- Особенности масштабирования систем планирования и управления поставками

Содержание
- 2. Масштабируемость нужна крупным: Интернет-проектам highscalability.com А также банкам, биржам, интернет-провайдерам, системам планирования поставок и еще много
- 3. Как выглядит управление поставками (supply chain management, SCM) Сверху вниз –производится и поставляется товар Снизу вверх
- 4. Из каких компонентов состоит?
- 5. Что делает ритейлер? Заказывает товары у вендоров Продает их покупателям в своих магазинах (В идеале) получает
- 6. Что нужно ритейлеру от SCM-системы? Получать данные о происходящем в его магазинах (продажи, скидки и т.п.)
- 7. Какие трудности при разработке? Крупные компании медлительны «быстро уточнить» или «попросить исправить на своей стороне» трудно
- 8. Специфика масштабирования – пользователи Их мало (десятки, сотни), и они эксперты в предметной области Обычно они
- 9. Специфика масштабирования – данные Их много, и их надо хранить и обрабатывать 2 тысячи магазинов *
- 10. Специфика масштабирования – данные, ч.2 Их надо обрабатывать Статистический (долгосрочный) прогноз Эвристический (краткосрочный) прогноз Создание заказов
- 11. Стек технологий Oracle 10g / 11g, RAC (RedHat Linux) Java 1.6, JBoss AS 4.2 (Windows 2003)
- 12. Собственно масштабирование Хранение массивных таблиц и индексов Быстрая загрузка интеграционных данных извне Оптимизация отдельных запросов Настройка
- 13. Oracle Partitioning Разбиение таблиц и индексов на отдельные секции Которыми можно управлять индивидуально (add, drop, move,
- 14. Примеры table partitioning List partitioning CREATE TABLE employers ( emp_no NUMBER PRIMARY KEY, ename VARCHAR2(30), deptno
- 15. Загрузка данных - Oracle SQL Loader
- 16. Пример использования SQL Loader Control file load data CHARACTERSET UTF8 infile 'c:\data\mydata.csv' into table employer fields
- 17. SQL Loader – ускорение загрузки Два режима загрузки - Conventional Load и Direct Path Load Отключение
- 18. 2-х шаговая загрузка через SQL Loader Создаем временную таблицу той же структуры, что и CSV-файл, загружаем
- 19. External tables Хранятся не внутри tablespace, а как указатели на внешний flat file Позволяют обращаться к
- 20. Жизненный цикл запроса Проверка синтаксиса Проверки обращений к объектам БД Трансформация запроса оптимизатором Оценка статистики, выбор
- 21. Explain plan Иерархичен Измеряется в costs – смысл зависит от модели оптимизации Требует знания: Базовых методов
- 22. Мониторинг БД – Oracle Grid Control
- 23. Oracle Grid Control - продолжение
- 24. Transient Kernel Profiler (tkprof) alter session set sql_trace=true; alter session set timed_statistics=true; Форматирование файла трассировки Анализ
- 25. Оптимизация UI Пре-агрегирование данных (materialized views, вспомогательные таблицы с ручным обновлением) Вынос туда повторяющихся «тяжелых» частей
- 26. Оптимизация engines Выделение цепочки engines для обработки данных Выделение групп данных, которые могут рассчитываться независимо друг
- 27. Выводы о масштабируемости Узкое место – I/O на серверах БД Хотя многие операции проще и быстрее
- 29. Скачать презентацию
Слайд 2Масштабируемость нужна крупным:
Интернет-проектам
highscalability.com
А также банкам, биржам, интернет-провайдерам, системам планирования поставок и еще
Масштабируемость нужна крупным:
Интернет-проектам
highscalability.com
А также банкам, биржам, интернет-провайдерам, системам планирования поставок и еще

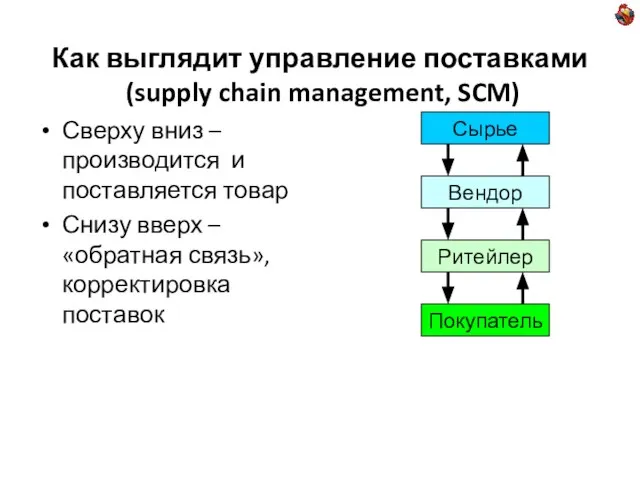
Слайд 3Как выглядит управление поставками
(supply chain management, SCM)
Сверху вниз –производится и поставляется
Как выглядит управление поставками
(supply chain management, SCM)
Сверху вниз –производится и поставляется
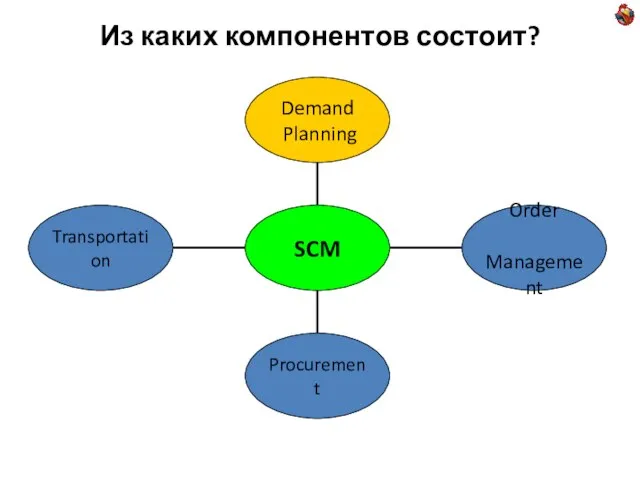
Слайд 4Из каких компонентов состоит?
Из каких компонентов состоит?
Слайд 5Что делает ритейлер?
Заказывает товары у вендоров
Продает их покупателям в своих магазинах
(В идеале)
Что делает ритейлер?
Заказывает товары у вендоров
Продает их покупателям в своих магазинах
(В идеале)

Слайд 6Что нужно ритейлеру от SCM-системы?
Получать данные о происходящем в его магазинах (продажи,
Что нужно ритейлеру от SCM-системы?
Получать данные о происходящем в его магазинах (продажи,

Слайд 7Какие трудности при разработке?
Крупные компании медлительны
«быстро уточнить» или «попросить исправить на своей
Какие трудности при разработке?
Крупные компании медлительны
«быстро уточнить» или «попросить исправить на своей

Слайд 8Специфика масштабирования –
пользователи
Их мало (десятки, сотни), и они эксперты в предметной
Специфика масштабирования –
пользователи
Их мало (десятки, сотни), и они эксперты в предметной

Слайд 9Специфика масштабирования –
данные
Их много, и их надо хранить и обрабатывать
2 тысячи
Специфика масштабирования –
данные
Их много, и их надо хранить и обрабатывать
2 тысячи

Слайд 10Специфика масштабирования –
данные, ч.2
Их надо обрабатывать
Статистический (долгосрочный) прогноз
Эвристический (краткосрочный) прогноз
Создание заказов
Время
Специфика масштабирования –
данные, ч.2
Их надо обрабатывать
Статистический (долгосрочный) прогноз
Эвристический (краткосрочный) прогноз
Создание заказов
Время

Слайд 11Стек технологий
Oracle 10g / 11g, RAC (RedHat Linux)
Java 1.6, JBoss AS 4.2
Стек технологий
Oracle 10g / 11g, RAC (RedHat Linux)
Java 1.6, JBoss AS 4.2

Слайд 12Собственно масштабирование
Хранение массивных таблиц и индексов
Быстрая загрузка интеграционных данных извне
Оптимизация отдельных
Собственно масштабирование
Хранение массивных таблиц и индексов
Быстрая загрузка интеграционных данных извне
Оптимизация отдельных

Слайд 13Oracle Partitioning
Разбиение таблиц и индексов на отдельные секции
Которыми можно управлять индивидуально
Oracle Partitioning
Разбиение таблиц и индексов на отдельные секции
Которыми можно управлять индивидуально

Слайд 14Примеры table partitioning
List partitioning
CREATE TABLE employers (
emp_no NUMBER PRIMARY KEY,
ename VARCHAR2(30),
deptno NUMBER)
PARTITION BY LIST (deptno) (
Примеры table partitioning
List partitioning
CREATE TABLE employers (
emp_no NUMBER PRIMARY KEY,
ename VARCHAR2(30),
deptno NUMBER)
PARTITION BY LIST (deptno) (

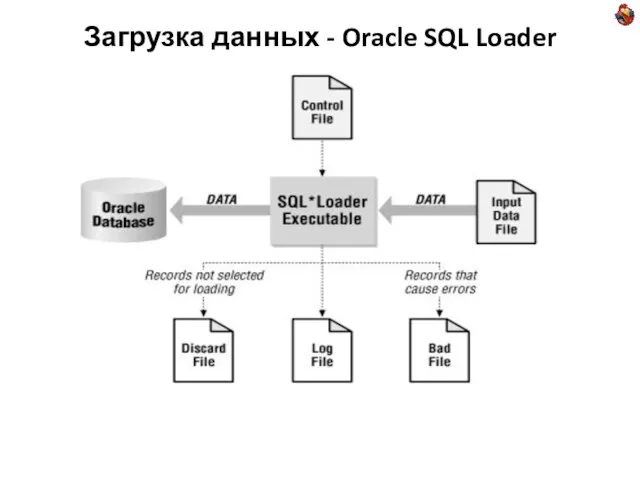
Слайд 15Загрузка данных - Oracle SQL Loader
Загрузка данных - Oracle SQL Loader
Слайд 16Пример использования SQL Loader
Control file
load data
CHARACTERSET UTF8
infile 'c:\data\mydata.csv'
into table employer
fields terminated by
Пример использования SQL Loader
Control file
load data
CHARACTERSET UTF8
infile 'c:\data\mydata.csv'
into table employer
fields terminated by

Слайд 17SQL Loader – ускорение загрузки
Два режима загрузки - Conventional Load и Direct
SQL Loader – ускорение загрузки
Два режима загрузки - Conventional Load и Direct

Слайд 182-х шаговая загрузка через SQL Loader
Создаем временную таблицу той же структуры, что
2-х шаговая загрузка через SQL Loader
Создаем временную таблицу той же структуры, что

Слайд 19External tables
Хранятся не внутри tablespace, а как указатели на внешний flat file
Позволяют
External tables
Хранятся не внутри tablespace, а как указатели на внешний flat file
Позволяют

Слайд 20Жизненный цикл запроса
Проверка синтаксиса
Проверки обращений к объектам БД
Трансформация запроса оптимизатором
Оценка статистики, выбор
Жизненный цикл запроса
Проверка синтаксиса
Проверки обращений к объектам БД
Трансформация запроса оптимизатором
Оценка статистики, выбор

Слайд 21Explain plan
Иерархичен
Измеряется в costs – смысл зависит от модели оптимизации
Требует знания:
Базовых методов
Explain plan
Иерархичен
Измеряется в costs – смысл зависит от модели оптимизации
Требует знания:
Базовых методов

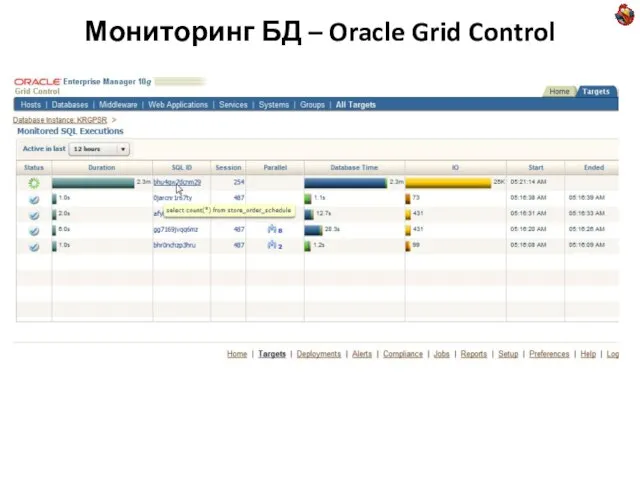
Слайд 22Мониторинг БД – Oracle Grid Control
Мониторинг БД – Oracle Grid Control
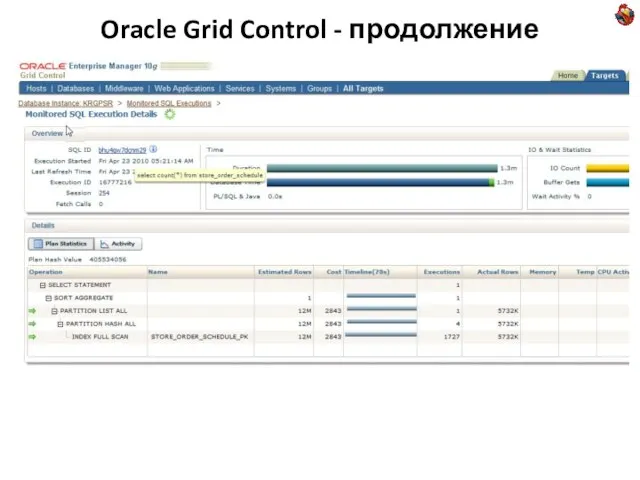
Слайд 23Oracle Grid Control - продолжение
Oracle Grid Control - продолжение
Слайд 24Transient Kernel Profiler (tkprof)
alter session set sql_trace=true;
alter session set timed_statistics=true;
<Выполнение любых запросов>
Форматирование
Transient Kernel Profiler (tkprof)
alter session set sql_trace=true;
alter session set timed_statistics=true;
<Выполнение любых запросов>
Форматирование

Слайд 25Оптимизация UI
Пре-агрегирование данных (materialized views,
вспомогательные таблицы с ручным обновлением)
Вынос туда повторяющихся
Оптимизация UI
Пре-агрегирование данных (materialized views,
вспомогательные таблицы с ручным обновлением)
Вынос туда повторяющихся

Слайд 26Оптимизация engines
Выделение цепочки engines для обработки данных
Выделение групп данных, которые могут рассчитываться
Оптимизация engines
Выделение цепочки engines для обработки данных
Выделение групп данных, которые могут рассчитываться

Слайд 27Выводы о масштабируемости
Узкое место – I/O на серверах БД
Хотя многие операции проще
Выводы о масштабируемости
Узкое место – I/O на серверах БД
Хотя многие операции проще

 Грегор Иоганн Мендель
Грегор Иоганн Мендель Презентация на тему Архитектурный облик Древней Руси
Презентация на тему Архитектурный облик Древней Руси Рекламное агентство Фолькон
Рекламное агентство Фолькон Искусство этрусков и Древнего Рима
Искусство этрусков и Древнего Рима  «Из истории родного края»
«Из истории родного края» Великий мыслитель (страницы жизни Н.И. Лобочевского)
Великий мыслитель (страницы жизни Н.И. Лобочевского) Волшебное число
Волшебное число Выбор оптимального способа сварки при изготовлении сварной конструкции Рама
Выбор оптимального способа сварки при изготовлении сварной конструкции Рама Основы безопасности: сетевые коммутаторы RTT
Основы безопасности: сетевые коммутаторы RTT ЗАО «Черник, Джаарбеков и партнеры»
ЗАО «Черник, Джаарбеков и партнеры» Обобщение опыта работы учителя физической культуры муниципального бюджетного общеобразовательного учреждения средней
Обобщение опыта работы учителя физической культуры муниципального бюджетного общеобразовательного учреждения средней Выполнила: Орел Ю.А. Должность: учитель муз.-теоретических дисциплин
Выполнила: Орел Ю.А. Должность: учитель муз.-теоретических дисциплин Треугольник проекта
Треугольник проекта Язык программирования LOGO
Язык программирования LOGO Модель и моделирование_Светиков_Кирилл_6У
Модель и моделирование_Светиков_Кирилл_6У Правила планирования преемственности
Правила планирования преемственности Советский тыл в Годы Великой Отечественной войны
Советский тыл в Годы Великой Отечественной войны ПРЕЗЕНТАЦИЯСЕРВИСНОГО ЦЕНТРАХ5 Retail Group
ПРЕЗЕНТАЦИЯСЕРВИСНОГО ЦЕНТРАХ5 Retail Group Товарное соседство пищевых продуктов
Товарное соседство пищевых продуктов  УСТАНОВЛЕНИЕ ПРОИСХОЖДЕНИЯ ДЕТЕЙ
УСТАНОВЛЕНИЕ ПРОИСХОЖДЕНИЯ ДЕТЕЙ Папоротники. Особенности строения и жизнедеятельности
Папоротники. Особенности строения и жизнедеятельности Программа "Одаренные дети"
Программа "Одаренные дети" Особенности межличностного взаимодействия. Толерантность
Особенности межличностного взаимодействия. Толерантность Типы товаров
Типы товаров Одежда Курян
Одежда Курян На Билбордах по городу Алматы
На Билбордах по городу Алматы Механика игры Спорт, как искусство
Механика игры Спорт, как искусство Капризы у детей 3-4 лет
Капризы у детей 3-4 лет