Программный комплекс «СМАЛТ». Морфологически размеченный корпус по русской публицистикевторой половины XIX века
- Программный комплекс «СМАЛТ». Морфологически размеченный корпус по русской публицистикевторой половины XIX века

Содержание
- 2. Программный комплекс «СМАЛТ»
- 3. Система подготовки данных для БД
- 4. Особенности морфологического разбора текстов XIX века (орфографическая вариативность) Примеры: очень-многiе, само-по-себе, до-сихъ-поръ, на-дняхъ, какъ-будто, ничемъ другъ-къ-другу
- 5. Виды морфологической разметки Разметка 1 Опирается на следующий инвентарь частей речи: существительное, прилагательное, числительное, местоимение, глагол,
- 6. Фрагмент структуры морфологической разметки Часть речи Глагол Существительное Время ……… ……….. Прошедшее Род Мужской ……….. Падеж
- 7. Статистика словаря Корпус текстов состоит из публицистических статей разной тематической направленности из петербургских журналов «Время», «Эпоха»,
- 8. Преформатирование и грамматический разбор
- 9. Схема доступа к БД Алфавитный словарь Частотный словарь Поиск слов по грамматическим признакам Функция показа выбранного
- 10. Схема доступа к БД Интернет-доступ http://smalt.karelia.ru/projects.html Локальный доступ Быстрая скорость Возможность самостоятельно формировать БД
- 11. Поиск
- 12. Вывод результата
- 13. Вывод контекстов
- 14. Вывод оригинального текста
- 15. Поиск по грамматическим параметрам
- 16. Словарь
- 17. Модуль статистического анализа программного комплекса «СМАЛТ»
- 18. Достоевский редактировал и возглавлял три журнала Время (1861-1863) Эпоха (1864-1865) Гражданин (1873-1874) Издавал свой личный журнал
- 19. Методы анализа текстов Статистические методы Проверка статистических гипотез Разбиение текстов на группы с использованием кластерного анализа
- 20. Авторский инвариант Под авторским инвариантом понимают такую характеристику литературных текстов (некий параметр), которая 1. однозначно характеризует
- 21. Свойства авторского инварианта 1. Она должна быть достаточно «массовой», интегральной, чтобы слабо контролироваться автором на сознательном
- 22. «Некролог. Иван Иванович Панаев», Dubia, «Время», 1862, №2, 16 предложений «Несколько слов о Ристори», А. А.
- 23. «Сильный граф» для произведения «Подписка на 1863 год», Ф. М. Достоевский, «Время», 1862, №9, 161 предложение
- 24. Часть таблицы коэффициентов близости текстов Узловые значение графа устанавливались экспериментально и варьировались от 3 до 6.
- 25. Развитие исследования Гейра Хетсо Отличия: Использование текстов в авторской орфографии и пунктуации; Проверка устойчивости методик на
- 26. Используемые лингвостатистические параметры 1. Средняя длина слова в буквах, вычисляемая на основании выборок размером в 200,
- 27. Средняя длина слова в буквах H0 = {гипотеза о равенстве средних для двух выборок, одна из
- 28. использовалась следующая формула критерия Стьюдента: В этой формуле m1 и m2 - сравниваемые средние частоты, n1
- 29. Средняя длина слова в буквах. Критерий Стьюдента для разных объемов выборки.
- 30. Общее распределение длины слова. Получены данные о том, сколько в каждом тексте слов, имеющих по 1,
- 31. Средняя длина предложения в словах Проводится тест исключительности на основании выборок в 30 предложений. Проверка на
- 32. Общее распределение длины предложения Информация об общем распределении длины предложения была получена по интервалам в 1-5,
- 33. Лексический спектр текста на уровне словаря и Лексический спектр текста на уровне текста Лексический спектр текст
- 34. Индекс разнообразия лексики Индекса разнообразия лексики - отношения числа разных слов к числу словоупотреблений. Исследуется степень
- 35. Результаты исследования Несмотря на использование разных источников и соответственно на наличие некоторых различий, результаты с исследованием
- 36. Основной результат В исследовании Хетсо был использован общий принцип применимости статистических методов. То есть для каждого
- 37. Предположение о том, что распределение частей речи на первых трех и последних трех позициях предложения может
- 38. 1) с номера 1 по 7. Имя существительное (падеж) 2) с номера 8 по 13. Имя
- 39. Иерархическая кластеризация Алгоритмы кластеризации: метод ближайшего соседа метод дальнего соседа Меры близости между объектами: 1. Евклидова
- 40. В результате применения метода иерархической кластеризации оказалось, что невозможно четко выделить две группы объектов, ядро первой
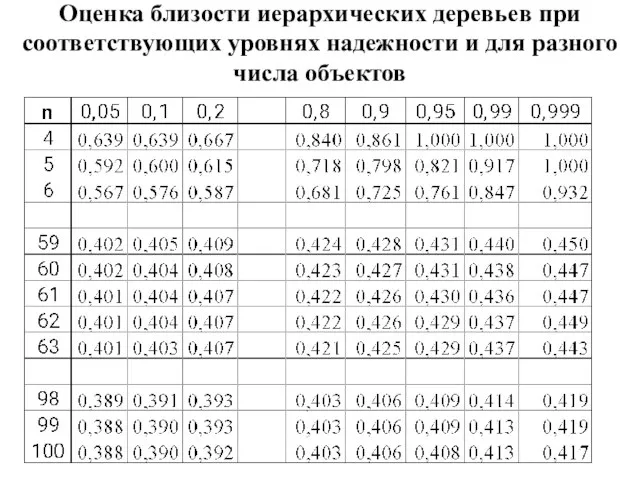
- 41. Оценка близости иерархических деревьев где n-1 показывает число уровней объединения или сечения, а Пусть n –
- 42. Оценка близости иерархических деревьев при соответствующих уровнях надежности и для разного числа объектов
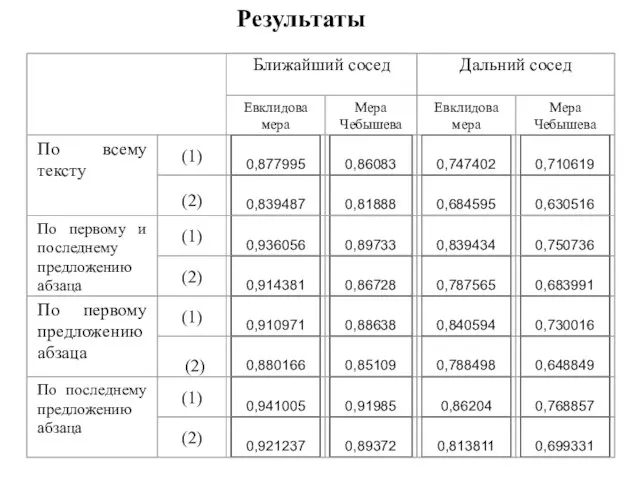
- 43. Результаты
- 45. Скачать презентацию
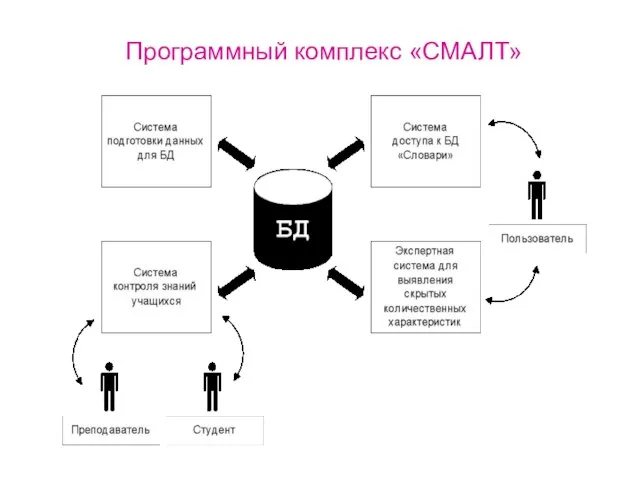
Слайд 3Система подготовки данных для БД
Система подготовки данных для БД
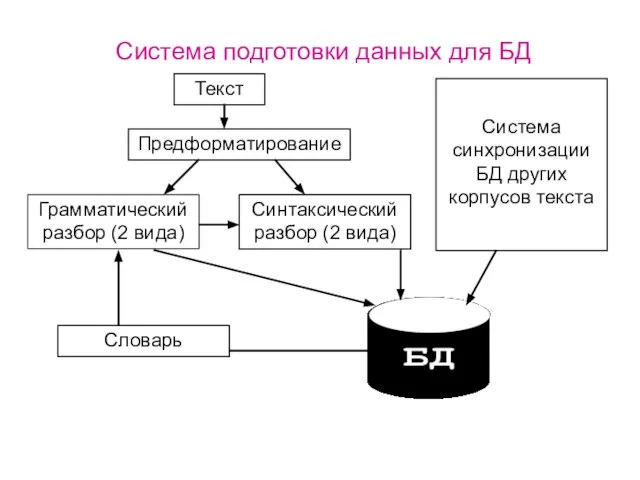
Слайд 4Особенности морфологического разбора текстов XIX века
(орфографическая вариативность)
Примеры: очень-многiе,
само-по-себе, до-сихъ-поръ, на-дняхъ, какъ-будто,
Особенности морфологического разбора текстов XIX века
(орфографическая вариативность)
Примеры: очень-многiе,
само-по-себе, до-сихъ-поръ, на-дняхъ, какъ-будто,
Слайд 5Виды морфологической разметки
Разметка 1
Опирается на следующий инвентарь частей речи: существительное, прилагательное,
Виды морфологической разметки
Разметка 1
Опирается на следующий инвентарь частей речи: существительное, прилагательное,

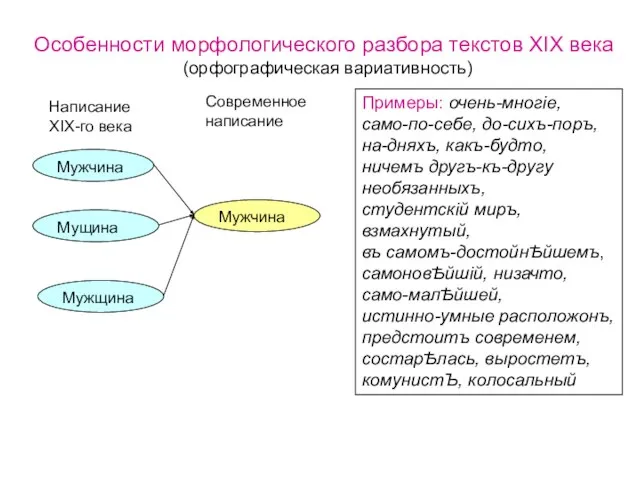
Слайд 6Фрагмент структуры морфологической разметки
Часть речи
Глагол
Существительное
Время
………
………..
Прошедшее
Род
Мужской
………..
Падеж
Именительный
Прилагательное
Число
……….
Фрагмент структуры морфологической разметки
Часть речи
Глагол
Существительное
Время
………
………..
Прошедшее
Род
Мужской
………..
Падеж
Именительный
Прилагательное
Число
……….
Слайд 7Статистика словаря
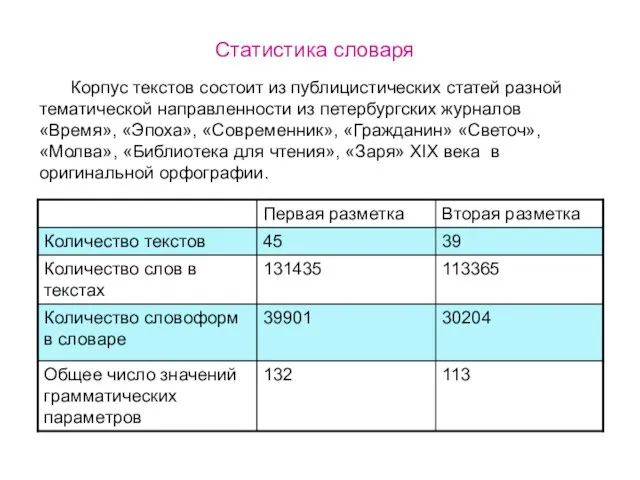
Корпус текстов состоит из публицистических статей разной тематической направленности из петербургских
Статистика словаря
Корпус текстов состоит из публицистических статей разной тематической направленности из петербургских
Слайд 8Преформатирование и грамматический разбор
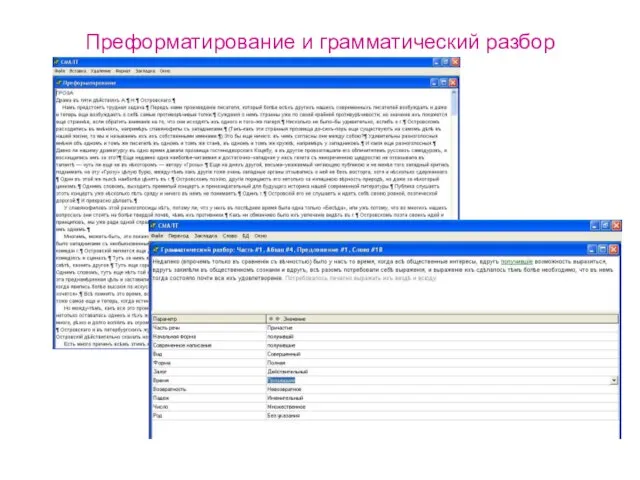
Преформатирование и грамматический разбор
Слайд 9Схема доступа к БД
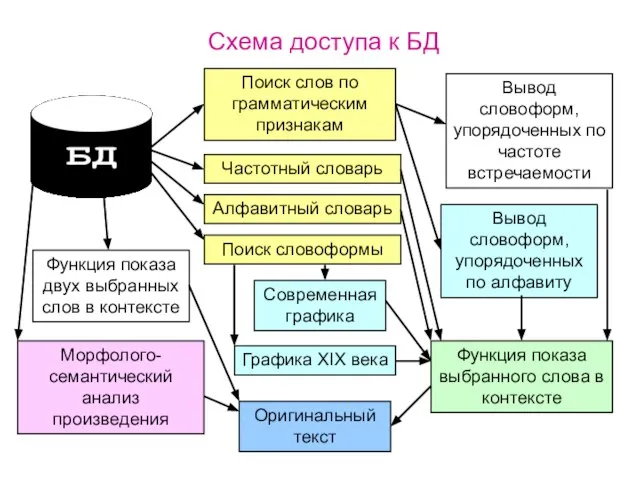
Алфавитный словарь
Частотный словарь
Поиск слов по грамматическим признакам
Функция показа выбранного
Схема доступа к БД
Алфавитный словарь
Частотный словарь
Поиск слов по грамматическим признакам
Функция показа выбранного
Слайд 10Схема доступа к БД
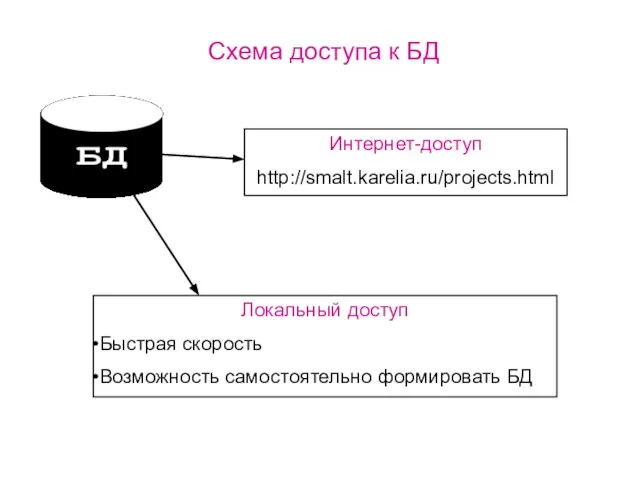
Интернет-доступ
http://smalt.karelia.ru/projects.html
Локальный доступ
Быстрая скорость
Возможность самостоятельно формировать БД
Схема доступа к БД
Интернет-доступ
http://smalt.karelia.ru/projects.html
Локальный доступ
Быстрая скорость
Возможность самостоятельно формировать БД
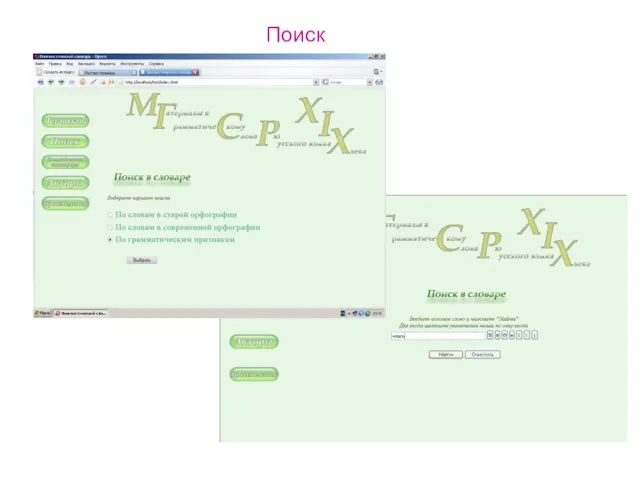
Слайд 11Поиск
Поиск
Слайд 12Вывод результата
Вывод результата
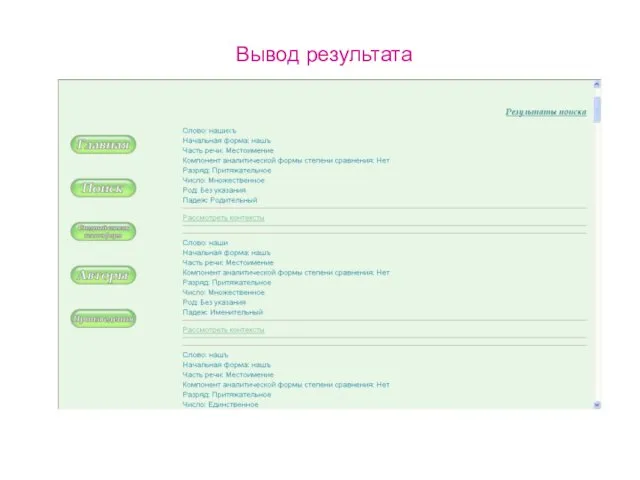
Слайд 13Вывод контекстов
Вывод контекстов

Слайд 14Вывод оригинального текста
Вывод оригинального текста
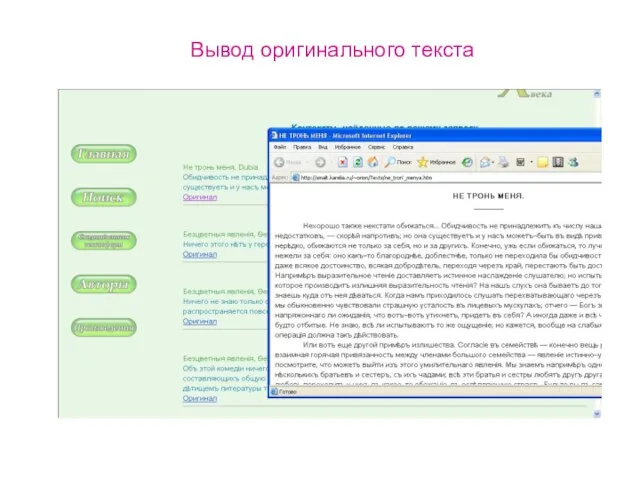
Слайд 15Поиск по грамматическим параметрам
Поиск по грамматическим параметрам

Слайд 16Словарь
Словарь

Слайд 17Модуль статистического анализа программного комплекса «СМАЛТ»
Модуль статистического анализа программного комплекса «СМАЛТ»
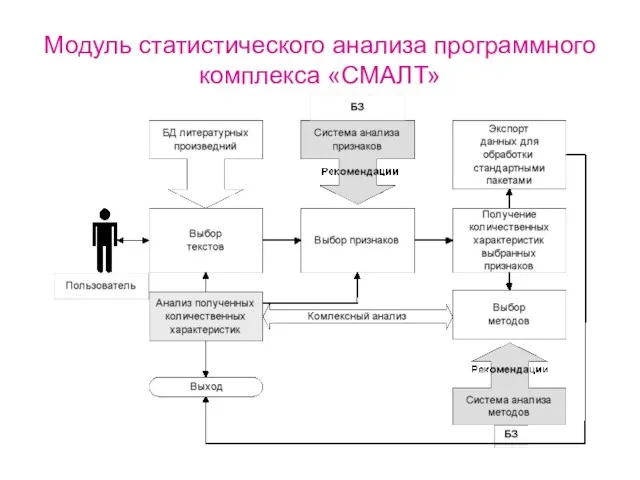
Слайд 18Достоевский редактировал и возглавлял три журнала
Время (1861-1863)
Эпоха (1864-1865)
Гражданин (1873-1874)
Издавал свой личный журнал
Время (1861-1863)
Эпоха (1864-1865)
Гражданин (1873-1874)
Издавал свой личный журнал

Слайд 19Методы анализа текстов
Статистические методы
Проверка статистических гипотез
Разбиение текстов на группы с использованием кластерного
Методы анализа текстов
Статистические методы
Проверка статистических гипотез
Разбиение текстов на группы с использованием кластерного

Слайд 20Авторский инвариант
Под авторским инвариантом понимают такую характеристику литературных текстов (некий параметр),
Авторский инвариант
Под авторским инвариантом понимают такую характеристику литературных текстов (некий параметр),

Слайд 21Свойства авторского инварианта
1. Она должна быть достаточно «массовой», интегральной, чтобы слабо контролироваться
Свойства авторского инварианта
1. Она должна быть достаточно «массовой», интегральной, чтобы слабо контролироваться

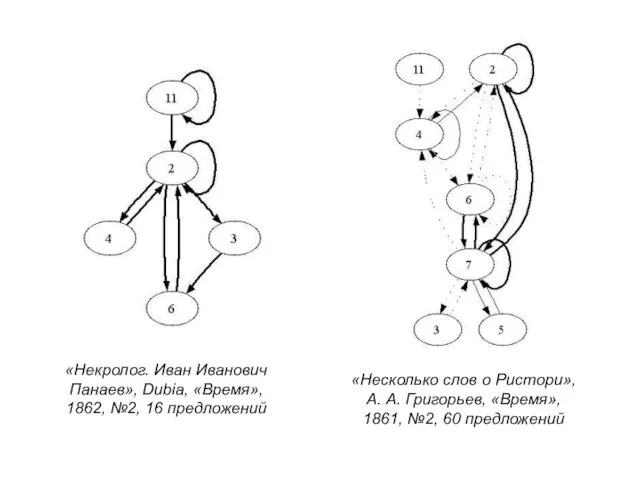
Слайд 22«Некролог. Иван Иванович Панаев», Dubia, «Время», 1862, №2, 16 предложений
«Несколько слов о
«Некролог. Иван Иванович Панаев», Dubia, «Время», 1862, №2, 16 предложений
«Несколько слов о
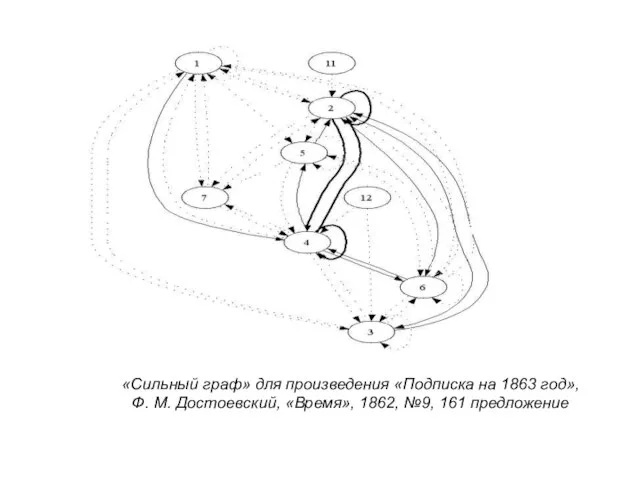
Слайд 23«Сильный граф» для произведения «Подписка на 1863 год»,
Ф. М. Достоевский, «Время», 1862, №9,
«Сильный граф» для произведения «Подписка на 1863 год»,
Ф. М. Достоевский, «Время», 1862, №9,
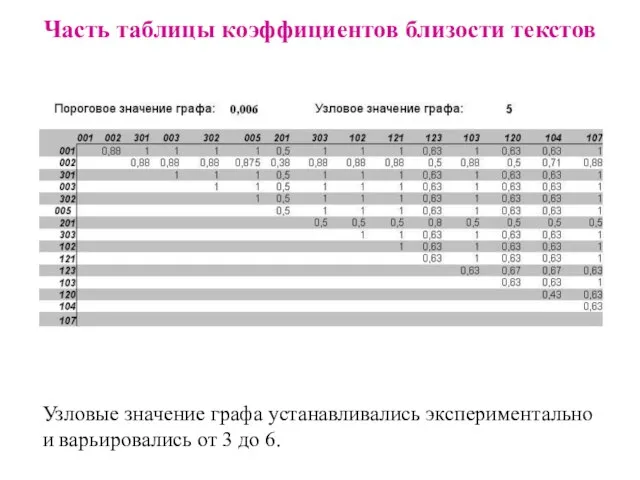
Слайд 24Часть таблицы коэффициентов близости текстов
Узловые значение графа устанавливались экспериментально
и варьировались от 3
Часть таблицы коэффициентов близости текстов
Узловые значение графа устанавливались экспериментально
и варьировались от 3
Слайд 25Развитие исследования Гейра Хетсо
Отличия:
Использование текстов в авторской орфографии и пунктуации;
Развитие исследования Гейра Хетсо
Отличия:
Использование текстов в авторской орфографии и пунктуации;

Слайд 26Используемые лингвостатистические параметры
1. Средняя длина слова в буквах, вычисляемая на основании
выборок размером
Используемые лингвостатистические параметры
1. Средняя длина слова в буквах, вычисляемая на основании
выборок размером

Слайд 27Средняя длина слова в буквах
H0 = {гипотеза о равенстве средних для
Средняя длина слова в буквах
H0 = {гипотеза о равенстве средних для

Слайд 28использовалась следующая формула критерия Стьюдента:
В этой формуле m1 и m2 -
использовалась следующая формула критерия Стьюдента:
В этой формуле m1 и m2 -

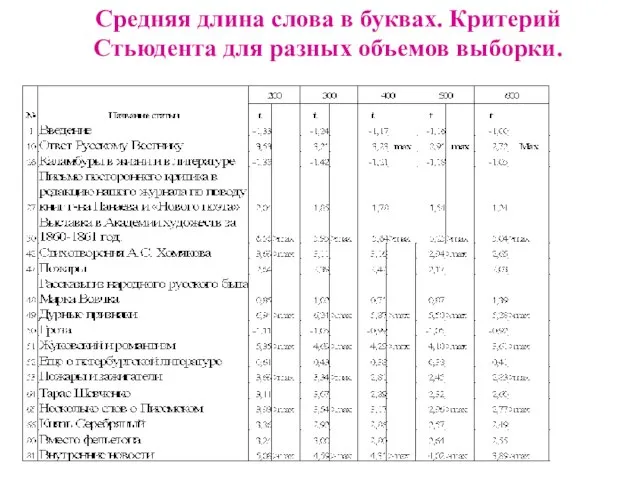
Слайд 29Средняя длина слова в буквах. Критерий Стьюдента для разных объемов выборки.
Средняя длина слова в буквах. Критерий Стьюдента для разных объемов выборки.
Слайд 30Общее распределение длины слова.
Получены данные о том, сколько в каждом тексте
Общее распределение длины слова.
Получены данные о том, сколько в каждом тексте

Слайд 31Средняя длина предложения в словах
Проводится тест исключительности на основании выборок в
Средняя длина предложения в словах
Проводится тест исключительности на основании выборок в

Слайд 32Общее распределение длины предложения
Информация об общем распределении длины предложения была получена
Общее распределение длины предложения
Информация об общем распределении длины предложения была получена

Слайд 33Лексический спектр текста на уровне словаря
и
Лексический спектр текста на уровне текста
Лексический спектр текста на уровне словаря
и
Лексический спектр текста на уровне текста

Слайд 34Индекс разнообразия лексики
Индекса разнообразия лексики - отношения числа разных слов к
Индекс разнообразия лексики
Индекса разнообразия лексики - отношения числа разных слов к

Слайд 35Результаты исследования
Несмотря на использование разных источников и соответственно на наличие некоторых
Результаты исследования
Несмотря на использование разных источников и соответственно на наличие некоторых

Слайд 36Основной результат
В исследовании Хетсо был использован общий принцип применимости статистических методов.
Основной результат
В исследовании Хетсо был использован общий принцип применимости статистических методов.

Слайд 37Предположение о том, что распределение частей речи на первых трех и последних
Предположение о том, что распределение частей речи на первых трех и последних

Слайд 381) с номера 1 по 7. Имя существительное (падеж)
2) с номера 8
1) с номера 1 по 7. Имя существительное (падеж)
2) с номера 8

Слайд 39Иерархическая кластеризация
Алгоритмы кластеризации:
метод ближайшего соседа
метод дальнего соседа
Меры близости между объектами:
1.
Иерархическая кластеризация
Алгоритмы кластеризации:
метод ближайшего соседа
метод дальнего соседа
Меры близости между объектами:
1.

Слайд 40В результате применения метода иерархической кластеризации оказалось, что невозможно четко выделить две
В результате применения метода иерархической кластеризации оказалось, что невозможно четко выделить две

Слайд 41Оценка близости иерархических деревьев
где n-1 показывает число уровней объединения или сечения, а
Пусть
Оценка близости иерархических деревьев
где n-1 показывает число уровней объединения или сечения, а
Пусть

Слайд 42Оценка близости иерархических деревьев при соответствующих уровнях надежности и для разного числа
Оценка близости иерархических деревьев при соответствующих уровнях надежности и для разного числа
Слайд 43Результаты
Результаты
 Корона - горшок для орхидей
Корона - горшок для орхидей Партнёры Архангельской межрегиональной организации профсоюза работников народного образования и науки РФ
Партнёры Архангельской межрегиональной организации профсоюза работников народного образования и науки РФ Учет движения наличных денежных средств с использованием 1С: Бухгалтерия
Учет движения наличных денежных средств с использованием 1С: Бухгалтерия Традиционные общества в XIX – начале XX века
Традиционные общества в XIX – начале XX века Результаты 1 полугодия МБОУ СОШ №1
Результаты 1 полугодия МБОУ СОШ №1 7кл_18-сабак_Тізбек_Презентация
7кл_18-сабак_Тізбек_Презентация Что было - что есть
Что было - что есть Партнерская программа
Партнерская программа Эдельвейс
Эдельвейс Магнитная составляющая электромагнитных волн
Магнитная составляющая электромагнитных волн Своя игра«Знаешь ли ты Ярославль?»
Своя игра«Знаешь ли ты Ярославль?» Презентация1
Презентация1 Формирование образного и логического мышления в процессе обучения литературе.
Формирование образного и логического мышления в процессе обучения литературе. Лекция 7. Духовно-нравственное воспитание и общие основы православной педагогики
Лекция 7. Духовно-нравственное воспитание и общие основы православной педагогики Отечественная война 1812 года
Отечественная война 1812 года Монферран Анри Луи Огюст Рикар
Монферран Анри Луи Огюст Рикар Открытая экоотчетность : требование времени
Открытая экоотчетность : требование времени Аварийно-спасательные работы
Аварийно-спасательные работы  Образование как целостный педагогический процесс
Образование как целостный педагогический процесс Презентация на тему Безопасный путь в школу
Презентация на тему Безопасный путь в школу ОРВИ на современном этапе
ОРВИ на современном этапе СКОРО СКАЗКА СКАЗЫВАЕТСЯ…
СКОРО СКАЗКА СКАЗЫВАЕТСЯ… АЛЕКСАНДР СУВОРОВ- «ГЕНЕРАЛ ВПЕРЁД»
АЛЕКСАНДР СУВОРОВ- «ГЕНЕРАЛ ВПЕРЁД» Транспорт России
Транспорт России Анализ нормативно – правовых актов: Азербайджан
Анализ нормативно – правовых актов: Азербайджан Улучшение технологического процесса изготовления шлангов ПЭ-32 SDR 18
Улучшение технологического процесса изготовления шлангов ПЭ-32 SDR 18 Общие должностные и специальные обязанности военнослужащих
Общие должностные и специальные обязанности военнослужащих Сказки, мифы, легенды, былины
Сказки, мифы, легенды, былины