- Процессоры: микроархитектуры и программирование. Глава 3

Содержание
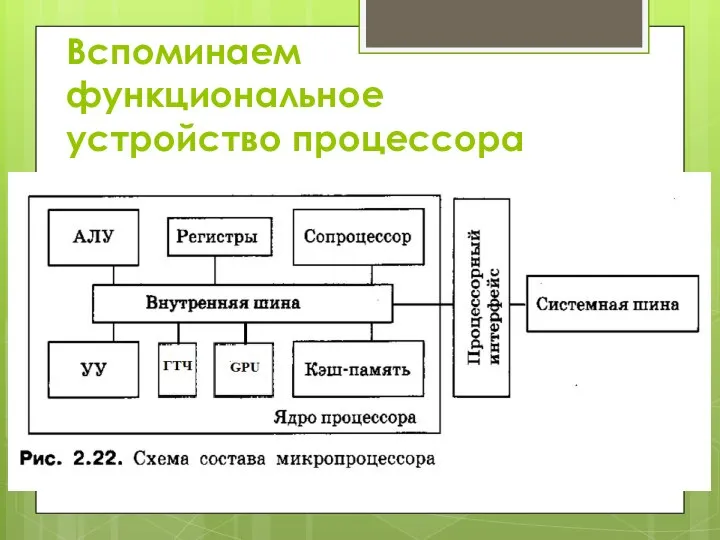
- 2. Вспоминаем функциональное устройство процессора
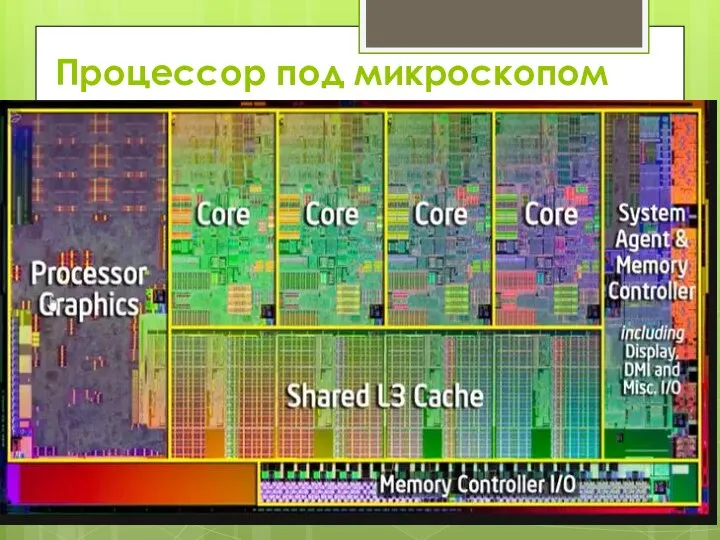
- 3. Процессор под микроскопом
- 4. Введение Вспомним… П р о ц е с с о р и о п е р
- 5. 3.1. Общее представление о структуре и архитектуре процессоров Системы команд Основные команды ЭВМ классифицируются следующим образом:
- 6. Увеличение разрядности позволяет увеличить адресность команды и длину адреса (т. е. объем памяти, доступной данной команде,
- 7. Классы процессоров В зависимости от набора и порядка выполнения команд процессоры подразделяются на четыре класса:
- 8. CISC (Complex Instruction Set Computer) Классическая архитектура процессоров, которая начала свое развитие в 1940-х гг. с
- 9. Типичным примером CISC являются процессоры Intel х86 (в частности, семейство Pentium). Количество команд: более 200 команд
- 10. Такое многообразие выполняемых команд и способов адресации позволяет программисту реализовать наиболее эффективные алгоритмы решения различных задач.
- 11. RISC (Redused Instuction Set Computer) Архитектура отличается использованием ограниченного набора команд фиксированного формата. Первый процессор RISC
- 12. Значительно сокращается число используемых способов адресации. В результате процессор на 20—30 % реже обращается к оперативной
- 13. Упростилась топология процессора, выполняемого в виде одной интегральной схемы, сократились сроки ее разработки, она стала дешевле.
- 14. CISC или RISС? В то время, как в процессоре CISC для выполнения одной команды необходимо в
- 15. Процессор MISC Работает с минимальным набором длинных команд и характеризуется небольшим набором чаще всего встречающихся команд.
- 16. VLIW (Very Large Instruction Word) архитектура, которая появилась относительно недавно (в 1990-х гг.). Ее особенностью является
- 18. Компилятор В давние времена, когда компьютеры были большими, время доступа к памяти было небольшим, но и
- 19. Специальный компилятор планирования перед выполнением прикладной программы проводит ее анализ. По множеству ветвей последовательности операций определяет
- 20. Во-первых, в течение одного такта выполнять группу коротких («обычных») команд, Во-вторых — упростить структуру процессора. Этим
- 21. К VLIW-типу можно отнести процессор Elbrus, объявленный российской компанией «Эльбрус».
- 22. 3.2. Технологии повышения производительности процессоров и эффективности ЭВМ Конвейерная обработка команд Обработка команды, или цикл процессора,
- 23. Все команды в таких процессорах следуют одна за другой – это носит название конвейерной (pipeline) обработки.
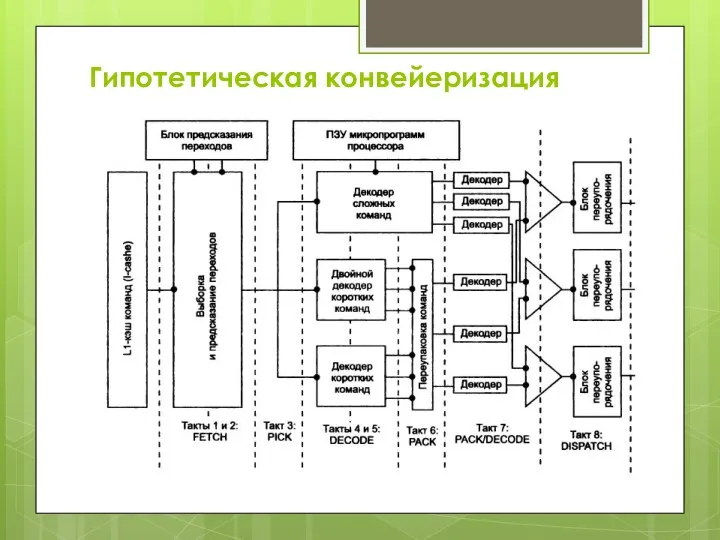
- 24. Конвейеризация Конвейеризация технология, осуществляющая многопоточную параллельную обработку команд. В каждый момент одна из команд считывается, другая
- 25. Гипотетическая конвейеризация
- 26. Конвейеризация реальная
- 27. Пояснение к схемам Причина увеличения длины конвейера заключается в том, что многие команды являются довольно сложными
- 28. Свойства конвейеризации С ростом числа линий конвейера и увеличением числа ступеней на линии увеличивается пропускная способность
- 29. Суперскаляризация Процессоры с несколькими линиями конвейера получили название с у п е р с к а
- 30. Суперскалярный процессор Суперскалярный процессор - Процессор, поддерживающий так называемый параллелизм на уровне инструкций (то есть, процессор,
- 31. Во многих вычислительных системах, наряду с конвейером команд, используются конвейеры данных. Сочетание этих двух конвейеров дает
- 32. Сопроцессоры Для расширения вычислительных возможностей центрального процессора — выполнения арифметических операций над вещественными числами (с плавающей
- 33. Применение сопроцессора повышает производительность вычислений в сотни раз. В разных поколениях процессоров он назывался по-разному —
- 34. Блоки операций с плавающей запятой С программной точки зрения сопроцессор и процессор выглядят как единое целое.
- 35. Увеличение разрядности систем В 1980-е годы соответствие между типом ЭВМ и ее разрядностью имело простейший вид:
- 37. Использование GPU GPU - отдельное устройство персонального компьютера, выполняющее графический рендеринг. GPU это вспомогательный микрочип, который
- 38. Видеокарта GPU способна быстро проводить расчёты, где используется одна или схожая формула (например, вычисление точки затенения
- 40. Как по внешнему виду понять встроенная видео карта или внешняя
- 41. Для чего нужна внешняя видеокарта при встроенном GPU
- 42. Использование виртуализации процессора Hyper-threading (англ. hyper-threading — гиперпоточность, HTT или HT) — технология, разработанная компанией Intel
- 45. Архитектуры на 64 разряда (64-bit architecture). IA-64. Спецификация IA-64 означает «Архитектура Intel, 64 бита». Появляется полностью
- 46. AMD64 Набор команд AMD64 (первоначально названный х86-64), в значительной степени построен на основе IA-32 и таким
- 47. EM64T (Extended Memory 64-bit Technology, или Intel 64) — набор команд (ранее известный как Yamhill), объявленный
- 48. Векторная обработка (SIMD-команды) В классификации Г. Флинна имеется рубрика SIMD — поток данных, обрабатываемых одной командой.
- 49. MMX MMX (MultiMedia extension) — архитектура системы команд, непосредственно предназначенных для задач мультимедиа, связи и графических
- 50. Это и определило новую структуру данных и расширение системы команд. При этом было достигнуто общее повышение
- 51. Архитектура 3DNow! впервые реализована в процессорах AMD К6-2 (май 1998 г.). Технология 3DNow! включает 21 дополнительную
- 52. Динамическое исполнение (dynamic execution technology) Динамическое исполнение — технология обработки данных процессором, обеспечивающая более эффективную работу
- 53. Внеочередное выполнение Внеочередное выполнение (выполнение вне естественного порядка — out-of-order execution). Процессор анализирует поток команд и
- 54. Переименование (ротация) регистров Переименование (ротация) регистров (register rename) Чтобы избежать пересылок данных между регистрами в соответствующей
- 55. Выполнение по предположению Выполнение по предположению (спекулятивное — speculative). Процессор выполняет инструкции (до пяти инструкций одновременно)
- 56. Предикация (predication) — одновременное исполнение нескольких ветвей программы вместо предсказания переходов (выполнения наиболее вероятного); Если в
- 57. Опережающее чтение данных Опережающее чтение данных (speculative loading), т. е. загрузка данных в регистры с опережением,
- 59. Скачать презентацию
Слайд 3Процессор под микроскопом
Процессор под микроскопом
Слайд 4Введение
Вспомним…
П р о ц е с с о р и о п
Введение
Вспомним…
П р о ц е с с о р и о п

Слайд 53.1. Общее представление о структуре и архитектуре процессоров
Системы команд
Основные команды ЭВМ классифицируются
3.1. Общее представление о структуре и архитектуре процессоров
Системы команд
Основные команды ЭВМ классифицируются

Слайд 6Увеличение разрядности позволяет увеличить адресность команды и длину адреса (т. е. объем

Слайд 7Классы процессоров
В зависимости от набора и порядка выполнения команд процессоры подразделяются на
Классы процессоров
В зависимости от набора и порядка выполнения команд процессоры подразделяются на

Слайд 8CISC
(Complex Instruction Set Computer)
Классическая архитектура процессоров, которая начала свое развитие в
CISC
(Complex Instruction Set Computer)
Классическая архитектура процессоров, которая начала свое развитие в

Слайд 9Типичным примером CISC являются процессоры Intel х86 (в частности, семейство Pentium).
Количество
Типичным примером CISC являются процессоры Intel х86 (в частности, семейство Pentium).
Количество

Слайд 10Такое многообразие выполняемых команд и способов адресации позволяет программисту реализовать наиболее эффективные
Такое многообразие выполняемых команд и способов адресации позволяет программисту реализовать наиболее эффективные

Слайд 11RISC (Redused Instuction Set Computer)
Архитектура отличается использованием ограниченного набора команд фиксированного формата.
RISC (Redused Instuction Set Computer)
Архитектура отличается использованием ограниченного набора команд фиксированного формата.

Слайд 12Значительно сокращается число используемых способов адресации.
В результате процессор на 20—30 % реже
Значительно сокращается число используемых способов адресации.
В результате процессор на 20—30 % реже

Слайд 13Упростилась топология процессора, выполняемого в виде одной интегральной схемы, сократились сроки ее
Упростилась топология процессора, выполняемого в виде одной интегральной схемы, сократились сроки ее

Слайд 14CISC или RISС?
В то время, как в процессоре CISC для выполнения одной
CISC или RISС?
В то время, как в процессоре CISC для выполнения одной

Слайд 15Процессор MISC
Работает с минимальным набором длинных команд и характеризуется небольшим набором чаще
Процессор MISC
Работает с минимальным набором длинных команд и характеризуется небольшим набором чаще

Слайд 16VLIW (Very Large Instruction Word)
архитектура, которая появилась относительно недавно (в 1990-х гг.).
VLIW (Very Large Instruction Word)
архитектура, которая появилась относительно недавно (в 1990-х гг.).


Слайд 18Компилятор
В давние времена, когда компьютеры были большими, время доступа к памяти было
Компилятор
В давние времена, когда компьютеры были большими, время доступа к памяти было

Слайд 19Специальный компилятор планирования перед выполнением прикладной программы проводит ее анализ. По множеству
Специальный компилятор планирования перед выполнением прикладной программы проводит ее анализ. По множеству

Слайд 20Во-первых, в течение одного такта выполнять группу коротких («обычных») команд,
Во-вторых —
Во-первых, в течение одного такта выполнять группу коротких («обычных») команд,
Во-вторых —

Слайд 21К VLIW-типу можно отнести процессор Elbrus, объявленный российской компанией «Эльбрус».
К VLIW-типу можно отнести процессор Elbrus, объявленный российской компанией «Эльбрус».

Слайд 223.2. Технологии
повышения производительности
процессоров и эффективности ЭВМ
Конвейерная обработка команд
Обработка команды, или цикл
3.2. Технологии
повышения производительности
процессоров и эффективности ЭВМ
Конвейерная обработка команд
Обработка команды, или цикл

Слайд 23Все команды в таких процессорах следуют одна за другой – это носит
Все команды в таких процессорах следуют одна за другой – это носит

Слайд 24Конвейеризация
Конвейеризация технология, осуществляющая многопоточную параллельную обработку команд.
В каждый момент одна из команд
Конвейеризация
Конвейеризация технология, осуществляющая многопоточную параллельную обработку команд.
В каждый момент одна из команд

Слайд 25Гипотетическая конвейеризация
Гипотетическая конвейеризация
Слайд 26Конвейеризация реальная
Конвейеризация реальная
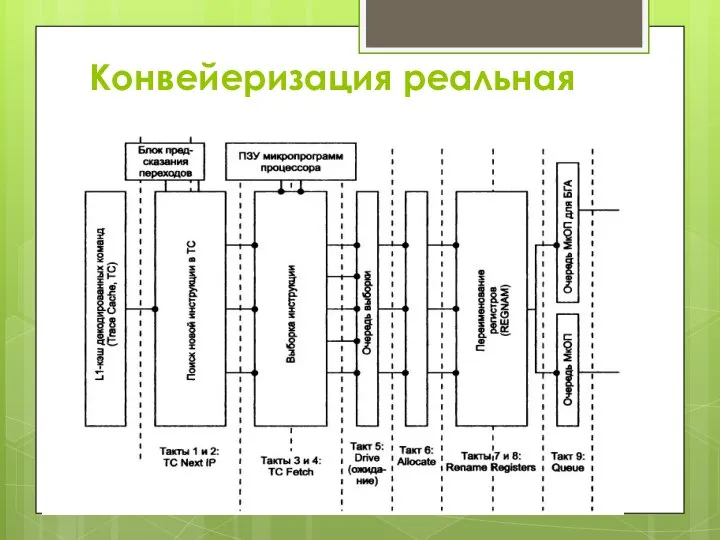
Слайд 27Пояснение к схемам
Причина увеличения длины конвейера заключается в том, что многие команды
Пояснение к схемам
Причина увеличения длины конвейера заключается в том, что многие команды

Слайд 28Свойства конвейеризации
С ростом числа линий конвейера и увеличением числа ступеней на линии
Свойства конвейеризации
С ростом числа линий конвейера и увеличением числа ступеней на линии

Слайд 29Суперскаляризация
Процессоры с несколькими линиями конвейера получили название с у п е р
Суперскаляризация
Процессоры с несколькими линиями конвейера получили название с у п е р

Слайд 30Суперскалярный процессор
Суперскалярный процессор - Процессор, поддерживающий так называемый параллелизм на уровне инструкций
Суперскалярный процессор
Суперскалярный процессор - Процессор, поддерживающий так называемый параллелизм на уровне инструкций

Слайд 31Во многих вычислительных системах, наряду с конвейером команд, используются конвейеры данных.
Сочетание
Во многих вычислительных системах, наряду с конвейером команд, используются конвейеры данных.
Сочетание

Слайд 32Сопроцессоры
Для расширения вычислительных возможностей центрального процессора — выполнения арифметических операций над вещественными
Сопроцессоры
Для расширения вычислительных возможностей центрального процессора — выполнения арифметических операций над вещественными

Слайд 33Применение сопроцессора повышает производительность вычислений в сотни раз.
В разных поколениях процессоров
Применение сопроцессора повышает производительность вычислений в сотни раз.
В разных поколениях процессоров

Слайд 34Блоки операций с плавающей запятой
С программной точки зрения сопроцессор и процессор выглядят
Блоки операций с плавающей запятой
С программной точки зрения сопроцессор и процессор выглядят

Слайд 35Увеличение разрядности систем
В 1980-е годы соответствие между типом ЭВМ и ее разрядностью
Увеличение разрядности систем
В 1980-е годы соответствие между типом ЭВМ и ее разрядностью


Слайд 37Использование GPU
GPU - отдельное устройство персонального компьютера, выполняющее графический рендеринг.
GPU это вспомогательный
Использование GPU
GPU - отдельное устройство персонального компьютера, выполняющее графический рендеринг.
GPU это вспомогательный

Слайд 38Видеокарта GPU способна быстро проводить расчёты, где используется одна или схожая формула
Видеокарта GPU способна быстро проводить расчёты, где используется одна или схожая формула


Слайд 40Как по внешнему виду понять встроенная видео карта или внешняя
Как по внешнему виду понять встроенная видео карта или внешняя

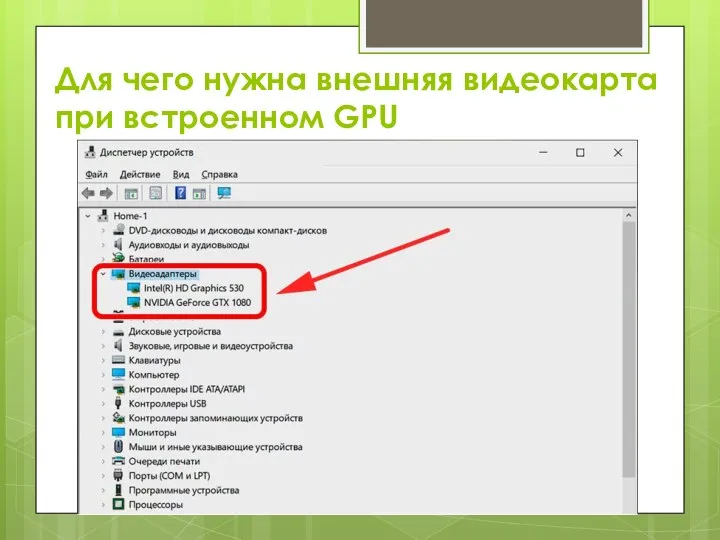
Слайд 41Для чего нужна внешняя видеокарта при встроенном GPU
Для чего нужна внешняя видеокарта при встроенном GPU
Слайд 42Использование
виртуализации процессора
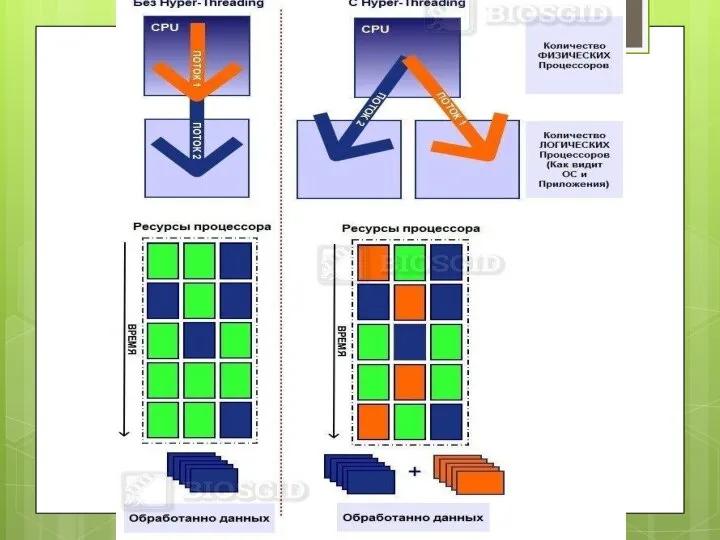
Hyper-threading (англ. hyper-threading — гиперпоточность, HTT или HT)
— технология, разработанная компанией
Использование
виртуализации процессора
Hyper-threading (англ. hyper-threading — гиперпоточность, HTT или HT)
— технология, разработанная компанией


Слайд 45Архитектуры на 64 разряда (64-bit architecture).
IA-64. Спецификация IA-64 означает «Архитектура Intel, 64
Архитектуры на 64 разряда (64-bit architecture).
IA-64. Спецификация IA-64 означает «Архитектура Intel, 64

Слайд 46AMD64
Набор команд AMD64 (первоначально названный
х86-64), в значительной степени построен на основе IA-32
AMD64
Набор команд AMD64 (первоначально названный
х86-64), в значительной степени построен на основе IA-32

Слайд 47EM64T
(Extended Memory 64-bit Technology, или Intel 64) —
набор команд (ранее известный
EM64T
(Extended Memory 64-bit Technology, или Intel 64) —
набор команд (ранее известный

Слайд 48Векторная
обработка (SIMD-команды)
В классификации Г. Флинна имеется рубрика SIMD — поток данных,
Векторная
обработка (SIMD-команды)
В классификации Г. Флинна имеется рубрика SIMD — поток данных,

Слайд 49MMX
MMX (MultiMedia extension) — архитектура системы команд, непосредственно предназначенных для задач мультимедиа,
MMX
MMX (MultiMedia extension) — архитектура системы команд, непосредственно предназначенных для задач мультимедиа,

Слайд 50Это и определило новую структуру данных и расширение системы команд. При этом
Это и определило новую структуру данных и расширение системы команд. При этом

Слайд 51Архитектура 3DNow!
впервые реализована в процессорах
AMD К6-2 (май 1998 г.). Технология 3DNow! включает
Архитектура 3DNow!
впервые реализована в процессорах
AMD К6-2 (май 1998 г.). Технология 3DNow! включает

Слайд 52Динамическое исполнение (dynamic execution technology)
Динамическое исполнение — технология обработки данных процессором, обеспечивающая
Динамическое исполнение (dynamic execution technology)
Динамическое исполнение — технология обработки данных процессором, обеспечивающая

Слайд 53Внеочередное выполнение
Внеочередное выполнение (выполнение вне естественного порядка — out-of-order execution). Процессор анализирует
Внеочередное выполнение
Внеочередное выполнение (выполнение вне естественного порядка — out-of-order execution). Процессор анализирует

Слайд 54Переименование (ротация) регистров
Переименование (ротация) регистров (register rename)
Чтобы избежать пересылок данных между регистрами
Переименование (ротация) регистров
Переименование (ротация) регистров (register rename)
Чтобы избежать пересылок данных между регистрами

Слайд 55Выполнение по предположению
Выполнение по предположению (спекулятивное — speculative). Процессор выполняет инструкции (до
Выполнение по предположению
Выполнение по предположению (спекулятивное — speculative). Процессор выполняет инструкции (до

Слайд 56Предикация (predication) — одновременное исполнение нескольких ветвей программы вместо предсказания переходов (выполнения
Предикация (predication) — одновременное исполнение нескольких ветвей программы вместо предсказания переходов (выполнения

Слайд 57Опережающее чтение данных
Опережающее чтение данных (speculative loading), т. е. загрузка данных в
Опережающее чтение данных
Опережающее чтение данных (speculative loading), т. е. загрузка данных в

 Презентация на тему Интенсивное чтение Чтение слов, предложений, текстов с буквами Ш, ш
Презентация на тему Интенсивное чтение Чтение слов, предложений, текстов с буквами Ш, ш Викторина Все о новом годе
Викторина Все о новом годе Презентация на тему Бактерии в организме человека
Презентация на тему Бактерии в организме человека эффективный и экономичный канал привлечения клиентов Казань: 850 000 писем в неделю 240 000 подписчиков (2,38%)
эффективный и экономичный канал привлечения клиентов Казань: 850 000 писем в неделю 240 000 подписчиков (2,38%) Что, где, когда. Игра по правовым знаниям
Что, где, когда. Игра по правовым знаниям Особенности планирования имиджевой рекламы в интернете
Особенности планирования имиджевой рекламы в интернете Рокотов Федор Степанович
Рокотов Федор Степанович Создание сети платежных терминалов для Банка
Создание сети платежных терминалов для Банка Возможности «1С:Зарплата и управление персоналом 8 КОРП» для автоматизации крупных предприятий и холдингов
Возможности «1С:Зарплата и управление персоналом 8 КОРП» для автоматизации крупных предприятий и холдингов 1--1-- יוני 2009 Сентябрь 2011 Взаимное Поручительство - провозглашение новой социальной экономики. - презентация
1--1-- יוני 2009 Сентябрь 2011 Взаимное Поручительство - провозглашение новой социальной экономики. - презентация Потенциал
Потенциал  Лекарства. Цены или наценки?Возможности и риски регуляторной политики.
Лекарства. Цены или наценки?Возможности и риски регуляторной политики. Закупки СИЗ из Резервного фонда. Оптимизация процедур закупок
Закупки СИЗ из Резервного фонда. Оптимизация процедур закупок Breakfast. Vocabulary
Breakfast. Vocabulary Русский язык
Русский язык Гестозы
Гестозы Управлениепроблемными активами
Управлениепроблемными активами «Прогулки по Италии: музей под открытым небом»
«Прогулки по Италии: музей под открытым небом» Конституционное право (схемы)
Конституционное право (схемы) Электричество
Электричество Тамбов в годы Великой Отечественной Войны
Тамбов в годы Великой Отечественной Войны Культура ислама
Культура ислама ABBYY TestReader 5.2 Новое в версии 5.2 Калинин Алексей Олегович
ABBYY TestReader 5.2 Новое в версии 5.2 Калинин Алексей Олегович Индийские касты
Индийские касты История социальных сетей Интересно о неинтересном* Автор: @desperado_alex (*попытка не пытка)
История социальных сетей Интересно о неинтересном* Автор: @desperado_alex (*попытка не пытка) Деньги. Понятие денег
Деньги. Понятие денег Онегин, добрый мой приятель
Онегин, добрый мой приятель Project Countries of the world Country the Italy
Project Countries of the world Country the Italy