- Оптимизация LAMP-приложения на примере OpenX: разгоняемся до 1000 запросов в секунду

Содержание
- 2. Кто я? alexander@[email protected]@[email protected], [email protected] http://alexclear.livejournal.com Работаю разработчиком ПО с 1998 года В настоящее время – разработка
- 3. Почему я? Нагрузка 500-5000 пользователей в день есть у всех Нагрузка 100500 запросов в секунду –
- 4. Постановка задачи OpenX – существующее open source веб- приложение для показа рекламы Linux, Apache, MySQL, PHP
- 5. Предметная область OpenX: баннеры, кампании, зоны, пользователи Баннеры – собственно, баннеры Пользователи – управляют баннерами Кампании
- 6. Начало Одна виртуальная машина в локальной сети 1000 баннеров, 1 зона, 1 кампания ~ 5 запросов
- 7. Требования Заказчик – большая компания, требования расплывчаты 200000 баннеров, 400-700 запросов в секунду
- 8. Особенности OpenX Расчет весов баннеров непосредственно в PHP коде при каждом показе Продукт уже оптимизирован, есть
- 9. Расчет весов Несколько циклов в PHP-коде 200000 баннеров – 200000 повторений в циклах Внутренние объекты PHP
- 10. Оптимизация Декомпозиция объектов до уровня отдельных полей, вынос полей в memcached Веса рассчитываются один раз в
- 11. Первые проблемы Много запросов к memcached, он почему-то не работает – переход к хранению данных в
- 12. Тестирование: средства Siege, JMeter JMeter: создание разветвеленных сценариев, GUI Siege: URL не меняется, командная строка Siege:
- 13. Тестирование: результаты От трех до семи нод, одна DB Проблемы: ноды перетирают данные в базе (нет
- 14. Решение проблем Назад к memcached (slab allocator) php-memcached работает, php-memcache - нет Нет под Debian Lenny,
- 15. Новые вводные данные Заказчик – большая компания, нас тоже много Требования конкретизируются прямо на ходу Зон
- 16. Новые проблемы Если веса нельзя кэшировать, нужно их пересчитывать Данные кэшируются для зоны, 100 зон –
- 17. Варианты решения Поменять алгоритм выбора – варианты? Non-uniform distribution -> uniform distribution – только через отрезок,
- 18. Компромисс Баннеров в зоне не более 200 Зон по-прежнему может быть 100 Всего три типа limitations
- 19. Изменения в коде Объекты баннеров до применения limitations хранятся в DB Limitations транслируются из срокового представления
- 20. Пара слов о хостинге Первый этап – Amazon EC2 Миграция на Rackspace Cloud Проблемы: средняя нода
- 21. Тестирование: средства Siege не подходит: 100 зон, около 50 параметров для каждого из лимитов – нужно
- 22. Tsung Tsung: написан на Erlang – распределенность на уровне VM языка Создавался с учетом многонодовых конфигураций
- 23. Архитектура Представлена на картинке Картинку перерисовывали 7 раз
- 24. Распределение нагрузки nginx, HAProxy nginx – HTTP/1.0, генерирует кучу соединений, нет встроенного мониторинга состояния HAProxy –
- 25. Тестирование: проблемы 1 8 web-nod, одна DB, 100 rps Одна нода memcached не выдерживает поток запросов
- 26. Тестирование: проблемы 2 12 web-nod, одна DB, ~250 rps Большая нагрузка на web-ноды Из 4-х циклов
- 27. Тестирование: проблемы 3 Включили maintenance скрипт в cron – перестала справляться DB Суть проблемы: раз в
- 28. Декомпозиция DB, тюнинг выделенной части Выделение raw logs в отдельную базу на отдельном узле Попытка поменять
- 29. Варианты решения MariaDB vs Percona Server – разницы в производительности нет MySQL vs PostgreSQL NoSQL vs
- 30. Мониторинг Zabbix, Cacti Cacti: mysql-cacti-templates от коллег из Percona Zabbix: сильно нагружает сервер, data backend не
- 31. Тюнинг FS По умолчанию ext3 с data=ordered Перемонтировали с data=writeback, iowait вместо ~10% стал ~1.5% Перемонтировали
- 32. Тестирование: проблемы 4 Теперь не справляются кэш-таблицы На MySQL скачки I/O Большое количество uncheckpointed bytes в
- 33. Тестирование: проблемы 5 12 web-нод, ~300 rps, три ноды DB Проблема: скачки I/O на cache DB
- 34. Шардинг Мысли о шардинге были с самого начала, но по какому параметру разделять по шардам? И
- 35. Тестирование 12 web-нод, 300 rps, три ноды cache DB, одна нода raw logs DB и одна
- 36. Предел ~700 rps – начинаются ошибки на балансере Мониторинг: нет корреляции с событиями в системе Что
- 37. Отказоустойчивость SPOF – распределенные узлы memcached При падении одного узла таймаут на обращении к нему –
- 38. Отказоустойчивость: Moxi Проксирование запросов к memcached – Moxi Составная часть проекта Membase Работает на 127.0.0.1:11211 Знает
- 39. Отказоустойчивость: Membase Работает на порту memcached по его протоколу Два режима работы: с persistence и как
- 40. Отказоустойчивость: MySQL Master-slave репликация – не средство обеспечения автоматической отказоустойчивости Master-master репликация – менее распространена, делается
- 41. Развертывание Chef, Puppet Оба написаны на Ruby Про Puppet есть книга, про Chef нет Chef более
- 42. Команда Участвовало от 5 до 8 человек Разработка, интеграция, тестирование, документирование, координация Производительностью занимались выделенные разработчики
- 43. Что дальше? Security assesment Deployment Релиз Задача: распределить ввод-вывод по нескольким нодам параллельно Задача: обсчитывать большие
- 44. Выводы Времени всегда очень мало, вариантов может быть очень много Система не должна быть черным ящиком
- 45. Вопросы?
- 47. Скачать презентацию
Слайд 2Кто я?
alexander@[email protected]@[email protected], [email protected]
http://alexclear.livejournal.com
Работаю разработчиком ПО с 1998 года
В настоящее время – разработка
Кто я?
alexander@[email protected]@[email protected], [email protected]
http://alexclear.livejournal.com
Работаю разработчиком ПО с 1998 года
В настоящее время – разработка

Слайд 3Почему я?
Нагрузка 500-5000 пользователей в день есть у всех
Нагрузка 100500 запросов в
Почему я?
Нагрузка 500-5000 пользователей в день есть у всех
Нагрузка 100500 запросов в

Слайд 4Постановка задачи
OpenX – существующее open source веб- приложение для показа рекламы
Linux, Apache,
Постановка задачи
OpenX – существующее open source веб- приложение для показа рекламы
Linux, Apache,

Слайд 5Предметная область
OpenX: баннеры, кампании, зоны, пользователи
Баннеры – собственно, баннеры
Пользователи – управляют баннерами
Кампании
Предметная область
OpenX: баннеры, кампании, зоны, пользователи
Баннеры – собственно, баннеры
Пользователи – управляют баннерами
Кампании

Слайд 6Начало
Одна виртуальная машина в локальной сети
1000 баннеров, 1 зона, 1 кампания
~ 5
Начало
Одна виртуальная машина в локальной сети
1000 баннеров, 1 зона, 1 кампания
~ 5

Слайд 7Требования
Заказчик – большая компания, требования расплывчаты
200000 баннеров, 400-700 запросов в секунду
Требования
Заказчик – большая компания, требования расплывчаты
200000 баннеров, 400-700 запросов в секунду

Слайд 8Особенности OpenX
Расчет весов баннеров непосредственно в PHP коде при каждом показе
Продукт уже
Особенности OpenX
Расчет весов баннеров непосредственно в PHP коде при каждом показе
Продукт уже

Слайд 9Расчет весов
Несколько циклов в PHP-коде
200000 баннеров – 200000 повторений в циклах
Внутренние объекты
Расчет весов
Несколько циклов в PHP-коде
200000 баннеров – 200000 повторений в циклах
Внутренние объекты

Слайд 10Оптимизация
Декомпозиция объектов до уровня отдельных полей, вынос полей в memcached
Веса рассчитываются один
Оптимизация
Декомпозиция объектов до уровня отдельных полей, вынос полей в memcached
Веса рассчитываются один

Слайд 11Первые проблемы
Много запросов к memcached, он почему-то не работает – переход к
Первые проблемы
Много запросов к memcached, он почему-то не работает – переход к

Слайд 12Тестирование: средства
Siege, JMeter
JMeter: создание разветвеленных сценариев, GUI
Siege: URL не меняется, командная строка
Siege:
Тестирование: средства
Siege, JMeter
JMeter: создание разветвеленных сценариев, GUI
Siege: URL не меняется, командная строка
Siege:

Слайд 13Тестирование: результаты
От трех до семи нод, одна DB
Проблемы: ноды перетирают данные в
Тестирование: результаты
От трех до семи нод, одна DB
Проблемы: ноды перетирают данные в

Слайд 14Решение проблем
Назад к memcached (slab allocator)
php-memcached работает, php-memcache - нет
Нет под Debian
Решение проблем
Назад к memcached (slab allocator)
php-memcached работает, php-memcache - нет
Нет под Debian

Слайд 15Новые вводные данные
Заказчик – большая компания, нас тоже много
Требования конкретизируются прямо на
Новые вводные данные
Заказчик – большая компания, нас тоже много
Требования конкретизируются прямо на

Слайд 16Новые проблемы
Если веса нельзя кэшировать, нужно их пересчитывать
Данные кэшируются для зоны, 100
Новые проблемы
Если веса нельзя кэшировать, нужно их пересчитывать
Данные кэшируются для зоны, 100

Слайд 17Варианты решения
Поменять алгоритм выбора – варианты?
Non-uniform distribution -> uniform distribution – только
Варианты решения
Поменять алгоритм выбора – варианты?
Non-uniform distribution -> uniform distribution – только

Слайд 18Компромисс
Баннеров в зоне не более 200
Зон по-прежнему может быть 100
Всего три типа
Компромисс
Баннеров в зоне не более 200
Зон по-прежнему может быть 100
Всего три типа

Слайд 19Изменения в коде
Объекты баннеров до применения limitations хранятся в DB
Limitations транслируются из
Изменения в коде
Объекты баннеров до применения limitations хранятся в DB
Limitations транслируются из

Слайд 20Пара слов о хостинге
Первый этап – Amazon EC2
Миграция на Rackspace Cloud
Проблемы: средняя
Пара слов о хостинге
Первый этап – Amazon EC2
Миграция на Rackspace Cloud
Проблемы: средняя

Слайд 21Тестирование: средства
Siege не подходит: 100 зон, около 50 параметров для каждого из
Тестирование: средства
Siege не подходит: 100 зон, около 50 параметров для каждого из

Слайд 22Tsung
Tsung: написан на Erlang – распределенность на уровне VM языка
Создавался с учетом
Tsung
Tsung: написан на Erlang – распределенность на уровне VM языка
Создавался с учетом

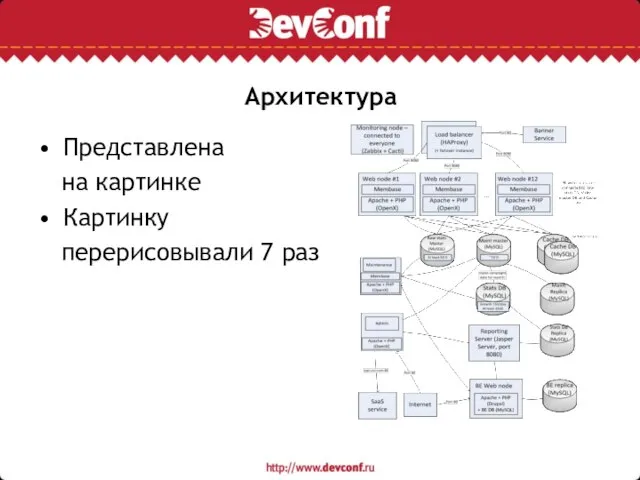
Слайд 23Архитектура
Представлена
на картинке
Картинку
перерисовывали 7 раз
Архитектура
Представлена
на картинке
Картинку
перерисовывали 7 раз
Слайд 24Распределение нагрузки
nginx, HAProxy
nginx – HTTP/1.0, генерирует кучу соединений, нет встроенного мониторинга состояния
HAProxy
Распределение нагрузки
nginx, HAProxy
nginx – HTTP/1.0, генерирует кучу соединений, нет встроенного мониторинга состояния
HAProxy

Слайд 25Тестирование: проблемы 1
8 web-nod, одна DB, 100 rps
Одна нода memcached не выдерживает
Тестирование: проблемы 1
8 web-nod, одна DB, 100 rps
Одна нода memcached не выдерживает

Слайд 26Тестирование: проблемы 2
12 web-nod, одна DB, ~250 rps
Большая нагрузка на web-ноды
Из 4-х
Тестирование: проблемы 2
12 web-nod, одна DB, ~250 rps
Большая нагрузка на web-ноды
Из 4-х

Слайд 27Тестирование: проблемы 3
Включили maintenance скрипт в cron – перестала справляться DB
Суть проблемы:
Тестирование: проблемы 3
Включили maintenance скрипт в cron – перестала справляться DB
Суть проблемы:

Слайд 28Декомпозиция DB, тюнинг выделенной части
Выделение raw logs в отдельную базу на отдельном
Декомпозиция DB, тюнинг выделенной части
Выделение raw logs в отдельную базу на отдельном

Слайд 29Варианты решения
MariaDB vs Percona Server – разницы в производительности нет
MySQL vs PostgreSQL
NoSQL
Варианты решения
MariaDB vs Percona Server – разницы в производительности нет
MySQL vs PostgreSQL
NoSQL

Слайд 30Мониторинг
Zabbix, Cacti
Cacti: mysql-cacti-templates от коллег из Percona
Zabbix: сильно нагружает сервер, data backend
Мониторинг
Zabbix, Cacti
Cacti: mysql-cacti-templates от коллег из Percona
Zabbix: сильно нагружает сервер, data backend

Слайд 31Тюнинг FS
По умолчанию ext3 с data=ordered
Перемонтировали с data=writeback, iowait вместо ~10% стал
Тюнинг FS
По умолчанию ext3 с data=ordered
Перемонтировали с data=writeback, iowait вместо ~10% стал

Слайд 32Тестирование: проблемы 4
Теперь не справляются кэш-таблицы
На MySQL скачки I/O
Большое количество uncheckpointed bytes
Тестирование: проблемы 4
Теперь не справляются кэш-таблицы
На MySQL скачки I/O
Большое количество uncheckpointed bytes

Слайд 33Тестирование: проблемы 5
12 web-нод, ~300 rps, три ноды DB
Проблема: скачки I/O на
Тестирование: проблемы 5
12 web-нод, ~300 rps, три ноды DB
Проблема: скачки I/O на

Слайд 34Шардинг
Мысли о шардинге были с самого начала, но по какому параметру разделять
Шардинг
Мысли о шардинге были с самого начала, но по какому параметру разделять

Слайд 35Тестирование
12 web-нод, 300 rps, три ноды cache DB, одна нода raw logs
Тестирование
12 web-нод, 300 rps, три ноды cache DB, одна нода raw logs

Слайд 36Предел
~700 rps – начинаются ошибки на балансере
Мониторинг: нет корреляции с событиями в
Предел
~700 rps – начинаются ошибки на балансере
Мониторинг: нет корреляции с событиями в

Слайд 37Отказоустойчивость
SPOF – распределенные узлы memcached
При падении одного узла таймаут на обращении к
Отказоустойчивость
SPOF – распределенные узлы memcached
При падении одного узла таймаут на обращении к

Слайд 38Отказоустойчивость: Moxi
Проксирование запросов к memcached – Moxi
Составная часть проекта Membase
Работает на 127.0.0.1:11211
Знает
Отказоустойчивость: Moxi
Проксирование запросов к memcached – Moxi
Составная часть проекта Membase
Работает на 127.0.0.1:11211
Знает

Слайд 39Отказоустойчивость: Membase
Работает на порту memcached по его протоколу
Два режима работы: с persistence
Отказоустойчивость: Membase
Работает на порту memcached по его протоколу
Два режима работы: с persistence

Слайд 40Отказоустойчивость: MySQL
Master-slave репликация – не средство обеспечения автоматической отказоустойчивости
Master-master репликация – менее
Отказоустойчивость: MySQL
Master-slave репликация – не средство обеспечения автоматической отказоустойчивости
Master-master репликация – менее

Слайд 41Развертывание
Chef, Puppet
Оба написаны на Ruby
Про Puppet есть книга, про Chef нет
Chef более
Развертывание
Chef, Puppet
Оба написаны на Ruby
Про Puppet есть книга, про Chef нет
Chef более

Слайд 42Команда
Участвовало от 5 до 8 человек
Разработка, интеграция, тестирование, документирование, координация
Производительностью занимались выделенные
Команда
Участвовало от 5 до 8 человек
Разработка, интеграция, тестирование, документирование, координация
Производительностью занимались выделенные

Слайд 43Что дальше?
Security assesment
Deployment
Релиз
Задача: распределить ввод-вывод по нескольким нодам параллельно
Задача: обсчитывать большие объемы
Что дальше?
Security assesment
Deployment
Релиз
Задача: распределить ввод-вывод по нескольким нодам параллельно
Задача: обсчитывать большие объемы

Слайд 44Выводы
Времени всегда очень мало, вариантов может быть очень много
Система не должна быть
Выводы
Времени всегда очень мало, вариантов может быть очень много
Система не должна быть

Слайд 45Вопросы?
Вопросы?

 Презентация на тему Использование информационных технологий в дошкольном образовании
Презентация на тему Использование информационных технологий в дошкольном образовании Унҗиденче март. Билгеле үткән заман хикәя фигыль
Унҗиденче март. Билгеле үткән заман хикәя фигыль доц.д-р Десислава Бошнакова, зам. ректор на НБУ и управител на ROI Communication
доц.д-р Десислава Бошнакова, зам. ректор на НБУ и управител на ROI Communication Химическое равновесие
Химическое равновесие Нормативные основания для прохождения ЕГЭ
Нормативные основания для прохождения ЕГЭ Влияние цвета на здоровье
Влияние цвета на здоровье Приключения в Англии
Приключения в Англии «Переход на электронный документооборот стал актуальным! Алгоритм действий»Пальчиков И.И.«Такском»
«Переход на электронный документооборот стал актуальным! Алгоритм действий»Пальчиков И.И.«Такском» Шаблон описания предприятия
Шаблон описания предприятия Книжное дело
Книжное дело Алтайский заповедник
Алтайский заповедник Музыкальная терапиякак средство творческого развития ребенка
Музыкальная терапиякак средство творческого развития ребенка אנחנו רוצים מחברות חדשות
אנחנו רוצים מחברות חדשות Presentation Title
Presentation Title  Значение молока в питании человека
Значение молока в питании человека The Turkic khanate
The Turkic khanate Формулы квадрата суммы и квадрата разности двух выражений
Формулы квадрата суммы и квадрата разности двух выражений Химическая промышленность Украины
Химическая промышленность Украины Презентация на тему Энергетические напитки - польза или вред
Презентация на тему Энергетические напитки - польза или вред Лекция 3. Этапы разработки проекта
Лекция 3. Этапы разработки проекта Сейсмические пояса
Сейсмические пояса Мингазутдинова М. 343 гр Содержание и направления работы с родителями при организации тренинговой работы с детьми
Мингазутдинова М. 343 гр Содержание и направления работы с родителями при организации тренинговой работы с детьми Отделы руководства в гражданской авиации
Отделы руководства в гражданской авиации МУНИЦИПАЛЬНОЕ БЮДЖЕТНОЕДОШКОЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ «ДЕТСКИЙ САД № 47 «ЗЕЛЕНЫЙ ОГОНЕК» КОМПЕНСИРУЮЩЕГО ВИДА» г. Север
МУНИЦИПАЛЬНОЕ БЮДЖЕТНОЕДОШКОЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ «ДЕТСКИЙ САД № 47 «ЗЕЛЕНЫЙ ОГОНЕК» КОМПЕНСИРУЮЩЕГО ВИДА» г. Север ФСС РФ
ФСС РФ Велесов день - середина зимы. Фольклорное путешествие
Велесов день - середина зимы. Фольклорное путешествие РУССКИЙ ЯЗЫК
РУССКИЙ ЯЗЫК Имидж, поведение, репутация как фактор жизненного успеха
Имидж, поведение, репутация как фактор жизненного успеха