- Методы интеллектуального анализа данных и некоторые их приложения

Содержание
- 2. Эволюция технологий хранения и обработки данных … — 1960-е: Файлы и файловые архивы 1960-е: Первые СУБД,
- 3. Актуальность и необходимость интеллектуального анализа данных Проблема больших объемов («Data explosion»): Средства автоматического сбора данных, повсеместное
- 4. Интеллектуальный анализ данных (Data Mining) Системы интеллектуального анализа данных (ИАД) – класс программных систем поддержки принятия
- 5. Процесс ИАД (1) Анализ предметной области: выявление и формулировка необходимых априорных знаний о предметной области, целей
- 6. Процесс ИАД (2) Выбор (или разработка) алгоритма анализа: определение ограничений и требований к алгоритму по точности,
- 7. Программные системы ИАД Типовая архитектура: Классификация систем ИАД: По типу анализируемых данных По типу решаемых задач
- 8. Типы исходных данных (1) Транзакционные базы данных и репозитории «событий» Объекты анализа – «события» различной структуры
- 9. Типы исходных данных (2) Географические и пространственные данные Привязка к пространственным координатам, учет географии объектов при
- 10. Задачи ИАД = типы выявляемых закономерностей Классификация («Обучение с учителем») Отнесение объектов к заранее определенным категориям
- 11. Методы анализа Data Mining Технологии БД Статистика и теор. вер. Другие дисциплины Теория информации Машинное обучение
- 12. Область применения систем ИАД Системы ИАД «общего назначения» По сути включают framework, библиотеку алгоритмов анализа и
- 13. Отличия ИАД систем (1) Наличие «обучения» база знаний формируются на основе анализируемых данных, а не экспертных
- 14. Отличия ИАД систем (2) Наличие большого объема данных сложной структуры зачастую скорость работы алгоритмов в ИАД
- 15. Отличия ИАД систем (3) Наличие человека - аналитика как оконечного потребителя результатов работы ИАД системы в
- 16. ИАД в проектах лаборатории «Технологий Программирования» Компьютерная безопасность Обнаружение внешних и внутренних вторжений Моделирование и анализ
- 17. ИАД в компьютерной безопасности Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных Вторжение – действия
- 18. Традиционные средства выявления вторжений Основные концепции: Используют базах сигнатур известных атак Источники информации: системные журналы и
- 19. Методы ИАД в задачах выявления вторжений Основное предположение: активность пользователей и программ можно полностью отследить и
- 20. Обнаружение нарушений Особенности: Строится обобщенная модель атаки Основано на методах классификации Атакой считаются события или последовательности
- 21. Обнаружение аномалий Особенности : Строится обобщенная модель нормальной активности пользователей или программ (профайл) Основано на методах
- 22. Разработанные и реализованные алгоритмы Обнаружение аномалий: Оценка степени «типичности» событий и их последовательностей - нечеткая кластеризация
- 23. Система мониторинга и анализа поведения пользователей Функциональность: Сбор и консолидация данных о работе пользователей Статистический и
- 24. Архитектура системы мониторинга
- 25. Особенности реализации и результаты Подсистема консолидации исходных данных: Мульти-агентный подход Нет ограничений на источники собираемых данных
- 26. Электронный документооборот Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия Система анализа и много-темной классификации
- 27. Алгоритм классификации (на SVM): векторная форма представления письма высокая точность эффективность по скорости персональная модель классификации
- 28. Архитектура системы фильтрации Особенности реализации: Учет ресурсоемкости алгоритмов на этапе обучения Распределение и баланс нагрузки Классификация
- 29. Результаты экспериментальной реализации и апробации Почтовый сервер лаборатории «Технологий программирования» эксплуатация с весны 2004 около 1
- 30. Цели создания систем анализа и фильтрации Интернет-трафика Блокирование доступа к нелегальной (экстремистской, антисоциальной, террористической и т.п.)
- 31. Существующие системы фильтрации Традиционный подход («сигнатурные» методы): Использование при анализе Интернет-трафика специализированных, формируемых экспертами, баз знаний,
- 32. Анализ и фильтрация Интернет- трафика на основе методов ИАД Основная идея: Классификация потока гипертекстовой информации в
- 33. Преимущества Классификация в реальном времени статических и динамических интернет ресурсов; Точность выше, чем у «сигнатурных» методов;
- 34. Архитектура системы
- 35. Основные результаты Реализация системы: Формализованы требования и сценарии взаимодействия Спроектированы и реализованы базовые компоненты, их функционал,
- 36. Интеллектуальная система анализа и мониторинга электронного документооборота организации Драйвер ФС: определяет с какими файлами работал пользователь;
- 37. Модель аннотирования Кластер документов – набор «схожих» документов; Каждый документ кластера разбивается на фрагменты текста; Каждый
- 38. Алгоритмы поиска ключевых характеристик Латентно-семантический анализ (LSA - Latent Semantic Analysis): основан на использовании разложения исходной
- 39. Аннотирование новых документов Для каждого документа определяется ближайший кластер и соответствующая ему модель аннотирования; Документ разбивается
- 40. Архитектура ИАД системы анализа поведения технологических процессов Особенности реализации: выявление аномалий в характеристик ТП функционирование в
- 41. Выявление нештатных ситуаций построение модели поведения ТП (на этапе обучения) оценка отклонения текущего состояния ТП от
- 42. Анализ и прогнозирование качества ТП Какие параметры производственного процесса влияют на качество продукции? Quality = F(X1,
- 43. Результат Разработаны алгоритмы: на основе нечетких деревьев решений с поддержкой эволюционных методов оптимизации нечетких переменных и
- 44. Ситуационный центр Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной области, на основе
- 45. Место ИАД в процессе поддержки принятия решений в СЦ ЛПР Аналитик Оператор Принятие решениий Представление результатов
- 46. Расчет и хранение индикаторов Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
- 47. Выявление аномалий в значениях индикаторов
- 48. Определение тенденций и прогнозирование значений индикаторов
- 49. Текущие результаты Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа ситуаций: Просмотр ситуации
- 51. Скачать презентацию
Слайд 2Эволюция технологий хранения и обработки данных
… — 1960-е:
Файлы и файловые архивы
1960-е:
Первые
Эволюция технологий хранения и обработки данных
… — 1960-е:
Файлы и файловые архивы
1960-е:
Первые

Слайд 3Актуальность и необходимость интеллектуального анализа данных
Проблема больших объемов («Data explosion»):
Средства
Актуальность и необходимость интеллектуального анализа данных
Проблема больших объемов («Data explosion»):
Средства

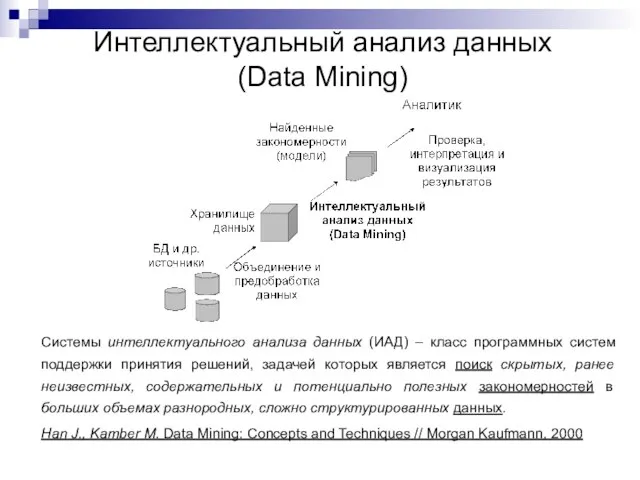
Слайд 4Интеллектуальный анализ данных
(Data Mining)
Системы интеллектуального анализа данных (ИАД) – класс программных систем
Интеллектуальный анализ данных
(Data Mining)
Системы интеллектуального анализа данных (ИАД) – класс программных систем
Слайд 5Процесс ИАД (1)
Анализ предметной области:
выявление и формулировка необходимых априорных знаний о предметной
Процесс ИАД (1)
Анализ предметной области:
выявление и формулировка необходимых априорных знаний о предметной

Слайд 6Процесс ИАД (2)
Выбор (или разработка) алгоритма анализа:
определение ограничений и требований к алгоритму
Процесс ИАД (2)
Выбор (или разработка) алгоритма анализа:
определение ограничений и требований к алгоритму

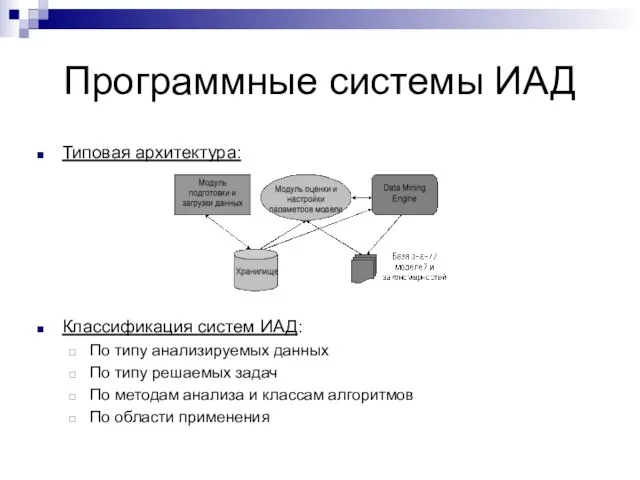
Слайд 7Программные системы ИАД
Типовая архитектура:
Классификация систем ИАД:
По типу анализируемых данных
По типу решаемых задач
По
Программные системы ИАД
Типовая архитектура:
Классификация систем ИАД:
По типу анализируемых данных
По типу решаемых задач
По
Слайд 8Типы исходных данных (1)
Транзакционные базы данных и репозитории «событий»
Объекты анализа – «события»
Типы исходных данных (1)
Транзакционные базы данных и репозитории «событий»
Объекты анализа – «события»

Слайд 9Типы исходных данных (2)
Географические и пространственные данные
Привязка к пространственным координатам, учет географии
Типы исходных данных (2)
Географические и пространственные данные
Привязка к пространственным координатам, учет географии

Слайд 10Задачи ИАД = типы выявляемых закономерностей
Классификация («Обучение с учителем»)
Отнесение объектов к заранее
Задачи ИАД = типы выявляемых закономерностей
Классификация («Обучение с учителем»)
Отнесение объектов к заранее

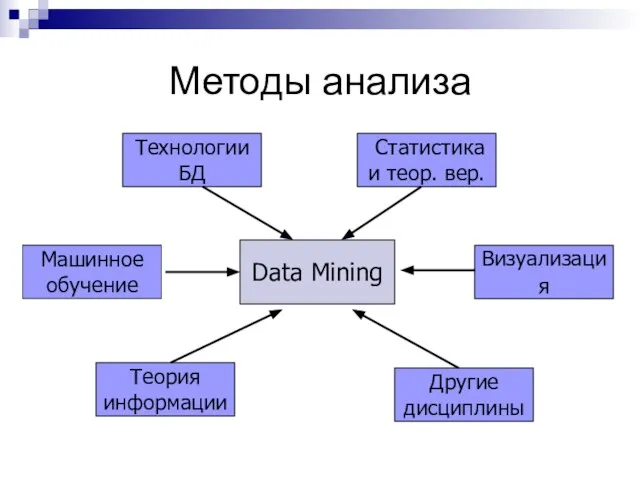
Слайд 11Методы анализа
Data Mining
Технологии
БД
Статистика
и теор. вер.
Другие
дисциплины
Теория
информации
Машинное
обучение
Визуализация
Методы анализа
Data Mining
Технологии
БД
Статистика
и теор. вер.
Другие
дисциплины
Теория
информации
Машинное
обучение
Визуализация
Слайд 12Область применения систем ИАД
Системы ИАД «общего назначения»
По сути включают framework, библиотеку алгоритмов
Область применения систем ИАД
Системы ИАД «общего назначения»
По сути включают framework, библиотеку алгоритмов

Слайд 13Отличия ИАД систем (1)
Наличие «обучения»
база знаний формируются на основе анализируемых данных, а
Отличия ИАД систем (1)
Наличие «обучения»
база знаний формируются на основе анализируемых данных, а

Слайд 14Отличия ИАД систем (2)
Наличие большого объема данных сложной структуры
зачастую скорость работы алгоритмов
Отличия ИАД систем (2)
Наличие большого объема данных сложной структуры
зачастую скорость работы алгоритмов

Слайд 15Отличия ИАД систем (3)
Наличие человека - аналитика как оконечного потребителя результатов работы
Отличия ИАД систем (3)
Наличие человека - аналитика как оконечного потребителя результатов работы

Слайд 16ИАД в проектах лаборатории «Технологий Программирования»
Компьютерная безопасность
Обнаружение внешних и внутренних вторжений
Моделирование
ИАД в проектах лаборатории «Технологий Программирования»
Компьютерная безопасность
Обнаружение внешних и внутренних вторжений
Моделирование

Слайд 17ИАД в компьютерной безопасности
Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных
Вторжение
ИАД в компьютерной безопасности
Цели компьютерной безопасности: обеспечение конфиденциальности, целостности и доступности данных
Вторжение

Слайд 18Традиционные средства выявления вторжений
Основные концепции:
Используют базах сигнатур известных атак
Источники информации:
Традиционные средства выявления вторжений
Основные концепции:
Используют базах сигнатур известных атак
Источники информации:

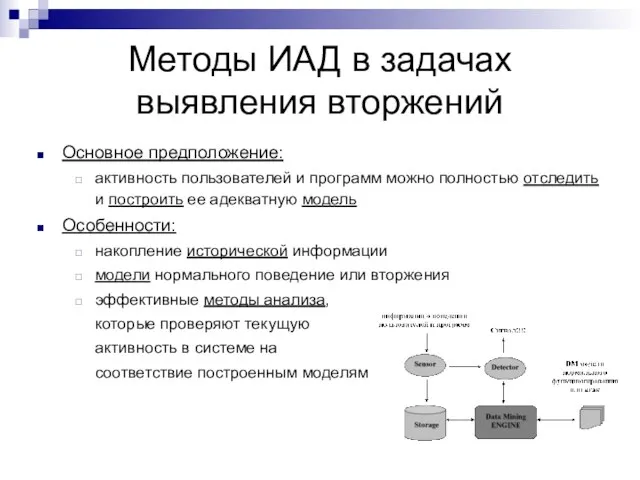
Слайд 19Методы ИАД в задачах выявления вторжений
Основное предположение:
активность пользователей и программ можно
Методы ИАД в задачах выявления вторжений
Основное предположение:
активность пользователей и программ можно
Слайд 20Обнаружение нарушений
Особенности:
Строится обобщенная модель атаки
Основано на методах классификации
Атакой считаются события или
Обнаружение нарушений
Особенности:
Строится обобщенная модель атаки
Основано на методах классификации
Атакой считаются события или

Слайд 21Обнаружение аномалий
Особенности :
Строится обобщенная модель нормальной активности пользователей или программ (профайл)
Основано на
Обнаружение аномалий
Особенности :
Строится обобщенная модель нормальной активности пользователей или программ (профайл)
Основано на

Слайд 22Разработанные и реализованные алгоритмы
Обнаружение аномалий:
Оценка степени «типичности» событий и их последовательностей
Разработанные и реализованные алгоритмы
Обнаружение аномалий:
Оценка степени «типичности» событий и их последовательностей

Слайд 23Система мониторинга и анализа поведения пользователей
Функциональность:
Сбор и консолидация данных о работе пользователей
Статистический
Система мониторинга и анализа поведения пользователей
Функциональность:
Сбор и консолидация данных о работе пользователей
Статистический

Слайд 24Архитектура системы мониторинга
Архитектура системы мониторинга
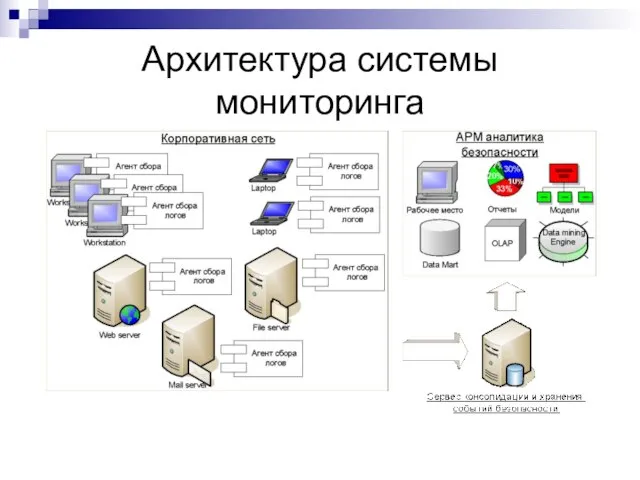
Слайд 25Особенности реализации и результаты
Подсистема консолидации исходных данных:
Мульти-агентный подход
Нет ограничений на источники собираемых
Особенности реализации и результаты
Подсистема консолидации исходных данных:
Мульти-агентный подход
Нет ограничений на источники собираемых

Слайд 26Электронный документооборот
Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия
Система анализа и
Электронный документооборот
Интеллектуальная система анализа и фильтрации электронной почты масштаба предприятия
Система анализа и

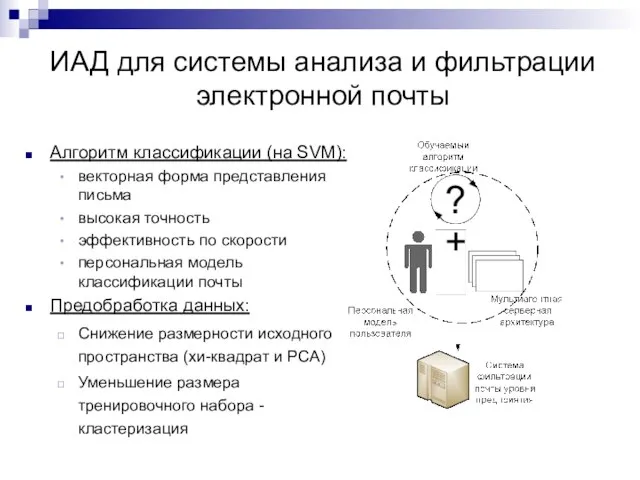
Слайд 27Алгоритм классификации (на SVM):
векторная форма представления письма
высокая точность
эффективность по скорости
персональная модель классификации
Алгоритм классификации (на SVM):
векторная форма представления письма
высокая точность
эффективность по скорости
персональная модель классификации
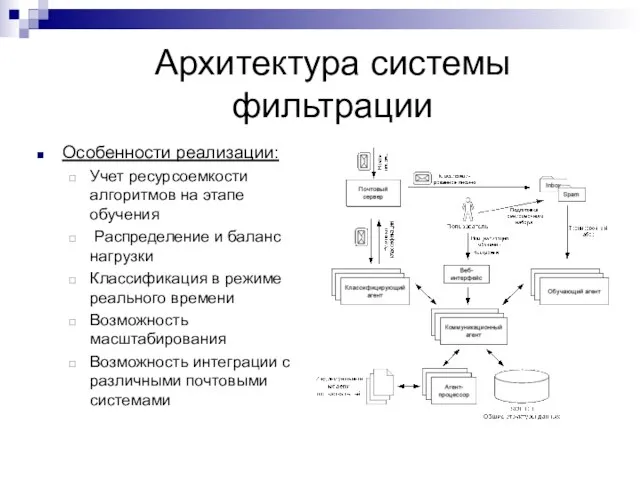
Слайд 28Архитектура системы фильтрации
Особенности реализации:
Учет ресурсоемкости алгоритмов на этапе обучения
Распределение и баланс
Архитектура системы фильтрации
Особенности реализации:
Учет ресурсоемкости алгоритмов на этапе обучения
Распределение и баланс
Слайд 29Результаты экспериментальной реализации и апробации
Почтовый сервер лаборатории «Технологий программирования»
эксплуатация с весны 2004
около
Результаты экспериментальной реализации и апробации
Почтовый сервер лаборатории «Технологий программирования»
эксплуатация с весны 2004
около

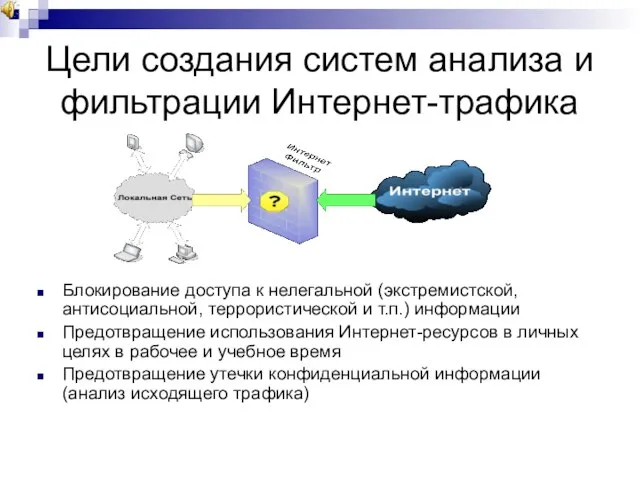
Слайд 30Цели создания систем анализа и фильтрации Интернет-трафика
Блокирование доступа к нелегальной (экстремистской, антисоциальной,
Цели создания систем анализа и фильтрации Интернет-трафика
Блокирование доступа к нелегальной (экстремистской, антисоциальной,
Слайд 31Существующие системы фильтрации
Традиционный подход («сигнатурные» методы):
Использование при анализе Интернет-трафика специализированных, формируемых экспертами,
Существующие системы фильтрации
Традиционный подход («сигнатурные» методы):
Использование при анализе Интернет-трафика специализированных, формируемых экспертами,

Слайд 32Анализ и фильтрация Интернет- трафика на основе методов ИАД
Основная идея:
Классификация потока гипертекстовой
Анализ и фильтрация Интернет- трафика на основе методов ИАД
Основная идея:
Классификация потока гипертекстовой

Слайд 33Преимущества
Классификация в реальном времени статических и динамических интернет ресурсов;
Точность выше, чем у
Преимущества
Классификация в реальном времени статических и динамических интернет ресурсов;
Точность выше, чем у

Слайд 34Архитектура системы
Архитектура системы
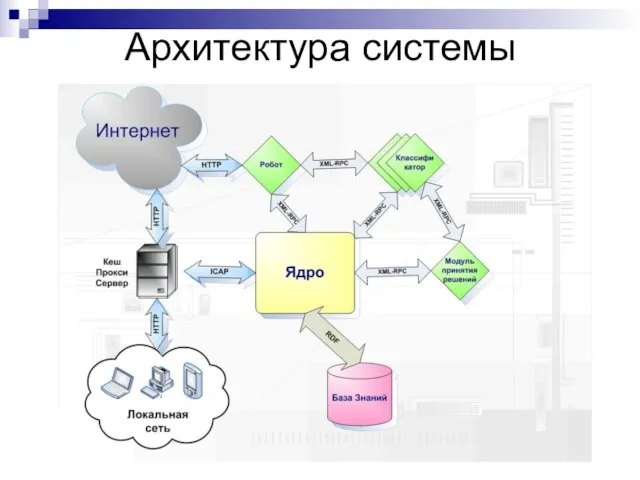
Слайд 35Основные результаты
Реализация системы:
Формализованы требования и сценарии взаимодействия
Спроектированы и реализованы базовые компоненты,
Основные результаты
Реализация системы:
Формализованы требования и сценарии взаимодействия
Спроектированы и реализованы базовые компоненты,

Слайд 36Интеллектуальная система анализа и мониторинга электронного документооборота организации
Драйвер ФС: определяет с какими
Интеллектуальная система анализа и мониторинга электронного документооборота организации
Драйвер ФС: определяет с какими
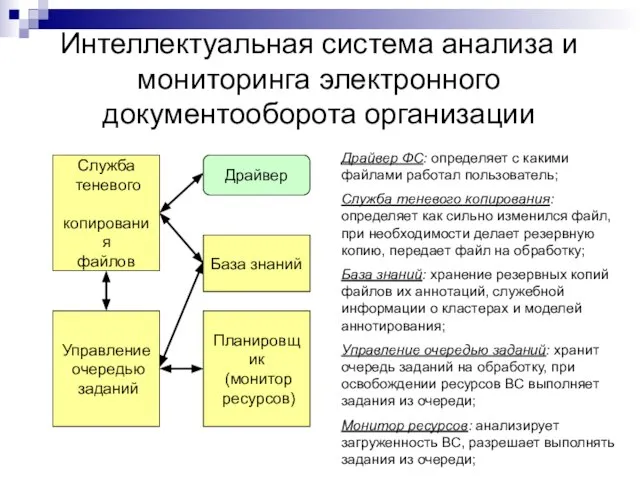
Слайд 37Модель аннотирования
Кластер документов – набор «схожих» документов;
Каждый документ кластера разбивается
Модель аннотирования
Кластер документов – набор «схожих» документов;
Каждый документ кластера разбивается

Слайд 38Алгоритмы поиска ключевых характеристик
Латентно-семантический анализ (LSA - Latent Semantic Analysis): основан на
Алгоритмы поиска ключевых характеристик
Латентно-семантический анализ (LSA - Latent Semantic Analysis): основан на

Слайд 39Аннотирование новых документов
Для каждого документа определяется ближайший кластер и соответствующая ему
Аннотирование новых документов
Для каждого документа определяется ближайший кластер и соответствующая ему

Слайд 40Архитектура ИАД системы анализа поведения технологических процессов
Особенности реализации:
выявление аномалий в характеристик ТП
функционирование
Архитектура ИАД системы анализа поведения технологических процессов
Особенности реализации:
выявление аномалий в характеристик ТП
функционирование
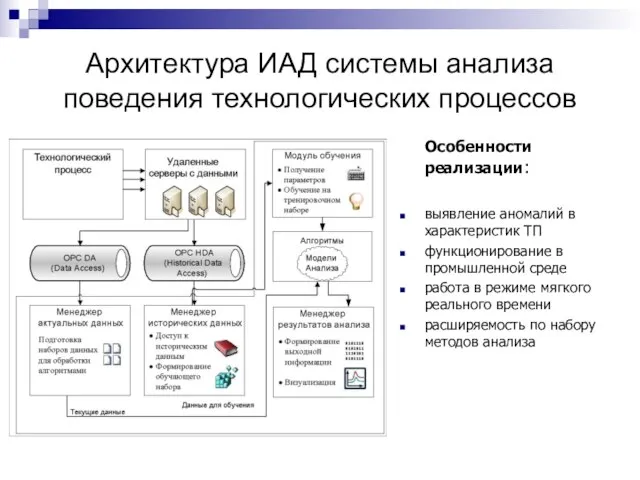
Слайд 41Выявление нештатных ситуаций
построение модели поведения ТП (на этапе обучения)
оценка отклонения текущего состояния
Выявление нештатных ситуаций
построение модели поведения ТП (на этапе обучения)
оценка отклонения текущего состояния
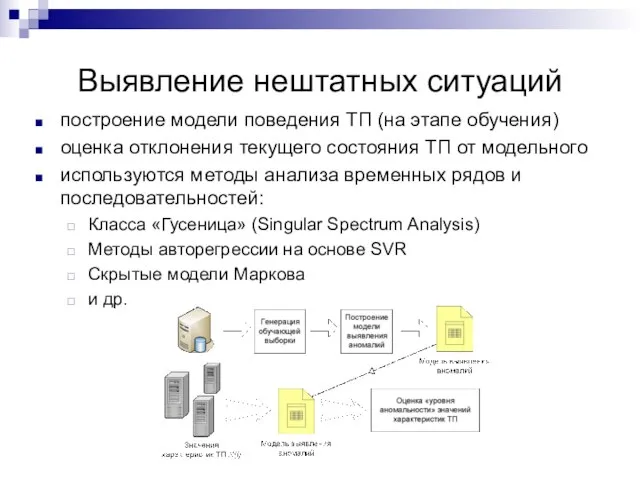
Слайд 42Анализ и прогнозирование качества ТП
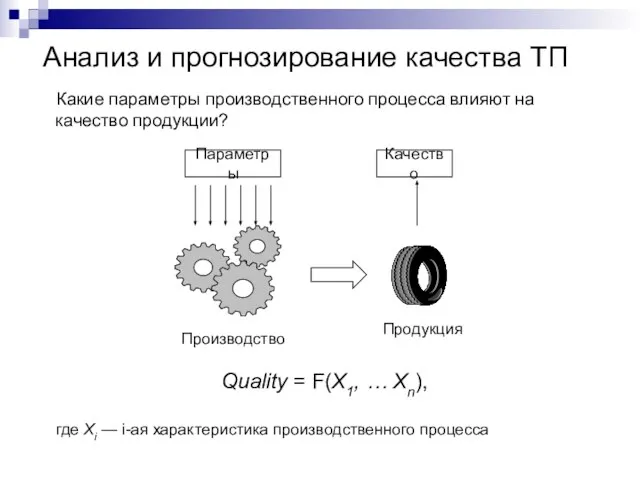
Какие параметры производственного процесса влияют на качество продукции?
Quality
Анализ и прогнозирование качества ТП
Какие параметры производственного процесса влияют на качество продукции?
Quality
Слайд 43Результат
Разработаны алгоритмы:
на основе нечетких деревьев решений
с поддержкой эволюционных методов оптимизации
Результат
Разработаны алгоритмы:
на основе нечетких деревьев решений
с поддержкой эволюционных методов оптимизации

Слайд 44Ситуационный центр
Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной
Ситуационный центр
Основная задача СЦ — строить наглядные образы ситуаций, возникающих в предметной

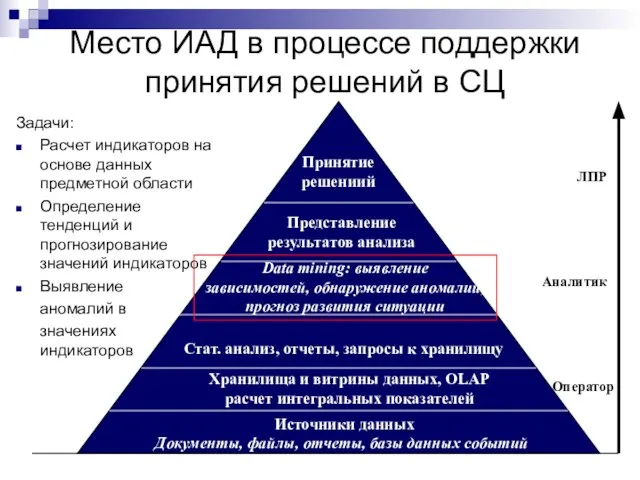
Слайд 45Место ИАД в процессе поддержки принятия решений в СЦ
ЛПР
Аналитик
Оператор
Принятие
решениий
Представление
результатов анализа
Data mining:
Место ИАД в процессе поддержки принятия решений в СЦ
ЛПР
Аналитик
Оператор
Принятие
решениий
Представление
результатов анализа
Data mining:
Слайд 46Расчет и хранение индикаторов
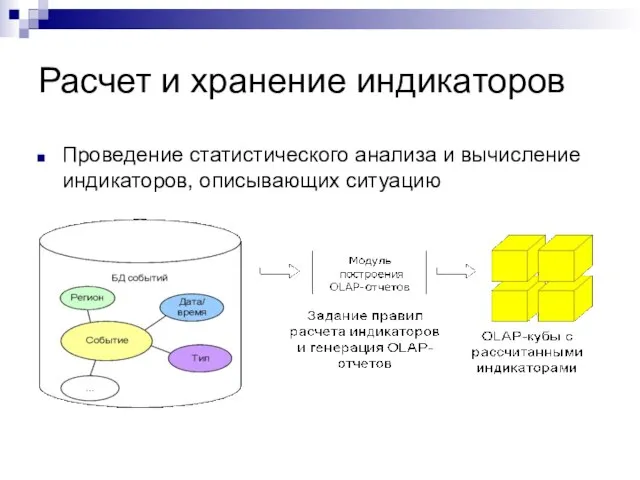
Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
Расчет и хранение индикаторов
Проведение статистического анализа и вычисление индикаторов, описывающих ситуацию
Слайд 47Выявление аномалий в значениях индикаторов
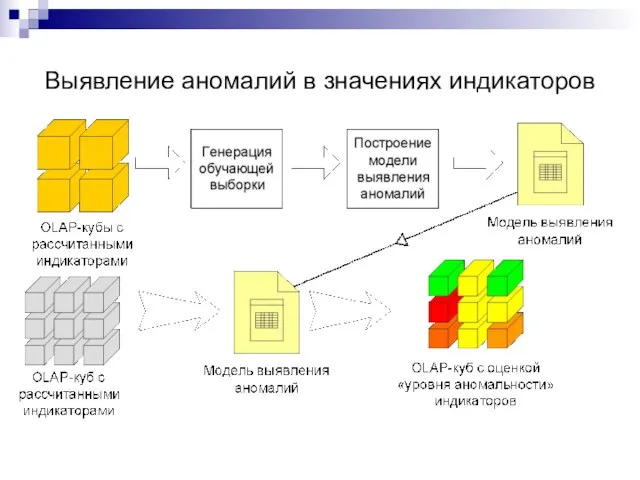
Выявление аномалий в значениях индикаторов
Слайд 48Определение тенденций и прогнозирование значений индикаторов
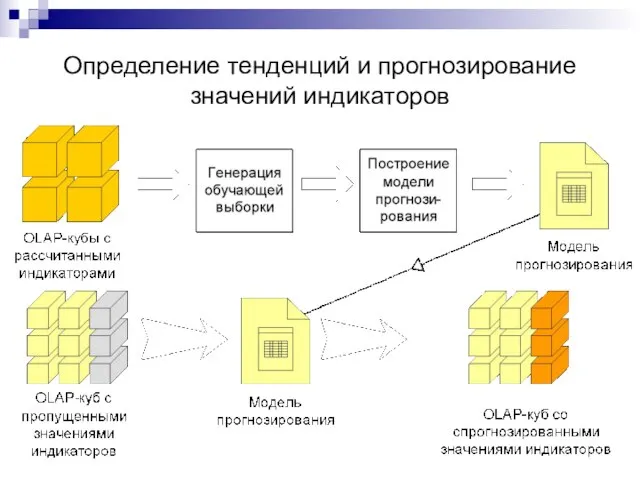
Определение тенденций и прогнозирование значений индикаторов
Слайд 49Текущие результаты
Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа
Текущие результаты
Проектирование и создание рабочего места аналитика ситуационного центра мониторинга и анализа

 Использование ИКТ в образовательном процессе как способ оптимизации деятельности учителя
Использование ИКТ в образовательном процессе как способ оптимизации деятельности учителя Психология зависимого поведения
Психология зависимого поведения ПРЕЗЕНТАЦИЯ МОИХ РАБОТ«ВРЕМЕНА ГОДА»
ПРЕЗЕНТАЦИЯ МОИХ РАБОТ«ВРЕМЕНА ГОДА» Рак почки. Эпидемиология, классификация, этиология, патогенез, клиническая картина
Рак почки. Эпидемиология, классификация, этиология, патогенез, клиническая картина Dmitry Sergeyevich Likhachov
Dmitry Sergeyevich Likhachov Вопрос о правде в драме М.Горького «На дне».
Вопрос о правде в драме М.Горького «На дне». Информационно-справочная система Предприятие средств диспетчерского и технологического управления РУП Гродноэнерго
Информационно-справочная система Предприятие средств диспетчерского и технологического управления РУП Гродноэнерго Презентация на тему Албания
Презентация на тему Албания  Мониторинг и оценкав деятельности НКО
Мониторинг и оценкав деятельности НКО Научно-методические основы корректировочного курса по русскому языку как неродному(глагольное предложное управление в азербай
Научно-методические основы корректировочного курса по русскому языку как неродному(глагольное предложное управление в азербай Педагогический meet-up Начать легко
Педагогический meet-up Начать легко Наше Сердце.
Наше Сердце. Презентация на тему ОЛИМПИАДА 2014 г. СОЧИ
Презентация на тему ОЛИМПИАДА 2014 г. СОЧИ  Соединение деталей шурупами
Соединение деталей шурупами Подготовка документов для создания организации
Подготовка документов для создания организации Фундаментальные и прикладные вопросы нейробиологии
Фундаментальные и прикладные вопросы нейробиологии Литература Древнего Египта
Литература Древнего Египта ТЕХНИЧЕСКОЕ ЗАДАНИЕ
ТЕХНИЧЕСКОЕ ЗАДАНИЕ Презентация на тему Жизненный цикл клетки. Митоз. Амитоз
Презентация на тему Жизненный цикл клетки. Митоз. Амитоз Мир художественной культуры эпохи Возрождения
Мир художественной культуры эпохи Возрождения Сервис 1С-Товары
Сервис 1С-Товары House
House Этиология и распространенность наркологических заболеваний
Этиология и распространенность наркологических заболеваний Ноябрь 18 - соок-ирей кырган-ачавыстыӊ төрүттүнген хүнү болур, уруглар
Ноябрь 18 - соок-ирей кырган-ачавыстыӊ төрүттүнген хүнү болур, уруглар Экипаж. Отечественное кино
Экипаж. Отечественное кино Л.С. Выготский о законах личностного развития
Л.С. Выготский о законах личностного развития Find 1 word for 3 pictures
Find 1 word for 3 pictures 01.09.20121 3 «ПОСЛЕДНИЙ ДЕНЬ ПЕРЕД РОЖДЕСТВОМ ПРОШЁЛ.ЗИМНЯЯ, ЯСНАЯ НОЧЬ НАСТУПИЛА. ГЛЯНУЛИ ЗВЁЗДЫ.»
01.09.20121 3 «ПОСЛЕДНИЙ ДЕНЬ ПЕРЕД РОЖДЕСТВОМ ПРОШЁЛ.ЗИМНЯЯ, ЯСНАЯ НОЧЬ НАСТУПИЛА. ГЛЯНУЛИ ЗВЁЗДЫ.»