Слайд 2Алфавитный (объёмный) подход к измерению информации
Алфавитный (объёмный) подход к измерению информации позволяет

определить количество информации, заключенной в тексте, записанном с помощью некоторого алфавита.
Алфавит – множество используемых символов в языке.
Обычно под алфавитом понимают не только буквы, но и цифры, знаки препинания и пробел.
Мощность алфавита (N) – количество символов, используемых в алфавите.
Например, мощность алфавита из русских букв равна 32 (буква ё обычно не используется).
Если допустить, что все символы алфавита встречаются в тексте с одинаковой частотой (равновероятно), то количество информации, которое несет каждый символ, вычисляется по формуле Хартли: i=log2N
Слайд 3N– мощность алфавита. Задает связь между количеством возможных событий N и количеством

информации: N=2^i
Из базового курса информатики известно, что в компьютерах используется двоичное кодирование информации. Для двоичного представления текстов в компьютере чаще всего используется равномерный восьмиразрядный код. С его помощью можно закодировать алфавит из 256 символов, поскольку 256=28.
В стандартную кодовую таблицу (например, ASCII) помещаются все необходимые символы: английские и русские прописные и строчные буквы, цифры, знаки препинания, знаки арифметических операций, всевозможные скобки и пр.
В двоичном коде один двоичный разряд несет одну единицу информации, которая называется 1 бит.
Например, в 2-символьном алфавите каждый символ «весит» 1 бит (log22=1); в 4-символьном алфавите каждый символ несет 2 бита информации (log2=2); в 8-символьном – 3 бита (log28=3) и т. д.
Один символ из алфавита мощностью 256 ( 28) несет в тексте 8 битов информации. Такое количество информации называется байтом.
1 байт =8 битов
Информационный объем текста в памяти компьютера измеряется в байтах. Он равен количеству знаков в записи текста.
Слайд 5Единицы измерения количества информации, в названии которых есть приставки «кило», «мега» и

т. д., с точки зрения теории измерений не являются корректными, поскольку эти приставки используются в метрической системе мер, в которой в качестве множителей кратных единиц используется коэффициент
10, где n=3,6,9 и т. д.
Для устранения этой некорректности Международная электротехническая комиссия, занимающаяся созданием стандартов для отрасли электронных технологий, утвердила ряд новых приставок для единиц измерения количества информации: киби (kibi), меби (mebi), гиби (gibi), теби (tebi), пети (peti), эксби (exbi). Однако пока используются старые обозначения единиц измерения количества информации, и требуется время, чтобы новые названия начали широко применяться.
Слайд 6Название «байт» было придумано в 1956 году В. Бухгольцем при проектировании первого

суперкомпьютера. Слово «byte» было получено путем замены второй буквы в созвучном слове «bite», чтобы избежать путаницы с уже имеющимся термином «bit».
Слайд 7Последовательность действий при переводе одних единиц измерения информации в другие приведена на
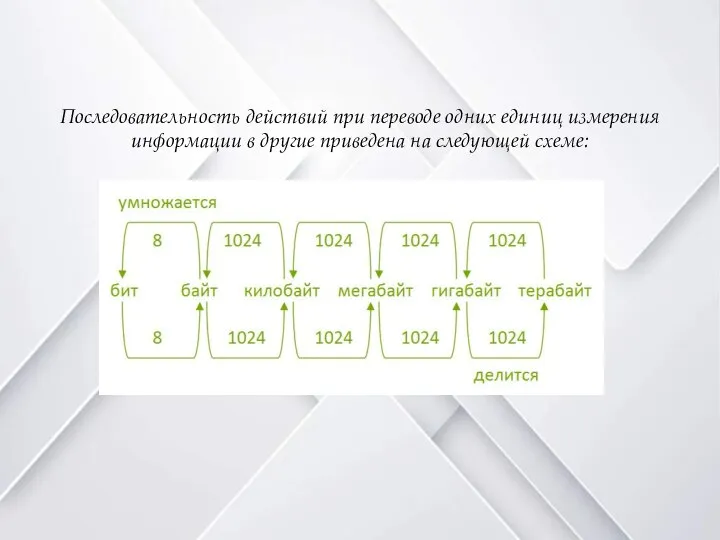
следующей схеме:
Слайд 8Если весь текст состоит из K символов, то при алфавитном подходе объём

V содержащейся в нем информации равен:
V=K⋅i
где i – информационный вес одного символа в используемом алфавите.
Зная, что i=log2N, данную выше формулу можно представить в другом виде:
если количество символов алфавита равно N, а количество символов в записи сообщения – K, то информационный объем V данного сообщения вычисляется по формуле:
V=K⋅log2N
При алфавитном подходе к измерению информации информационный объем текста зависит только от размера текста и от мощности алфавита, а не от содержания. Поэтому нельзя сравнивать информационные объемы текстов, написанных на разных языках, по размеру текста.
Пример:
1. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения: Белеет Парус Одинокий В Тумане Моря Голубом!
Решение.
Так как в предложении 44 символа (считая знаки препинания и пробелы), то информационный объем вычисляется по формуле:
V=44⋅1 байт=44 байта=44⋅8 бит=352 бита
2. Объем сообщения равен 11 Кбайт. Сообщение содержит 11264 символа. Какова мощность алфавита?
Решение.
Выясним, какое количество бит выделено на 1 символ. Для этого переведем объем сообщения в биты:
11 Кбайт=11⋅210 байт=11⋅210⋅23 бит=11⋅213 бит и разделим его на число символов.
На 1 символ приходится: (11⋅213)/11264=(11⋅213)/(11⋅210)=23=8 бит.
Мощность алфавита определяем из формулы Хартли: N=28=256 символов.


 Данные. Модели данных
Данные. Модели данных GRandapp. Смартфон - это просто
GRandapp. Смартфон - это просто Странствие. Игра платформер-лабиринт с элементами квеста
Странствие. Игра платформер-лабиринт с элементами квеста База данных с характеристиками электросетевых объектов
База данных с характеристиками электросетевых объектов Компьютер и его устройство
Компьютер и его устройство Компьютерные презентации. Настройка гиперссылки
Компьютерные презентации. Настройка гиперссылки Измерение информации
Измерение информации Организация ввода-вывода информации в БД. Лекция 7
Организация ввода-вывода информации в БД. Лекция 7 Требования к интернет-системам
Требования к интернет-системам Безопасность детей в Интернете
Безопасность детей в Интернете Центральный процессор
Центральный процессор Оптимизация Photoshop
Оптимизация Photoshop Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование Информационная система федерального института промышленной собственности РФ
Информационная система федерального института промышленной собственности РФ Обработка ошибок
Обработка ошибок Магия и боль ML. Машинное обучение
Магия и боль ML. Машинное обучение 7-1-5
7-1-5 Математические основы информатики. Единицы представления информации. (Тема 3)
Математические основы информатики. Единицы представления информации. (Тема 3) Электронный чек-лист. Способ оценивания
Электронный чек-лист. Способ оценивания Переменные. Сложение чисел: простое решение. 10 класс
Переменные. Сложение чисел: простое решение. 10 класс Scratch. Практическая работа Правильные многоугольники
Scratch. Практическая работа Правильные многоугольники Виды информации
Виды информации Введение в информатику Вещественно-энергетическая картина мира
Введение в информатику Вещественно-энергетическая картина мира Система типов C#
Система типов C# Lecture_02_Python
Lecture_02_Python Программирование. Введение (
Программирование. Введение ( Презентация на тему Разветвляющийся алгоритм
Презентация на тему Разветвляющийся алгоритм  Dota 2
Dota 2