- Использование графических ускорителей при решении задач обработки текстов

Содержание
- 2. План Что такое GPU и CUDA Алгоритмы анализа данных Задачи обработки текстов
- 3. GPU и CUDA GPU = Graphic Processing Unit CUDA = Computing Unified Device Architecture
- 4. Почему графические ускорители (GPU)?
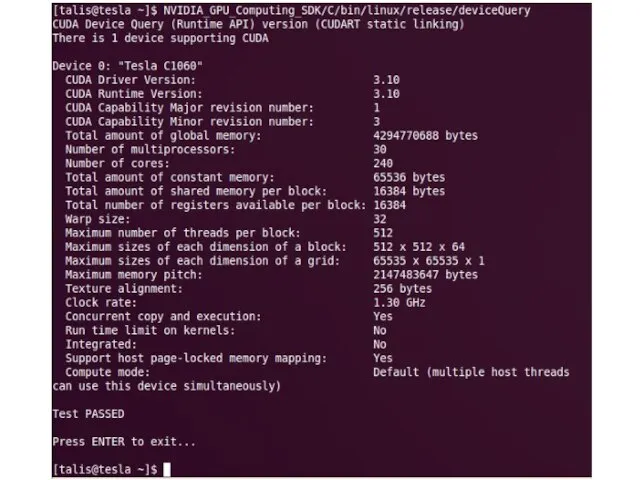
- 8. Внешний вид
- 9. Графические процессоры
- 11. #2 in Top500: NEBULAE 1.27 PFlops Linpack 2.9 PFlops peak
- 12. CUDA – почти С Единственное отличие – добавления для работы с потоками
- 13. Архитектура CUDA SIMD мультипроцессоры (8 или 16 ядер) Мультипроцессор имеет регистры и разделяемую (локальную) память Задача
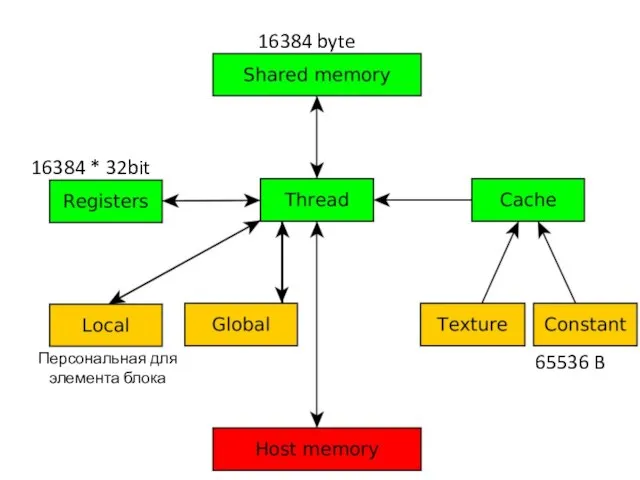
- 14. Общая для элементов блока Персональная для элемента блока
- 16. Персональная для элемента блока 16384 * 32bit 16384 byte 65536 B
- 18. Алгоритмы анализа данных Выявление ассоциативных зависимостей (Association rule mining, Apriori) Классификация (KNN) Кластеризация (K-means) Уменьшение размерности
- 19. Выявление зависимостей I={i1,...,im} — множество атрибутов База данных — набор записей вида (TID, i1, ..., ip)
- 20. Алгоритм выявления Найти все частотные 1-наборы Для k=2,... и пока есть новые наборы Построение k-кандидатов: объединение
- 21. Классификация Метод ближайших соседей Задана выборка объектов с приписанными метками Для нового объекта вычисляется расстояние до
- 22. Понижение размерности На вход алгоритма поступает матрица расстояний, принцип действия следующий: На плоскости случайным образом фиксируются
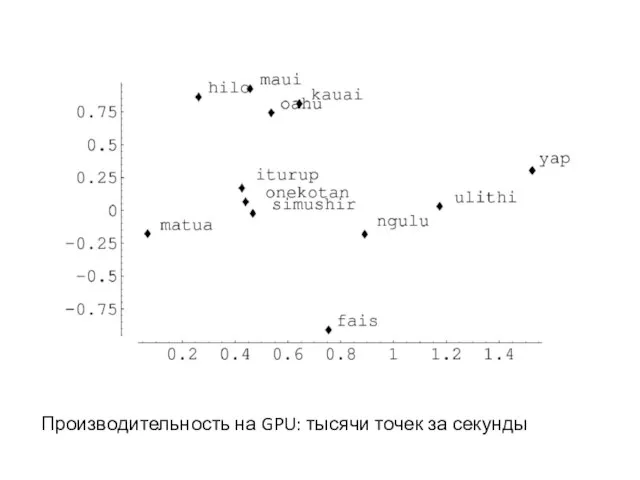
- 23. Производительность на GPU: тысячи точек за секунды
- 25. Скачать презентацию

Слайд 3GPU и CUDA
GPU = Graphic Processing Unit
CUDA = Computing Unified Device Architecture
GPU и CUDA
GPU = Graphic Processing Unit
CUDA = Computing Unified Device Architecture

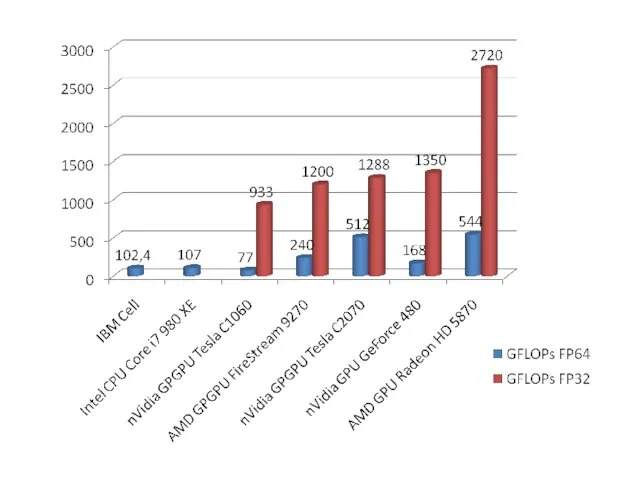
Слайд 4Почему графические ускорители (GPU)?
Почему графические ускорители (GPU)?

Слайд 8Внешний вид
Внешний вид

Слайд 9Графические процессоры
Графические процессоры


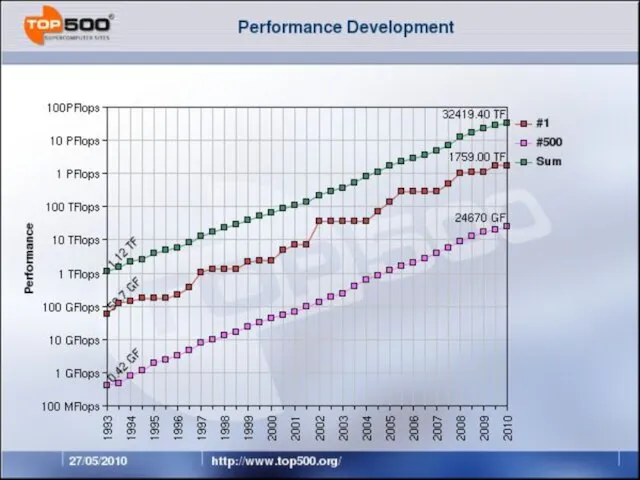
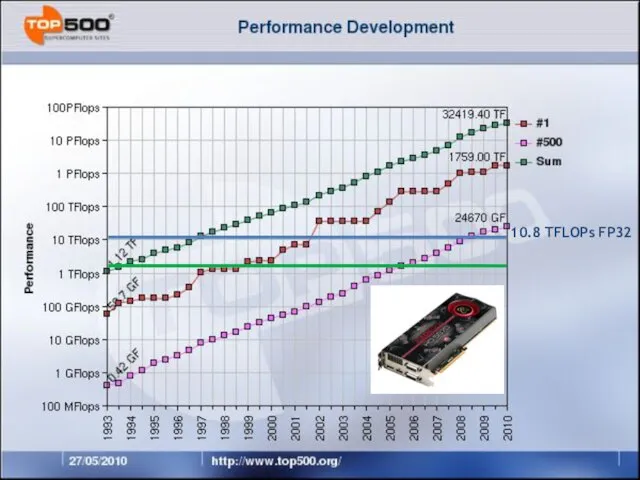
Слайд 11#2 in Top500: NEBULAE
1.27 PFlops Linpack 2.9 PFlops peak
#2 in Top500: NEBULAE
1.27 PFlops Linpack 2.9 PFlops peak

Слайд 12CUDA – почти С
Единственное отличие – добавления для работы с потоками
CUDA – почти С
Единственное отличие – добавления для работы с потоками

Слайд 13Архитектура CUDA
SIMD мультипроцессоры (8 или 16 ядер)
Мультипроцессор имеет регистры и разделяемую (локальную)
Архитектура CUDA
SIMD мультипроцессоры (8 или 16 ядер)
Мультипроцессор имеет регистры и разделяемую (локальную)

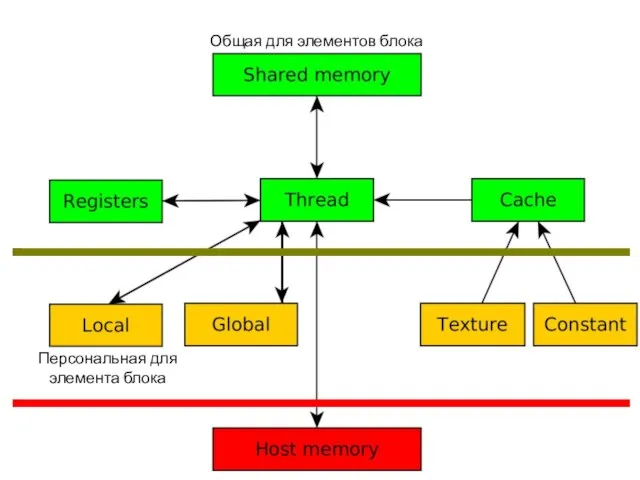
Слайд 14Общая для элементов блока
Персональная для
элемента блока
Общая для элементов блока
Персональная для
элемента блока
Слайд 16Персональная для
элемента блока
16384 * 32bit
16384 byte
65536 B
Персональная для
элемента блока
16384 * 32bit
16384 byte
65536 B

Слайд 18Алгоритмы анализа данных
Выявление ассоциативных зависимостей (Association rule mining, Apriori)
Классификация (KNN)
Кластеризация (K-means)
Уменьшение размерности
Алгоритмы анализа данных
Выявление ассоциативных зависимостей (Association rule mining, Apriori)
Классификация (KNN)
Кластеризация (K-means)
Уменьшение размерности

Слайд 19Выявление зависимостей
I={i1,...,im} — множество атрибутов
База данных — набор записей вида (TID, i1,
Выявление зависимостей
I={i1,...,im} — множество атрибутов
База данных — набор записей вида (TID, i1,

Слайд 20Алгоритм выявления
Найти все частотные 1-наборы
Для k=2,... и пока есть новые наборы
Построение k-кандидатов:
Алгоритм выявления
Найти все частотные 1-наборы
Для k=2,... и пока есть новые наборы
Построение k-кандидатов:

Слайд 21Классификация
Метод ближайших соседей
Задана выборка объектов с приписанными метками
Для нового объекта вычисляется расстояние
Классификация
Метод ближайших соседей
Задана выборка объектов с приписанными метками
Для нового объекта вычисляется расстояние

Слайд 22Понижение размерности
На вход алгоритма поступает матрица расстояний, принцип действия следующий:
На плоскости случайным
Понижение размерности
На вход алгоритма поступает матрица расстояний, принцип действия следующий:
На плоскости случайным

Слайд 23Производительность на GPU: тысячи точек за секунды
Производительность на GPU: тысячи точек за секунды
 Презентация на тему Причины возникновения МОТ и история ее развития
Презентация на тему Причины возникновения МОТ и история ее развития Этапы продаж
Этапы продаж Разработка конструкции, методики диагностики, ремонта, настройки функционального узла (Цифровой регулятор напряжения (ЦРН))
Разработка конструкции, методики диагностики, ремонта, настройки функционального узла (Цифровой регулятор напряжения (ЦРН)) Этикет Вайшнава
Этикет Вайшнава Портрет. Работы детей фотостудий
Портрет. Работы детей фотостудий Учебный Центр БИТ
Учебный Центр БИТ Презентация на тему Азербайджан
Презентация на тему Азербайджан Техника безопасности на занятиях гимнастикой. Группы мышц и способы их развития
Техника безопасности на занятиях гимнастикой. Группы мышц и способы их развития Реализация деятельностного подхода в обучении через проектную методику
Реализация деятельностного подхода в обучении через проектную методику Явление радиоактивности и его значение в медицине.
Явление радиоактивности и его значение в медицине. Комплексный подход кавтоматизацииЖКХ
Комплексный подход кавтоматизацииЖКХ Биография Петра I
Биография Петра I Построение графиков функций, содержащих знак модуля
Построение графиков функций, содержащих знак модуля Рисуем животных
Рисуем животных Восточные танцы
Восточные танцы Перестрахование в ОСАГО
Перестрахование в ОСАГО Расчёт напряженно-деформированного состояния лопатки компрессора авиационного двигателя
Расчёт напряженно-деформированного состояния лопатки компрессора авиационного двигателя Музыка в истории психологии
Музыка в истории психологии portfolio
portfolio Арбитражный процесс
Арбитражный процесс Продаем с порога
Продаем с порога Презентация на тему Потребность в сне и отдыхе
Презентация на тему Потребность в сне и отдыхе  ИССЛЕДОВАНИЕ ТЕКСТОВ, ВЫПОЛНЕННЫХ «ПЕЧАТНЫМ» ПОЧЕРКОМ
ИССЛЕДОВАНИЕ ТЕКСТОВ, ВЫПОЛНЕННЫХ «ПЕЧАТНЫМ» ПОЧЕРКОМ Эти загадочные – теплые, мягкие, пушистые
Эти загадочные – теплые, мягкие, пушистые Защита информации в Пенсионном фонде Российской Федерации
Защита информации в Пенсионном фонде Российской Федерации А. С. Пушкин Капитанская дочка
А. С. Пушкин Капитанская дочка Николаев Максим 5б
Николаев Максим 5б Презентация на тему Как я выбираю свою будущую профессию
Презентация на тему Как я выбираю свою будущую профессию