- Математическая статистика

Содержание
- 2. Содержание Введение Генеральная совокупность и выборка Способы отбора Статистическое распределение выборки Эмпирическая функция распределения Статистические оценки
- 3. Введение Математическая статистика – наука, занимающаяся методами обработки экспериментальных данных, полученных в результате наблюдений над случайными
- 4. Генеральная совокупность и выборка Полный набор всех возможных значений дискретной СВ называется генеральной совокупностью. N –
- 5. Способы отбора Отбор, не требующий расчленения: простой, бесповторный с повторениями Отбор, при котором вся генеральная совокупность
- 6. Статистическое распределение выборки Пусть из генеральной совокупности извлечена выборка, причем значение x1 встречалось n1 и т.д.,
- 7. Эмпирическая функция распределения Эмпирической функцией распределения (функция распределения выборки) называетсяF*(x), определяющую для каждого значения xотносительную частоту
- 8. Статистические оценки параметров распределения Точечные оценки Интервальные оценки Точность и надежность Доверительный интервал для мат.ожидания Доверительный
- 9. Для того, чтобы статистические оценки давали хорошее приближение оценивающих параметров, они должны удовлетворять условиям: объем выборки
- 10. Точечные оценки Точечной называют оценку, определяющую одним числом. Пусть требуется изучить количественный признак генеральной совокупности. Допустим,
- 11. Генеральная и выборочная средняя Генеральная средняя – среднее арифметическое значений генеральной совокупности – с повторениями Генеральная
- 12. Генеральная и выборочная дисперсии Генеральной дисперсией называют среднее арифметическое квадратов отклонений значений генеральной совокупности от их
- 13. Интервальные оценки Интервальной оценкой называют оценку, определяющуюся двумя концами интервала. При выборке малого объема точечная оценка
- 14. Точность и надежность Пусть найденная по данной выборке статистическая характеристика θ* служит оценкой неизвестного параметра θ
- 15. Доверительный интервал для мат.ожидания Рассмотрим нахождение доверительного интервала для M(X) нормально распределенной СВ, т.е. нужно найти
- 16. Расчет доверительных интервалов при известной дисперсии Будем рассматривать выборочную среднюю как случайную величину. Примем без доказательств,
- 17. Расчет доверительных интервалов при неизвестной дисперсии Если D(x) неизвестна, а ее несмещенная оценка S2, то в
- 18. Доверительный интервал для оценки дисперсии Доверительный интервал строится на основании того, что величина (n–1)S2/σ распределена по
- 19. Проверка статистических гипотез Статистической гипотезой называют, гипотезу о видах неизвестного распределения или о параметрах известного распределения.
- 20. Классификация гипотез Статистические, нестатистические Выдвинутая, конкурирующая. Выдвинутую гипотезу называют нулевой (основной) и обозначают Н0. Конкурирующая гипотеза
- 21. Статистический критерий, статистическая область Для проверки Н0, используют специально подобранную слу-чайную величину, точное или приближенное значение
- 22. Критической областью называют, совокупность значений критерия при которых Н0 отвергается. Областью принятия гипотезы (областью допустимых значений),
- 23. Правостороннюю называют критическую область определяемую неравенством К>Ккр Левостороннюю называют критическую область определяемую неравенством К Двустороннюю называют
- 24. Сравнение двух дисперсий Рассмотрим гипотезу о параметрах нормального распределе-ния. Пусть имеется две серии опытов, регистрирующая значение
- 25. Механизм проверки По данным выборок значений nх и nу, вычисляют наблюдаемое значение критерия как отношение большей
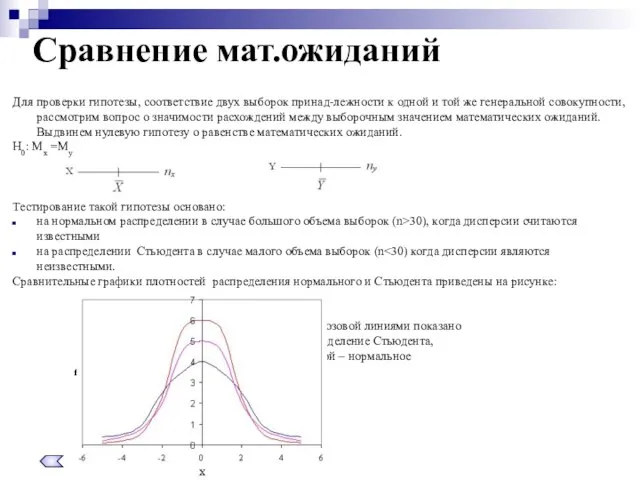
- 26. Для проверки гипотезы, соответствие двух выборок принад-лежности к одной и той же генеральной совокупности, рассмотрим вопрос
- 27. Для того чтобы при заданном уровне значимости α =0.05 проверить нулевую гипотезу Н0: Мх=Му о равенстве
- 28. Проверка гипотезы о равенстве средних при неизвестных дисперсиях Постановка задач: пусть генеральные совокупности распределены нормально, причем
- 29. Алгоритм проверки 1) Прежде чем сравнивать средние требуется проверить Н0: Dх=Dу 2) Если гипотеза подтвердилась нужно
- 30. Проверка гипотезы о законе распределения генеральной совокупности Если закон распределения не известен, но есть основание предположить,
- 31. Критерий Пирсона Пусть по выборке объема n получены эмпирические частоты, т.е. мы имеем предполагаемое распределение. Допустим,
- 32. Правила проверки Для того, чтобы при заданном уровне значимости α проверить Н0: “генеральная совокупность распределена нормально”,
- 33. Корреляционно-регрессионный анализ Корреляционная зависимость Корреляционный момент Коррелированность и зависимость случайных величин Выборочное корреляционное отношение Простейшие случаи
- 34. Во многих задачах требуется установить или оценить зависимость изучаемо случайной величины Y от одной или нескольких
- 35. Корреляционная зависимость Предположим изучается связь между случайными величинами Х и Y. Пусть каждому значению Х соответствует
- 36. Коэффициент корреляции. Выборочным коэффициентом корреляции называется отношение разности между М(Х) произведения случайных величины и произведением математических
- 37. Корреляционный момент Корреляционным моментом μху случайных величин Х и Y, называют математическое ожидание при отклонении этих
- 38. Коррелированность и зависимость случайных величин Две случайных величин называются коррелированными, если их корреляционный момент (или что
- 39. Выборочное корреляционное отношение Для оценки тесноты нелинейной корреляционной связи служат такие характеристики как: выборочное корреляционное отношение
- 40. Достоинства корреляционного отношения. Корреляционное отношение служит мерой тесноты связи любой, в том числе и линейной. В
- 41. Простейшие случаи криволинейной корреляции Если график регрессии Y на Х изображен кривой линией, то корреляция называется
- 42. Метод наименьших квадратов Метод наименьших квадратов заключается в том, что сумма квадратов отклонений теоретических данных от
- 43. Для того чтобы найти погрешность данного метода необходимо вычислить Если предположили нелинейную корреляцию, то уравнение связи
- 44. Если нужно отобрать 20% изготовленных деталей, то отбирают каждую пятую. Детали изготавливаются на разных станках. Выборка
- 45. Задано распределение частот выборки. Определить объем, написать распределение относительных частот. n=3+10+12=20 Σ Wi=1 Σ ni=n
- 46. Пусть имеется нормальное распределение. Тогда нужно оценить, найти M(x) и σ. Для показательного распределения нужно оценить
- 47. Найти доверительный интервал с надежностью 0.9 неизвестного M(X) нормально распределенной СВ Х, если известны =20.9, σ=2,
- 48. По данным выборки, объема 50, найдена =-0.155, S=936. Найти доверительный интервал для неизвестной дисперсии, β=0.95. n=50,
- 49. При доверительной вероятности 90% найти доверительный интервал для D(x), если для выборки, объемом 5 выборочная D(x)=6.6,
- 50. Если Н0 состоит в предположении, что математическое ожидание М(Х) нормального распределения равно 10, то Н1 может
- 52. Скачать презентацию
Слайд 2Содержание
Введение
Генеральная совокупность и выборка
Способы отбора
Статистическое распределение выборки
Эмпирическая функция распределения
Статистические оценки параметров распределения
Проверка
Содержание
Введение
Генеральная совокупность и выборка
Способы отбора
Статистическое распределение выборки
Эмпирическая функция распределения
Статистические оценки параметров распределения
Проверка

Слайд 3Введение
Математическая статистика – наука, занимающаяся методами обработки экспериментальных данных, полученных в результате
Введение
Математическая статистика – наука, занимающаяся методами обработки экспериментальных данных, полученных в результате

Слайд 4Генеральная совокупность и выборка
Полный набор всех возможных значений дискретной СВ
называется
Генеральная совокупность и выборка
Полный набор всех возможных значений дискретной СВ
называется

Слайд 5Способы отбора
Отбор, не требующий расчленения:
простой, бесповторный
с повторениями
Отбор, при котором вся генеральная совокупность
Способы отбора
Отбор, не требующий расчленения:
простой, бесповторный
с повторениями
Отбор, при котором вся генеральная совокупность

Слайд 6Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем значение x1 встречалось
Статистическое распределение выборки
Пусть из генеральной совокупности извлечена выборка, причем значение x1 встречалось

Слайд 7Эмпирическая функция распределения
Эмпирической функцией распределения (функция
распределения выборки) называетсяF*(x), определяющую для
Эмпирическая функция распределения
Эмпирической функцией распределения (функция
распределения выборки) называетсяF*(x), определяющую для

Слайд 8Статистические оценки параметров распределения
Точечные оценки
Интервальные оценки
Точность и надежность
Доверительный интервал для мат.ожидания
Доверительный интервал
Статистические оценки параметров распределения
Точечные оценки
Интервальные оценки
Точность и надежность
Доверительный интервал для мат.ожидания
Доверительный интервал

Слайд 9Для того, чтобы статистические оценки давали хорошее приближение оценивающих параметров, они должны
Для того, чтобы статистические оценки давали хорошее приближение оценивающих параметров, они должны

Слайд 10Точечные оценки
Точечной называют оценку, определяющую одним числом.
Пусть требуется изучить количественный признак
Точечные оценки
Точечной называют оценку, определяющую одним числом.
Пусть требуется изучить количественный признак

Слайд 11Генеральная и выборочная средняя
Генеральная средняя – среднее арифметическое значений генеральной совокупности
–
Генеральная и выборочная средняя
Генеральная средняя – среднее арифметическое значений генеральной совокупности
–

Слайд 12Генеральная и выборочная дисперсии
Генеральной дисперсией называют среднее арифметическое квадратов
отклонений значений
Генеральная и выборочная дисперсии
Генеральной дисперсией называют среднее арифметическое квадратов
отклонений значений

Слайд 13Интервальные оценки
Интервальной оценкой называют оценку,
определяющуюся двумя концами интервала.
При выборке малого
Интервальные оценки
Интервальной оценкой называют оценку,
определяющуюся двумя концами интервала.
При выборке малого

Слайд 14Точность и надежность
Пусть найденная по данной выборке статистическая характеристика θ* служит оценкой
Точность и надежность
Пусть найденная по данной выборке статистическая характеристика θ* служит оценкой

Слайд 15Доверительный интервал для мат.ожидания
Рассмотрим нахождение доверительного интервала для M(X) нормально распределенной СВ,
Доверительный интервал для мат.ожидания
Рассмотрим нахождение доверительного интервала для M(X) нормально распределенной СВ,

Слайд 16Расчет доверительных интервалов при известной дисперсии
Будем рассматривать выборочную среднюю как случайную величину.
Расчет доверительных интервалов при известной дисперсии
Будем рассматривать выборочную среднюю как случайную величину.

Слайд 17Расчет доверительных интервалов при неизвестной дисперсии
Если D(x) неизвестна, а ее несмещенная оценка
Расчет доверительных интервалов при неизвестной дисперсии
Если D(x) неизвестна, а ее несмещенная оценка

Слайд 18Доверительный интервал для оценки дисперсии
Доверительный интервал строится на основании того, что величина
Доверительный интервал для оценки дисперсии
Доверительный интервал строится на основании того, что величина

Слайд 19Проверка статистических гипотез
Статистической гипотезой называют, гипотезу о видах неизвестного распределения или о
Проверка статистических гипотез
Статистической гипотезой называют, гипотезу о видах неизвестного распределения или о

Слайд 20Классификация гипотез
Статистические, нестатистические
Выдвинутая, конкурирующая.
Выдвинутую гипотезу называют нулевой (основной) и обозначают Н0. Конкурирующая
Классификация гипотез
Статистические, нестатистические
Выдвинутая, конкурирующая.
Выдвинутую гипотезу называют нулевой (основной) и обозначают Н0. Конкурирующая

Слайд 21Статистический критерий, статистическая область
Для проверки Н0, используют специально подобранную слу-чайную величину, точное
Статистический критерий, статистическая область
Для проверки Н0, используют специально подобранную слу-чайную величину, точное

Слайд 22Критической областью называют, совокупность значений критерия при которых Н0 отвергается.
Областью принятия гипотезы
Критической областью называют, совокупность значений критерия при которых Н0 отвергается.
Областью принятия гипотезы

Слайд 23Правостороннюю называют критическую область определяемую неравенством К>Ккр
Левостороннюю называют критическую область определяемую неравенством
Правостороннюю называют критическую область определяемую неравенством К>Ккр
Левостороннюю называют критическую область определяемую неравенством

Слайд 24Сравнение двух дисперсий
Рассмотрим гипотезу о параметрах нормального распределе-ния. Пусть имеется две серии
Сравнение двух дисперсий
Рассмотрим гипотезу о параметрах нормального распределе-ния. Пусть имеется две серии

Слайд 25Механизм проверки
По данным выборок значений nх и nу, вычисляют наблюдаемое значение критерия
Механизм проверки
По данным выборок значений nх и nу, вычисляют наблюдаемое значение критерия

Слайд 26Для проверки гипотезы, соответствие двух выборок принад-лежности к одной и той же
Для проверки гипотезы, соответствие двух выборок принад-лежности к одной и той же
Слайд 27Для того чтобы при заданном уровне значимости α =0.05 проверить нулевую гипотезу
Для того чтобы при заданном уровне значимости α =0.05 проверить нулевую гипотезу

Слайд 28Проверка гипотезы о равенстве средних при неизвестных дисперсиях
Постановка задач: пусть генеральные совокупности
Проверка гипотезы о равенстве средних при неизвестных дисперсиях
Постановка задач: пусть генеральные совокупности

Слайд 29Алгоритм проверки
1) Прежде чем сравнивать средние требуется проверить Н0: Dх=Dу
2) Если
Алгоритм проверки
1) Прежде чем сравнивать средние требуется проверить Н0: Dх=Dу
2) Если

Слайд 30Проверка гипотезы о законе распределения генеральной совокупности
Если закон распределения не известен, но
Проверка гипотезы о законе распределения генеральной совокупности
Если закон распределения не известен, но

Слайд 31Критерий Пирсона
Пусть по выборке объема n получены эмпирические частоты, т.е. мы имеем
Критерий Пирсона
Пусть по выборке объема n получены эмпирические частоты, т.е. мы имеем

Слайд 32Правила проверки
Для того, чтобы при заданном уровне значимости α проверить Н0: “генеральная
Правила проверки
Для того, чтобы при заданном уровне значимости α проверить Н0: “генеральная

Слайд 33Корреляционно-регрессионный анализ
Корреляционная зависимость
Корреляционный момент
Коррелированность и зависимость случайных величин
Выборочное корреляционное отношение
Простейшие случаи криволинейной
Корреляционно-регрессионный анализ
Корреляционная зависимость
Корреляционный момент
Коррелированность и зависимость случайных величин
Выборочное корреляционное отношение
Простейшие случаи криволинейной

Слайд 34Во многих задачах требуется установить или оценить зависимость изучаемо случайной величины Y
Во многих задачах требуется установить или оценить зависимость изучаемо случайной величины Y

Слайд 35Корреляционная зависимость
Предположим изучается связь между случайными величинами Х и Y. Пусть каждому
Корреляционная зависимость
Предположим изучается связь между случайными величинами Х и Y. Пусть каждому

Слайд 36Коэффициент корреляции.
Выборочным коэффициентом корреляции называется отношение разности между М(Х) произведения случайных величины
Коэффициент корреляции.
Выборочным коэффициентом корреляции называется отношение разности между М(Х) произведения случайных величины

Слайд 37Корреляционный момент
Корреляционным моментом μху случайных величин Х и Y,
называют математическое
Корреляционный момент
Корреляционным моментом μху случайных величин Х и Y,
называют математическое

Слайд 38Коррелированность и зависимость случайных величин
Две случайных величин называются коррелированными, если их корреляционный
Коррелированность и зависимость случайных величин
Две случайных величин называются коррелированными, если их корреляционный

Слайд 39Выборочное корреляционное отношение
Для оценки тесноты нелинейной корреляционной связи служат такие характеристики как:
Выборочное корреляционное отношение
Для оценки тесноты нелинейной корреляционной связи служат такие характеристики как:

Слайд 40Достоинства корреляционного отношения.
Корреляционное отношение служит мерой тесноты связи любой, в том числе
Достоинства корреляционного отношения.
Корреляционное отношение служит мерой тесноты связи любой, в том числе

Слайд 41Простейшие случаи криволинейной корреляции
Если график регрессии Y на Х изображен кривой линией,
Простейшие случаи криволинейной корреляции
Если график регрессии Y на Х изображен кривой линией,

Слайд 42Метод наименьших квадратов
Метод наименьших квадратов заключается в том, что сумма квадратов отклонений
Метод наименьших квадратов
Метод наименьших квадратов заключается в том, что сумма квадратов отклонений

Слайд 43Для того чтобы найти погрешность данного метода необходимо вычислить
Если предположили нелинейную
Для того чтобы найти погрешность данного метода необходимо вычислить
Если предположили нелинейную

Слайд 44Если нужно отобрать 20% изготовленных деталей, то отбирают каждую пятую.
Детали изготавливаются на
Если нужно отобрать 20% изготовленных деталей, то отбирают каждую пятую.
Детали изготавливаются на

Слайд 45Задано распределение частот выборки.
Определить объем, написать распределение относительных частот.
n=3+10+12=20
Σ Wi=1
Σ ni=n
Задано распределение частот выборки.
Определить объем, написать распределение относительных частот.
n=3+10+12=20
Σ Wi=1
Σ ni=n

Слайд 46Пусть имеется нормальное распределение. Тогда нужно оценить, найти M(x) и σ. Для
Пусть имеется нормальное распределение. Тогда нужно оценить, найти M(x) и σ. Для

Слайд 47Найти доверительный интервал с надежностью 0.9 неизвестного M(X) нормально распределенной СВ Х,
Найти доверительный интервал с надежностью 0.9 неизвестного M(X) нормально распределенной СВ Х,

Слайд 48По данным выборки, объема 50, найдена =-0.155, S=936. Найти доверительный интервал для
По данным выборки, объема 50, найдена =-0.155, S=936. Найти доверительный интервал для

Слайд 49При доверительной вероятности 90% найти доверительный интервал для D(x), если для выборки,
При доверительной вероятности 90% найти доверительный интервал для D(x), если для выборки,

Слайд 50Если Н0 состоит в предположении, что математическое ожидание М(Х) нормального распределения равно
Если Н0 состоит в предположении, что математическое ожидание М(Х) нормального распределения равно

 Sozdanie_zaprosov_na_sozdanie_tablitsy
Sozdanie_zaprosov_na_sozdanie_tablitsy Правила перевозок железнодорожным транспортом подкарантинных грузов
Правила перевозок железнодорожным транспортом подкарантинных грузов PR в индустрии моды
PR в индустрии моды BIcons Group. Услуги по направлениям аудита, налогового консалтинга, юридической защиты прав
BIcons Group. Услуги по направлениям аудита, налогового консалтинга, юридической защиты прав Типология религий. Мировые религии
Типология религий. Мировые религии Love Story by Erich Segal
Love Story by Erich Segal  Технологія обрізування декоративних чагарників
Технологія обрізування декоративних чагарників Блокнот
Блокнот Движение воды в океане. Волны
Движение воды в океане. Волны Урок 08 Магнітні властивості речовин. Гіпотеза Ампера (1)
Урок 08 Магнітні властивості речовин. Гіпотеза Ампера (1) Психолингвистика, как наука о речевой деятельности
Психолингвистика, как наука о речевой деятельности 3MFM - 3 (1)
3MFM - 3 (1) Новинки в ассортименте фасадной плитки Hauberk-2021
Новинки в ассортименте фасадной плитки Hauberk-2021 Выбираем 3CX Phone System Ключевые возможности и преимущества
Выбираем 3CX Phone System Ключевые возможности и преимущества Соборы Московского Кремля
Соборы Московского Кремля Турбины, насосы, насосо-турбины, обратимые гидромашины: виды, устройство, принципы работы
Турбины, насосы, насосо-турбины, обратимые гидромашины: виды, устройство, принципы работы Кремль – исторический центр Москвы
Кремль – исторический центр Москвы Норвегия
Норвегия Презентация на тему Хоть и маленькие мы, но достаточно умны
Презентация на тему Хоть и маленькие мы, но достаточно умны Право и мораль
Право и мораль Энциклопедия чувств
Энциклопедия чувств Эмоциональное выгорание
Эмоциональное выгорание Александр Бречалов
Александр Бречалов 04.10
04.10 Содержание, принципы и методы обучения черчению
Содержание, принципы и методы обучения черчению Таможенные сборы. Тема 2
Таможенные сборы. Тема 2 Табличные цифровые регуляторы САР
Табличные цифровые регуляторы САР Михаил Евграфович Салтыков-Щедрин. Сказки
Михаил Евграфович Салтыков-Щедрин. Сказки