- Языки и методы конструирования программ

Содержание
- 2. Содержание Лекция 1. Модель вычислений фон Неймана и традиционные языки Лекция 2. Нетрадиционные модели вычислений Лекция
- 3. Лекция 1. Модель вычислений фон Неймана и традиционные языки
- 4. Каноническая архитектура фон Неймана Три элемента вычислительной системы: Память Процессор Управляющее устройство Однородность памяти и адресация
- 5. Схема выполнения двухадресной команды
- 6. Модификация канонической схемы
- 7. Альтернатива канонической схемы Разрешить выполнение всех команд, для которых готовы операнды Замена хранения результата передачей его
- 8. Особенности традиционных языков Присваивание значений (переменная — аналог ячейки) Операторы (зависимость выполнения, последовательность) Структура управления (разветвления
- 9. Присваивание значений a = процессор память Оператор Выполнение – команда Зависимость одного от другого (изменение памяти)
- 10. Приведения Типов выражения и переменной в присваивании Округление и отбрасывание Контролируемые (явно указываемые) и по умолчанию
- 11. Подпрограммы Типовой прием группировки команд Повторяемые действия Модульность Современное понимание (расширено)
- 12. Нарушения канона: побудительные причины Повышение эффективности Повышение выразительности Фиксация типовых приемов программирования Нарушение однородности памяти Сегментация
- 13. Традиционные языки (некоторые) Fortran (IV, 76, 90, 95, 2000, 2003, …) Algol 60 Simula, Simula 67
- 14. Лекция 2. Нетрадиционные модели вычислений
- 15. Повелительное и изъявительное наклонения Изъявительное наклонение и развитость языка Идеи внедрения изъявительного наклонения Системы продукций Системы
- 16. Системы продукций Соотношения записываются как правила вывода: Левая Часть => Правая Часть Обрабатываемые данные сопоставляются с
- 17. Системы функций Программа – соотношение между функциями, связанных между собой аргументами, которые в свою очередь могут
- 18. Коммутационные системы Элемент системы – вершина графа (входные и выходные места) Дуги – каналы передачи значений
- 19. Ассоциативные системы Элементы системы — активные данные, представляющие собой пары: Спаривание элементов с одинаковыми ключами ->
- 20. Ассоциативные системы Элементы системы — активные данные, представляющие собой пары: Спаривание элементов с одинаковыми ключами ->
- 21. Аксиоматические системы Аксиомы Описание знаний на фиксированном языке Классическая логика – соотношение между данными Вывод теорем
- 22. Programming styles and structuring. Program and data structuring from three points of view Task: output (
- 23. Стили программирования • Программирование от состояний; • Структурное программирование; • Сентенциальное программирование; • Программирование от событий;
- 24. Лекция 3. Ленивые вычисления и функциональная модель
- 25. Ленивые и жадные вычисления Необходимость и возможность вычисления Принцип ленивости (рекурсивный ответ на вопрос): Что из
- 26. Необходимости при выполнении процедуры procedure P (in a, out b); … P (6*8, x); Когда появляется
- 27. Метод обобщения специфичного в функциональном программировании list of x = nil | cons x (list of
- 28. Метод обобщения специфичного (продолжение) reduce f x nil = x reduce f x (cons a l)
- 29. Gluing Functions Together: Composition and Map A function to double all the elements of a list
- 30. Lazy Evaluation: Scheme F and G — programs: ( G.F ) input G ( F
- 31. Лекция 4. Постулаты необходимости, их следствия. Особенности ленивых и жадных вычислений при решении различных задач
- 32. Постулаты необходимости Любое вычисление активизируется тогда и только тогда, когда оно (его результат) требуется для осуществимости
- 33. Следствия постулатов необходимости То, что ленивые вычисления задают управление программы через потоки данных, следует из постулатов
- 34. Конкретизации необходимости Для императивного языка Необходимость, определяется правилами, задающими поток управления в программе (декларируется необходимость выполнения
- 35. Пример-иллюстрация F строит «очень большое» дерево (например, всех возможных последовательностей ходов) G запрашивает поддерево фиксированной глубины,
- 36. Лекция 5. Решение численных задач в функциональном стиле
- 37. Метод Ньютона-Рафсона: вычисление квадратного корня Функциональная программа не эффективна. Правда ли это? Алгоритм: Начинать с первой
- 38. Метод Ньютона-Рафсона: функциональная программа Первый вариант: next N x = (x + N/x) / 2 [a0,
- 39. Численное дифференцирование easydiff f x h = (f (x + h) - f (x)) / h
- 40. Лекция 6. Ленивые вычисления: императивные примеры
- 41. Boolean выражения ℜ ≡ α&β&γ : (α == false) ⇒ ℜ == false (α == true)
- 42. Анализ ленивого и жадного cat File_F | grep WWW | head -1 Жадный вариант: cat File_F
- 43. Мемоизация Программа F (n) = F (n-1) + F (n-2) традиционный пример, когда рекурсия вредна
- 44. Анализ векторно-матричного примера Consider the example more closely: a = b + c + d; t1
- 45. Лекция 7. Элементы сентенциального стиля программирования
- 46. Что такое сентенциальное программирование? Sentence – предложение → грамматика, определяющая все правильные предложения Обрабатываемые данные имеют
- 47. E → T 1| E + T 2| E – T 3 T → I 4|
- 48. Логический вывод утверждений на основе фактов и язык Prolog Семья (МАША и САША) – предикат, истинность
- 49. Фразовые формы, резолюция, унификация P1 ˅ P1 ˅ … ˅ Pn ˅ N1 ˅ N2 ˅
- 50. Нисходящая (обратная) стратегия T = { P(a) ˅ ~Q(b,c) Q(x,y) ˅ ~R(x,y) S(b) R(a,b) } Является
- 51. Семантика Prolog’а начальник(Фамилия, Оклад) :— служащий(Фамилия, Оклад), Оклад > 70000 Декларативная модель: Некое лицо (Фамилия) является
- 52. Пример: обращение списка % Метод 1 / с правом для присоединить обр_порядок ([C|L1], L2) :- обр_порядок
- 53. Prolog’овские базы знаний Что такое база знаний vs. база данных? Представление знаний Вычислительные формализмы: Дескриптивный язык
- 54. Задания Написать на Prolog’е программу дифференцирования Где оканчивается адекватная применимость Prolog’а? Чем означивание (в двух его
- 55. Сопоставление строки α ∈T* с образцом π = , где Pi, – составляющие (подтермы) элементы, из
- 56. Сопоставление с образцом: примеры Пусть α ∈{‘a’, ‘b’, …, ‘z’}* = T* = → α′0 –
- 57. Рефал: основная идея Приспособить к практическим нуждам теоретический Алгорифм Маркова: { αi → βi }, где
- 58. Основные символы, структурированные строки αi строится как структурированная строка, из следующего: символы T, не являющиеся скобками.
- 59. Рефал: продукции (операторы языка) Продукции Рефала принимают следующий вид: kαi.→βi (левая часть → правая часть) где
- 60. Проецирование строки αi = X1... Xu...Xr продукции k αi. → βi на перерабатываемую строку Все следующие
- 61. Применение продукции kαi. → βi построение проекции αi на α′i (одной из возможных), построение β′i по
- 62. Разрешение неоднозначностей При неоднозначном выборе проекции αi на α′i предпочтение отдается той проекции, удовлетворяющей одному из
- 63. Дополнение основного механизма Цель: сужение вариантов проецирования, снижение возможной недетерминированности, как следствие, повышение эффективности вычислений, повышение
- 64. Содержательный пример: дифференцирование (функция k/dif/) 1. ke1. → k/dif/e1. 2. k/dif/v1+v2. → (k/dif/v1.+k/dif/v2.) 3. k/dif/v1*v2. →
- 65. Продолжение примерa Дифференцирование a*x+bx*(c+x)+d ka*x+bx*(c+x)+d. ⇒/1/ k/dif/a*x+bx*(c+x)+d. ⇒/2/ (k/dif/a*x.+k/dif/bx*(c+x)+d.) ⇒/2/ (k/dif/a*x.+(k/dif/bx*(c+x).+k/dif/d.)) ⇒/3/ ((k/dif/a.*(x)+k/dif/x.*(a))+(k/dif/bx*(c+x).+ k/dif/d.)) ⇒/7,6/ ((0*(x)+1*(a))+(k/dif/bx*(c+x).+k/dif/d.))
- 66. Внешние вычисления в Рефале Арифметические вычисления нерациональны: k/sum/v1+v2. → k/sum/ k/plus1/v1. + k/minus1/v2.. k/sum/v1+1. → k/plus1/v1.
- 67. Схема вычисления Peфал программы
- 68. Представление строки kAB(CD)(E)F. в поле зрения Рефал-машины
- 69. Лекция 9. Концепция «Model View Controller» (что не удалось сделать в Delphi)
- 70. Система и ее декомпозиция Система – набор связанных между собой и взаимодействующих компонент. Это структура системы
- 71. Декомпозиция и моделирование Моделирование предполагает абстрагирование от несущественных с точки зрения рассмотрения деталей и выделение того,
- 72. Виды декомпозиции Стихийная (Почему это плохо? Когда приемлемо?) Концептуальная – уровень соглашений о системе Проектная –
- 73. MVC – это: Концептуальная декомпозиция приложения, которая следует постулату разделения трех сущностей: Понятия, объекты, действия и
- 74. Отвечает за взаимодействие с Model и View, обрабатывает пользовательский ввод формирует запросы к View и передает
- 75. Зачем нужно выделять View? Model Controller Пользователь U-Model Задача U-Control Задача View Абстрактный уровень Конкретный уровень
- 76. Информация для выбора представлений Model ↔ View + User Абстрактное представление (abstract view) Абстрактный синтаксис (abstract
- 77. Model ↔ Controller Информация для управления: Состояние системы, Данные, перерабатываемые приложением, Условия корректности изменений Model Команды
- 78. Controller ↔ View Controller View Формы для представления информации на абстрактном уровне: Воздействия пользователей и окружения,
- 79. Прагматическая точка зрения: При реализации систем для разных пользователей (разные view, а функционирование подобно) Стандартизация интерфейса
- 80. Немного истории Delphi продукт года → другие системы (C/C++ Builder, MS Visual Studio и др.) Swing
- 81. Лекция 10. Жизненный цикл программного обеспечения и его модели
- 82. Мотивация изучения жизненного цикла и его моделей Жизненный цикл — база методологий Жизненные циклы технических и
- 83. Жизненный цикл программного обеспечения: определение Цикл разработки, Издержки после завершения разработки Жизненный цикл — это проекция
- 84. Задача методологии и жизненный цикл Методологии — это инструменты, с помощью которых создание программного продукта превращается
- 85. Модели процесса и продукта Модель процесса разработки: Целенаправленное развитие объекта под воздействием разработчиков Ключевые понятия: развитие,
- 86. Лекция 11. Классические модели
- 87. Общепринятая модель жизненного цикла программного обеспечения
- 88. Общепринятая модель — источник базовых понятий Начало разработки — идентификация потребности Определение требований — определяются: контекст
- 89. Классическая итерационная модель Отражает потребность исправления ошибок пройденных этапов!
- 90. Исправление ошибок или адаптивность проекта? Классическая итерационная модель — абсолютизация возможности возвратов для исправления ошибок, т.е.
- 91. Каскадная модель Чем заканчи- ваются этапы
- 92. Каскадная модель: новые понятия Характерные черты каскадной модели: завершение этапов проверкой полученных результатов циклическое повторение пройденных
- 93. Строгая каскадная модель Чем заканчи- ваются этапы Удалены «лишние» возвраты За счет чего это достигается?
- 94. Строгая каскадная модель: дополнительные требования к разработке проекта Минимизация возвратов за счет ликвидации переходов через уровни
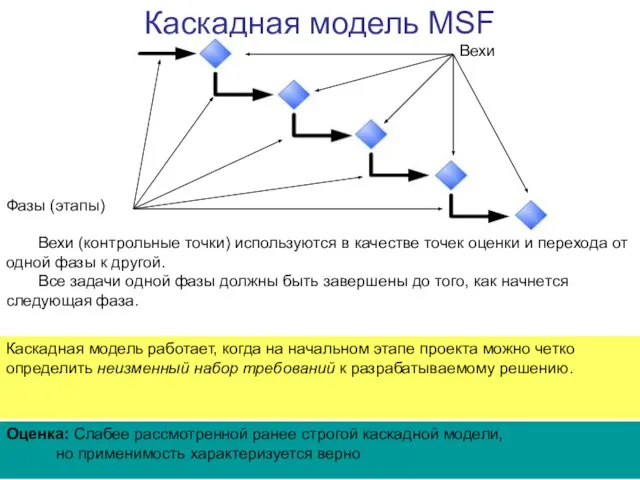
- 95. Каскадная модель MSF Вехи (контрольные точки) используются в качестве точек оценки и перехода от одной фазы
- 96. Вопросы и задания Какие из рассмотренных моделей можно сделать инструментальными, а какие не допускают этого? Ответ
- 97. Лекция 12. Развитые модели жизненного цикла: Производственные функции в моделировании жизненного цикла: модель фазы — функции
- 98. Модель фазы—функции Гантера: Анализ осущест- Конструиро- вание → Программирование → Оценка → Фазы (этапы) ←5 Спецификации
- 99. Основной тезис: На разных этапах функции имеют различное содержание, требуют различной интенсивности, при реализации проекта совмещаются.
- 100. 10 Модель фазы—функции Гантера: функциональное измерение Программирование → Оценка → Фазы: 0 Планирование Разработка Обслуживание Выпуск
- 101. Вариативность модели Гантера В зависимости от проекта функции можно трактовать свободно, дополнять другими классами функций, игнорировать
- 102. Учет итеративности в модели фазы—функции Программирование → Оценка → Использование → Фазы (этапы) Контрольные точки Конструиро-
- 103. Моделирование жизненного цикла объектно-ориентированных программных проектов
- 104. Принципы объектно-ориентированного проектирования Итеративность развития — возможность перейти от последовательного развития к стратегии итеративного наращивания возможностей
- 105. Моделирование при объектно-ориентированном проектировании Распределение реализуемых требований по итерациям: Совокупность сценариев, реализуемых на очередной итерации +
- 106. ←5 Спецификации утверждены ←6 Автономная проверка завершена, комплексное тестирование началось ← Программирование → ← Оценка →
- 107. Контрольные точки и вехи Контрольные точки (check points) — точки линии жизни жизненного цикла проекта, в
- 108. Для каждой итерации должны быть определены: Общие требования — что требуется от проекта в целом в
- 109. Жизненный цикл при объектно-ориентированном развитии проекта (функциональное измерение) Планирование Разработка Обслуживание Выпуск документации Испытания Поддержка Сопровождение
- 110. Дополнительные лекции Лекция A. Введение в базы данных: мотивация СУБД
- 111. Структурированные файлы и базы данных Файл как последовательность записей → справедливая мысль о связи понятий файла
- 112. Структурированные файлы и базы данных Файл как последовательность записей → справедливая мысль о связи понятий файла
- 113. Комплекс программ для поддержки работы приемной комиссии вуза Роли: абитуриент, секретарь, экзаменатор, посетитель и привилегированный посетитель,
- 114. Проектирование БД и задача унификации Какое отношение проектирование имеет к файлам? Система файлов – среда, в
- 115. Автоматизация работы приемной комиссии: структура информации об абитуриенте type TAbit = record ... end; var FileAbitInf
- 116. Требования к типу Tabit Фамилия непригодна для однозначного соответствия: существуют однофамильцы; поиск записи, содержащей строковое поле
- 117. Выбор структуры для типа TAbit const lName = 10; type TAbit = record RegNum : Word;
- 118. Выбор структуры для типа TAbit const lName = 10; type TAbit = record RegNum : Word;
- 119. Анализ выбранной структуры для типа Tabit Разумна ли выбранная структура? Нет! Для поиска абитуриентов из одного
- 120. Обсуждение модернизации типа TAbit Целесообразность разбиения информационного массива БД на несколько файлов: для повышения эффективности для
- 121. Почему нужны СУБД F (ki : T) 1 2 n Вычисляется заранее ∀ k F (k)
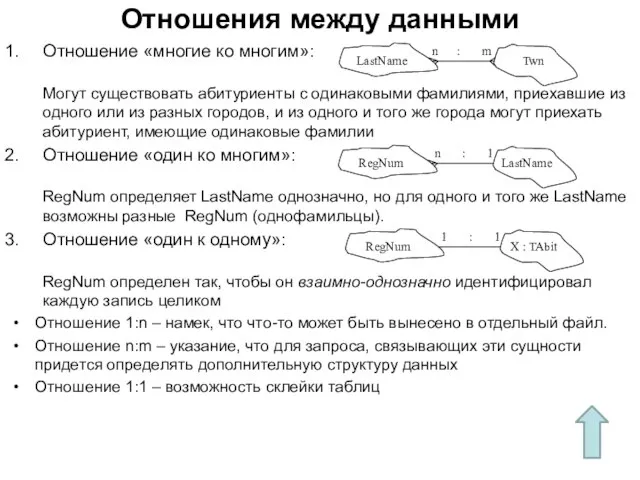
- 122. Отношения между данными Отношение «многие ко многим»: Могут существовать абитуриенты с одинаковыми фамилиями, приехавшие из одного
- 123. Лекция B. Модели баз данных
- 124. Модели баз данных.Что это? Данные: хранятся, появляются, уничтожаются, предоставляются – пассивные Сведения: формируются, сообщаются, передаются –
- 125. Иерархическая модель Понятия иерархий и отношений, задающих иерархии Иерархии для накопления данных, а также поиска и
- 126. Сетевая модель Используется граф: вершины данные, дуги используются для навигации (узнали гипертекстовый html?) Есть естественная (сетевая)
- 127. Реляционная модель: неформальное определение Дейт: вся информация в базе данных представлена в таблицах; поддерживается три реляционные
- 128. Таблицы и базы данных (1) таблица строка столбец table row column отношение кортеж атрибут relation tuple
- 129. Независимость: на логическом уровне на физическом уровне Независимость данных (2) Изменение взаимосвязей между таблицами не влияет
- 130. Манипулирование данными (ЯМД); Определение данных (ЯОД); Определение хранимых данных (ЯОХД) Администрирование (управление) Все это есть в
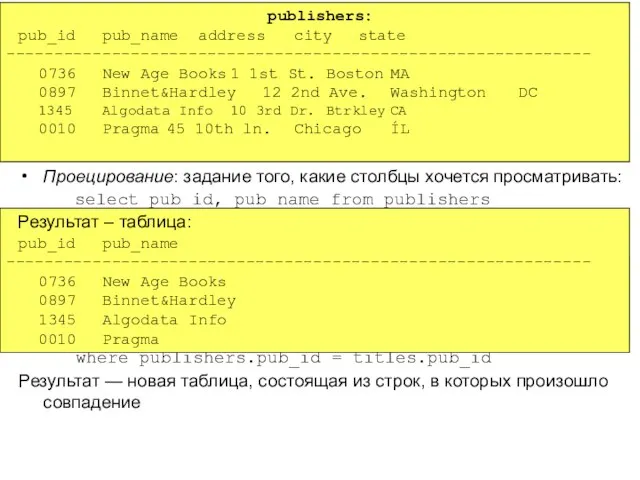
- 131. Манипулирование данными: выборка select * from publishers вставка строки insert into publishers values (‘0010’,‘Pragma’,‘45 10th ln.’,‘Chicago’,‘ÍL’)
- 132. Основа всех операций – оператор select Синтаксис (упрощенный): select from where Проецирование: задание того, какие столбцы
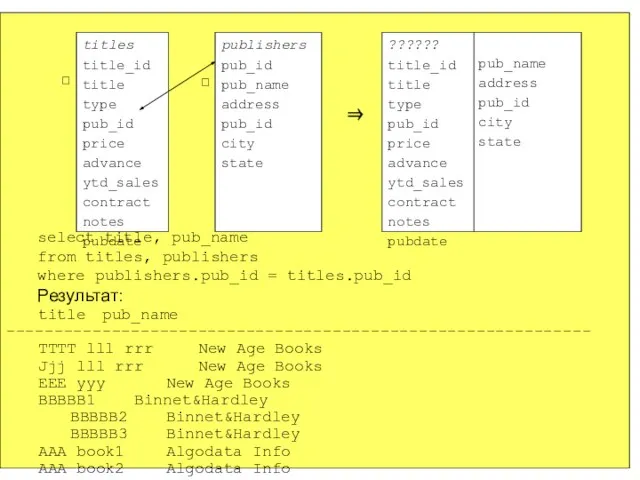
- 133. select title, pub_name from titles, publishers where publishers.pub_id = titles.pub_id Результат: title pub_name ------------------------------------------------------------- TTTT lll
- 134. Реляционные и теоретико-множественные операции (4 - продолжение) А почему бы не использовать объединенную таблицу? Ответ: дублирование
- 135. Виртуальные таблицы(5) Альтернативный способ просмотра данных: образование виртуальной таблицы, или курсора (view), или производной таблицы create
- 136. Безопасность: авторизация (7.2) Права доступа и роли → авторизация — механизм «знания» системой имен ее пользователей
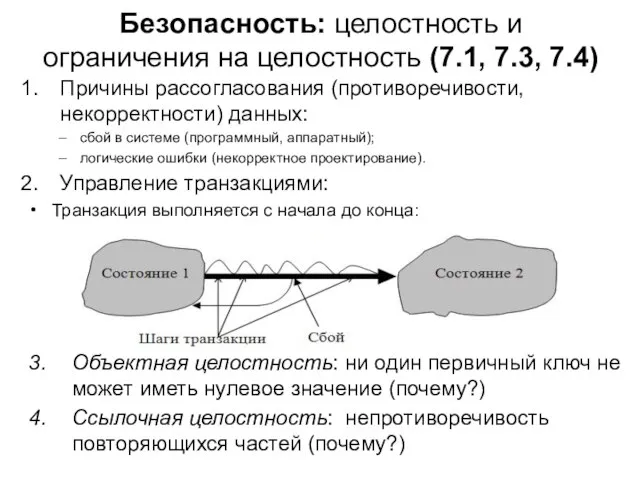
- 137. Безопасность: целостность и ограничения на целостность (7.1, 7.3, 7.4) Причины рассогласования (противоречивости, некорректности) данных: сбой в
- 138. Безопасность: целостность и ограничения на целостность (продолжение)
- 139. Лекция C. Проектирование баз данных
- 140. Общие положения Выбор: таблиц, столбцов таблиц, взаимосвязей между таблицами и столбцами таблиц Логическая структура не должна
- 141. Последовательность шагов Исследовать информационную среду, которую нужно моделировать: откуда поступают данные? как они вводятся, и кто
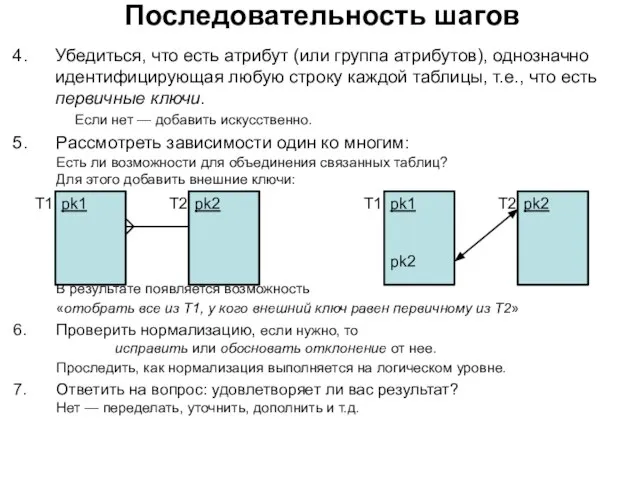
- 142. Последовательность шагов Убедиться, что есть атрибут (или группа атрибутов), однозначно идентифицирующая любую строку каждой таблицы, т.е.,
- 143. Хорошая и плохая структура базы данных Что такое «хорошая структура» базы данных? максимально простое взаимодействие; гарантии
- 144. Проект БД «Книги, авторы, издатели» (1) Вопросы, которые могут задавать пользователи, — самые разные: Кто из
- 145. Проект БД «Книги, авторы, издатели» (2) Объекты: Свойства: Взаимосвязи: авторы имя у книги есть один или
- 146. Проект БД «Книги, авторы, издатели» (3) Отношения один ко многим Задача: связать Titles и Publishers. В
- 147. Проект БД «Книги, авторы, издатели» (4) Анализ решения (целостность): обе таблицы содержат по одной строке на
- 148. Проект БД «Книги, авторы, издатели» (5) Отношения многие к многим Автор может писать много книг, а
- 149. Проект БД «Книги, авторы, издатели» (6) Анализ может указать явно на то, что требуется реализация запросов,
- 150. Проект БД «Книги, авторы, издатели» (7) Отношения один к одному свободны от необходимости угадывать будущие незапланированные
- 151. Проект БД «Книги, авторы, издатели» (8) Первый итог: независимые объекты — строки таблиц; свойства — столбцы;
- 152. Проект БД «Книги, авторы, издатели» (9) Диаграммы «Сущность – связь» (ER-диаграммы) Их нужно уметь Составлять Читать
- 153. Лекция C. Нормализация
- 154. Понятие нормализации и первая нормальная форма Нормализация — набор стандартов проектирования БД, называемых нормальными формами, которые
- 155. Первая нормальная форма: пример Tаблица Sales не удовлетворяет пожеланию заказчика иметь в одном заказе несколько книг.
- 156. Первая нормальная форма: пример (результат) Что здесь обязательно, а что относится к специфике? обязательное Связь главной
- 157. Вторая нормальная форма 2НФ в добавление к 1НФ требует: любой неключевой столбец должен зависеть (= определяться
- 158. Третья нормальная форма 3НФ в добавление к к 1НФ и 2НФ требует: ни один неключевой столбец
- 159. Другие нормальные формы Четвертая нормальная форма формализует требования, выполнение которых гарантирует от появления «дырявых» таблиц, т.е.
- 161. Скачать презентацию
Слайд 2Содержание
Лекция 1. Модель вычислений фон Неймана и традиционные языки
Лекция 2. Нетрадиционные
Содержание
Лекция 1. Модель вычислений фон Неймана и традиционные языки
Лекция 2. Нетрадиционные

Слайд 3Лекция 1. Модель вычислений фон Неймана и традиционные языки
Лекция 1. Модель вычислений фон Неймана и традиционные языки

Слайд 4Каноническая архитектура фон Неймана
Три элемента вычислительной системы:
Память
Процессор
Управляющее устройство
Однородность памяти и адресация
Понятия ячейки,
Каноническая архитектура фон Неймана
Три элемента вычислительной системы:
Память
Процессор
Управляющее устройство
Однородность памяти и адресация
Понятия ячейки,

Слайд 5Схема выполнения двухадресной команды
Схема выполнения двухадресной команды
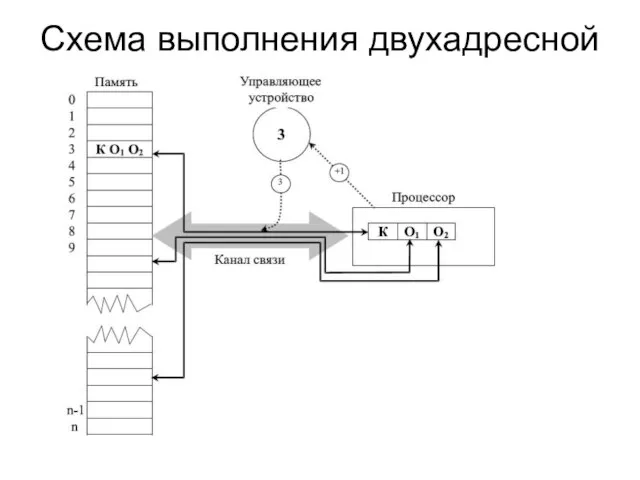
Слайд 6Модификация канонической схемы
Модификация канонической схемы

Слайд 7Альтернатива канонической схемы
Разрешить выполнение всех команд, для которых готовы операнды
Замена хранения результата
Альтернатива канонической схемы
Разрешить выполнение всех команд, для которых готовы операнды
Замена хранения результата

Слайд 8Особенности традиционных языков
Присваивание значений (переменная — аналог ячейки)
Операторы (зависимость выполнения, последовательность)
Структура управления
Особенности традиционных языков
Присваивание значений (переменная — аналог ячейки)
Операторы (зависимость выполнения, последовательность)
Структура управления

Слайд 9Присваивание значений
a = <выражение>
процессор
память
Оператор
Выполнение – команда
Зависимость одного от другого (изменение памяти)
Структура управления
Последовательность
Присваивание значений
a = <выражение>
процессор
память
Оператор
Выполнение – команда
Зависимость одного от другого (изменение памяти)
Структура управления
Последовательность

Слайд 10Приведения
Типов выражения и переменной в присваивании
Округление и отбрасывание
Контролируемые (явно указываемые) и
Приведения
Типов выражения и переменной в присваивании
Округление и отбрасывание
Контролируемые (явно указываемые) и

Слайд 11Подпрограммы
Типовой прием группировки команд
Повторяемые действия
Модульность
Современное понимание (расширено)
Подпрограммы
Типовой прием группировки команд
Повторяемые действия
Модульность
Современное понимание (расширено)

Слайд 12Нарушения канона: побудительные причины
Повышение эффективности
Повышение выразительности
Фиксация типовых приемов программирования
Нарушение однородности памяти
Сегментация памяти
Быстрые
Нарушения канона: побудительные причины
Повышение эффективности
Повышение выразительности
Фиксация типовых приемов программирования
Нарушение однородности памяти
Сегментация памяти
Быстрые

Слайд 13Традиционные языки (некоторые)
Fortran (IV, 76, 90, 95, 2000, 2003, …)
Algol 60
Simula, Simula
Традиционные языки (некоторые)
Fortran (IV, 76, 90, 95, 2000, 2003, …)
Algol 60
Simula, Simula

Слайд 14Лекция 2. Нетрадиционные модели вычислений
Лекция 2. Нетрадиционные модели вычислений

Слайд 15Повелительное и изъявительное наклонения
Изъявительное наклонение и развитость языка
Идеи внедрения изъявительного наклонения
Системы продукций
Системы
Повелительное и изъявительное наклонения
Изъявительное наклонение и развитость языка
Идеи внедрения изъявительного наклонения
Системы продукций
Системы

Слайд 16Системы продукций
Соотношения записываются как правила вывода:
Левая Часть => Правая Часть
Обрабатываемые данные
Системы продукций
Соотношения записываются как правила вывода:
Левая Часть => Правая Часть
Обрабатываемые данные

Слайд 17Системы функций
Программа – соотношение между функциями, связанных между собой аргументами, которые в
Системы функций
Программа – соотношение между функциями, связанных между собой аргументами, которые в

Слайд 18Коммутационные системы
Элемент системы – вершина графа (входные и выходные места)
Дуги – каналы
Коммутационные системы
Элемент системы – вершина графа (входные и выходные места)
Дуги – каналы

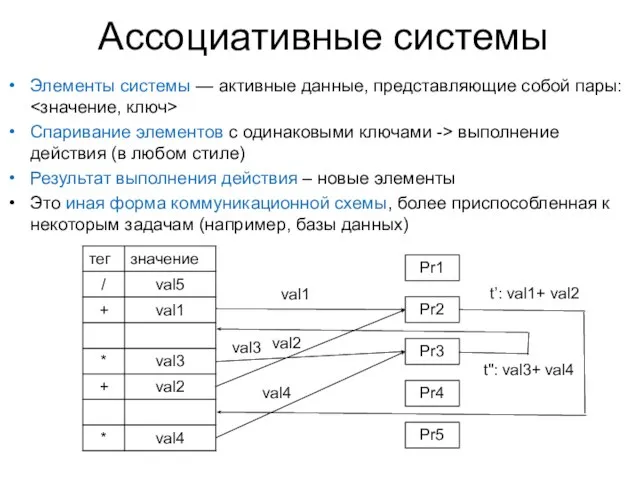
Слайд 19Ассоциативные системы
Элементы системы — активные данные, представляющие собой пары: <значение, ключ>
Спаривание элементов
Ассоциативные системы
Элементы системы — активные данные, представляющие собой пары: <значение, ключ>
Спаривание элементов
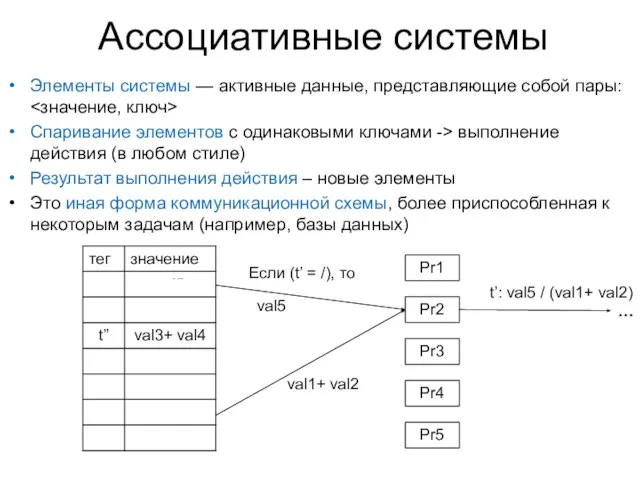
Слайд 20Ассоциативные системы
Элементы системы — активные данные, представляющие собой пары: <значение, ключ>
Спаривание элементов
Ассоциативные системы
Элементы системы — активные данные, представляющие собой пары: <значение, ключ>
Спаривание элементов
Слайд 21Аксиоматические системы
Аксиомы
Описание знаний на фиксированном языке
Классическая логика – соотношение между данными
Вывод теорем
Аксиоматические системы
Аксиомы
Описание знаний на фиксированном языке
Классическая логика – соотношение между данными
Вывод теорем

Слайд 22Programming styles and structuring. Program and data structuring from three points of
Programming styles and structuring. Program and data structuring from three points of
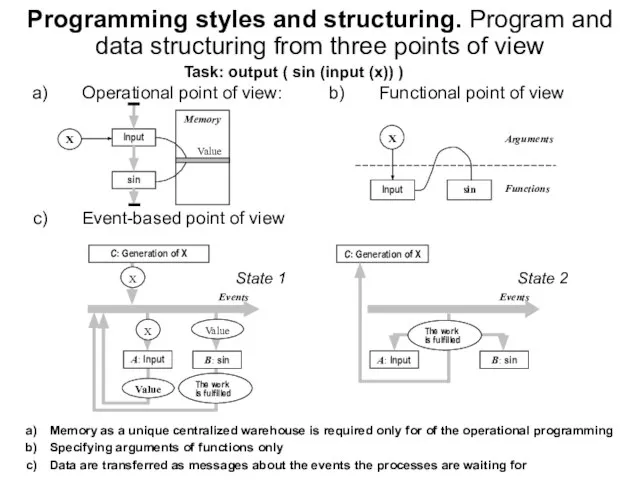
Слайд 23Стили программирования
• Программирование от состояний;
• Структурное программирование;
• Сентенциальное программирование;
• Программирование
Стили программирования
• Программирование от состояний;
• Структурное программирование;
• Сентенциальное программирование;
• Программирование

Слайд 24Лекция 3. Ленивые вычисления и функциональная модель
Лекция 3. Ленивые вычисления и функциональная модель

Слайд 25Ленивые и жадные вычисления
Необходимость и возможность вычисления
Принцип ленивости (рекурсивный ответ на вопрос):
Ленивые и жадные вычисления
Необходимость и возможность вычисления
Принцип ленивости (рекурсивный ответ на вопрос):

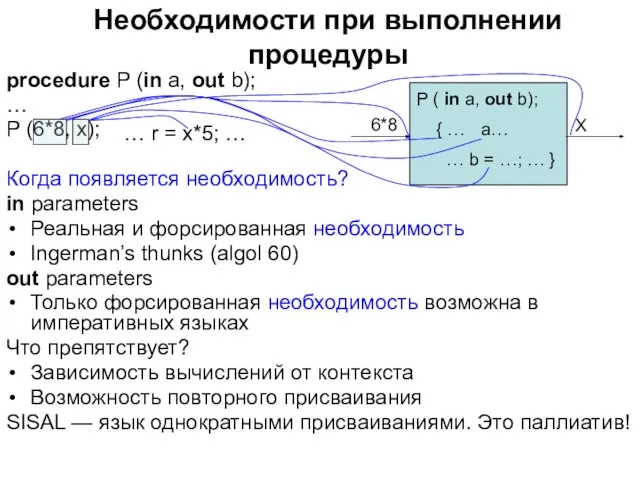
Слайд 26Необходимости при выполнении процедуры
procedure P (in a, out b);
…
P (6*8, x);
Когда появляется
Необходимости при выполнении процедуры
procedure P (in a, out b);
…
P (6*8, x);
Когда появляется
Слайд 27Метод обобщения специфичного в функциональном программировании
list of x = nil | cons
Метод обобщения специфичного в функциональном программировании
list of x = nil | cons

Слайд 28Метод обобщения специфичного (продолжение)
reduce f x nil = x
reduce f x (cons
Метод обобщения специфичного (продолжение)
reduce f x nil = x
reduce f x (cons

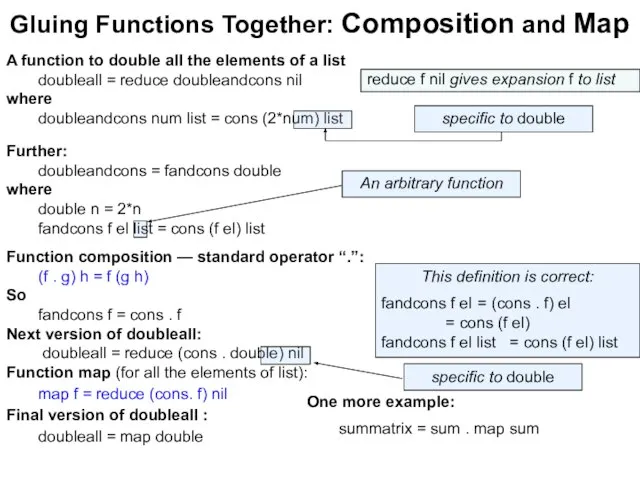
Слайд 29Gluing Functions Together: Composition and Map
A function to double all the elements
Gluing Functions Together: Composition and Map
A function to double all the elements
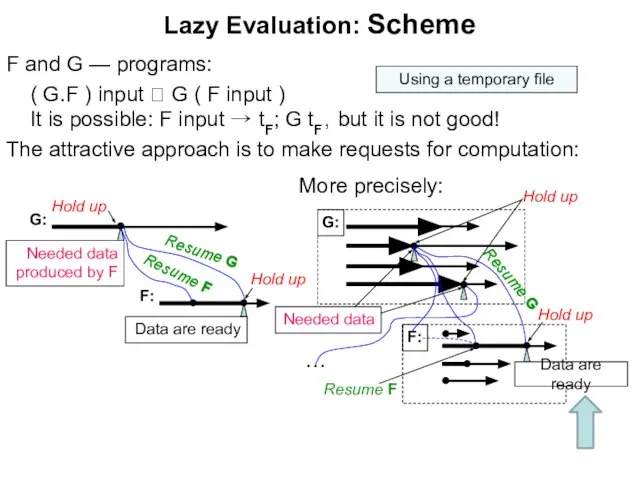
Слайд 30Lazy Evaluation: Scheme
F and G — programs:
( G.F ) input G
Lazy Evaluation: Scheme
F and G — programs:
( G.F ) input G
Слайд 31Лекция 4. Постулаты необходимости, их следствия. Особенности ленивых и жадных вычислений при
Лекция 4. Постулаты необходимости, их следствия. Особенности ленивых и жадных вычислений при

Слайд 32Постулаты необходимости
Любое вычисление активизируется тогда и только тогда, когда оно (его результат)
Постулаты необходимости
Любое вычисление активизируется тогда и только тогда, когда оно (его результат)

Слайд 33Следствия постулатов необходимости
То, что ленивые вычисления задают управление программы через потоки данных,
Следствия постулатов необходимости
То, что ленивые вычисления задают управление программы через потоки данных,

Слайд 34Конкретизации необходимости
Для императивного языка
Необходимость, определяется правилами, задающими поток управления в программе (декларируется
Конкретизации необходимости
Для императивного языка
Необходимость, определяется правилами, задающими поток управления в программе (декларируется

Слайд 35Пример-иллюстрация
F строит «очень большое» дерево (например, всех возможных последовательностей ходов)
G запрашивает поддерево
Пример-иллюстрация
F строит «очень большое» дерево (например, всех возможных последовательностей ходов)
G запрашивает поддерево

Слайд 36Лекция 5. Решение численных задач в функциональном стиле
Лекция 5. Решение численных задач в функциональном стиле

Слайд 37Метод Ньютона-Рафсона: вычисление квадратного корня
Функциональная программа не эффективна. Правда ли это?
Алгоритм:
Начинать
Метод Ньютона-Рафсона: вычисление квадратного корня
Функциональная программа не эффективна. Правда ли это?
Алгоритм:
Начинать

Слайд 38Метод Ньютона-Рафсона: функциональная программа
Первый вариант:
next N x = (x + N/x) /
Метод Ньютона-Рафсона: функциональная программа
Первый вариант:
next N x = (x + N/x) /

Слайд 39Численное дифференцирование
easydiff f x h = (f (x + h) -
Численное дифференцирование
easydiff f x h = (f (x + h) -

Слайд 40Лекция 6. Ленивые вычисления: императивные примеры
Лекция 6. Ленивые вычисления: императивные примеры

Слайд 41Boolean выражения
ℜ ≡ α&β&γ : (α == false) ⇒ ℜ == false
Boolean выражения
ℜ ≡ α&β&γ : (α == false) ⇒ ℜ == false

Слайд 42Анализ ленивого и жадного cat File_F | grep WWW | head -1
Жадный
Анализ ленивого и жадного cat File_F | grep WWW | head -1
Жадный
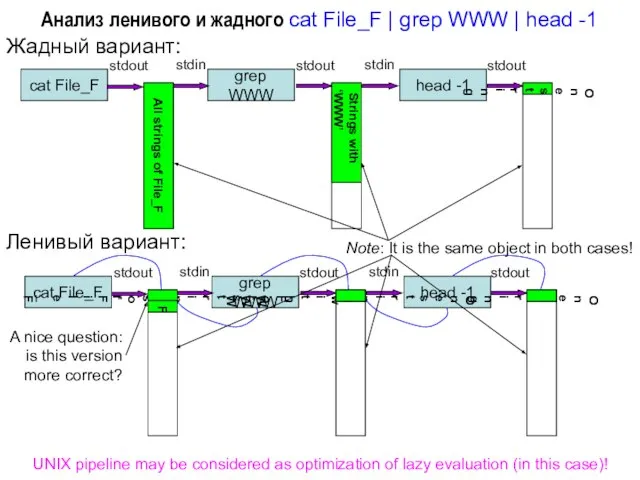
Слайд 43Мемоизация
Программа F (n) = F (n-1) + F (n-2)
традиционный пример, когда
Мемоизация
Программа F (n) = F (n-1) + F (n-2) традиционный пример, когда

Слайд 44Анализ векторно-матричного примера
Consider the example more closely:
a = b + c +
Анализ векторно-матричного примера
Consider the example more closely:
a = b + c +
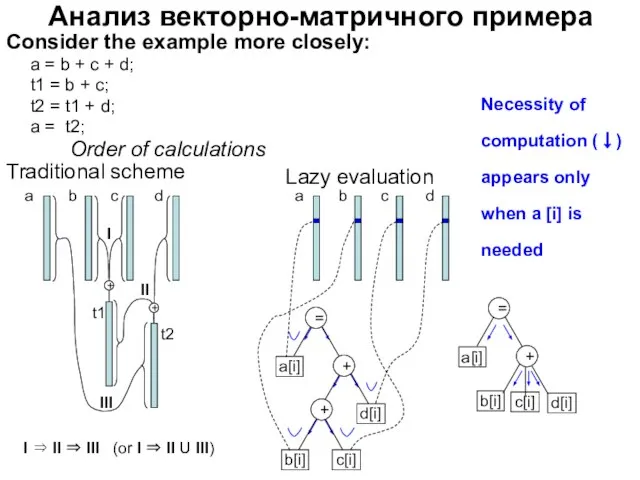
Слайд 45Лекция 7. Элементы сентенциального стиля программирования
Лекция 7. Элементы сентенциального стиля программирования

Слайд 46Что такое сентенциальное программирование?
Sentence – предложение → грамматика, определяющая все правильные предложения
Обрабатываемые
Что такое сентенциальное программирование?
Sentence – предложение → грамматика, определяющая все правильные предложения
Обрабатываемые

Слайд 47E → T 1| E + T 2| E – T 3
T
E → T 1| E + T 2| E – T 3
T
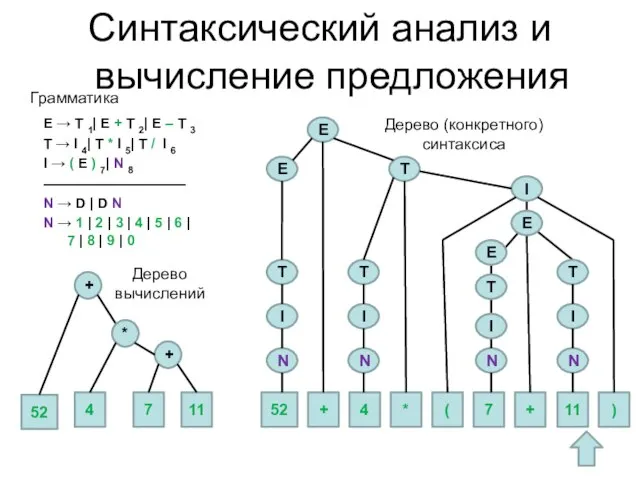
Слайд 48Логический вывод утверждений на основе фактов и язык Prolog
Семья (МАША и САША)
Логический вывод утверждений на основе фактов и язык Prolog
Семья (МАША и САША)

Слайд 49Фразовые формы, резолюция, унификация
P1 ˅ P1 ˅ … ˅ Pn ˅ N1
Фразовые формы, резолюция, унификация
P1 ˅ P1 ˅ … ˅ Pn ˅ N1

Слайд 50Нисходящая (обратная) стратегия
T = { P(a) ˅ ~Q(b,c)
Q(x,y) ˅ ~R(x,y)
S(b)
R(a,b) }
Является ли
Нисходящая (обратная) стратегия
T = { P(a) ˅ ~Q(b,c)
Q(x,y) ˅ ~R(x,y)
S(b)
R(a,b) }
Является ли

Слайд 51Семантика Prolog’а
начальник(Фамилия, Оклад) :— служащий(Фамилия, Оклад), Оклад > 70000
Декларативная модель:
Некое лицо (Фамилия)
Семантика Prolog’а
начальник(Фамилия, Оклад) :— служащий(Фамилия, Оклад), Оклад > 70000
Декларативная модель:
Некое лицо (Фамилия)

Слайд 52Пример: обращение списка
% Метод 1 / с правом для присоединить
обр_порядок ([C|L1],
Пример: обращение списка
% Метод 1 / с правом для присоединить
обр_порядок ([C|L1],

Слайд 53Prolog’овские базы знаний
Что такое база знаний vs. база данных?
Представление знаний
Вычислительные формализмы:
Дескриптивный язык
Prolog’овские базы знаний
Что такое база знаний vs. база данных?
Представление знаний
Вычислительные формализмы:
Дескриптивный язык

Слайд 54Задания
Написать на Prolog’е программу дифференцирования
Где оканчивается адекватная применимость Prolog’а?
Чем означивание (в двух
Задания
Написать на Prolog’е программу дифференцирования
Где оканчивается адекватная применимость Prolog’а?
Чем означивание (в двух

Слайд 55Сопоставление строки α ∈T* с образцом π = ,
Сопоставление строки α ∈T* с образцом π =
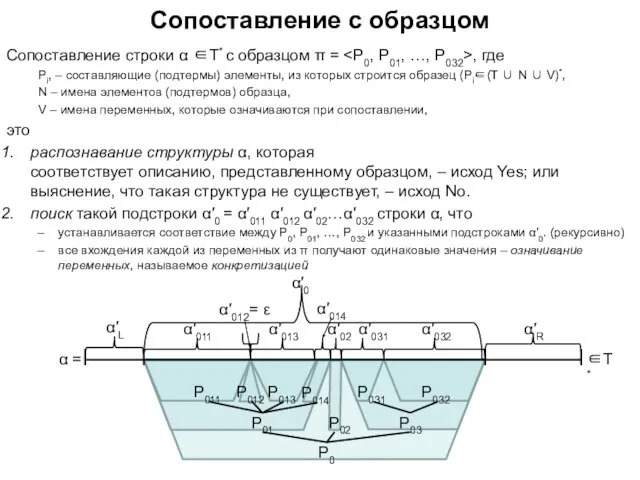
Слайд 56Сопоставление с образцом: примеры
Пусть α ∈{‘a’, ‘b’, …, ‘z’}* = T*
= <‘a’> →
Сопоставление с образцом: примеры
Пусть α ∈{‘a’, ‘b’, …, ‘z’}* = T*
= <‘a’> →

Слайд 57Рефал: основная идея
Приспособить к практическим нуждам теоретический Алгорифм Маркова:
{ αi → βi
Рефал: основная идея
Приспособить к практическим нуждам теоретический Алгорифм Маркова:
{ αi → βi

Слайд 58Основные символы, структурированные строки
αi строится как структурированная строка, из следующего:
символы T, не
Основные символы, структурированные строки
αi строится как структурированная строка, из следующего:
символы T, не

Слайд 59Рефал: продукции (операторы языка)
Продукции Рефала принимают следующий вид:
kαi.→βi (левая часть → правая
Рефал: продукции (операторы языка)
Продукции Рефала принимают следующий вид:
kαi.→βi (левая часть → правая

Слайд 60Проецирование строки αi = X1... Xu...Xr продукции k αi. → βi на
Проецирование строки αi = X1... Xu...Xr продукции k αi. → βi на

Слайд 61Применение продукции kαi. → βi
построение проекции αi на α′i (одной из возможных),
построение
Применение продукции kαi. → βi
построение проекции αi на α′i (одной из возможных),
построение

Слайд 62Разрешение неоднозначностей
При неоднозначном выборе проекции αi на α′i предпочтение отдается той проекции,
Разрешение неоднозначностей
При неоднозначном выборе проекции αi на α′i предпочтение отдается той проекции,

Слайд 63Дополнение основного механизма
Цель: сужение вариантов проецирования, снижение возможной недетерминированности, как следствие,
Дополнение основного механизма
Цель: сужение вариантов проецирования, снижение возможной недетерминированности, как следствие,

Слайд 64Содержательный пример: дифференцирование (функция k/dif/)
1. ke1. → k/dif/e1.
2. k/dif/v1+v2. → (k/dif/v1.+k/dif/v2.)
3. k/dif/v1*v2.
Содержательный пример: дифференцирование (функция k/dif/)
1. ke1. → k/dif/e1.
2. k/dif/v1+v2. → (k/dif/v1.+k/dif/v2.)
3. k/dif/v1*v2.

Слайд 65Продолжение примерa
Дифференцирование a*x+bx*(c+x)+d
ka*x+bx*(c+x)+d. ⇒/1/
k/dif/a*x+bx*(c+x)+d. ⇒/2/
(k/dif/a*x.+k/dif/bx*(c+x)+d.) ⇒/2/
(k/dif/a*x.+(k/dif/bx*(c+x).+k/dif/d.)) ⇒/3/
((k/dif/a.*(x)+k/dif/x.*(a))+(k/dif/bx*(c+x).+ k/dif/d.))
Продолжение примерa
Дифференцирование a*x+bx*(c+x)+d
ka*x+bx*(c+x)+d. ⇒/1/
k/dif/a*x+bx*(c+x)+d. ⇒/2/
(k/dif/a*x.+k/dif/bx*(c+x)+d.) ⇒/2/
(k/dif/a*x.+(k/dif/bx*(c+x).+k/dif/d.)) ⇒/3/
((k/dif/a.*(x)+k/dif/x.*(a))+(k/dif/bx*(c+x).+ k/dif/d.))

Слайд 66Внешние вычисления в Рефале
Арифметические вычисления нерациональны:
k/sum/v1+v2. → k/sum/ k/plus1/v1. + k/minus1/v2..
k/sum/v1+1. →
Внешние вычисления в Рефале
Арифметические вычисления нерациональны:
k/sum/v1+v2. → k/sum/ k/plus1/v1. + k/minus1/v2..
k/sum/v1+1. →

Слайд 67Схема вычисления Peфал программы
Схема вычисления Peфал программы
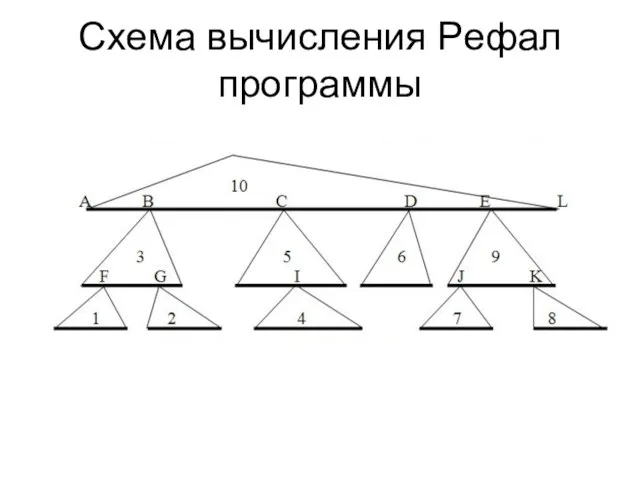
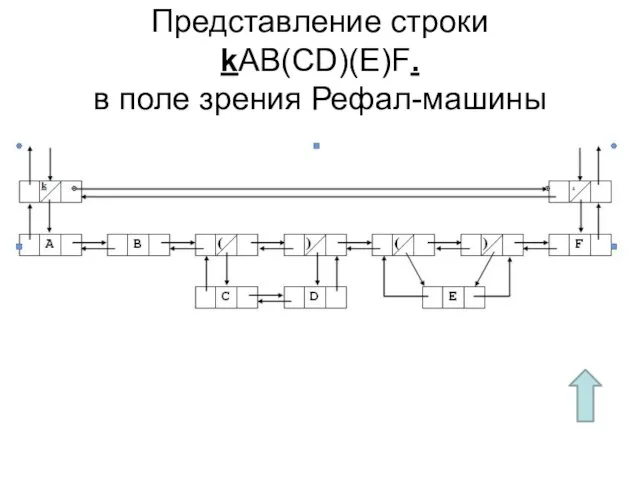
Слайд 68Представление строки
kAB(CD)(E)F.
в поле зрения Рефал-машины
Представление строки
kAB(CD)(E)F.
в поле зрения Рефал-машины
Слайд 69Лекция 9. Концепция «Model View Controller»
(что не удалось сделать в Delphi)
Лекция 9. Концепция «Model View Controller»
(что не удалось сделать в Delphi)

Слайд 70Система и ее декомпозиция
Система – набор связанных между собой и взаимодействующих компонент.
Система и ее декомпозиция
Система – набор связанных между собой и взаимодействующих компонент.

Слайд 71Декомпозиция и моделирование
Моделирование предполагает абстрагирование от несущественных с точки зрения рассмотрения деталей
Декомпозиция и моделирование
Моделирование предполагает абстрагирование от несущественных с точки зрения рассмотрения деталей

Слайд 72Виды декомпозиции
Стихийная (Почему это плохо? Когда приемлемо?)
Концептуальная – уровень соглашений о системе
Проектная
Виды декомпозиции
Стихийная (Почему это плохо? Когда приемлемо?)
Концептуальная – уровень соглашений о системе
Проектная

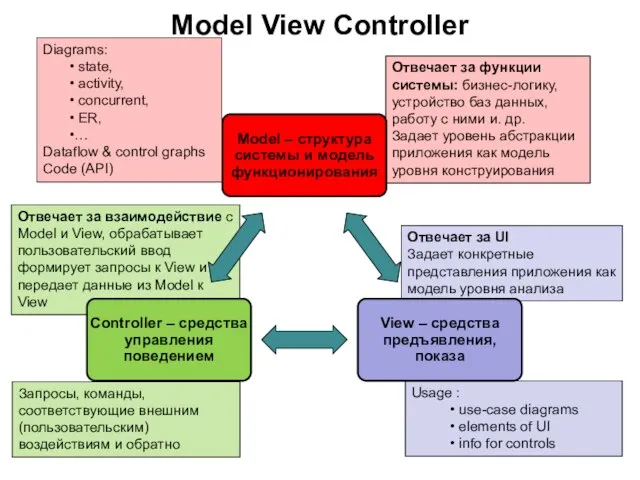
Слайд 73MVC – это:
Концептуальная декомпозиция приложения, которая следует постулату разделения трех сущностей:
Понятия, объекты,
MVC – это:
Концептуальная декомпозиция приложения, которая следует постулату разделения трех сущностей:
Понятия, объекты,

Слайд 74Отвечает за взаимодействие с Model и View, обрабатывает пользовательский ввод
формирует запросы к
Отвечает за взаимодействие с Model и View, обрабатывает пользовательский ввод формирует запросы к
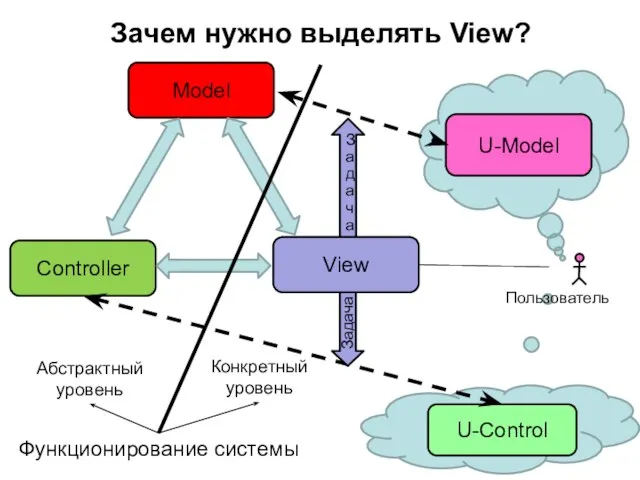
Слайд 75Зачем нужно выделять View?
Model
Controller
Пользователь
U-Model
Задача
U-Control
Задача
View
Абстрактный уровень
Конкретный уровень
Функционирование системы
Зачем нужно выделять View?
Model
Controller
Пользователь
U-Model
Задача
U-Control
Задача
View
Абстрактный уровень
Конкретный уровень
Функционирование системы
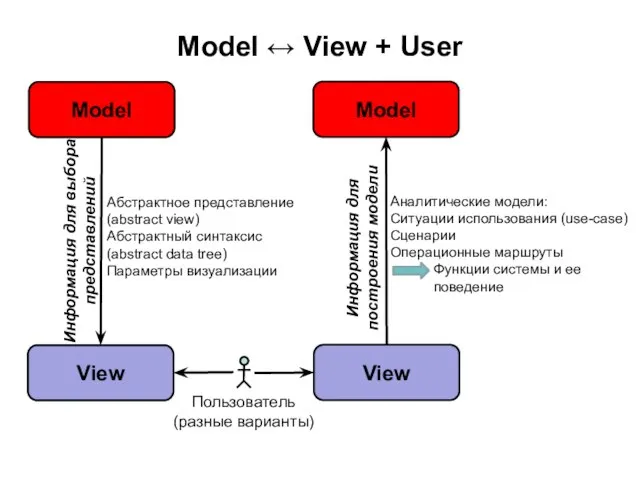
Слайд 76Информация для выбора представлений
Model ↔ View + User
Абстрактное представление (abstract view)
Абстрактный синтаксис
Информация для выбора представлений
Model ↔ View + User
Абстрактное представление (abstract view) Абстрактный синтаксис
Слайд 77Model ↔ Controller
Информация для управления:
Состояние системы,
Данные, перерабатываемые приложением,
Условия корректности изменений
Model
Команды управления поведением:
Вводимые
Model ↔ Controller
Информация для управления:
Состояние системы,
Данные, перерабатываемые приложением,
Условия корректности изменений
Model
Команды управления поведением:
Вводимые
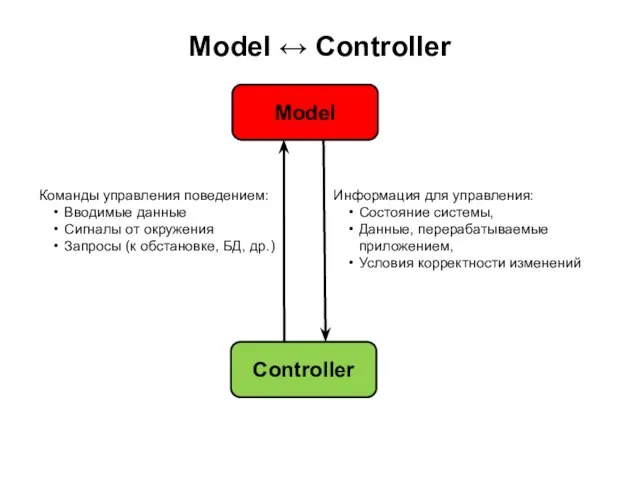
Слайд 78Controller ↔ View
Controller
View
Формы для представления информации на абстрактном уровне:
Воздействия пользователей и окружения,
Ввод
Controller ↔ View
Controller
View
Формы для представления информации на абстрактном уровне:
Воздействия пользователей и окружения,
Ввод
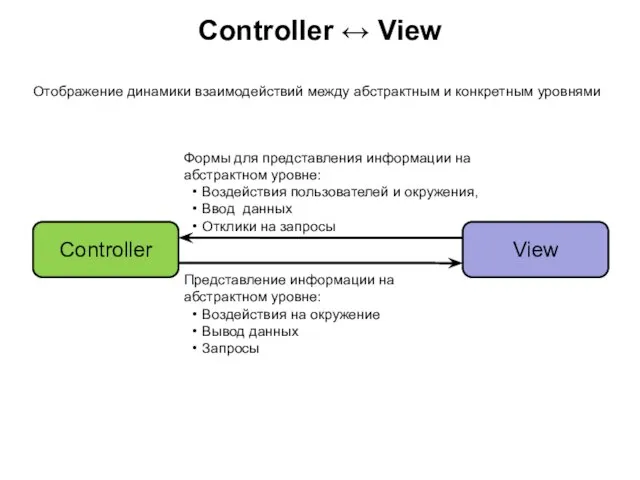
Слайд 79Прагматическая точка зрения:
При реализации систем для разных пользователей (разные view, а функционирование
Прагматическая точка зрения:
При реализации систем для разных пользователей (разные view, а функционирование

Слайд 80Немного истории
Delphi продукт года → другие системы
(C/C++ Builder, MS Visual Studio
Немного истории
Delphi продукт года → другие системы
(C/C++ Builder, MS Visual Studio

Слайд 81Лекция 10. Жизненный цикл программного обеспечения и его модели
Лекция 10. Жизненный цикл программного обеспечения и его модели

Слайд 82Мотивация изучения жизненного цикла и его моделей
Жизненный цикл — база методологий
Жизненные циклы
Мотивация изучения жизненного цикла и его моделей
Жизненный цикл — база методологий
Жизненные циклы
Слайд 83Жизненный цикл программного обеспечения: определение
Цикл разработки,
Издержки после завершения разработки
Жизненный цикл —
Жизненный цикл программного обеспечения: определение
Цикл разработки,
Издержки после завершения разработки
Жизненный цикл —

Слайд 84Задача методологии и жизненный цикл
Методологии — это инструменты, с помощью которых создание
Задача методологии и жизненный цикл
Методологии — это инструменты, с помощью которых создание

Слайд 85Модели процесса и продукта
Модель процесса разработки:
Целенаправленное развитие объекта под
воздействием разработчиков
Модели процесса и продукта
Модель процесса разработки:
Целенаправленное развитие объекта под
воздействием разработчиков
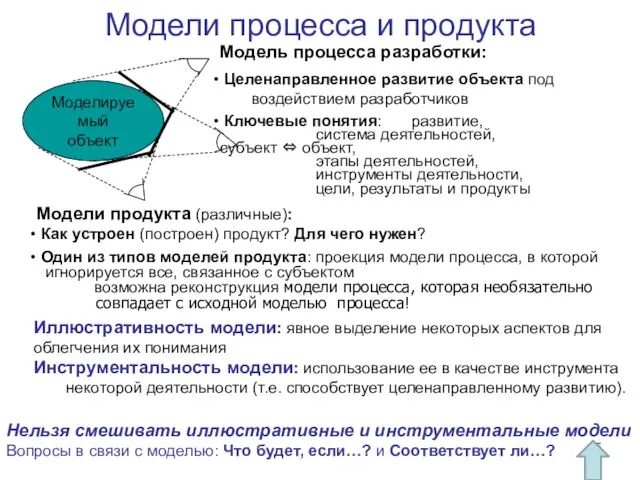
Слайд 86Лекция 11. Классические модели
Лекция 11. Классические модели

Слайд 87Общепринятая модель жизненного цикла
программного обеспечения
Общепринятая модель жизненного цикла
программного обеспечения
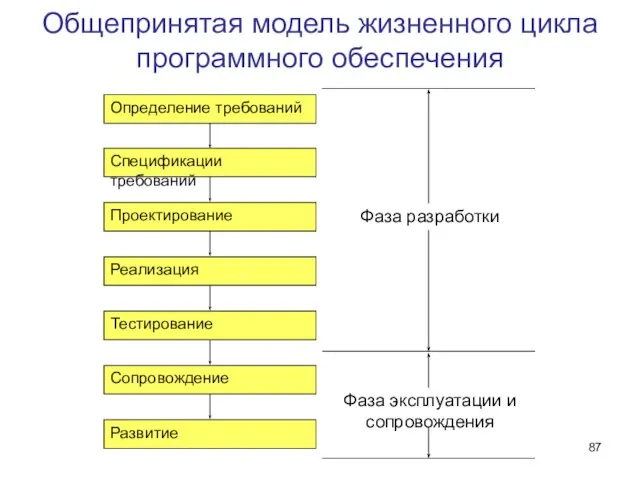
Слайд 88Общепринятая модель — источник базовых понятий
Начало разработки — идентификация потребности
Определение требований
Общепринятая модель — источник базовых понятий
Начало разработки — идентификация потребности
Определение требований

Слайд 89Классическая итерационная модель
Отражает потребность исправления ошибок пройденных этапов!
Классическая итерационная модель
Отражает потребность исправления ошибок пройденных этапов!
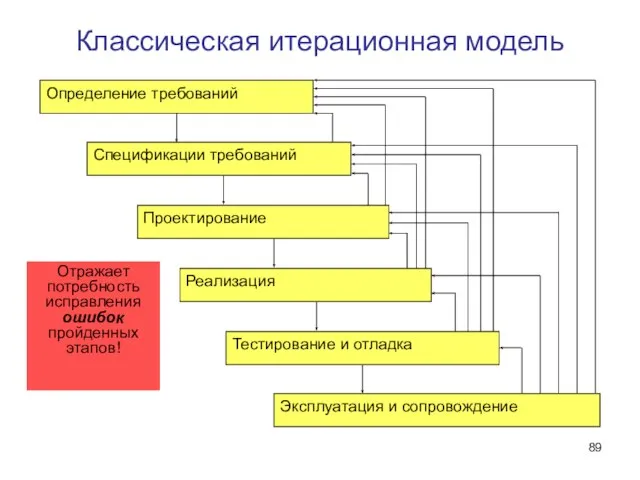
Слайд 90Исправление ошибок или адаптивность проекта?
Классическая итерационная модель — абсолютизация возможности возвратов для
Исправление ошибок или адаптивность проекта?
Классическая итерационная модель — абсолютизация возможности возвратов для

Слайд 91Каскадная модель
Чем заканчи- ваются этапы
Каскадная модель
Чем заканчи- ваются этапы
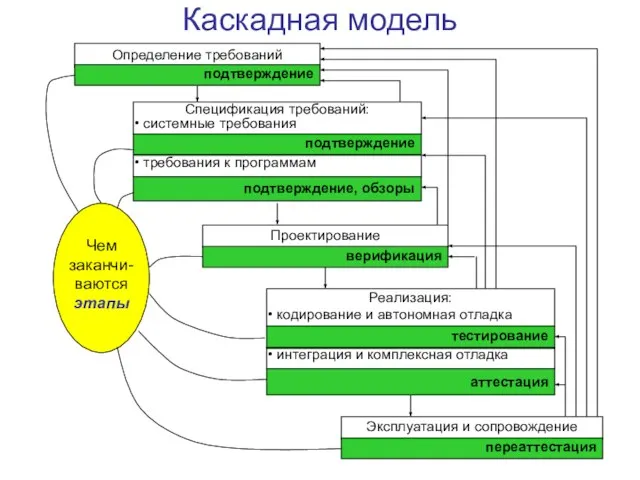
Слайд 92Каскадная модель: новые понятия
Характерные черты каскадной модели:
завершение этапов проверкой полученных результатов
циклическое
Каскадная модель: новые понятия
Характерные черты каскадной модели:
завершение этапов проверкой полученных результатов
циклическое

Слайд 93Строгая каскадная модель
Чем заканчи- ваются этапы
Удалены
«лишние»
возвраты
За счет чего это достигается?
Строгая каскадная модель
Чем заканчи- ваются этапы
Удалены
«лишние»
возвраты
За счет чего это достигается?
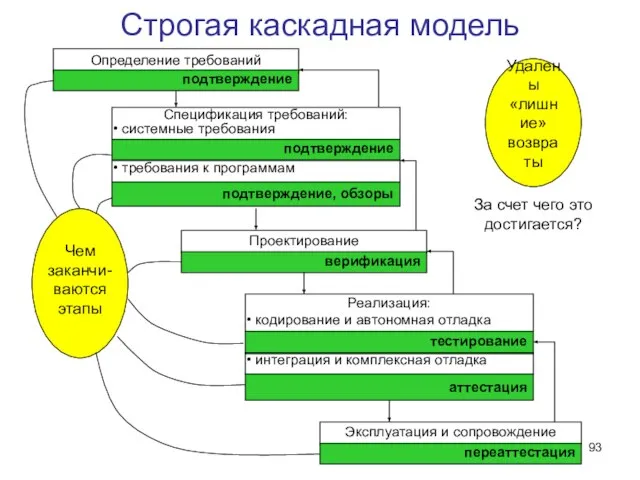
Слайд 94Строгая каскадная модель: дополнительные требования к разработке проекта
Минимизация возвратов за счет ликвидации
Строгая каскадная модель: дополнительные требования к разработке проекта
Минимизация возвратов за счет ликвидации

Слайд 95Каскадная модель MSF
Вехи (контрольные точки) используются в качестве точек оценки и перехода
Каскадная модель MSF
Вехи (контрольные точки) используются в качестве точек оценки и перехода
Слайд 96Вопросы и задания
Какие из рассмотренных моделей можно сделать инструментальными, а какие не
Вопросы и задания
Какие из рассмотренных моделей можно сделать инструментальными, а какие не

Слайд 97Лекция 12. Развитые модели жизненного цикла:
Производственные функции в моделировании жизненного цикла: модель
Лекция 12. Развитые модели жизненного цикла:
Производственные функции в моделировании жизненного цикла: модель

Слайд 98Модель фазы—функции Гантера:
Анализ осущест-
Конструиро-
вание →
Программирование →
Оценка →
Фазы
Модель фазы—функции Гантера:
Анализ осущест-
Конструиро-
вание →
Программирование →
Оценка →
Фазы
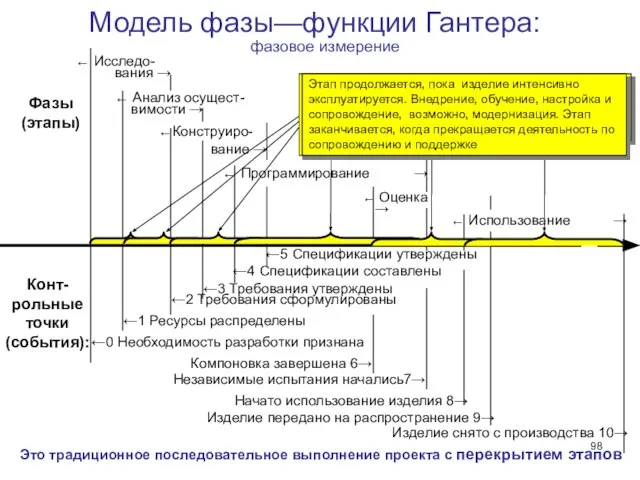
Слайд 99Основной тезис: На разных этапах функции
имеют различное содержание, требуют различной интенсивности,
Основной тезис: На разных этапах функции имеют различное содержание, требуют различной интенсивности,

Слайд 10010
Модель фазы—функции Гантера:
функциональное измерение
Программирование →
Оценка →
Фазы:
0
Планирование
Разработка
Обслуживание
10
Модель фазы—функции Гантера:
функциональное измерение
Программирование →
Оценка →
Фазы:
0
Планирование
Разработка
Обслуживание
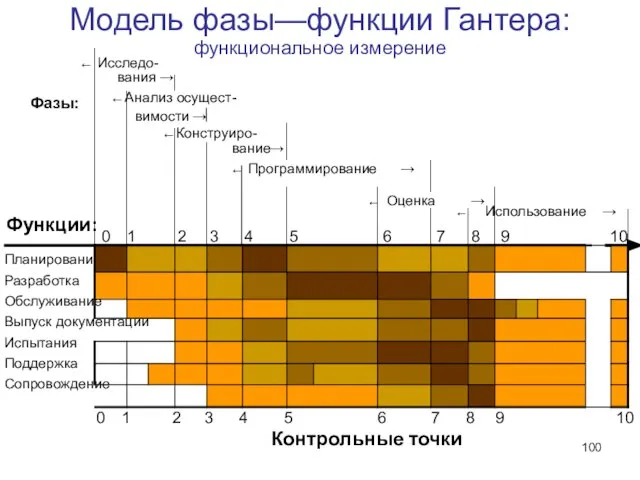
Слайд 101Вариативность модели Гантера
В зависимости от проекта функции можно трактовать свободно, дополнять другими
Вариативность модели Гантера
В зависимости от проекта функции можно трактовать свободно, дополнять другими

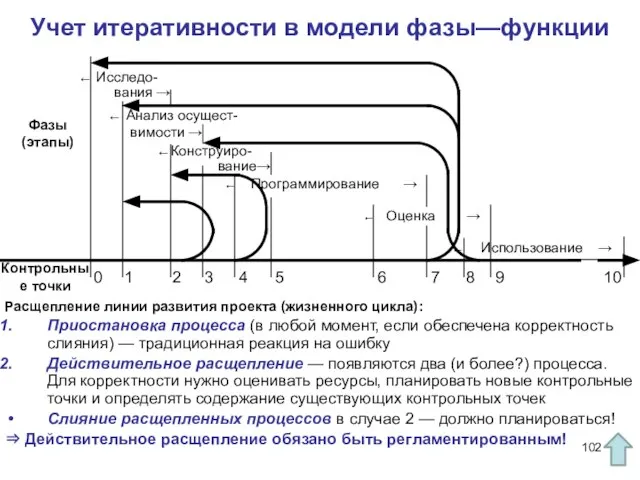
Слайд 102Учет итеративности в модели фазы—функции
Программирование →
Оценка →
Учет итеративности в модели фазы—функции
Программирование →
Оценка →
Слайд 103Моделирование жизненного цикла объектно-ориентированных программных проектов
Моделирование жизненного цикла объектно-ориентированных программных проектов

Слайд 104Принципы объектно-ориентированного проектирования
Итеративность развития — возможность перейти от последовательного развития к
Принципы объектно-ориентированного проектирования
Итеративность развития — возможность перейти от последовательного развития к

Слайд 105Моделирование при объектно-ориентированном проектировании
Распределение реализуемых требований по итерациям: Совокупность сценариев, реализуемых на
Моделирование при объектно-ориентированном проектировании
Распределение реализуемых требований по итерациям: Совокупность сценариев, реализуемых на

Слайд 106←5 Спецификации утверждены
←6 Автономная проверка завершена,
комплексное тестирование
началось
← Программирование →
← Оценка
←5 Спецификации утверждены
←6 Автономная проверка завершена,
комплексное тестирование
началось
← Программирование →
← Оценка
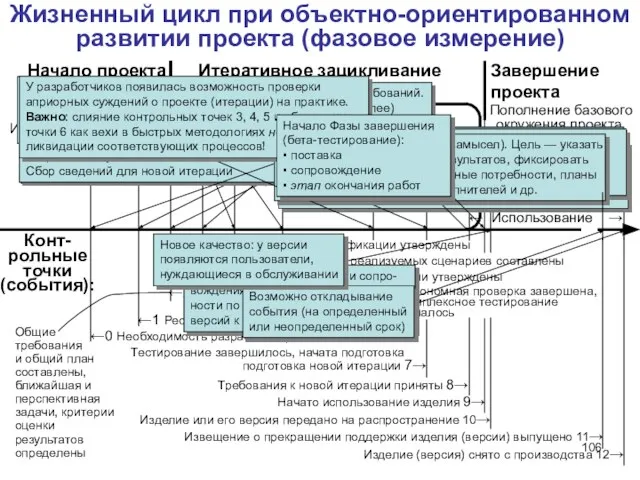
Слайд 107Контрольные точки и вехи
Контрольные точки (check points) — точки линии жизни жизненного
Контрольные точки и вехи
Контрольные точки (check points) — точки линии жизни жизненного

Слайд 108Для каждой итерации должны быть определены:
Общие требования — что требуется от проекта
Для каждой итерации должны быть определены:
Общие требования — что требуется от проекта

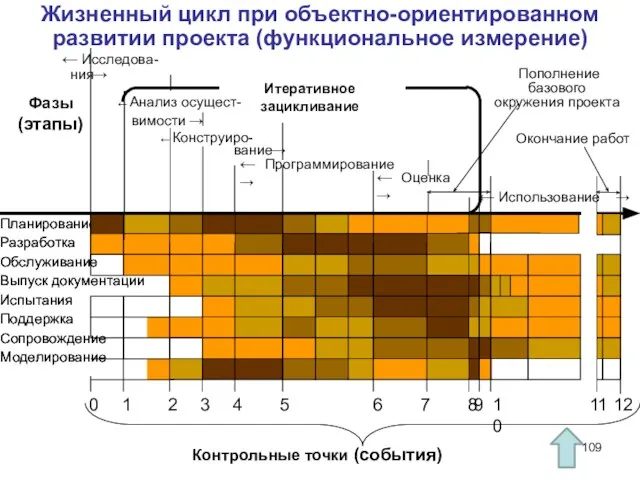
Слайд 109Жизненный цикл при объектно-ориентированном развитии проекта (функциональное измерение)
Планирование
Разработка
Обслуживание
Выпуск документации
Испытания
Жизненный цикл при объектно-ориентированном развитии проекта (функциональное измерение)
Планирование
Разработка
Обслуживание
Выпуск документации
Испытания
Слайд 110Дополнительные лекции
Лекция A. Введение в базы данных: мотивация СУБД
Дополнительные лекции
Лекция A. Введение в базы данных: мотивация СУБД

Слайд 111Структурированные файлы и базы данных
Файл как последовательность записей → справедливая мысль о
Структурированные файлы и базы данных
Файл как последовательность записей → справедливая мысль о

Слайд 112Структурированные файлы и базы данных
Файл как последовательность записей → справедливая мысль о
Структурированные файлы и базы данных
Файл как последовательность записей → справедливая мысль о

Слайд 113Комплекс программ для поддержки работы приемной комиссии вуза
Роли: абитуриент, секретарь, экзаменатор, посетитель
Комплекс программ для поддержки работы приемной комиссии вуза
Роли: абитуриент, секретарь, экзаменатор, посетитель

Слайд 114Проектирование БД и задача унификации
Какое отношение проектирование имеет к файлам?
Система файлов
Проектирование БД и задача унификации
Какое отношение проектирование имеет к файлам?
Система файлов

Слайд 115Автоматизация работы приемной комиссии: структура информации об абитуриенте
type TAbit = record
...
Автоматизация работы приемной комиссии: структура информации об абитуриенте
type TAbit = record
...

Слайд 116Требования к типу Tabit
Фамилия непригодна для однозначного соответствия:
существуют однофамильцы;
поиск записи, содержащей строковое
Требования к типу Tabit
Фамилия непригодна для однозначного соответствия:
существуют однофамильцы;
поиск записи, содержащей строковое

Слайд 117Выбор структуры для типа TAbit
const lName = 10;
type TAbit =
record
RegNum
Выбор структуры для типа TAbit
const lName = 10;
type TAbit =
record
RegNum

Слайд 118Выбор структуры для типа TAbit
const lName = 10;
type TAbit =
record
RegNum
Выбор структуры для типа TAbit
const lName = 10;
type TAbit =
record
RegNum

Слайд 119Анализ выбранной структуры для типа Tabit
Разумна ли выбранная структура? Нет!
Для поиска абитуриентов
Анализ выбранной структуры для типа Tabit
Разумна ли выбранная структура? Нет!
Для поиска абитуриентов

Слайд 120Обсуждение модернизации типа TAbit
Целесообразность разбиения информационного массива БД на несколько файлов:
для
Обсуждение модернизации типа TAbit
Целесообразность разбиения информационного массива БД на несколько файлов:
для

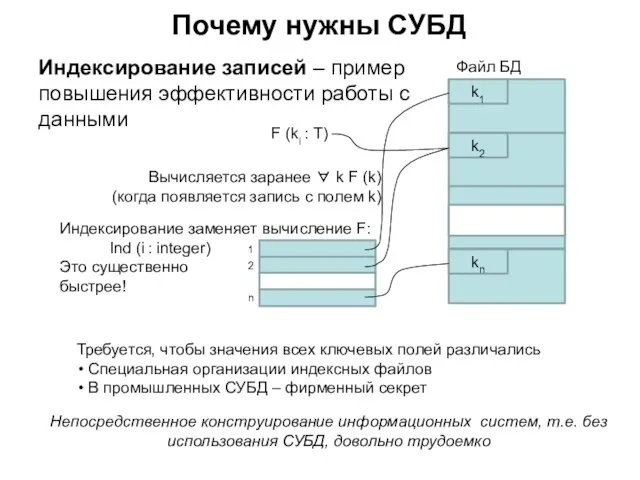
Слайд 121Почему нужны СУБД
F (ki : T)
1
2
n
Вычисляется заранее ∀ k F (k)
(когда появляется
Почему нужны СУБД
F (ki : T)
1
2
n
Вычисляется заранее ∀ k F (k) (когда появляется
Слайд 122Отношения между данными
Отношение «многие ко многим»:
Могут существовать абитуриенты с одинаковыми фамилиями,
Отношения между данными
Отношение «многие ко многим»: Могут существовать абитуриенты с одинаковыми фамилиями,
Слайд 123Лекция B. Модели баз данных
Лекция B. Модели баз данных

Слайд 124Модели баз данных.Что это?
Данные: хранятся, появляются, уничтожаются, предоставляются – пассивные
Сведения: формируются, сообщаются,
Модели баз данных.Что это?
Данные: хранятся, появляются, уничтожаются, предоставляются – пассивные
Сведения: формируются, сообщаются,

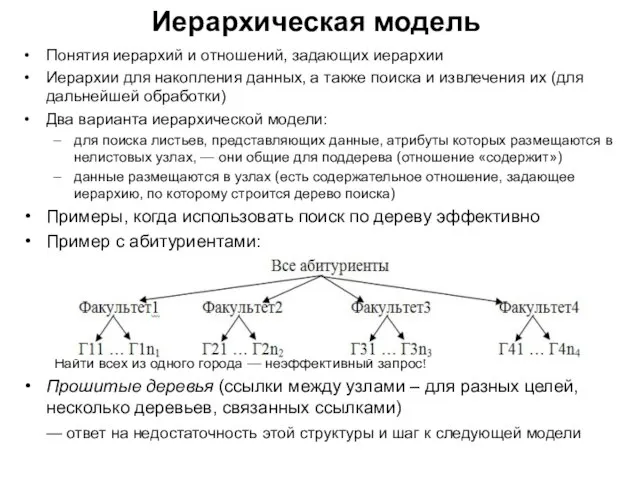
Слайд 125Иерархическая модель
Понятия иерархий и отношений, задающих иерархии
Иерархии для накопления данных, а также
Иерархическая модель
Понятия иерархий и отношений, задающих иерархии
Иерархии для накопления данных, а также
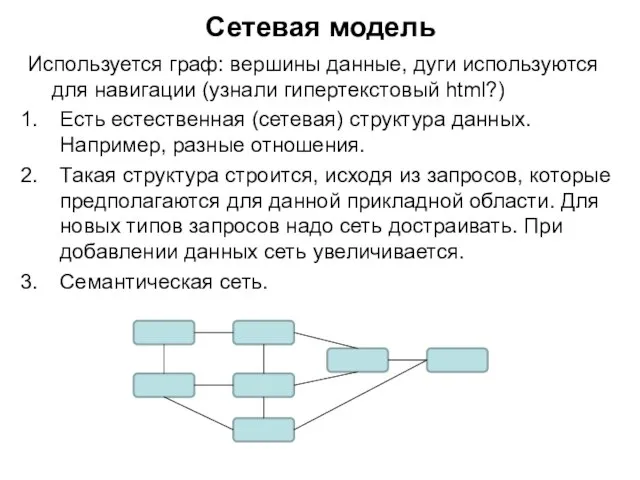
Слайд 126Сетевая модель
Используется граф: вершины данные, дуги используются для навигации (узнали гипертекстовый html?)
Есть
Сетевая модель
Используется граф: вершины данные, дуги используются для навигации (узнали гипертекстовый html?)
Есть
Слайд 127Реляционная модель: неформальное определение
Дейт:
вся информация в базе данных представлена в таблицах;
поддерживается
Реляционная модель: неформальное определение
Дейт:
вся информация в базе данных представлена в таблицах;
поддерживается

Слайд 128Таблицы и базы данных (1)
таблица строка столбец
table row column
отношение кортеж атрибут
relation tuple attribute
файл запись поле
file record field
База данных
Таблицы и базы данных (1)
таблица строка столбец
table row column
отношение кортеж атрибут
relation tuple attribute
файл запись поле
file record field
База данных

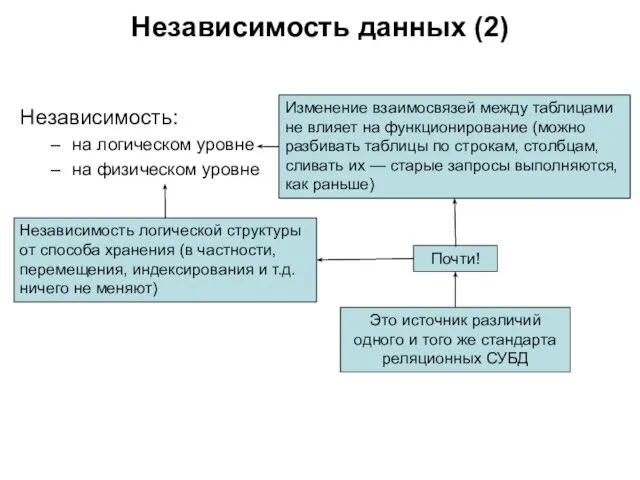
Слайд 129Независимость:
на логическом уровне
на физическом уровне
Независимость данных (2)
Изменение взаимосвязей между таблицами
Независимость:
на логическом уровне
на физическом уровне
Независимость данных (2)
Изменение взаимосвязей между таблицами
Слайд 130
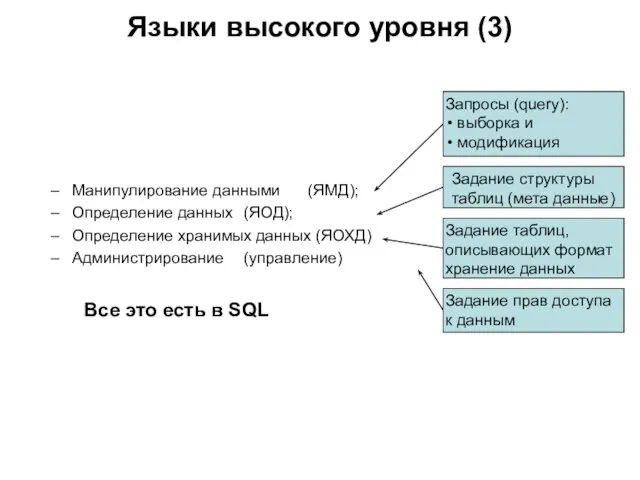
Манипулирование данными (ЯМД);
Определение данных (ЯОД);
Определение хранимых данных (ЯОХД)
Администрирование (управление)
Все это есть в SQL
Языки высокого
Манипулирование данными (ЯМД);
Определение данных (ЯОД);
Определение хранимых данных (ЯОХД)
Администрирование (управление)
Все это есть в SQL
Языки высокого
Слайд 131Манипулирование данными:
выборка
select * from publishers
вставка строки
insert into publishers
values (‘0010’,‘Pragma’,‘45 10th ln.’,‘Chicago’,‘ÍL’)
Определение
Манипулирование данными:
выборка
select * from publishers
вставка строки
insert into publishers
values (‘0010’,‘Pragma’,‘45 10th ln.’,‘Chicago’,‘ÍL’)
Определение

Слайд 132Основа всех операций – оператор select
Синтаксис (упрощенный): select <список выбора>
from <список таблиц>
where
Основа всех операций – оператор select
Синтаксис (упрощенный): select <список выбора>
from <список таблиц>
where
Слайд 133
select title, pub_name
from titles, publishers
where publishers.pub_id = titles.pub_id
Результат:
title pub_name
-------------------------------------------------------------
TTTT lll rrr New
select title, pub_name
from titles, publishers
where publishers.pub_id = titles.pub_id
Результат:
title pub_name
-------------------------------------------------------------
TTTT lll rrr New
Слайд 134Реляционные и теоретико-множественные операции (4 - продолжение)
А почему бы не использовать объединенную
Реляционные и теоретико-множественные операции (4 - продолжение)
А почему бы не использовать объединенную

Слайд 135Виртуальные таблицы(5)
Альтернативный способ просмотра данных: образование виртуальной таблицы, или курсора (view), или
Виртуальные таблицы(5)
Альтернативный способ просмотра данных: образование виртуальной таблицы, или курсора (view), или

Слайд 136Безопасность: авторизация (7.2)
Права доступа и роли
→ авторизация — механизм «знания» системой
Безопасность: авторизация (7.2)
Права доступа и роли → авторизация — механизм «знания» системой

Слайд 137Безопасность: целостность и ограничения на целостность (7.1, 7.3, 7.4)
Причины рассогласования (противоречивости, некорректности)
Безопасность: целостность и ограничения на целостность (7.1, 7.3, 7.4)
Причины рассогласования (противоречивости, некорректности)
Слайд 138Безопасность: целостность и ограничения на целостность (продолжение)
Безопасность: целостность и ограничения на целостность (продолжение)

Слайд 139Лекция C. Проектирование баз данных
Лекция C. Проектирование баз данных

Слайд 140Общие положения
Выбор:
таблиц,
столбцов таблиц,
взаимосвязей между таблицами и столбцами таблиц
Логическая структура не должна выбираться,
Общие положения
Выбор:
таблиц,
столбцов таблиц,
взаимосвязей между таблицами и столбцами таблиц
Логическая структура не должна выбираться,

Слайд 141Последовательность шагов
Исследовать информационную среду, которую нужно моделировать:
откуда поступают данные?
как они вводятся,
Последовательность шагов
Исследовать информационную среду, которую нужно моделировать:
откуда поступают данные?
как они вводятся,

Слайд 142Последовательность шагов
Убедиться, что есть атрибут (или группа атрибутов), однозначно идентифицирующая любую
Последовательность шагов
Убедиться, что есть атрибут (или группа атрибутов), однозначно идентифицирующая любую
Слайд 143Хорошая и плохая структура базы данных
Что такое «хорошая структура» базы данных?
максимально простое
Хорошая и плохая структура базы данных
Что такое «хорошая структура» базы данных?
максимально простое

Слайд 144Проект БД «Книги, авторы, издатели» (1)
Вопросы, которые могут задавать пользователи, — самые
Проект БД «Книги, авторы, издатели» (1)
Вопросы, которые могут задавать пользователи, — самые

Слайд 145Проект БД «Книги, авторы, издатели» (2)
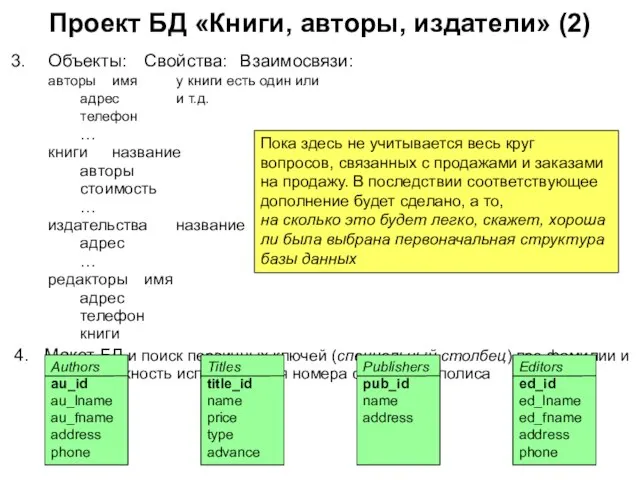
Объекты: Свойства: Взаимосвязи:
авторы имя у книги есть один или
адрес и т.д.
телефон
…
книги название
авторы
стоимость
…
издательства название
Проект БД «Книги, авторы, издатели» (2)
Объекты: Свойства: Взаимосвязи:
авторы имя у книги есть один или
адрес и т.д.
телефон
…
книги название
авторы
стоимость
…
издательства название
Слайд 146Проект БД «Книги, авторы, издатели» (3)
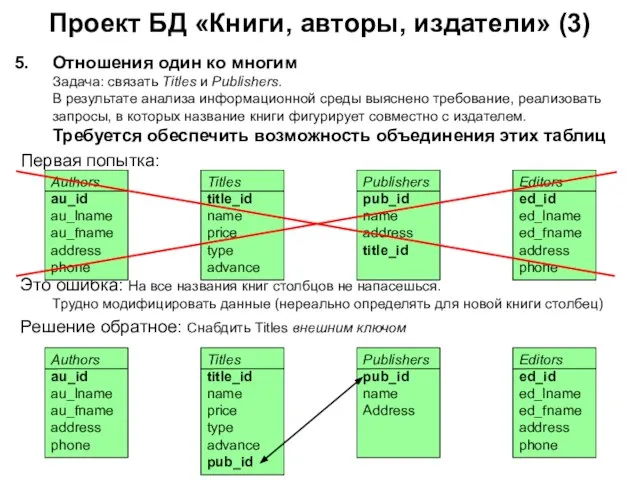
Отношения один ко многим
Задача: связать Titles и
Проект БД «Книги, авторы, издатели» (3)
Отношения один ко многим Задача: связать Titles и
Слайд 147Проект БД «Книги, авторы, издатели» (4)
Анализ решения (целостность):
обе таблицы содержат по одной
Проект БД «Книги, авторы, издатели» (4)
Анализ решения (целостность):
обе таблицы содержат по одной

Слайд 148Проект БД «Книги, авторы, издатели» (5)
Отношения многие к многим
Автор может писать много
Проект БД «Книги, авторы, издатели» (5)
Отношения многие к многим Автор может писать много
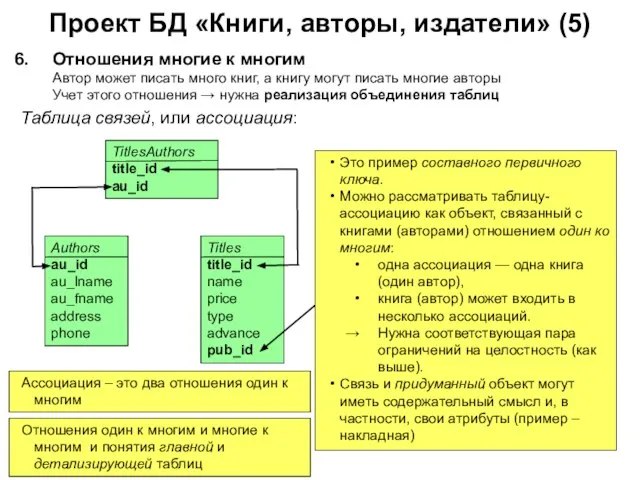
Слайд 149Проект БД «Книги, авторы, издатели» (6)
Анализ может
указать явно на то, что
Проект БД «Книги, авторы, издатели» (6)
Анализ может указать явно на то, что

Слайд 150Проект БД «Книги, авторы, издатели» (7)
Отношения один к одному
свободны от необходимости
Проект БД «Книги, авторы, издатели» (7)
Отношения один к одному
свободны от необходимости

Слайд 151Проект БД «Книги, авторы, издатели» (8)
Первый итог:
независимые объекты — строки таблиц;
свойства —
Проект БД «Книги, авторы, издатели» (8)
Первый итог:
независимые объекты — строки таблиц;
свойства —

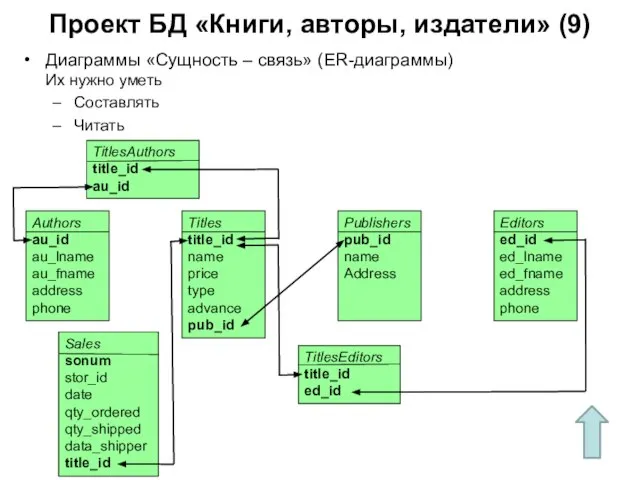
Слайд 152Проект БД «Книги, авторы, издатели» (9)
Диаграммы «Сущность – связь» (ER-диаграммы)
Их нужно уметь
Проект БД «Книги, авторы, издатели» (9)
Диаграммы «Сущность – связь» (ER-диаграммы) Их нужно уметь
Слайд 153Лекция C. Нормализация
Лекция C. Нормализация

Слайд 154Понятие нормализации и первая нормальная форма
Нормализация — набор стандартов проектирования БД, называемых
Понятие нормализации и первая нормальная форма
Нормализация — набор стандартов проектирования БД, называемых

Слайд 155Первая нормальная форма: пример
Tаблица Sales не удовлетворяет пожеланию заказчика иметь в одном
Первая нормальная форма: пример
Tаблица Sales не удовлетворяет пожеланию заказчика иметь в одном

Слайд 156Первая нормальная форма: пример (результат)
Что здесь обязательно, а что относится к специфике?
обязательное
Первая нормальная форма: пример (результат)
Что здесь обязательно, а что относится к специфике?
обязательное
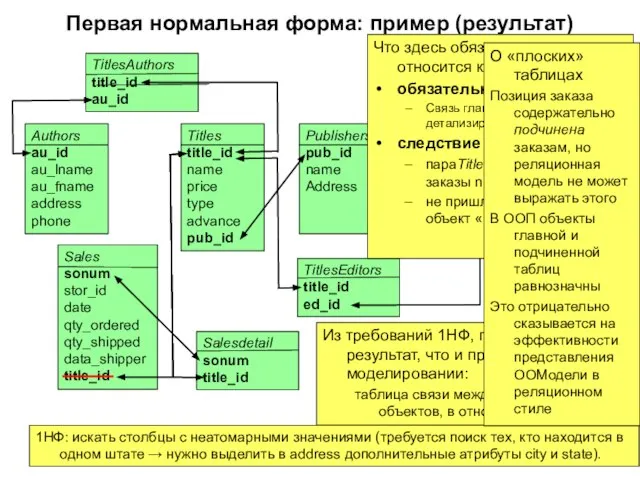
Слайд 157Вторая нормальная форма
2НФ в добавление к 1НФ требует: любой неключевой столбец должен
Вторая нормальная форма
2НФ в добавление к 1НФ требует: любой неключевой столбец должен

Слайд 158Третья нормальная форма
3НФ в добавление к к 1НФ и 2НФ требует: ни
Третья нормальная форма
3НФ в добавление к к 1НФ и 2НФ требует: ни

Слайд 159Другие нормальные формы
Четвертая нормальная форма формализует требования, выполнение которых гарантирует от появления
Другие нормальные формы
Четвертая нормальная форма формализует требования, выполнение которых гарантирует от появления

 Судебный этикет как составляющая культуры уголовно-процессуальной деятельности. Нормативные основы судебного этикета
Судебный этикет как составляющая культуры уголовно-процессуальной деятельности. Нормативные основы судебного этикета Оружие массового поражения
Оружие массового поражения Модельный ряд грузовых автомобилей Mercedes-Benz
Модельный ряд грузовых автомобилей Mercedes-Benz Энергетика: вчера, сегодня, завтра
Энергетика: вчера, сегодня, завтра ГИИС ЭБ. Запрос на аннулирование
ГИИС ЭБ. Запрос на аннулирование Элементы интернет-маркетинга и их взаимодействие
Элементы интернет-маркетинга и их взаимодействие 1. ОСНОВНЫЕ ПОНЯТИЯ Компьютерный исполнитель – это виртуальный объект, действующий в виртуальной среде обитания. Примеры: –Чертеж
1. ОСНОВНЫЕ ПОНЯТИЯ Компьютерный исполнитель – это виртуальный объект, действующий в виртуальной среде обитания. Примеры: –Чертеж Beerfest
Beerfest Красота осени
Красота осени Социально-психологическая служба в школе
Социально-психологическая служба в школе Как принимать управленческие решения
Как принимать управленческие решения Денежные переводы в Республике Таджикистан
Денежные переводы в Республике Таджикистан Темы в Drupal 6 Что нового, и чем оно грозит
Темы в Drupal 6 Что нового, и чем оно грозит Память в камне
Память в камне Помещение для открытия магазина Белорусская косметика
Помещение для открытия магазина Белорусская косметика Огневая подготовка. Версия 3
Огневая подготовка. Версия 3 Горный Дагестан
Горный Дагестан Методические рекомендации по введению модульной системы и системы зачетных единиц Методические рекомендации по разработке рабо
Методические рекомендации по введению модульной системы и системы зачетных единиц Методические рекомендации по разработке рабо Внутренний мир болезни
Внутренний мир болезни Техническое обслуживание и ремонт трансформатора ТДТНГ 40500\115\38,5\6,6 кВ Смоленск – 1
Техническое обслуживание и ремонт трансформатора ТДТНГ 40500\115\38,5\6,6 кВ Смоленск – 1 Кинестетик
Кинестетик Илья Ефимович Репин –великий русский художник
Илья Ефимович Репин –великий русский художник Václavské náměstí
Václavské náměstí Презентация на тему Иван третий (4 класс)
Презентация на тему Иван третий (4 класс) 11 причин инвестировать в Свердловскую область
11 причин инвестировать в Свердловскую область Технология установки врезного замка
Технология установки врезного замка Религия и мораль
Религия и мораль Караевское сельское поселение. Золотые руки мастера по бисероплетению
Караевское сельское поселение. Золотые руки мастера по бисероплетению