- Визуализация статистики вхождения слов

Содержание
- 2. При подборе ключевых слов для поиска важно учитывать такое их свойство, как «различительная» или дискриминантная сила.
- 3. Нами реализованы инструментальные средства позволяющие визуализировать плотность встречаемости слова в тексте в зависимости от ширины окна
- 4. В результирующей спектограмме по горизонтали откладываются номера вхождения слова в тексте, а по вертикали - ширина
- 8. Для исследований распределения слов представляет интерес числовая последовательность, составленная из расстояний между появлениями слов в тексте.
- 9. Такие последовательности позволяют ответить на вопросы, актуальные при автоматическом поиске и реферировании текстовых массивов/документов. Например, представляется,
- 10. В естественных науках как величина меры «изрезанности» числовых последовательностей используется показатель Херста, который вычисляется на основании
- 12. Скачать презентацию

Слайд 3Нами реализованы инструментальные средства позволяющие
визуализировать плотность встречаемости слова в тексте в
Нами реализованы инструментальные средства позволяющие
визуализировать плотность встречаемости слова в тексте в
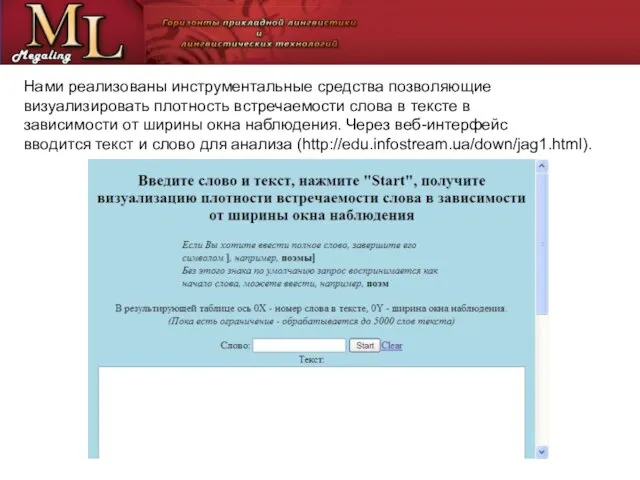
Слайд 4В результирующей спектограмме по горизонтали откладываются номера
вхождения слова в тексте, а
В результирующей спектограмме по горизонтали откладываются номера
вхождения слова в тексте, а
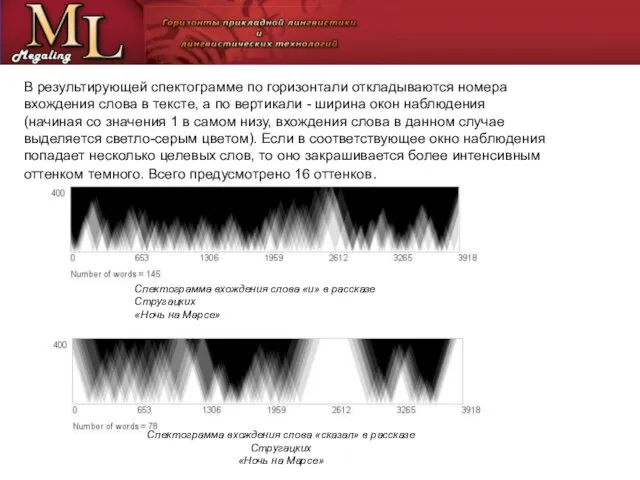


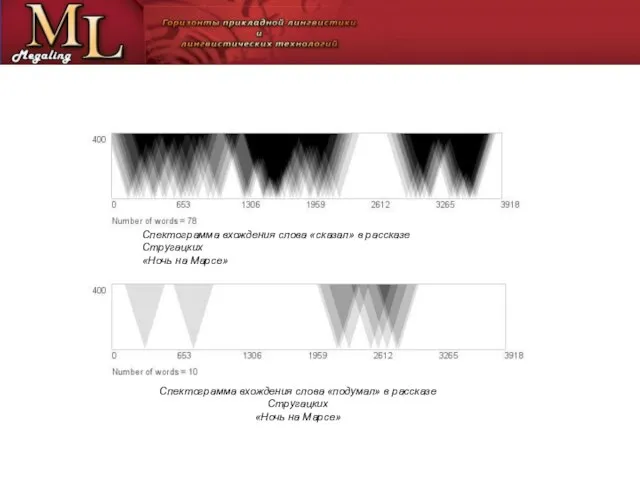
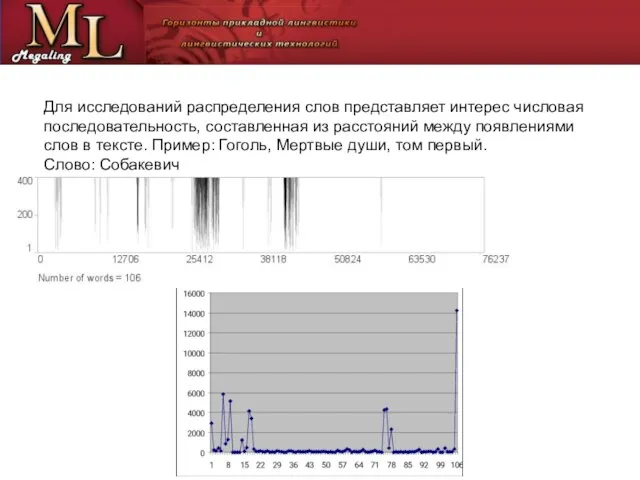
Слайд 8Для исследований распределения слов представляет интерес числовая
последовательность, составленная из расстояний между появлениями
Для исследований распределения слов представляет интерес числовая
последовательность, составленная из расстояний между появлениями
Слайд 9Такие последовательности позволяют ответить на вопросы, актуальные при
автоматическом поиске и реферировании
Такие последовательности позволяют ответить на вопросы, актуальные при
автоматическом поиске и реферировании

Слайд 10В естественных науках как величина меры «изрезанности» числовых
последовательностей используется показатель Херста, который
В естественных науках как величина меры «изрезанности» числовых
последовательностей используется показатель Херста, который

 Договор купли-продажи виды содержание ответственность за неисполнение
Договор купли-продажи виды содержание ответственность за неисполнение ПЕРСПЕКТИВЫ РАЗВИТИЯ БИБЛИОТЕК В XXI ВЕКЕ
ПЕРСПЕКТИВЫ РАЗВИТИЯ БИБЛИОТЕК В XXI ВЕКЕ Жесты и мимика
Жесты и мимика «Она в любовь верила – эта великая женщина!»
«Она в любовь верила – эта великая женщина!» Что мы знаем о законе
Что мы знаем о законе ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА БАКАЛАВРАпо направлению «031100.62 – Лингвистика»на тему:«Когнитивный анализ предикатных выраж
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА БАКАЛАВРАпо направлению «031100.62 – Лингвистика»на тему:«Когнитивный анализ предикатных выраж 1С:Автоматизация.Управление рабочим временем 8.0 (ред.1.0)
1С:Автоматизация.Управление рабочим временем 8.0 (ред.1.0) Правовой режим тайны регистрации
Правовой режим тайны регистрации Проект Барс
Проект Барс Введение в научную деятельность
Введение в научную деятельность Александр Сергеевич Пушкин
Александр Сергеевич Пушкин Загадки про осень 1-4 класс
Загадки про осень 1-4 класс Размещение рекламных материалов в фитнес-клубах г. Москвы
Размещение рекламных материалов в фитнес-клубах г. Москвы Прикладная архитектурная акустика
Прикладная архитектурная акустика МОЗАИКА
МОЗАИКА Пакеты прикладных программ для математической обработки данных
Пакеты прикладных программ для математической обработки данных Happy Halloween
Happy Halloween «Кнопка Запуска» внутренних ресурсов.
«Кнопка Запуска» внутренних ресурсов. проф качест
проф качест Презентация на тему Животные Севера
Презентация на тему Животные Севера  э
э «Если бы природа могла чувствовать благодарность к человеку за то, что он проник в ее тайную жизнь и воспел ее красоту, то, прежде вс
«Если бы природа могла чувствовать благодарность к человеку за то, что он проник в ее тайную жизнь и воспел ее красоту, то, прежде вс Презентация на тему Формирование современной образовательной инфраструктуры: новые подходы, модели
Презентация на тему Формирование современной образовательной инфраструктуры: новые подходы, модели Найди решение. Конкурс стартапов. Наша земля. Твой проект
Найди решение. Конкурс стартапов. Наша земля. Твой проект Благотворительная
Благотворительная Презентация "Живопись и скульптура Микеланджело" - скачать презентации по МХК
Презентация "Живопись и скульптура Микеланджело" - скачать презентации по МХК Веселые моменты школьной жизни
Веселые моменты школьной жизни История возникновения книги
История возникновения книги