- Межпроцедурные анализы и оптимизации

Содержание
- 2. Содержание Межпроцедурные оптимизации: Граф вызовов процедур ( call graph ) Подстановка процедур ( inline ) Частичная
- 3. Граф вызовов процедур Граф вызовов – мультиграф, вершины – процедуры. Вершины proc1, proc2 соединены ориентированном ребром
- 4. Подстановка процедур Подстановка процедуры – замена вызова процедуры на копию ее кода, связывание формальных параметров с
- 5. Подстановка процедур Трудности: Несовпадение числа формальных и фактических параметров ( функции с переменным числом параметров, нотация
- 6. Подстановка процедур Схемы подстановки – разный обход графа вызовов: Начиная с main берем процедуру и подставляем
- 7. Частичная подстановка Частичная подстановка ( partial inline) - процедуры с большим размером кода, не подходящим по
- 8. Частичная подстановка Подстановка: Если у процедуры есть разрезанная копия, то подставляем вероятную часть и оставляем вызов
- 9. Пропагатор Пропагация констант ( constant propagation) – пропагирует статически известные константные значения по представлению. Propagator
- 10. Пропагатор Пропагация выравниваний определяет для каждой операции доступа в память выровненность на определенное значение ( фортран
- 11. Клонирование процедур Клон – спецификация процедуры для определенного вызывающего контекста Клонирование подставляет вместо вызова процедуры вызов
- 12. Клонирование процедур Cloning
- 13. Замена стандартных процедур Replacing – замена вызова стандартной функции с некоторыми параметрами на эквивалентный код Это
- 14. Хвостовая рекурсия Хвостовая рекурсия – преобразование рекурсии в цикл заменой рекурсивного вызова процедуры переходом к первой
- 15. Оптимизации работы с памятью Оптимизация размещения данных в памяти замена выделения многомерного массива на одномерный. Разбор
- 16. Оптимизации работы с памятью Memory optimizations
- 17. Оптимизации работы с памятью Memory optimizations
- 18. Оптимизации работы с памятью Memory optimizations
- 19. Оптимизации работы с памятью Достаточные условия для применения: Выделение памяти через стандартные функции malloc, calloc, memalign
- 20. Анализы указателей и алиасов Результаты анализов: анализ указателей – на какие области памяти указывает каждый указатель
- 21. Анализы may-point-to и must-point-to Свойства результатов: анализ may-point-to – указатель может указывать на некоторую область памяти
- 22. Неинициализированные указатели и неадресные значения Разыменование неинициализированного указателя Некорректная семантика – завершение анализа Разыменование в правой
- 23. Неинициализированные указатели и неадресные значения Неадресные значения ( что считать инициализацией указателя) Любое присваивание в указатель
- 24. Чувствительность к потоку управления Учитывает или нет поток управления внутри анализируемых процедур ( flow-sensitive и flow-insensitive
- 25. Чувствительность к вызывающему контексту Разделение информации ( вызывающий контекст), приходящей в процедуру по разным путям исполнения
- 26. Чувствительность к вызывающему контексту Вызывающий контекст однозначно определяется путем в графе вызовов Разные пути могут давать
- 27. Модель обработки динамической памяти Вся динамическая память - один объект Создавать уникальный объект динамической памяти по
- 28. Модель обработки динамической памяти Эвристически распознавать выделение памяти ( newnode – выделение памяти)
- 29. Обработка составных объектов Различать элементы составных объектов или рассматривать как единое целое Множество локализаций – подмножество
- 30. Обработка составных объектов Соотвествие языковых типов и множества локализаций
- 31. Обработка составных объектов Некорректное использование union
- 32. Учет языковых типов Учет типа для операций доступа в память Область памяти, независимо от типа, может
- 33. Требование компиляции всей программы Необходимо наличие для анализа всей программы, за исключением возможно стандартных библиотек (
- 34. Пример эффективного анализа Анализ на основе свойства транзитивности Для отношения «алиасить» добавляется свойство транзитивности: если и
- 35. Пример точного анализа Анализ на основе ЧТФ Трасферная функция процедуры определена для всех вызывающих контекстов, результат
- 36. Анализ на основе ЧТФ Идея абстрактной интерпритации – начиная с main итерационно собирается информация о значении
- 37. Анализ на основе ЧТФ Пример Как формализовать контекст с точки зрения интересующего нас свойства указывать?
- 38. Анализ на основе ЧТФ Чтобы задать область определения ТФ используем points-to функции p->{x,y} p->{y} 1-й и
- 39. Анализ на основе ЧТФ Начальная points-to функция для main Начальная и конечная points-to функция для f
- 40. Анализ на основе ЧТФ Начальная и конечная points-to функция для f в точках вызова S3 пунктиром
- 41. Анализ на основе ЧТФ Блоки создаем только когда встречаем реальное разыменование указателя, т.е. записываем информацию не
- 42. Анализ на основе ЧТФ Неявные вызовы – включаем в область определения ЧТФ таблицу с указателями на
- 43. Анализ на основе ЧТФ Обработка рекурсии
- 45. Скачать презентацию
Слайд 2Содержание
Межпроцедурные оптимизации:
Граф вызовов процедур ( call graph )
Подстановка процедур ( inline )
Частичная
Содержание
Межпроцедурные оптимизации:
Граф вызовов процедур ( call graph )
Подстановка процедур ( inline )
Частичная

Слайд 3Граф вызовов процедур
Граф вызовов – мультиграф, вершины – процедуры. Вершины proc1, proc2
Граф вызовов процедур
Граф вызовов – мультиграф, вершины – процедуры. Вершины proc1, proc2

Слайд 4Подстановка процедур
Подстановка процедуры – замена вызова процедуры на копию ее кода, связывание
Подстановка процедур
Подстановка процедуры – замена вызова процедуры на копию ее кода, связывание
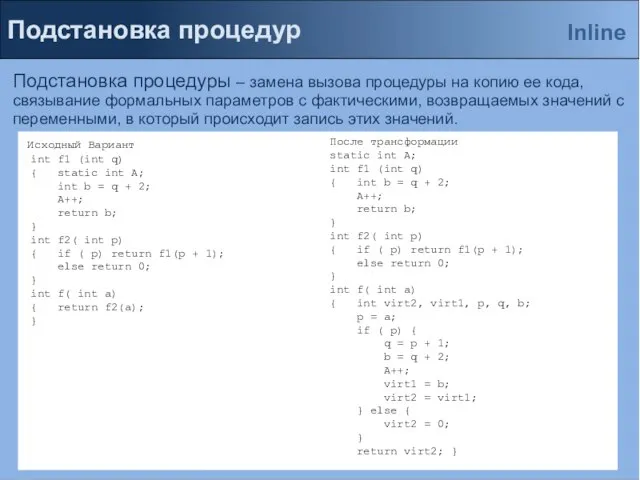
Слайд 5Подстановка процедур
Трудности:
Несовпадение числа формальных и фактических параметров ( функции с переменным числом
Подстановка процедур
Трудности:
Несовпадение числа формальных и фактических параметров ( функции с переменным числом

Слайд 6Подстановка процедур
Схемы подстановки – разный обход графа вызовов:
Начиная с main берем процедуру
Подстановка процедур
Схемы подстановки – разный обход графа вызовов:
Начиная с main берем процедуру

Слайд 7Частичная подстановка
Частичная подстановка ( partial inline) - процедуры с большим размером кода,
Частичная подстановка
Частичная подстановка ( partial inline) - процедуры с большим размером кода,
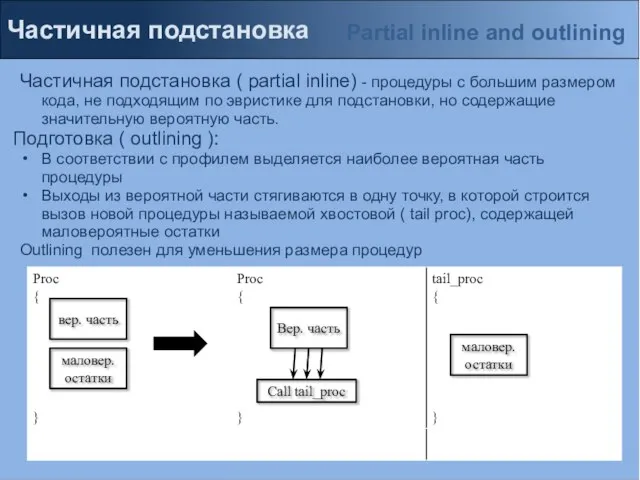
Слайд 8Частичная подстановка
Подстановка:
Если у процедуры есть разрезанная копия, то подставляем вероятную часть и
Частичная подстановка
Подстановка:
Если у процедуры есть разрезанная копия, то подставляем вероятную часть и

Слайд 9Пропагатор
Пропагация констант ( constant propagation) – пропагирует статически известные константные значения
Пропагатор
Пропагация констант ( constant propagation) – пропагирует статически известные константные значения

Слайд 10Пропагатор
Пропагация выравниваний определяет для каждой операции доступа в память выровненность на
Пропагатор
Пропагация выравниваний определяет для каждой операции доступа в память выровненность на

Слайд 11Клонирование процедур
Клон – спецификация процедуры для определенного вызывающего контекста
Клонирование подставляет вместо
Клонирование процедур
Клон – спецификация процедуры для определенного вызывающего контекста
Клонирование подставляет вместо
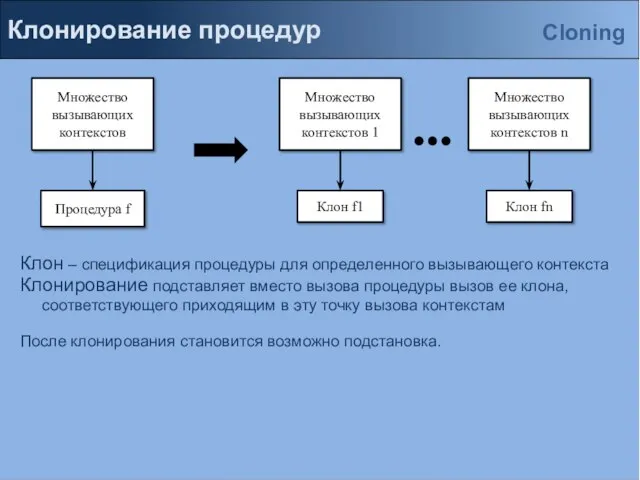
Слайд 12Клонирование процедур
Cloning
Клонирование процедур
Cloning

Слайд 13Замена стандартных процедур
Replacing – замена вызова стандартной функции с некоторыми параметрами
Замена стандартных процедур
Replacing – замена вызова стандартной функции с некоторыми параметрами

Слайд 14Хвостовая рекурсия
Хвостовая рекурсия – преобразование рекурсии в цикл заменой рекурсивного вызова процедуры
Хвостовая рекурсия
Хвостовая рекурсия – преобразование рекурсии в цикл заменой рекурсивного вызова процедуры

Слайд 15Оптимизации работы с памятью
Оптимизация размещения данных в памяти замена выделения многомерного массива
Оптимизации работы с памятью
Оптимизация размещения данных в памяти замена выделения многомерного массива

Слайд 16Оптимизации работы с памятью
Memory optimizations
Оптимизации работы с памятью
Memory optimizations

Слайд 17Оптимизации работы с памятью
Memory optimizations
Оптимизации работы с памятью
Memory optimizations

Слайд 18Оптимизации работы с памятью
Memory optimizations
Оптимизации работы с памятью
Memory optimizations

Слайд 19Оптимизации работы с памятью
Достаточные условия для применения:
Выделение памяти через стандартные функции malloc,
Оптимизации работы с памятью
Достаточные условия для применения:
Выделение памяти через стандартные функции malloc,

Слайд 20Анализы указателей и алиасов
Результаты анализов:
анализ указателей – на какие области памяти указывает
Анализы указателей и алиасов
Результаты анализов:
анализ указателей – на какие области памяти указывает

Слайд 21Анализы may-point-to и must-point-to
Свойства результатов:
анализ may-point-to – указатель может указывать на некоторую
Анализы may-point-to и must-point-to
Свойства результатов:
анализ may-point-to – указатель может указывать на некоторую

Слайд 22Неинициализированные указатели и неадресные значения
Разыменование неинициализированного указателя
Некорректная семантика – завершение анализа
Разыменование в
Неинициализированные указатели и неадресные значения
Разыменование неинициализированного указателя
Некорректная семантика – завершение анализа
Разыменование в

Слайд 23Неинициализированные указатели и неадресные значения
Неадресные значения ( что считать инициализацией указателя)
Любое присваивание
Неинициализированные указатели и неадресные значения
Неадресные значения ( что считать инициализацией указателя)
Любое присваивание

Слайд 24Чувствительность к потоку управления
Учитывает или нет поток управления внутри анализируемых процедур (
Чувствительность к потоку управления
Учитывает или нет поток управления внутри анализируемых процедур (

Слайд 25Чувствительность к вызывающему контексту
Разделение информации ( вызывающий контекст), приходящей в процедуру по
Чувствительность к вызывающему контексту
Разделение информации ( вызывающий контекст), приходящей в процедуру по

Слайд 26Чувствительность к вызывающему контексту
Вызывающий контекст однозначно определяется путем в графе вызовов
Разные пути
Чувствительность к вызывающему контексту
Вызывающий контекст однозначно определяется путем в графе вызовов
Разные пути

Слайд 27Модель обработки динамической памяти
Вся динамическая память - один объект
Создавать уникальный объект динамической
Модель обработки динамической памяти
Вся динамическая память - один объект
Создавать уникальный объект динамической

Слайд 28Модель обработки динамической памяти
Эвристически распознавать выделение памяти ( newnode – выделение памяти)
Модель обработки динамической памяти
Эвристически распознавать выделение памяти ( newnode – выделение памяти)

Слайд 29Обработка составных объектов
Различать элементы составных объектов или рассматривать как единое целое
Множество локализаций
Обработка составных объектов
Различать элементы составных объектов или рассматривать как единое целое
Множество локализаций

Слайд 30Обработка составных объектов
Соотвествие языковых типов и множества локализаций
Обработка составных объектов
Соотвествие языковых типов и множества локализаций

Слайд 31Обработка составных объектов
Некорректное использование union
Обработка составных объектов
Некорректное использование union

Слайд 32Учет языковых типов
Учет типа для операций доступа в память
Область памяти, независимо от
Учет языковых типов
Учет типа для операций доступа в память
Область памяти, независимо от

Слайд 33Требование компиляции всей программы
Необходимо наличие для анализа всей программы, за исключением возможно
Требование компиляции всей программы
Необходимо наличие для анализа всей программы, за исключением возможно

Слайд 34Пример эффективного анализа
Анализ на основе свойства транзитивности
Для отношения «алиасить» добавляется свойство транзитивности:
Пример эффективного анализа
Анализ на основе свойства транзитивности
Для отношения «алиасить» добавляется свойство транзитивности:

Слайд 35Пример точного анализа
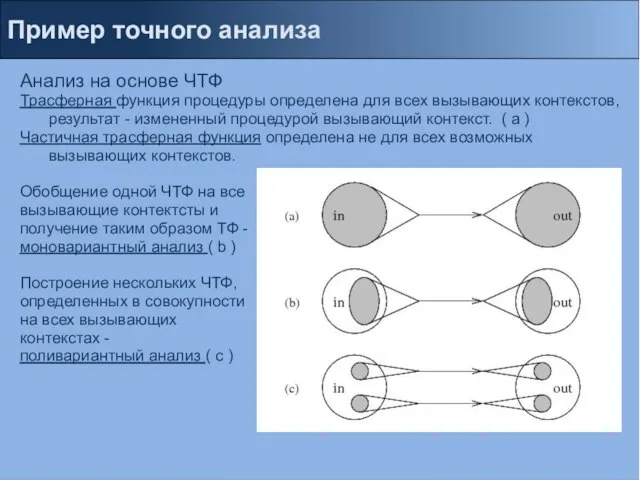
Анализ на основе ЧТФ
Трасферная функция процедуры определена для всех вызывающих
Пример точного анализа
Анализ на основе ЧТФ
Трасферная функция процедуры определена для всех вызывающих
Слайд 36Анализ на основе ЧТФ
Идея абстрактной интерпритации – начиная с main итерационно собирается
Анализ на основе ЧТФ
Идея абстрактной интерпритации – начиная с main итерационно собирается
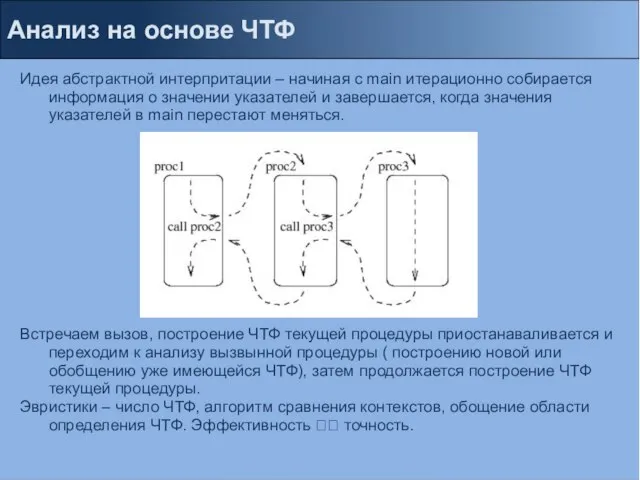
Слайд 37Анализ на основе ЧТФ
Пример
Как формализовать контекст с точки зрения интересующего нас свойства
Анализ на основе ЧТФ
Пример
Как формализовать контекст с точки зрения интересующего нас свойства

Слайд 38Анализ на основе ЧТФ
Чтобы задать область определения ТФ используем points-to функции
p->{x,y}
Анализ на основе ЧТФ
Чтобы задать область определения ТФ используем points-to функции
p->{x,y}

Слайд 39Анализ на основе ЧТФ
Начальная points-to функция для main
Начальная и конечная points-to функция
Анализ на основе ЧТФ
Начальная points-to функция для main
Начальная и конечная points-to функция
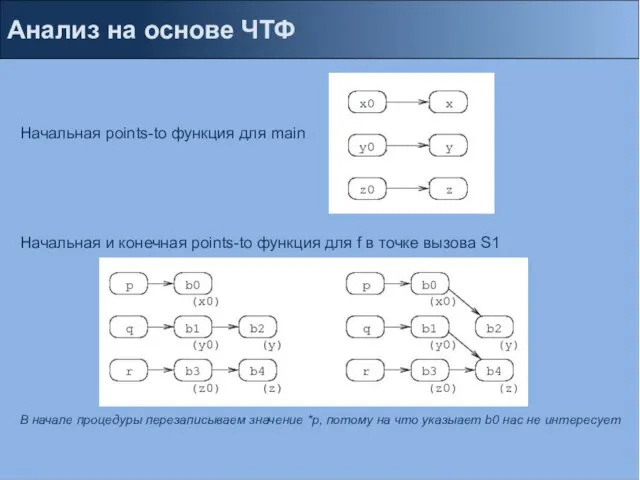
Слайд 40Анализ на основе ЧТФ
Начальная и конечная points-to функция для f в точках
Анализ на основе ЧТФ
Начальная и конечная points-to функция для f в точках
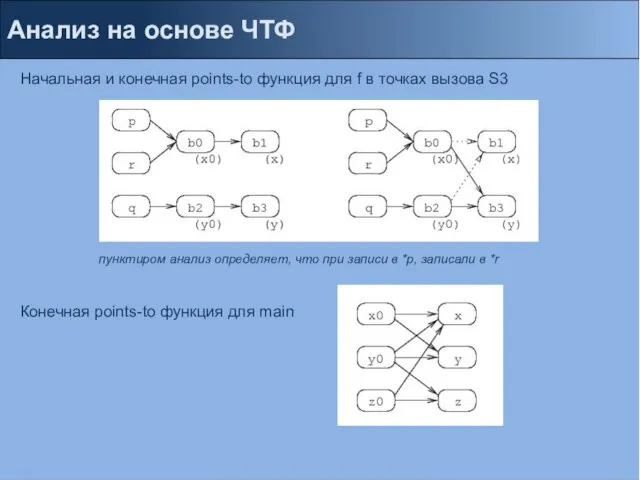
Слайд 41Анализ на основе ЧТФ
Блоки создаем только когда встречаем реальное разыменование указателя, т.е.
Анализ на основе ЧТФ
Блоки создаем только когда встречаем реальное разыменование указателя, т.е.

Слайд 42Анализ на основе ЧТФ
Неявные вызовы – включаем в область определения ЧТФ таблицу
Анализ на основе ЧТФ
Неявные вызовы – включаем в область определения ЧТФ таблицу

Слайд 43Анализ на основе ЧТФ
Обработка рекурсии
Анализ на основе ЧТФ
Обработка рекурсии
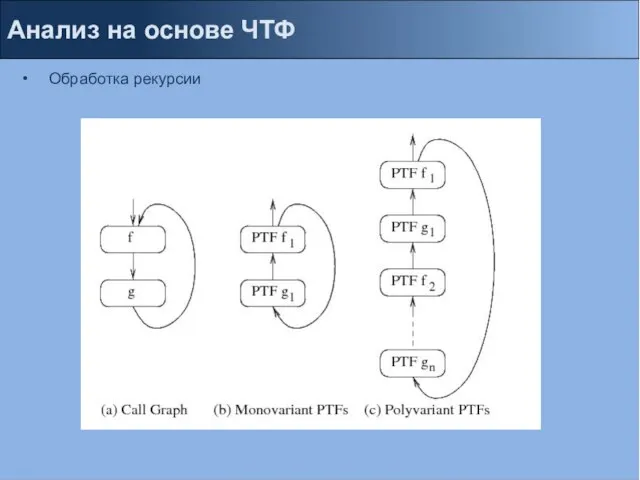
 Презентация на тему Economy of Canada (Экономика Канады)
Презентация на тему Economy of Canada (Экономика Канады) Белки
Белки prezentatsiya-lemon-festival-starlight-6 (1)
prezentatsiya-lemon-festival-starlight-6 (1) Технологическая среда ведения бизнеса
Технологическая среда ведения бизнеса Формы мышления. Логика
Формы мышления. Логика Легкая атлетика
Легкая атлетика Система дистанционного обучения Moodlе
Система дистанционного обучения Moodlе Тема: «Формирование эмоционально-ценностного отношения к миру у учащихся через экологический модуль на уроках химии»
Тема: «Формирование эмоционально-ценностного отношения к миру у учащихся через экологический модуль на уроках химии» Презентация на тему Занятость и безработица (11 класс)
Презентация на тему Занятость и безработица (11 класс) Программно-аппаратные комплексы для масштабной наработки стволовых клеток человека
Программно-аппаратные комплексы для масштабной наработки стволовых клеток человека Алюминиевые и магнивые сплавы.маркировка, свойства, применяемость
Алюминиевые и магнивые сплавы.маркировка, свойства, применяемость НАПРАВЛЕНИЕ ПОДГОТОВКИ: ПЕДАГОГИЧЕСКОЕ ОБРАЗОВАНИЕ ПРОФИЛЬ ПОДГОТОВКИ ГЕОГРАФИЯ ШКОЛА ПЕДАГОГИКИ.
НАПРАВЛЕНИЕ ПОДГОТОВКИ: ПЕДАГОГИЧЕСКОЕ ОБРАЗОВАНИЕ ПРОФИЛЬ ПОДГОТОВКИ ГЕОГРАФИЯ ШКОЛА ПЕДАГОГИКИ. Зиновьева Зоя. Самопрезентация
Зиновьева Зоя. Самопрезентация Презентация на тему Риск. Виды рисков, методы нейтрализации рисков
Презентация на тему Риск. Виды рисков, методы нейтрализации рисков  ПРАВОВЫЕ ОСНОВЫ ИННОВАЦИОННОЙ ДЕЯТЕЛЬНОСТИ
ПРАВОВЫЕ ОСНОВЫ ИННОВАЦИОННОЙ ДЕЯТЕЛЬНОСТИ  Фронтальная компфронтальная композиция, развёрнутая фронтально к главной точке зрения
Фронтальная компфронтальная композиция, развёрнутая фронтально к главной точке зрения Социальные права граждан.
Социальные права граждан.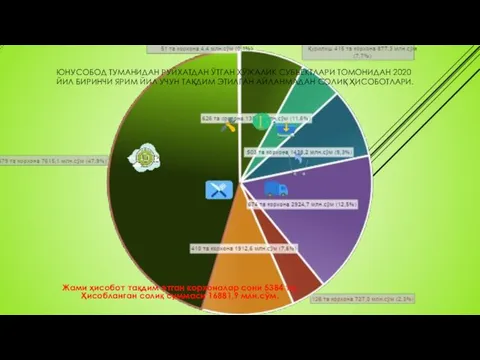 Юнусобод туманидан руйхатдан ўтган хўжалик субъектлари томонидан 2020
Юнусобод туманидан руйхатдан ўтган хўжалик субъектлари томонидан 2020 Health is the Greatest wealth
Health is the Greatest wealth ОП_Лекція_03
ОП_Лекція_03 Мы должны гордиться тем, что живем в одном из красивейших уголков Западной Сибири, с относительно благополучной экологической обс
Мы должны гордиться тем, что живем в одном из красивейших уголков Западной Сибири, с относительно благополучной экологической обс Модификация как один из эффективных способов совершенствования эксплуатационных свойств фанерной продукции
Модификация как один из эффективных способов совершенствования эксплуатационных свойств фанерной продукции Наши эмоции
Наши эмоции Понятие вакуума.Вакуумная техника.Семинар студентов и аспирантов ИФМ РАНдокладчик: А.Е. Пестов
Понятие вакуума.Вакуумная техника.Семинар студентов и аспирантов ИФМ РАНдокладчик: А.Е. Пестов Подготовка к ЕГЭ Задание А13-14, вариант 2. Орфография
Подготовка к ЕГЭ Задание А13-14, вариант 2. Орфография Рефлексивная компетентность как компонент структуры личности младшего школьника
Рефлексивная компетентность как компонент структуры личности младшего школьника Русские сезоны в Париже
Русские сезоны в Париже Спичечное и тарное производство
Спичечное и тарное производство