- Кодирование в системах связи. Тема 3

Содержание
- 2. Сжатие информации представляет собой процесс преобразования исходного сообщения из одной кодовой системы в другую, в результате
- 3. Процесс восстановления называется декомпрессией или распаковкой и только после процесса распаковки данные пригодны для обработки в
- 4. Необратимое сжатие имеет гораздо более высокую степень сжатия, но допускает некоторые отклонения декодированных данных от исходных.
- 5. 3. Помехоустойчивое кодирование
- 9. Помехоустойчивое кодирование - предназначено для обнаружения и по возможности исправления ошибок, возникших вследствие действия помех при
- 10. Общим для всех трех видов кодирования является то, что информация каким-либо образом меняет форму представления, но
- 12. 2. Параметры кодов Число m используемых для кодирования элементарных символов, определяет основание кода. Коды с основанием
- 13. Расстоянием по Хэммингу между двумя кодовыми словами называется число разрядов, в которых они различны. При этом
- 14. Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих
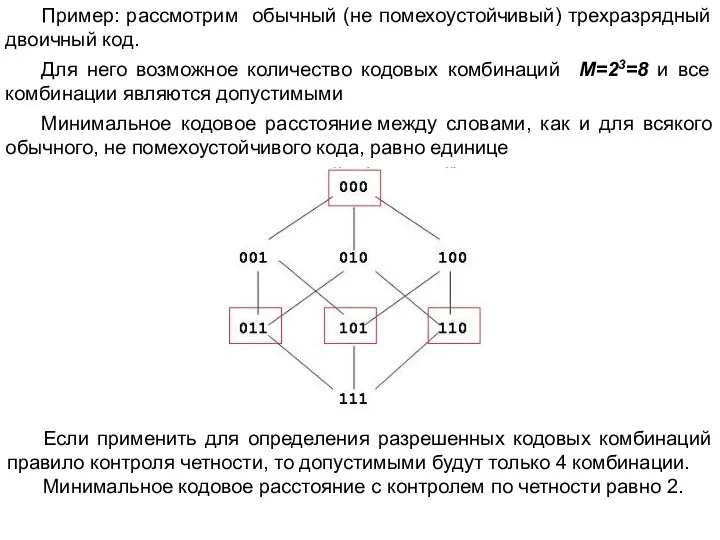
- 15. Пример: рассмотрим обычный (не помехоустойчивый) трехразрядный двоичный код. Для него возможное количество кодовых комбинаций M=23=8 и
- 16. Платой за помехоустойчивость является необходимость увеличения длины слов по сравнению с обычным кодом. В данном примере
- 17. Таким образом, для того чтобы код мог обнаруживать и устранять ошибки, необходимо отказаться от его безызбыточности.
- 18. Введение дополнительных контрольных разрядов увеличивает затраты на хранение или передачу кодированной информации. При этом фактический объем
- 19. Чтобы код обладал свойствами обнаруживать одиночные ошибки, необходимо ввести избыточность, которая обеспечивала бы минимальное расстояние между
- 20. 2. Для исправления одиночной ошибки каждой разрешенной кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций. Чтобы
- 21. Для ориентировочного определения необходимой избыточности кода при заданном кодовом расстоянии d можно воспользоваться верхней граничной оценкой
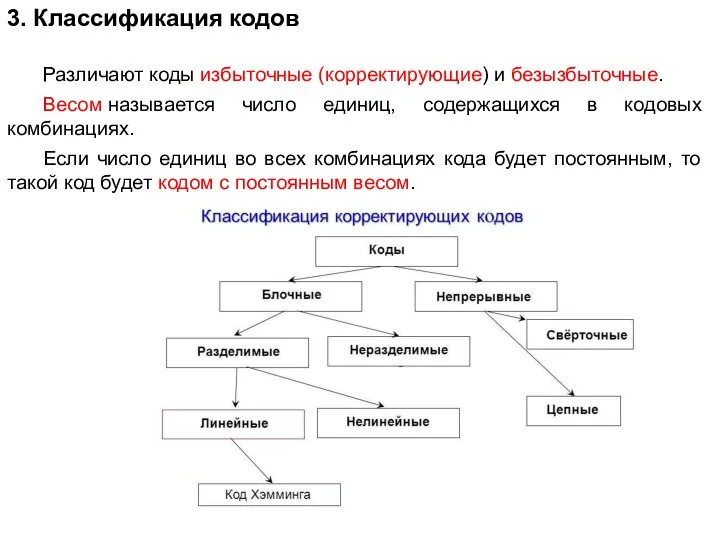
- 22. 3. Классификация кодов Различают коды избыточные (корректирующие) и безызбыточные. Весом называется число единиц, содержащихся в кодовых
- 23. Равномерные и неравномерные коды. У равномерных кодов n=const, например, пятиразрядный код Бодо. У неравномерных кодов n
- 25. Код Морзе статистически согласован с английским языком. Так буква Е, которая в английском языке имеет наибольшую
- 26. Неравномерность является основной особенностью кода Морзе, которая позволяет учитывать статистику сообщения. Однако код Морзе менее экономичный,
- 27. Неравномерность кода Морзе не позволяет осуществить слитную передачу кодовых комбинаций, а следовательно, и осуществить кодом Морзе
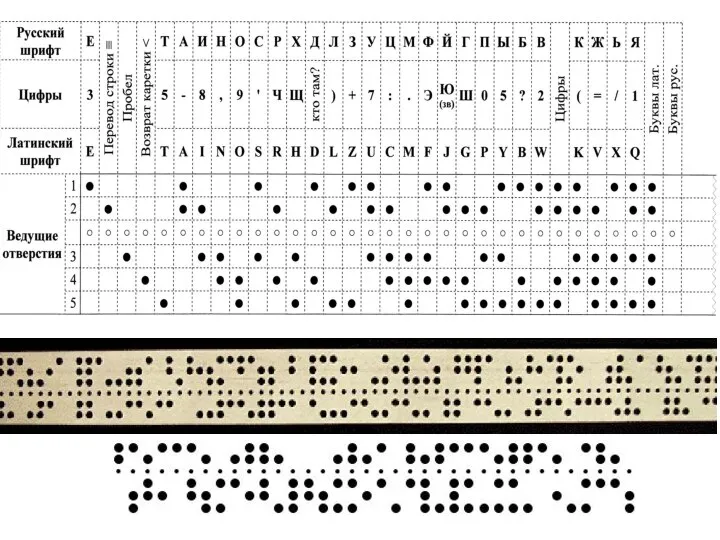
- 28. Код Бодо
- 30. Равномерные корректирующие коды подразделяются на блочные и непрерывные. В блочных двоичных кодах последовательность элементарных сообщений источника
- 31. Среди помехоустойчивых кодов выделяют разделимые коды и неразделимые коды. В разделимых кодах разряды могут быть принципиально
- 32. Для систематического кода применяется обозначение (n,m)–код, где n – число всех разрядов в кодовой комбинации, m
- 44. Циклические коды относятся к блоковым кодам. Последовательность кодовых комбинаций в циклическом коде разбивается на отдельные блоки,
- 45. Циклические коды имеют высокую эффективность обнаружения ошибок и сравнительно просты в реализации кодирующих и декодирующих устройств.
- 46. Цифры двоичного кода можно рассматривать как коэффициенты многочлена переменной х. Например, для кодовой комбинации 1011011 (n=7)
- 47. Принцип обнаружения ошибок при помощи циклического кода заключается в том, что в качестве разрешенных кодовых комбинаций
- 48. Построение комбинаций циклического кода возможно путем умножения исходной комбинации А(х) на образующий полином G(x) с приведением
- 49. В процессе кодирования сообщения: Mногочлен А(x), отображающий двоичный код исходного передаваемого сообщения, умножается на хk. При
- 50. Пример. Дано: n=7, m=4, k=3 и G(x)=x3+x2+1. Требуется закодировать сообщение 1 0 1 1. Cообщению 1011
- 51. При применении циклического кода в качестве кода с исправлением ошибок места искаженных разрядов определяются путем анализа
- 52. 5. Код Хемминга Ричард Хемминг разработал код, который обеспечивает обнаружение и исправление одиночных ошибок при минимально
- 53. Рассмотрим пример, когда количество информационных бит m в блоке равно 4. Это код (7,4), количество проверочных
- 54. Построение корректирующего кода Хэмминга производится исходя из требуемого объема информационных сообщений и статистических данных о наиболее
- 55. Значения символов в проверочных разрядах устанавливаются в результате суммирования по модулю 2 значений символов в определенных
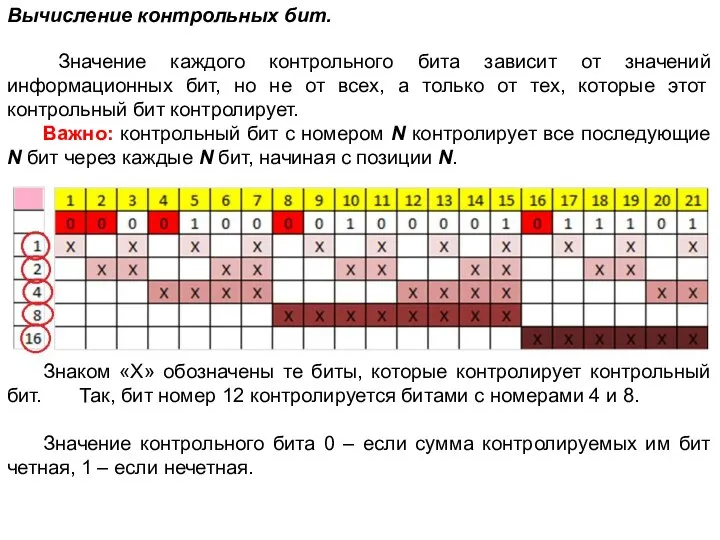
- 56. Вычисление контрольных бит. Значение каждого контрольного бита зависит от значений информационных бит, но не от всех,
- 57. Проверка на приемной стороне принятой кодовой комбинации осуществляется следующим образом: создаются контрольные суммы S1, S2, S3,
- 58. Сущность обнаружения позиции ошибки, а значит и ее исправления кодом Хэмминга состоит в том, что производятся
- 59. . Пример. Построить код Хэмминга с исправлением одиночной ошибки при 11 информационных разрядах, т.е. m=11. Определим
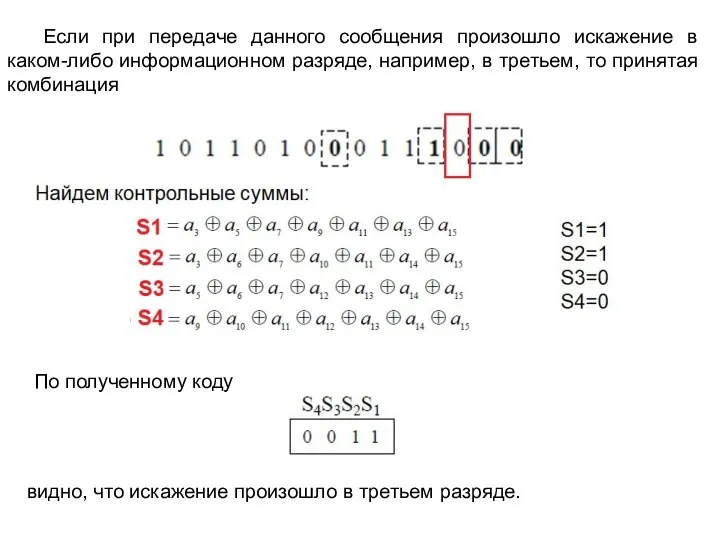
- 60. Если при передаче данного сообщения произошло искажение в каком-либо информационном разряде, например, в третьем, то принятая
- 61. 6. Коды Рида-Соломона Коды Рида-Соломона были предложены в 1960 сотрудниками Линкольнской лаборатории МТИ Ирвином Ридом и
- 63. Скачать презентацию
Слайд 2 Сжатие информации представляет собой процесс преобразования исходного сообщения из одной кодовой системы в
Сжатие информации представляет собой процесс преобразования исходного сообщения из одной кодовой системы в

Слайд 3 Процесс восстановления называется декомпрессией или распаковкой и только после процесса распаковки данные
Процесс восстановления называется декомпрессией или распаковкой и только после процесса распаковки данные

Слайд 4 Необратимое сжатие имеет гораздо более высокую степень сжатия, но допускает некоторые отклонения декодированных
Необратимое сжатие имеет гораздо более высокую степень сжатия, но допускает некоторые отклонения декодированных

Слайд 5 3. Помехоустойчивое кодирование
3. Помехоустойчивое кодирование




Слайд 9 Помехоустойчивое кодирование - предназначено для обнаружения и по возможности исправления ошибок,
Помехоустойчивое кодирование - предназначено для обнаружения и по возможности исправления ошибок,

Слайд 10 Общим для всех трех видов кодирования является то, что информация каким-либо образом меняет
Общим для всех трех видов кодирования является то, что информация каким-либо образом меняет


Слайд 122. Параметры кодов
Число m используемых для кодирования элементарных символов, определяет основание кода.
2. Параметры кодов
Число m используемых для кодирования элементарных символов, определяет основание кода.

Слайд 13 Расстоянием по Хэммингу между двумя кодовыми словами называется число разрядов, в которых
Расстоянием по Хэммингу между двумя кодовыми словами называется число разрядов, в которых

Слайд 14
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число

Слайд 15 Пример: рассмотрим обычный (не помехоустойчивый) трехразрядный двоичный код.
Для него возможное количество
Пример: рассмотрим обычный (не помехоустойчивый) трехразрядный двоичный код.
Для него возможное количество
Слайд 16 Платой за помехоустойчивость является необходимость увеличения длины слов по сравнению с обычным
Платой за помехоустойчивость является необходимость увеличения длины слов по сравнению с обычным

Слайд 17 Таким образом, для того чтобы код мог обнаруживать и устранять ошибки, необходимо
Таким образом, для того чтобы код мог обнаруживать и устранять ошибки, необходимо

Слайд 18 Введение дополнительных контрольных разрядов увеличивает затраты на хранение или передачу кодированной информации. При этом
Введение дополнительных контрольных разрядов увеличивает затраты на хранение или передачу кодированной информации. При этом

Слайд 19Чтобы код обладал свойствами обнаруживать одиночные ошибки, необходимо ввести избыточность, которая обеспечивала
Чтобы код обладал свойствами обнаруживать одиночные ошибки, необходимо ввести избыточность, которая обеспечивала

Слайд 202. Для исправления одиночной ошибки каждой разрешенной кодовой комбинации необходимо сопоставить подмножество

Слайд 21 Для ориентировочного определения необходимой избыточности кода при заданном кодовом расстоянии d можно воспользоваться верхней
Для ориентировочного определения необходимой избыточности кода при заданном кодовом расстоянии d можно воспользоваться верхней

Слайд 223. Классификация кодов
Различают коды избыточные (корректирующие) и безызбыточные.
Весом называется число единиц, содержащихся в
3. Классификация кодов
Различают коды избыточные (корректирующие) и безызбыточные.
Весом называется число единиц, содержащихся в
Слайд 23 Равномерные и неравномерные коды.
У равномерных кодов n=const, например, пятиразрядный код Бодо.
У
Равномерные и неравномерные коды.
У равномерных кодов n=const, например, пятиразрядный код Бодо.
У

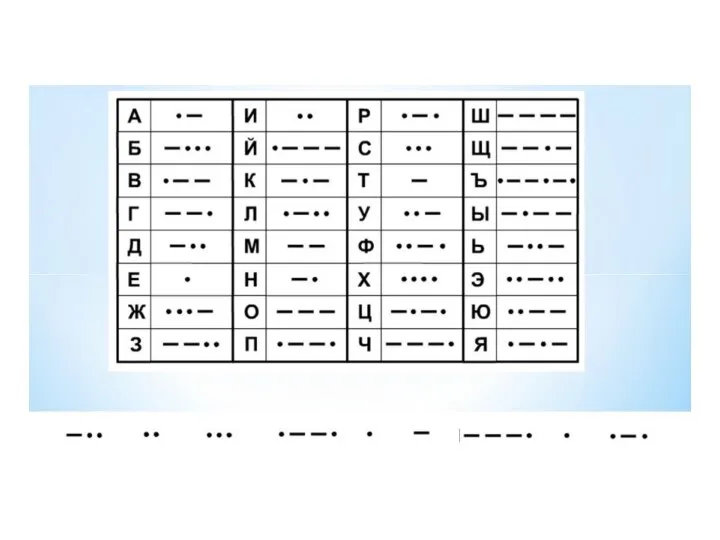
Слайд 25 Код Морзе статистически согласован с английским языком.
Так буква Е, которая в
Код Морзе статистически согласован с английским языком.
Так буква Е, которая в

Слайд 26 Неравномерность является основной особенностью кода Морзе, которая позволяет учитывать статистику сообщения.
Однако
Неравномерность является основной особенностью кода Морзе, которая позволяет учитывать статистику сообщения.
Однако

Слайд 27
Неравномерность кода Морзе не позволяет осуществить слитную передачу кодовых комбинаций, а следовательно,
Неравномерность кода Морзе не позволяет осуществить слитную передачу кодовых комбинаций, а следовательно,

Слайд 28Код Бодо
Код Бодо

Слайд 30 Равномерные корректирующие коды подразделяются на блочные и непрерывные.
В блочных двоичных кодах
Равномерные корректирующие коды подразделяются на блочные и непрерывные.
В блочных двоичных кодах

Слайд 31
Среди помехоустойчивых кодов выделяют разделимые коды и неразделимые коды.
В разделимых кодах разряды
Среди помехоустойчивых кодов выделяют разделимые коды и неразделимые коды.
В разделимых кодах разряды

Слайд 32
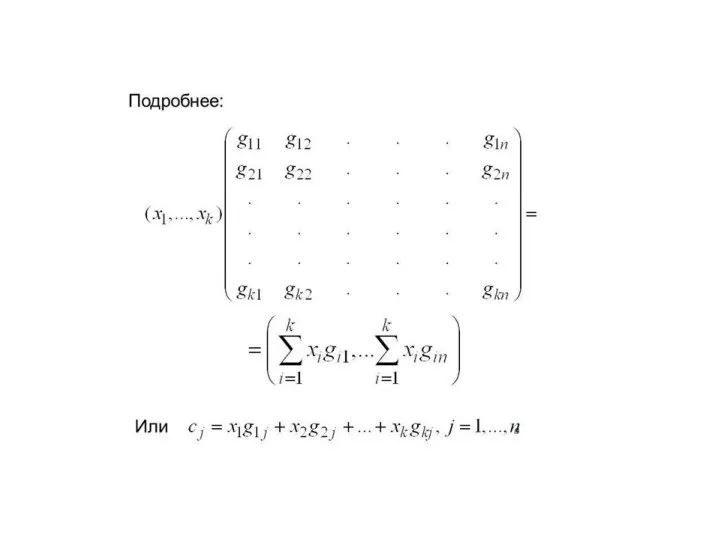
Для систематического кода применяется обозначение (n,m)–код,
где
n – число всех
Для систематического кода применяется обозначение (n,m)–код,
где
n – число всех




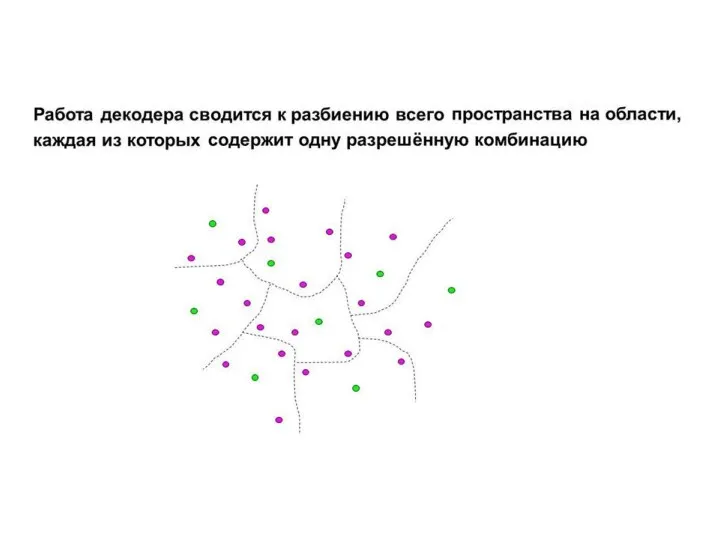





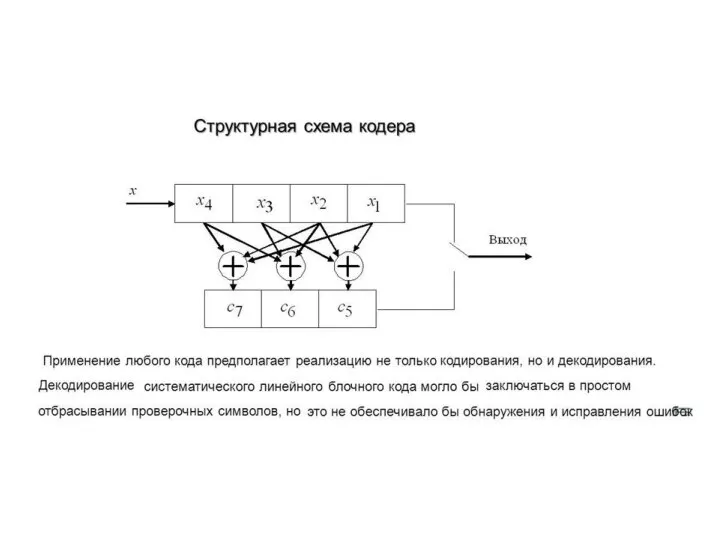
Слайд 44 Циклические коды относятся к блоковым кодам.
Последовательность кодовых комбинаций в циклическом коде разбивается
Циклические коды относятся к блоковым кодам.
Последовательность кодовых комбинаций в циклическом коде разбивается

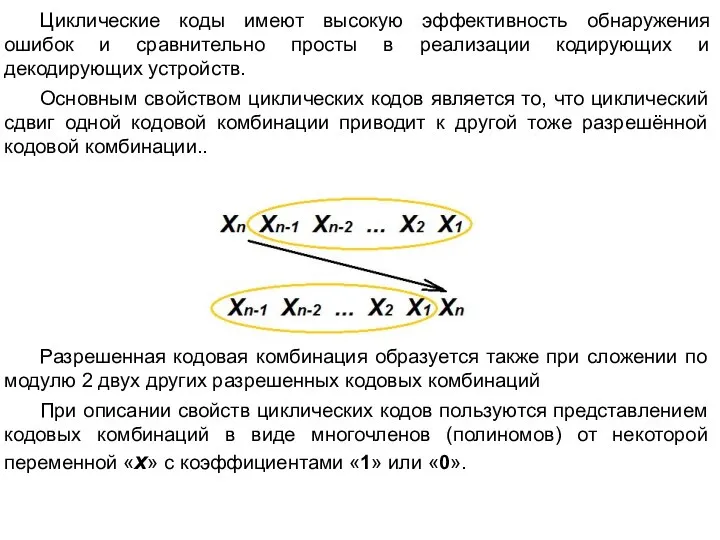
Слайд 45 Циклические коды имеют высокую эффективность обнаружения ошибок и сравнительно просты в реализации
Циклические коды имеют высокую эффективность обнаружения ошибок и сравнительно просты в реализации
Слайд 46 Цифры двоичного кода можно рассматривать как коэффициенты многочлена переменной х. Например, для
Цифры двоичного кода можно рассматривать как коэффициенты многочлена переменной х. Например, для

Слайд 47 Принцип обнаружения ошибок при помощи циклического кода заключается в том, что в
Принцип обнаружения ошибок при помощи циклического кода заключается в том, что в

Слайд 48 Построение комбинаций циклического кода возможно путем умножения исходной комбинации А(х) на образующий полином G(x)
Построение комбинаций циклического кода возможно путем умножения исходной комбинации А(х) на образующий полином G(x)

Слайд 49
В процессе кодирования сообщения:
Mногочлен А(x), отображающий двоичный код исходного передаваемого сообщения, умножается
В процессе кодирования сообщения:
Mногочлен А(x), отображающий двоичный код исходного передаваемого сообщения, умножается

Слайд 50
Пример.
Дано: n=7, m=4, k=3 и G(x)=x3+x2+1.
Требуется закодировать сообщение 1 0
Пример.
Дано: n=7, m=4, k=3 и G(x)=x3+x2+1.
Требуется закодировать сообщение 1 0

Слайд 51
При применении циклического кода в качестве кода с исправлением ошибок места искаженных
При применении циклического кода в качестве кода с исправлением ошибок места искаженных

Слайд 52
5. Код Хемминга
Ричард Хемминг разработал код, который обеспечивает обнаружение и исправление одиночных
5. Код Хемминга
Ричард Хемминг разработал код, который обеспечивает обнаружение и исправление одиночных

Слайд 53 Рассмотрим пример, когда количество информационных бит m в блоке равно 4. Это
Рассмотрим пример, когда количество информационных бит m в блоке равно 4. Это

Слайд 54
Построение корректирующего кода Хэмминга производится исходя из требуемого объема информационных сообщений и
Построение корректирующего кода Хэмминга производится исходя из требуемого объема информационных сообщений и

Слайд 55
Значения символов в проверочных разрядах устанавливаются в результате суммирования по модулю 2
Значения символов в проверочных разрядах устанавливаются в результате суммирования по модулю 2

Слайд 56Вычисление контрольных бит.
Значение каждого контрольного бита зависит от значений информационных бит,
Вычисление контрольных бит.
Значение каждого контрольного бита зависит от значений информационных бит,
Слайд 57
Проверка на приемной стороне принятой кодовой комбинации осуществляется следующим образом: создаются контрольные
Проверка на приемной стороне принятой кодовой комбинации осуществляется следующим образом: создаются контрольные

Слайд 58
Сущность обнаружения позиции ошибки, а значит и ее исправления кодом Хэмминга состоит
Сущность обнаружения позиции ошибки, а значит и ее исправления кодом Хэмминга состоит

Слайд 59 .
Пример. Построить код Хэмминга с исправлением одиночной ошибки при 11 информационных разрядах,
.
Пример. Построить код Хэмминга с исправлением одиночной ошибки при 11 информационных разрядах,

Слайд 60 Если при передаче данного сообщения произошло искажение в каком-либо информационном разряде, например,
Если при передаче данного сообщения произошло искажение в каком-либо информационном разряде, например,
Слайд 616. Коды Рида-Соломона
Коды Рида-Соломона были предложены в 1960 сотрудниками Линкольнской лаборатории
6. Коды Рида-Соломона
Коды Рида-Соломона были предложены в 1960 сотрудниками Линкольнской лаборатории

 Методические аспекты эволюции информационных технологий. NBICS-конвергенция
Методические аспекты эволюции информационных технологий. NBICS-конвергенция PHP. Доступ к базам данных
PHP. Доступ к базам данных Web of science. Символы усечения
Web of science. Символы усечения Искусственные и естественные источники информации
Искусственные и естественные источники информации 17 протокол маршрутизации
17 протокол маршрутизации BMWSTART (1)
BMWSTART (1) Быть в 10 раз эффективнее благодаря Groovy
Быть в 10 раз эффективнее благодаря Groovy Базы данных. Access 2007. Запросы
Базы данных. Access 2007. Запросы Браузер Google Chrome
Браузер Google Chrome Insignia. Исследование
Insignia. Исследование Что такое компьютер?
Что такое компьютер? Вложенные циклы и двумерные массивы
Вложенные циклы и двумерные массивы Объекты мультимедиа
Объекты мультимедиа Информационная культура современного человека 11 класс
Информационная культура современного человека 11 класс Признаки объектов
Признаки объектов Операционные системы
Операционные системы Основы программирования C++
Основы программирования C++ Разработка веб-ориентированного специализированного табличного редактора
Разработка веб-ориентированного специализированного табличного редактора Adobe Photoshop
Adobe Photoshop Проектирование,информационное моделирование (bim) и визуализация гражданских и промышленных зданий
Проектирование,информационное моделирование (bim) и визуализация гражданских и промышленных зданий Сеть широкополосного мобильного доступа стандарта LTE для города Сызрань
Сеть широкополосного мобильного доступа стандарта LTE для города Сызрань Разработка и реализация алгоритма создания и балансировки двоичного дерева поиска со взвешенными узлами
Разработка и реализация алгоритма создания и балансировки двоичного дерева поиска со взвешенными узлами Введение в логику
Введение в логику Проектирование объектно – ориентированного приложения. Создание интерфейса пользователя
Проектирование объектно – ориентированного приложения. Создание интерфейса пользователя Персональный компьютер
Персональный компьютер Представление научных результатов
Представление научных результатов Двоичный поиск в упорядоченном массиве
Двоичный поиск в упорядоченном массиве Objektorientierte Programmierung
Objektorientierte Programmierung