- Двоичный поиск в упорядоченном массиве

Содержание
- 3. Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с ключом поиска «Х». Возможны варианты:
- 4. Алгоритм на псевдокоде (первая версия) Обозначим L, R – правая и левая границы рабочей части массива,
- 5. 1 2 3 4 5 6 7 8 9 10 11 12 а б б б
- 6. Рассмотрим вторую версию алгоритма, в которой уменьшим количество сравнений путем исключения из алгоритма проверки на равенство.
- 7. L: = 1, R: = n DO ( L m: = ⌊(L+R)/2⌋ IF (am ELSE R:
- 8. 1 2 3 4 5 6 7 8 9 10 11 12 а б б б
- 9. Трудоемкость двоичного поиска Сначала определим максимальное количество итераций (k). Рассмотрим худший случай, когда 1) часть массива
- 10. Трудоемкость двоичного поиска
- 12. Графики трудоемкости двоичного поиска
- 13. Сортировка данных со сложной структурой Дан массив абонентов А: Иванов Петров Абрамов 223322 345767 667891 Struct
- 14. Сортировка данных со сложной структурой Пример. Struct abonent { char name[10]; long phone; } A[n]; Попытка
- 16. Логическая функция Less (меньше) При сортировке по имени абонента: int less ( struct abonent X, struct
- 17. Наполовину пуст? Наполовину полон? Программист считает, что стакан в два раза больше, чем нужно
- 18. При сортировке по сложному ключу так же легко определить функцию less. Для сортировки по фамилии абонента
- 19. Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less. Например, в пузырьковой сортировке: DO
- 20. Вывод: Если структура сортируемых данных не соответствует простым (встроенным) типам языка, то операции отношения необходимо переопределить
- 21. Преимущества: 1) Операции отношения могут быть определены различными способами в зависимости от ключа сортировки и условия
- 23. Сортировка по множеству ключей Пусть рассмотренный телефонный справочник хранится в виде базы данных в памяти компьютера
- 24. Индексация данных Рассмотрим суть индексации на массиве целых чисел: 1 2 3 4 5 6 7
- 25. Чтобы упорядочить массив А (по возрастанию), мы построили индексный массив В, в него записали номера элементов
- 26. Пример. Вывод элементов массива (по возрастанию): DO ( i = 1, …, n) вывод ( А
- 27. Построение индексного массива Построение индексного массива выполняется на базе любого алгоритма сортировки. *Вначале в массив В
- 28. Построение индексного массива Алгоритм на псевдокоде (на примере пузырьковой сортировки) B := (1, 2, …, n)
- 29. Преимущества индексации 1) Появляется возможность построения нескольких различных индексов, которые можно использовать по мере необходимости. 2)
- 31. Скачать презентацию

Слайд 3
Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с ключом
Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с ключом

Слайд 4Алгоритм на псевдокоде
(первая версия)
Обозначим
L, R – правая и левая границы
Алгоритм на псевдокоде
(первая версия)
Обозначим
L, R – правая и левая границы

Слайд 5 1 2 3 4 5 6 7 8 9 10 11
1 2 3 4 5 6 7 8 9 10 11

Слайд 6Рассмотрим вторую версию алгоритма,
в которой
уменьшим количество сравнений
путем исключения
Рассмотрим вторую версию алгоритма,
в которой
уменьшим количество сравнений
путем исключения

Слайд 7L: = 1, R: = n
DO ( L m: = ⌊(L+R)/2⌋
IF (am
L: = 1, R: = n
DO ( L
IF (am

Слайд 8 1 2 3 4 5 6 7 8 9 10 11
1 2 3 4 5 6 7 8 9 10 11

Слайд 9Трудоемкость двоичного поиска
Сначала определим
максимальное количество итераций (k).
Рассмотрим худший случай, когда
Трудоемкость двоичного поиска
Сначала определим
максимальное количество итераций (k).
Рассмотрим худший случай, когда

Слайд 10Трудоемкость двоичного поиска
Трудоемкость двоичного поиска


Слайд 12Графики трудоемкости двоичного поиска
Графики трудоемкости двоичного поиска

Слайд 13Сортировка данных
со сложной структурой
Дан массив абонентов
А: Иванов Петров Абрамов
223322
Сортировка данных
со сложной структурой
Дан массив абонентов
А: Иванов Петров Абрамов
223322

Слайд 14Сортировка данных
со сложной структурой
Пример. Struct abonent { char name[10];
long
Сортировка данных
со сложной структурой
Пример. Struct abonent { char name[10];
long
![Сортировка данных со сложной структурой Пример. Struct abonent { char name[10]; long](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1036061/slide-13.jpg)

Слайд 16 Логическая функция Less (меньше)
При сортировке по имени абонента:
int less ( struct
Логическая функция Less (меньше)
При сортировке по имени абонента:
int less ( struct

Слайд 17Наполовину пуст?
Наполовину полон?
Программист считает, что
стакан в два раза больше, чем нужно
Наполовину пуст?
Наполовину полон?
Программист считает, что
стакан в два раза больше, чем нужно

Слайд 18При сортировке по сложному ключу так же легко определить функцию less.
Для сортировки
При сортировке по сложному ключу так же легко определить функцию less.
Для сортировки

Слайд 19Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less.
Например, в
Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less.
Например, в

Слайд 20 Вывод:
Если структура сортируемых данных
не соответствует
простым (встроенным) типам языка, то
операции
Вывод:
Если структура сортируемых данных
не соответствует
простым (встроенным) типам языка, то
операции

Слайд 21 Преимущества:
1) Операции отношения могут быть определены различными способами в зависимости от ключа
Преимущества:
1) Операции отношения могут быть определены различными способами в зависимости от ключа


Слайд 23Сортировка по множеству ключей
Пусть рассмотренный телефонный справочник хранится в виде базы данных
Сортировка по множеству ключей
Пусть рассмотренный телефонный справочник хранится в виде базы данных

Слайд 24Индексация данных
Рассмотрим суть индексации на массиве целых чисел:
1 2 3 4
Индексация данных
Рассмотрим суть индексации на массиве целых чисел:
1 2 3 4

Слайд 25 Чтобы упорядочить массив А (по возрастанию),
мы построили индексный массив В,
Чтобы упорядочить массив А (по возрастанию),
мы построили индексный массив В,

Слайд 26Пример. Вывод элементов массива (по возрастанию):
DO ( i = 1, …, n)
Пример. Вывод элементов массива (по возрастанию):
DO ( i = 1, …, n)

Слайд 27Построение индексного массива
Построение индексного массива выполняется
на базе любого алгоритма сортировки.
*Вначале в
Построение индексного массива
Построение индексного массива выполняется
на базе любого алгоритма сортировки.
*Вначале в

Слайд 28
Построение индексного массива
Алгоритм на псевдокоде
(на примере пузырьковой сортировки)
B :=
Построение индексного массива
Алгоритм на псевдокоде
(на примере пузырьковой сортировки)
B :=

Слайд 29Преимущества индексации
1) Появляется возможность построения нескольких различных индексов, которые можно использовать
Преимущества индексации
1) Появляется возможность построения нескольких различных индексов, которые можно использовать

 Программирование на языке Python
Программирование на языке Python Защита информации. Безопасность информации. Математический аппарат
Защита информации. Безопасность информации. Математический аппарат Защита информации
Защита информации Готовимся к КР по информатике
Готовимся к КР по информатике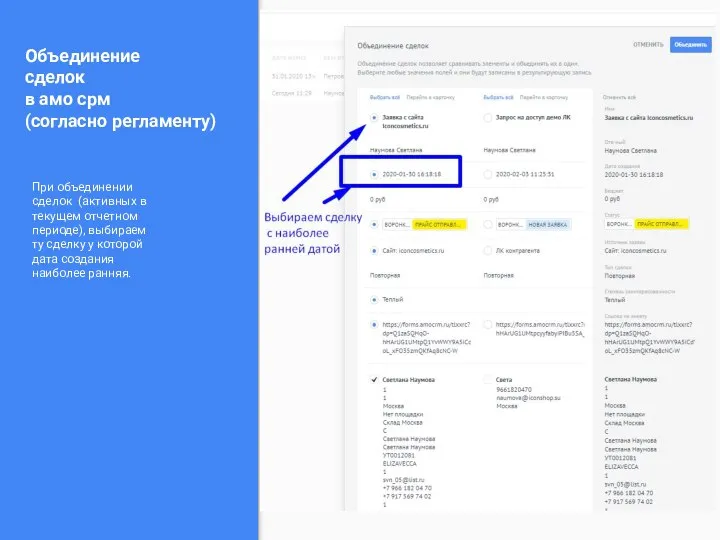 Amo SRM: как использовать
Amo SRM: как использовать Троичная и двоично-десятичная системы счисления
Троичная и двоично-десятичная системы счисления Язык программирования общего назначения С++
Язык программирования общего назначения С++ Человеко-машинное взаимодействие
Человеко-машинное взаимодействие Textovye_redaktory
Textovye_redaktory Правовые организационные основы защиты информации ограниченного доступа
Правовые организационные основы защиты информации ограниченного доступа Информатика в начальной школе, как своеобразная картина окружающего мира
Информатика в начальной школе, как своеобразная картина окружающего мира Правила создания дизайна баннеров
Правила создания дизайна баннеров Двоичное кодирование информации
Двоичное кодирование информации Операционная система. Программное обеспечение
Операционная система. Программное обеспечение Конфигурация MySQL-сервера для Интернет-проекта
Конфигурация MySQL-сервера для Интернет-проекта Организация хранения информации в компьютере. Файлы
Организация хранения информации в компьютере. Файлы Написание литературного обзора
Написание литературного обзора Life style аудитории у команды NonStop в социальных сетях
Life style аудитории у команды NonStop в социальных сетях Логические основы обработки данных. Арифметико-логическое устройство
Логические основы обработки данных. Арифметико-логическое устройство Презентация на тему Total Commander
Презентация на тему Total Commander  Mind Map For PowerPoint
Mind Map For PowerPoint Виды программного обеспечения
Виды программного обеспечения lektsia_informatika
lektsia_informatika Представление числовых данных
Представление числовых данных Как писать статьи
Как писать статьи Отечественные ученые в области информатики
Отечественные ученые в области информатики История компьютерной техники
История компьютерной техники Словари
Словари