- Динамические структуры данных (язык Паскаль)

Содержание
- 2. Тема 1. Указатели © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
- 3. Статические данные переменная (массив) имеет имя, по которому к ней можно обращаться размер заранее известен (задается
- 4. Динамические данные размер заранее неизвестен, определяется во время работы программы память выделяется во время работы программы
- 5. Указатели Указатель – это переменная, в которую можно записывать адрес другой переменной (или блока памяти). Объявление:
- 6. Обращение к данным через указатель program qq; var m, n: integer; pI: ^integer; begin m :=
- 7. Обращение к данным (массивы) program qq; var i: integer; A: array[1..4] of integer; pI: ^integer; begin
- 8. Что надо знать об указателях указатель – это переменная, в которой можно хранить адрес другой переменной;
- 9. Тема 2. Динамические массивы © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
- 10. Где нужны динамические массивы? Задача. Ввести размер массива, затем – элементы массива. Отсортировать массив и вывести
- 11. Использование указателей (Delphi) program qq; type intArray = array[1..1] of integer; var A: ^intArray; i, N:
- 12. Использование указателей для выделения памяти используют процедуру GetMem GetMem( указатель, размер в байтах ); указатель должен
- 13. Ошибки при работе с памятью Запись в «чужую» область памяти: память не была выделена, а массив
- 14. Динамические массивы(Delphi) program qq; var A: array of integer; i, N: integer; begin writeln('Размер массива>'); readln(N);
- 15. Динамические массивы (Delphi) при объявлении массива указывают только его тип, память не выделяется: var A: array
- 16. Динамические матрицы (Delphi) Задача. Ввести размеры матрицы и выделить для нее место в памяти во время
- 17. Тема 3. Структуры (записи) © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
- 18. Структуры (в Паскале – записи) Структура (запись) – это тип данных, который может включать в себя
- 19. Одна запись readln(Book.author); // ввод readln(Book.title); Book.year := 1998; // присваивание if Book.pages > 200 then
- 20. Массив записей Объявление (выделение памяти): const N = 10; var aBooks: array[1..N] of record author: string[40];
- 21. Массив записей for i:=1 to N do begin readln(aBooks[i].author); readln(aBooks[i].title); ... end; for i:=1 to N
- 22. Новый тип данных – запись const N = 10; var Book: TBook; // одна запись aBooks:
- 23. Записи в процедурах и функциях Book.author := 'А.С. Пушкин'; ShowAuthor ( Book ); Book.year := 1800;
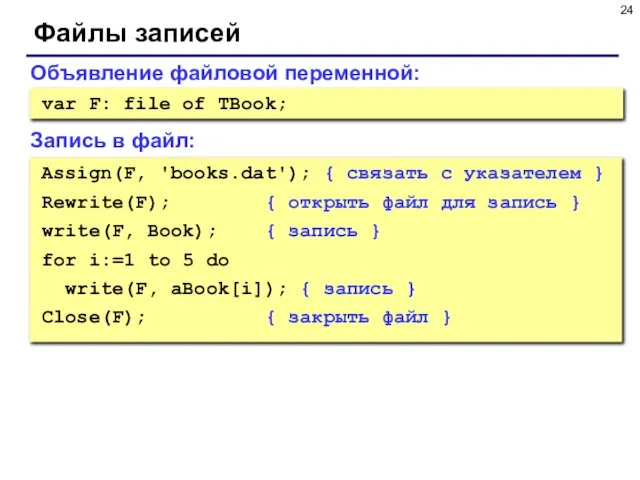
- 24. Файлы записей Объявление файловой переменной: var F: file of TBook; Assign(F, 'books.dat'); { связать с указателем
- 25. Чтение из файла Известное число записей: Assign(F, 'books.dat'); { связать с указателем } Reset(F); { открыть
- 26. Пример программы Задача: в файле books.dat записаны данные о книгах в виде массива структур типа TBook
- 27. Пример программы Чтение «пока не кончатся»: Assign(F, 'books.dat'); Reset(F); N := 0; while not eof(F) and
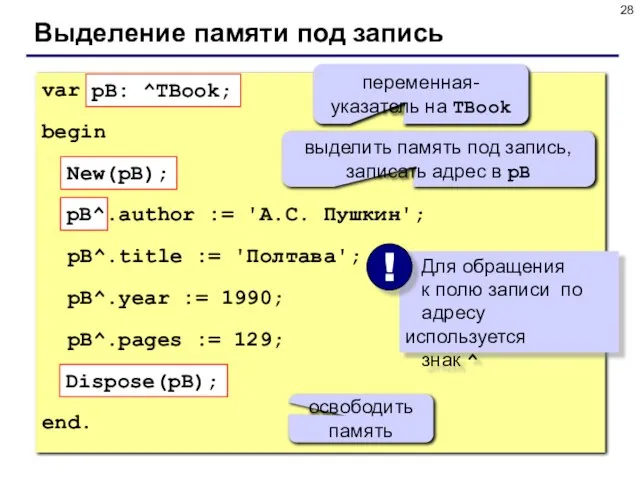
- 28. Выделение памяти под запись var pB: ^TBook; begin New(pB); pB^.author := 'А.С. Пушкин'; pB^.title := 'Полтава';
- 29. Сортировка массива записей Ключ (ключевое поле) – это поле записи (или комбинация полей), по которому выполняется
- 30. Сортировка массива записей for i:=1 to N-1 do for j:=N-1 downto i do if aBooks[j].year >
- 31. Сортировка массива записей Проблема: как избежать копирования записи при сортировке? Решение: использовать вспомогательный массив указателей, при
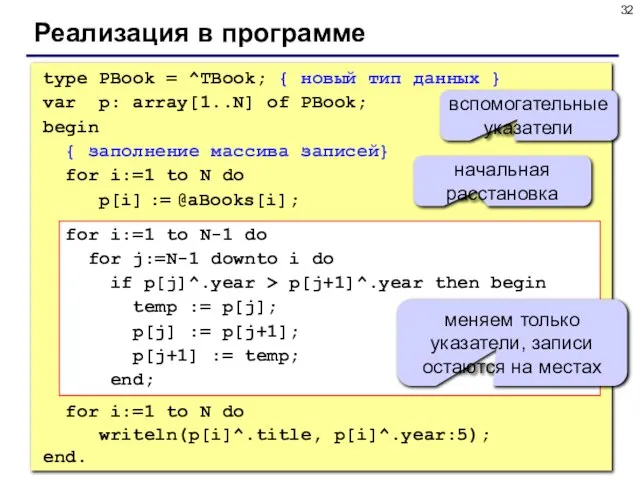
- 32. Реализация в программе type PBook = ^TBook; { новый тип данных } var p: array[1..N] of
- 33. Тема 4. Списки © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
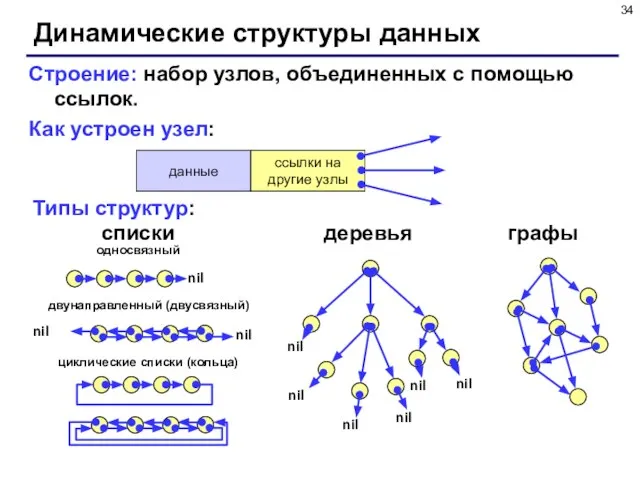
- 34. Динамические структуры данных Строение: набор узлов, объединенных с помощью ссылок. Как устроен узел: Типы структур: списки
- 35. Когда нужны списки? Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать в другой файл в
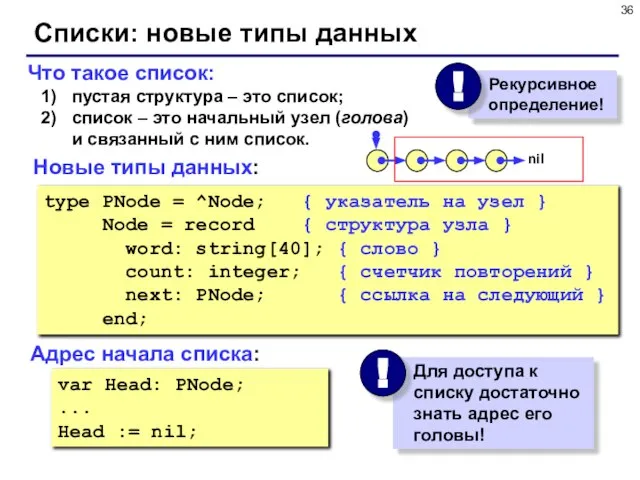
- 36. Что такое список: пустая структура – это список; список – это начальный узел (голова) и связанный
- 37. Что нужно уметь делать со списком? Создать новый узел. Добавить узел: а) в начало списка; б)
- 38. Создание узла function CreateNode(NewWord: string): PNode; var NewNode: PNode; begin New(NewNode); NewNode^.word := NewWord; NewNode^.count :=
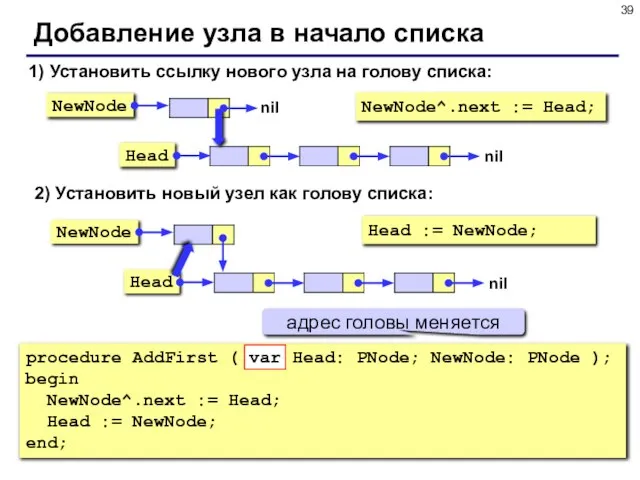
- 39. Добавление узла в начало списка 1) Установить ссылку нового узла на голову списка: NewNode^.next := Head;
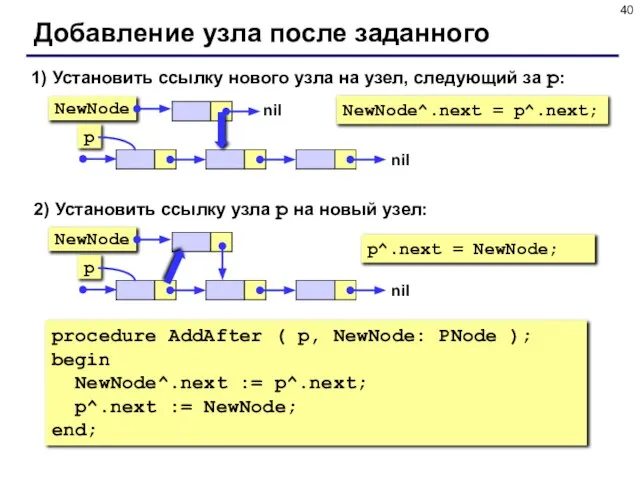
- 40. Добавление узла после заданного 1) Установить ссылку нового узла на узел, следующий за p: NewNode^.next =
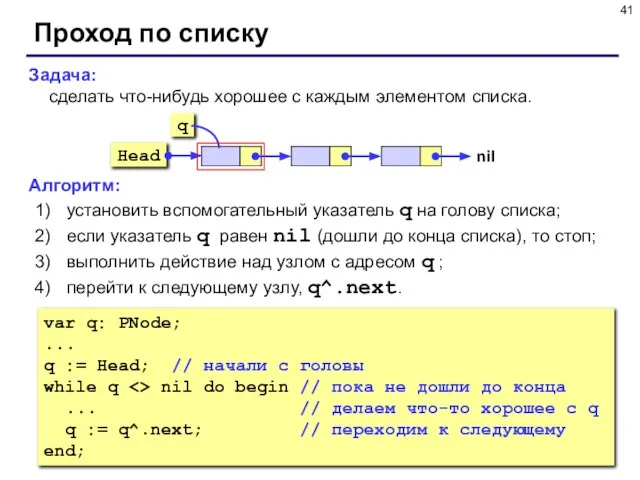
- 41. Задача: сделать что-нибудь хорошее с каждым элементом списка. Алгоритм: установить вспомогательный указатель q на голову списка;
- 42. Добавление узла в конец списка Задача: добавить новый узел в конец списка. Алгоритм: найти последний узел
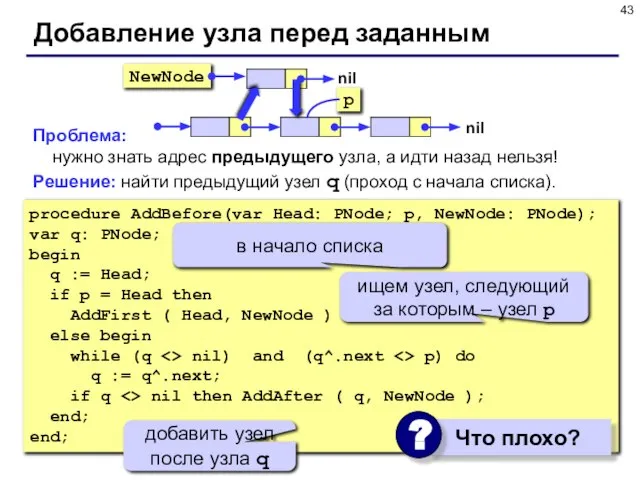
- 43. Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя! Решение: найти предыдущий узел q (проход
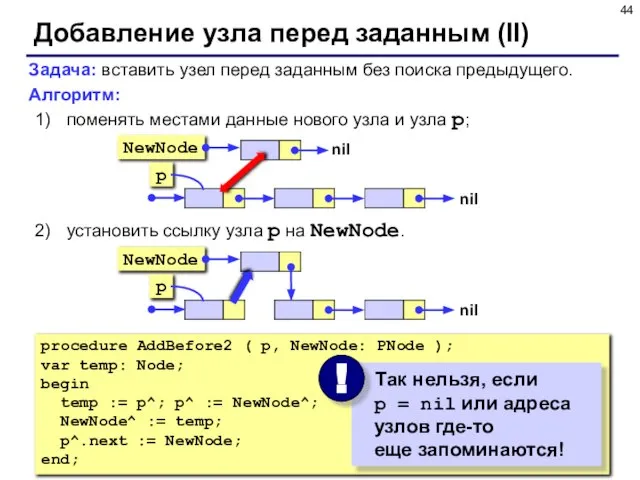
- 44. Добавление узла перед заданным (II) Задача: вставить узел перед заданным без поиска предыдущего. Алгоритм: поменять местами
- 45. Поиск слова в списке Задача: найти в списке заданное слово или определить, что его нет. Функция
- 46. Куда вставить новое слово? Задача: найти узел, перед которым нужно вставить, заданное слово, так чтобы в
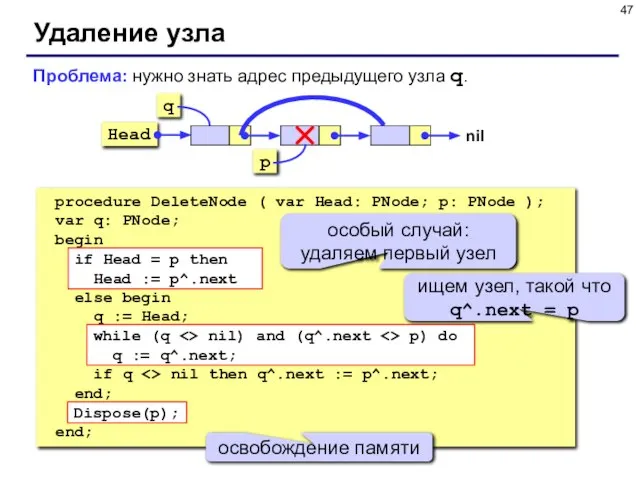
- 47. Удаление узла procedure DeleteNode ( var Head: PNode; p: PNode ); var q: PNode; begin if
- 48. Алфавитно-частотный словарь Алгоритм: открыть файл на чтение; прочитать очередное слово (как?) если файл закончился, то перейти
- 49. Как прочитать одно слово из файла? function GetWord ( F: Text ) : string; var c:
- 50. Полная программа type PNode = ^Node; Node = record ... end; { новые типы данных }
- 51. Полная программа (II) { читаем слова из файла, строим список } while True do begin {
- 52. Полная программа (III) { выводим список в другой файл } q := Head; { проход с
- 53. type PNode = ^Node; { указатель на узел } Node = record { структура узла }
- 54. Задания «4»: «Собрать» из этих функций программу для построения алфавитно-частотного словаря. В конце файла вывести общее
- 55. Тема 5. Стеки, очереди, деки © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
- 56. Стек Стек – это линейная структура данных, в которой добавление и удаление элементов возможно только с
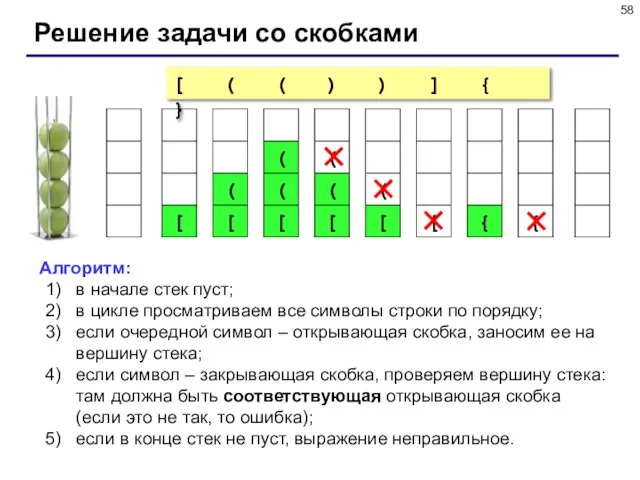
- 57. Пример задачи Задача: вводится символьная строка, в которой записано выражение со скобками трех типов: [], {}
- 58. Решение задачи со скобками Алгоритм: в начале стек пуст; в цикле просматриваем все символы строки по
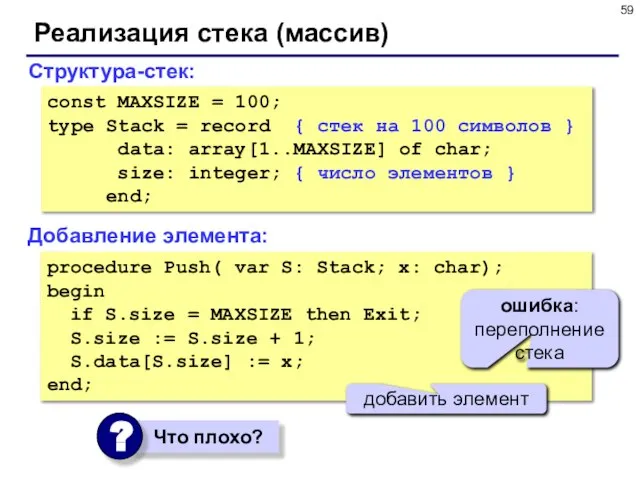
- 59. Реализация стека (массив) Структура-стек: const MAXSIZE = 100; type Stack = record { стек на 100
- 60. Реализация стека (массив) function Pop ( var S:Stack ): char; begin if S.size = 0 then
- 61. Программа var br1, br2, expr: string; i, k: integer; upper: char; { то, что сняли со
- 62. Обработка строки (основной цикл) for i:=1 to length(expr) do begin for k:=1 to 3 do begin
- 63. Реализация стека (список) Добавление элемента: Структура узла: type PNode = ^Node; { указатель на узел }
- 64. Реализация стека (список) Снятие элемента с вершины: function Pop ( var Head: PNode ): char; var
- 65. Реализация стека (список) Изменения в основной программе: var S: Stack; ... S.size := 0; var S:
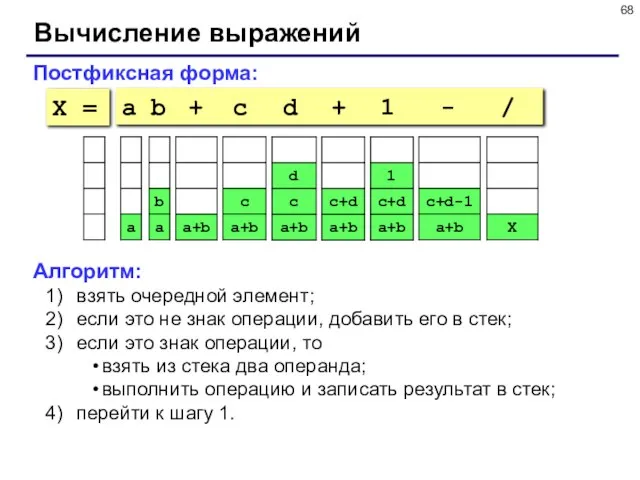
- 66. Вычисление арифметических выражений a b + c d + 1 - / Как вычислять автоматически: Инфиксная
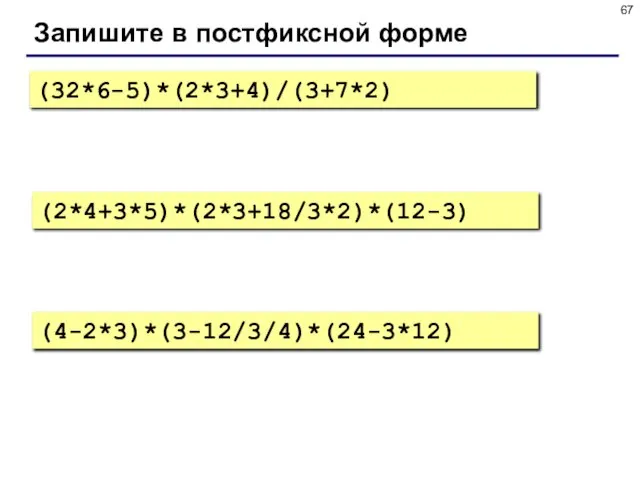
- 67. Запишите в постфиксной форме (32*6-5)*(2*3+4)/(3+7*2) (2*4+3*5)*(2*3+18/3*2)*(12-3) (4-2*3)*(3-12/3/4)*(24-3*12)
- 68. Вычисление выражений Постфиксная форма: a b + c d + 1 - / Алгоритм: взять очередной
- 69. Системный стек (Windows – 1 Мб) Используется для размещения локальных переменных; хранения адресов возврата (по которым
- 70. Очередь Очередь – это линейная структура данных, в которой добавление элементов возможно только с одного конца
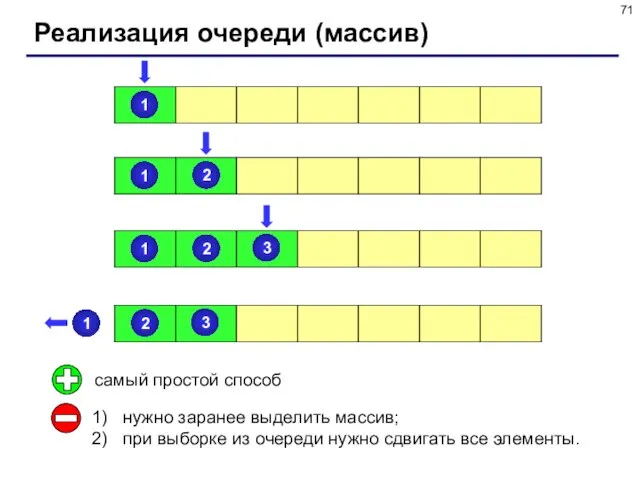
- 71. Реализация очереди (массив) самый простой способ нужно заранее выделить массив; при выборке из очереди нужно сдвигать
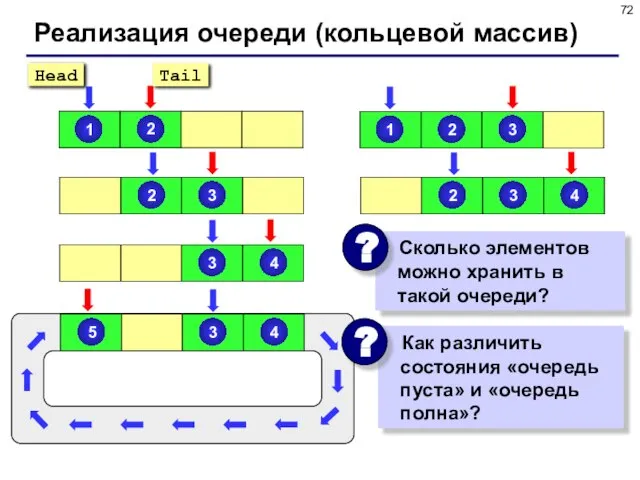
- 72. Реализация очереди (кольцевой массив)
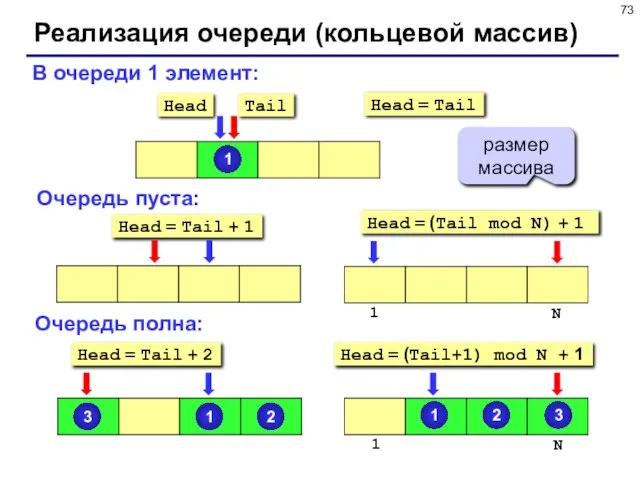
- 73. Реализация очереди (кольцевой массив) В очереди 1 элемент: Очередь пуста: Очередь полна: Head = Tail +
- 74. Реализация очереди (кольцевой массив) type Queue = record data: array[1..MAXSIZE] of integer; head, tail: integer; end;
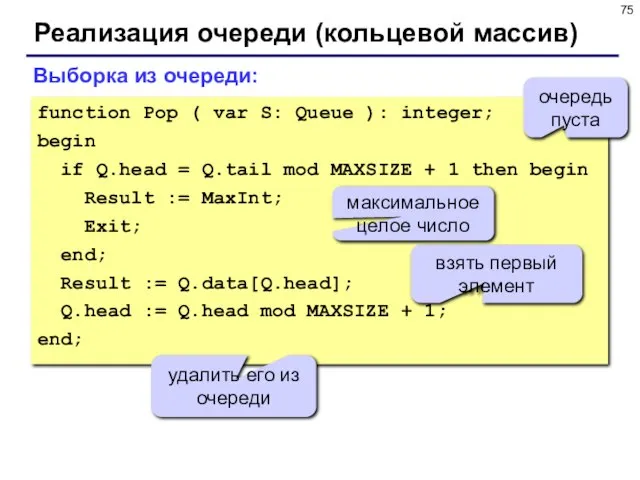
- 75. Реализация очереди (кольцевой массив) Выборка из очереди: function Pop ( var S: Queue ): integer; begin
- 76. Реализация очереди (списки) type PNode = ^Node; Node = record data: integer; next: PNode; end; type
- 77. Реализация очереди (списки) procedure PushTail( var Q: Queue; x: integer ); var NewNode: PNode; begin New(NewNode);
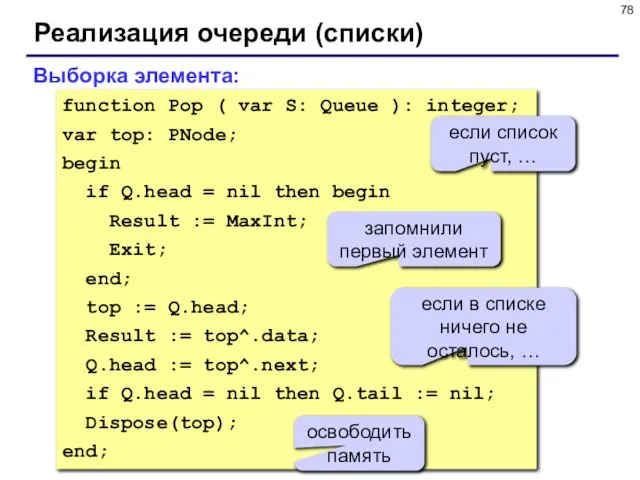
- 78. Реализация очереди (списки) function Pop ( var S: Queue ): integer; var top: PNode; begin if
- 79. Дек Дек (deque = double ended queue, очередь с двумя концами) – это линейная структура данных,
- 80. Задания «4»: В файле input.dat находится список чисел (или слов). Переписать его в файл output.dat в
- 81. Тема 6. Деревья © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
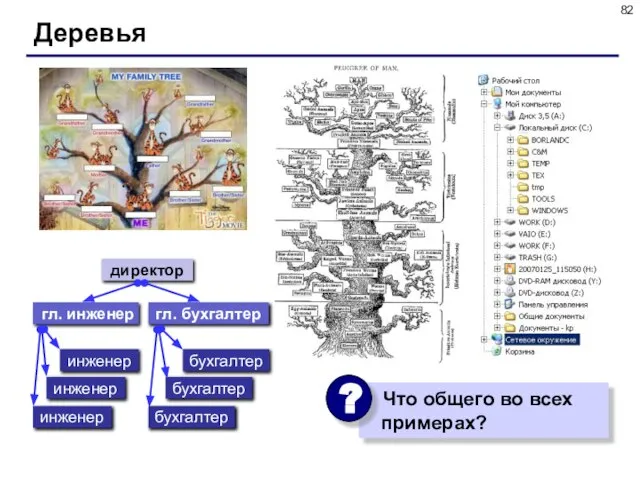
- 82. Деревья
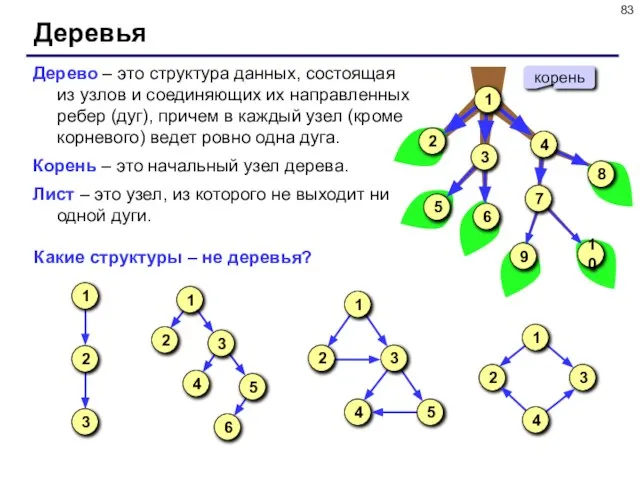
- 83. Деревья Дерево – это структура данных, состоящая из узлов и соединяющих их направленных ребер (дуг), причем
- 84. Деревья Предок узла x – это узел, из которого существует путь по стрелкам в узел x.
- 85. Дерево – рекурсивная структура данных Рекурсивное определение: Пустая структура – это дерево. Дерево – это корень
- 86. Двоичные деревья Структура узла: type PNode = ^Node; { указатель на узел } Node = record
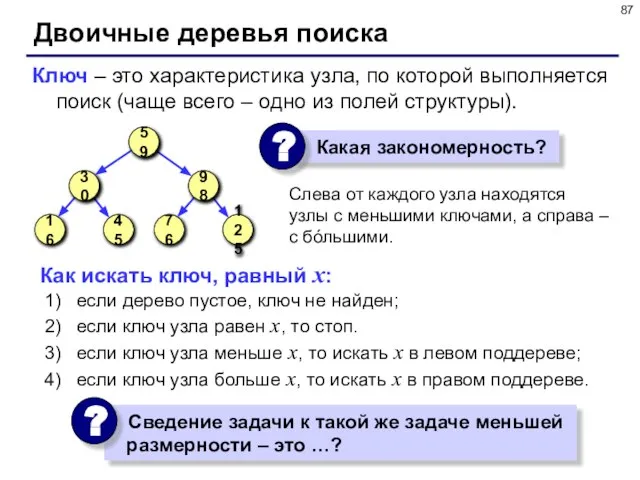
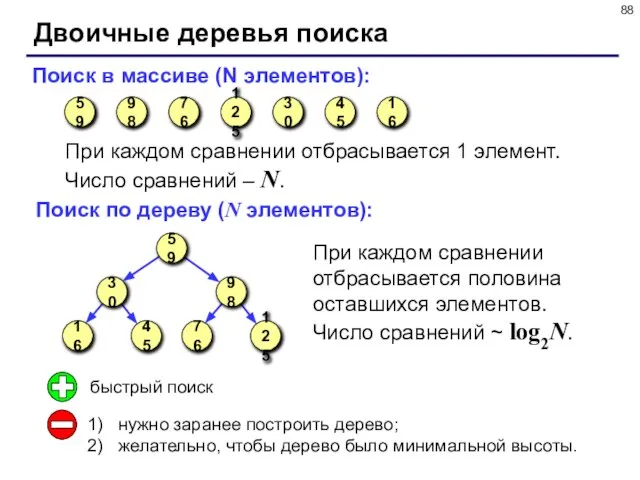
- 87. Двоичные деревья поиска Слева от каждого узла находятся узлы с меньшими ключами, а справа – с
- 88. Двоичные деревья поиска Поиск в массиве (N элементов): При каждом сравнении отбрасывается 1 элемент. Число сравнений
- 89. Реализация алгоритма поиска { Функция Search – поиск по дереву Вход: Tree - адрес корня, x
- 90. Как построить дерево поиска? { Процедура AddToTree – добавить элемент Вход: Tree - адрес корня, x
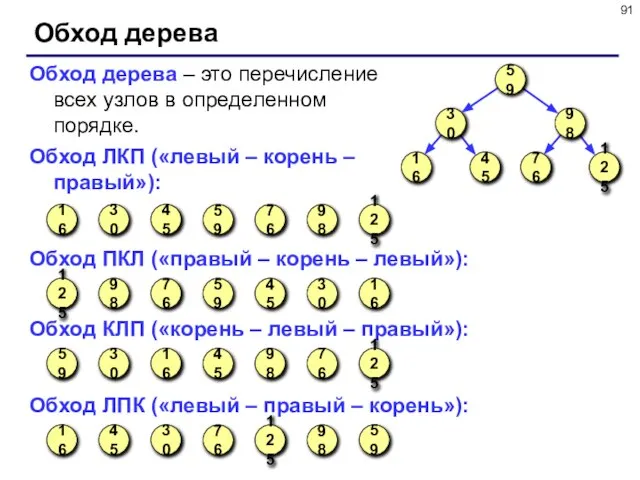
- 91. Обход дерева Обход дерева – это перечисление всех узлов в определенном порядке. Обход ЛКП («левый –
- 92. Обход дерева – реализация { Процедура LKP – обход дерева в порядке ЛКП (левый – корень
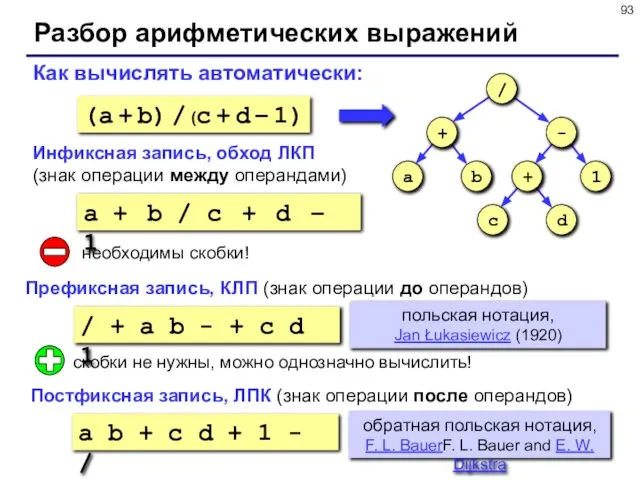
- 93. Разбор арифметических выражений a b + c d + 1 - / Как вычислять автоматически: Инфиксная
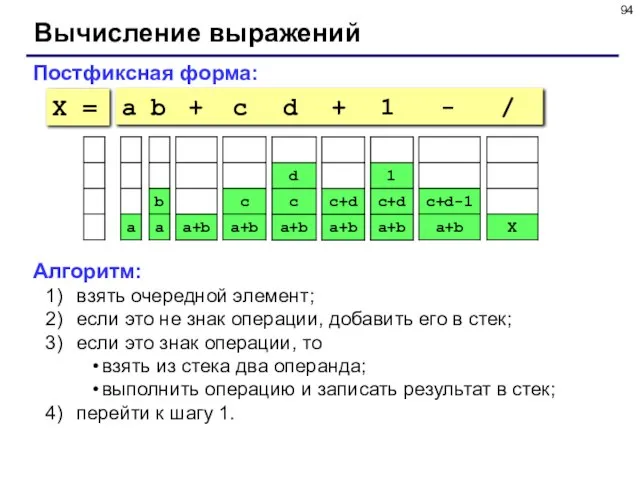
- 94. Вычисление выражений Постфиксная форма: a b + c d + 1 - / Алгоритм: взять очередной
- 95. Вычисление выражений Задача: в символьной строке записано правильное арифметическое выражение, которое может содержать только однозначные числа
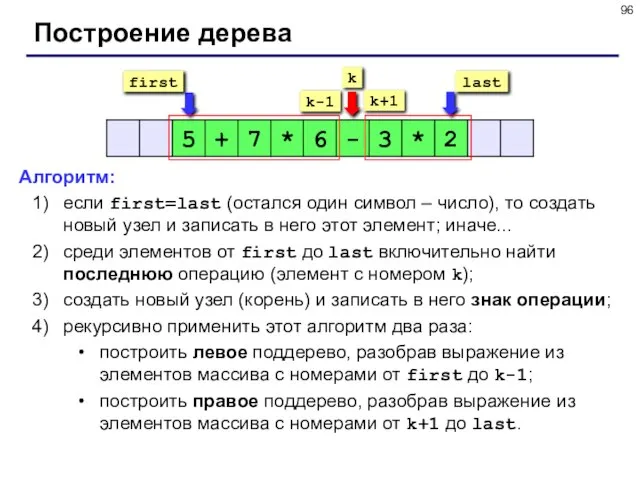
- 96. Построение дерева Алгоритм: если first=last (остался один символ – число), то создать новый узел и записать
- 97. Как найти последнюю операцию? Порядок выполнения операций умножение и деление; сложение и вычитание. Приоритет (старшинство) –
- 98. Приоритет операции { Функция Priority – приоритет операции Вход: символ операции Выход: приоритет или 100, если
- 99. Номер последней операции { Функция LastOperation – номер последней операции Вход: строка, номера первого и последнего
- 100. Построение дерева Структура узла type PNode = ^Node; Node = record data: char; left, right: PNode;
- 101. Построение дерева { Функция MakeTree – построение дерева Вход: строка, номера первого и последнего символов рассматриваемой
- 102. Вычисление выражения по дереву { Функция CalcTree – вычисление по дереву Вход: адрес дерева Выход: значение
- 103. Основная программа { Ввод и вычисление выражения с помощью дерева } program qq; var Tree: PNode;
- 104. Дерево игры Задача. Перед двумя игроками лежат две кучки камней, в первой из которых 3, а
- 105. Дерево игры 3, 2 игрок 1 3, 6 27, 2 3, 18 3, 3 4, 2
- 106. Задания «4»: «Собрать» программу для вычисления правильного арифметического выражения, включающего только однозначные числа и знаки операций
- 107. Тема 7. Графы © К.Ю. Поляков, 2008-2010 Динамические структуры данных (язык Паскаль)
- 108. Определения Граф – это набор вершин (узлов) и соединяющих их ребер (дуг). Направленный граф (ориентированный, орграф)
- 109. Определения Связный граф – это граф, в котором существует цепь между каждой парой вершин. k-cвязный граф
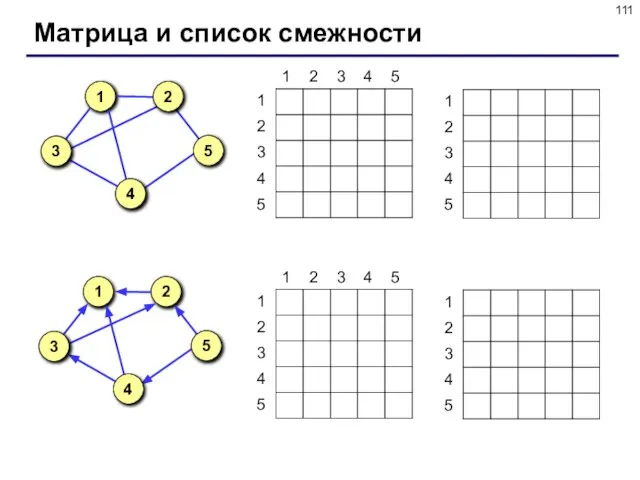
- 110. Описание графа Матрица смежности – это матрица, элемент M[i][j] которой равен 1, если существует ребро из
- 111. Матрица и список смежности
- 112. Построения графа по матрице смежности
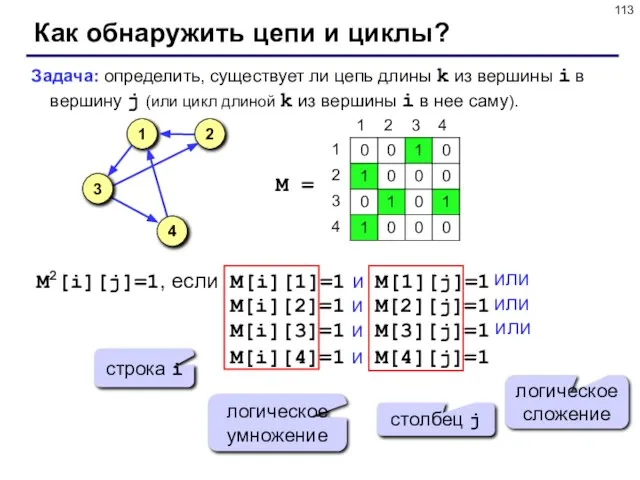
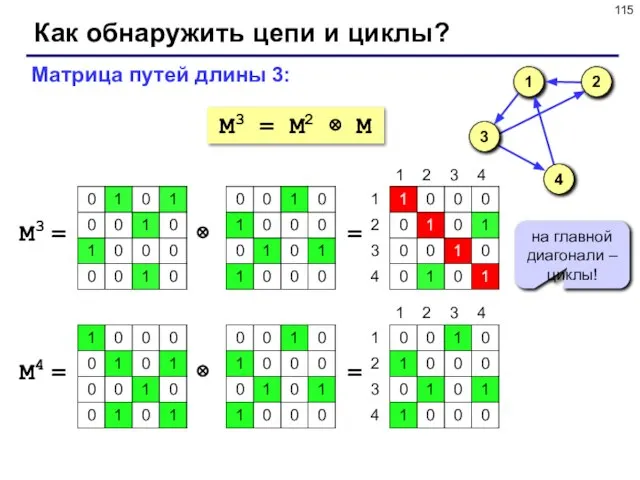
- 113. Как обнаружить цепи и циклы? Задача: определить, существует ли цепь длины k из вершины i в
- 114. Как обнаружить цепи и циклы? M2 = M ⊗ M Логическое умножение матрицы на себя: матрица
- 115. Как обнаружить цепи и циклы? M3 = M2 ⊗ M Матрица путей длины 3: M3 =
- 116. Весовая матрица Весовая матрица – это матрица, элемент W[i,j] которой равен весу ребра из вершины i
- 117. Задача Прима-Краскала Задача: соединить N городов телефонной сетью так, чтобы длина телефонных линий была минимальная. Та
- 118. Жадный алгоритм Жадный алгоритм – это многошаговый алгоритм, в котором на каждом шаге принимается решение, лучшее
- 119. Реализация алгоритма Прима-Краскала Проблема: как проверить, что 1) ребро не выбрано, и 2) ребро не образует
- 120. Реализация алгоритма Прима-Краскала Структура «ребро»: type rebro = record i, j: integer; { номера вершин }
- 121. Реализация алгоритма Прима-Краскала for k:=1 to N-1 do begin min := MaxInt; for i:=1 to N
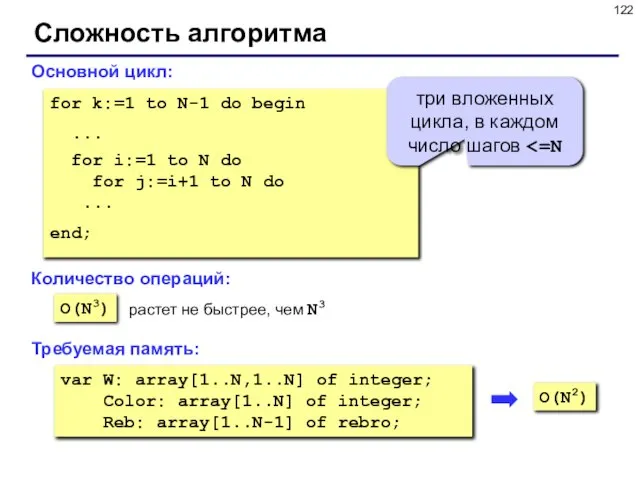
- 122. Сложность алгоритма Основной цикл: O(N3) for k:=1 to N-1 do begin ... for i:=1 to N
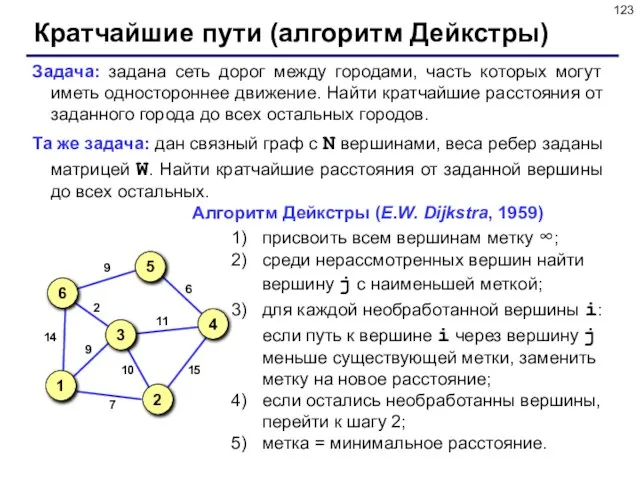
- 123. Кратчайшие пути (алгоритм Дейкстры) Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее движение.
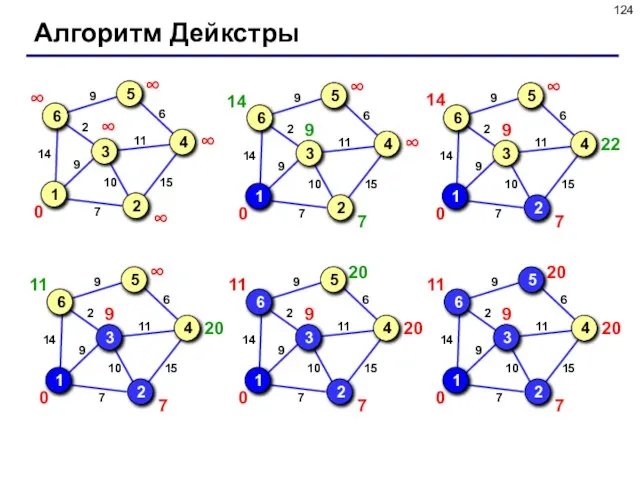
- 124. Алгоритм Дейкстры
- 125. Реализация алгоритма Дейкстры Массивы: массив a, такой что a[i]=1, если вершина уже рассмотрена, и a[i]=0, если
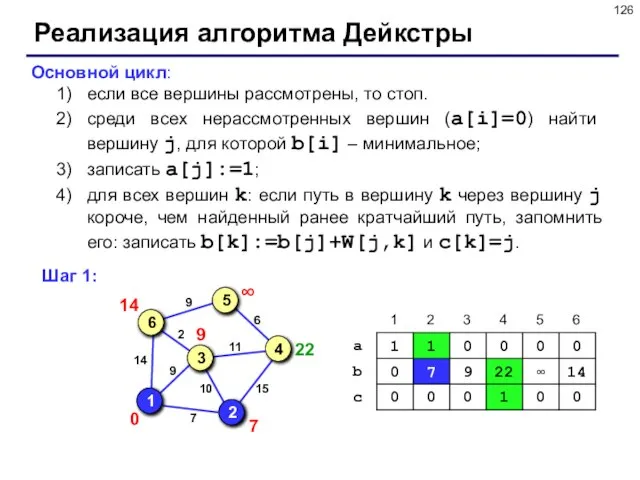
- 126. Реализация алгоритма Дейкстры Основной цикл: если все вершины рассмотрены, то стоп. среди всех нерассмотренных вершин (a[i]=0)
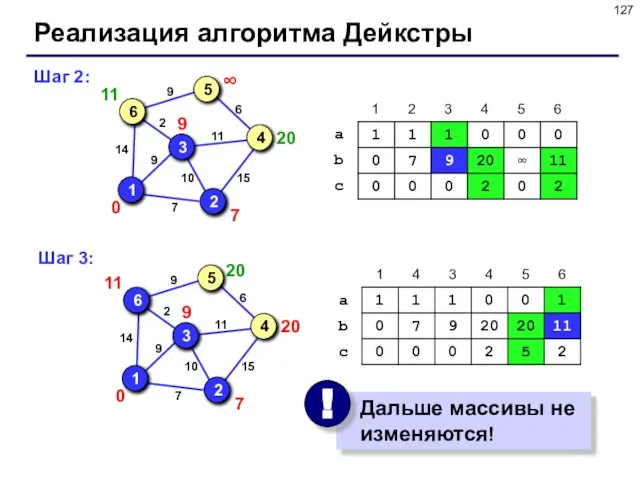
- 127. Реализация алгоритма Дейкстры Шаг 2: Шаг 3:
- 128. Как вывести маршрут? Результат работа алгоритма Дейкстры: длины путей Маршрут из вершины 0 в вершину 4:
- 129. Алгоритм Флойда-Уоршелла Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее движение. Найти все
- 130. Алгоритм Флойда-Уоршелла Версия с запоминанием маршрута: for i:= 1 to N for j := 1 to
- 131. Задача коммивояжера Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города и, посетив по разу
- 132. Другие классические задачи Задача на минимум суммы. Имеется N населенных пунктов, в каждом из которых живет
- 134. Скачать презентацию

Слайд 3Статические данные
переменная (массив) имеет имя, по которому к ней можно обращаться
размер
Статические данные
переменная (массив) имеет имя, по которому к ней можно обращаться
размер

Слайд 4Динамические данные
размер заранее неизвестен, определяется во время работы программы
память выделяется во время
Динамические данные
размер заранее неизвестен, определяется во время работы программы
память выделяется во время

Слайд 5Указатели
Указатель – это переменная, в которую можно записывать адрес другой переменной (или
Указатели
Указатель – это переменная, в которую можно записывать адрес другой переменной (или

Слайд 6Обращение к данным через указатель
program qq;
var m, n: integer;
pI: ^integer;
begin
m
Обращение к данным через указатель
program qq;
var m, n: integer;
pI: ^integer;
begin
m

Слайд 7Обращение к данным (массивы)
program qq;
var i: integer;
A: array[1..4] of integer;
pI:
Обращение к данным (массивы)
program qq;
var i: integer;
A: array[1..4] of integer;
pI:
![Обращение к данным (массивы) program qq; var i: integer; A: array[1..4] of](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-6.jpg)
Слайд 8Что надо знать об указателях
указатель – это переменная, в которой можно хранить
Что надо знать об указателях
указатель – это переменная, в которой можно хранить

Слайд 9Тема 2. Динамические массивы
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 2. Динамические массивы
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 10Где нужны динамические массивы?
Задача. Ввести размер массива, затем – элементы массива. Отсортировать
Где нужны динамические массивы?
Задача. Ввести размер массива, затем – элементы массива. Отсортировать

Слайд 11Использование указателей (Delphi)
program qq;
type intArray = array[1..1] of integer;
var A: ^intArray;
i,
Использование указателей (Delphi)
program qq;
type intArray = array[1..1] of integer;
var A: ^intArray;
i,
![Использование указателей (Delphi) program qq; type intArray = array[1..1] of integer; var](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-10.jpg)
Слайд 12Использование указателей
для выделения памяти используют процедуру GetMem
GetMem( указатель, размер в байтах
Использование указателей
для выделения памяти используют процедуру GetMem
GetMem( указатель, размер в байтах

Слайд 13Ошибки при работе с памятью
Запись в «чужую» область памяти:
память не была выделена,
Ошибки при работе с памятью
Запись в «чужую» область памяти:
память не была выделена,

Слайд 14Динамические массивы(Delphi)
program qq;
var A: array of integer;
i, N: integer;
begin
writeln('Размер массива>');
Динамические массивы(Delphi)
program qq;
var A: array of integer;
i, N: integer;
begin
writeln('Размер массива>');

Слайд 15Динамические массивы (Delphi)
при объявлении массива указывают только его тип, память не выделяется:
Динамические массивы (Delphi)
при объявлении массива указывают только его тип, память не выделяется:

Слайд 16Динамические матрицы (Delphi)
Задача. Ввести размеры матрицы и выделить для нее место в
Динамические матрицы (Delphi)
Задача. Ввести размеры матрицы и выделить для нее место в

Слайд 17Тема 3. Структуры (записи)
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 3. Структуры (записи)
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 18Структуры (в Паскале – записи)
Структура (запись) – это тип данных, который может
Структуры (в Паскале – записи)
Структура (запись) – это тип данных, который может

Слайд 19Одна запись
readln(Book.author); // ввод
readln(Book.title);
Book.year := 1998; // присваивание
if Book.pages > 200 then
Одна запись
readln(Book.author); // ввод
readln(Book.title);
Book.year := 1998; // присваивание
if Book.pages > 200 then

Слайд 20Массив записей
Объявление (выделение памяти):
const N = 10;
var aBooks: array[1..N] of record
Массив записей
Объявление (выделение памяти):
const N = 10;
var aBooks: array[1..N] of record
![Массив записей Объявление (выделение памяти): const N = 10; var aBooks: array[1..N]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-19.jpg)
Слайд 21Массив записей
for i:=1 to N do begin
readln(aBooks[i].author);
readln(aBooks[i].title);
...
end;
for
Массив записей
for i:=1 to N do begin
readln(aBooks[i].author);
readln(aBooks[i].title);
...
end;
for
![Массив записей for i:=1 to N do begin readln(aBooks[i].author); readln(aBooks[i].title); ... end;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-20.jpg)
Слайд 22Новый тип данных – запись
const N = 10;
var Book: TBook; // одна
Новый тип данных – запись
const N = 10;
var Book: TBook; // одна

Слайд 23Записи в процедурах и функциях
Book.author := 'А.С. Пушкин';
ShowAuthor ( Book );
Book.year :=
Записи в процедурах и функциях
Book.author := 'А.С. Пушкин';
ShowAuthor ( Book );
Book.year :=

Слайд 24Файлы записей
Объявление файловой переменной:
var F: file of TBook;
Assign(F, 'books.dat'); { связать с
Файлы записей
Объявление файловой переменной:
var F: file of TBook;
Assign(F, 'books.dat'); { связать с
Слайд 25Чтение из файла
Известное число записей:
Assign(F, 'books.dat'); { связать с указателем }
Reset(F); {
Чтение из файла
Известное число записей:
Assign(F, 'books.dat'); { связать с указателем }
Reset(F); {

Слайд 26Пример программы
Задача: в файле books.dat записаны данные о книгах в виде массива
Пример программы
Задача: в файле books.dat записаны данные о книгах в виде массива

Слайд 27Пример программы
Чтение «пока не кончатся»:
Assign(F, 'books.dat');
Reset(F);
N := 0;
while
Пример программы
Чтение «пока не кончатся»:
Assign(F, 'books.dat');
Reset(F);
N := 0;
while

Слайд 28Выделение памяти под запись
var pB: ^TBook;
begin
New(pB);
pB^.author := 'А.С. Пушкин';
pB^.title
Выделение памяти под запись
var pB: ^TBook;
begin
New(pB);
pB^.author := 'А.С. Пушкин';
pB^.title
Слайд 29Сортировка массива записей
Ключ (ключевое поле) – это поле записи (или комбинация полей),
Сортировка массива записей
Ключ (ключевое поле) – это поле записи (или комбинация полей),

Слайд 30Сортировка массива записей
for i:=1 to N-1 do
for j:=N-1 downto i do
Сортировка массива записей
for i:=1 to N-1 do
for j:=N-1 downto i do

Слайд 31Сортировка массива записей
Проблема:
как избежать копирования записи при сортировке?
Решение:
использовать вспомогательный массив
Сортировка массива записей
Проблема:
как избежать копирования записи при сортировке?
Решение:
использовать вспомогательный массив

Слайд 32Реализация в программе
type PBook = ^TBook; { новый тип данных }
var p:
Реализация в программе
type PBook = ^TBook; { новый тип данных }
var p:
Слайд 33Тема 4. Списки
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 4. Списки
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 34Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы структур:
списки
деревья
графы
односвязный
двунаправленный
Динамические структуры данных
Строение: набор узлов, объединенных с помощью ссылок.
Как устроен узел:
Типы структур:
списки
деревья
графы
односвязный
двунаправленный
Слайд 35Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать в
Когда нужны списки?
Задача (алфавитно-частотный словарь). В файле записан текст. Нужно записать в

Слайд 36Что такое список:
пустая структура – это список;
список – это начальный узел (голова)
Что такое список:
пустая структура – это список;
список – это начальный узел (голова)
Слайд 37Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
а) в начало списка;
б)
Что нужно уметь делать со списком?
Создать новый узел.
Добавить узел:
а) в начало списка;
б)

Слайд 38Создание узла
function CreateNode(NewWord: string): PNode;
var NewNode: PNode;
begin
New(NewNode);
NewNode^.word := NewWord;
NewNode^.count
Создание узла
function CreateNode(NewWord: string): PNode;
var NewNode: PNode;
begin
New(NewNode);
NewNode^.word := NewWord;
NewNode^.count

Слайд 39Добавление узла в начало списка
1) Установить ссылку нового узла на голову списка:
NewNode^.next
Добавление узла в начало списка
1) Установить ссылку нового узла на голову списка:
NewNode^.next
Слайд 40Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий за
Добавление узла после заданного
1) Установить ссылку нового узла на узел, следующий за
Слайд 41Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q на
Задача:
сделать что-нибудь хорошее с каждым элементом списка.
Алгоритм:
установить вспомогательный указатель q на
Слайд 42Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти последний
Добавление узла в конец списка
Задача: добавить новый узел в конец списка.
Алгоритм:
найти последний

Слайд 43Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти предыдущий
Проблема: нужно знать адрес предыдущего узла, а идти назад нельзя!
Решение: найти предыдущий
Слайд 44Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска предыдущего.
Алгоритм:
поменять
Добавление узла перед заданным (II)
Задача: вставить узел перед заданным без поиска предыдущего.
Алгоритм:
поменять
Слайд 45Поиск слова в списке
Задача:
найти в списке заданное слово или определить, что
Поиск слова в списке
Задача: найти в списке заданное слово или определить, что

Слайд 46Куда вставить новое слово?
Задача:
найти узел, перед которым нужно вставить, заданное слово,
Куда вставить новое слово?
Задача: найти узел, перед которым нужно вставить, заданное слово,

Слайд 47Удаление узла
procedure DeleteNode ( var Head: PNode; p: PNode );
var q: PNode;
begin
Удаление узла
procedure DeleteNode ( var Head: PNode; p: PNode );
var q: PNode;
begin
Слайд 48Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать очередное слово (как?)
если файл закончился, то перейти
Алфавитно-частотный словарь
Алгоритм:
открыть файл на чтение;
прочитать очередное слово (как?)
если файл закончился, то перейти

Слайд 49Как прочитать одно слово из файла?
function GetWord ( F: Text ) :
Как прочитать одно слово из файла?
function GetWord ( F: Text ) :

Слайд 50Полная программа
type PNode = ^Node;
Node = record ... end; { новые
Полная программа
type PNode = ^Node;
Node = record ... end; { новые

Слайд 51Полная программа (II)
{ читаем слова из файла, строим список }
while True do
Полная программа (II)
{ читаем слова из файла, строим список }
while True do

Слайд 52Полная программа (III)
{ выводим список в другой файл }
q := Head; {
Полная программа (III)
{ выводим список в другой файл }
q := Head; {

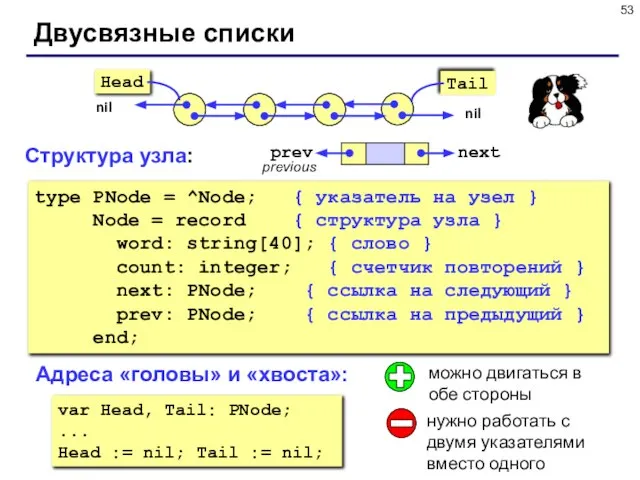
Слайд 53type PNode = ^Node; { указатель на узел }
Node =
type PNode = ^Node; { указатель на узел }
Node =
Слайд 54Задания
«4»: «Собрать» из этих функций программу для построения алфавитно-частотного словаря. В конце
Задания
«4»: «Собрать» из этих функций программу для построения алфавитно-частотного словаря. В конце

Слайд 55Тема 5. Стеки, очереди, деки
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 5. Стеки, очереди, деки
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 56Стек
Стек – это линейная структура данных, в которой добавление и удаление элементов
Стек
Стек – это линейная структура данных, в которой добавление и удаление элементов

Слайд 57Пример задачи
Задача: вводится символьная строка, в которой записано выражение со скобками трех
Пример задачи
Задача: вводится символьная строка, в которой записано выражение со скобками трех

Слайд 58Решение задачи со скобками
Алгоритм:
в начале стек пуст;
в цикле просматриваем все символы строки
Решение задачи со скобками
Алгоритм:
в начале стек пуст;
в цикле просматриваем все символы строки
Слайд 59Реализация стека (массив)
Структура-стек:
const MAXSIZE = 100;
type Stack = record { стек на
Реализация стека (массив)
Структура-стек:
const MAXSIZE = 100;
type Stack = record { стек на
Слайд 60Реализация стека (массив)
function Pop ( var S:Stack ): char;
begin
if S.size =
Реализация стека (массив)
function Pop ( var S:Stack ): char;
begin
if S.size =

Слайд 61Программа
var br1, br2, expr: string;
i, k: integer;
upper: char; { то,
Программа
var br1, br2, expr: string;
i, k: integer;
upper: char; { то,

Слайд 62Обработка строки (основной цикл)
for i:=1 to length(expr)
do begin
for
Обработка строки (основной цикл)
for i:=1 to length(expr)
do begin
for

Слайд 63Реализация стека (список)
Добавление элемента:
Структура узла:
type PNode = ^Node; { указатель на узел
Реализация стека (список)
Добавление элемента:
Структура узла:
type PNode = ^Node; { указатель на узел

Слайд 64Реализация стека (список)
Снятие элемента с вершины:
function Pop ( var Head: PNode ):
Реализация стека (список)
Снятие элемента с вершины:
function Pop ( var Head: PNode ):

Слайд 65Реализация стека (список)
Изменения в основной программе:
var S: Stack;
...
S.size := 0;
var S: PNode;
S
Реализация стека (список)
Изменения в основной программе:
var S: Stack;
...
S.size := 0;
var S: PNode;
S

Слайд 66Вычисление арифметических выражений
a b + c d + 1 - /
Как вычислять
Вычисление арифметических выражений
a b + c d + 1 - /
Как вычислять

Слайд 67Запишите в постфиксной форме
(32*6-5)*(2*3+4)/(3+7*2)
(2*4+3*5)*(2*3+18/3*2)*(12-3)
(4-2*3)*(3-12/3/4)*(24-3*12)
Запишите в постфиксной форме
(32*6-5)*(2*3+4)/(3+7*2)
(2*4+3*5)*(2*3+18/3*2)*(12-3)
(4-2*3)*(3-12/3/4)*(24-3*12)
Слайд 68Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Алгоритм:
взять
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Алгоритм:
взять
Слайд 69Системный стек (Windows – 1 Мб)
Используется для
размещения локальных переменных;
хранения адресов возврата
Системный стек (Windows – 1 Мб)
Используется для
размещения локальных переменных;
хранения адресов возврата

Слайд 70Очередь
Очередь – это линейная структура данных, в которой
добавление элементов возможно только
Очередь
Очередь – это линейная структура данных, в которой добавление элементов возможно только

Слайд 71Реализация очереди (массив)
самый простой способ
нужно заранее выделить массив;
при выборке из очереди нужно
Реализация очереди (массив)
самый простой способ
нужно заранее выделить массив;
при выборке из очереди нужно
Слайд 72Реализация очереди (кольцевой массив)
Реализация очереди (кольцевой массив)
Слайд 73Реализация очереди (кольцевой массив)
В очереди 1 элемент:
Очередь пуста:
Очередь полна:
Head = Tail +
Реализация очереди (кольцевой массив)
В очереди 1 элемент:
Очередь пуста:
Очередь полна:
Head = Tail +
Слайд 74Реализация очереди (кольцевой массив)
type Queue = record
data: array[1..MAXSIZE] of integer;
head,
Реализация очереди (кольцевой массив)
type Queue = record
data: array[1..MAXSIZE] of integer;
head,
![Реализация очереди (кольцевой массив) type Queue = record data: array[1..MAXSIZE] of integer;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-73.jpg)
Слайд 75Реализация очереди (кольцевой массив)
Выборка из очереди:
function Pop ( var S: Queue ):
Реализация очереди (кольцевой массив)
Выборка из очереди:
function Pop ( var S: Queue ):
Слайд 76Реализация очереди (списки)
type PNode = ^Node;
Node = record
data: integer;
next:
Реализация очереди (списки)
type PNode = ^Node;
Node = record
data: integer;
next:

Слайд 77Реализация очереди (списки)
procedure PushTail( var Q: Queue; x: integer );
var NewNode: PNode;
begin
Реализация очереди (списки)
procedure PushTail( var Q: Queue; x: integer );
var NewNode: PNode;
begin

Слайд 78Реализация очереди (списки)
function Pop ( var S: Queue ): integer;
var top: PNode;
begin
Реализация очереди (списки)
function Pop ( var S: Queue ): integer;
var top: PNode;
begin
Слайд 79Дек
Дек (deque = double ended queue, очередь с двумя концами) – это
Дек
Дек (deque = double ended queue, очередь с двумя концами) – это

Слайд 80Задания
«4»: В файле input.dat находится список чисел (или слов). Переписать его в
Задания
«4»: В файле input.dat находится список чисел (или слов). Переписать его в

Слайд 81Тема 6. Деревья
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 6. Деревья
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 82Деревья
Деревья
Слайд 83Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их направленных
Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их направленных
Слайд 84Деревья
Предок узла x – это узел, из которого существует путь по стрелкам
Деревья
Предок узла x – это узел, из которого существует путь по стрелкам

Слайд 85Дерево – рекурсивная структура данных
Рекурсивное определение:
Пустая структура – это дерево.
Дерево – это
Дерево – рекурсивная структура данных
Рекурсивное определение:
Пустая структура – это дерево.
Дерево – это

Слайд 86Двоичные деревья
Структура узла:
type PNode = ^Node; { указатель на узел }
Двоичные деревья
Структура узла:
type PNode = ^Node; { указатель на узел }

Слайд 87Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами, а
Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами, а
Слайд 88Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1 элемент.
Число
Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1 элемент.
Число
Слайд 89Реализация алгоритма поиска
{ Функция Search – поиск по дереву
Вход: Tree -
Реализация алгоритма поиска
{ Функция Search – поиск по дереву
Вход: Tree -

Слайд 90Как построить дерево поиска?
{ Процедура AddToTree – добавить элемент
Вход: Tree -
Как построить дерево поиска?
{ Процедура AddToTree – добавить элемент
Вход: Tree -

Слайд 91Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход ЛКП
Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход ЛКП
Слайд 92Обход дерева – реализация
{ Процедура LKP – обход дерева в порядке ЛКП
Обход дерева – реализация
{ Процедура LKP – обход дерева в порядке ЛКП

Слайд 93Разбор арифметических выражений
a b + c d + 1 - /
Как вычислять
Разбор арифметических выражений
a b + c d + 1 - /
Как вычислять
Слайд 94Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Алгоритм:
взять
Вычисление выражений
Постфиксная форма:
a b + c d + 1 - /
Алгоритм:
взять
Слайд 95Вычисление выражений
Задача: в символьной строке записано правильное арифметическое выражение, которое может содержать
Вычисление выражений
Задача: в символьной строке записано правильное арифметическое выражение, которое может содержать

Слайд 96Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый узел
Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый узел
Слайд 97Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство) –
Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство) –

Слайд 98Приоритет операции
{ Функция Priority – приоритет операции
Вход: символ операции
Выход: приоритет
Приоритет операции
{ Функция Priority – приоритет операции
Вход: символ операции
Выход: приоритет

Слайд 99Номер последней операции
{ Функция LastOperation – номер последней операции
Вход: строка, номера
Номер последней операции
{ Функция LastOperation – номер последней операции
Вход: строка, номера

Слайд 100Построение дерева
Структура узла
type PNode = ^Node;
Node = record
data: char;
left,
Построение дерева
Структура узла
type PNode = ^Node;
Node = record
data: char;
left,

Слайд 101Построение дерева
{ Функция MakeTree – построение дерева
Вход: строка, номера первого и
Построение дерева
{ Функция MakeTree – построение дерева
Вход: строка, номера первого и

Слайд 102Вычисление выражения по дереву
{ Функция CalcTree – вычисление по дереву
Вход: адрес
Вычисление выражения по дереву
{ Функция CalcTree – вычисление по дереву
Вход: адрес

Слайд 103Основная программа
{ Ввод и вычисление выражения с помощью дерева }
program qq;
var Tree:
Основная программа
{ Ввод и вычисление выражения с помощью дерева }
program qq;
var Tree:

Слайд 104Дерево игры
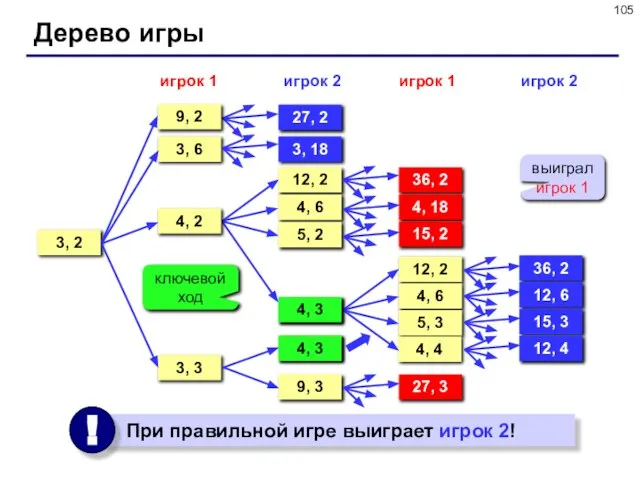
Задача.
Перед двумя игроками лежат две кучки камней, в первой из
Дерево игры
Задача. Перед двумя игроками лежат две кучки камней, в первой из

Слайд 105Дерево игры
3, 2
игрок 1
3, 6
27, 2
3, 18
3, 3
4, 2
12, 2
4, 6
5, 2
4,
Дерево игры
3, 2
игрок 1
3, 6
27, 2
3, 18
3, 3
4, 2
12, 2
4, 6
5, 2
4,
Слайд 106Задания
«4»: «Собрать» программу для вычисления правильного арифметического выражения, включающего только однозначные числа
Задания
«4»: «Собрать» программу для вычисления правильного арифметического выражения, включающего только однозначные числа

Слайд 107Тема 7. Графы
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)
Тема 7. Графы
© К.Ю. Поляков, 2008-2010
Динамические структуры данных
(язык Паскаль)

Слайд 108Определения
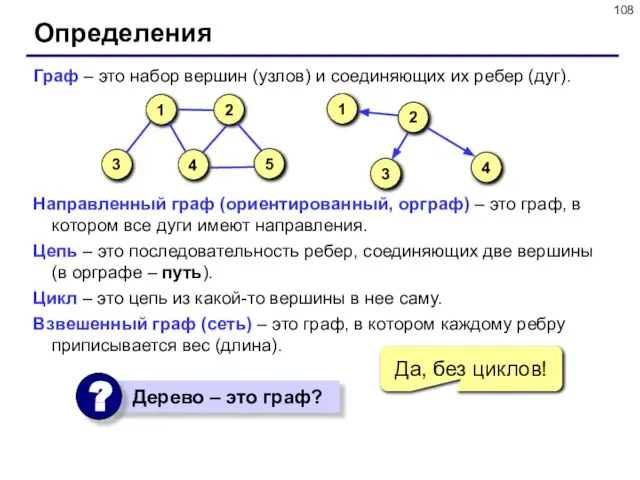
Граф – это набор вершин (узлов) и соединяющих их ребер (дуг).
Направленный граф
Определения
Граф – это набор вершин (узлов) и соединяющих их ребер (дуг).
Направленный граф
Слайд 109Определения
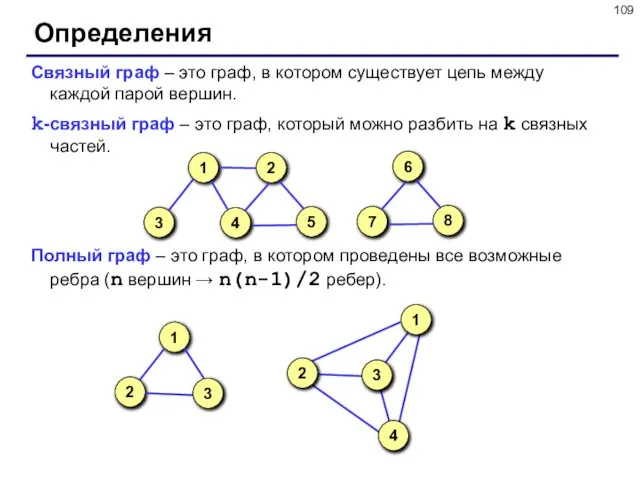
Связный граф – это граф, в котором существует цепь между каждой парой
Определения
Связный граф – это граф, в котором существует цепь между каждой парой
Слайд 110Описание графа
Матрица смежности – это матрица, элемент M[i][j] которой равен 1, если
Описание графа
Матрица смежности – это матрица, элемент M[i][j] которой равен 1, если
![Описание графа Матрица смежности – это матрица, элемент M[i][j] которой равен 1,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-109.jpg)
Слайд 111Матрица и список смежности
Матрица и список смежности
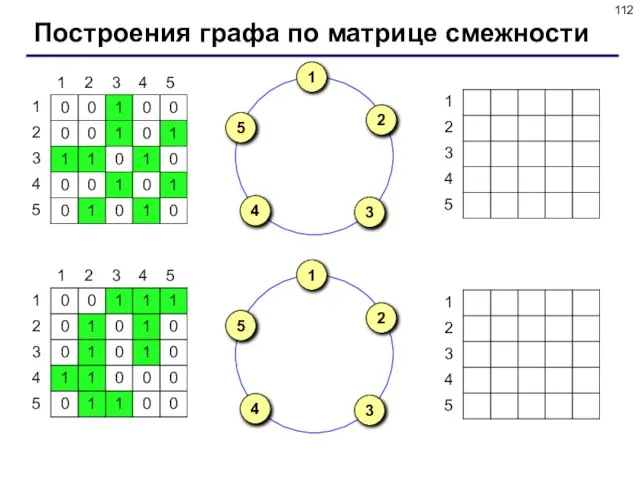
Слайд 112Построения графа по матрице смежности
Построения графа по матрице смежности
Слайд 113Как обнаружить цепи и циклы?
Задача: определить, существует ли цепь длины k из
Как обнаружить цепи и циклы?
Задача: определить, существует ли цепь длины k из
Слайд 114Как обнаружить цепи и циклы?
M2 = M ⊗ M
Логическое умножение матрицы на
Как обнаружить цепи и циклы?
M2 = M ⊗ M
Логическое умножение матрицы на
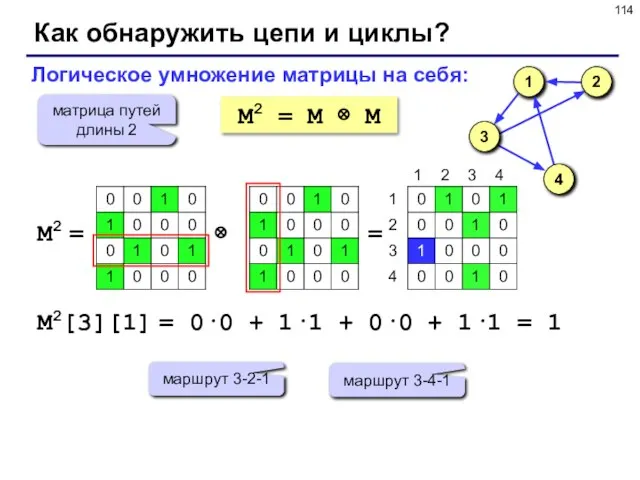
Слайд 115Как обнаружить цепи и циклы?
M3 = M2 ⊗ M
Матрица путей длины 3:
M3
Как обнаружить цепи и циклы?
M3 = M2 ⊗ M
Матрица путей длины 3:
M3
Слайд 116Весовая матрица
Весовая матрица – это матрица, элемент W[i,j] которой равен весу ребра
Весовая матрица
Весовая матрица – это матрица, элемент W[i,j] которой равен весу ребра
![Весовая матрица Весовая матрица – это матрица, элемент W[i,j] которой равен весу](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-115.jpg)
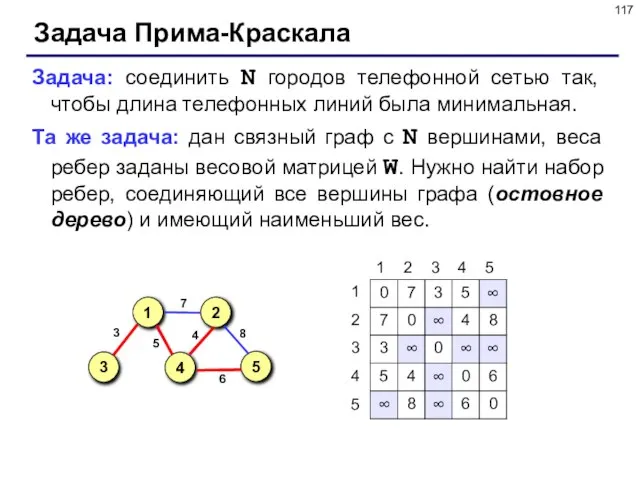
Слайд 117Задача Прима-Краскала
Задача: соединить N городов телефонной сетью так, чтобы длина телефонных линий
Задача Прима-Краскала
Задача: соединить N городов телефонной сетью так, чтобы длина телефонных линий
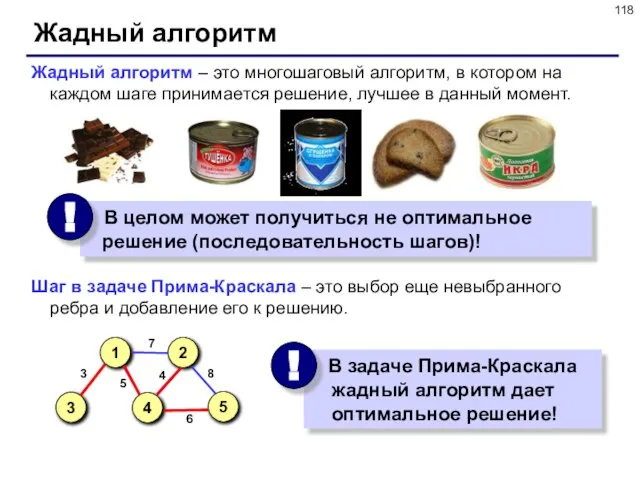
Слайд 118Жадный алгоритм
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом шаге
Жадный алгоритм
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом шаге
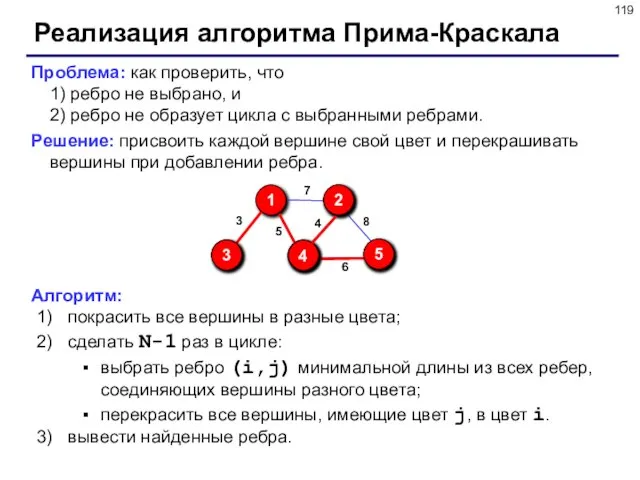
Слайд 119Реализация алгоритма Прима-Краскала
Проблема: как проверить, что
1) ребро не выбрано, и
2)
Реализация алгоритма Прима-Краскала
Проблема: как проверить, что 1) ребро не выбрано, и 2)
Слайд 120Реализация алгоритма Прима-Краскала
Структура «ребро»:
type rebro = record
i, j: integer; { номера
Реализация алгоритма Прима-Краскала
Структура «ребро»:
type rebro = record
i, j: integer; { номера

Слайд 121Реализация алгоритма Прима-Краскала
for k:=1 to N-1 do begin
min := MaxInt;
for
Реализация алгоритма Прима-Краскала
for k:=1 to N-1 do begin
min := MaxInt;
for

Слайд 122Сложность алгоритма
Основной цикл:
O(N3)
for k:=1 to N-1 do begin
...
for i:=1
Сложность алгоритма
Основной цикл:
O(N3)
for k:=1 to N-1 do begin
...
for i:=1
Слайд 123Кратчайшие пути (алгоритм Дейкстры)
Задача: задана сеть дорог между городами, часть которых могут
Кратчайшие пути (алгоритм Дейкстры)
Задача: задана сеть дорог между городами, часть которых могут
Слайд 124Алгоритм Дейкстры
Алгоритм Дейкстры
Слайд 125Реализация алгоритма Дейкстры
Массивы:
массив a, такой что a[i]=1, если вершина уже рассмотрена, и
Реализация алгоритма Дейкстры
Массивы:
массив a, такой что a[i]=1, если вершина уже рассмотрена, и
![Реализация алгоритма Дейкстры Массивы: массив a, такой что a[i]=1, если вершина уже](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/896123/slide-124.jpg)
Слайд 126Реализация алгоритма Дейкстры
Основной цикл:
если все вершины рассмотрены, то стоп.
среди всех нерассмотренных вершин
Реализация алгоритма Дейкстры
Основной цикл:
если все вершины рассмотрены, то стоп.
среди всех нерассмотренных вершин
Слайд 127Реализация алгоритма Дейкстры
Шаг 2:
Шаг 3:
Реализация алгоритма Дейкстры
Шаг 2:
Шаг 3:
Слайд 128Как вывести маршрут?
Результат работа алгоритма Дейкстры:
длины путей
Маршрут из вершины 0 в вершину
Как вывести маршрут?
Результат работа алгоритма Дейкстры:
длины путей
Маршрут из вершины 0 в вершину

Слайд 129Алгоритм Флойда-Уоршелла
Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее
Алгоритм Флойда-Уоршелла
Задача: задана сеть дорог между городами, часть которых могут иметь одностороннее

Слайд 130Алгоритм Флойда-Уоршелла
Версия с запоминанием маршрута:
for i:= 1 to N
for j :=
Алгоритм Флойда-Уоршелла
Версия с запоминанием маршрута:
for i:= 1 to N
for j :=

Слайд 131Задача коммивояжера
Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города и,
Задача коммивояжера
Задача коммивояжера. Коммивояжер (бродячий торговец) должен выйти из первого города и,

Слайд 132Другие классические задачи
Задача на минимум суммы. Имеется N населенных пунктов, в каждом
Другие классические задачи
Задача на минимум суммы. Имеется N населенных пунктов, в каждом

 Характеристика алгоритмической сложности. Понятие и свойства алгоритмической сложности
Характеристика алгоритмической сложности. Понятие и свойства алгоритмической сложности Shox International Hospital. Международная больница Шокс
Shox International Hospital. Международная больница Шокс Системы счисления
Системы счисления Презентация на тему SUBD ACCESS
Презентация на тему SUBD ACCESS  Организация работы с документацией. Лабораторная работа
Организация работы с документацией. Лабораторная работа Оценка эффективности информационной системы
Оценка эффективности информационной системы Реализация бота для взаимосдействия с сайтом
Реализация бота для взаимосдействия с сайтом Цифровая платформа Van & Gog. Цифровая платформаприложение
Цифровая платформа Van & Gog. Цифровая платформаприложение БАРС. Web-образование
БАРС. Web-образование Знакомство с файловой системой
Знакомство с файловой системой Easytrading. Poloniex trade bot. Реферальная система
Easytrading. Poloniex trade bot. Реферальная система Jeeeni cldna
Jeeeni cldna Системы счисления. Математические основы информатики
Системы счисления. Математические основы информатики тестирование смэв 2022
тестирование смэв 2022 Системы счисления
Системы счисления Презентация на тему Архивация данных
Презентация на тему Архивация данных  ВКР: Математическое и программное обеспечение для исследования простых эвристик при решении задач линейного раскроя
ВКР: Математическое и программное обеспечение для исследования простых эвристик при решении задач линейного раскроя Графическая информация. Виды, сходства, различия
Графическая информация. Виды, сходства, различия Информационное моделирование на компьютере
Информационное моделирование на компьютере Компьютерная инди-игра в жанре песочницы Minecraft
Компьютерная инди-игра в жанре песочницы Minecraft Основные объекты Access. Назначения и возможности
Основные объекты Access. Назначения и возможности Типы данных. Переменные в С#
Типы данных. Переменные в С# Программное обеспечение: Уровни и классификация
Программное обеспечение: Уровни и классификация Современные возможности планшета в автомобиле
Современные возможности планшета в автомобиле Стандарты защиты
Стандарты защиты Итоги конкурса по сторителлингу Информатика в тренде
Итоги конкурса по сторителлингу Информатика в тренде Социальные медиа
Социальные медиа Форматирование текста. Задания
Форматирование текста. Задания