- Тема 6 ОТКАЗОУСТОЙЧИВОСТЬ

Содержание
- 2. Содержание 1. Основные определения 2. Модели отказов 3. Маскирование ошибок при помощи избыточности 4. Отказоустойчивость процессов
- 3. Содержание 6. Надежная групповая рассылка 7. Распределенное подтверждение 8. Восстановление 9. Критерии отказоустойчивости 10. Отказоустойчивые сервера
- 4. 1. Основные определения Отказоустойчивость относится к надежностным характеристикам системы. Надежность — это термин, охватывающий множество важных
- 5. 1. Основные определения Система отказывает (fail), если она не в состоянии выполнять свою работу. Ошибкой (error)
- 6. 1. Основные определения Отказы обычно подразделяются на проходные, перемежающиеся и постоянные. Проходные отказы (transient faults) происходят
- 7. 2. Модели отказов Различные типы отказов:
- 8. 2. Модели отказов Поломка (crash failure) имеет место при внезапной остановке сервера, при этом до момента
- 9. 2. Модели отказов Ошибки синхронизации (timing failures) возникают при ожидании ответа дольше определенного временного интервала. Ошибки
- 10. 3. Маскирование ошибок при помощи избыточности Если система считается отказоустойчивой, она должна пытаться маскировать факты ошибок
- 11. 4. Отказоустойчивость процессов Отказоустойчивость процессов организуется путем репликации процессов в группах. Основной подход к защите от
- 12. 4. Отказоустойчивость процессов Взаимодействие в одноранговой и иерархической группах:
- 13. 5. Надежная связь клиент-сервер Во многих распределенных сетях надежная сквозная (point-to-point) передача реализуется путем использования надежного
- 14. 5. Надежная связь клиент-сервер Назначение RPC — скрыть сам факт взаимодействия путем вызовов удаленных процедур, которые
- 15. 5. Надежная связь клиент-сервер Клиент не в состоянии обнаружить сервер Решение: заставить ошибку возбуждать исключение (exception).
- 16. 5. Надежная связь клиент-сервер 4. Поломка сервера Решение: В случае (б) система должна передать клиенту сообщение
- 17. 5. Надежная связь клиент-сервер 5. Поломка клиента Не имеющие заказчика вычисления называются сиротами (orphans). Решение: перед
- 18. 6. Надежная групповая рассылка Каждый локальный координатор пересылает сообщения своим потомкам, а затем обрабатывает запросы на
- 19. 6. Надежная групповая рассылка Если производится серия изменений и в ходе выполнения одного из них случается
- 20. 7. Распределенное подтверждение Задача распределенного подтверждения включает в себя операции, производимые либо с каждым членом группы
- 21. 7. Распределенное подтверждение Координатор Участник Двухфазное подтверждение:
- 22. 7. Распределенное подтверждение Двухфазное подтверждение: 1. Координатор рассылает всем участникам сообщение VOTE_REQUEST. 2. После того как
- 23. 7. Распределенное подтверждение Координатор Участник Трехфазное подтверждение:
- 24. 7. Распределенное подтверждение Трехфазное подтверждение: Не существует такого состояния, в котором невозможно принять итоговое решение, но
- 25. 8. Восстановление Основа отказоустойчивости — исправление после ошибок. Два основных способа восстановления после ошибок: обратное исправление
- 26. В РС возможно большое количество мест повреждений. Вероятность ее безотказной работы может быть оценена статистически (при
- 27. Такая оценка связывает отказоустойчивость с количеством возникших повреждений, при этом р — статистическая оценка вероятности отказа
- 28. Полученное семейство точек условно разбито на три зоны: — зона І: 0 ≤ n ≤ n1;
- 29. Очевидно, что отказоустойчивость системы зависит от значений n1 и n2 и тем выше, чем дольше сохраняется
- 30. 9. Критерии отказоустойчивости
- 31. Приведенные типы отказоустойчивости представляют собой условную аппроксимацию экспериментальных точек прямыми. Первый тип по своим показателям соответствует
- 32. Второй тип соответствует системе c негарантированной отказоустойчивостью, т.к. первое же любое повреждение может привести к отказу.
- 33. Третий тип отказоустойчивости также является ненадежным с точки зрения эксплуатационных характеристик системы, поскольку после некоторого количества
- 34. В качестве критерия отказоустойчивости четвертого типа рекомендуется произведение т.к. аппроксимирующая кривая отказов этого типа содержит участки,
- 35. Пример Экспериментальные значения статистической оценки вероятности отказа для двух различных систем Учитывая изложенное, а также исходя
- 36. Каждая i-я экспериментальная точка содержит в себе информацию о вероятности двух событий, представляющих собой полное множество:
- 37. Катастрофоустойчивый кластер 10. Отказоустойчивые сервера
- 38. Отказоустойчивость виртуальных серверов: В широком смысле слова, виртуализация – это программная имитация некоей физической сущности. К
- 39. Отказоустойчивость виртуальных серверов Преимущества: -Рациональное использование аппаратных ресурсов -Экономия денег, места и электроэнергии -Удобство администрирования Недостатки:
- 40. FAILOVER FAILBACK 10. Отказоустойчивые сервера
- 41. FAILOVER FAILBACK 10. Отказоустойчивые сервера
- 42. Обслуживание серверов Переносим виртуальные машины на другой сервер Производим обслуживание (установка обновлений, замена оборудования…) Переносим виртуальные
- 43. Копирование содержимого памяти осуществляется по сети страницами по 4Кб. Копируется все содержимое памяти виртуальной машины. Если
- 44. Выводы Отказоустойчивость определяется как способность системы маскировать появление ошибок и исправлять их. Система отказоустойчива, если она
- 45. Выводы В условиях протокола двухфазного подтверждения координатор сначала проверяет готовность всех процессов к выполнению одной и
- 46. Выводы Для повышения производительности множество распределенных систем сочетают контрольные точки с протоколированием сообщений. Благодаря протоколированию взаимодействия
- 47. Список использованной литературы Черкесов Г.Н. Надежность аппаратно-программных комплексов. Рябинин И.А. Надежность и безопасность структурно сложных систем.
- 49. Скачать презентацию
Слайд 2Содержание
1. Основные определения
2. Модели отказов
3. Маскирование ошибок при помощи избыточности
4. Отказоустойчивость процессов
5.
Содержание
1. Основные определения
2. Модели отказов
3. Маскирование ошибок при помощи избыточности
4. Отказоустойчивость процессов
5.

Слайд 3Содержание
6. Надежная групповая рассылка
7. Распределенное подтверждение
8. Восстановление
9. Критерии отказоустойчивости
10. Отказоустойчивые сервера
Выводы
Список использованной
Содержание
6. Надежная групповая рассылка
7. Распределенное подтверждение
8. Восстановление
9. Критерии отказоустойчивости
10. Отказоустойчивые сервера
Выводы
Список использованной

Слайд 41. Основные определения
Отказоустойчивость относится к надежностным характеристикам системы. Надежность — это термин,
1. Основные определения
Отказоустойчивость относится к надежностным характеристикам системы. Надежность — это термин,

Слайд 51. Основные определения
Система отказывает (fail), если она не в состоянии выполнять свою
1. Основные определения
Система отказывает (fail), если она не в состоянии выполнять свою

Слайд 61. Основные определения
Отказы обычно подразделяются на проходные, перемежающиеся и постоянные.
Проходные отказы (transient
1. Основные определения
Отказы обычно подразделяются на проходные, перемежающиеся и постоянные.
Проходные отказы (transient

Слайд 72. Модели отказов
Различные типы отказов:
2. Модели отказов
Различные типы отказов:

Слайд 82. Модели отказов
Поломка (crash failure) имеет место при внезапной остановке сервера, при
2. Модели отказов
Поломка (crash failure) имеет место при внезапной остановке сервера, при

Слайд 92. Модели отказов
Ошибки синхронизации (timing failures) возникают при ожидании ответа дольше определенного
2. Модели отказов
Ошибки синхронизации (timing failures) возникают при ожидании ответа дольше определенного

Слайд 103. Маскирование ошибок при помощи избыточности
Если система считается отказоустойчивой, она должна пытаться
3. Маскирование ошибок при помощи избыточности
Если система считается отказоустойчивой, она должна пытаться

Слайд 114. Отказоустойчивость процессов
Отказоустойчивость процессов организуется путем репликации процессов в группах.
Основной подход к
4. Отказоустойчивость процессов
Отказоустойчивость процессов организуется путем репликации процессов в группах.
Основной подход к

Слайд 124. Отказоустойчивость процессов
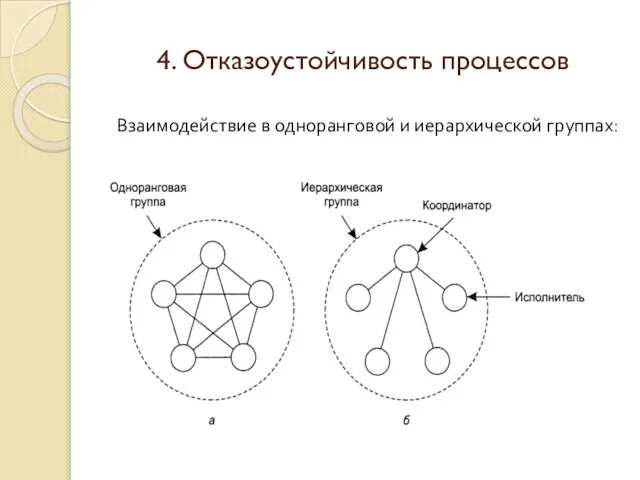
Взаимодействие в одноранговой и иерархической группах:
4. Отказоустойчивость процессов
Взаимодействие в одноранговой и иерархической группах:
Слайд 135. Надежная связь клиент-сервер
Во многих распределенных сетях надежная сквозная (point-to-point) передача реализуется
5. Надежная связь клиент-сервер
Во многих распределенных сетях надежная сквозная (point-to-point) передача реализуется

Слайд 145. Надежная связь клиент-сервер
Назначение RPC — скрыть сам факт взаимодействия путем вызовов
5. Надежная связь клиент-сервер
Назначение RPC — скрыть сам факт взаимодействия путем вызовов

Слайд 155. Надежная связь клиент-сервер
Клиент не в состоянии обнаружить сервер
Решение: заставить ошибку возбуждать
5. Надежная связь клиент-сервер
Клиент не в состоянии обнаружить сервер
Решение: заставить ошибку возбуждать

Слайд 165. Надежная связь клиент-сервер
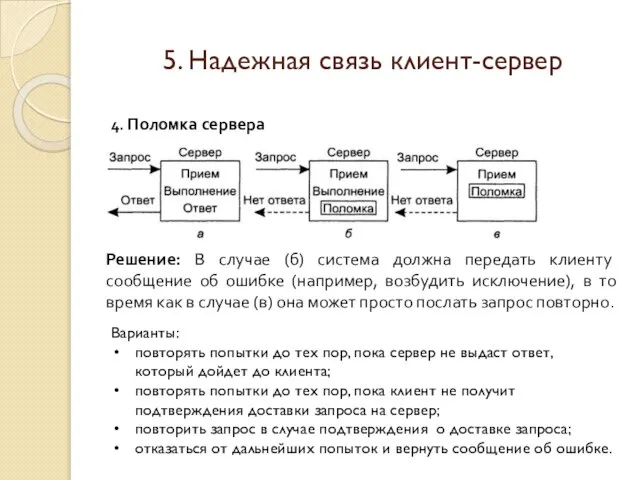
4. Поломка сервера
Решение: В случае (б) система должна передать
5. Надежная связь клиент-сервер
4. Поломка сервера
Решение: В случае (б) система должна передать
Слайд 175. Надежная связь клиент-сервер
5. Поломка клиента
Не имеющие заказчика вычисления называются сиротами (orphans).
Решение:
5. Надежная связь клиент-сервер
5. Поломка клиента
Не имеющие заказчика вычисления называются сиротами (orphans).
Решение:

Слайд 186. Надежная групповая рассылка
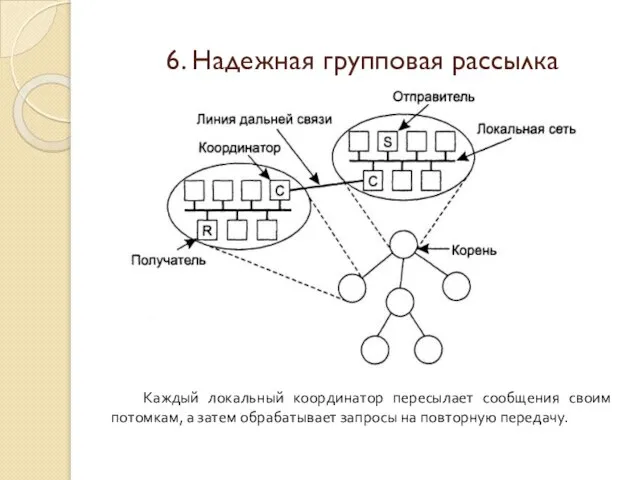
Каждый локальный координатор пересылает сообщения своим потомкам, а затем
6. Надежная групповая рассылка
Каждый локальный координатор пересылает сообщения своим потомкам, а затем
Слайд 196. Надежная групповая рассылка
Если производится серия изменений и в ходе выполнения одного
6. Надежная групповая рассылка
Если производится серия изменений и в ходе выполнения одного

Слайд 207. Распределенное подтверждение
Задача распределенного подтверждения включает в себя операции, производимые либо с
7. Распределенное подтверждение
Задача распределенного подтверждения включает в себя операции, производимые либо с

Слайд 217. Распределенное подтверждение
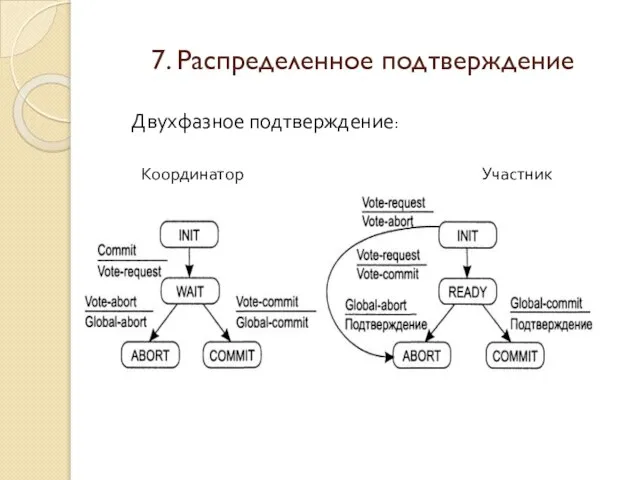
Координатор Участник
Двухфазное подтверждение:
7. Распределенное подтверждение
Координатор Участник
Двухфазное подтверждение:
Слайд 227. Распределенное подтверждение
Двухфазное подтверждение:
1. Координатор рассылает всем участникам сообщение VOTE_REQUEST.
2. После того
7. Распределенное подтверждение
Двухфазное подтверждение:
1. Координатор рассылает всем участникам сообщение VOTE_REQUEST.
2. После того

Слайд 237. Распределенное подтверждение
Координатор Участник
Трехфазное подтверждение:
7. Распределенное подтверждение
Координатор Участник
Трехфазное подтверждение:
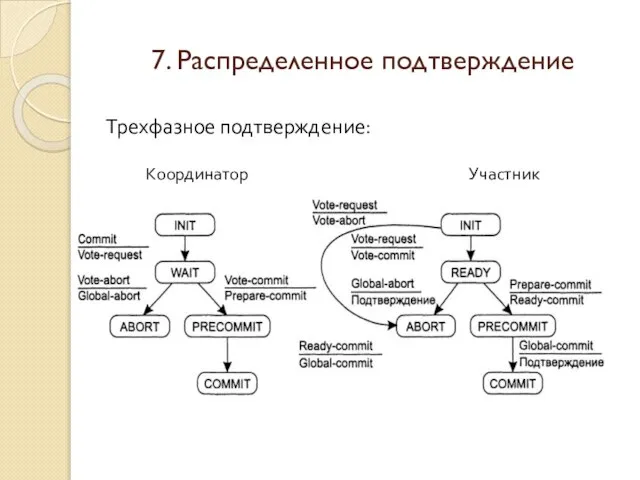
Слайд 247. Распределенное подтверждение
Трехфазное подтверждение:
Не существует такого состояния, в котором невозможно принять итоговое
7. Распределенное подтверждение
Трехфазное подтверждение:
Не существует такого состояния, в котором невозможно принять итоговое

Слайд 258. Восстановление
Основа отказоустойчивости — исправление после ошибок.
Два основных способа восстановления после ошибок:
8. Восстановление
Основа отказоустойчивости — исправление после ошибок.
Два основных способа восстановления после ошибок:

Слайд 26 В РС возможно большое количество мест повреждений. Вероятность ее безотказной работы может
В РС возможно большое количество мест повреждений. Вероятность ее безотказной работы может

Слайд 27 Такая оценка связывает отказоустойчивость с количеством возникших повреждений, при этом
р —
Такая оценка связывает отказоустойчивость с количеством возникших повреждений, при этом
р —

Слайд 28 Полученное семейство точек условно разбито на три зоны:
— зона І: 0
Полученное семейство точек условно разбито на три зоны:
— зона І: 0

Слайд 29 Очевидно, что отказоустойчивость системы зависит от значений n1 и n2 и тем
Очевидно, что отказоустойчивость системы зависит от значений n1 и n2 и тем

Слайд 309. Критерии отказоустойчивости
9. Критерии отказоустойчивости

Слайд 31 Приведенные типы отказоустойчивости представляют собой условную аппроксимацию экспериментальных точек прямыми.
Первый тип
Приведенные типы отказоустойчивости представляют собой условную аппроксимацию экспериментальных точек прямыми.
Первый тип

Слайд 32 Второй тип соответствует системе
c негарантированной отказоустойчивостью, т.к. первое же любое повреждение
Второй тип соответствует системе
c негарантированной отказоустойчивостью, т.к. первое же любое повреждение

Слайд 33 Третий тип отказоустойчивости также является ненадежным с точки зрения эксплуатационных характеристик системы,
Третий тип отказоустойчивости также является ненадежным с точки зрения эксплуатационных характеристик системы,

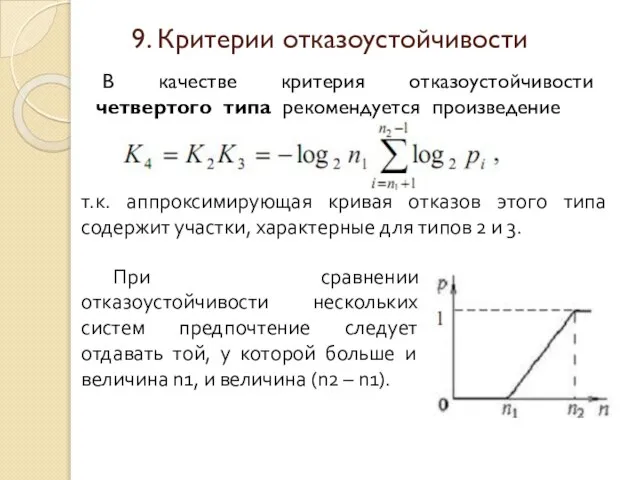
Слайд 34 В качестве критерия отказоустойчивости четвертого типа рекомендуется произведение
т.к. аппроксимирующая кривая отказов этого
В качестве критерия отказоустойчивости четвертого типа рекомендуется произведение
т.к. аппроксимирующая кривая отказов этого
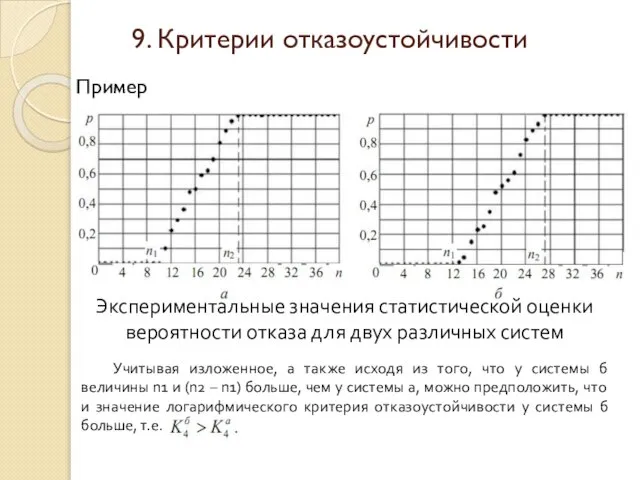
Слайд 35Пример
Экспериментальные значения статистической оценки
вероятности отказа для двух различных систем
Учитывая изложенное,
Пример
Экспериментальные значения статистической оценки
вероятности отказа для двух различных систем
Учитывая изложенное,
Слайд 36 Каждая i-я экспериментальная точка содержит в себе информацию о вероятности двух событий,

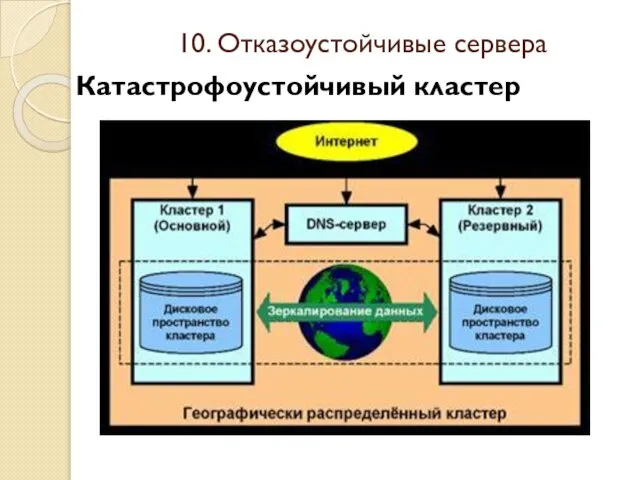
Слайд 37Катастрофоустойчивый кластер
10. Отказоустойчивые сервера
Катастрофоустойчивый кластер
10. Отказоустойчивые сервера
Слайд 38Отказоустойчивость виртуальных серверов:
В широком смысле слова, виртуализация – это программная имитация некоей
Отказоустойчивость виртуальных серверов:
В широком смысле слова, виртуализация – это программная имитация некоей

Слайд 39Отказоустойчивость виртуальных серверов
Преимущества:
-Рациональное использование аппаратных ресурсов
-Экономия денег, места и электроэнергии
-Удобство администрирования
Недостатки:
-Необходимость приобретения
Отказоустойчивость виртуальных серверов
Преимущества:
-Рациональное использование аппаратных ресурсов
-Экономия денег, места и электроэнергии
-Удобство администрирования
Недостатки:
-Необходимость приобретения

Слайд 40FAILOVER
FAILBACK
10. Отказоустойчивые сервера
FAILOVER
FAILBACK
10. Отказоустойчивые сервера
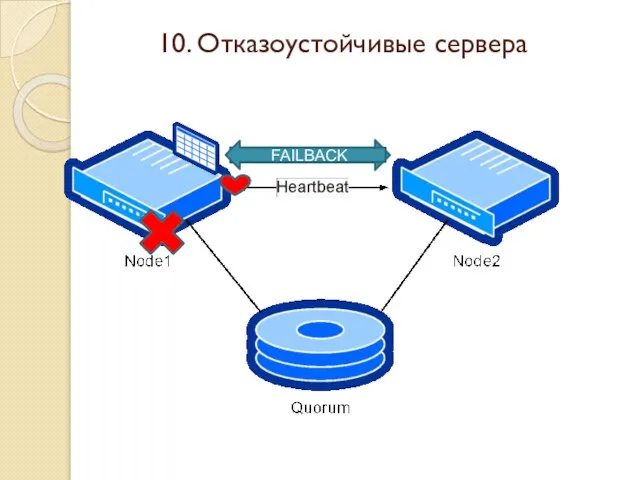
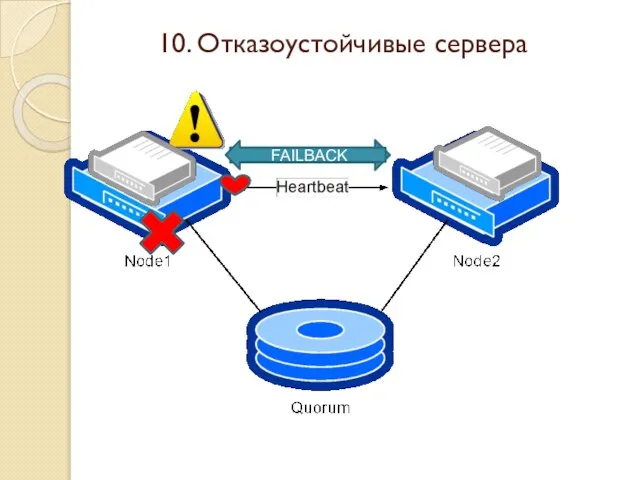
Слайд 41FAILOVER
FAILBACK
10. Отказоустойчивые сервера
FAILOVER
FAILBACK
10. Отказоустойчивые сервера
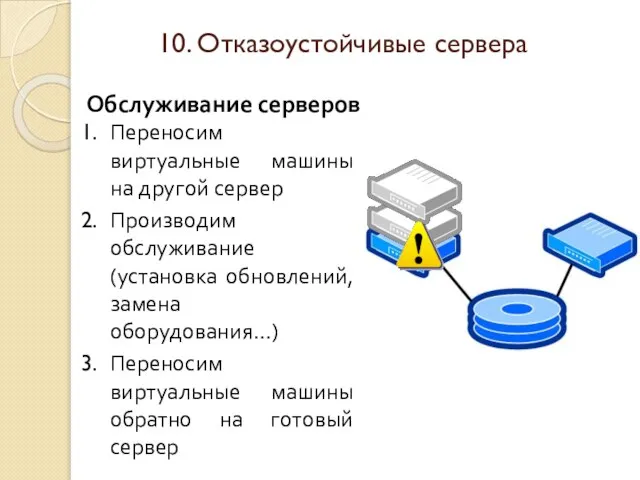
Слайд 42Обслуживание серверов
Переносим виртуальные машины на другой сервер
Производим обслуживание (установка обновлений, замена оборудования…)
Переносим
Обслуживание серверов
Переносим виртуальные машины на другой сервер
Производим обслуживание (установка обновлений, замена оборудования…)
Переносим
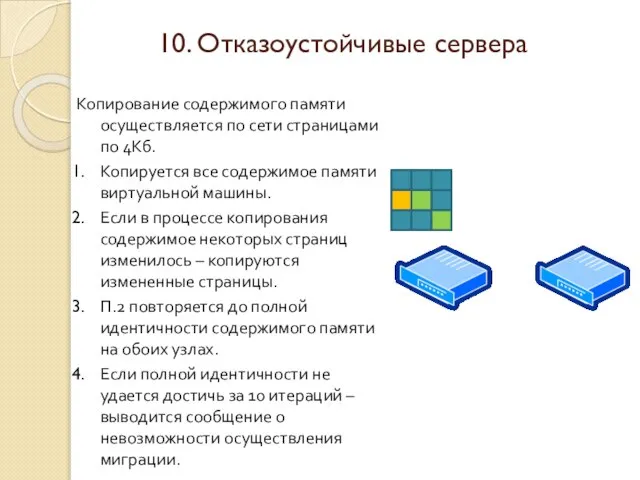
Слайд 43Копирование содержимого памяти осуществляется по сети страницами по 4Кб.
Копируется все содержимое памяти
Копирование содержимого памяти осуществляется по сети страницами по 4Кб.
Копируется все содержимое памяти
Слайд 44Выводы
Отказоустойчивость определяется как способность системы маскировать появление ошибок и исправлять их. Система
Выводы
Отказоустойчивость определяется как способность системы маскировать появление ошибок и исправлять их. Система

Слайд 45Выводы
В условиях протокола двухфазного подтверждения координатор сначала проверяет готовность всех процессов к
Выводы
В условиях протокола двухфазного подтверждения координатор сначала проверяет готовность всех процессов к

Слайд 46Выводы
Для повышения производительности множество распределенных систем сочетают контрольные точки с протоколированием сообщений.
Выводы
Для повышения производительности множество распределенных систем сочетают контрольные точки с протоколированием сообщений.

Слайд 47Список использованной литературы
Черкесов Г.Н. Надежность аппаратно-программных комплексов.
Рябинин И.А. Надежность и безопасность структурно
Список использованной литературы
Черкесов Г.Н. Надежность аппаратно-программных комплексов.
Рябинин И.А. Надежность и безопасность структурно

 Интерактивный квест Спасение эйленов
Интерактивный квест Спасение эйленов ОФБУ как форма управления активами
ОФБУ как форма управления активами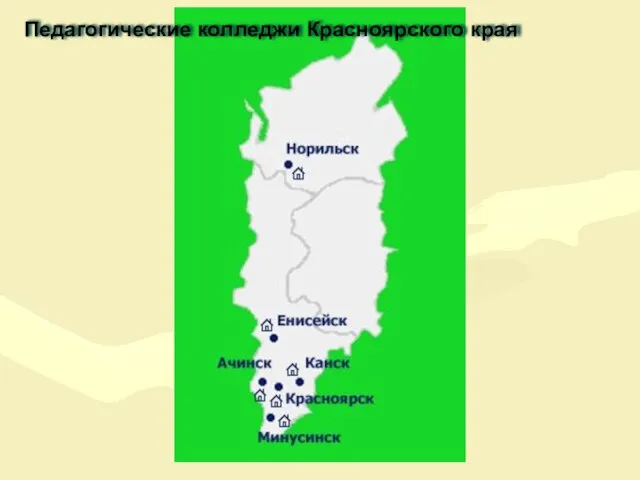 Педагогические колледжи Красноярского края
Педагогические колледжи Красноярского края Осторожно огонь
Осторожно огонь Требования, предъявляемые к лицам, назначаемым на должности прокуроров
Требования, предъявляемые к лицам, назначаемым на должности прокуроров А. Куприн «Слон»
А. Куприн «Слон» Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров
Что изменилось в отчетности за 9 месяцев: Декларация по НДС и прослеживаемость товаров Презентация на тему Вред здоровью человека от сотового телефона
Презентация на тему Вред здоровью человека от сотового телефона  «Роль игры в развитии речи дошкольника»
«Роль игры в развитии речи дошкольника» Спорт среди молодежи в Красноярске
Спорт среди молодежи в Красноярске Лувр
Лувр Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму»
Государственная поддержка субъектов предпринимательства в Республике Казахстан со стороны АО «Фонд «Даму» Моделирование при разработке управленческих решений. Разработка управленческого решения
Моделирование при разработке управленческих решений. Разработка управленческого решения Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори
Как на самом деле любить детей. «Именно любовь делает человека таким, каким он должен быть.» Подготовила воспитатель Кори Страницы истории
Страницы истории  Презентация на тему Петр 1
Презентация на тему Петр 1  5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование
5S: Сортировка. Систематизация. Сияние. Стандартизация. Самосовершенствование Использование современных образовательных технологий в процессе обучения русскому языку
Использование современных образовательных технологий в процессе обучения русскому языку Медведев Егор Бийск ОПШ 2022 (1) (1)
Медведев Егор Бийск ОПШ 2022 (1) (1) Россия выбирает президента
Россия выбирает президента Изображение головы человека в пространстве
Изображение головы человека в пространстве Искусство раннего Возрождения
Искусство раннего Возрождения Проверка домашнего задания
Проверка домашнего задания Новая сказка про Красную Шапочку
Новая сказка про Красную Шапочку Танковая навигационная аппаратура
Танковая навигационная аппаратура Social and personality development and types of play pre-school years
Social and personality development and types of play pre-school years  Презентация на тему ЗУНР Западно-Украинская Народная Республика
Презентация на тему ЗУНР Западно-Украинская Народная Республика  Спин - HIV
Спин - HIV