- Методы сжатия цифровой информации

Содержание
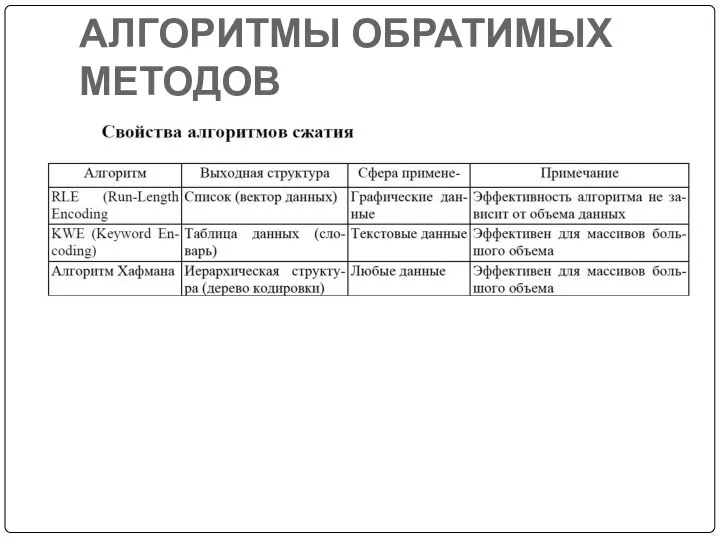
- 2. АЛГОРИТМЫ ОБРАТИМЫХ МЕТОДОВ
- 3. АЛГОРИТМ кодирования по ключевым словам
- 4. АЛГОРИТМ KWE
- 5. алгоритм LZ и алгоритм LZW Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются:
- 6. алгоритм LZ и алгоритм LZW Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает
- 7. Алгоритмы Лемпеля—Зива LZ77 и LZ78 Кодируются не отдельные буквы, а слова. Общая схема алгоритма LZ77 такова
- 8. Пример. Фраза КОЛОКОЛ_ОКОЛО_КОЛОКОЛЬНИ закодируется алгоритмом LZ77 как ________ Алгоритмы Лемпела Зива - Яндекс.Видео (yandex.ru) Недостатки LZ77:
- 9. Общая схема алгоритма LZ78 такова (это не точное описание алгоритма): • алгоритм во время сжатия текста
- 10. Алгоритмы Лемпеля—Зива тем лучше сжимают текст, чем больше размер входного массива. Характерной особенностью обратных алгоритмов LZ77
- 12. Скачать презентацию
Слайд 3АЛГОРИТМ кодирования по ключевым словам
АЛГОРИТМ кодирования по ключевым словам

Слайд 4АЛГОРИТМ KWE
АЛГОРИТМ KWE

Слайд 5алгоритм LZ и алгоритм LZW
Существует довольно много реализаций этого алгоритма, среди которых
алгоритм LZ и алгоритм LZW
Существует довольно много реализаций этого алгоритма, среди которых

Слайд 6алгоритм LZ и алгоритм LZW
Словарем в данном алгоритме является потенциально бесконечный список
алгоритм LZ и алгоритм LZW
Словарем в данном алгоритме является потенциально бесконечный список

Слайд 7Алгоритмы Лемпеля—Зива LZ77 и LZ78
Кодируются не отдельные буквы, а слова.
Общая схема алгоритма
Алгоритмы Лемпеля—Зива LZ77 и LZ78
Кодируются не отдельные буквы, а слова.
Общая схема алгоритма

Слайд 8Пример. Фраза КОЛОКОЛ_ОКОЛО_КОЛОКОЛЬНИ
закодируется алгоритмом LZ77 как ________
Алгоритмы Лемпела Зива - Яндекс.Видео
Пример. Фраза КОЛОКОЛ_ОКОЛО_КОЛОКОЛЬНИ
закодируется алгоритмом LZ77 как ________
Алгоритмы Лемпела Зива - Яндекс.Видео

Слайд 9Общая схема алгоритма LZ78 такова (это не точное описание алгоритма):
• алгоритм во
Общая схема алгоритма LZ78 такова (это не точное описание алгоритма):
• алгоритм во

Слайд 10 Алгоритмы Лемпеля—Зива тем лучше сжимают текст, чем больше размер входного массива.
Алгоритмы Лемпеля—Зива тем лучше сжимают текст, чем больше размер входного массива.

 Системы счисления
Системы счисления Аппаратная реализация компьютера
Аппаратная реализация компьютера Программирование на языке C++
Программирование на языке C++ ВК: продвижение страницы
ВК: продвижение страницы Домашняя компьютерная сеть
Домашняя компьютерная сеть Data Warehouse Concepts and Architectures
Data Warehouse Concepts and Architectures Dugapur PU mix sistem
Dugapur PU mix sistem Теория игр
Теория игр Компьютерный дизайн. Цветовые модели
Компьютерный дизайн. Цветовые модели inf_92882
inf_92882 Информация и информационные системы
Информация и информационные системы Инструкция. Web- Quest Mechanic’s Trap
Инструкция. Web- Quest Mechanic’s Trap net intro
net intro Выпускная квалификационная работа: применение XML технологий на MS SQL для сопровождения корпоративных приложений
Выпускная квалификационная работа: применение XML технологий на MS SQL для сопровождения корпоративных приложений Фейковые новости и как их отличить от настоящих
Фейковые новости и как их отличить от настоящих Лекция 3-4
Лекция 3-4 Claroline. Системы дистанционного обучения
Claroline. Системы дистанционного обучения Алгоритмы
Алгоритмы Construct 2.создаем спиннер
Construct 2.создаем спиннер Презентация5_Исключительные ситуации
Презентация5_Исключительные ситуации Многозадачность как свойство операционной системы. Параллельные последовательности
Многозадачность как свойство операционной системы. Параллельные последовательности Розробка та створення Інтернет-провайдери Харкова
Розробка та створення Інтернет-провайдери Харкова Начало. Конец
Начало. Конец Режим анализ ZEMAX
Режим анализ ZEMAX Рабочий стол заказов
Рабочий стол заказов Презентация
Презентация Innovative technologies of event-management in the field of media and information literacy (MIL)
Innovative technologies of event-management in the field of media and information literacy (MIL) Информационная система
Информационная система