- Кодирование источника (эффективное кодирование)

Содержание
- 2. Кодирование источника Для источников с памятью избыточность тем больше, чем выше степень статистической (вероятностной) зависимости символов
- 3. Кодирование Один символ источника → кодовое слово (кодовая комбинация) Если для всех символов источника длина кодовых
- 4. При неравномерном коде говорят о средней длине кодового слова (усреднение длин кодовых слов производится по априорному
- 5. H’(U) = uC H(U) = uK log M = C µ= uK / uC = H(U)
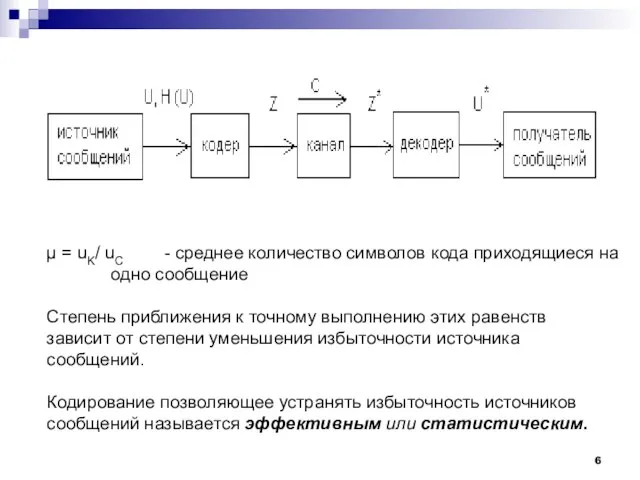
- 6. µ = uK/ uC - среднее количество символов кода приходящиеся на одно сообщение Степень приближения к
- 7. Избыточность дискретных источников обуславливается двумя причинами: 1) памятью источника; 2) неравномерностью сообщений. Универсальным способом уменьшения избыточности
- 8. Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9. В этом тривиальном случае
- 10. 1-я Теорема Шеннона Предельные возможности статистического кодирования раскрывается в теореме Шеннона для канала без шума, которая
- 11. 1-я Теорема Шеннона Получить меньшее значение µ невозможно (обратная теорема). Обратная часть теоремы утверждающая, что невозможно
- 12. 1-я Теорема Шеннона «Основная теорема о кодировании в отсутствие шумов»: Среднюю длину кодовых слов для передачи
- 13. Пример. Если источник без памяти имеет объем алфавита 32, то при равновероятных символах его энтропия равна
- 14. Практическое значение теоремы Шеннона заключается в возможности повышения эффективности систем передачи информации (систем связи) путем применения
- 15. Пример 8.5. Известный код Морзе служит примером неравномерного кода. Кодовые слова состоят из трех различных символов:
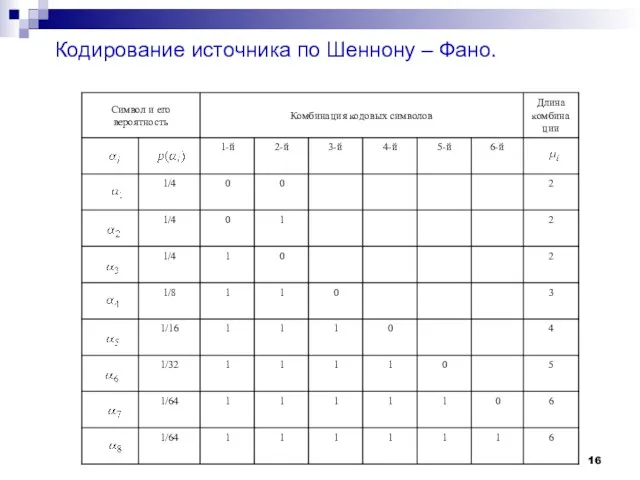
- 16. Кодирование источника по Шеннону – Фано.
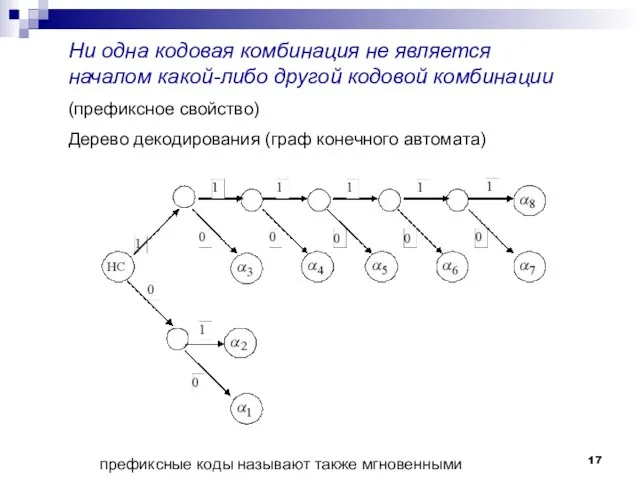
- 17. Ни одна кодовая комбинация не является началом какой-либо другой кодовой комбинации (префиксное свойство) Дерево декодирования (граф
- 18. Средняя длина кодовой комбинации для построенного кода Согласно теореме Шеннона при оптимальном кодировании можно достичь средней
- 19. Определим вероятность появления определенного символа в кодовой комбинации (пусть это будет символ 1). Её можно найти
- 20. при оптимальном кодировании источника кодовые символы равновероятны; такое кодирование является безызбыточным. Источник вместе с кодером можно
- 21. Кодирование источника по Хаффману Все символы алфавита записываются в порядке убывания вероятностей. 2. Два нижних символа
- 22. Кодирование источника по Хаффмену
- 23. Энтропия алфавита . Средняя длина кодового слова =0,3⋅2+0,2⋅2+0,15⋅3+0,15⋅3+0,1⋅3+0,04⋅4+0,03⋅5+0,03⋅5=2,66 Вероятность символа 1 в последовательности кодовых комбинаций находится
- 24. Оптимальность кода Шеннона – Фано в рассмотренном примере объясняется специально подобранными вероятностями символов, так, что на
- 25. Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9. В этом тривиальном случае
- 27. Скачать презентацию
Слайд 2Кодирование источника
Для источников с памятью избыточность тем больше, чем выше степень статистической
Кодирование источника
Для источников с памятью избыточность тем больше, чем выше степень статистической

Слайд 3Кодирование
Один символ источника → кодовое слово (кодовая комбинация)
Если для всех символов источника
Кодирование
Один символ источника → кодовое слово (кодовая комбинация)
Если для всех символов источника

Слайд 4При неравномерном коде говорят о средней длине кодового слова (усреднение длин кодовых
При неравномерном коде говорят о средней длине кодового слова (усреднение длин кодовых

Слайд 5H’(U) = uC H(U) = uK log M = C
µ= uK /
H’(U) = uC H(U) = uK log M = C
µ= uK /
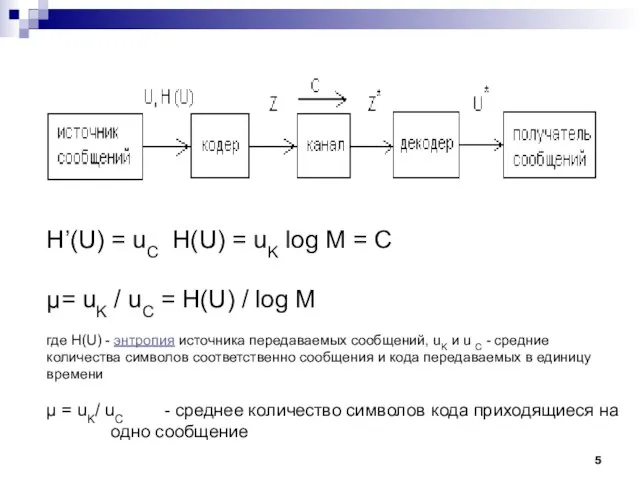
Слайд 6µ = uK/ uC - среднее количество символов кода приходящиеся на одно
Слайд 7Избыточность дискретных источников обуславливается двумя причинами:
1) памятью источника;
2) неравномерностью сообщений.
Универсальным способом уменьшения
Избыточность дискретных источников обуславливается двумя причинами:
1) памятью источника;
2) неравномерностью сообщений.
Универсальным способом уменьшения

Слайд 8Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9.
Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9.


Слайд 101-я Теорема Шеннона
Предельные возможности статистического кодирования раскрывается в теореме Шеннона для канала
1-я Теорема Шеннона
Предельные возможности статистического кодирования раскрывается в теореме Шеннона для канала

Слайд 111-я Теорема Шеннона
Получить меньшее значение µ невозможно
(обратная теорема).
Обратная часть теоремы
1-я Теорема Шеннона
Получить меньшее значение µ невозможно
(обратная теорема).
Обратная часть теоремы

Слайд 121-я Теорема Шеннона
«Основная теорема о кодировании в отсутствие шумов»:
Среднюю длину кодовых
1-я Теорема Шеннона
«Основная теорема о кодировании в отсутствие шумов»:
Среднюю длину кодовых

Слайд 13Пример. Если источник без памяти имеет объем алфавита 32, то при равновероятных
Пример. Если источник без памяти имеет объем алфавита 32, то при равновероятных

Слайд 14Практическое значение теоремы Шеннона заключается в возможности повышения эффективности систем передачи информации
Практическое значение теоремы Шеннона заключается в возможности повышения эффективности систем передачи информации

Слайд 15Пример 8.5. Известный код Морзе служит примером неравномерного кода. Кодовые слова состоят
Пример 8.5. Известный код Морзе служит примером неравномерного кода. Кодовые слова состоят

Слайд 16Кодирование источника по Шеннону – Фано.
Кодирование источника по Шеннону – Фано.
Слайд 17Ни одна кодовая комбинация не является началом какой-либо другой кодовой комбинации
(префиксное
Ни одна кодовая комбинация не является началом какой-либо другой кодовой комбинации
(префиксное
Слайд 18Средняя длина кодовой комбинации для построенного кода
Согласно теореме Шеннона при оптимальном кодировании
Средняя длина кодовой комбинации для построенного кода
Согласно теореме Шеннона при оптимальном кодировании

Слайд 19Определим вероятность появления определенного символа в кодовой комбинации (пусть это будет
символ
Определим вероятность появления определенного символа в кодовой комбинации (пусть это будет символ

Слайд 20при оптимальном кодировании источника кодовые символы равновероятны; такое кодирование является безызбыточным. Источник
при оптимальном кодировании источника кодовые символы равновероятны; такое кодирование является безызбыточным. Источник

Слайд 21Кодирование источника по Хаффману
Все символы алфавита записываются в порядке убывания вероятностей.
2.
Кодирование источника по Хаффману
Все символы алфавита записываются в порядке убывания вероятностей.
2.

Слайд 22Кодирование источника по Хаффмену
Кодирование источника по Хаффмену

Слайд 23Энтропия алфавита .
Средняя длина кодового слова
=0,3⋅2+0,2⋅2+0,15⋅3+0,15⋅3+0,1⋅3+0,04⋅4+0,03⋅5+0,03⋅5=2,66
Вероятность символа 1 в последовательности
Энтропия алфавита .
Средняя длина кодового слова
=0,3⋅2+0,2⋅2+0,15⋅3+0,15⋅3+0,1⋅3+0,04⋅4+0,03⋅5+0,03⋅5=2,66
Вероятность символа 1 в последовательности

Слайд 24Оптимальность кода Шеннона – Фано в рассмотренном примере объясняется специально подобранными вероятностями
Оптимальность кода Шеннона – Фано в рассмотренном примере объясняется специально подобранными вероятностями

Слайд 25Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9.
Пример. Рассмотрим источник, вырабатывающий два независимых символа с вероятностями 0,1 и 0,9.

 Інтимні селфі в інтернеті - жарт чи ризик?
Інтимні селфі в інтернеті - жарт чи ризик? Глобальная компьютерная сеть Интернет. 10 класс
Глобальная компьютерная сеть Интернет. 10 класс Линейное программирование
Линейное программирование Рендеры
Рендеры Финальный проект на Mit App Inventor
Финальный проект на Mit App Inventor Игрофикация
Игрофикация 7-1-2
7-1-2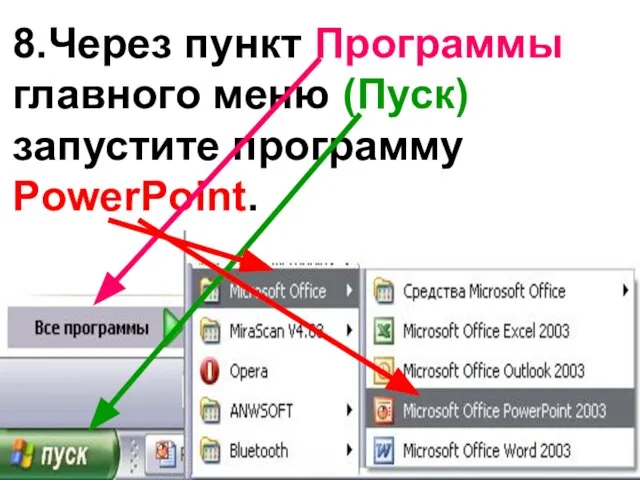 Программа PowerPoint
Программа PowerPoint Анализ программ с циклом
Анализ программ с циклом Синтаксис
Синтаксис Операционная система Windows
Операционная система Windows Физические основы компьютерной графики. Зрение, спектр, цвет, свет, цветовые модели. Лекция №2
Физические основы компьютерной графики. Зрение, спектр, цвет, свет, цветовые модели. Лекция №2 Основы программирования на языке Python
Основы программирования на языке Python Процедуры и функции. Заголовок и тело процедур и функций, классификация параметров. Вызов процедур и функций. Лекция 9
Процедуры и функции. Заголовок и тело процедур и функций, классификация параметров. Вызов процедур и функций. Лекция 9 Электронные таблицы (на примере Exсel)
Электронные таблицы (на примере Exсel) Связь в небоскрёбах
Связь в небоскрёбах On-line сервисы
On-line сервисы Динамічні КМ БПКС (комутатори з просторовим розподілом)
Динамічні КМ БПКС (комутатори з просторовим розподілом) Командная разработка программных средств
Командная разработка программных средств The concept of information technology
The concept of information technology Нежурналистика. Медиа Школа Экономического факультета
Нежурналистика. Медиа Школа Экономического факультета Visual Rare Studio. Веб-студия дизайна, разработки и продвижения сайтов
Visual Rare Studio. Веб-студия дизайна, разработки и продвижения сайтов Классификация программного обеспечения
Классификация программного обеспечения Системное программирование. Работа с файлами в Windows API
Системное программирование. Работа с файлами в Windows API Почему программисты через 10 лет будут не нужны?
Почему программисты через 10 лет будут не нужны? Архитектура ПК лекция
Архитектура ПК лекция Основы логики (упражнения)
Основы логики (упражнения) Оценка эффективности информационной системы
Оценка эффективности информационной системы