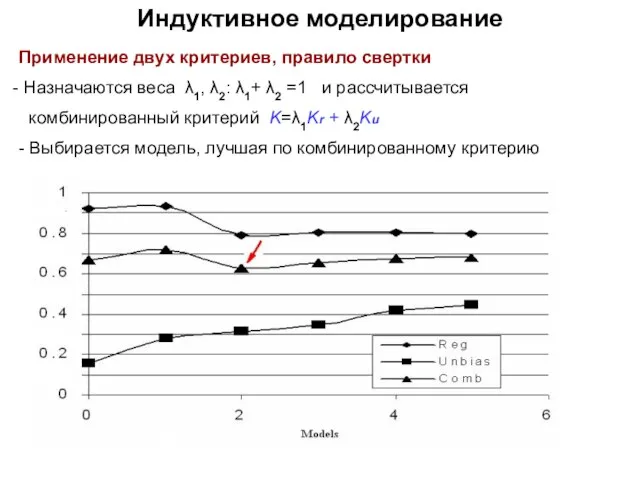
- 23. Индуктивное моделирование Применение двух критериев, правило свертки Назначаются веса λ1, λ2: λ1+ λ2 =1 и рассчитывается
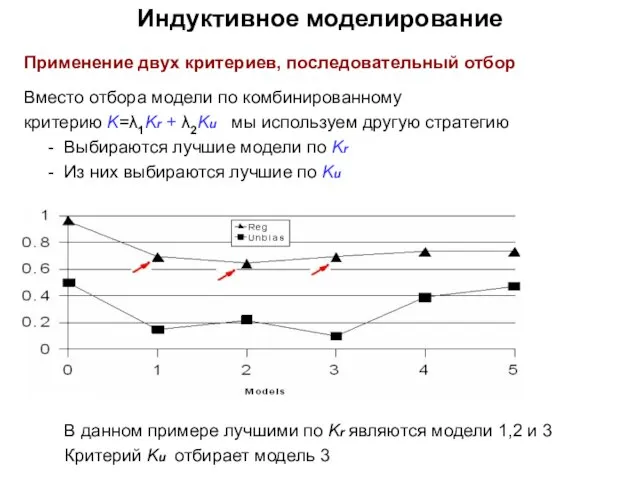
- 24. Индуктивное моделирование Применение двух критериев, последовательный отбор Вместо отбора модели по комбинированному критерию K=λ1Kr + λ2Ku
- 25. Индуктивное моделирование Подавление шума Утверждение Пусть имеем N-данных наблюдений y1, y2, y3, ....yN Пусть имеем k-параметров
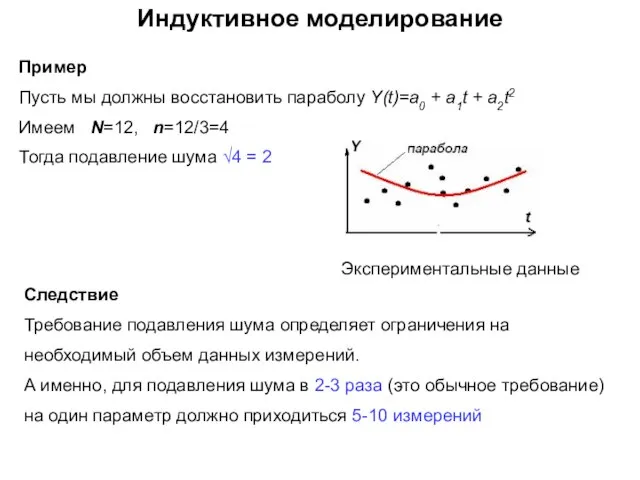
- 26. Индуктивное моделирование Пример Пусть мы должны восстановить параболу Y(t)=a0 + a1t + a2t2 Имеем N=12, n=12/3=4
- 27. Варианты ИМСОМ Имеется два традиционных варианта: 1) Комбинаторный вариант ИСОМ - КОМБИ Перебираются всевозможные модели в
- 28. Индуктивное моделирование Пример применения селекции Пусть имеем 20 точек наблюдений = 10 (обучение) + 10 (контроль)
- 29. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 30. Постановка задачи Предмет рассмотрения Статистический стеммер. Построение эмпирической формулы, обученной на примерах Техника Индуктивное моделирование
- 31. Постановка задачи Стемминг Состоит в выборе части слова, отражающей основное значение слова Примеры sad, sadly, sadness,
- 32. Постановка задачи Проблема Построить формулу для принятия решения о подобии пары слов Актуальность Нам приходится обрабатывать
- 33. Эмпирические формулы Параметры для сравнения пары слов Мы будем обучать формулу на положительных примерах, то есть
- 34. Эмпирические формулы Требования Построенная формула должна отражать два обстоятельства: Поддержать факт, что небольшое относительное число несовпавших
- 35. Эмпирические формулы Модели для принятия решений Какую формулу стоит настраивать под примеры, заданные экспертом? n/s Здесь:
- 36. Эмпирические формулы Число степеней свободы Как было указано выше, формула должна зависеть от: - относительной доли
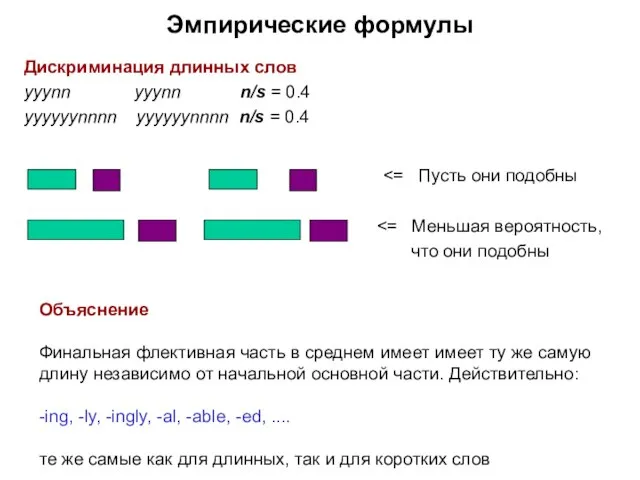
- 37. Дискриминация длинных слов yyynn yyynn n/s = 0.4 yyyyyynnnn yyyyyynnnn n/s = 0.4 что они подобны
- 38. Эмпирические формулы Сложность модели F(y) ? Чтобы определить сложность модели (степень полинома), мы используем ИМСОМ =
- 39. Подход 1) Мы рассматриваем экстремальные случаи (равенство) n/s = a0 + a1y + a2y2 + ...
- 40. ИМСОМ - Реализация Пример n/s = a0 + a1y + a2y2+.... asking asked n = 5
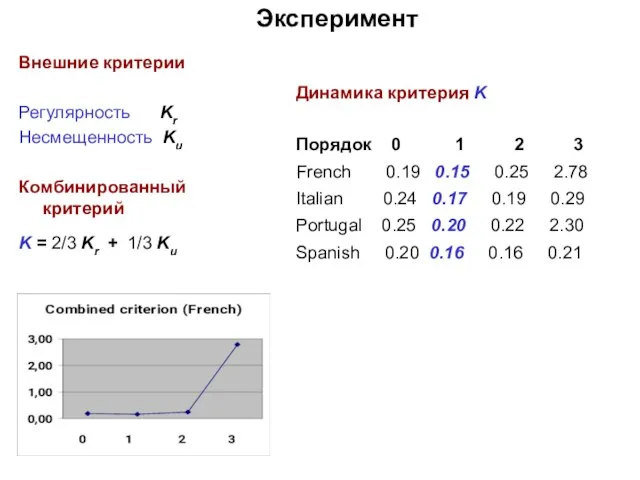
- 41. Внешние критерии Регулярность Kr Несмещенность Ku Комбинированный критерий K = 2/3 Kr + 1/3 Ku Эксперимент
- 42. Результаты Формулы (линейные модели) French n/s ≤ 0.48 – 0.024 y Italian n/s ≤ 0.57 –
- 43. Демонстрация Пример Начальный список 1-й шаг 2-й шаг 3-й шаг transform (7) transform (12) transform (19)
- 44. Дискуссия и выводы Примеры Мартина Портера Д-р Портер, автор знаменитого стеммера, реализованного на многих европейских языках,
- 45. Дискуссия и выводы Недостатки стеммера - Относительно низкая точность (80%-90%) - Зависимость результатов применения от длины
- 46. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 47. Введение Предмет рассмотрения Subjectivity/Sentiment analysis. Построение эмпирических формул для автоматической оценки вежливости, удовлетворенности и компетентности на
- 48. Введение Subjectivity/Sentiment анализ это область обработки естественных языков (NLP), которая направлена на автоматическую оценку эмоций и
- 49. Введение Одно из приложений SSA это обработка диалогов. В настоящее время такая обработка широко используется для
- 50. Исходные данные Данные состояли из 85 диалогов между пассажирами и справочной железнодорожного вокзала Барселоны Язык –
- 51. Пример: Вежливость
- 52. Вежливость, параметризация А. Индиктор первого приветствия (g - greeting) Имеет значение 1, при первом приветствии «Could
- 53. Вежливость, параметризация Для числового представления v и w следует учесть - длину документа информационный аспект появления
- 54. Вежливость, параметризация Ручные оценки учитывают только вежливость (но не грубость) по шкале: 0 - обычная вежливость
- 55. Вежливость, параметризация
- 56. Вежливость, модели Мы предположили, что зависимость между числовыми индикаторами и и уровнем вежливости может быть описана
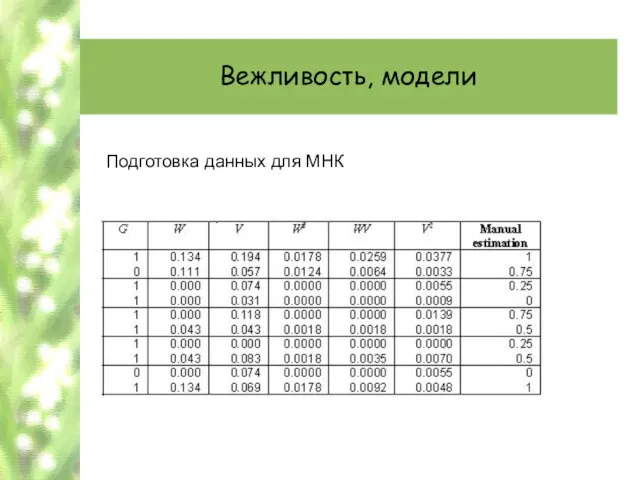
- 57. Вежливость, модели Подготовка данных для МНК
- 58. Вежливость, результаты Наилучшая модель (по двум критериям) F(g,w,v) = 0.18g + 3.29w + 3.43v ε =0.16
- 59. Удовлетворенность, параметризация Серия моделей Model 0: F(b,f,q) = A0 Model 1: F(b,f,q) = B100b + B010f
- 60. Удовлетворенность, результаты Наилучшие модели (по двум критериям) F(b,f,q) = 0.18b + 0.06f - 1.11q ε =
- 61. Компетентность,параметризация Серия моделей Model 0: F(b,f,q) = A0 Model 1: F(b,f,q) = B100l + B010f +
- 62. Компетентность, результаты Наилучшая модель (по двум критериям) F(f,l,q) = 0.52f + 0.19l + 0.16q ε =0.26
- 63. Выводы 1. ИМСОМ обеспечивает методологию для автоматической оценки различных «размытых» характеристик диалога, имеющих высокий уовень субъективности
- 64. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 65. Предмет рассмотрения Терминография. Выявление гранулярности терминов заданной предметной области Техника Идеи индуктивного моделирования
- 66. Под терминами будем понимать ключевые слова предметной области Ключевые слова используются для: A. Суммаризации документов Б.
- 67. Главные термины области Рост специфичности Применения гранулированных терминов: 1. Суммаризация документов по различным уровням детальности 2.
- 68. Определение гранулярности на основе корпуса текстов (corpus-based granularity): Уровни гранулярности это классы терминов, имеющих близкие значения
- 69. Definitions Определение проблемы: Выявление уровней гранулярности эквивалентно проблеме размещения точек перехода на оси специфичности. Проблема гранулярности
- 71. Мы используем ИМСОМ-подобный алгоритм Напомним основные шаги ИМСОМ: 1. Эксперт определяет последовательность моделей от простейшей к
- 72. Первое, мы делим документы на два набора. Оба они равноценны и называем их Набор-1 и Набор-2,
- 73. Шаги алгоритма 1. Фиксируем длину окна специфичности, прикладываем его к началу диапазона специфичности и берем термины
- 74. Главная гипотеза: Если распределения специфичностей внутри некоторого окна специфичности для обоих наборов данных близки, то термины,
- 75. Внешние критерии Давайте зафиксируем одно и тоже окно Δs = [s1,s2] внутри диапазонов специфичности для каждого
- 76. Мы используем корпус, названный hep-ex, изначально принадлежащий CERN -у. Он состоит из абстрактов статей, связанных с
- 77. Поведение критерия K1 (основанный на энтропии) для различной длины окна
- 78. Поведение критерия K1 (основанного на энтропии) для различных разбиений корпуса
- 81. Слова в Таблице упорядочены согласно их специфичности
- 82. 1) Мы постарались формализовать понятие гранулярности для терминологии предметной области. Для этого мы ввели различные меры
- 83. Содержание Введение Коллеги и соавторы Индуктивное моделирование Статистический стеммер Subjectivity/Sentiment analysis Терминография Ресурсы
- 84. Ресурсы - Украина (1) Международный центр информационных технологий и систем, НАН и МОН Украины, отдел информационных
- 85. Ресурсы - Украина Поддержка сообщества ИМ Отдел проф. В.С. Степашко организует: 1) Ежегодные Летние Школы по
- 86. Ресурсы - Украина (2) Компания Geos Research Group, Киев, Украина http:// www.gmdhshell.com Компания разработала промышленную оболочку
- 87. Ресурсы - Украина Пример работы оболочки GMDH-Shell
- 88. Ресурсы - Москва (1) Вычислительный Центр РАН Московский физико-технический институт http:// www.machinelearning.ru Это Wiki подобный ресурс,
- 89. Ресурсы - Москва Часть главной страницы Wiki ресурса http:// www.machinelearning.ru
- 90. Ресурсы - Москва (2) Компания Forecsys, Москва, Россия http:// www.forecsys.ru/site/about/about/ Компания Forecsys — российский вендор BI-решений.
- 91. Ресурсы - Москва Процедуры генерации моделей, реализованные в MVR Модель как произвольная суперпозиция Список порождающих функций
- 93. Скачать презентацию
Слайд 2Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 3Введение
История
ИМСОМ = Индуктивный Метод Самоорганизации Моделей
Был разработан в в 70-80 годы
Введение
История
ИМСОМ = Индуктивный Метод Самоорганизации Моделей
Был разработан в в 70-80 годы

Слайд 4Введение
Что стоит за названием?
ИМСОМ = Индуктивный Метод Самоорганизации Моделей
Понятие модели зависит от
Введение
Что стоит за названием?
ИМСОМ = Индуктивный Метод Самоорганизации Моделей
Понятие модели зависит от
Слайд 5Введение
В чем индуктивность?
Индукция = из частных случаев делают обобщенный вывод
Дедукция =
Введение
В чем индуктивность?
Индукция = из частных случаев делают обобщенный вывод
Дедукция =

Слайд 6Введение
В чем самоорганизация?
Саморганизация системы – это изменение ее структуры/параметров
под влиянием
Введение
В чем самоорганизация?
Саморганизация системы – это изменение ее структуры/параметров
под влиянием

Слайд 7Введение
Возможности
ИМСОМ позволяет выбрать модель оптимальной сложности
из заданного класса моделей, чтобы описать ограниченный
набор
Введение
Возможности
ИМСОМ позволяет выбрать модель оптимальной сложности
из заданного класса моделей, чтобы описать ограниченный
набор

Слайд 8Введение
Терминология
Термин ИМСОМ был почти сразу заменен авторами метода
на термин МГУА
МГУА =
Введение
Терминология
Термин ИМСОМ был почти сразу заменен авторами метода
на термин МГУА
МГУА =

Слайд 9Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 10Коллеги и соавторы
Pavel Makagonov
Titled Research Professor
Mixteca University of Technology, Mexico
Коллеги и соавторы
Pavel Makagonov
Titled Research Professor
Mixteca University of Technology, Mexico

Слайд 11Коллеги и соавторы
Xavier Blanco
Titled Professor of French Philology Department
Universidad Autonoma
Коллеги и соавторы
Xavier Blanco
Titled Professor of French Philology Department
Universidad Autonoma

Слайд 12Коллеги и соавторы
Alexander Gelbukh
Chief of NLP Laboratory
Center for
Коллеги и соавторы
Alexander Gelbukh
Chief of NLP Laboratory
Center for

Слайд 13Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 14Индуктивное Моделирование
Классы и сложность модели
ИМСОМ имеет дело с заранее фиксированным классом моделей.
Индуктивное Моделирование
Классы и сложность модели
ИМСОМ имеет дело с заранее фиксированным классом моделей.

Слайд 15Индуктивное моделирование
Каноническая проблема
Описание временного ряда некоторой
формулой
Пусть начальная информация задана ?
Заданная
Индуктивное моделирование
Каноническая проблема
Описание временного ряда некоторой
формулой
Пусть начальная информация задана ?
Заданная

Слайд 16Индуктивное моделирование
Мы имеем начальную информацию
Заданная регрессионная модель
Ym= a0 + a1t or
Индуктивное моделирование
Мы имеем начальную информацию
Заданная регрессионная модель
Ym= a0 + a1t or
Слайд 17Индуктивное моделирование
Каноническая проблема
Описание временного ряда некоторой формулой
Пусть начальная информация отсутствует ?
У
Индуктивное моделирование
Каноническая проблема
Описание временного ряда некоторой формулой
Пусть начальная информация отсутствует ?
У

Слайд 18Индуктивное моделирование
Принцип индуктивности
ИМСОМ не может найти самую оптимальную модель среди всех
возможных!
Индуктивное моделирование
Принцип индуктивности
ИМСОМ не может найти самую оптимальную модель среди всех
возможных!

Слайд 19Индуктивное моделирование
Подход 1
Мы должны обеспечить хорошее свойство
прогнозирования, то есть ограниченную
чувствительность к
Индуктивное моделирование
Подход 1
Мы должны обеспечить хорошее свойство
прогнозирования, то есть ограниченную
чувствительность к
Слайд 20Индуктивное моделирование
Подход 2
Мы должны обеспечить хорошее
описательное свойство, то есть
независимость описания
Индуктивное моделирование
Подход 2
Мы должны обеспечить хорошее
описательное свойство, то есть
независимость описания
Слайд 21Индуктивное моделирование
Формы внешних критериев
Качество модели оценивается внешними критериями
Каждый из критериев может
Индуктивное моделирование
Формы внешних критериев
Качество модели оценивается внешними критериями
Каждый из критериев может
Слайд 22Индуктивное моделирование
Шаги ИМСОМ <= !
Определить серию моделей
2. Экспериментальные данные =
Индуктивное моделирование
Шаги ИМСОМ <= !
Определить серию моделей
2. Экспериментальные данные =
Слайд 23Индуктивное моделирование
Применение двух критериев, правило свертки
Назначаются веса λ1, λ2: λ1+ λ2
Индуктивное моделирование
Применение двух критериев, правило свертки
Назначаются веса λ1, λ2: λ1+ λ2
Слайд 24Индуктивное моделирование
Применение двух критериев, последовательный отбор
Вместо отбора модели по комбинированному
критерию K=λ1Kr
Индуктивное моделирование
Применение двух критериев, последовательный отбор
Вместо отбора модели по комбинированному
критерию K=λ1Kr
Слайд 25Индуктивное моделирование
Подавление шума
Утверждение
Пусть имеем N-данных наблюдений y1, y2, y3, ....yN
Пусть имеем k-параметров
Индуктивное моделирование
Подавление шума
Утверждение
Пусть имеем N-данных наблюдений y1, y2, y3, ....yN
Пусть имеем k-параметров

Слайд 26Индуктивное моделирование
Пример
Пусть мы должны восстановить параболу Y(t)=a0 + a1t + a2t2
Имеем N=12,
Индуктивное моделирование
Пример
Пусть мы должны восстановить параболу Y(t)=a0 + a1t + a2t2
Имеем N=12,
Слайд 27Варианты ИМСОМ
Имеется два традиционных варианта:
1) Комбинаторный вариант ИСОМ - КОМБИ
Перебираются
Варианты ИМСОМ
Имеется два традиционных варианта:
1) Комбинаторный вариант ИСОМ - КОМБИ
Перебираются

Слайд 28Индуктивное моделирование
Пример применения селекции
Пусть имеем 20 точек наблюдений = 10 (обучение)
Индуктивное моделирование
Пример применения селекции
Пусть имеем 20 точек наблюдений = 10 (обучение)

Слайд 29Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 30Постановка задачи
Предмет рассмотрения
Статистический стеммер.
Построение эмпирической формулы, обученной на примерах
Техника
Индуктивное моделирование
Постановка задачи
Предмет рассмотрения
Статистический стеммер.
Построение эмпирической формулы, обученной на примерах
Техника
Индуктивное моделирование

Слайд 31Постановка задачи
Стемминг
Состоит в выборе части слова,
отражающей основное значение слова
Примеры
sad, sadly,
Постановка задачи
Стемминг
Состоит в выборе части слова,
отражающей основное значение слова
Примеры
sad, sadly,

Слайд 32Постановка задачи
Проблема
Построить формулу для принятия решения
о подобии пары слов
Актуальность
Нам приходится обрабатывать
Постановка задачи
Проблема
Построить формулу для принятия решения
о подобии пары слов
Актуальность
Нам приходится обрабатывать

Слайд 33Эмпирические формулы
Параметры для сравнения пары слов
Мы будем обучать формулу на положительных примерах,
Эмпирические формулы
Параметры для сравнения пары слов
Мы будем обучать формулу на положительных примерах,

Слайд 34Эмпирические формулы
Требования
Построенная формула должна отражать два обстоятельства:
Поддержать факт, что небольшое относительное число
Эмпирические формулы
Требования
Построенная формула должна отражать два обстоятельства:
Поддержать факт, что небольшое относительное число

Слайд 35Эмпирические формулы
Модели для принятия решений
Какую формулу стоит настраивать
под примеры, заданные экспертом?
Эмпирические формулы
Модели для принятия решений
Какую формулу стоит настраивать
под примеры, заданные экспертом?

Слайд 36Эмпирические формулы
Число степеней свободы
Как было указано выше, формула должна зависеть от:
- относительной
Эмпирические формулы
Число степеней свободы
Как было указано выше, формула должна зависеть от:
- относительной

Слайд 37
Дискриминация длинных слов
yyynn yyynn n/s = 0.4
yyyyyynnnn yyyyyynnnn n/s = 0.4
Дискриминация длинных слов
yyynn yyynn n/s = 0.4
yyyyyynnnn yyyyyynnnn n/s = 0.4
Слайд 38Эмпирические формулы
Сложность модели F(y) ?
Чтобы определить сложность модели (степень полинома), мы
используем ИМСОМ
Эмпирические формулы
Сложность модели F(y) ?
Чтобы определить сложность модели (степень полинома), мы
используем ИМСОМ

Слайд 39
Подход
1) Мы рассматриваем
экстремальные случаи (равенство)
n/s = a0 + a1y + a2y2 + ...
Подход
1) Мы рассматриваем
экстремальные случаи (равенство)
n/s = a0 + a1y + a2y2 + ...

Слайд 40
ИМСОМ - Реализация
Пример
n/s = a0 + a1y + a2y2+....
asking asked
n = 5 s =
ИМСОМ - Реализация
Пример
n/s = a0 + a1y + a2y2+....
asking asked
n = 5 s =

Слайд 41
Внешние критерии
Регулярность Kr
Несмещенность Ku
Комбинированный критерий
K = 2/3 Kr + 1/3 Ku
Внешние критерии
Регулярность Kr
Несмещенность Ku
Комбинированный критерий
K = 2/3 Kr + 1/3 Ku
Слайд 42
Результаты
Формулы (линейные модели)
French n/s ≤ 0.48 – 0.024 y
Italian
Результаты
Формулы (линейные модели)
French n/s ≤ 0.48 – 0.024 y
Italian

Слайд 43Демонстрация
Пример
Начальный список 1-й шаг 2-й шаг 3-й шаг
transform (7) transform (12) transform
Демонстрация
Пример
Начальный список 1-й шаг 2-й шаг 3-й шаг
transform (7) transform (12) transform

Слайд 44Дискуссия и выводы
Примеры Мартина Портера
Д-р Портер, автор знаменитого стеммера, реализованного
на многих
Дискуссия и выводы
Примеры Мартина Портера
Д-р Портер, автор знаменитого стеммера, реализованного
на многих

Слайд 45Дискуссия и выводы
Недостатки стеммера
- Относительно низкая точность (80%-90%)
- Зависимость результатов применения от
Дискуссия и выводы
Недостатки стеммера
- Относительно низкая точность (80%-90%)
- Зависимость результатов применения от

Слайд 46Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 47Введение
Предмет рассмотрения
Subjectivity/Sentiment analysis.
Построение эмпирических формул для автоматической оценки вежливости, удовлетворенности и компетентности
Введение
Предмет рассмотрения
Subjectivity/Sentiment analysis.
Построение эмпирических формул для автоматической оценки вежливости, удовлетворенности и компетентности

Слайд 48Введение
Subjectivity/Sentiment анализ это область обработки
естественных языков (NLP), которая направлена на
автоматическую
Введение
Subjectivity/Sentiment анализ это область обработки
естественных языков (NLP), которая направлена на
автоматическую

Слайд 49Введение
Одно из приложений SSA это обработка диалогов.
В настоящее время такая обработка
Введение
Одно из приложений SSA это обработка диалогов.
В настоящее время такая обработка

Слайд 50Исходные данные
Данные состояли из 85 диалогов между пассажирами
и справочной железнодорожного вокзала
Исходные данные
Данные состояли из 85 диалогов между пассажирами
и справочной железнодорожного вокзала

Слайд 51Пример: Вежливость
Пример: Вежливость

Слайд 52Вежливость, параметризация
А. Индиктор первого приветствия (g - greeting)
Имеет значение 1, при
Вежливость, параметризация
А. Индиктор первого приветствия (g - greeting)
Имеет значение 1, при

Слайд 53Вежливость, параметризация
Для числового представления v и w следует учесть
- длину документа
информационный
Вежливость, параметризация
Для числового представления v и w следует учесть
- длину документа
информационный

Слайд 54Вежливость, параметризация
Ручные оценки учитывают только вежливость
(но не грубость) по шкале:
0
Вежливость, параметризация
Ручные оценки учитывают только вежливость
(но не грубость) по шкале:
0

Слайд 55Вежливость, параметризация
Вежливость, параметризация

Слайд 56Вежливость, модели
Мы предположили, что зависимость между числовыми
индикаторами и и уровнем
Вежливость, модели
Мы предположили, что зависимость между числовыми
индикаторами и и уровнем

Слайд 57Вежливость, модели
Подготовка данных для МНК
Вежливость, модели
Подготовка данных для МНК
Слайд 58Вежливость, результаты
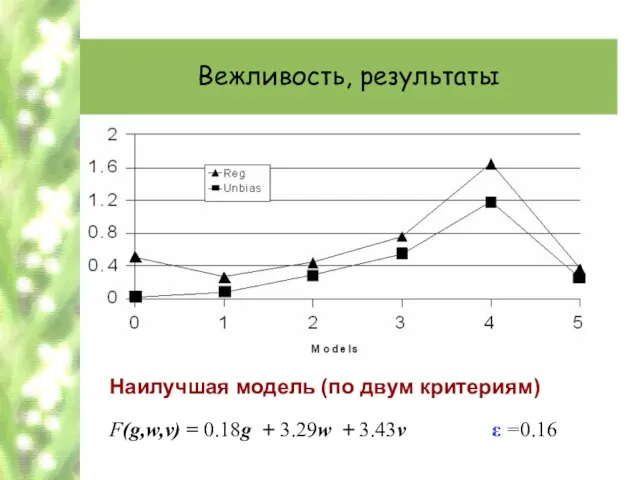
Наилучшая модель (по двум критериям)
F(g,w,v) = 0.18g + 3.29w + 3.43v
Вежливость, результаты
Наилучшая модель (по двум критериям)
F(g,w,v) = 0.18g + 3.29w + 3.43v
Слайд 59Удовлетворенность, параметризация
Серия моделей
Model 0: F(b,f,q) = A0
Model 1: F(b,f,q) = B100b +
Удовлетворенность, параметризация
Серия моделей
Model 0: F(b,f,q) = A0
Model 1: F(b,f,q) = B100b +

Слайд 60Удовлетворенность, результаты
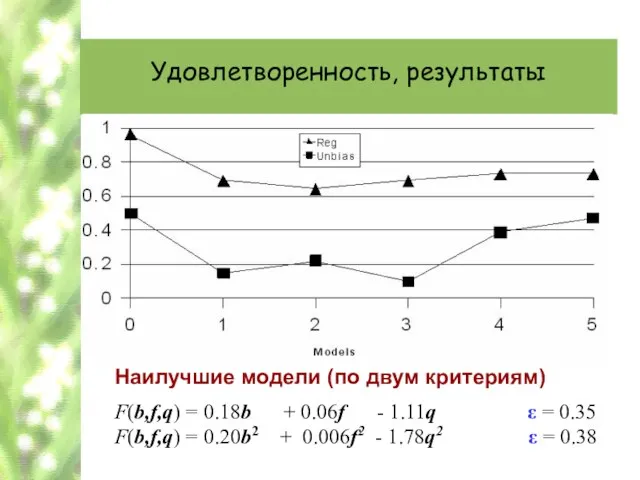
Наилучшие модели (по двум критериям)
F(b,f,q) = 0.18b + 0.06f - 1.11q
Удовлетворенность, результаты
Наилучшие модели (по двум критериям)
F(b,f,q) = 0.18b + 0.06f - 1.11q
Слайд 61Компетентность,параметризация
Серия моделей
Model 0: F(b,f,q) = A0
Model 1: F(b,f,q) = B100l + B010f
Компетентность,параметризация
Серия моделей
Model 0: F(b,f,q) = A0
Model 1: F(b,f,q) = B100l + B010f

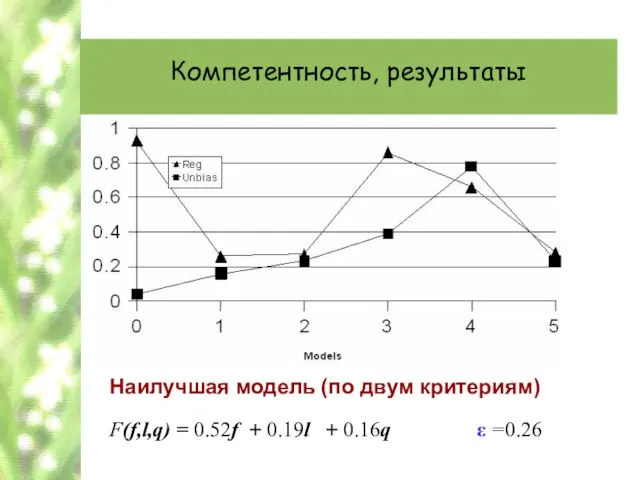
Слайд 62Компетентность, результаты
Наилучшая модель (по двум критериям)
F(f,l,q) = 0.52f + 0.19l + 0.16q
Компетентность, результаты
Наилучшая модель (по двум критериям)
F(f,l,q) = 0.52f + 0.19l + 0.16q
Слайд 63Выводы
1. ИМСОМ обеспечивает методологию для автоматической
оценки различных «размытых» характеристик диалога,
имеющих
Выводы
1. ИМСОМ обеспечивает методологию для автоматической
оценки различных «размытых» характеристик диалога,
имеющих

Слайд 64Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 65Предмет рассмотрения
Терминография.
Выявление гранулярности терминов
заданной предметной области
Техника
Идеи индуктивного моделирования
Предмет рассмотрения
Терминография.
Выявление гранулярности терминов
заданной предметной области
Техника
Идеи индуктивного моделирования
Слайд 66Под терминами будем понимать ключевые слова предметной области
Ключевые слова используются для:
A.
Под терминами будем понимать ключевые слова предметной области
Ключевые слова используются для:
A.
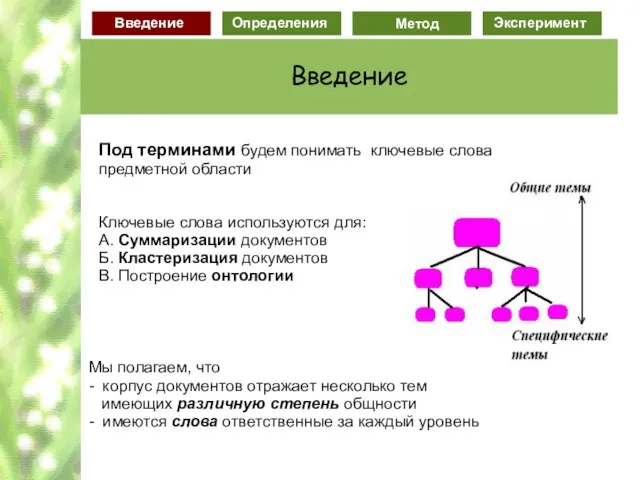
Слайд 67Главные термины
области
Рост специфичности
Применения гранулированных терминов:
1. Суммаризация документов по различным уровням детальности
2.
Главные термины
области
Рост специфичности
Применения гранулированных терминов:
1. Суммаризация документов по различным уровням детальности
2.

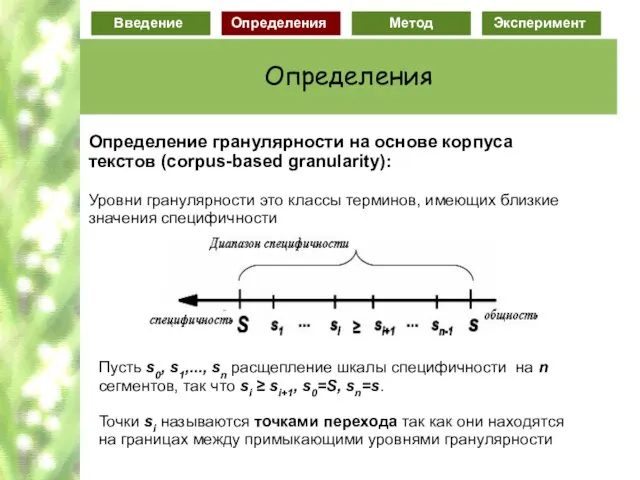
Слайд 68Определение гранулярности на основе корпуса текстов (corpus-based granularity):
Уровни гранулярности это классы
Определение гранулярности на основе корпуса текстов (corpus-based granularity):
Уровни гранулярности это классы
Слайд 69Definitions
Определение проблемы:
Выявление уровней гранулярности эквивалентно проблеме размещения точек перехода на оси
Definitions
Определение проблемы:
Выявление уровней гранулярности эквивалентно проблеме размещения точек перехода на оси


Слайд 71Мы используем ИМСОМ-подобный алгоритм
Напомним основные шаги ИМСОМ:
1. Эксперт определяет последовательность моделей
Мы используем ИМСОМ-подобный алгоритм
Напомним основные шаги ИМСОМ:
1. Эксперт определяет последовательность моделей

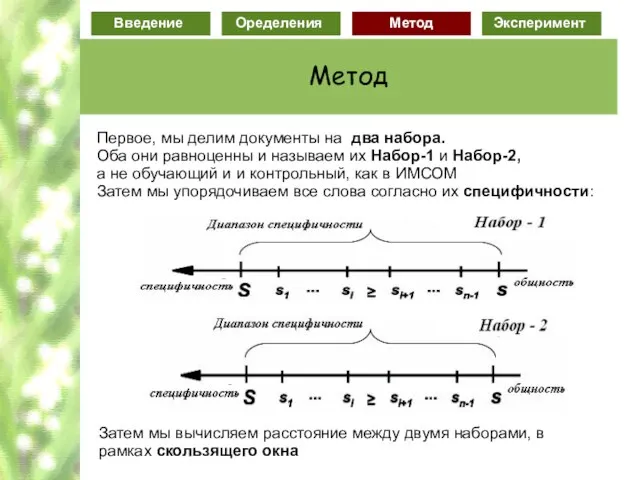
Слайд 72Первое, мы делим документы на два набора.
Оба они равноценны и называем
Первое, мы делим документы на два набора.
Оба они равноценны и называем
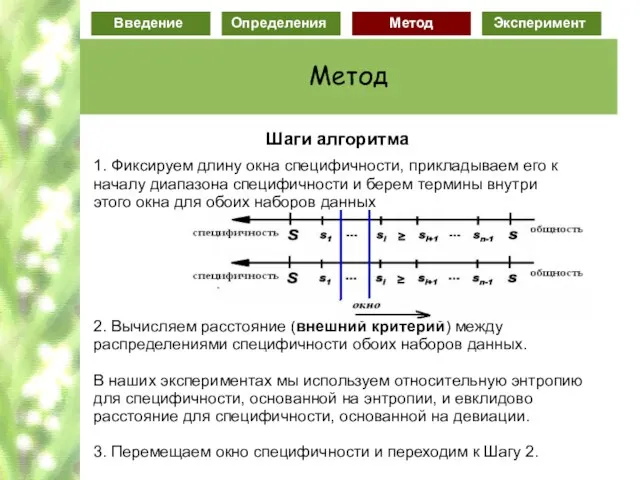
Слайд 73 Шаги алгоритма
1. Фиксируем длину окна специфичности, прикладываем его к началу диапазона
Шаги алгоритма
1. Фиксируем длину окна специфичности, прикладываем его к началу диапазона
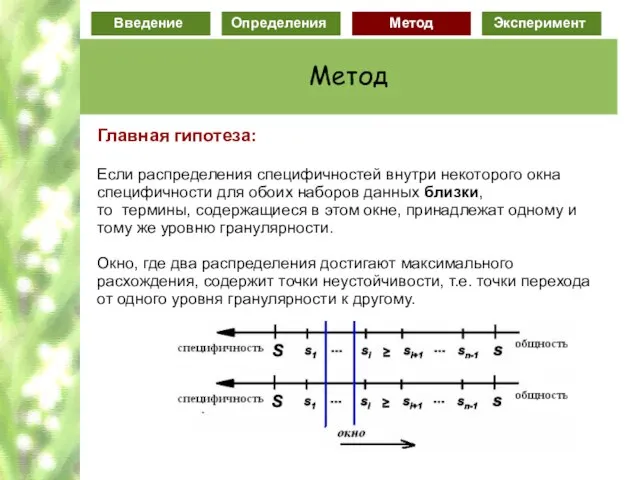
Слайд 74Главная гипотеза:
Если распределения специфичностей внутри некоторого окна
специфичности для обоих наборов данных
Главная гипотеза:
Если распределения специфичностей внутри некоторого окна
специфичности для обоих наборов данных
Слайд 75Внешние критерии
Давайте зафиксируем одно и тоже окно Δs = [s1,s2] внутри диапазонов
Давайте зафиксируем одно и тоже окно Δs = [s1,s2] внутри диапазонов
![Внешние критерии Давайте зафиксируем одно и тоже окно Δs = [s1,s2] внутри](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/368782/slide-74.jpg)
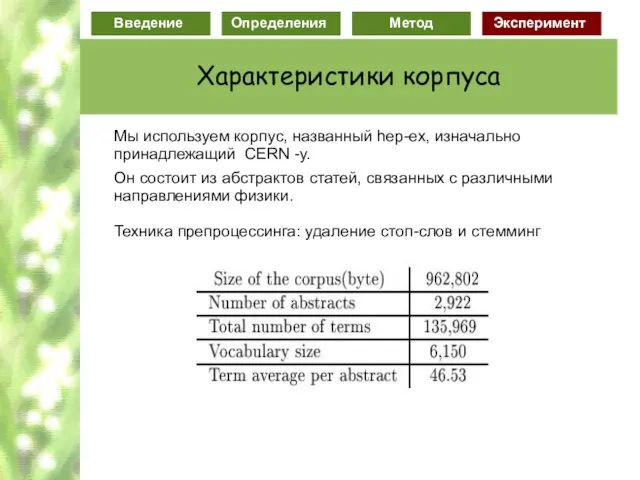
Слайд 76Мы используем корпус, названный hep-ex, изначально
принадлежащий CERN -у.
Он состоит из абстрактов
Мы используем корпус, названный hep-ex, изначально
принадлежащий CERN -у.
Он состоит из абстрактов
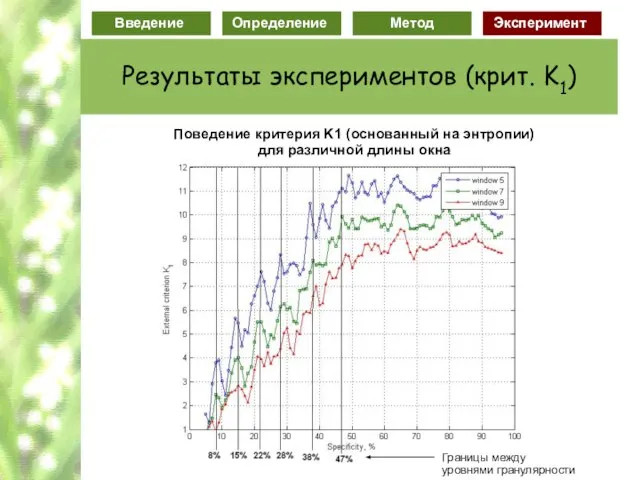
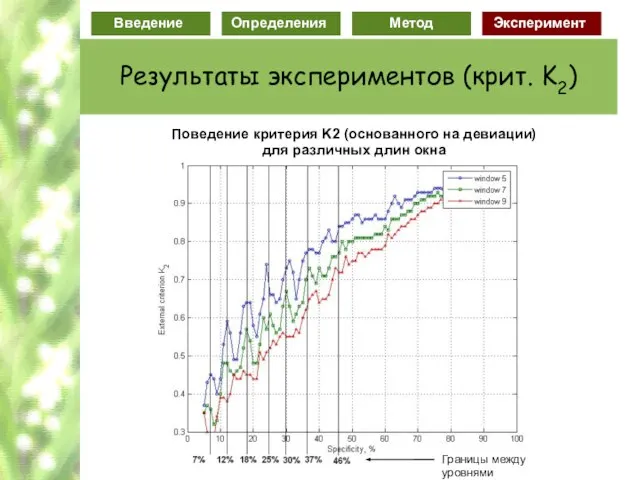
Слайд 77Поведение критерия K1 (основанный на энтропии)
для различной длины окна
Поведение критерия K1 (основанный на энтропии)
для различной длины окна
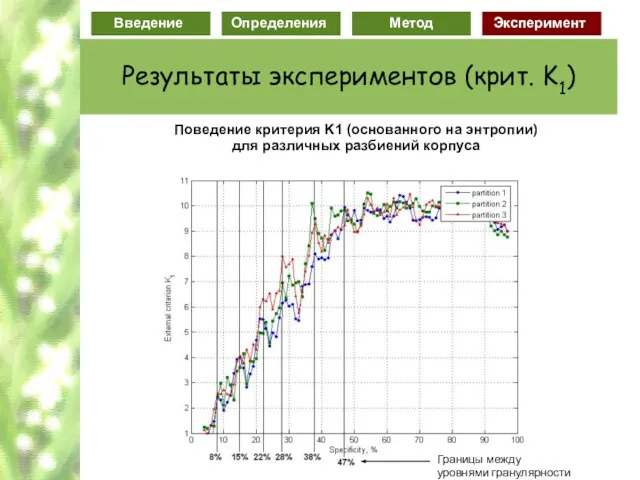
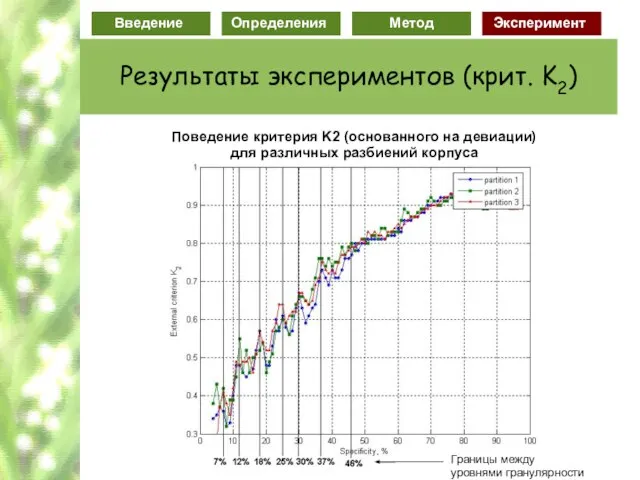
Слайд 78Поведение критерия K1 (основанного на энтропии)
для различных разбиений корпуса
Поведение критерия K1 (основанного на энтропии)
для различных разбиений корпуса
Слайд 81Слова в Таблице упорядочены согласно их специфичности
Слова в Таблице упорядочены согласно их специфичности

Слайд 821) Мы постарались формализовать понятие гранулярности для терминологии предметной области. Для этого
1) Мы постарались формализовать понятие гранулярности для терминологии предметной области. Для этого

Слайд 83Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы
Содержание
Введение
Коллеги и соавторы
Индуктивное моделирование
Статистический стеммер
Subjectivity/Sentiment analysis
Терминография
Ресурсы

Слайд 84Ресурсы - Украина
(1) Международный центр информационных технологий и систем, НАН и МОН
Ресурсы - Украина
(1) Международный центр информационных технологий и систем, НАН и МОН

Слайд 85Ресурсы - Украина
Поддержка сообщества ИМ
Отдел проф. В.С. Степашко организует:
1) Ежегодные Летние Школы
Ресурсы - Украина
Поддержка сообщества ИМ
Отдел проф. В.С. Степашко организует:
1) Ежегодные Летние Школы

Слайд 86Ресурсы - Украина
(2) Компания Geos Research Group, Киев, Украина
http:// www.gmdhshell.com
Компания
Ресурсы - Украина
(2) Компания Geos Research Group, Киев, Украина
http:// www.gmdhshell.com
Компания
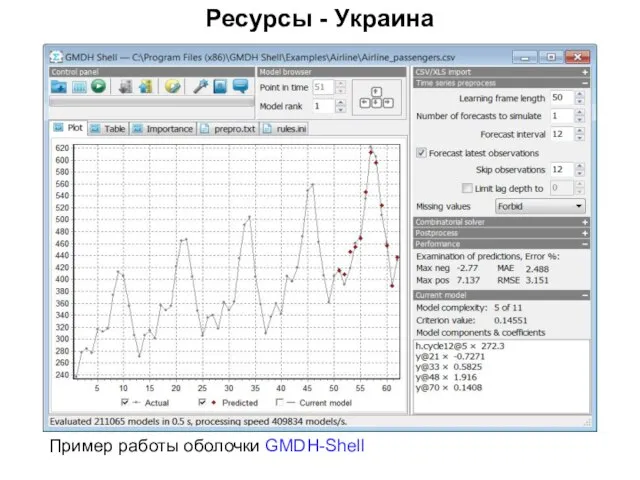
Слайд 87Ресурсы - Украина
Пример работы оболочки GMDH-Shell
Ресурсы - Украина
Пример работы оболочки GMDH-Shell
Слайд 88Ресурсы - Москва
(1) Вычислительный Центр РАН
Московский физико-технический институт
http:// www.machinelearning.ru
Это Wiki подобный
Ресурсы - Москва
(1) Вычислительный Центр РАН
Московский физико-технический институт
http:// www.machinelearning.ru
Это Wiki подобный

Слайд 89Ресурсы - Москва
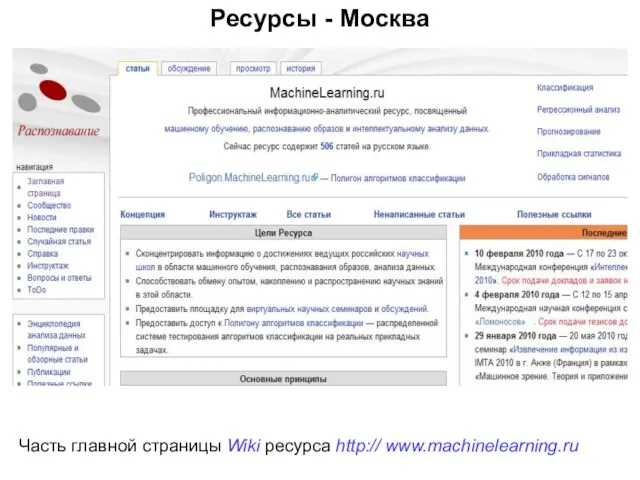
Часть главной страницы Wiki ресурса http:// www.machinelearning.ru
Ресурсы - Москва
Часть главной страницы Wiki ресурса http:// www.machinelearning.ru
Слайд 90Ресурсы - Москва
(2) Компания Forecsys, Москва, Россия
http:// www.forecsys.ru/site/about/about/
Компания Forecsys — российский вендор
Ресурсы - Москва
(2) Компания Forecsys, Москва, Россия
http:// www.forecsys.ru/site/about/about/
Компания Forecsys — российский вендор

Слайд 91Ресурсы - Москва
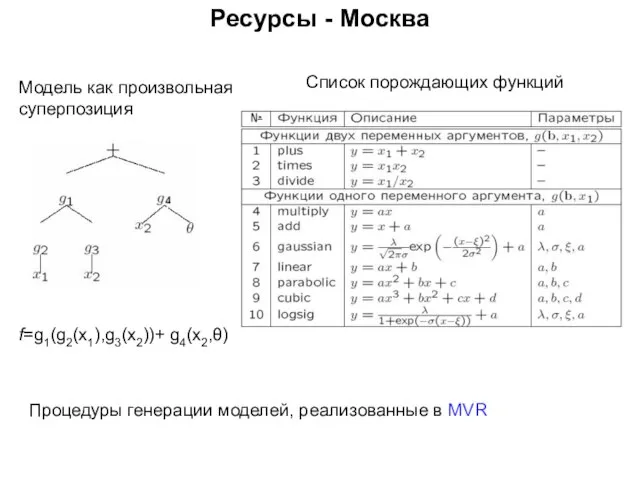
Процедуры генерации моделей, реализованные в MVR
Модель как произвольная
суперпозиция
Список порождающих
Ресурсы - Москва
Процедуры генерации моделей, реализованные в MVR
Модель как произвольная
суперпозиция
Список порождающих
 Интерактивный квест Спасение эйленов
Интерактивный квест Спасение эйленов ОФБУ как форма управления активами
ОФБУ как форма управления активами Педагогические колледжи Красноярского края
Педагогические колледжи Красноярского края Осторожно огонь
Осторожно огонь Требования, предъявляемые к лицам, назначаемым на должности прокуроров
Требования, предъявляемые к лицам, назначаемым на должности прокуроров А. Куприн «Слон»
А. Куприн «Слон» Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров
Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров Презентация на тему Вред здоровью человека от сотового телефона
Презентация на тему Вред здоровью человека от сотового телефона  «Роль игры в развитии речи дошкольника»
«Роль игры в развитии речи дошкольника» Спорт среди молодежи в Красноярске
Спорт среди молодежи в Красноярске Лувр
Лувр Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму»
Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму» Моделирование при разработке управленческих решений. Разработка управленческого решения
Моделирование при разработке управленческих решений. Разработка управленческого решения Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори
Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори Страницы истории
Страницы истории  Презентация на тему Петр 1
Презентация на тему Петр 1  5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование
5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование Использование современных образовательных технологий в процессе обучения русскому языку
Использование современных образовательных технологий в процессе обучения русскому языку Медведев Егор Бийск ОПШ 2022 (1) (1)
Медведев Егор Бийск ОПШ 2022 (1) (1) Россия выбирает президента
Россия выбирает президента Изображение головы человека в пространстве
Изображение головы человека в пространстве Искусство раннего Возрождения
Искусство раннего Возрождения Проверка домашнего задания
Проверка домашнего задания Новая сказка про Красную Шапочку
Новая сказка про Красную Шапочку Танковая навигационная аппаратура
Танковая навигационная аппаратура Social and personality development and types of play pre-school years
Social and personality development and types of play pre-school years  Презентация на тему ЗУНР Западно-Украинская Народная Республика
Презентация на тему ЗУНР Западно-Украинская Народная Республика  Спин - HIV
Спин - HIV