- Анализ данных. Подготовка данных

Содержание
- 2. Основные этапы подготовки данных Загрузка данных в хранилища Разделение данных Приведение данных к одинаковым единицам измерения
- 3. Анализ данных. Подготовка данных Загрузка данных в хранилища Кафедра информационно-аналитических систем Как правило, в системах хранения
- 4. Анализ данных. Подготовка данных Разделение данных Кафедра информационно-аналитических систем Простой пример задачи, с которой сталкиваются многие
- 5. Анализ данных. Подготовка данных Данные, также требующие разделения… Кафедра информационно-аналитических систем
- 6. Пример (разнообразие имен из реального хранилища) Анализ данных. Подготовка данных Кафедра информационно-аналитических систем
- 7. Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Преобразование данных к одинаковым единицам измерения Еще один важный
- 8. Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Пример преобразование данных к одинаковым единицам измерения
- 9. Преобразование к унифицированной лексике Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Одной из самых трудоемких задач
- 10. Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Пример преобразования к унифицированной лексике
- 11. Анализ данных. Подготовка данных Объединение данных из разных источников Кафедра информационно-аналитических систем
- 12. Анализ данных. Подготовка данных Объединение данных из разных источников. Вариант 1 Кафедра информационно-аналитических систем
- 13. Анализ данных. Подготовка данных Объединение данных из разных источников. Вариант 2 Кафедра информационно-аналитических систем
- 14. Анализ данных. Подготовка данных Соединение данных из разных источников Первая проблема – соответствие полей. Так же,
- 15. Анализ данных. Подготовка данных Пример соединения данных из разных источников Кафедра информационно-аналитических систем
- 16. Заполнение отсутствующих численных значений Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Одна из самых раздражающих проблем
- 17. Аппроксимация пропущенных значений В большинстве случаев (особенно во временных рядах) аппроксимация пропущенных значений осуществляется за счет
- 18. Пример (пропущенные значения) Анализ данных. Подготовка данных Кафедра информационно-аналитических систем
- 19. Очистка данных Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Как правило, очистка данных может быть сведена
- 20. Сочетание полей Для проверки данных можно также использовать сочетание полей. Иногда это действительно необходимо, потому что
- 21. Сравнение с образцом/Регулярные выражения Другой тип проверки данных, включает в себя сравнение с образцом. Такой вид
- 22. Устранение дубликатов Одна из проблем, решаемая на этапе очистки данных, это устранение дубликатов. Дубликаты могут появляться
- 23. Контроль диапазонов Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Контроль диапазонов − это на первый взгляд
- 24. Пример (контроль диапазонов) Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Вот как выглядят первые строки отсортированной
- 25. Анализ данных. Подготовка данных Контроль диапазонов Кафедра информационно-аналитических систем В примере с оценками визуального анализа вполне
- 26. Анализ данных. Подготовка данных Дисперсия Кафедра информационно-аналитических систем Дисперсия выборки – среднее арифметическое квадратов отклонений значений
- 27. Пример (вычисление дисперсии) Анализ данных. Подготовка данных Кафедра информационно-аналитических систем
- 28. Стандартное отклонение Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Стандартное отклонение вычисляется как корень квадратный из
- 29. Неравенство Чебышева Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Для интерпретации стандартного отклонения используют неравенство Чебышева.
- 30. Интерпретация стандартного отклонения Анализ данных. Подготовка данных Кафедра информационно-аналитических систем Можно утверждать, что интервал с границами
- 31. Интерпретация стандартного отклонения Анализ данных. Подготовка данных Кафедра информационно-аналитических систем В математической статистике доказывают что….
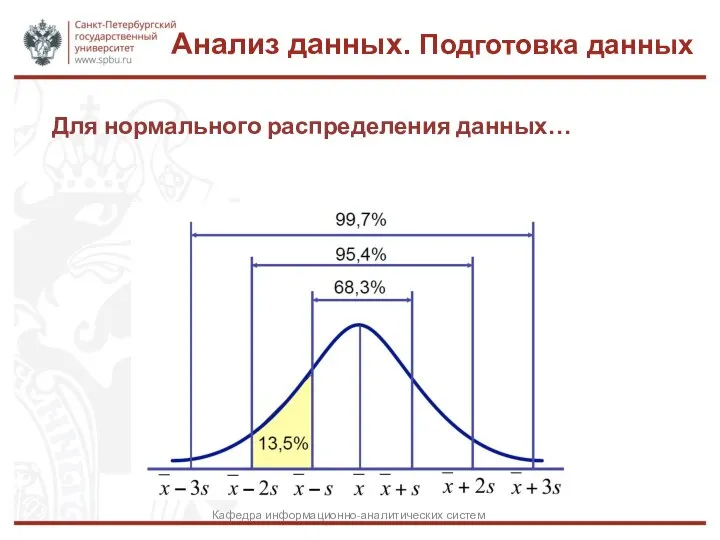
- 32. Для нормального распределения данных… Анализ данных. Подготовка данных Кафедра информационно-аналитических систем
- 33. Контроль диапазонов (итоги) Для определения выбросов используется понятие стандартного отклонения. Как правило – достаточно коэффициента k
- 34. Основные этапы подготовки данных – подведем итог Загрузка данных в хранилища Разделение данных Приведение данных к
- 35. Анализ данных. Подготовка данных Рассчитайте дисперсию, стандартное отклонение, а затем определите выбросы в одном из своих
- 37. Скачать презентацию
Слайд 2Основные этапы подготовки данных
Загрузка данных в хранилища
Разделение данных
Приведение данных к одинаковым единицам
Загрузка данных в хранилища
Разделение данных
Приведение данных к одинаковым единицам

Слайд 3Анализ данных. Подготовка данных
Загрузка данных в хранилища
Кафедра информационно-аналитических систем
Как правило, в системах
Анализ данных. Подготовка данных
Загрузка данных в хранилища
Кафедра информационно-аналитических систем
Как правило, в системах

Слайд 4Анализ данных. Подготовка данных
Разделение данных
Кафедра информационно-аналитических систем
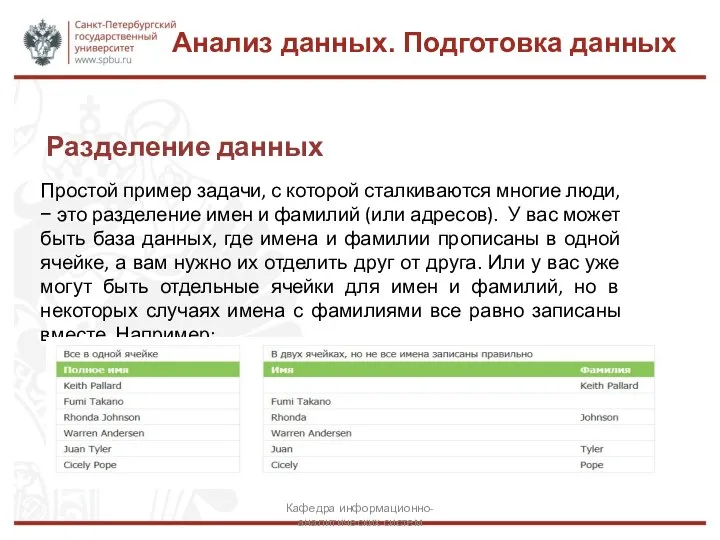
Простой пример задачи, с которой сталкиваются
Анализ данных. Подготовка данных
Разделение данных
Кафедра информационно-аналитических систем
Простой пример задачи, с которой сталкиваются
Слайд 5Анализ данных. Подготовка данных
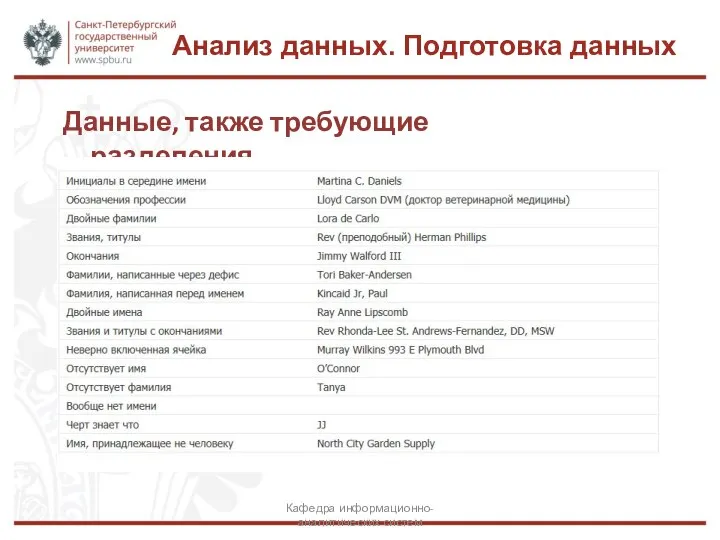
Данные, также требующие разделения…
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Данные, также требующие разделения…
Кафедра информационно-аналитических систем
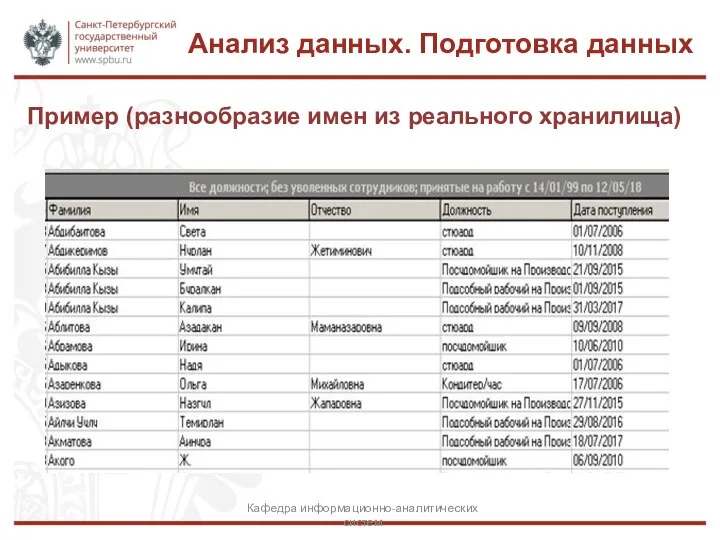
Слайд 6Пример (разнообразие имен из реального хранилища)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Слайд 7Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Преобразование данных к одинаковым единицам измерения
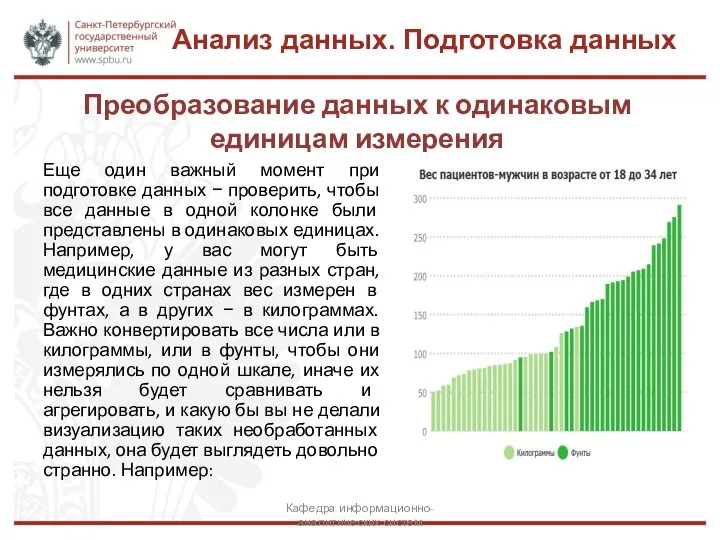
Еще один
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Преобразование данных к одинаковым единицам измерения
Еще один
Слайд 8Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
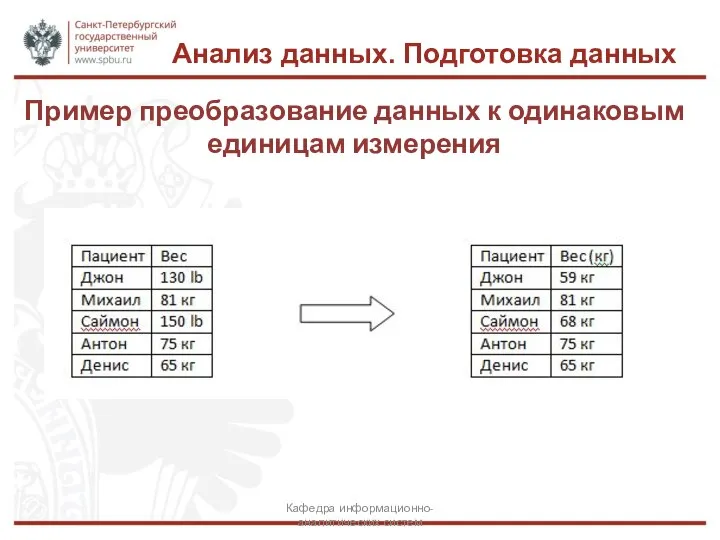
Пример преобразование данных к одинаковым единицам измерения
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Пример преобразование данных к одинаковым единицам измерения
Слайд 9Преобразование к унифицированной лексике
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
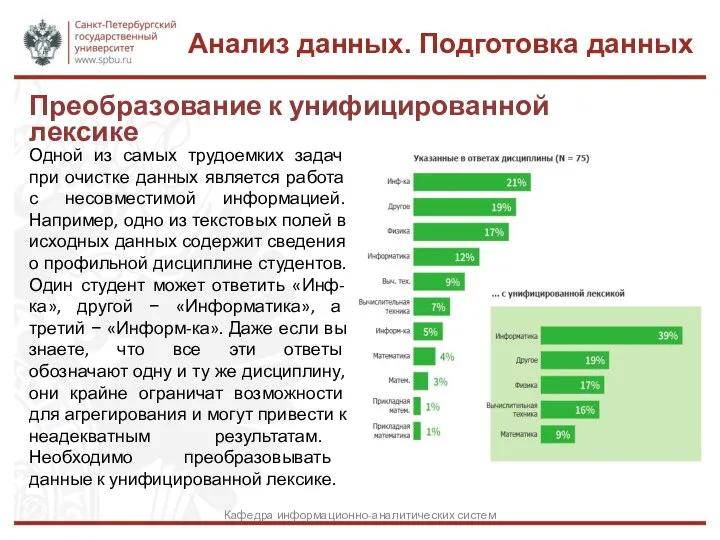
Одной из самых трудоемких
Преобразование к унифицированной лексике
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Одной из самых трудоемких
Слайд 10Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
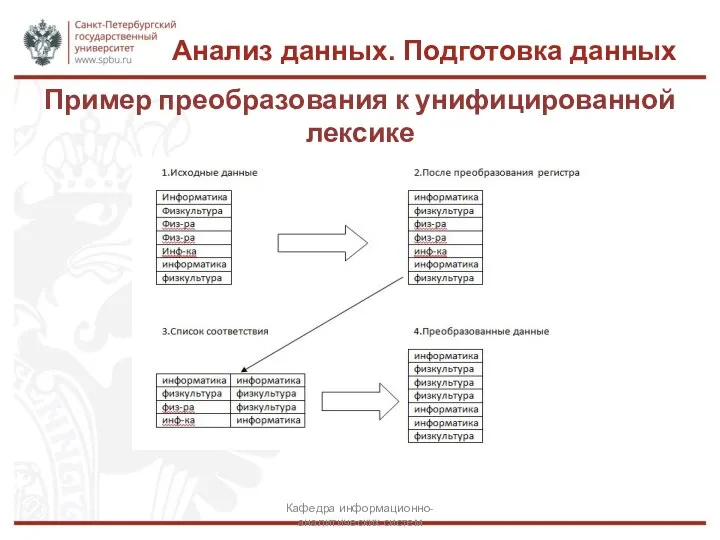
Пример преобразования к унифицированной лексике
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Пример преобразования к унифицированной лексике
Слайд 11Анализ данных. Подготовка данных
Объединение данных из разных источников
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Объединение данных из разных источников
Кафедра информационно-аналитических систем

Слайд 12Анализ данных. Подготовка данных
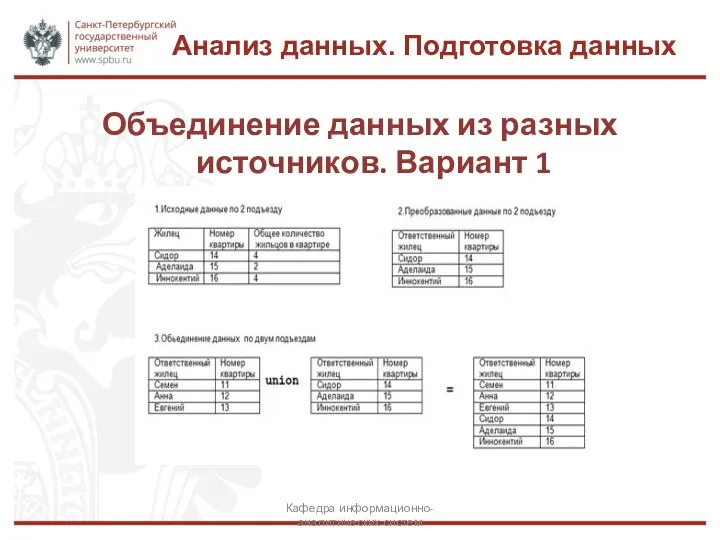
Объединение данных из разных источников. Вариант 1
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Объединение данных из разных источников. Вариант 1
Кафедра информационно-аналитических систем
Слайд 13Анализ данных. Подготовка данных
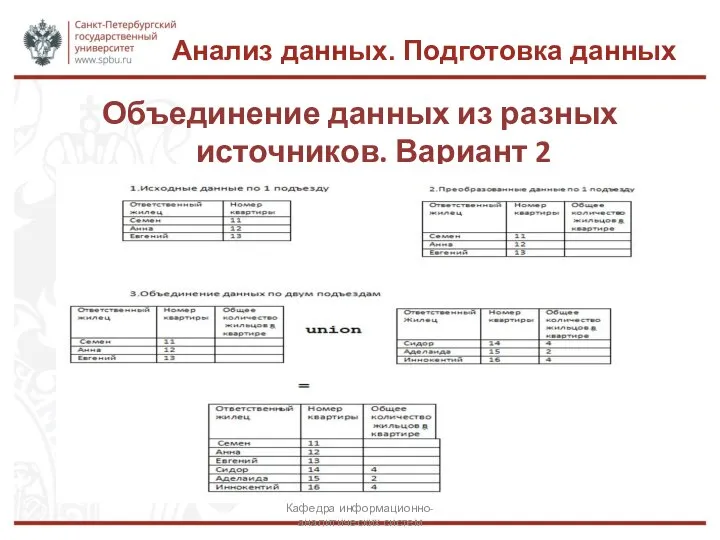
Объединение данных из разных источников. Вариант 2
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Объединение данных из разных источников. Вариант 2
Кафедра информационно-аналитических систем
Слайд 14Анализ данных. Подготовка данных
Соединение данных из разных источников
Первая проблема – соответствие полей.
Анализ данных. Подготовка данных
Соединение данных из разных источников
Первая проблема – соответствие полей.

Слайд 15Анализ данных. Подготовка данных
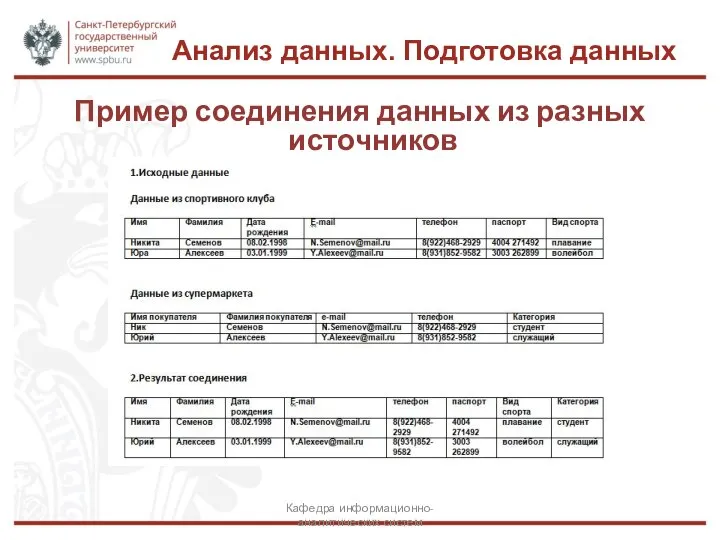
Пример соединения данных из разных источников
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Пример соединения данных из разных источников
Кафедра информационно-аналитических систем
Слайд 16Заполнение отсутствующих численных значений
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Одна из самых
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Одна из самых

Слайд 17Аппроксимация пропущенных значений
В большинстве случаев (особенно во временных рядах) аппроксимация пропущенных
В большинстве случаев (особенно во временных рядах) аппроксимация пропущенных

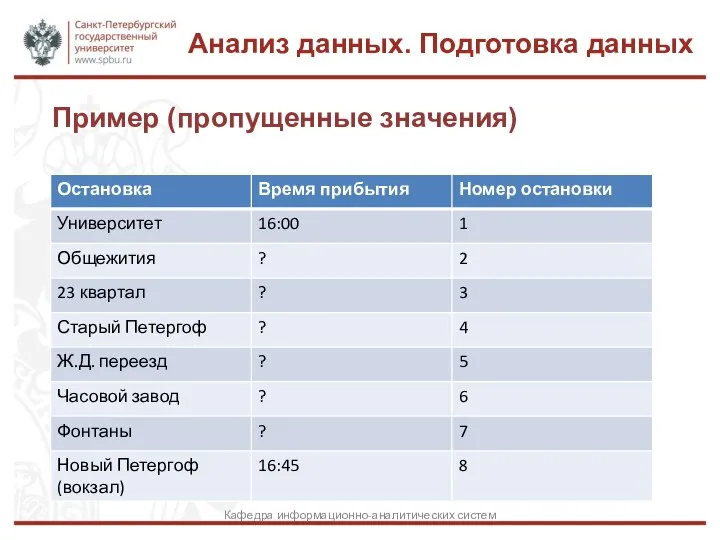
Слайд 18Пример (пропущенные значения)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Слайд 19Очистка данных
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Как правило, очистка данных может быть
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Как правило, очистка данных может быть

Слайд 20Сочетание полей
Для проверки данных можно также использовать сочетание полей. Иногда это действительно
Для проверки данных можно также использовать сочетание полей. Иногда это действительно

Слайд 21Сравнение с образцом/Регулярные выражения
Другой тип проверки данных, включает в себя сравнение с
Другой тип проверки данных, включает в себя сравнение с

Слайд 22Устранение дубликатов
Одна из проблем, решаемая на этапе очистки данных, это устранение дубликатов.
Одна из проблем, решаемая на этапе очистки данных, это устранение дубликатов.

Слайд 23Контроль диапазонов
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Контроль диапазонов − это на первый
Контроль диапазонов
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Контроль диапазонов − это на первый

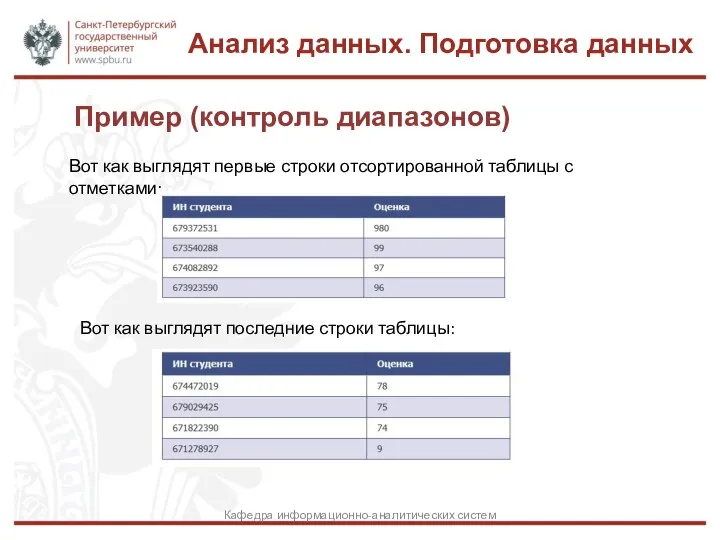
Слайд 24Пример (контроль диапазонов)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Вот как выглядят
Пример (контроль диапазонов)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Вот как выглядят
Слайд 25Анализ данных. Подготовка данных
Контроль диапазонов
Кафедра информационно-аналитических систем
В примере с оценками визуального
Анализ данных. Подготовка данных
Контроль диапазонов
Кафедра информационно-аналитических систем
В примере с оценками визуального

Слайд 26Анализ данных. Подготовка данных
Дисперсия
Кафедра информационно-аналитических систем
Дисперсия выборки – среднее арифметическое
Анализ данных. Подготовка данных
Дисперсия
Кафедра информационно-аналитических систем
Дисперсия выборки – среднее арифметическое

Слайд 27Пример (вычисление дисперсии)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Пример (вычисление дисперсии)
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем

Слайд 28Стандартное отклонение
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Стандартное отклонение вычисляется как корень
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Стандартное отклонение вычисляется как корень

Слайд 29Неравенство Чебышева
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Для интерпретации стандартного отклонения используют неравенство
Неравенство Чебышева
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Для интерпретации стандартного отклонения используют неравенство

Слайд 30Интерпретация стандартного отклонения
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Можно утверждать, что интервал с
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Можно утверждать, что интервал с

Слайд 31Интерпретация стандартного отклонения
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
В математической статистике доказывают что….
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
В математической статистике доказывают что….

Слайд 32Для нормального распределения данных…
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Анализ данных. Подготовка данных
Кафедра информационно-аналитических систем
Слайд 33Контроль диапазонов (итоги)
Для определения выбросов используется понятие стандартного отклонения. Как правило –
Для определения выбросов используется понятие стандартного отклонения. Как правило –

Слайд 34Основные этапы подготовки данных – подведем итог
Загрузка данных в хранилища
Разделение данных
Приведение данных
Загрузка данных в хранилища
Разделение данных
Приведение данных

Слайд 35Анализ данных. Подготовка данных
Рассчитайте дисперсию, стандартное отклонение, а затем определите выбросы в
Анализ данных. Подготовка данных
Рассчитайте дисперсию, стандартное отклонение, а затем определите выбросы в

 Методы обеспечивающие безопасность информации
Методы обеспечивающие безопасность информации Роль информатики и информационных технологий в современном мире
Роль информатики и информационных технологий в современном мире Информация и свойства информации
Информация и свойства информации Язык программирования Python
Язык программирования Python Microgrid на основе технологии blockchain
Microgrid на основе технологии blockchain Понятие как форма мышления. Урок 12
Понятие как форма мышления. Урок 12 The internet
The internet MapInfo Professional: назначение и возможности
MapInfo Professional: назначение и возможности Общие сведения о языке программирования Паскаль
Общие сведения о языке программирования Паскаль Разработка интернет-магазина на базе CMS OpenCar
Разработка интернет-магазина на базе CMS OpenCar История внедрения и перспективы применения компьютерных технологий в современной медицине и практике
История внедрения и перспективы применения компьютерных технологий в современной медицине и практике Briefing designers
Briefing designers Golem Forge
Golem Forge Проектная деятельность студентов
Проектная деятельность студентов Инженерная и компьютерная графика. Лекция 1
Инженерная и компьютерная графика. Лекция 1 Методология , структура и преимущество ERP – систем, смысл новой идеологии CSRP, расширенное управление
Методология , структура и преимущество ERP – систем, смысл новой идеологии CSRP, расширенное управление Опрос аудитории паблика OH MY HYPE
Опрос аудитории паблика OH MY HYPE Настройка шаблона
Настройка шаблона Компьютерные сети
Компьютерные сети SMM специалист с нуля
SMM специалист с нуля Основы использования новых информационных технологий в управленческой деятельности. Лекция № 2-2019
Основы использования новых информационных технологий в управленческой деятельности. Лекция № 2-2019 Палитры цветов в системах цветопередачи RGB, CMYK и HSB
Палитры цветов в системах цветопередачи RGB, CMYK и HSB Текстовый редактор MS-WORD
Текстовый редактор MS-WORD Виды компьютерных систем
Виды компьютерных систем Информационная система диагностики оборудования электродегидратора
Информационная система диагностики оборудования электродегидратора Подпись в МФЦ
Подпись в МФЦ Дискретная математика. Переводы из двоичной
Дискретная математика. Переводы из двоичной Локальные компьютерные сети (интерактивный плакат)
Локальные компьютерные сети (интерактивный плакат)