- Бинарный линейный классификатор

Содержание
- 2. Бинарный линейный классификатор XN={(x1,y1),…, (xN,yN)}, xi∈ RP, yi ∈{-1,+1} Цель: каждый новый входной вектор x отнести
- 3. Примеры задач Data mining классификация – отнесение объекта к одной из категорий (классов) на основании его
- 4. Линейная модель классификации
- 5. Пример нелинейного разделения классов
- 6. Confusion matrix (матрица ошибок классификации)
- 7. Метрики качества классификации Доля правильных ответов: Малоинформативна в задачах с неравными классами. Пример. Допустим, мы хотим
- 8. Метрики качества классификации precision (точность) и recall (полнота). Precision показывает долю объектов, названных классификатором положительными и
- 9. AUC-ROC –площадь под кривой ошибок TPR - это полнота, а FPR показывает, какую долю из объектов
- 10. AUC-ROC –площадь под кривой ошибок В идеальном случае, когда классификатор не делает ошибок (FPR = 0,
- 11. Чувствительность и специфичность Наряду с FPR и TPR при оценке качества классификации используют также понятия чувствительности
- 12. Дерево решений Деревья решений - это метод, позволяющий предсказывать значения зависимой переменной в зависимости от соответствующих
- 13. Графическая иллюстрация нелинейного разделения классов На рисунки приведен пример классификации объектов по двум непрерывным признакам. Объекты,
- 14. Использование деревьев решений в задачах регрессии
- 15. Этапы построения дерева решений 1. Выбор критерия точности прогноза 2. Выбор типа ветвления 3. Определение момента
- 16. Выбор типа ветвления (criterion) Есть различные способы выбирать очередной признак для текущего ветвления: Алгоритм ID3, где
- 17. Энтропия Энтропия Шеннона для системы с s возможными состояниями:
- 18. Прирост информации (ID3)
- 19. Прогноз игры в футбол Первый вариант дерева Второй вариант дерева
- 20. Вычисление энтропии и прироста информации
- 21. Нормализованный прирост информации (C4.5)
- 22. Индекс Gini (CART)
- 23. Правила разбиения (CART)
- 24. Правила остановки Минимальное число объектов, при котором выполняется расщепление (min_samples_split). В этом варианте ветвление прекращается, когда
- 25. Механизм отсечения дерева (CART)
- 26. Иллюстрация переобучения
- 27. Случайный лес (Random forest) Случайный лес — алгоритм машинного обучения, заключающийся в использовании комитета (ансамбля) деревьев
- 28. Обучение случайного леса
- 30. Скачать презентацию
Слайд 2Бинарный линейный классификатор
XN={(x1,y1),…, (xN,yN)}, xi∈ RP, yi ∈{-1,+1}
Цель: каждый новый входной вектор
Бинарный линейный классификатор
XN={(x1,y1),…, (xN,yN)}, xi∈ RP, yi ∈{-1,+1}
Цель: каждый новый входной вектор

Слайд 3Примеры задач Data mining
классификация – отнесение объекта к одной из категорий (классов)
Примеры задач Data mining
классификация – отнесение объекта к одной из категорий (классов)

Слайд 4Линейная модель классификации
Линейная модель классификации

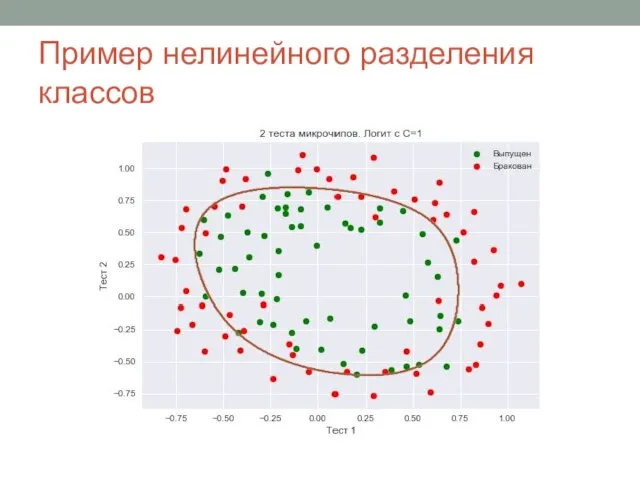
Слайд 5Пример нелинейного разделения классов
Пример нелинейного разделения классов
Слайд 6Confusion matrix (матрица ошибок классификации)
Confusion matrix (матрица ошибок классификации)

Слайд 7Метрики качества классификации
Доля правильных ответов:
Малоинформативна в задачах с неравными классами.
Пример. Допустим,
Метрики качества классификации
Доля правильных ответов:
Малоинформативна в задачах с неравными классами.
Пример. Допустим,

Слайд 8Метрики качества классификации
precision (точность) и recall (полнота).
Precision показывает долю объектов, названных классификатором
Метрики качества классификации
precision (точность) и recall (полнота).
Precision показывает долю объектов, названных классификатором

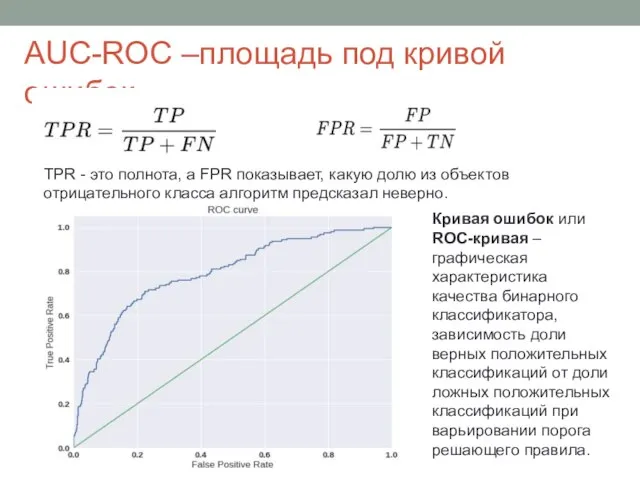
Слайд 9AUC-ROC –площадь под кривой ошибок
TPR - это полнота, а FPR показывает, какую
AUC-ROC –площадь под кривой ошибок
TPR - это полнота, а FPR показывает, какую
Слайд 10AUC-ROC –площадь под кривой ошибок
В идеальном случае, когда классификатор не делает ошибок
AUC-ROC –площадь под кривой ошибок
В идеальном случае, когда классификатор не делает ошибок

Слайд 11Чувствительность и специфичность
Наряду с FPR и TPR при оценке качества классификации используют
Чувствительность и специфичность
Наряду с FPR и TPR при оценке качества классификации используют

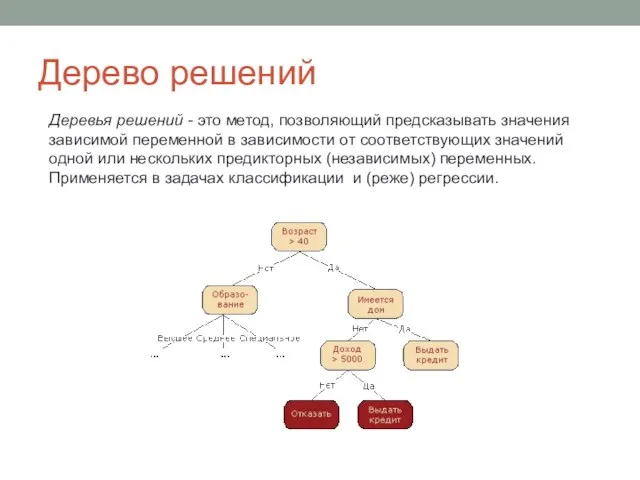
Слайд 12Дерево решений
Деревья решений - это метод, позволяющий предсказывать значения зависимой переменной в
Дерево решений
Деревья решений - это метод, позволяющий предсказывать значения зависимой переменной в
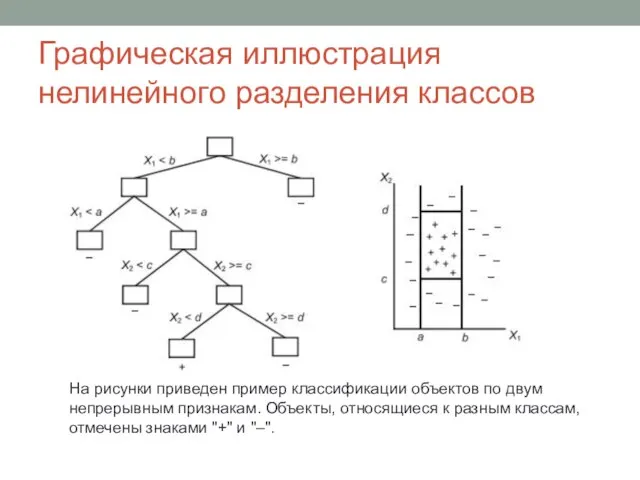
Слайд 13Графическая иллюстрация нелинейного разделения классов
На рисунки приведен пример классификации объектов по двум
Графическая иллюстрация нелинейного разделения классов
На рисунки приведен пример классификации объектов по двум
Слайд 14Использование деревьев решений в задачах регрессии
Использование деревьев решений в задачах регрессии
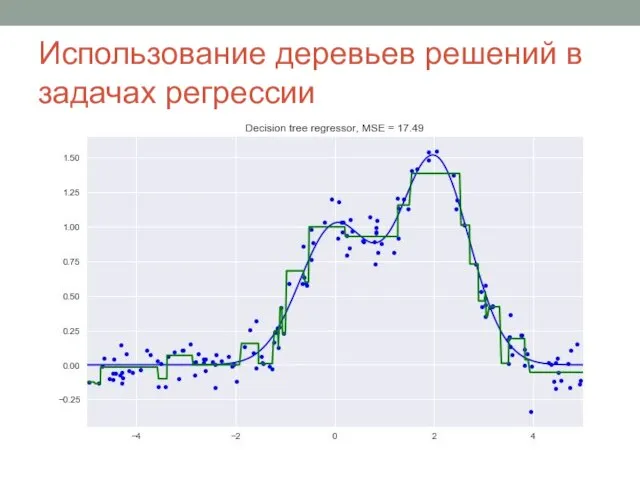
Слайд 15Этапы построения дерева решений
1. Выбор критерия точности прогноза
2. Выбор типа ветвления
3. Определение момента
Этапы построения дерева решений
1. Выбор критерия точности прогноза
2. Выбор типа ветвления
3. Определение момента

Слайд 16Выбор типа ветвления (criterion)
Есть различные способы выбирать очередной признак для текущего ветвления:
Алгоритм
Выбор типа ветвления (criterion)
Есть различные способы выбирать очередной признак для текущего ветвления:
Алгоритм

Слайд 17Энтропия
Энтропия Шеннона для системы с s возможными состояниями:
Энтропия
Энтропия Шеннона для системы с s возможными состояниями:

Слайд 18Прирост информации (ID3)
Прирост информации (ID3)

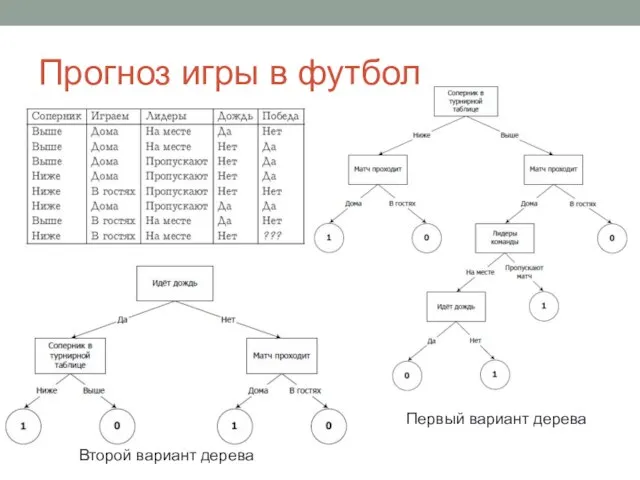
Слайд 19Прогноз игры в футбол
Первый вариант дерева
Второй вариант дерева
Прогноз игры в футбол
Первый вариант дерева
Второй вариант дерева
Слайд 20Вычисление энтропии и прироста информации
Вычисление энтропии и прироста информации

Слайд 21Нормализованный прирост информации (C4.5)
Нормализованный прирост информации (C4.5)

Слайд 22Индекс Gini (CART)
Индекс Gini (CART)

Слайд 23Правила разбиения (CART)
Правила разбиения (CART)

Слайд 24Правила остановки
Минимальное число объектов, при котором выполняется расщепление (min_samples_split). В этом варианте
Правила остановки
Минимальное число объектов, при котором выполняется расщепление (min_samples_split). В этом варианте

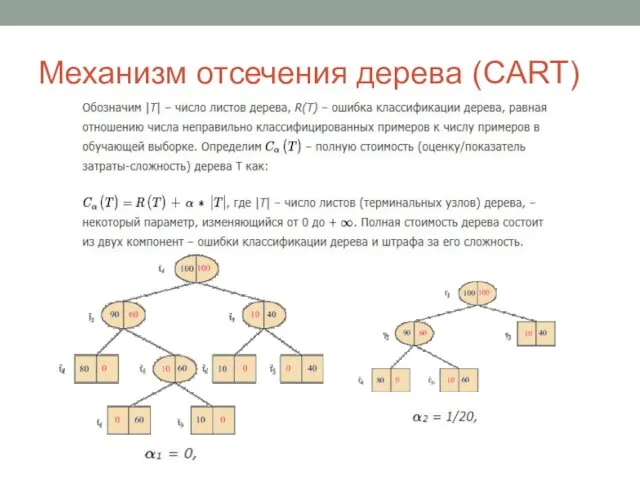
Слайд 25Механизм отсечения дерева (CART)
Механизм отсечения дерева (CART)
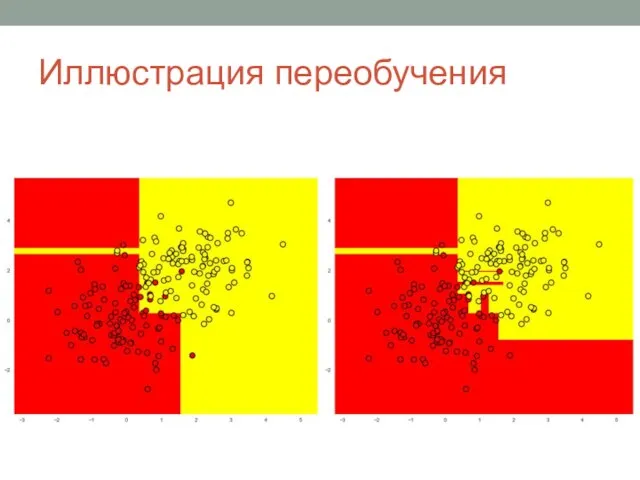
Слайд 26Иллюстрация переобучения
Иллюстрация переобучения
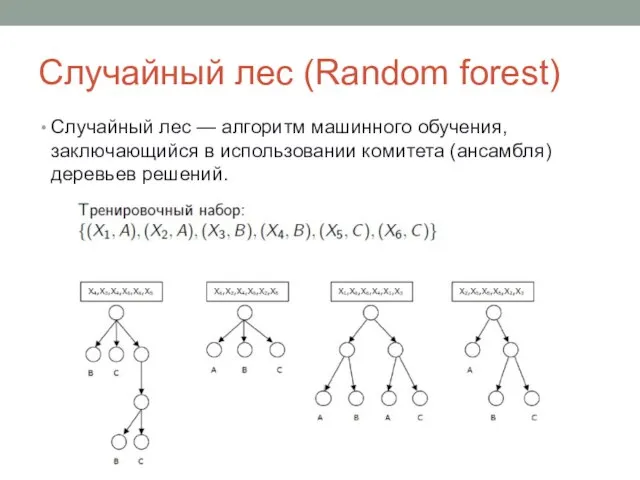
Слайд 27Случайный лес (Random forest)
Случайный лес — алгоритм машинного обучения, заключающийся в использовании комитета
Случайный лес (Random forest)
Случайный лес — алгоритм машинного обучения, заключающийся в использовании комитета
Слайд 28Обучение случайного леса
Обучение случайного леса

 Устройства вывода информации
Устройства вывода информации Рисуем снежинку. Занятие по программе Paint
Рисуем снежинку. Занятие по программе Paint Классификация программного обеспечения
Классификация программного обеспечения Черепашка и координатная система
Черепашка и координатная система Устройство компьютера и ОС Windows
Устройство компьютера и ОС Windows Фокусы. Оптимизация компилятором
Фокусы. Оптимизация компилятором Информационная деятельность
Информационная деятельность Безопасность в сети Интернет
Безопасность в сети Интернет Компьютерные технологии в системе сельской техники
Компьютерные технологии в системе сельской техники Программа: PROGRAM arifm
Программа: PROGRAM arifm Методика підготовки та надсилання до ЄДРСР за допомогою КП Д-З документів минулих років
Методика підготовки та надсилання до ЄДРСР за допомогою КП Д-З документів минулих років Функции и модули (1)
Функции и модули (1) Реализация на жесткой и программируемой логике
Реализация на жесткой и программируемой логике Электронная система поиска Скопус. Особенности работы
Электронная система поиска Скопус. Особенности работы Интернет-угрозы в молодёжной среде
Интернет-угрозы в молодёжной среде Районная газета Ваша звезда, Павлоградского района Омской области
Районная газета Ваша звезда, Павлоградского района Омской области Інформатика 9 клас. Урок 1
Інформатика 9 клас. Урок 1 Теория автоматов в программировании. Лекция 1
Теория автоматов в программировании. Лекция 1 Виды серверного ПО
Виды серверного ПО презентация Сервисы для хранения информации в Интернете
презентация Сервисы для хранения информации в Интернете Информатика. Анаграмма
Информатика. Анаграмма Электронно-цифровая подпись
Электронно-цифровая подпись Признаки объектов
Признаки объектов Безопасность в сети Интернет
Безопасность в сети Интернет Создание и редактирование рисунка. Графический редактор Paint
Создание и редактирование рисунка. Графический редактор Paint Процессоры от зарождения до наших дней
Процессоры от зарождения до наших дней Создание молекулярных ассемблеров
Создание молекулярных ассемблеров Дистанционное обучение в художественной студии дворца учащейся молодежи Санкт-Петербурга
Дистанционное обучение в художественной студии дворца учащейся молодежи Санкт-Петербурга