- Методы «раскопки данных» — Data Mining

Содержание
- 2. Медицинские данные Результаты медико-биологических исследований – большое количество данных различного характера Результаты лабораторных исследований; Социально-паспортные и
- 3. Анализ медицинских данных Статистические методы Методы, основанные на знаниях «Раскопка данных» (Data Mining) Экспертные системы Data
- 4. Статистические методы
- 5. Согласованность с нормальным законом распределения
- 6. Корреляционный анализ R-коэффициент корреляции Spearman Pearson Kendall
- 7. Гармонизированный анализ
- 8. Нестатистические методы: «раскопка данных» Обучающая выборка
- 9. Кластеризация Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Цель кластеризации -
- 10. Разделить образцы на k групп (классов) автоматически, без информации о настоящем классе образца Выбрать начальное положение
- 11. Классификация
- 12. Задача классификации Цель классификации: необходимо отнести имеющиеся статические образцы (данные медосмотра) к определенному классу. Методы: Классификатор
- 13. Классификация 25 пациентов, перенесших ишемический инсульт; 44 показателя Факторы риска ишемическая болезнь сердца артериальная гипертензия сахарный
- 14. Классификатор Байеса Классификатор Байеса—вероятностный классификатор, основанный на применении Теоремы Байеса со строгими (наивными) предположениями о независимости.
- 15. Нейронные сети При обучении сети предлагаются различные образцы образов с указанием того, к какому классу они
- 16. Дерево решений Деревья принятия решений- это дерево, на ребрах которого записаны атрибуты, от которых зависит целевая
- 17. Метод k ближайших соседей Метод k ближайших соседей (англ. k-nearest neighbor algorithm, kNN) - метод автоматической
- 18. Сравнение классификации и кластеризации
- 19. Бесплатный Data Miner: RapidMiner
- 20. Результат запуска: построенный классификатор
- 21. Экспертные системы База знаний (правил) Механизм вывода База данных (фактов)
- 22. Интеллектуальная медицинская информационная система
- 23. Изображение, полученное с микровизора Показатель степени МКБ Число кристаллов в пограничной зоне Диагностика мочекаменной болезни
- 25. Скачать презентацию
Слайд 2Медицинские данные
Результаты медико-биологических исследований – большое количество данных различного характера
Результаты лабораторных исследований;
Социально-паспортные
Медицинские данные
Результаты медико-биологических исследований – большое количество данных различного характера
Результаты лабораторных исследований;
Социально-паспортные

Слайд 3Анализ медицинских данных
Статистические методы
Методы, основанные на знаниях
«Раскопка данных» (Data Mining)
Экспертные системы
Data Mining
Анализ медицинских данных
Статистические методы
Методы, основанные на знаниях
«Раскопка данных» (Data Mining)
Экспертные системы
Data Mining

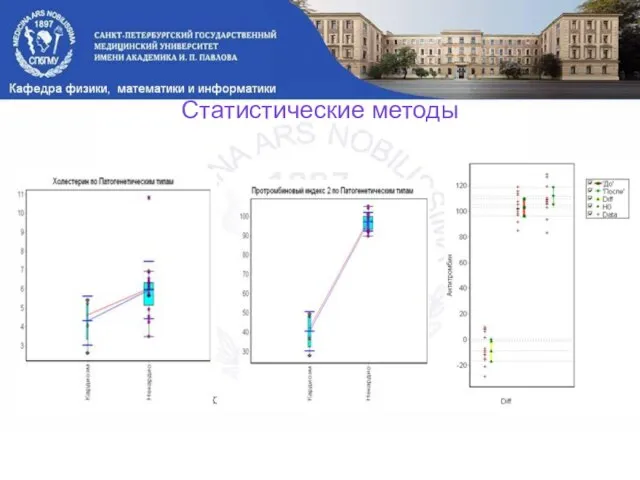
Слайд 4Статистические методы
Статистические методы
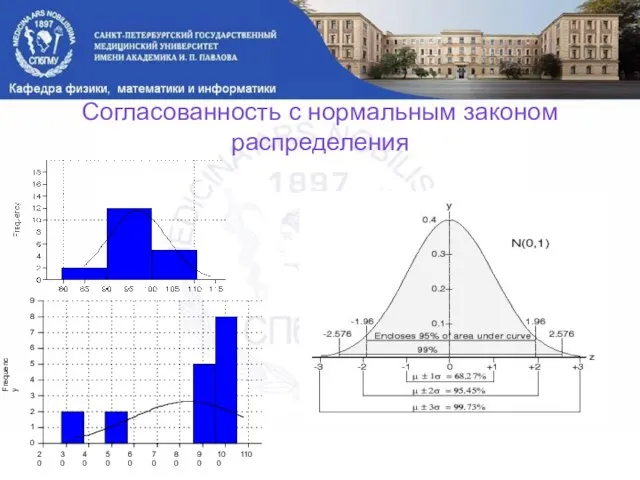
Слайд 5Согласованность с нормальным законом распределения
Согласованность с нормальным законом распределения
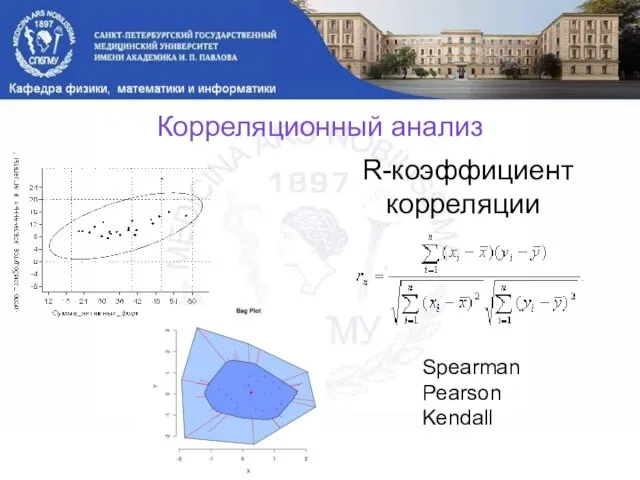
Слайд 6Корреляционный анализ
R-коэффициент корреляции
Spearman
Pearson
Kendall
Корреляционный анализ
R-коэффициент корреляции
Spearman
Pearson
Kendall
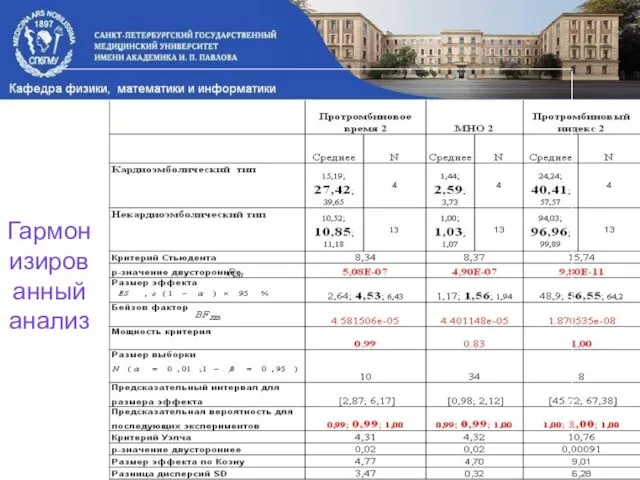
Слайд 7Гармонизированный анализ
Гармонизированный анализ
Слайд 8Нестатистические методы: «раскопка данных»
Обучающая выборка
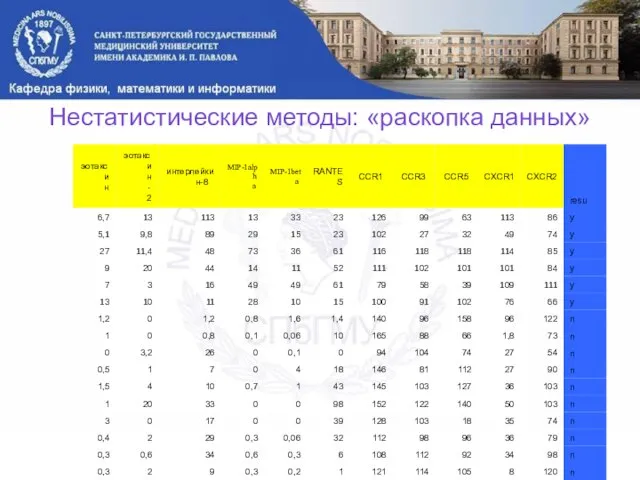
Нестатистические методы: «раскопка данных»
Обучающая выборка
Слайд 9Кластеризация
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы).
Цель кластеризации - поиск
Кластеризация
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы).
Цель кластеризации - поиск

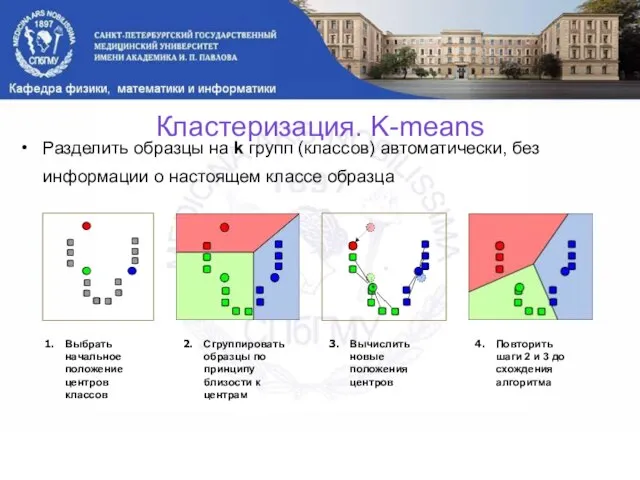
Слайд 10Разделить образцы на k групп (классов) автоматически, без информации о настоящем классе
Разделить образцы на k групп (классов) автоматически, без информации о настоящем классе
Слайд 11Классификация
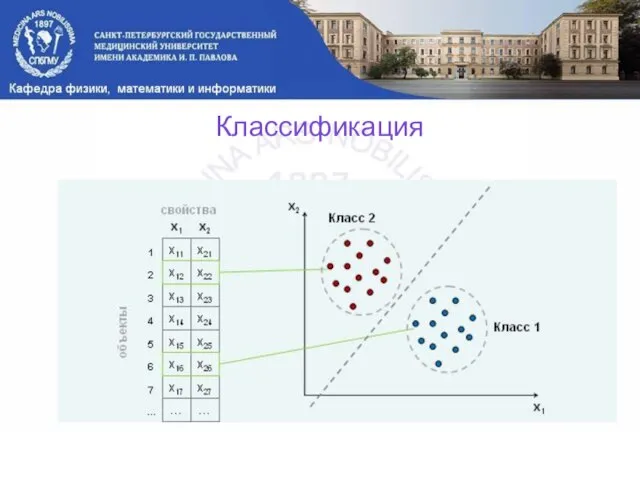
Классификация
Слайд 12Задача классификации
Цель классификации:
необходимо отнести имеющиеся статические образцы (данные медосмотра) к определенному
Задача классификации
Цель классификации:
необходимо отнести имеющиеся статические образцы (данные медосмотра) к определенному

Слайд 13Классификация
25 пациентов, перенесших ишемический инсульт; 44 показателя
Факторы риска
ишемическая болезнь сердца
артериальная гипертензия
сахарный диабет
курение
…
Классифицирующий
Классификация
25 пациентов, перенесших ишемический инсульт; 44 показателя
Факторы риска
ишемическая болезнь сердца
артериальная гипертензия
сахарный диабет
курение
…
Классифицирующий

Слайд 14Классификатор Байеса
Классификатор Байеса—вероятностный классификатор, основанный на применении Теоремы Байеса со строгими (наивными)
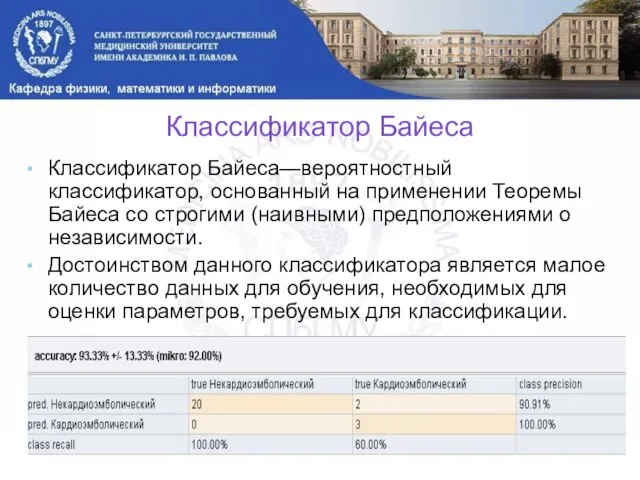
Классификатор Байеса
Классификатор Байеса—вероятностный классификатор, основанный на применении Теоремы Байеса со строгими (наивными)
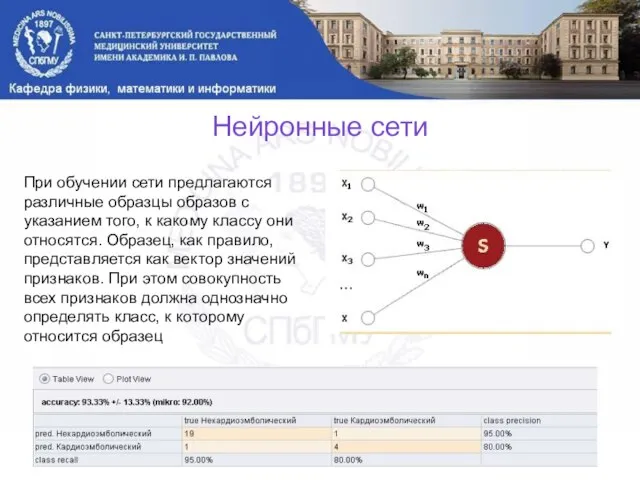
Слайд 15Нейронные сети
При обучении сети предлагаются различные образцы образов с указанием того, к
Нейронные сети
При обучении сети предлагаются различные образцы образов с указанием того, к
Слайд 16Дерево решений
Деревья принятия решений- это дерево, на ребрах которого записаны атрибуты, от
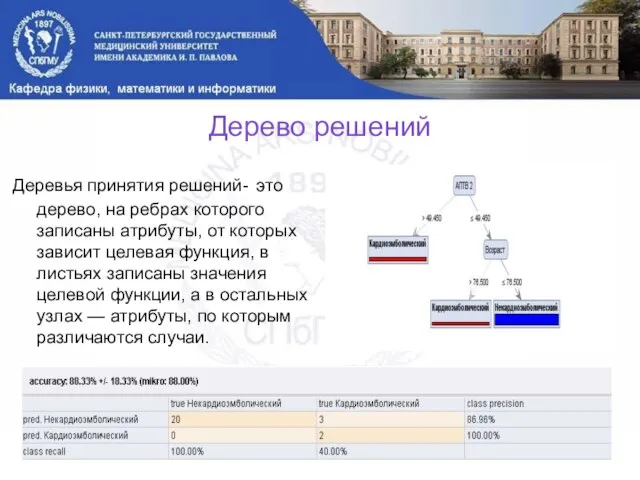
Дерево решений
Деревья принятия решений- это дерево, на ребрах которого записаны атрибуты, от
Слайд 17Метод k ближайших соседей
Метод k ближайших соседей (англ. k-nearest neighbor algorithm, kNN) -
Метод k ближайших соседей
Метод k ближайших соседей (англ. k-nearest neighbor algorithm, kNN) -

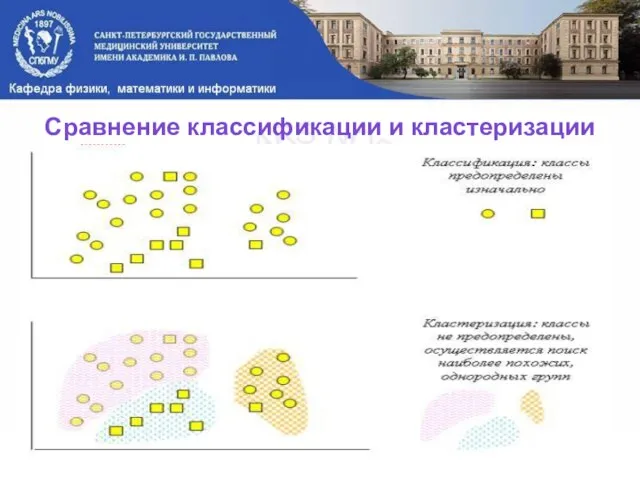
Слайд 18Сравнение классификации и кластеризации
Сравнение классификации и кластеризации
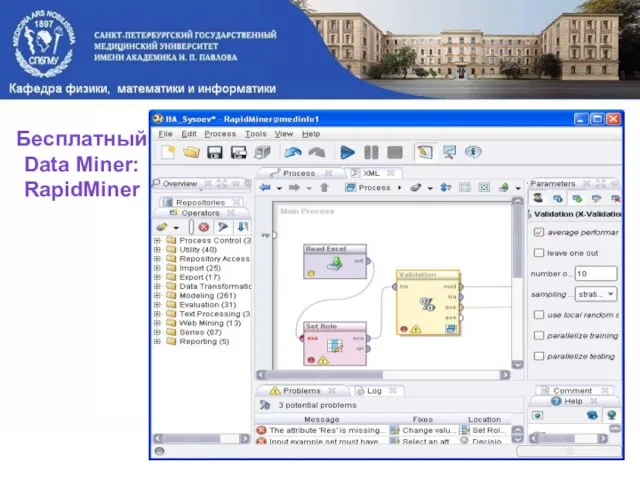
Слайд 19Бесплатный Data Miner: RapidMiner
Бесплатный Data Miner: RapidMiner
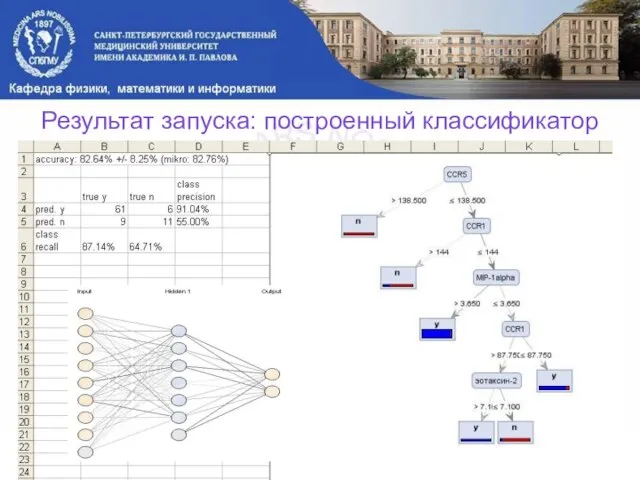
Слайд 20Результат запуска: построенный классификатор
Результат запуска: построенный классификатор
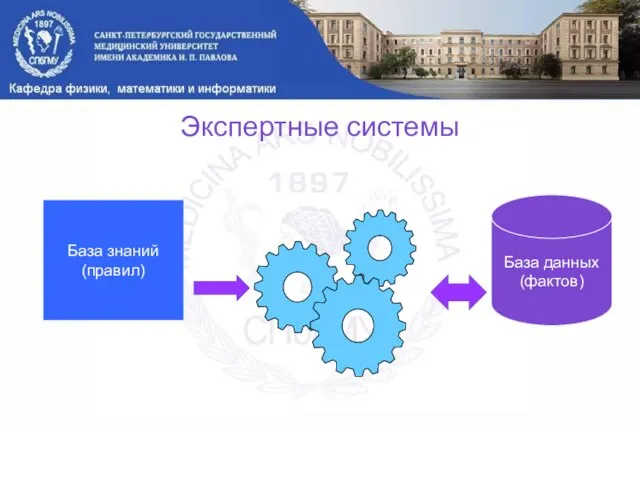
Слайд 21Экспертные системы
База знаний
(правил)
Механизм вывода
База данных
(фактов)
Экспертные системы
База знаний
(правил)
Механизм вывода
База данных
(фактов)
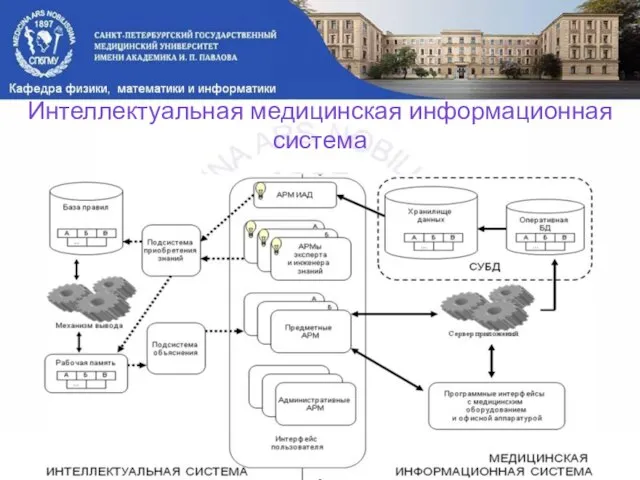
Слайд 22Интеллектуальная медицинская информационная система
Интеллектуальная медицинская информационная система
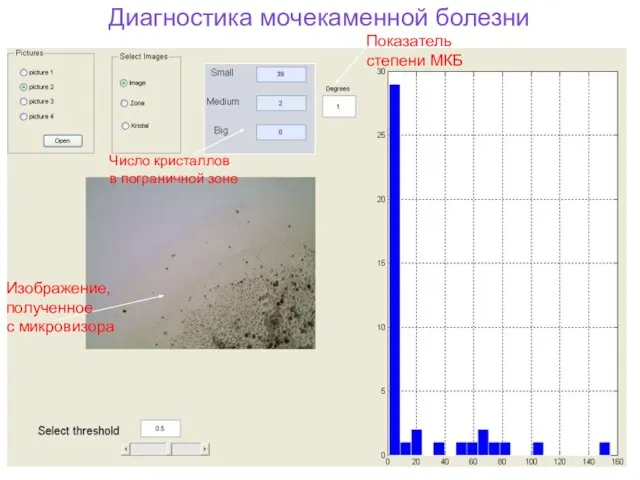
Слайд 23Изображение,
полученное
с микровизора
Показатель
степени МКБ
Число кристаллов
в пограничной зоне
Диагностика мочекаменной болезни
Изображение,
полученное
с микровизора
Показатель
степени МКБ
Число кристаллов
в пограничной зоне
Диагностика мочекаменной болезни
 00079766-3ed2eb83 (1)
00079766-3ed2eb83 (1) Продажа помещения. Фото (11)
Продажа помещения. Фото (11) Как подготовиться к сдаче ЕГЭ
Как подготовиться к сдаче ЕГЭ видеоролик
видеоролик Понятие культуры труда
Понятие культуры труда Публичный отчет за 2020-2021 годы
Публичный отчет за 2020-2021 годы M
M Проект информатизации Образовательного учреждения
Проект информатизации Образовательного учреждения 2019 декабрь ООО Жилкомсервис Кронштадтского района
2019 декабрь ООО Жилкомсервис Кронштадтского района Frohe Weihnachten!
Frohe Weihnachten! Северная чернь
Северная чернь Тема урока « Наука и семья»8 КЛАСС( химия и литература)
Тема урока « Наука и семья»8 КЛАСС( химия и литература) Буддизм в России
Буддизм в России Изменения внешней среды деятельности организаций
Изменения внешней среды деятельности организаций Независимая оценка качества образования. Этапы формирования 1-х классов
Независимая оценка качества образования. Этапы формирования 1-х классов 1-high
1-high Образец оформления конспекта
Образец оформления конспекта Технология индустриального программирования
Технология индустриального программирования  Презентация на тему "mala akademiya" - скачать презентации по Педагогике
Презентация на тему "mala akademiya" - скачать презентации по Педагогике Unknown Company The Next Phase
Unknown Company The Next Phase Фрагмент Лекции СМО
Фрагмент Лекции СМО Акция Service Clinic
Акция Service Clinic О жизни и деятельности (1885-1969 гг.)
О жизни и деятельности (1885-1969 гг.) Оформление документации по итогам ежемесячного пересчета
Оформление документации по итогам ежемесячного пересчета Недемократические режимы
Недемократические режимы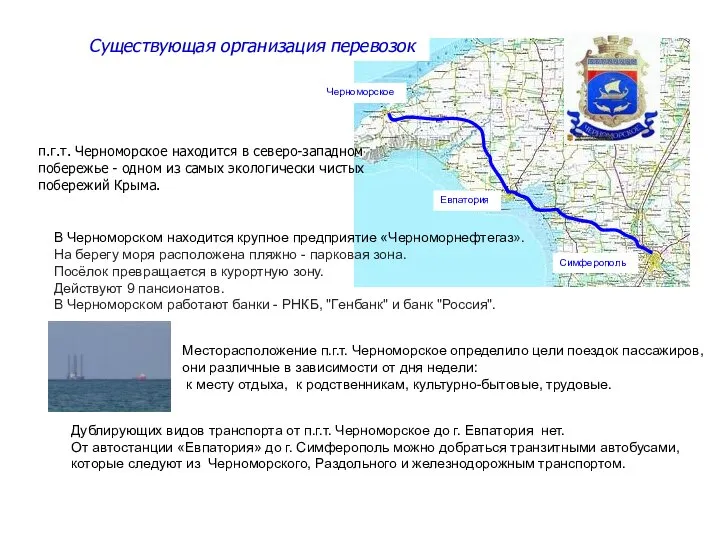 Существующая организация перевозок п.г.т. Черноморское
Существующая организация перевозок п.г.т. Черноморское Подмосковные промыслы
Подмосковные промыслы Танцы, 4 класс
Танцы, 4 класс