- Определение новизны информации в новостном кластере

Содержание
- 2. Определение новизны информации Определение новизны информации – важная и нерешённая задача. Проблема в общем виде: поток
- 3. Конкретная задача Новостной кластер – набор документов по поводу некоторого события. Аннотация – краткое описание события,
- 4. Конференция TREC Создана при поддержке Национального Института Стандартов и Технологий (NIST) и Департамента Защиты США. Проект
- 5. Постановка задачи «Определение новизны» в TREC Данная задача разрабатывалась в TREC в 2002 – 2004 годах
- 6. Постановка задачи-1 То есть по сути задача делится на две части: Обнаружение значимых (важных) предложений. (identifying
- 7. Постановка задачи-2 4 дисциплины: Task 1. Дан набор документов и топик, определить все релевантные и новые
- 8. Входные данные-1 AQUAINT collection. New York Times News Service (Jun 1998 – Sep 2000), AP (also
- 9. Входные данные-2 Специалисты NIST сделали 50 кратких описаний новостей из данной коллекции. Новости были 2-ух типов:
- 10. Оценка результатов-1 Каждый топик был проанализирован двумя независимыми экспертами из NIST. Эксперты из набора документов выбрали
- 11. Оценка результатов-2
- 12. Оценка результатов-3 Введём следующие обозначения: M – число «правильных» предложений, то есть предложений, выбранных обоими экспертами
- 13. Оценка результатов-4 Тогда: R = M / A – эффективность поиска. (Recall) P = M /
- 14. Оценка результатов-5 Вариант решения: F-мера (F-measure) Общий вид: F-measure, используемая на Novelty track:
- 15. Оценка результатов-6
- 16. Участники
- 17. Результаты - 1 В целом не очень высокие абсолютные результаты. Среднее значение F – меры: 0.36
- 18. Результаты - 2
- 19. Результаты - 3
- 20. Результаты - 4
- 21. Анализ результатов TREC Task 2. Даны релевантные предложения во всех документах, определить все новые предложения. Данная
- 23. Особенности и основные идеи системы SumSeg-1 Новая информация может появляться в сегментах больше или меньше одного
- 24. Особенности и основные идеи системы SumSeg-2 Большое количество различных весов и порогов. База данных частотных характеристик
- 25. Векторно-пространственная модель-1 Алгебраическая модель представления текстовых документов (в общем случае любых объектов) в виде вектора идентификаторов.
- 26. Векторно-пространственная модель-2 Пример: Пусть есть два предложения. «Мама мыла раму» и «Папа мыл автомобиль». Сравним предложения
- 27. Направление дальнейшей работы Первоочередная задача – реализация векторно - пространственной модели и попытка её практического применения
- 29. Скачать презентацию
Слайд 2Определение новизны информации
Определение новизны информации – важная и нерешённая задача.
Проблема в
Определение новизны информации
Определение новизны информации – важная и нерешённая задача.
Проблема в

Слайд 3Конкретная задача
Новостной кластер – набор документов по поводу некоторого события.
Аннотация – краткое
Конкретная задача
Новостной кластер – набор документов по поводу некоторого события.
Аннотация – краткое

Слайд 4Конференция TREC
Создана при поддержке Национального Института Стандартов и Технологий (NIST) и Департамента
Конференция TREC
Создана при поддержке Национального Института Стандартов и Технологий (NIST) и Департамента

Слайд 5Постановка задачи «Определение новизны» в TREC
Данная задача разрабатывалась в TREC в 2002
Постановка задачи «Определение новизны» в TREC
Данная задача разрабатывалась в TREC в 2002

Слайд 6Постановка задачи-1
То есть по сути задача делится на две части:
Обнаружение значимых (важных)
Постановка задачи-1
То есть по сути задача делится на две части:
Обнаружение значимых (важных)

Слайд 7Постановка задачи-2
4 дисциплины:
Task 1. Дан набор документов и топик, определить все релевантные
Постановка задачи-2
4 дисциплины:
Task 1. Дан набор документов и топик, определить все релевантные

Слайд 8Входные данные-1
AQUAINT collection.
New York Times News Service (Jun 1998 – Sep
Входные данные-1
AQUAINT collection.
New York Times News Service (Jun 1998 – Sep

Слайд 9Входные данные-2
Специалисты NIST сделали 50 кратких описаний новостей из данной коллекции.
Новости были
Входные данные-2
Специалисты NIST сделали 50 кратких описаний новостей из данной коллекции.
Новости были

Слайд 10Оценка результатов-1
Каждый топик был проанализирован двумя независимыми экспертами из NIST.
Эксперты из набора
Оценка результатов-1
Каждый топик был проанализирован двумя независимыми экспертами из NIST.
Эксперты из набора

Слайд 11Оценка результатов-2
Оценка результатов-2
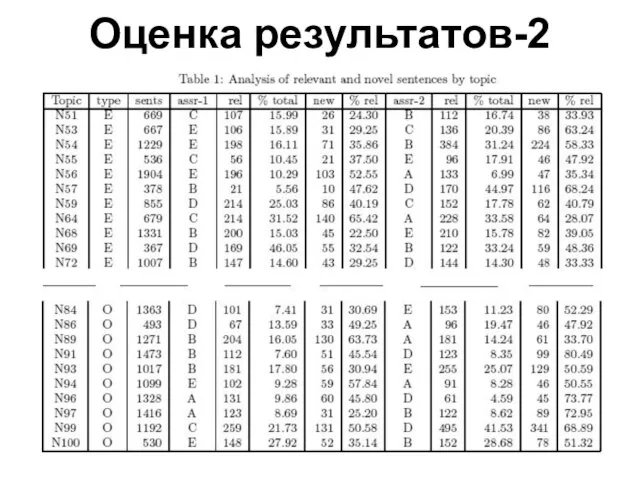
Слайд 12Оценка результатов-3
Введём следующие обозначения:
M – число «правильных» предложений, то есть предложений, выбранных
Оценка результатов-3
Введём следующие обозначения:
M – число «правильных» предложений, то есть предложений, выбранных

Слайд 13Оценка результатов-4
Тогда:
R = M / A – эффективность поиска. (Recall)
P = M
Оценка результатов-4
Тогда:
R = M / A – эффективность поиска. (Recall)
P = M

Слайд 14Оценка результатов-5
Вариант решения: F-мера (F-measure)
Общий вид:
F-measure, используемая на Novelty track:
Оценка результатов-5
Вариант решения: F-мера (F-measure)
Общий вид:
F-measure, используемая на Novelty track:

Слайд 15Оценка результатов-6
Оценка результатов-6
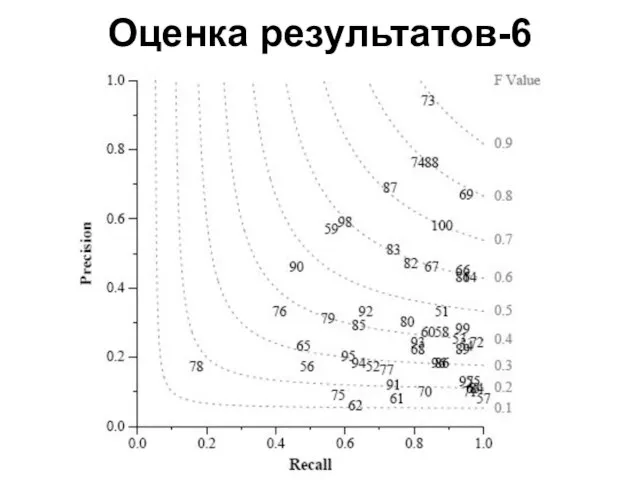
Слайд 16Участники
Участники
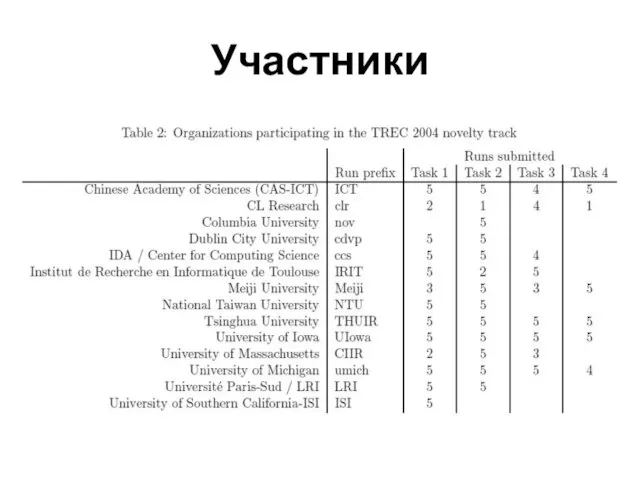
Слайд 17Результаты - 1
В целом не очень высокие абсолютные результаты.
Среднее значение F –
Результаты - 1
В целом не очень высокие абсолютные результаты.
Среднее значение F –

Слайд 18Результаты - 2
Результаты - 2
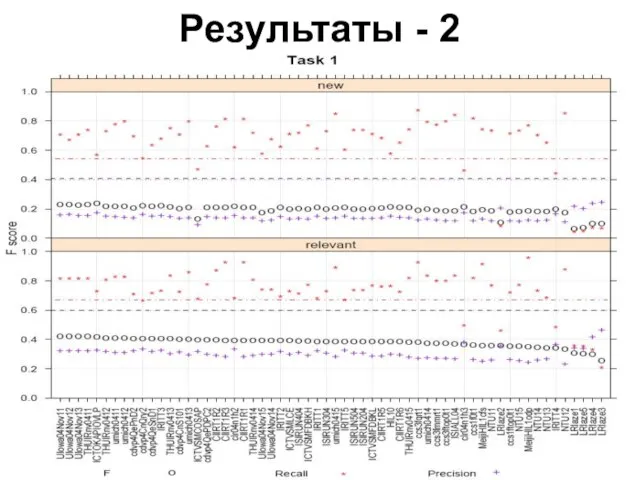
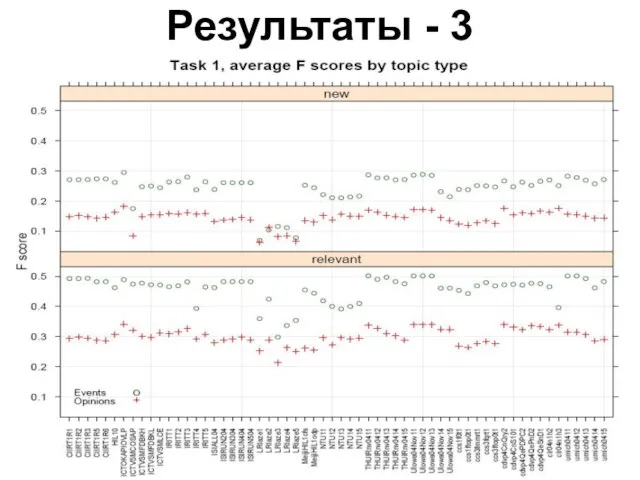
Слайд 19Результаты - 3
Результаты - 3
Слайд 20Результаты - 4
Результаты - 4
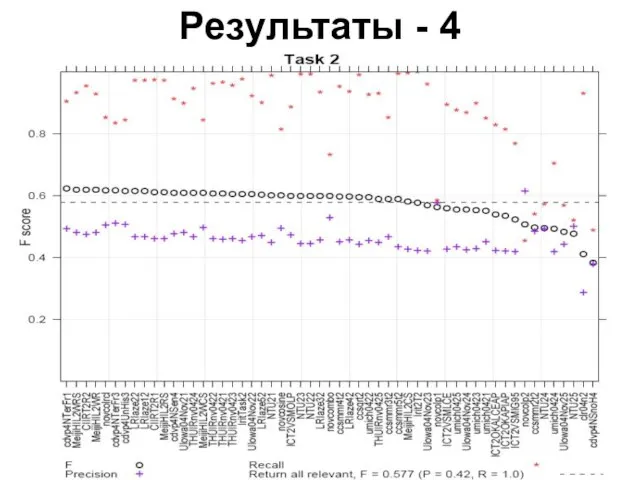
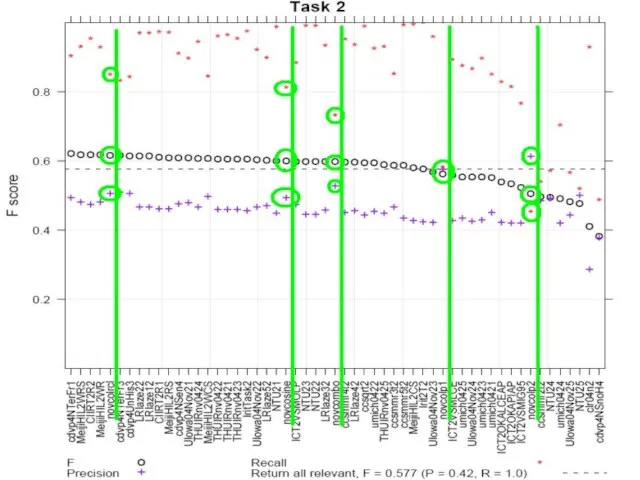
Слайд 21Анализ результатов TREC
Task 2. Даны релевантные предложения во всех документах, определить все
Анализ результатов TREC
Task 2. Даны релевантные предложения во всех документах, определить все

Слайд 23Особенности и основные идеи системы SumSeg-1
Новая информация может появляться в сегментах больше
Особенности и основные идеи системы SumSeg-1
Новая информация может появляться в сегментах больше

Слайд 24Особенности и основные идеи системы SumSeg-2
Большое количество различных весов и порогов.
База данных
Особенности и основные идеи системы SumSeg-2
Большое количество различных весов и порогов.
База данных

Слайд 25Векторно-пространственная модель-1
Алгебраическая модель представления текстовых документов (в общем случае любых объектов) в
Векторно-пространственная модель-1
Алгебраическая модель представления текстовых документов (в общем случае любых объектов) в

Слайд 26Векторно-пространственная модель-2
Пример: Пусть есть два предложения. «Мама мыла раму» и «Папа мыл
Векторно-пространственная модель-2
Пример: Пусть есть два предложения. «Мама мыла раму» и «Папа мыл

Слайд 27Направление дальнейшей работы
Первоочередная задача – реализация векторно - пространственной модели и попытка
Направление дальнейшей работы
Первоочередная задача – реализация векторно - пространственной модели и попытка

 Деятельность. Лекция №2
Деятельность. Лекция №2 Танец тени. Такие разные Я
Танец тени. Такие разные Я Иванова Варвара Александровна
Иванова Варвара Александровна Сочи: Вчера. Сегодня. Завтра. (Симметрия в архитектуре)
Сочи: Вчера. Сегодня. Завтра. (Симметрия в архитектуре) Поведенческие теории 2
Поведенческие теории 2 Виды случайных событий
Виды случайных событий ВИРТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ТРЕХМЕРНЫХ СЦЕН
ВИРТУАЛЬНОЕ МОДЕЛИРОВАНИЕ ТРЕХМЕРНЫХ СЦЕН Таможенное право. Лекция 1
Таможенное право. Лекция 1 ВКР: сравнительный анализ рефлексии у студентов различных направлений подготовки
ВКР: сравнительный анализ рефлексии у студентов различных направлений подготовки 1832__
1832__ Урок – ПРЕЗЕНТАЦИЯ по геометрии в 9? классе.
Урок – ПРЕЗЕНТАЦИЯ по геометрии в 9? классе. Самореализующееся пророчество (Эффект Розенталя)
Самореализующееся пророчество (Эффект Розенталя) Психологические особенности ответственности и личностной тревожности молодых людей
Психологические особенности ответственности и личностной тревожности молодых людей Тормозной путь автомобиля
Тормозной путь автомобиля Возможные макрофизические проявления гипотетического нейтринного заряда.
Возможные макрофизические проявления гипотетического нейтринного заряда. Практические инструменты маркетинга в бизнесе
Практические инструменты маркетинга в бизнесе Избирательная система
Избирательная система Использование вихревого эффекта в зерновой промышленности
Использование вихревого эффекта в зерновой промышленности "ВВЕДЕНИЕ В ИНФОРМАТИКУ"
"ВВЕДЕНИЕ В ИНФОРМАТИКУ" РАБОТА С ИЗДАТЕЛЬСТВАМИ. АССОРТИМЕНТ ПЕРИОДИЧЕСКИХ ИЗДАНИЙ. КОНТРОЛЬ ПРОДАЖ. ВОЗВРАТ НЕРЕАЛИЗОВАННЫХ ЭКЗЕМПЛЯРОВ.
РАБОТА С ИЗДАТЕЛЬСТВАМИ. АССОРТИМЕНТ ПЕРИОДИЧЕСКИХ ИЗДАНИЙ. КОНТРОЛЬ ПРОДАЖ. ВОЗВРАТ НЕРЕАЛИЗОВАННЫХ ЭКЗЕМПЛЯРОВ. Зрительные иллюзии в одежде
Зрительные иллюзии в одежде Картины исторические и бытовые
Картины исторические и бытовые Презентация на тему Угол поворота. Радианная мера угла
Презентация на тему Угол поворота. Радианная мера угла Выполнил: Котов О.Ю 5 курс, 4.1 группа Ставрополь 2010. - презентация
Выполнил: Котов О.Ю 5 курс, 4.1 группа Ставрополь 2010. - презентация Основы Технологического Бизнеса.
Основы Технологического Бизнеса. X Международная научно-практическая конференция Молодежь и будущее: профессиональная и личностная самореализация
X Международная научно-практическая конференция Молодежь и будущее: профессиональная и личностная самореализация Пищевые улучшители и добавки
Пищевые улучшители и добавки ДЕЕПРИЧАСТИЕ КАК ЧАСТЬ РЕЧИ
ДЕЕПРИЧАСТИЕ КАК ЧАСТЬ РЕЧИ