- Обнаружение текста на изображениях

Содержание
- 3. Зачем? Необходимо для дальнейшего распознавания текста (OCR) Документы – page layout analysis Фотографии, чертежи, графики –
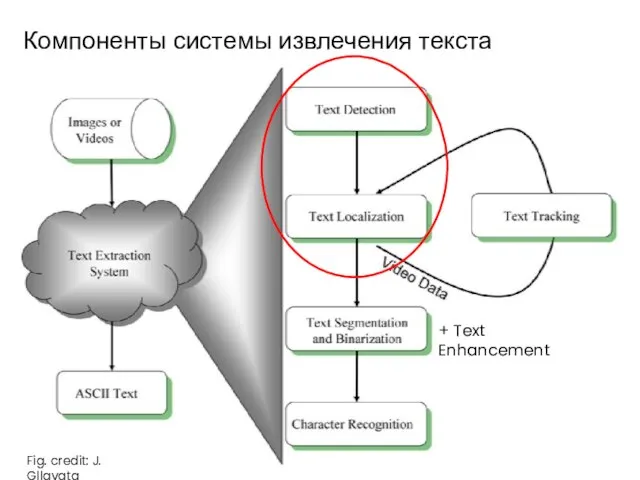
- 4. Компоненты системы извлечения текста Fig. credit: J. Gllavata + Text Enhancement
- 5. Приложения Оцифровка документов Индексирование и извлечение информации из графиков и чертежей Индексирование и поиск изображений, автоматическое
- 9. Обнаружение текста – газеты, журналы, книги обнаружение текстовых областей определение угла поворота текста (skew detection) определение
- 10. Обнаружение текста – произвольные изображения Исходное изображение Возможные результаты работы алгоритмов обнаружения текста
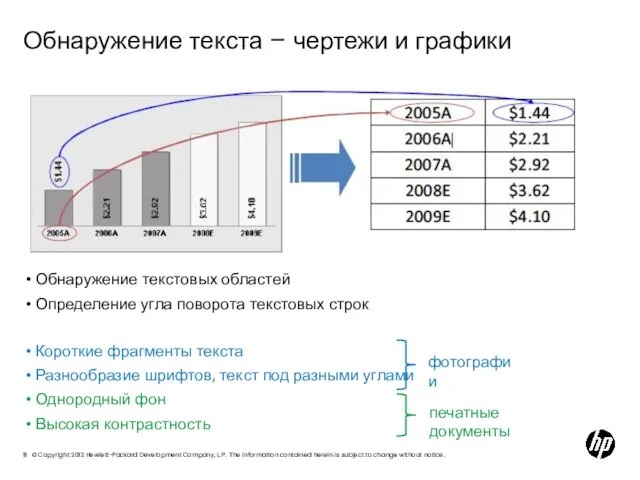
- 11. Обнаружение текста – чертежи и графики Обнаружение текстовых областей Определение угла поворота текстовых строк Короткие фрагменты
- 12. План лекции Зачем нужны алгоритмы обнаружения текста? Что такое цифровое изображение? Представление цифровых изображений Границы, компоненты
- 13. Представление цифровых изображений Растровое изображение
- 14. Представление цифровых изображений RGB – распространенная модель цвета Каждый пиксель задается тремя значениями: red, green, blue
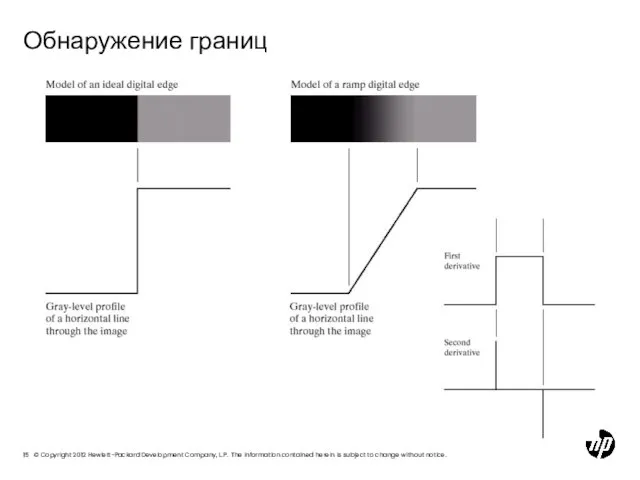
- 15. Обнаружение границ
- 16. Градиент изображения Градиент направлен в сторону наибольшего изменения интенсивности Направление градиента: Величина градиента:
- 17. Вычисление градиента изображения Roberts: Prewitt: Sobel: Дискретный случай:
- 18. Выделение границ: примеры Sobel Canny Исходное
- 19. Компоненты связности
- 20. Компоненты связности
- 21. Пороговая бинаризация Светлый объект на темном фоне Два светлых объекта на темном фоне Глобальная – порог
- 22. Бинаризация
- 23. Преобразование Хафа (Hough transform) x y m b m0 b0 image space Hough space Для данного
- 24. Преобразование Хафа (Hough transform) x y m b image space Hough space x0 y0 Для данного
- 25. План лекции Зачем нужны алгоритмы обнаружения текста? Что такое цифровое изображение? Представление цифровых изображений Границы, компоненты
- 26. Основные задачи Печатные документы Анализ структуры страницы (layout analysis, geometric structure analysis, page segmentation, region classification)
- 27. Основные задачи Печатные документы Анализ структуры страницы (layout analysis, geometric structure analysis, page segmentation, region classification)
- 28. Projection profiles and XY-cuts Вертикальная проекция Горизонтальная проекция Fig. credit: Y.Y. Tang et al.
- 29. Результат алгоритма Docstrum Методы «снизу-вверх» Fig. credit: A. Namboodiri et al.
- 30. Использование диаграмм Вороного Методы «снизу-вверх» Fig. credit: A. Namboodiri et al.
- 31. Основные задачи Печатные документы Определение поворота текста (page rotation, skew detection) Обнаружение текстовых строк (text line
- 32. План лекции Зачем нужны алгоритмы обнаружения текста? Что такое цифровое изображение? Представление цифровых изображений Границы, компоненты
- 33. Почему не работают традиционные методы? Фотографии Большое разнообразие шрифтов Разнообразие расположений и направлений текстовых строк Короткие
- 34. Классификация подходов Фотографии Text detection and localization Texture-based Region-based CC-based Edge-based K. Jung et al.
- 35. Методы, основанные на анализе текстуры Фотографии Построение пирамиды изображений Извлечение текстурных признаков (Gabor, Wevelets, DCT)
- 36. Методы, основанные на анализе текстуры Фотографии Сложный фон Вычислительно сложные (обработка нескольких масштабов, операции свертки) Произвольная
- 37. Region-based methods (bottom-up) Фотографии Выделение компонент связности на основе локальных признаков (близкий цвет или принадлежность границе)
- 38. Region-based methods Фотографии Произвольный размер шрифта Произвольная направленность текста Просты в реализации Сложный фон Шум и
- 39. Stroke Width Transform (SWT) B. Epshtein et al. Исходное изображение Результат SWT После фильтрации по признаку
- 40. Обнаружение текста при помощи SWT B. Epshtein et al.
- 41. Вычисление SWT Фрагмент штриха p – пиксель на границе штриха, q – пиксель на противоположной стороне
- 42. Обнаружение текста с помощью SWT Границы для нерезких изображений, низкого разрешения – ☹ Погрешность SWT на
- 43. Комбинированные методы Y.-F. Pan et al.
- 44. Шаг 1 – анализ текстуры Комбинированные методы Y.-F. Pan et al.
- 45. Шаг 2 – анализ компонент связности Комбинированные методы Y.-F. Pan et al.
- 46. Шаг 3 – выделение текстовых строк и слов Комбинированные методы Y.-F. Pan et al. построение минимального
- 47. Robust Reading Competitions ICDAR (2003, 2005, 2009, 2011) Распознавание символов Распознавание слов Локализация текста Распознавание текста
- 48. План лекции Зачем нужны алгоритмы обнаружения текста? Что такое цифровое изображение? Представление цифровых изображений Границы, компоненты
- 49. Графики и диаграммы Анализ компонент связности по цвету
- 50. Экспериментальная оценка LocationRecognitionRate = NLoc/NG LocationPrecisionRate = NLoc/NF TextPrecisionRate = NTxt/NF TextRecognitionRate = NTxt/NG NLoc –
- 51. Screenshots (+) Быстрая бинаризация Время обработки изображения1600x1008 Tesseract OCR: ~6.56 секунд Данный алгоритм: ~0.45 seconds (–)
- 53. Скачать презентацию

Слайд 3Зачем?
Необходимо для дальнейшего распознавания текста (OCR)
Документы – page layout analysis
Фотографии, чертежи, графики
Зачем?
Необходимо для дальнейшего распознавания текста (OCR)
Документы – page layout analysis
Фотографии, чертежи, графики

Слайд 4Компоненты системы извлечения текста
Fig. credit: J. Gllavata
+ Text Enhancement
Компоненты системы извлечения текста
Fig. credit: J. Gllavata
+ Text Enhancement
Слайд 5Приложения
Оцифровка документов
Индексирование и извлечение информации из графиков и чертежей
Индексирование и поиск изображений,
Приложения
Оцифровка документов
Индексирование и извлечение информации из графиков и чертежей
Индексирование и поиск изображений,



Слайд 9Обнаружение текста – газеты, журналы, книги
обнаружение текстовых областей
определение угла поворота текста (skew
Обнаружение текста – газеты, журналы, книги
обнаружение текстовых областей
определение угла поворота текста (skew

Слайд 10Обнаружение текста – произвольные изображения
Исходное изображение
Возможные результаты работы алгоритмов обнаружения текста
Обнаружение текста – произвольные изображения
Исходное изображение
Возможные результаты работы алгоритмов обнаружения текста

Слайд 11Обнаружение текста – чертежи и графики
Обнаружение текстовых областей
Определение угла поворота текстовых строк
Короткие
Обнаружение текста – чертежи и графики
Обнаружение текстовых областей
Определение угла поворота текстовых строк
Короткие
Слайд 12План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты
План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты

Слайд 13Представление цифровых изображений
Растровое изображение
Представление цифровых изображений
Растровое изображение

Слайд 14Представление цифровых изображений
RGB – распространенная модель цвета
Каждый пиксель задается тремя значениями: red,
Представление цифровых изображений
RGB – распространенная модель цвета
Каждый пиксель задается тремя значениями: red,

Слайд 15Обнаружение границ
Обнаружение границ
Слайд 16Градиент изображения
Градиент направлен в сторону наибольшего изменения интенсивности
Направление градиента:
Величина градиента:
Градиент изображения
Градиент направлен в сторону наибольшего изменения интенсивности
Направление градиента:
Величина градиента:

Слайд 17Вычисление градиента изображения
Roberts:
Prewitt:
Sobel:
Дискретный случай:
Вычисление градиента изображения
Roberts:
Prewitt:
Sobel:
Дискретный случай:

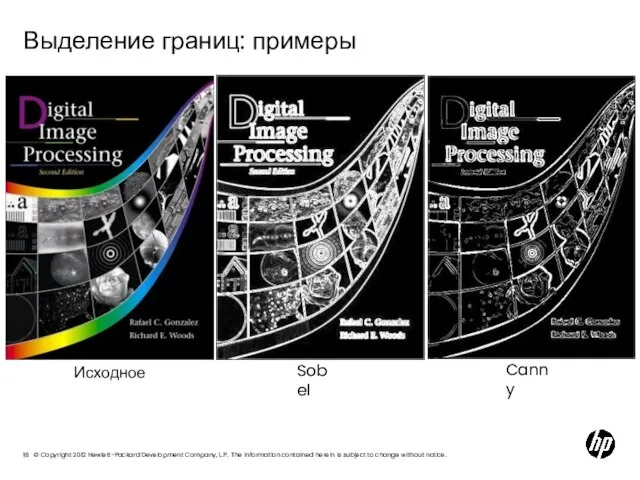
Слайд 18Выделение границ: примеры
Sobel
Canny
Исходное
Выделение границ: примеры
Sobel
Canny
Исходное
Слайд 19Компоненты связности
Компоненты связности

Слайд 20Компоненты связности
Компоненты связности

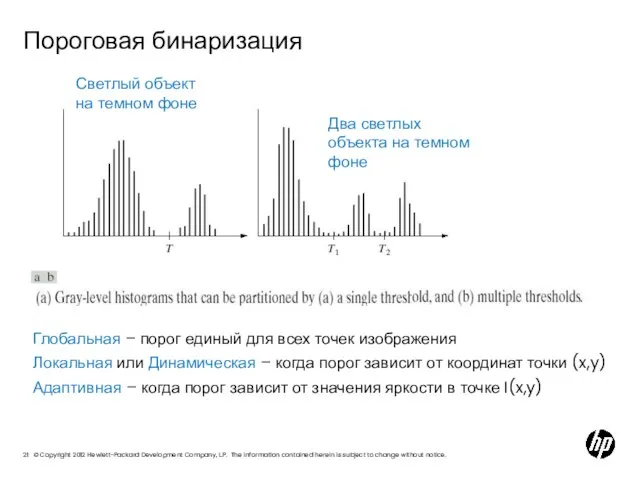
Слайд 21Пороговая бинаризация
Светлый объект на темном фоне
Два светлых объекта на темном фоне
Глобальная –
Пороговая бинаризация
Светлый объект на темном фоне
Два светлых объекта на темном фоне
Глобальная –
Слайд 22Бинаризация
Бинаризация

Слайд 23Преобразование Хафа (Hough transform)
x
y
m
b
m0
b0
image space
Hough space
Для данного набора точек (x, y)
Преобразование Хафа (Hough transform)
x
y
m
b
m0
b0
image space
Hough space
Для данного набора точек (x, y)

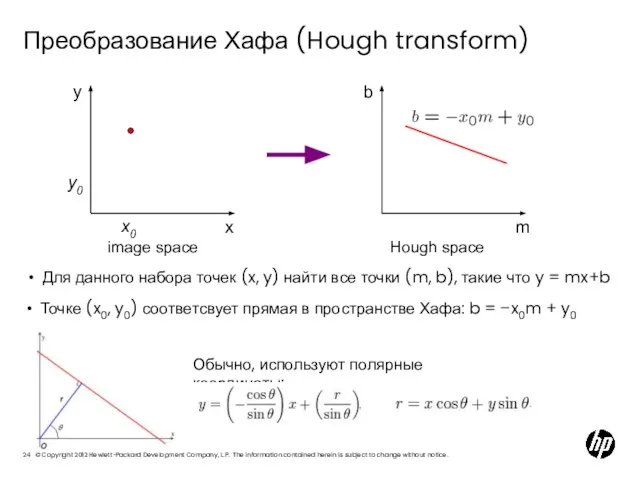
Слайд 24Преобразование Хафа (Hough transform)
x
y
m
b
image space
Hough space
x0
y0
Для данного набора точек (x, y)
Преобразование Хафа (Hough transform)
x
y
m
b
image space
Hough space
x0
y0
Для данного набора точек (x, y)
Слайд 25План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты
План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты

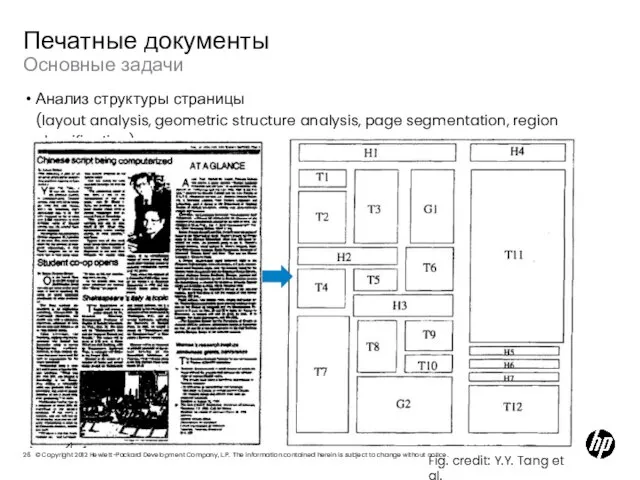
Слайд 26Основные задачи
Печатные документы
Анализ структуры страницы
(layout analysis, geometric structure analysis, page segmentation,
Основные задачи
Печатные документы
Анализ структуры страницы (layout analysis, geometric structure analysis, page segmentation,
Слайд 27Основные задачи
Печатные документы
Анализ структуры страницы
(layout analysis, geometric structure analysis, page segmentation,
Основные задачи
Печатные документы
Анализ структуры страницы (layout analysis, geometric structure analysis, page segmentation,
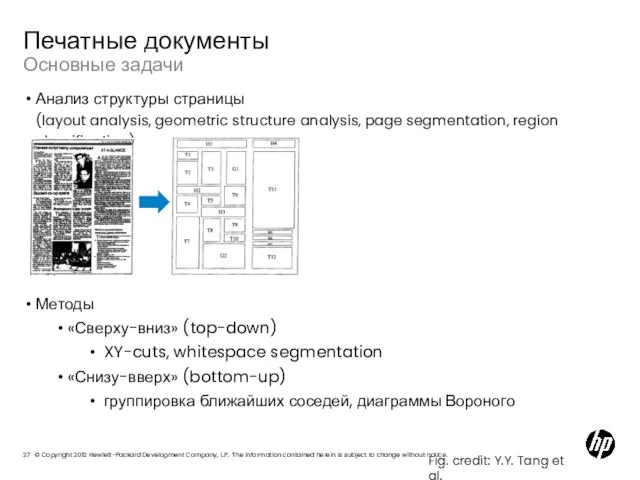
Слайд 28Projection profiles and XY-cuts
Вертикальная проекция
Горизонтальная проекция
Fig. credit: Y.Y. Tang et al.
Projection profiles and XY-cuts
Вертикальная проекция
Горизонтальная проекция
Fig. credit: Y.Y. Tang et al.

Слайд 29Результат алгоритма Docstrum
Методы «снизу-вверх»
Fig. credit: A. Namboodiri et al.
Результат алгоритма Docstrum
Методы «снизу-вверх»
Fig. credit: A. Namboodiri et al.

Слайд 30Использование диаграмм Вороного
Методы «снизу-вверх»
Fig. credit: A. Namboodiri et al.
Использование диаграмм Вороного
Методы «снизу-вверх»
Fig. credit: A. Namboodiri et al.

Слайд 31Основные задачи
Печатные документы
Определение поворота текста
(page rotation, skew detection)
Обнаружение текстовых строк
(text
Основные задачи
Печатные документы
Определение поворота текста
(page rotation, skew detection)
Обнаружение текстовых строк (text

Слайд 32План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты
План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты

Слайд 33Почему не работают традиционные методы?
Фотографии
Большое разнообразие шрифтов
Разнообразие расположений и направлений текстовых строк
Короткие
Почему не работают традиционные методы?
Фотографии
Большое разнообразие шрифтов
Разнообразие расположений и направлений текстовых строк
Короткие

Слайд 34Классификация подходов
Фотографии
Text detection and localization
Texture-based
Region-based
CC-based
Edge-based
K. Jung et al.
Классификация подходов
Фотографии
Text detection and localization
Texture-based
Region-based
CC-based
Edge-based
K. Jung et al.
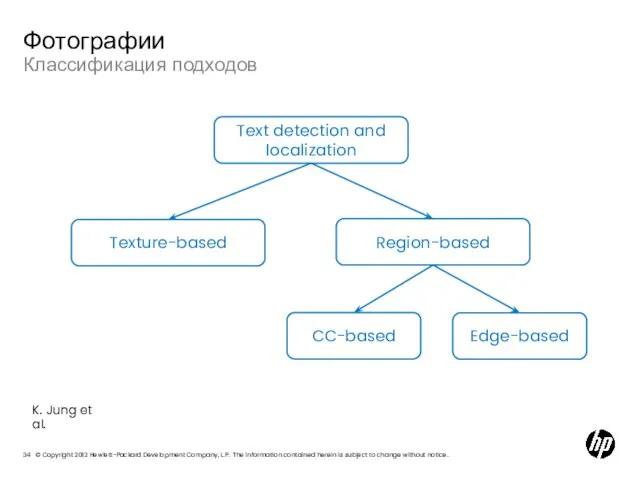
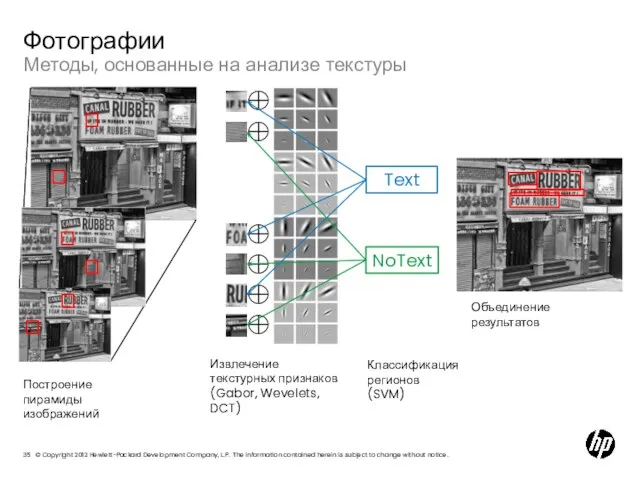
Слайд 35Методы, основанные на анализе текстуры
Фотографии
Построение пирамиды
изображений
Извлечение текстурных признаков
(Gabor, Wevelets, DCT)
Методы, основанные на анализе текстуры
Фотографии
Построение пирамиды
изображений
Извлечение текстурных признаков
(Gabor, Wevelets, DCT)
Слайд 36Методы, основанные на анализе текстуры
Фотографии
Сложный фон
Вычислительно сложные (обработка нескольких масштабов, операции свертки)
Произвольная
Методы, основанные на анализе текстуры
Фотографии
Сложный фон
Вычислительно сложные (обработка нескольких масштабов, операции свертки)
Произвольная

Слайд 37Region-based methods (bottom-up)
Фотографии
Выделение компонент связности на основе локальных признаков (близкий цвет или
Region-based methods (bottom-up)
Фотографии
Выделение компонент связности на основе локальных признаков (близкий цвет или

Слайд 38Region-based methods
Фотографии
Произвольный размер шрифта
Произвольная направленность текста
Просты в реализации
Сложный фон
Шум и нерезкость изображения
Используют
Region-based methods
Фотографии
Произвольный размер шрифта
Произвольная направленность текста
Просты в реализации
Сложный фон
Шум и нерезкость изображения
Используют

Слайд 39Stroke Width Transform (SWT)
B. Epshtein et al.
Исходное
изображение
Результат SWT
После фильтрации
по признаку постоянства
ширины
Stroke Width Transform (SWT)
B. Epshtein et al.
Исходное
изображение
Результат SWT
После фильтрации
по признаку постоянства
ширины

Слайд 40Обнаружение текста при помощи SWT
B. Epshtein et al.
Обнаружение текста при помощи SWT
B. Epshtein et al.
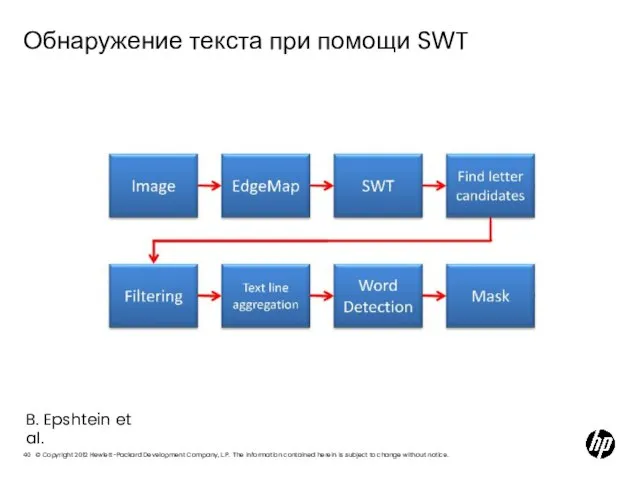
Слайд 41Вычисление SWT
Фрагмент штриха
p – пиксель на границе штриха,
q – пиксель на
Вычисление SWT
Фрагмент штриха
p – пиксель на границе штриха,
q – пиксель на

Слайд 42Обнаружение текста с помощью SWT
Границы для нерезких изображений, низкого разрешения – ☹
Погрешность
Обнаружение текста с помощью SWT
Границы для нерезких изображений, низкого разрешения – ☹
Погрешность

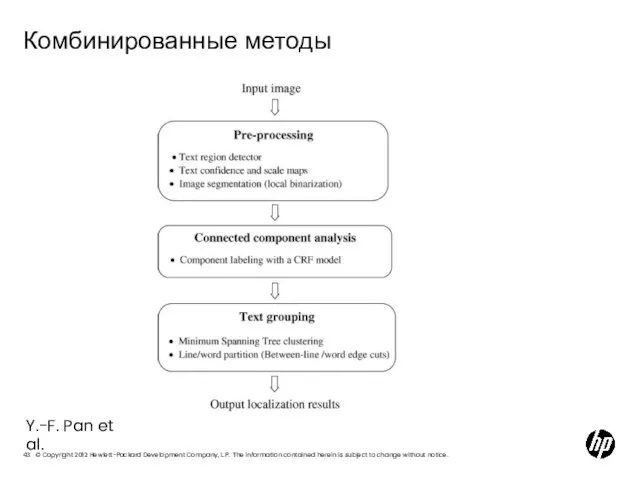
Слайд 43Комбинированные методы
Y.-F. Pan et al.
Комбинированные методы
Y.-F. Pan et al.
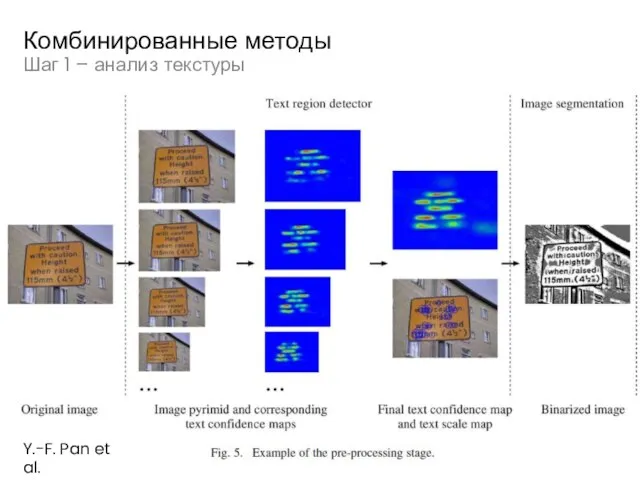
Слайд 44Шаг 1 – анализ текстуры
Комбинированные методы
Y.-F. Pan et al.
Шаг 1 – анализ текстуры
Комбинированные методы
Y.-F. Pan et al.
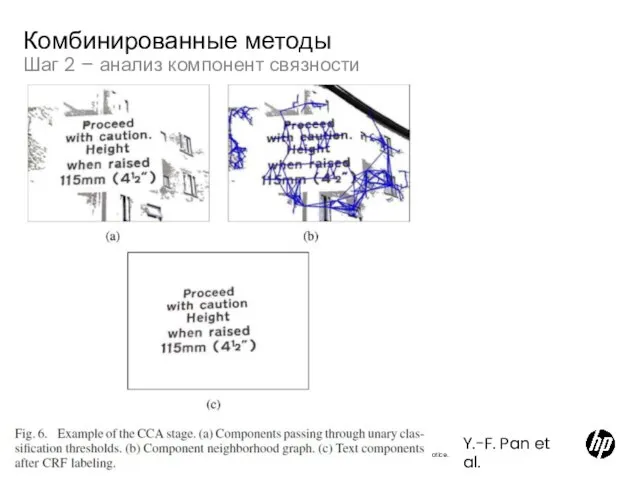
Слайд 45Шаг 2 – анализ компонент связности
Комбинированные методы
Y.-F. Pan et al.
Шаг 2 – анализ компонент связности
Комбинированные методы
Y.-F. Pan et al.
Слайд 46Шаг 3 – выделение текстовых строк и слов
Комбинированные методы
Y.-F. Pan et al.
Шаг 3 – выделение текстовых строк и слов
Комбинированные методы
Y.-F. Pan et al.

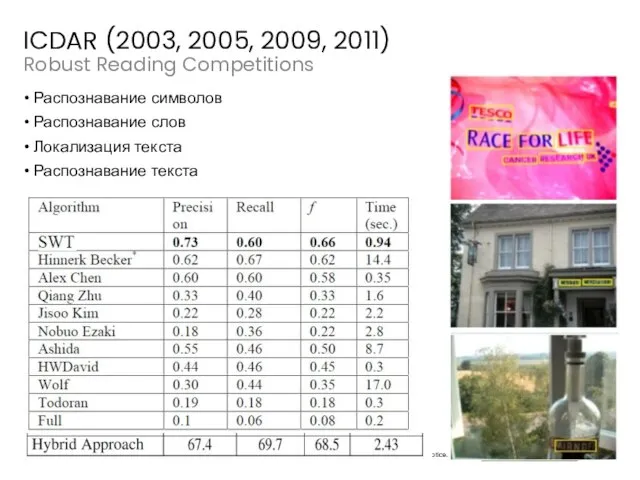
Слайд 47Robust Reading Competitions
ICDAR (2003, 2005, 2009, 2011)
Распознавание символов
Распознавание слов
Локализация текста
Распознавание текста
Robust Reading Competitions
ICDAR (2003, 2005, 2009, 2011)
Распознавание символов
Распознавание слов
Локализация текста
Распознавание текста
Слайд 48План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты
План лекции
Зачем нужны алгоритмы обнаружения текста?
Что такое цифровое изображение?
Представление цифровых изображений
Границы, компоненты

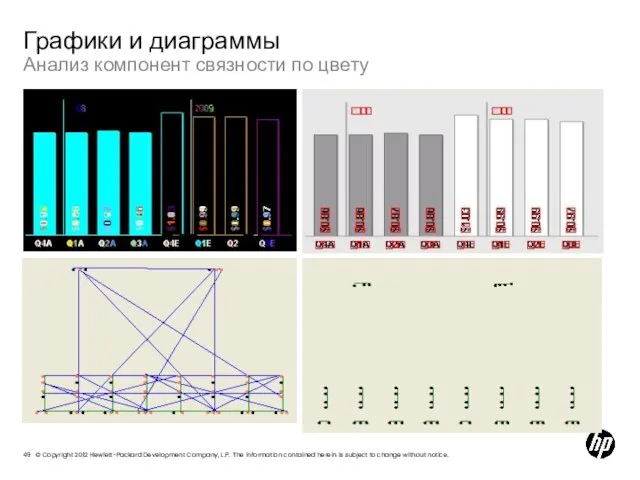
Слайд 49Графики и диаграммы
Анализ компонент связности по цвету
Графики и диаграммы
Анализ компонент связности по цвету
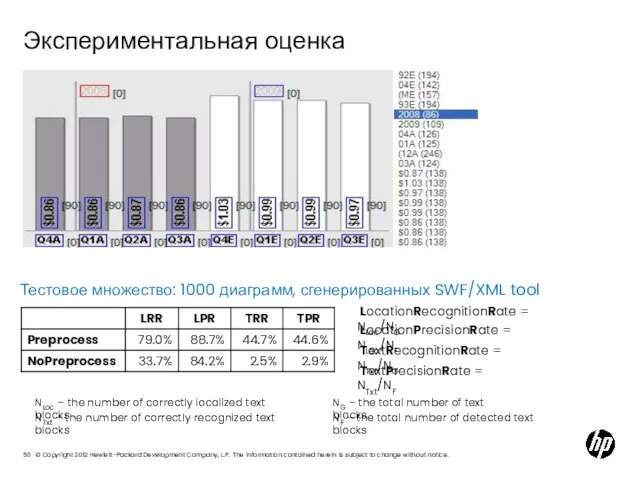
Слайд 50Экспериментальная оценка
LocationRecognitionRate = NLoc/NG
LocationPrecisionRate = NLoc/NF
TextPrecisionRate =
Экспериментальная оценка
LocationRecognitionRate = NLoc/NG
LocationPrecisionRate = NLoc/NF
TextPrecisionRate =
Слайд 51Screenshots
(+) Быстрая бинаризация
Время обработки изображения1600x1008
Tesseract OCR: ~6.56 секунд
Данный алгоритм: ~0.45 seconds
(–) Требует
Screenshots
(+) Быстрая бинаризация
Время обработки изображения1600x1008
Tesseract OCR: ~6.56 секунд
Данный алгоритм: ~0.45 seconds
(–) Требует

 00079766-3ed2eb83 (1)
00079766-3ed2eb83 (1) Продажа помещения. Фото (11)
Продажа помещения. Фото (11) Как подготовиться к сдаче ЕГЭ
Как подготовиться к сдаче ЕГЭ видеоролик
видеоролик Понятие культуры труда
Понятие культуры труда Публичный отчет за 2020-2021 годы
Публичный отчет за 2020-2021 годы M
M Проект информатизации Образовательного учреждения
Проект информатизации Образовательного учреждения 2019 декабрь ООО Жилкомсервис Кронштадтского района
2019 декабрь ООО Жилкомсервис Кронштадтского района Frohe Weihnachten!
Frohe Weihnachten! Северная чернь
Северная чернь Тема урока « Наука и семья»8 КЛАСС( химия и литература)
Тема урока « Наука и семья»8 КЛАСС( химия и литература) Буддизм в России
Буддизм в России Изменения внешней среды деятельности организаций
Изменения внешней среды деятельности организаций Независимая оценка качества образования. Этапы формирования 1-х классов
Независимая оценка качества образования. Этапы формирования 1-х классов 1-high
1-high Образец оформления конспекта
Образец оформления конспекта Технология индустриального программирования
Технология индустриального программирования  Презентация на тему "mala akademiya" - скачать презентации по Педагогике
Презентация на тему "mala akademiya" - скачать презентации по Педагогике Unknown Company The Next Phase
Unknown Company The Next Phase Фрагмент Лекции СМО
Фрагмент Лекции СМО Акция Service Clinic
Акция Service Clinic О жизни и деятельности (1885-1969 гг.)
О жизни и деятельности (1885-1969 гг.) Оформление документации по итогам ежемесячного пересчета
Оформление документации по итогам ежемесячного пересчета Недемократические режимы
Недемократические режимы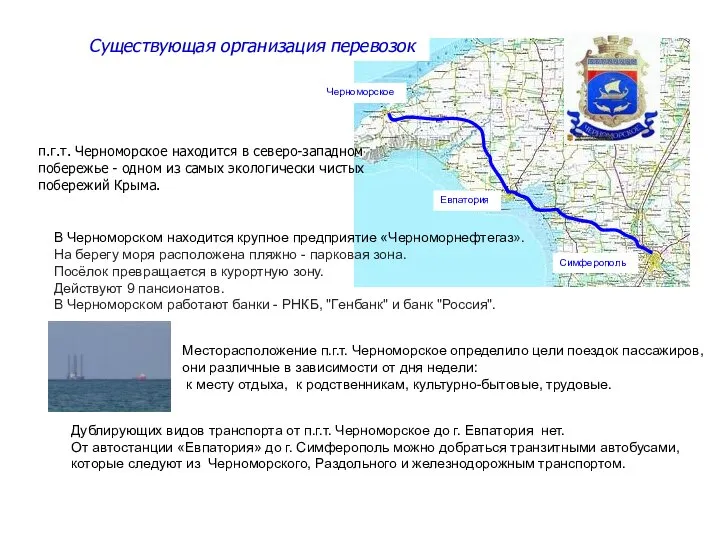 Существующая организация перевозок п.г.т. Черноморское
Существующая организация перевозок п.г.т. Черноморское Подмосковные промыслы
Подмосковные промыслы Танцы, 4 класс
Танцы, 4 класс