- Нейронные сети

Содержание
- 3. Хайкин С. Нейронные сети: полный курс, 2-е изд., 2006 Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое
- 7. Говорят, что компьютерная программа обучается на опыте E относительно некоторого класса задач T и меры качества
- 8. Классификация Классификация при отсутствии некоторых данных Регрессия Машинный перевод Структурный вывод Обнаружение аномалий Синтез и выборка
- 9. ОБУЧЕНИЕ
- 10. Ошибочная цель (неточная, неправильная) Ложные корреляции Накопление шума Технологические ошибки, неправильные запросы Данные не полны и/или
- 11. ЗАНЯТНЫЕ СОВПАДЕНИЯ
- 12. ЗАНЯТНЫЕ СОВПАДЕНИЯ
- 13. РАБОТА СПЕЦИАЛИСТА ПО ДАННЫМ
- 14. CRISP-DM
- 15. ПРОЦЕСС РАЗРАБОТКИ РЕШЕНИЙ В МО
- 16. DevOps DataOps ModelOps MLOps ГИБКИЕ ПРАКТИКИ
- 17. КОНВЕЙЕР ДАННЫХ
- 18. DATAOPS
- 19. MLOPS LEVEL 0
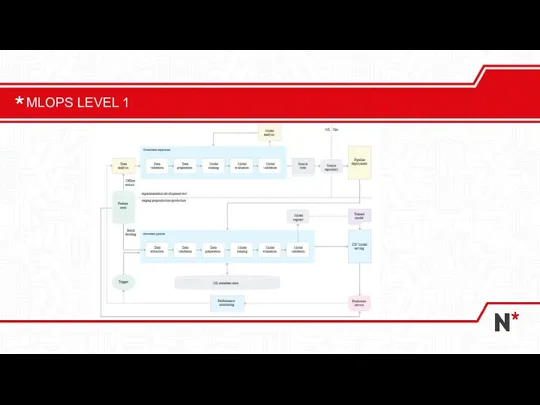
- 20. MLOPS LEVEL 1
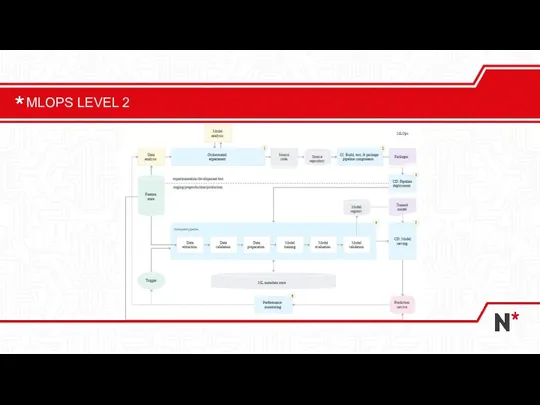
- 21. MLOPS LEVEL 2
- 22. Входные данные должны иметь смысл Ошибка в коде загрузчика Ошибки в разметке входных данных Слишком много
- 23. Извлекайте все данные, которые можно извлечь, но руководствуйтесь здравым смыслом. Оцените временной горизонт, полноту и корректность
- 24. Размерность пространства решения определяется количеством признаков и их увеличение приводит к экспоненциальному росту данных. Это в
- 25. тесная корреляционная взаимосвязь между отбираемыми для анализа признаками, совместно воздействующими на общий результат МУЛЬТИКОЛЛИНЕАРНОСТЬ
- 26. Инженерия признаков (feature extraction and feature engineering) – превращение данных, специфических для предметной области, в понятные
- 27. Исходные Производные Агрегированные – показатели, определенные по группе (сумма, среднее, минимум, максимум) Индикаторы – наличие или
- 28. тексты – это токенизация изображения – извлечение краев и цветовые пятна дата и время– полезно вычленить
- 29. Знание предметной области Описательная статистика Матрица корреляций признаков – с высокой степенью корреляции подумать над удалением
- 30. ОПИСАТЕЛЬНАЯ СТАТИСТИКА
- 31. Критерий Пирсона Прирост информации Критерий Гини Gain_ratio из алгоритма C4.5 ВАЖНОСТЬ ПРИЗНАКА
- 32. КРИТЕРИЙ РАЗБИЕНИЯ
- 33. КРИТЕРИЙ РАЗБИЕНИЯ
- 34. КРИТЕРИЙ РАЗБИЕНИЯ
- 35. Неоткалиброванные признаки Слишком сильная аугментация Применение предобработки только для одной из выборок Долговечность признака Пропуски Нерегулярная
- 36. Если доля пропущенных значений выше 60%, такой признак стоит игнорировать Иногда сам факт отсутствия данных может
- 37. Не заполнять пропуски нулями! Не применять восстановление к признакам, имеющим более 30% пропусков среднее значение или
- 38. Если равна 1, полезной информации нет, удалить Если мощность значительно меньше количества экземпляров, можно изменить тип
- 39. ВЫБРОСЫ
- 40. ПОРОГИ ОТСЕЧЕНИЯ
- 41. НОРМАЛИЗАЦИЯ
- 42. Обертка – процедура поиска, которая включает обучение и оценку модели. Начинаем с пустого множества и добавляем
- 44. Скачать презентацию

Слайд 3Хайкин С. Нейронные сети: полный курс, 2-е изд., 2006
Гудфеллоу Я., Бенджио И.,
Хайкин С. Нейронные сети: полный курс, 2-е изд., 2006
Гудфеллоу Я., Бенджио И.,



Слайд 7Говорят, что компьютерная программа обучается на опыте E относительно некоторого класса задач
Говорят, что компьютерная программа обучается на опыте E относительно некоторого класса задач

Слайд 8Классификация
Классификация при отсутствии некоторых данных
Регрессия
Машинный перевод
Структурный вывод
Обнаружение аномалий
Синтез и выборка
Шумоподавление
Кластеризация
ЗАДАЧА
Классификация
Классификация при отсутствии некоторых данных
Регрессия
Машинный перевод
Структурный вывод
Обнаружение аномалий
Синтез и выборка
Шумоподавление
Кластеризация
ЗАДАЧА

Слайд 9ОБУЧЕНИЕ
ОБУЧЕНИЕ

Слайд 10Ошибочная цель (неточная, неправильная)
Ложные корреляции
Накопление шума
Технологические ошибки, неправильные запросы
Данные не полны и/или
Ошибочная цель (неточная, неправильная)
Ложные корреляции
Накопление шума
Технологические ошибки, неправильные запросы
Данные не полны и/или

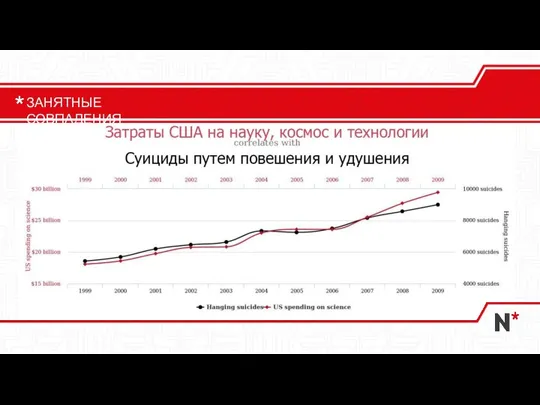
Слайд 11ЗАНЯТНЫЕ СОВПАДЕНИЯ
ЗАНЯТНЫЕ СОВПАДЕНИЯ
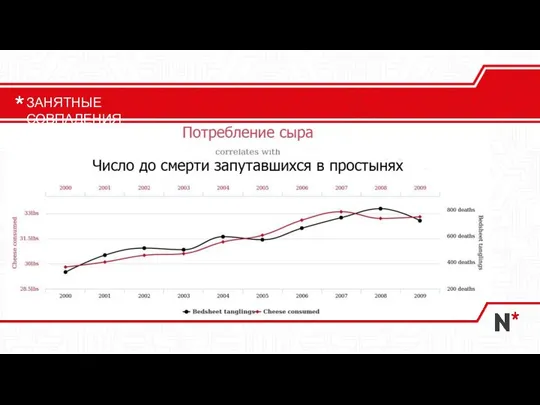
Слайд 12ЗАНЯТНЫЕ СОВПАДЕНИЯ
ЗАНЯТНЫЕ СОВПАДЕНИЯ
Слайд 13РАБОТА СПЕЦИАЛИСТА ПО ДАННЫМ
РАБОТА СПЕЦИАЛИСТА ПО ДАННЫМ

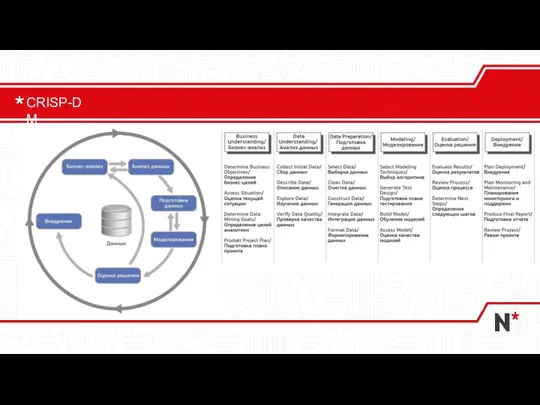
Слайд 14CRISP-DM
CRISP-DM
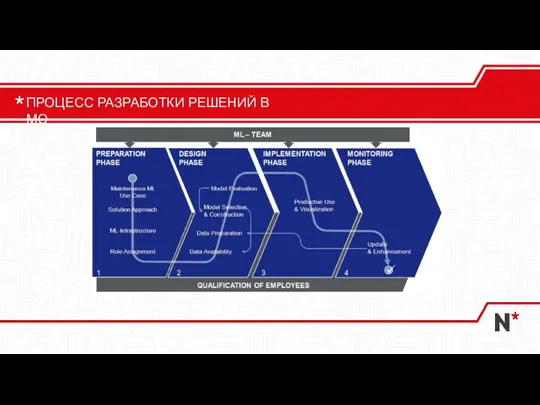
Слайд 15ПРОЦЕСС РАЗРАБОТКИ РЕШЕНИЙ В МО
ПРОЦЕСС РАЗРАБОТКИ РЕШЕНИЙ В МО
Слайд 16DevOps
DataOps
ModelOps
MLOps
ГИБКИЕ ПРАКТИКИ
DevOps
DataOps
ModelOps
MLOps
ГИБКИЕ ПРАКТИКИ

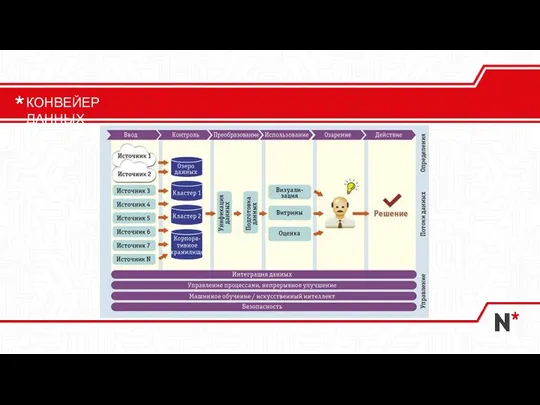
Слайд 17КОНВЕЙЕР ДАННЫХ
КОНВЕЙЕР ДАННЫХ
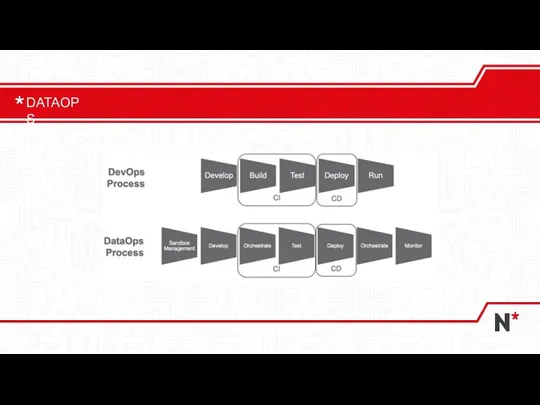
Слайд 18DATAOPS
DATAOPS
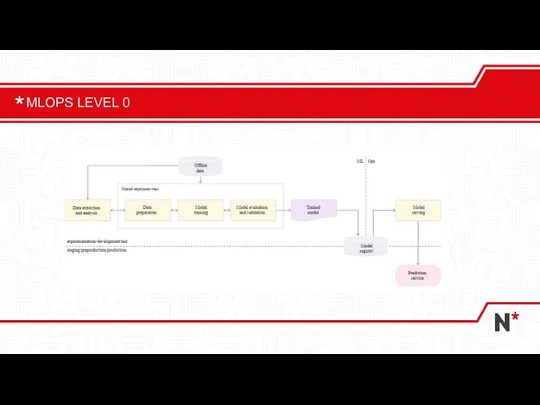
Слайд 19MLOPS LEVEL 0
MLOPS LEVEL 0
Слайд 20MLOPS LEVEL 1
MLOPS LEVEL 1
Слайд 21MLOPS LEVEL 2
MLOPS LEVEL 2
Слайд 22Входные данные должны иметь смысл
Ошибка в коде загрузчика
Ошибки в разметке входных данных
Слишком
Входные данные должны иметь смысл
Ошибка в коде загрузчика
Ошибки в разметке входных данных
Слишком

Слайд 23Извлекайте все данные, которые можно извлечь, но руководствуйтесь здравым смыслом.
Оцените временной горизонт,
Извлекайте все данные, которые можно извлечь, но руководствуйтесь здравым смыслом.
Оцените временной горизонт,

Слайд 24Размерность пространства решения определяется количеством признаков и их увеличение приводит к экспоненциальному
Размерность пространства решения определяется количеством признаков и их увеличение приводит к экспоненциальному

Слайд 25тесная корреляционная взаимосвязь между отбираемыми для анализа признаками, совместно воздействующими на общий
тесная корреляционная взаимосвязь между отбираемыми для анализа признаками, совместно воздействующими на общий

Слайд 26Инженерия признаков (feature extraction and feature engineering) – превращение данных, специфических для
Инженерия признаков (feature extraction and feature engineering) – превращение данных, специфических для

Слайд 27Исходные
Производные
Агрегированные – показатели, определенные по группе (сумма, среднее, минимум, максимум)
Индикаторы – наличие
Исходные
Производные
Агрегированные – показатели, определенные по группе (сумма, среднее, минимум, максимум)
Индикаторы – наличие

Слайд 28тексты – это токенизация
изображения – извлечение краев и цветовые пятна
дата и время–
тексты – это токенизация
изображения – извлечение краев и цветовые пятна
дата и время–

Слайд 29Знание предметной области
Описательная статистика
Матрица корреляций признаков – с высокой степенью корреляции подумать
Знание предметной области
Описательная статистика
Матрица корреляций признаков – с высокой степенью корреляции подумать

Слайд 30
ОПИСАТЕЛЬНАЯ СТАТИСТИКА
ОПИСАТЕЛЬНАЯ СТАТИСТИКА

Слайд 31Критерий Пирсона
Прирост информации
Критерий Гини
Gain_ratio из алгоритма C4.5
ВАЖНОСТЬ ПРИЗНАКА
Критерий Пирсона
Прирост информации
Критерий Гини
Gain_ratio из алгоритма C4.5
ВАЖНОСТЬ ПРИЗНАКА

Слайд 32
КРИТЕРИЙ РАЗБИЕНИЯ
КРИТЕРИЙ РАЗБИЕНИЯ

Слайд 33
КРИТЕРИЙ РАЗБИЕНИЯ
КРИТЕРИЙ РАЗБИЕНИЯ

Слайд 34
КРИТЕРИЙ РАЗБИЕНИЯ
КРИТЕРИЙ РАЗБИЕНИЯ

Слайд 35Неоткалиброванные признаки
Слишком сильная аугментация
Применение предобработки только для одной из выборок
Долговечность признака
Пропуски
Нерегулярная мощность
Выбросы
Неоткалиброванные признаки
Слишком сильная аугментация
Применение предобработки только для одной из выборок
Долговечность признака
Пропуски
Нерегулярная мощность
Выбросы

Слайд 36Если доля пропущенных значений выше 60%, такой признак стоит игнорировать
Иногда сам факт
Если доля пропущенных значений выше 60%, такой признак стоит игнорировать
Иногда сам факт

Слайд 37Не заполнять пропуски нулями!
Не применять восстановление к признакам, имеющим более 30% пропусков
среднее
Не заполнять пропуски нулями!
Не применять восстановление к признакам, имеющим более 30% пропусков
среднее

Слайд 38Если равна 1, полезной информации нет, удалить
Если мощность значительно меньше количества экземпляров,
Если равна 1, полезной информации нет, удалить
Если мощность значительно меньше количества экземпляров,

Слайд 39
ВЫБРОСЫ
ВЫБРОСЫ

Слайд 40
ПОРОГИ ОТСЕЧЕНИЯ
ПОРОГИ ОТСЕЧЕНИЯ

Слайд 41
НОРМАЛИЗАЦИЯ
НОРМАЛИЗАЦИЯ

Слайд 42Обертка – процедура поиска, которая включает обучение и оценку модели. Начинаем с
Обертка – процедура поиска, которая включает обучение и оценку модели. Начинаем с

 Виды склеек
Виды склеек С++. Отличия
С++. Отличия Интерактивные игровые формы работы в виртуальном поле библиотеки
Интерактивные игровые формы работы в виртуальном поле библиотеки Презентация на тему Язык программирования Си
Презентация на тему Язык программирования Си  Сайт Наркотики.ру
Сайт Наркотики.ру Мир логопеда. Студенческое научное сообщество
Мир логопеда. Студенческое научное сообщество Компьюьерная память
Компьюьерная память Как отправить заказ. Онлайн-магазин AVON
Как отправить заказ. Онлайн-магазин AVON Подключение к БД SQL Server
Подключение к БД SQL Server Управление компьютером. Приемы управления компьютером (Урок 4. )
Управление компьютером. Приемы управления компьютером (Урок 4. ) Работа в Scratch
Работа в Scratch Внутреннее строение ПК
Внутреннее строение ПК Операционные системы и оболочки
Операционные системы и оболочки Кодирование информации
Кодирование информации Информационные технологии в экологии. Часть 1
Информационные технологии в экологии. Часть 1 Язык программирования Pascal Процедуры и функции А. Жидков
Язык программирования Pascal Процедуры и функции А. Жидков Представление данных и машинные операции
Представление данных и машинные операции Структура программного обеспечения компьютера
Структура программного обеспечения компьютера Интеллектуальная игра. Город Интернет
Интеллектуальная игра. Город Интернет Создание анимации
Создание анимации Программирование в Lazarus. Массивы
Программирование в Lazarus. Массивы Конъюнкция (логическое умножение)
Конъюнкция (логическое умножение) Создание и настройка меню приложения
Создание и настройка меню приложения Графические средства для работы с MySQL
Графические средства для работы с MySQL Предварительная информация
Предварительная информация Технология мультимедиа
Технология мультимедиа Тексты в памяти компьютера
Тексты в памяти компьютера Site pass issue process and instruction
Site pass issue process and instruction