- Классификация и кластеризация документов

Содержание
- 2. Информационно-поисковые системы. Сычев А.В. 2006 г. Объединение документов или их представлений в одну группу, которая в
- 3. Информационно-поисковые системы. Сычев А.В. 2006 г. Два способа: на основе заранее заданной схемы классификации и уже
- 4. Информационно-поисковые системы. Сычев А.В. 2006 г. Фильтрация входящих документов Сжатие информации (аннотирование, реферирование) Расширение запросов за
- 5. Информационно-поисковые системы. Сычев А.В. 2006 г. 10 человек, 5 запросов Наиболее частые запросы с существенно различающимися
- 6. Информационно-поисковые системы. Сычев А.В. 2006 г. Классификация вручную. Результаты эксперимента. Наблюдается разброс в результатах классификации документов
- 7. Информационно-поисковые системы. Сычев А.В. 2006 г. Кластеризация Основой методов кластеризации является кластерная гипотеза (C.J. van Rijsbergen),
- 8. Информационно-поисковые системы. Сычев А.В. 2006 г. Fairthorne “The Mathematics of Classification” (1961) Эксперименты Марона (1961), Борко
- 9. Информационно-поисковые системы. Сычев А.В. 2006 г. Кластеризация – удобный инструмент при работе с документальным пространством, имеющим,
- 10. Информационно-поисковые системы. Сычев А.В. 2006 г. Обработка вновь поступающих документов не должна существенным образом изменять результат
- 11. Информационно-поисковые системы. Сычев А.В. 2006 г. Методы кластеризации, основанные на разбиении множеств Целью является разбиение исходного
- 12. Информационно-поисковые системы. Сычев А.В. 2006 г. Метод К-средних Документы описываются векторами с вещественными компонентами Каждый кластер
- 13. Информационно-поисковые системы. Сычев А.В. 2006 г. Алгоритм К-средних Задается метрика d для вычисления расстояния между элементами
- 14. Информационно-поисковые системы. Сычев А.В. 2006 г. Возможное условие остановки цикла: Количество итераций Группировка документов по кластерам
- 15. Информационно-поисковые системы. Сычев А.В. 2006 г. Недостатки: Результат кластеризации зависит от выбора стартовых элементов. Значение k
- 16. Информационно-поисковые системы. Сычев А.В. 2006 г. Иерархическая аггломеративная кластеризация Используется матрица сопряженности типа “документ-документ” (матрица подобия).
- 17. Информационно-поисковые системы. Сычев А.В. 2006 г. Иерархическая аггломеративная кластеризация Сечение дендограммы на любом уровне дает набор
- 18. Информационно-поисковые системы. Сычев А.В. 2006 г. Иерархическая аггломеративная кластеризация Порог принятия решения о подобии кластеров задается
- 19. Информационно-поисковые системы. Сычев А.В. 2006 г. Поиск кластера Входной запрос представляется в виде t-мерного вектора и
- 20. Информационно-поисковые системы. Сычев А.В. 2006 г. Существует необходимость распределенного хранения документов в кластерной системе По какому
- 21. Информационно-поисковые системы. Сычев А.В. 2006 г. Вырожденный случай – единая система Гетерогенные коллекции кластеры построены заранее
- 22. Информационно-поисковые системы. Сычев А.В. 2006 г. Выполнение запроса: Ранжирование коллекций относительно запроса Выбор n лучших коллекций
- 23. Информационно-поисковые системы. Сычев А.В. 2006 г. Кластеризация в распределенных системах: выводы Тематическая кластеризация эффективна для распределенного
- 24. Информационно-поисковые системы. Сычев А.В. 2006 г. Соседние в гиперссылочном графе документы могут содержать информацию, полезную при
- 25. Информационно-поисковые системы. Сычев А.В. 2006 г. Идея: использовать при классификации термины и метки классов документов-соседей по
- 26. Информационно-поисковые системы. Сычев А.В. 2006 г. Модификация запросов Переформулировка запроса Расширение запроса Добавление терминов в запрос
- 27. Информационно-поисковые системы. Сычев А.В. 2006 г. Обратная связь по релевантности Метод Rocchio: где Q0 – вектор
- 28. Информационно-поисковые системы. Сычев А.В. 2006 г. Латентно-семантическое индексирование как кластеризация LSI может рассматриваться как метод кластеризации
- 29. Информационно-поисковые системы. Сычев А.В. 2006 г. Литература R. Larson “Principles of Information Retrieval”. Слайды (http://www.sims.berkeley.edu/academics/courses/is240/s06/) G.
- 31. Скачать презентацию
Слайд 2Информационно-поисковые системы. Сычев А.В. 2006 г.
Объединение документов или их представлений в одну
Информационно-поисковые системы. Сычев А.В. 2006 г.
Объединение документов или их представлений в одну

Слайд 3Информационно-поисковые системы. Сычев А.В. 2006 г.
Два способа:
на основе заранее заданной схемы классификации
Информационно-поисковые системы. Сычев А.В. 2006 г.
Два способа:
на основе заранее заданной схемы классификации

Слайд 4Информационно-поисковые системы. Сычев А.В. 2006 г.
Фильтрация входящих документов
Сжатие информации (аннотирование, реферирование)
Расширение запросов
Информационно-поисковые системы. Сычев А.В. 2006 г.
Фильтрация входящих документов
Сжатие информации (аннотирование, реферирование)
Расширение запросов

Слайд 5Информационно-поисковые системы. Сычев А.В. 2006 г.
10 человек, 5 запросов
Наиболее частые запросы с
Информационно-поисковые системы. Сычев А.В. 2006 г.
10 человек, 5 запросов
Наиболее частые запросы с

Слайд 6Информационно-поисковые системы. Сычев А.В. 2006 г.
Классификация вручную. Результаты эксперимента.
Наблюдается разброс в результатах
Информационно-поисковые системы. Сычев А.В. 2006 г.
Классификация вручную. Результаты эксперимента.
Наблюдается разброс в результатах

Слайд 7Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация
Основой методов кластеризации является кластерная гипотеза (C.J.
Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация
Основой методов кластеризации является кластерная гипотеза (C.J.

Слайд 8Информационно-поисковые системы. Сычев А.В. 2006 г.
Fairthorne “The Mathematics of Classification” (1961)
Эксперименты Марона
Информационно-поисковые системы. Сычев А.В. 2006 г.
Fairthorne “The Mathematics of Classification” (1961)
Эксперименты Марона

Слайд 9Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация – удобный инструмент при работе с
Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация – удобный инструмент при работе с

Слайд 10Информационно-поисковые системы. Сычев А.В. 2006 г.
Обработка вновь поступающих документов не должна существенным
Информационно-поисковые системы. Сычев А.В. 2006 г.
Обработка вновь поступающих документов не должна существенным

Слайд 11Информационно-поисковые системы. Сычев А.В. 2006 г.
Методы кластеризации,
основанные на разбиении множеств
Целью является
Информационно-поисковые системы. Сычев А.В. 2006 г.
Методы кластеризации,
основанные на разбиении множеств
Целью является

Слайд 12Информационно-поисковые системы. Сычев А.В. 2006 г.
Метод К-средних
Документы описываются векторами с вещественными компонентами
Каждый
Информационно-поисковые системы. Сычев А.В. 2006 г.
Метод К-средних
Документы описываются векторами с вещественными компонентами
Каждый

Слайд 13Информационно-поисковые системы. Сычев А.В. 2006 г.
Алгоритм К-средних
Задается метрика d для вычисления расстояния
Информационно-поисковые системы. Сычев А.В. 2006 г.
Алгоритм К-средних
Задается метрика d для вычисления расстояния

Слайд 14Информационно-поисковые системы. Сычев А.В. 2006 г.
Возможное условие остановки цикла:
Количество итераций
Группировка документов по
Информационно-поисковые системы. Сычев А.В. 2006 г.
Возможное условие остановки цикла:
Количество итераций
Группировка документов по

Слайд 15Информационно-поисковые системы. Сычев А.В. 2006 г.
Недостатки:
Результат кластеризации зависит от выбора стартовых элементов.
Значение
Информационно-поисковые системы. Сычев А.В. 2006 г.
Недостатки:
Результат кластеризации зависит от выбора стартовых элементов.
Значение

Слайд 16Информационно-поисковые системы. Сычев А.В. 2006 г.
Иерархическая
аггломеративная кластеризация
Используется матрица сопряженности типа “документ-документ”
Информационно-поисковые системы. Сычев А.В. 2006 г.
Иерархическая
аггломеративная кластеризация
Используется матрица сопряженности типа “документ-документ”

Слайд 17Информационно-поисковые системы. Сычев А.В. 2006 г.
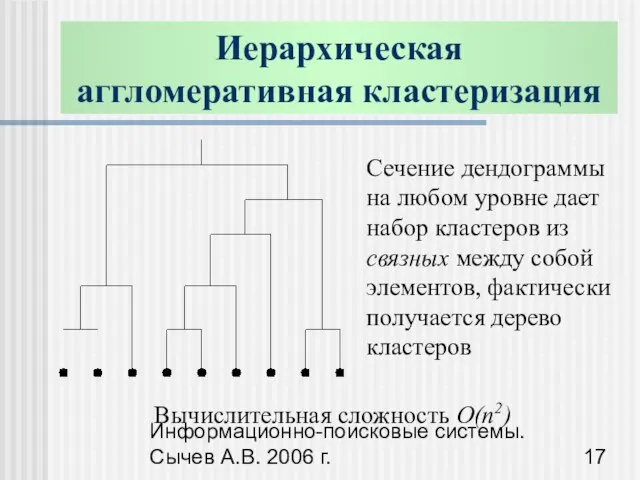
Иерархическая
аггломеративная кластеризация
Сечение дендограммы на любом уровне
Информационно-поисковые системы. Сычев А.В. 2006 г.
Иерархическая
аггломеративная кластеризация
Сечение дендограммы на любом уровне
Слайд 18Информационно-поисковые системы. Сычев А.В. 2006 г.
Иерархическая
аггломеративная кластеризация
Порог принятия решения о подобии
Информационно-поисковые системы. Сычев А.В. 2006 г.
Иерархическая
аггломеративная кластеризация
Порог принятия решения о подобии

Слайд 19Информационно-поисковые системы. Сычев А.В. 2006 г.
Поиск кластера
Входной запрос представляется в виде t-мерного
Информационно-поисковые системы. Сычев А.В. 2006 г.
Поиск кластера
Входной запрос представляется в виде t-мерного

Слайд 20Информационно-поисковые системы. Сычев А.В. 2006 г.
Существует необходимость распределенного хранения документов в кластерной
Информационно-поисковые системы. Сычев А.В. 2006 г.
Существует необходимость распределенного хранения документов в кластерной

Слайд 21Информационно-поисковые системы. Сычев А.В. 2006 г.
Вырожденный случай – единая система
Гетерогенные коллекции
кластеры построены
Информационно-поисковые системы. Сычев А.В. 2006 г.
Вырожденный случай – единая система
Гетерогенные коллекции
кластеры построены

Слайд 22Информационно-поисковые системы. Сычев А.В. 2006 г.
Выполнение запроса:
Ранжирование коллекций относительно запроса
Выбор n лучших
Информационно-поисковые системы. Сычев А.В. 2006 г.
Выполнение запроса:
Ранжирование коллекций относительно запроса
Выбор n лучших

Слайд 23Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация в распределенных системах: выводы
Тематическая кластеризация эффективна
Информационно-поисковые системы. Сычев А.В. 2006 г.
Кластеризация в распределенных системах: выводы
Тематическая кластеризация эффективна

Слайд 24Информационно-поисковые системы. Сычев А.В. 2006 г.
Соседние в гиперссылочном графе документы могут содержать
Информационно-поисковые системы. Сычев А.В. 2006 г.
Соседние в гиперссылочном графе документы могут содержать

Слайд 25Информационно-поисковые системы. Сычев А.В. 2006 г.
Идея: использовать при классификации термины и метки
Информационно-поисковые системы. Сычев А.В. 2006 г.
Идея: использовать при классификации термины и метки

Слайд 26Информационно-поисковые системы. Сычев А.В. 2006 г.
Модификация запросов
Переформулировка запроса
Расширение запроса
Добавление терминов в запрос
Информационно-поисковые системы. Сычев А.В. 2006 г.
Модификация запросов
Переформулировка запроса
Расширение запроса
Добавление терминов в запрос

Слайд 27Информационно-поисковые системы. Сычев А.В. 2006 г.
Обратная связь по релевантности
Метод Rocchio:
где
Q0 – вектор
Информационно-поисковые системы. Сычев А.В. 2006 г.
Обратная связь по релевантности
Метод Rocchio:
где
Q0 – вектор

Слайд 28Информационно-поисковые системы. Сычев А.В. 2006 г.
Латентно-семантическое индексирование как кластеризация
LSI может рассматриваться как
Информационно-поисковые системы. Сычев А.В. 2006 г.
Латентно-семантическое индексирование как кластеризация
LSI может рассматриваться как

Слайд 29Информационно-поисковые системы. Сычев А.В. 2006 г.
Литература
R. Larson “Principles of Information Retrieval”. Слайды
Информационно-поисковые системы. Сычев А.В. 2006 г.
Литература
R. Larson “Principles of Information Retrieval”. Слайды

 Итоговый урок физика8 класс
Итоговый урок физика8 класс Исчезающие виды рыб
Исчезающие виды рыб Описание места (6 класс)
Описание места (6 класс) Невыполненные мероприятия за 1 семестр2011-2012 уч. г.
Невыполненные мероприятия за 1 семестр2011-2012 уч. г. Elos. Эпиляция в новом формате
Elos. Эпиляция в новом формате Изменения в Свод правил и Тарифы АО "Центральный депозитарий ценных бумаг"
Изменения в Свод правил и Тарифы АО "Центральный депозитарий ценных бумаг" Витамин C (аскорбиновая кислота)
Витамин C (аскорбиновая кислота) Образ женщины – матери сквозь века
Образ женщины – матери сквозь века Где зимуют птицы?
Где зимуют птицы? Современные электросети Опыт модернизации энергосети Армении
Современные электросети Опыт модернизации энергосети Армении КОНФЛИКТ 8 класс
КОНФЛИКТ 8 класс  Проектирование раздела основной общеобразовательной программы ДОУ «Содержание коррекционной работы»
Проектирование раздела основной общеобразовательной программы ДОУ «Содержание коррекционной работы» Процедура оказания услуги удостоверяющего центра (УЦ). Проверка предоставленных сведений в УЦ
Процедура оказания услуги удостоверяющего центра (УЦ). Проверка предоставленных сведений в УЦ Организационные структуры инновационного менеджмента
Организационные структуры инновационного менеджмента Конкурс ребусов. Картинками зашифрованы русские названия популярных аниме
Конкурс ребусов. Картинками зашифрованы русские названия популярных аниме Поощрение и наказание в воспитании детей
Поощрение и наказание в воспитании детей Метод проектов
Метод проектов Английская литература XIX века
Английская литература XIX века Мои работы
Мои работы Карбоновые кислоты 10 класс
Карбоновые кислоты 10 класс Презентация на тему ПЧЕЛЫ И МУРАВЬИ -ОБЩЕСТВЕННЫЕ НАСЕКОМЫЕ
Презентация на тему ПЧЕЛЫ И МУРАВЬИ -ОБЩЕСТВЕННЫЕ НАСЕКОМЫЕ Базовая подготовка лошади
Базовая подготовка лошади АНАЛИЗАТОРЫ Органы слуха и равновесия
АНАЛИЗАТОРЫ Органы слуха и равновесия Поиск и обработка экономической информации средствами Интернет и офисных приложений
Поиск и обработка экономической информации средствами Интернет и офисных приложений MyTest
MyTest Оборудование Транслак
Оборудование Транслак Объединенная инжиниринговая компания
Объединенная инжиниринговая компания Модель ученического самоуправления
Модель ученического самоуправления