- Теоретико-графовые модели данных

Содержание
- 2. Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. В иерархической модели сегменты объединяются в ориентированный
- 3. На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели. Схема иерархической БД представляет собой
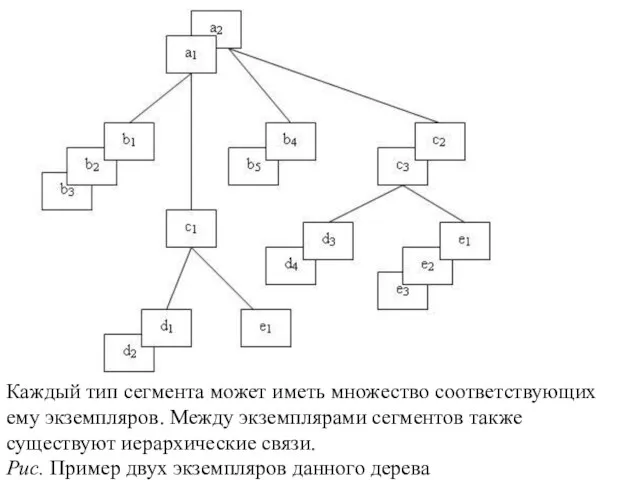
- 4. Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
- 5. Язык описания данных иерархической модели Языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования
- 6. Описание наборов данных, предназначенных для хранения БД: DATA SET D01 = . DEVICE = , [OVFLW
- 7. Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента. Для корневого
- 8. Для ранних иерархических моделей были определены только три типа данных: X — шестнадцатеричный, Р —упакованный десятичный,
- 9. Внешние модели Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный
- 10. Пример Указать модель, проверить наличие, полное описание индивидуальной модели.
- 11. Для индивидуальной модели нужна информация со склада
- 12. Язык манипулирования данными в иерархических базах данных Для доступа к базе данных у пользователя должна быть
- 13. Пример: Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
- 14. Получить перечень винчестеров со склада1, не менее 10 с объемом 10 Гб GET UNIQUE СКЛАД WHERE
- 15. Операторы поиска данных с возможностью модификации 1.Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой
- 16. Операторы модификации данных Удалить :DELETE Обновить : UPDATE Ввести новый экземпляр сегмента: INSERT Способ доступа, который
- 17. Сетевая модель данных Базовыми объектами модели являются: - элемент данных; - агрегат данных; - запись; набор
- 18. Пример Агрегат Адрес Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.
- 19. Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый граф, связывающий отношением «один-ко-многим»
- 20. Набор Два набора
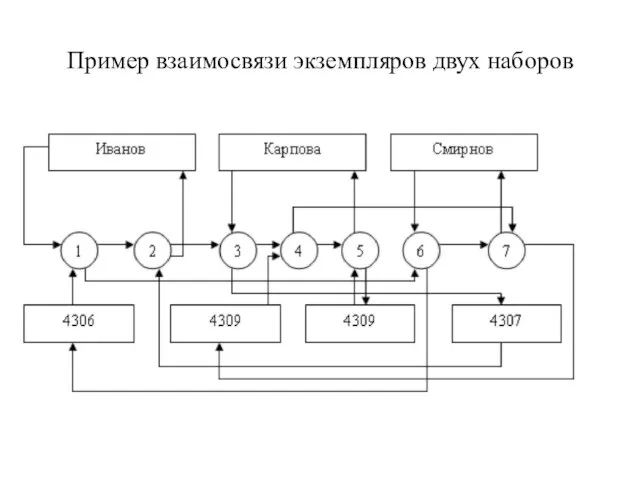
- 21. Пример взаимосвязи экземпляров двух наборов
- 22. Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого формально определена вся система.
- 23. Язык описания данных в сетевой модели Описание базы данных – области размещения Описания записей – элементов
- 24. Каждый тип записи должен быть приписан к некоторой физической области размещения: WITHIN AREA После описания записи
- 25. Описание набора и порядка включения членов в него выглядит следующим образом: SET NAME IS : OWNER
- 26. Язык манипулирования данными в сетевой модели Все операции манипулирования данными в сетевой модели делятся на навигационные
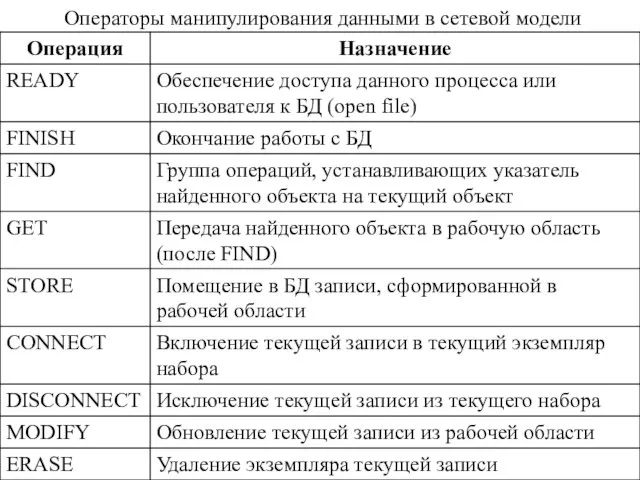
- 27. Операторы манипулирования данными в сетевой модели
- 28. В рабочей области пользователя хранятся шаблоны записей, программные переменные и три типа указателей текущего состояния: текущая
- 29. 2. Последовательный просмотр записей данного типа: FIND DUPLICATE RECORD BY CALC KEY 3. Найти владельца текущего
- 31. Скачать презентацию
Слайд 2Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели сегменты
Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента.
В иерархической модели сегменты

Слайд 3На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема иерархической
На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема иерархической

Слайд 4Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов
Слайд 5Язык описания данных иерархической модели
Языковые средства описания данных (DDL, Data Definition Language)
Язык описания данных иерархической модели
Языковые средства описания данных (DDL, Data Definition Language)

Слайд 6Описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя
Описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя

Слайд 7Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром
Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром

Слайд 8Для ранних иерархических моделей были определены только три типа данных: X —
Для ранних иерархических моделей были определены только три типа данных: X —

Слайд 9
Внешние модели
Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с
Внешние модели
Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с

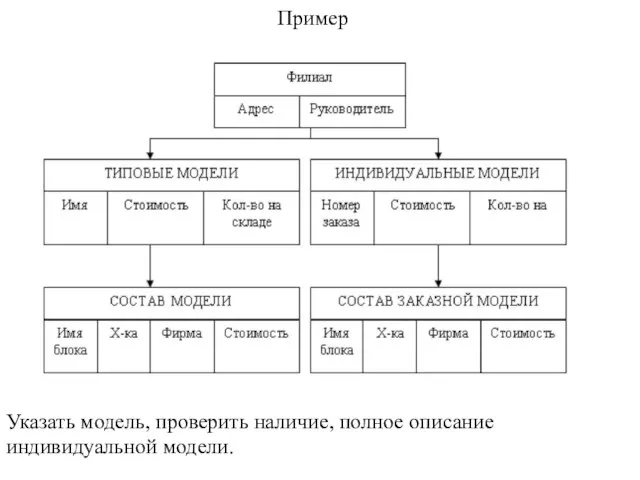
Слайд 10Пример
Указать модель, проверить наличие, полное описание индивидуальной модели.
Пример
Указать модель, проверить наличие, полное описание индивидуальной модели.
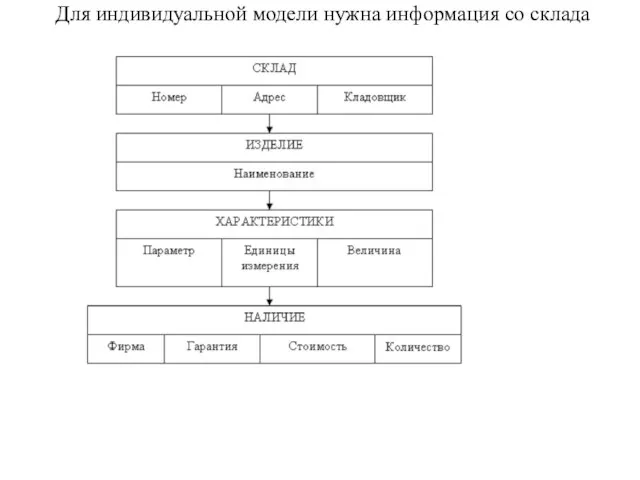
Слайд 11Для индивидуальной модели нужна информация со склада
Для индивидуальной модели нужна информация со склада
Слайд 12Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных у
Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных у

Слайд 13Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее чем
Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее чем

Слайд 14
Получить перечень винчестеров со склада1, не менее 10 с объемом 10 Гб
GET
Получить перечень винчестеров со склада1, не менее 10 с объемом 10 Гб
GET

Слайд 15Операторы поиска данных с возможностью модификации
1.Найти и удержать единственный экземпляр сегмента. Эта
Операторы поиска данных с возможностью модификации
1.Найти и удержать единственный экземпляр сегмента. Эта

Слайд 16
Операторы модификации данных
Удалить :DELETE
Обновить : UPDATE
Ввести новый экземпляр сегмента: INSERT <имя
Операторы модификации данных
Удалить :DELETE
Обновить : UPDATE
Ввести новый экземпляр сегмента: INSERT <имя

Слайд 17
Сетевая модель данных
Базовыми объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
набор
Сетевая модель данных
Базовыми объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
набор

Слайд 18Пример
Агрегат Адрес
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.
Пример
Агрегат Адрес
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных.

Слайд 19Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый
Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый

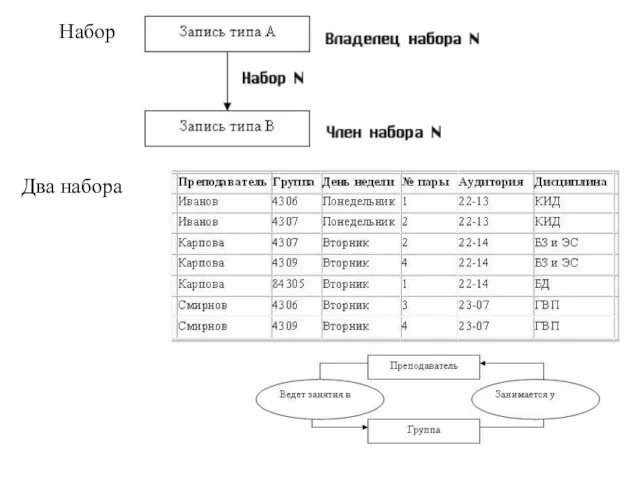
Слайд 20Набор
Два набора
Набор
Два набора
Слайд 21Пример взаимосвязи экземпляров двух наборов
Пример взаимосвязи экземпляров двух наборов
Слайд 22Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого
Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого

Слайд 23Язык описания данных в сетевой модели
Описание базы данных – области размещения
Описания записей
Язык описания данных в сетевой модели
Описание базы данных – области размещения
Описания записей

Слайд 24Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN <Имя
Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN <Имя

Слайд 25Описание набора и порядка включения членов в него выглядит следующим образом:
SET NAME
Описание набора и порядка включения членов в него выглядит следующим образом:
SET NAME

Слайд 26Язык манипулирования данными в сетевой модели
Все операции манипулирования данными в сетевой модели
Язык манипулирования данными в сетевой модели
Все операции манипулирования данными в сетевой модели

Слайд 27
Операторы манипулирования данными в сетевой модели
Операторы манипулирования данными в сетевой модели
Слайд 28В рабочей области пользователя хранятся шаблоны записей, программные переменные и три типа
В рабочей области пользователя хранятся шаблоны записей, программные переменные и три типа

Слайд 292. Последовательный просмотр записей данного типа:
FIND DUPLICATE <Имя записи> RECORD BY
2. Последовательный просмотр записей данного типа:
FIND DUPLICATE <Имя записи> RECORD BY

 Проектная деятельность на уроках технологии 6 класс
Проектная деятельность на уроках технологии 6 класс Презентация на темуПравописание О-Ё после шипящих и Ц в корнях, суффиксах всех частей речи
Презентация на темуПравописание О-Ё после шипящих и Ц в корнях, суффиксах всех частей речи Отряд Насекомых. Перепончатокрылые
Отряд Насекомых. Перепончатокрылые Футуризм в литературе и искусстве
Футуризм в литературе и искусстве Сравнительная характеристика особенностей формирования образа жизни учащихся общеобразовательных учреждений города Кирова
Сравнительная характеристика особенностей формирования образа жизни учащихся общеобразовательных учреждений города Кирова Административно-правовой статус
Административно-правовой статус Представляем Вашему вниманию новинку – коллекцию шампуней и бальзамов для волос «Поляница» BIO.
Представляем Вашему вниманию новинку – коллекцию шампуней и бальзамов для волос «Поляница» BIO. Текстильное разнообразие материалов
Текстильное разнообразие материалов Спортивные комплексы района
Спортивные комплексы района Бизнес-проект. Производство гусениц для тяжелой техники
Бизнес-проект. Производство гусениц для тяжелой техники Достопримечательности стран мира
Достопримечательности стран мира  Дню снятия блокады Ленинграда посвящается
Дню снятия блокады Ленинграда посвящается мезень
мезень Что такое Бенилюкс
Что такое Бенилюкс Использование графических ускорителей при решении задач обработки текстов
Использование графических ускорителей при решении задач обработки текстов Аксиомы в геометрии
Аксиомы в геометрии Московский театр Современник
Московский театр Современник Садово-парковое искусство Турции
Садово-парковое искусство Турции Маркетинговая оценка сбытовой деятельности предприятия
Маркетинговая оценка сбытовой деятельности предприятия Экономическая игра «БАНК. БИЗНЕС» Заместитель директора ВР Садирмекова М.А. 2010 год
Экономическая игра «БАНК. БИЗНЕС» Заместитель директора ВР Садирмекова М.А. 2010 год Кафедральная инновационная магистерская программа«Производственный менеджмент»
Кафедральная инновационная магистерская программа«Производственный менеджмент» Степан Разин
Степан Разин Мое представление о семье
Мое представление о семье Пути минимизации расходов на информационные системы и увеличения отдачи от деятельности информационных служб
Пути минимизации расходов на информационные системы и увеличения отдачи от деятельности информационных служб Об опыте антинаркотической работы медицинского кабинета профилактики ВИЧ-инфекции клинической инфекционной больницы им. С.П. Бот
Об опыте антинаркотической работы медицинского кабинета профилактики ВИЧ-инфекции клинической инфекционной больницы им. С.П. Бот Аттестационная работа. Создание творческого проекта Елочка
Аттестационная работа. Создание творческого проекта Елочка Презентация на тему Учёные степени и учёные звания
Презентация на тему Учёные степени и учёные звания  Российский государственный университет правосудия. Магистр частного права. Магистерская программа кафедры гражданского права
Российский государственный университет правосудия. Магистр частного права. Магистерская программа кафедры гражданского права