- Информация и алфавит

Содержание
- 3. Таблица для средних частот букв русского алфавита
- 5. Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называют шенноновскими, а порождающий
- 7. Понятие о кодировании. Коды. Кодирование символьной информации Теория кодирования информации является одним из разделов теоретической информатики.
- 9. Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без
- 10. Другим примером кодирования может служить двоичное представление чисел: Двоичный код
- 11. Представление кода в виде геометрической модели Представление кода в виде геометрической модели возможно благодаря тому, что
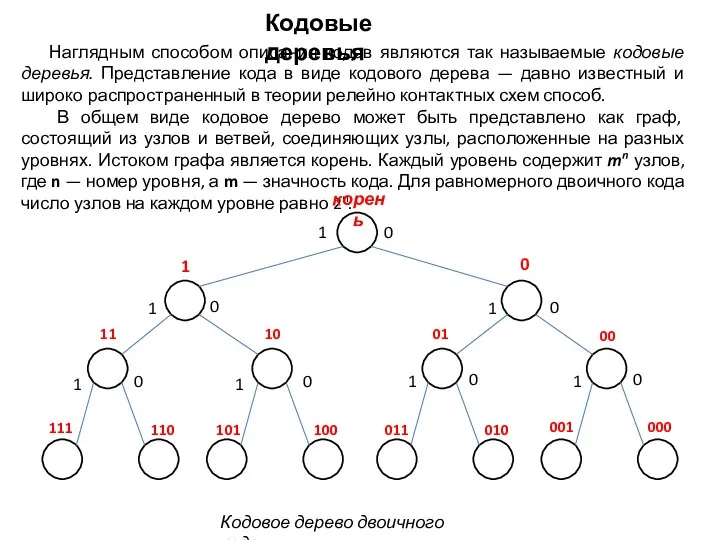
- 12. Наглядным способом описания кодов являются так называемые кодовые деревья. Представление кода в виде кодового дерева —
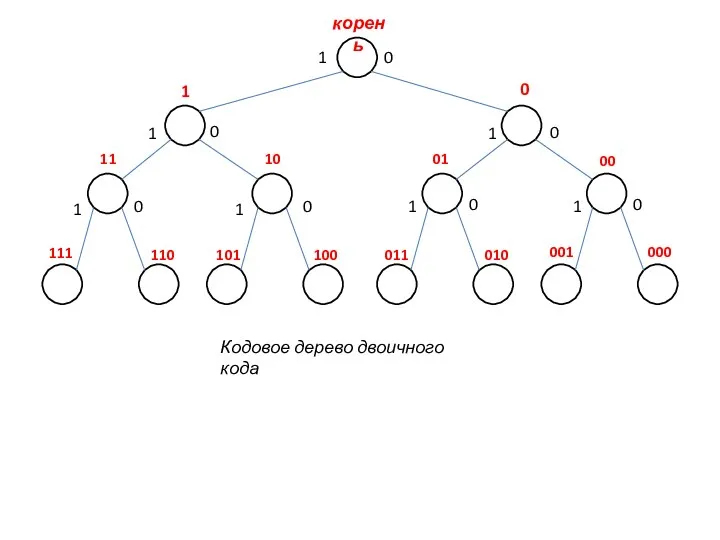
- 13. При помощи кодовых деревьев наглядно представляются коды, обладающие свойством префикса, или префиксные коды, т. е. коды,
- 14. Префиксом данной кодовой комбинации Аi является любая последовательность, составленная из ее начальной части, включая саму комбинацию
- 15. корень 1 0 1 0 1 1 1 1 1 1 0 0 0 0 0
- 16. Математическая постановка задачи кодирования Пусть первичный алфавит A содержит N знаков со средней информацией на знак,
- 17. Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех,
- 18. М=2 При отсутствии помех средняя длина двоичного кода может быть сколь угодно близкой к средней информации,
- 19. Возможны следующие особенности вторичного алфавита: Элементарные сигналы (0 и 1) могут иметь одинаковые или разные длительности.
- 20. Алфавитное неравномерное двоичное кодирование сигналами равной длительности построить такую систему кодирования, чтобы суммарная длительность кодов при
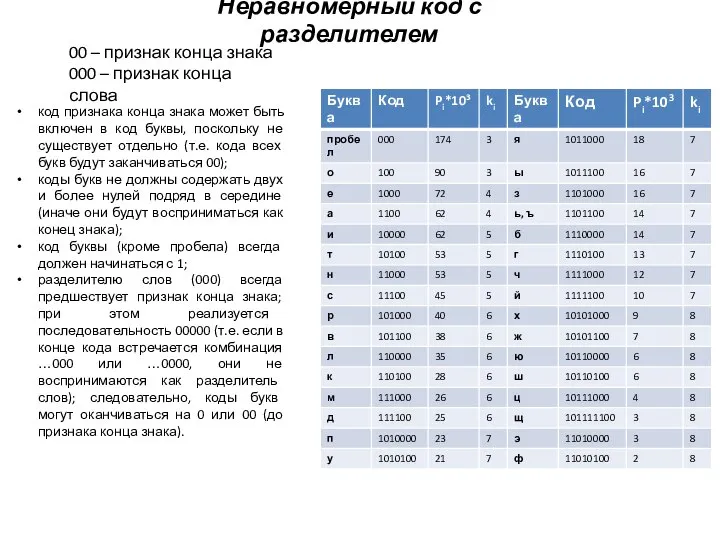
- 21. Неравномерный код с разделителем 00 – признак конца знака 000 – признак конца слова код признака
- 22. Поскольку для русского языка, I1(r)=4,356 бит, избыточность данного кода, согласно, составляет: Q(r) = 4,356/4,964 - 1
- 23. Оптимальное кодирование. Префиксные коды Оптимальным кодированием называется процедура преобразования символов первичного алфавита т: в кодовые слова
- 24. Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом (префиксом) какого-либо
- 25. а л м р у ы 10 010 00 11 0110 0111 Пример 00100010000111010101110000110 Отрезать от
- 26. Построение оптимального кода по методу Шеннона — Фано для сообщений сводится к следующей процедуре: множество из
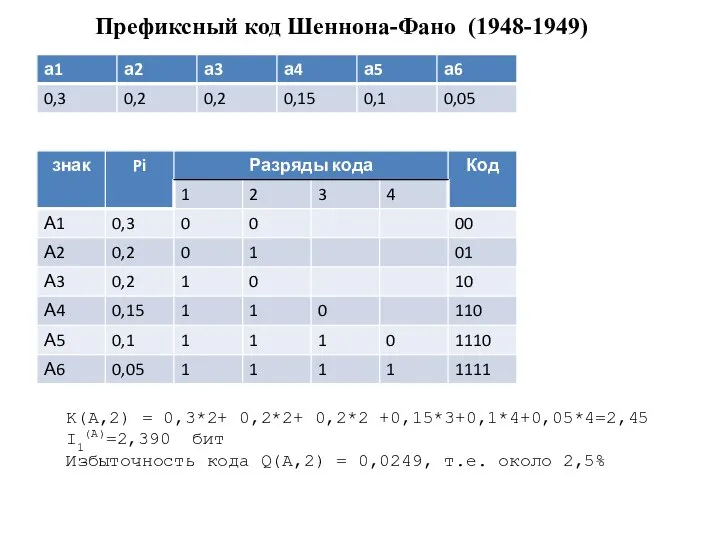
- 27. Префиксный код Шеннона-Фано (1948-1949) K(A,2) = 0,3*2+ 0,2*2+ 0,2*2 +0,15*3+0,1*4+0,05*4=2,45 I1(A)=2,390 бит Избыточность кода Q(A,2) =
- 28. Префиксный код Хаффмана Пример тот же. Алгоритм: Создадим новый вспомогательный алфавит A1, объединив два знака с
- 29. Прямой ход: Обратный ход:
- 30. Средняя длина кода оказывается равной K(2) = 4,395; избыточность кода Q(r) = 0,00887, т.е. менее 1%.
- 31. Код Хемминга. Построение дерева алфавитов
- 32. Код Хемминга. Обратный ход
- 33. Равномерное алфавитное двоичное кодирование. Байтовый код В этом случае двоичный код первичного алфавита строится цепочками равной
- 35. Скачать презентацию

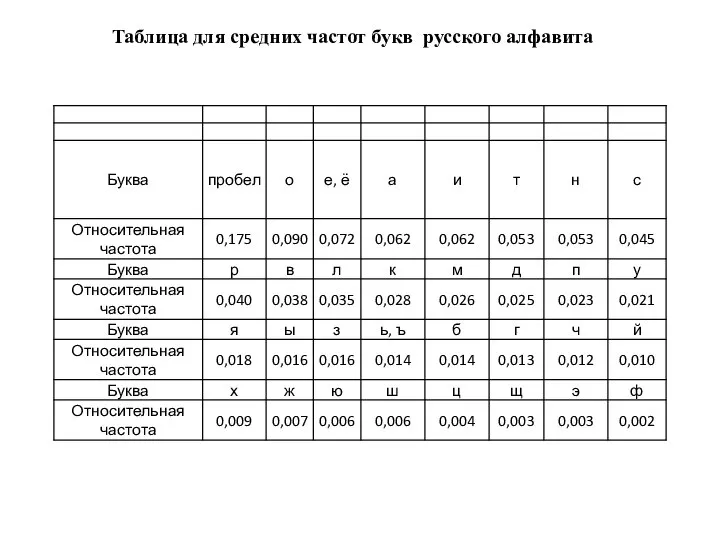
Слайд 3Таблица для средних частот букв русского алфавита
Таблица для средних частот букв русского алфавита
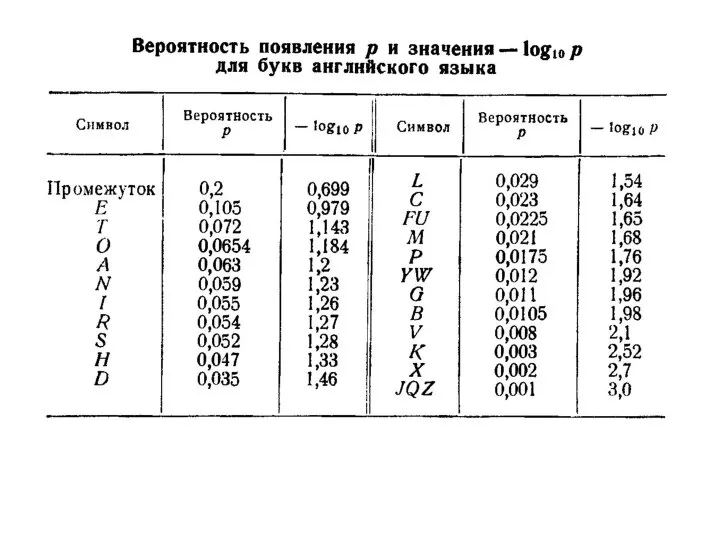
Слайд 5Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем,
Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем,


Слайд 7Понятие о кодировании. Коды.
Кодирование символьной информации
Теория кодирования информации является одним из
Понятие о кодировании. Коды.
Кодирование символьной информации
Теория кодирования информации является одним из


Слайд 9
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат

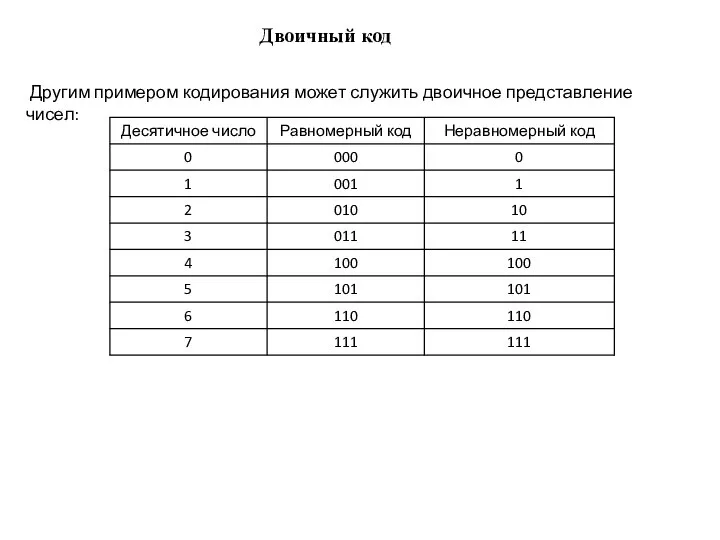
Слайд 10 Другим примером кодирования может служить двоичное представление чисел:
Двоичный код
Другим примером кодирования может служить двоичное представление чисел:
Двоичный код
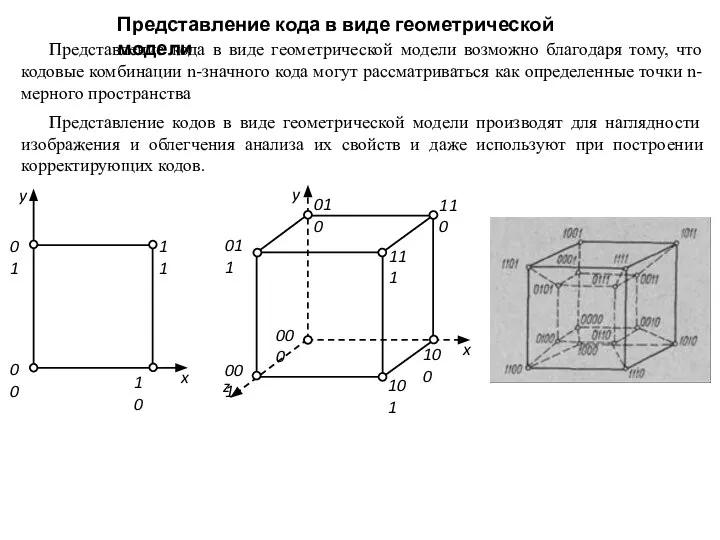
Слайд 11Представление кода в виде геометрической модели
Представление кода в виде геометрической модели возможно
Представление кода в виде геометрической модели
Представление кода в виде геометрической модели возможно
Слайд 12Наглядным способом описания кодов являются так называемые кодовые деревья. Представление кода в
Наглядным способом описания кодов являются так называемые кодовые деревья. Представление кода в
Слайд 13При помощи кодовых деревьев наглядно представляются коды, обладающие свойством префикса, или префиксные
При помощи кодовых деревьев наглядно представляются коды, обладающие свойством префикса, или префиксные

Слайд 14Префиксом данной кодовой комбинации Аi является любая последовательность, составленная из ее начальной
Префиксом данной кодовой комбинации Аi является любая последовательность, составленная из ее начальной

Слайд 15корень
1
0
1
0
1
1
1
1
1
1
0
0
0
0
0
0
11
10
01
00
111
110
101
100
011
010
001
000
Кодовое дерево двоичного кода
корень
1
0
1
0
1
1
1
1
1
1
0
0
0
0
0
0
11
10
01
00
111
110
101
100
011
010
001
000
Кодовое дерево двоичного кода
Слайд 16Математическая постановка задачи кодирования
Пусть первичный алфавит A содержит N знаков со средней
Математическая постановка задачи кодирования
Пусть первичный алфавит A содержит N знаков со средней

Слайд 17Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о
Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о

Слайд 18
М=2
При отсутствии помех средняя длина двоичного кода может быть сколь угодно близкой
М=2
При отсутствии помех средняя длина двоичного кода может быть сколь угодно близкой

Слайд 19Возможны следующие особенности вторичного алфавита:
Элементарные сигналы (0 и 1) могут иметь одинаковые
Возможны следующие особенности вторичного алфавита:
Элементарные сигналы (0 и 1) могут иметь одинаковые

Слайд 20Алфавитное неравномерное двоичное кодирование сигналами равной длительности
построить такую систему кодирования, чтобы суммарная
Алфавитное неравномерное двоичное кодирование сигналами равной длительности
построить такую систему кодирования, чтобы суммарная

Слайд 21Неравномерный код с разделителем
00 – признак конца знака
000 – признак конца слова
код
Неравномерный код с разделителем
00 – признак конца знака
000 – признак конца слова
код
Слайд 22Поскольку для русского языка, I1(r)=4,356 бит, избыточность данного кода, согласно, составляет:
Q(r)
Поскольку для русского языка, I1(r)=4,356 бит, избыточность данного кода, согласно, составляет:
Q(r)

Слайд 23Оптимальное кодирование. Префиксные коды
Оптимальным кодированием называется процедура преобразования символов первичного алфавита т:
Оптимальное кодирование. Префиксные коды
Оптимальным кодированием называется процедура преобразования символов первичного алфавита т:

Слайд 24Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает

Слайд 25а л м р у ы
10 010 00 11 0110 0111
Пример
00100010000111010101110000110
Отрезать от текущего сообщения крайний левый символ,
а л м р у ы
10 010 00 11 0110 0111
Пример
00100010000111010101110000110
Отрезать от текущего сообщения крайний левый символ,

Слайд 26Построение оптимального кода по методу Шеннона — Фано для сообщений сводится к
Построение оптимального кода по методу Шеннона — Фано для сообщений сводится к

Слайд 27Префиксный код Шеннона-Фано (1948-1949)
K(A,2) = 0,3*2+ 0,2*2+ 0,2*2 +0,15*3+0,1*4+0,05*4=2,45
I1(A)=2,390 бит
Избыточность кода
Префиксный код Шеннона-Фано (1948-1949)
K(A,2) = 0,3*2+ 0,2*2+ 0,2*2 +0,15*3+0,1*4+0,05*4=2,45
I1(A)=2,390 бит
Избыточность кода
Слайд 28Префиксный код Хаффмана
Пример тот же.
Алгоритм:
Создадим новый вспомогательный алфавит A1, объединив два
Префиксный код Хаффмана
Пример тот же.
Алгоритм:
Создадим новый вспомогательный алфавит A1, объединив два

Слайд 29Прямой ход:
Обратный ход:
Прямой ход:
Обратный ход:
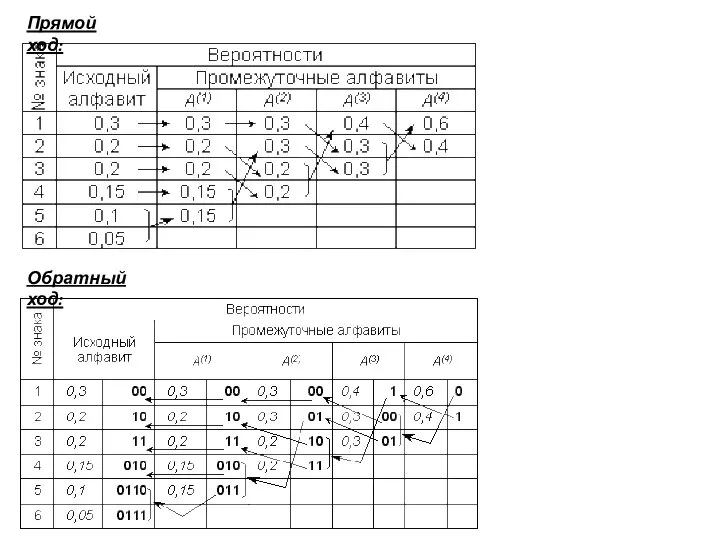
Слайд 30 Средняя длина кода оказывается равной K(2) = 4,395; избыточность кода
Q(r)
Средняя длина кода оказывается равной K(2) = 4,395; избыточность кода Q(r)

Слайд 31Код Хемминга. Построение дерева алфавитов
Код Хемминга. Построение дерева алфавитов

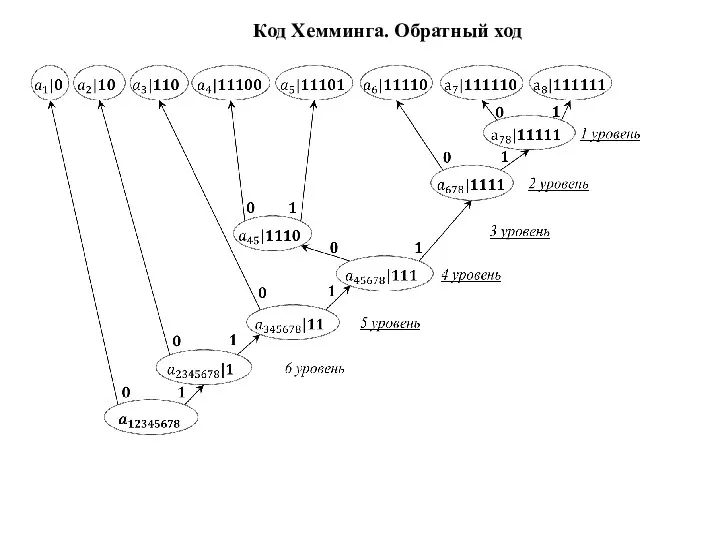
Слайд 32Код Хемминга. Обратный ход
Код Хемминга. Обратный ход
Слайд 33Равномерное алфавитное двоичное кодирование. Байтовый код
В этом случае двоичный код первичного
Равномерное алфавитное двоичное кодирование. Байтовый код
В этом случае двоичный код первичного

 Создание игрового портала
Создание игрового портала Операционная система (ОС)
Операционная система (ОС) Поисковые системы Республики Конго
Поисковые системы Республики Конго Аналитика по сводному потенциалу
Аналитика по сводному потенциалу Криптовалюта
Криптовалюта Архитектура операционных систем
Архитектура операционных систем Приложение мечты
Приложение мечты История возникновения интернета
История возникновения интернета Лекция №1 по курсу Мобильное программирование
Лекция №1 по курсу Мобильное программирование Оптимизация обновления информационной базы. Информация для технических специалистов
Оптимизация обновления информационной базы. Информация для технических специалистов Ветвления
Ветвления Инструкция по работе с личным кабинетом автора в eLibrary.ru
Инструкция по работе с личным кабинетом автора в eLibrary.ru Анализ информационной безопасности предприятия
Анализ информационной безопасности предприятия YouTube. Видеоблогинг
YouTube. Видеоблогинг Представление текста, изображений и звука
Представление текста, изображений и звука Презентация
Презентация Google company
Google company Windows 2000
Windows 2000 Вирусы и антивирусные программы
Вирусы и антивирусные программы Исполнитель Робот
Исполнитель Робот Иллюстратор - соавтор писателя
Иллюстратор - соавтор писателя Моделирование. Раздел 1
Моделирование. Раздел 1 Find Differences by helgabel
Find Differences by helgabel Презентация на тему Поисковые системы Интернета
Презентация на тему Поисковые системы Интернета  Программирование средств мультимедиа в среде Visual Studio на базе технологии Windows Forms (C#)
Программирование средств мультимедиа в среде Visual Studio на базе технологии Windows Forms (C#) Как выбрать книгу
Как выбрать книгу Разработка web-приложений на готовых платформах (CMS)
Разработка web-приложений на готовых платформах (CMS) Яндекс директ
Яндекс директ