- Информация и информационные процессы. Сжатие данных. 11 класс

Содержание
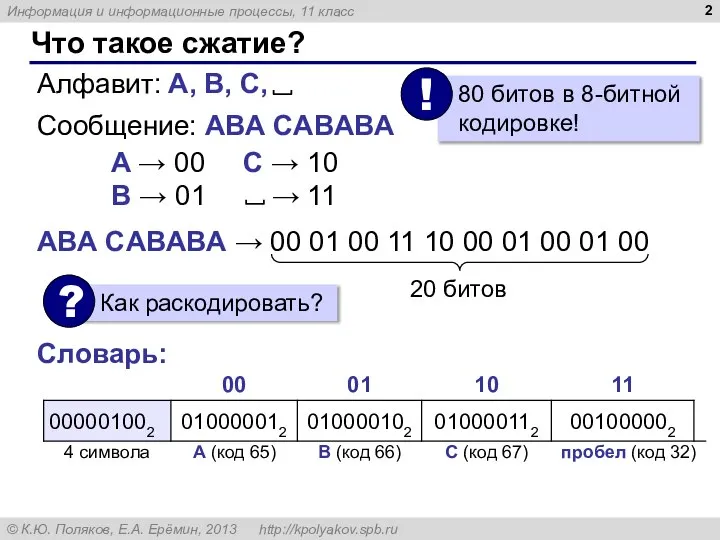
- 2. Что такое сжатие? Сообщение: АBА CАBАBА A → 00 B → 01 АBА CАBАBА → 00
- 3. Коэффициент сжатия Сообщение: 10240 символов Словарь: 5 байтов Длина кода: 10240×2 = 20480 битов = 2560
- 4. Сжатие без потерь Сжатие без потерь – это такое уменьшение объема закодированных данных, при котором можно
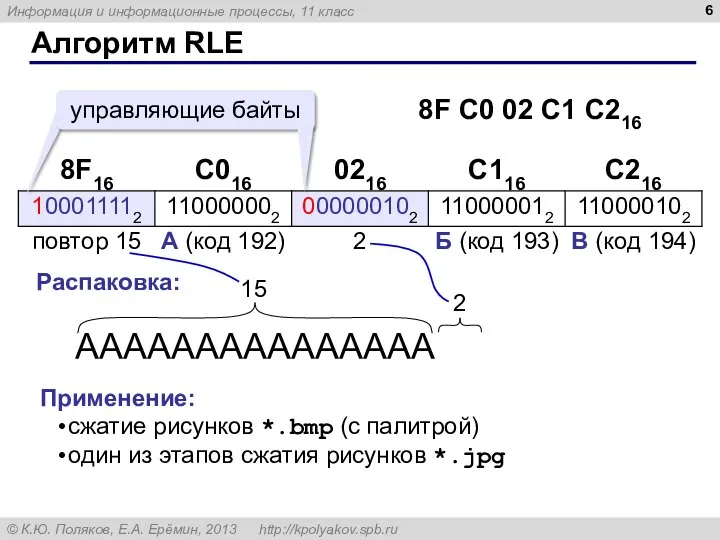
- 5. Алгоритм RLE RLE (англ. Run Length Encoding, кодирование цепочек одинаковых символов) 100 100 200 байтов Файл
- 6. Алгоритм RLE АААААААААААААААБВ Распаковка: 15 2 Применение: сжатие рисунков *.bmp (с палитрой) один из этапов сжатия
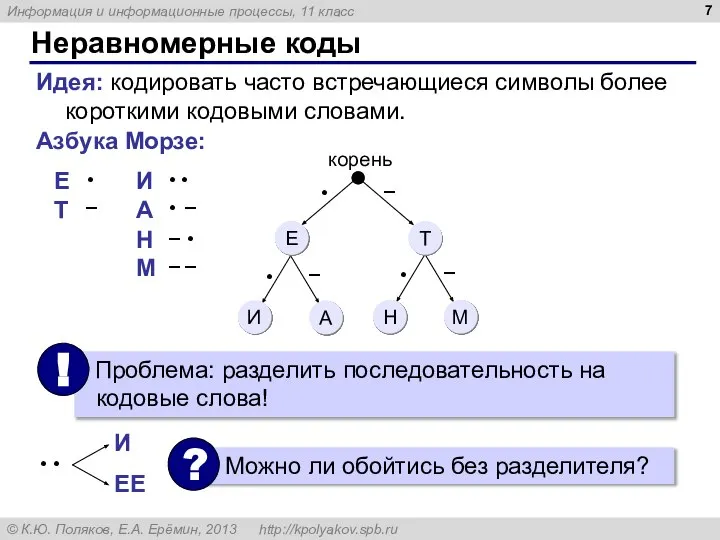
- 7. Неравномерные коды Идея: кодировать часто встречающиеся символы более короткими кодовыми словами. Азбука Морзе:
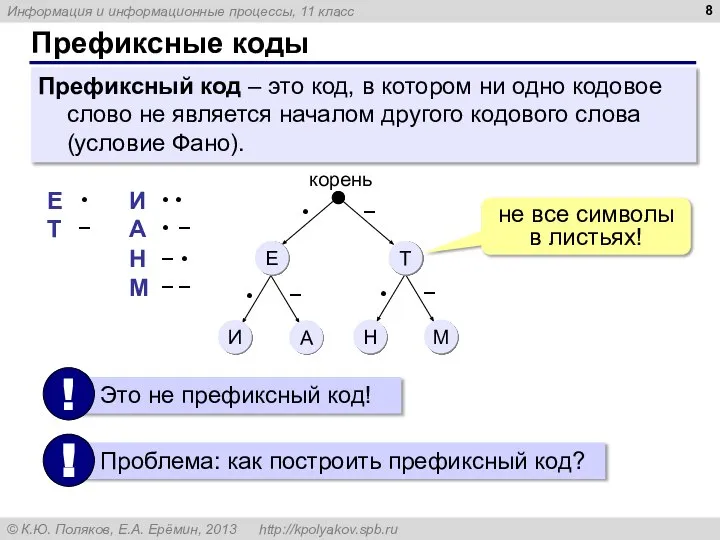
- 8. Префиксные коды Префиксный код – это код, в котором ни одно кодовое слово не является началом
- 9. Код Шеннона-Фано Количество символов в сообщении: На 2 группы с примерно равным числом символов: начинаются с
- 10. Код Шеннона-Фано Декодирование: 1110111101001011001111 111 01 111 01 00 10 110 01 111 Т O Т
- 11. Код Шеннона-Фано учитывается частота символов не нужен символ-разделитель код префиксный – можно декодировать по мере поступления
- 12. Алгоритм Хаффмана По увеличению частоты:
- 13. Алгоритм Хаффмана 0 Т 100 Н 101 Код Хаффмана: Е 110 О 111
- 14. Сравнение алгоритмов Количество символов в сообщении: Равномерное кодирование (8-битный код): (140 + 68 + 68 +
- 15. Сравнение алгоритмов Количество символов в сообщении: (140 + 68 + 68) ⋅ 2 + (64 +
- 16. Алгоритм Хаффмана код оптимальный среди алфавитных кодов нужно заранее знать частоты символов при ошибке в передаче
- 17. Алгоритм LZW 1977: А. Лемпел и Я. Зив, 1984: Т. Велч Идеи: кодировать не отдельные символы,
- 18. Сжатие с потерями Сжатие с потерями – это такое уменьшение объема закодированных данных, при которых распакованный
- 19. Снижение глубины цвета размер ↓ качество ↓
- 20. Сжатие JPEG Y = 0,299⋅R + 0,587⋅G + 0,114⋅B Cb = 128 – 0,1687⋅R – 0,3313⋅G
- 21. Сжатие JPEG Идея: глаз наиболее чувствителен к яркости 12 чисел + дискретное косинусное преобразование, алгоритмы RLE
- 22. Сжатие JPEG Артефакты – заметные искажения из-за сжатия с потерями
- 23. Сжатие рисунков с потерями и без
- 24. Сжатие звука (MP3) MP3 = MPEG-1 Layer 3, кодирование восприятия Битрейт – это число бит, используемых
- 25. Сжатие видео видео = изображения + звук Кодек (кодировщик/декодировщик) – это программа для сжатия данных и
- 27. Скачать презентацию
Слайд 3Коэффициент сжатия
Сообщение: 10240 символов
Словарь: 5 байтов
Длина кода:
10240×2 = 20480 битов
Коэффициент сжатия
Сообщение: 10240 символов
Словарь: 5 байтов
Длина кода:
10240×2 = 20480 битов

Слайд 4Сжатие без потерь
Сжатие без потерь – это такое уменьшение объема закодированных данных,
Сжатие без потерь
Сжатие без потерь – это такое уменьшение объема закодированных данных,

Слайд 5Алгоритм RLE
RLE (англ. Run Length Encoding, кодирование цепочек одинаковых символов)
100
100
200 байтов
Файл qq.txt
Файл
Алгоритм RLE
RLE (англ. Run Length Encoding, кодирование цепочек одинаковых символов)
100
100
200 байтов
Файл qq.txt
Файл

Слайд 6Алгоритм RLE
АААААААААААААААБВ
Распаковка:
15
2
Применение:
сжатие рисунков *.bmp (с палитрой)
один из этапов сжатия рисунков *.jpg
8F C0
Алгоритм RLE
АААААААААААААААБВ
Распаковка:
15
2
Применение:
сжатие рисунков *.bmp (с палитрой)
один из этапов сжатия рисунков *.jpg
8F C0
Слайд 7Неравномерные коды
Идея: кодировать часто встречающиеся символы более короткими кодовыми словами.
Азбука Морзе:
Неравномерные коды
Идея: кодировать часто встречающиеся символы более короткими кодовыми словами.
Азбука Морзе:
Слайд 8Префиксные коды
Префиксный код – это код, в котором ни одно кодовое слово
Префиксные коды
Префиксный код – это код, в котором ни одно кодовое слово
Слайд 9Код Шеннона-Фано
Количество символов в сообщении:
На 2 группы с примерно равным числом
Код Шеннона-Фано
Количество символов в сообщении:
На 2 группы с примерно равным числом

Слайд 10Код Шеннона-Фано
Декодирование:
1110111101001011001111
111
01
111
01
00
10
110
01
111
Т
O
Т
O
Е
Н
О
Т
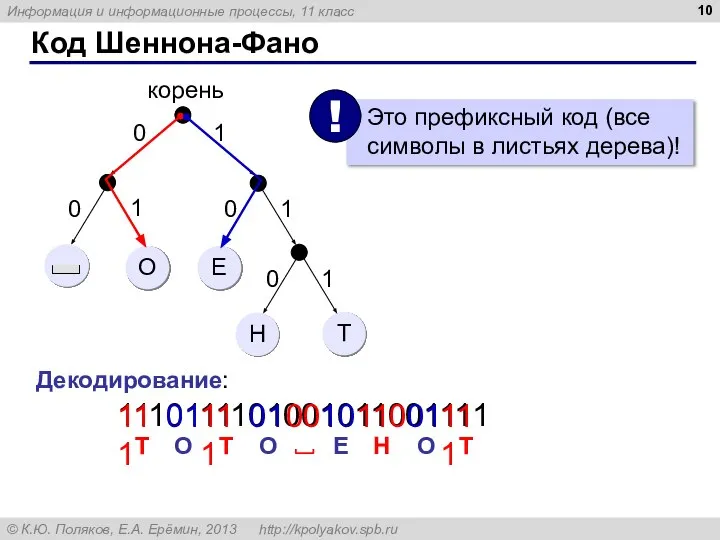
Код Шеннона-Фано
Декодирование:
1110111101001011001111
111
01
111
01
00
10
110
01
111
Т
O
Т
O
Е
Н
О
Т
Слайд 11Код Шеннона-Фано
учитывается частота символов
не нужен символ-разделитель
код префиксный – можно декодировать по мере
Код Шеннона-Фано
учитывается частота символов
не нужен символ-разделитель
код префиксный – можно декодировать по мере

Слайд 12Алгоритм Хаффмана
По увеличению частоты:
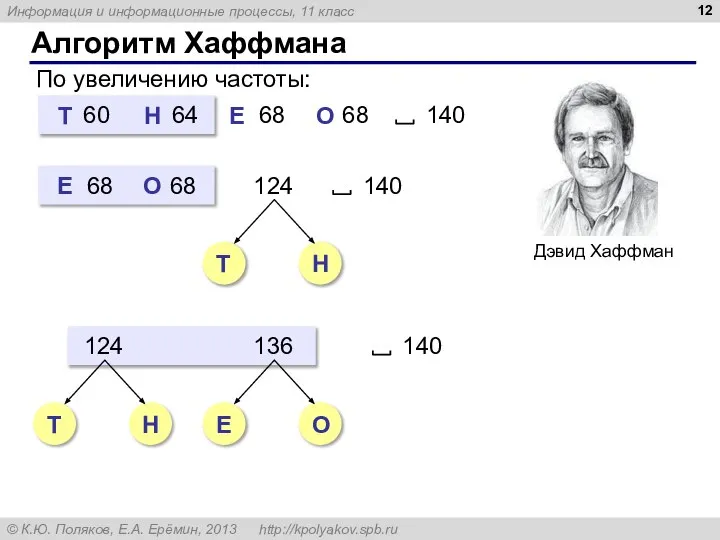
Алгоритм Хаффмана
По увеличению частоты:
Слайд 13Алгоритм Хаффмана
0
Т
100
Н
101
Код Хаффмана:
Е
110
О
111
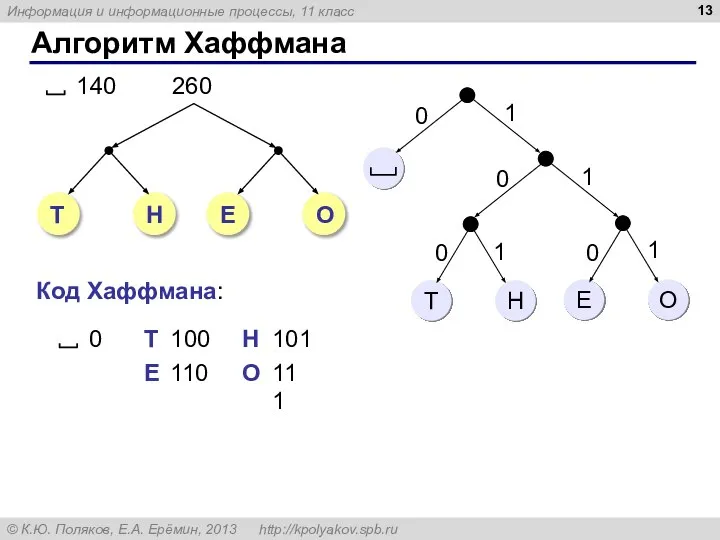
Алгоритм Хаффмана
0
Т
100
Н
101
Код Хаффмана:
Е
110
О
111
Слайд 14Сравнение алгоритмов
Количество символов в сообщении:
Равномерное кодирование (8-битный код):
(140 + 68
Сравнение алгоритмов
Количество символов в сообщении:
Равномерное кодирование (8-битный код):
(140 + 68

Слайд 15Сравнение алгоритмов
Количество символов в сообщении:
(140 + 68 + 68) ⋅ 2
Сравнение алгоритмов
Количество символов в сообщении:
(140 + 68 + 68) ⋅ 2

Слайд 16Алгоритм Хаффмана
код оптимальный среди алфавитных кодов
нужно заранее знать частоты символов
при ошибке в
Алгоритм Хаффмана
код оптимальный среди алфавитных кодов
нужно заранее знать частоты символов
при ошибке в

Слайд 17Алгоритм LZW
1977: А. Лемпел и Я. Зив, 1984: Т. Велч
Идеи:
кодировать не
Алгоритм LZW
1977: А. Лемпел и Я. Зив, 1984: Т. Велч
Идеи:
кодировать не

Слайд 18Сжатие с потерями
Сжатие с потерями – это такое уменьшение объема закодированных данных,
Сжатие с потерями
Сжатие с потерями – это такое уменьшение объема закодированных данных,

Слайд 19Снижение глубины цвета
размер ↓
качество ↓
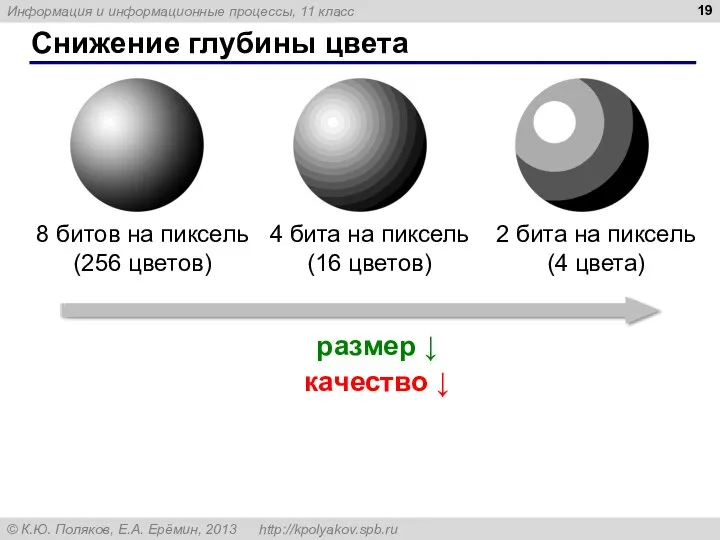
Снижение глубины цвета
размер ↓
качество ↓
Слайд 20Сжатие JPEG
Y = 0,299⋅R + 0,587⋅G + 0,114⋅B
Cb = 128 – 0,1687⋅R
Сжатие JPEG
Y = 0,299⋅R + 0,587⋅G + 0,114⋅B
Cb = 128 – 0,1687⋅R

Слайд 21Сжатие JPEG
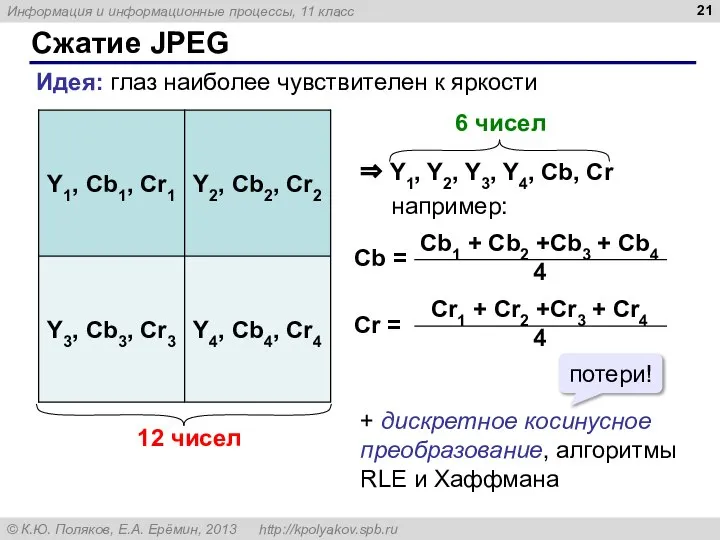
Идея: глаз наиболее чувствителен к яркости
12 чисел
+ дискретное косинусное преобразование, алгоритмы
Сжатие JPEG
Идея: глаз наиболее чувствителен к яркости
12 чисел
+ дискретное косинусное преобразование, алгоритмы
Слайд 22Сжатие JPEG
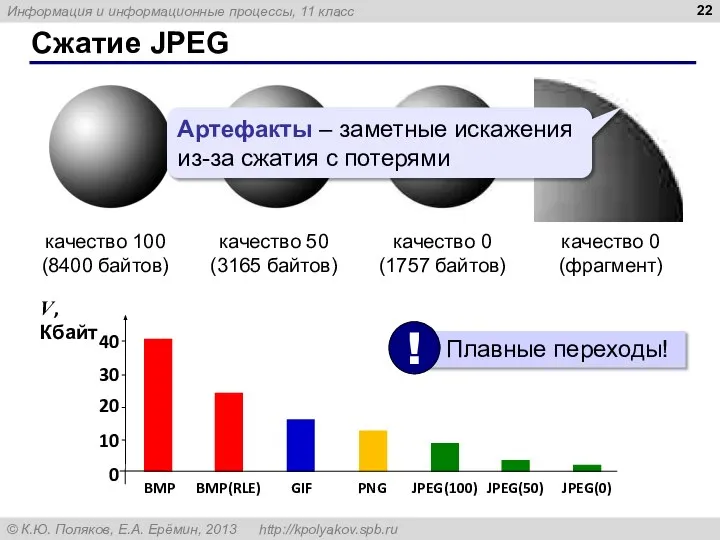
Артефакты – заметные искажения из-за сжатия с потерями
Сжатие JPEG
Артефакты – заметные искажения из-за сжатия с потерями
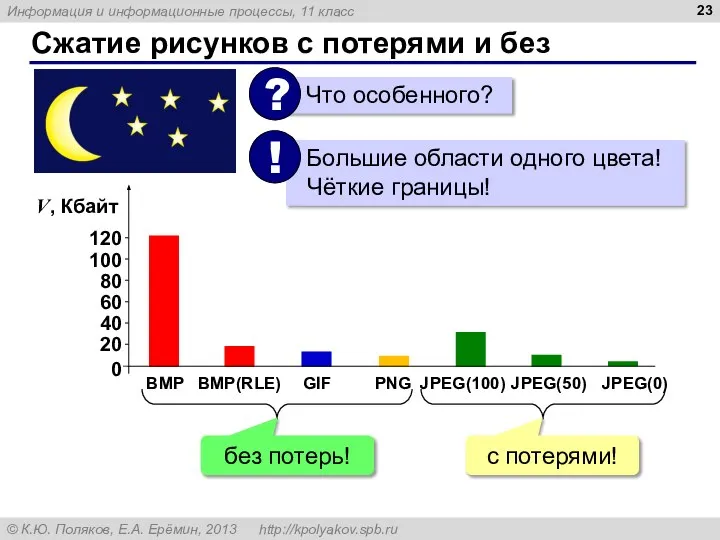
Слайд 23Сжатие рисунков с потерями и без
Сжатие рисунков с потерями и без
Слайд 24Сжатие звука (MP3)
MP3 = MPEG-1 Layer 3, кодирование восприятия
Битрейт – это число
Сжатие звука (MP3)
MP3 = MPEG-1 Layer 3, кодирование восприятия
Битрейт – это число

Слайд 25Сжатие видео
видео = изображения + звук
Кодек (кодировщик/декодировщик) – это программа для сжатия
Сжатие видео
видео = изображения + звук
Кодек (кодировщик/декодировщик) – это программа для сжатия

 Популяризация экологических проблем в интернет-сетях
Популяризация экологических проблем в интернет-сетях Теоретические основы компьютерной безопасности
Теоретические основы компьютерной безопасности Мобильное программирование. Лекция 7
Мобильное программирование. Лекция 7 Язык html
Язык html Создание презентации в Microsoft PowerPoint
Создание презентации в Microsoft PowerPoint Стоимостные характеристики информационной деятельности. Правовые нормы
Стоимостные характеристики информационной деятельности. Правовые нормы презентация Информация и ее свойства
презентация Информация и ее свойства Копирование, перемещение и удаление объектов
Копирование, перемещение и удаление объектов Социальные группы
Социальные группы Ссылка в html-документе
Ссылка в html-документе Электронные таблицы. Обработка числовой информации в электронных таблицах
Электронные таблицы. Обработка числовой информации в электронных таблицах Разработка приложений в ВК
Разработка приложений в ВК Продвижение сайта
Продвижение сайта Поиск профессионально значимой информации в сети интернет
Поиск профессионально значимой информации в сети интернет Информация и информационные процессы. 8 класс
Информация и информационные процессы. 8 класс Школа Московской биржи. Иркутск, день 1
Школа Московской биржи. Иркутск, день 1 Пред-лейнинг. Работа на лайнах
Пред-лейнинг. Работа на лайнах Телекоммуникационные сети. Сетевой трафик
Телекоммуникационные сети. Сетевой трафик Урок 25 Организация ввода вывода
Урок 25 Организация ввода вывода Системы программирования и прикладное программное обеспечение
Системы программирования и прикладное программное обеспечение Санс и Папайрус (Папирус) в виде пони
Санс и Папайрус (Папирус) в виде пони РПГ-Рогалик Бесконечная Шутка
РПГ-Рогалик Бесконечная Шутка Презентация на тему Кодирование информации с помощью знаковых систем
Презентация на тему Кодирование информации с помощью знаковых систем  Кибер спорт сегодня
Кибер спорт сегодня Подання та зберігання електронної звітності, реєстрація ПН. 10 способів зберегти свій час
Подання та зберігання електронної звітності, реєстрація ПН. 10 способів зберегти свій час Сайт Стерокорт (до патологии)
Сайт Стерокорт (до патологии) Презентация на тему Устройства ввода информации
Презентация на тему Устройства ввода информации  Алгоритм установления соединения в сети IP-телефонии по протоколу SIP
Алгоритм установления соединения в сети IP-телефонии по протоколу SIP