- Основы технологий хранения баз данных в памяти

Содержание
- 2. План Сжатие Макет данных Разбиение Вставка Обновление Удаление Только вставка Compression Data Layout Partitioning Insert Update
- 3. 1. Кодирование словарей Поскольку память является новым узким местом ("бутылочным горлышком") в системе, требуется минимизировать доступ
- 4. Кодирование словаря создает базу для ряда других методов сжатия, которые могут быть применены поверх закодированных столбцов.
- 5. В данной теме мы обсудим различия между горизонтальным, ориентированным на строки макете, и макете столбчатой планировки.
- 6. 1. Сжатие Методы сжатия • Тяжелый вес в сравнении методами легкого веса • Фокус на легких
- 7. Пример
- 8. 1. Префикс - кодирование В реальных базах данных, мы часто сталкиваемся с тем, что столбец содержит
- 9. Сжатие колонки предусматривает, что преобладающее значение не должно храниться в явном виде каждый раз, когда оно
- 10. Префикс-кодирование: • используется, если столбец начинается с длинной последовательности одного и того же значения; • лишь
- 11. Дан вектор атрибута столбца стран из таблицы населения мира, который отсортирован по численности населения стран в
- 12. Следующий расчет показывает степень сжатия. Прежде всего, количество бит, необходимых для хранения всех 200 стран рассчитывается
- 14. Таким образом, 1,3 ГБ, то есть 17% пространства в памяти экономится. Еще одно преимущество кодирования префикс
- 15. 2. Кодирование длин серий (Run-Length encoded) Кодирование длин серий представляет собой метод сжатия, который работает лучше
- 16. На рисунке 7.2 приведен пример кодирования длин серий с использованием стартовой позиции в виде смещения. Сохранение
- 17. Следовательно, размер вектора атрибута может быть значительно уменьшен примерно до 1 Кбайт без потери информации: 200
- 19. Кластерное кодирование • вектор атрибутов разбивается на N блоков фиксированного размера (обычно 1024) • если кластер
- 20. Разреженное кодирование • Удалить значение V, который появляется чаще всего Бит вектор указывает, из каких позиций
- 21. Косвенное кодирование Последовательность разбивается на N блоков размером S (обычно 1024) • Если блок содержит только
- 22. Дельта кодирование для словаря • Для строковых отсортированных значений • Блок-мудрое сжатие (как правило, 16 строк
- 24. Скачать презентацию
Слайд 2План
Сжатие
Макет данных
Разбиение
Вставка
Обновление
Удаление
Только вставка
Compression
Data Layout
Partitioning
Insert
Update
Delete
Insert Only
План
Сжатие
Макет данных
Разбиение
Вставка
Обновление
Удаление
Только вставка
Compression
Data Layout
Partitioning
Insert
Update
Delete
Insert Only

Слайд 31. Кодирование словарей
Поскольку память является новым узким местом ("бутылочным горлышком") в системе,
1. Кодирование словарей
Поскольку память является новым узким местом ("бутылочным горлышком") в системе,

Слайд 4Кодирование словаря создает базу для ряда других методов сжатия, которые могут быть
Кодирование словаря создает базу для ряда других методов сжатия, которые могут быть

Слайд 5В данной теме мы обсудим различия между горизонтальным, ориентированным на строки макете,
В данной теме мы обсудим различия между горизонтальным, ориентированным на строки макете,

Слайд 61. Сжатие
Методы сжатия
• Тяжелый вес в сравнении методами легкого веса
• Фокус на
1. Сжатие
Методы сжатия
• Тяжелый вес в сравнении методами легкого веса
• Фокус на

Слайд 7Пример
Пример
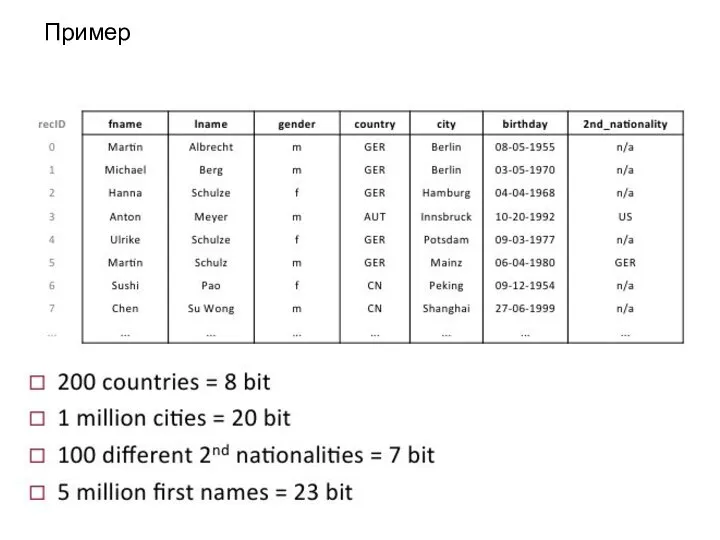
Слайд 81. Префикс - кодирование
В реальных базах данных, мы часто сталкиваемся с тем,
1. Префикс - кодирование
В реальных базах данных, мы часто сталкиваемся с тем,

Слайд 9Сжатие колонки предусматривает, что преобладающее значение не должно храниться в явном виде
Сжатие колонки предусматривает, что преобладающее значение не должно храниться в явном виде

Слайд 10Префикс-кодирование:
• используется, если столбец начинается с длинной последовательности одного и того же
Префикс-кодирование:
• используется, если столбец начинается с длинной последовательности одного и того же

Слайд 11Дан вектор атрибута столбца стран из таблицы населения мира, который отсортирован по
Дан вектор атрибута столбца стран из таблицы населения мира, который отсортирован по

Слайд 12Следующий расчет показывает степень сжатия. Прежде всего, количество бит, необходимых для хранения
Следующий расчет показывает степень сжатия. Прежде всего, количество бит, необходимых для хранения


Слайд 14Таким образом, 1,3 ГБ, то есть 17% пространства в памяти экономится. Еще
Таким образом, 1,3 ГБ, то есть 17% пространства в памяти экономится. Еще

Слайд 152. Кодирование длин серий (Run-Length encoded)
Кодирование длин серий представляет собой метод сжатия,
2. Кодирование длин серий (Run-Length encoded)
Кодирование длин серий представляет собой метод сжатия,

Слайд 16На рисунке 7.2 приведен пример кодирования длин серий с использованием стартовой позиции
На рисунке 7.2 приведен пример кодирования длин серий с использованием стартовой позиции

Слайд 17Следовательно, размер вектора атрибута может быть значительно уменьшен примерно до 1 Кбайт
Следовательно, размер вектора атрибута может быть значительно уменьшен примерно до 1 Кбайт


Слайд 19Кластерное кодирование
• вектор атрибутов разбивается на N блоков фиксированного размера (обычно 1024)
•
Кластерное кодирование
• вектор атрибутов разбивается на N блоков фиксированного размера (обычно 1024)
•

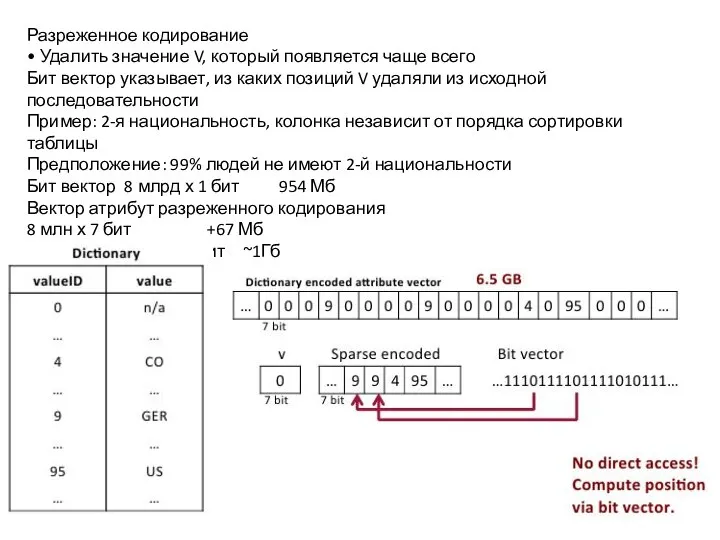
Слайд 20Разреженное кодирование
• Удалить значение V, который появляется чаще всего
Бит вектор указывает, из
Разреженное кодирование
• Удалить значение V, который появляется чаще всего
Бит вектор указывает, из
Слайд 21Косвенное кодирование
Последовательность разбивается на N блоков размером S (обычно 1024)
• Если блок
Косвенное кодирование
Последовательность разбивается на N блоков размером S (обычно 1024)
• Если блок

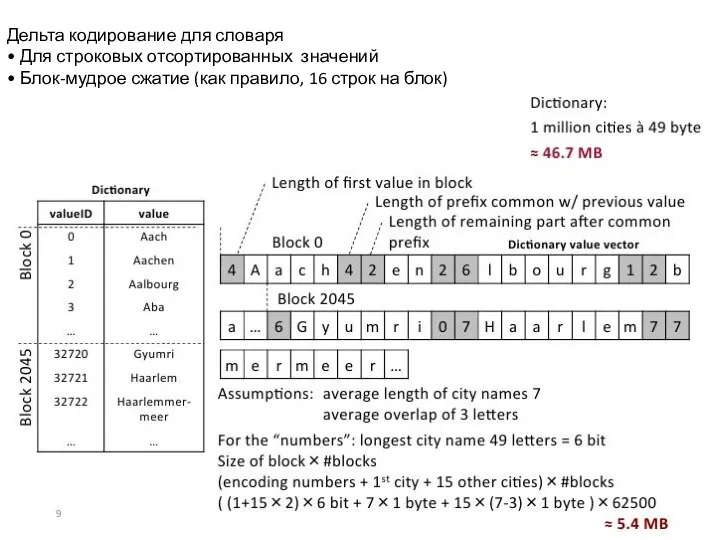
Слайд 22Дельта кодирование для словаря
• Для строковых отсортированных значений
• Блок-мудрое сжатие (как правило,
Дельта кодирование для словаря
• Для строковых отсортированных значений
• Блок-мудрое сжатие (как правило,
 Приглашаем на работу начинающих и опытных веб-программистов
Приглашаем на работу начинающих и опытных веб-программистов FDDI - наиболее подходящая технология для оптоволоконного кабеля
FDDI - наиболее подходящая технология для оптоволоконного кабеля Арифметические операции в системах счисления
Арифметические операции в системах счисления HTML и CSS. Анимация животных
HTML и CSS. Анимация животных Практика. Управление социальной защиты населения по городу улан-удэ
Практика. Управление социальной защиты населения по городу улан-удэ Меры по обеспечению устойчивого экономического развития РО
Меры по обеспечению устойчивого экономического развития РО Свобода доступа к информации и свобода ее распространения
Свобода доступа к информации и свобода ее распространения Своя игра. История ЭВМ. Интернет. Microsoft Word. Microsoft Excel. Microsoft Access (8 класс)
Своя игра. История ЭВМ. Интернет. Microsoft Word. Microsoft Excel. Microsoft Access (8 класс) личная информация. защита. личное пространство (1)
личная информация. защита. личное пространство (1) Интернет и всемирная паутина
Интернет и всемирная паутина Техническое задание на разработку мобильного приложения
Техническое задание на разработку мобильного приложения Презентация на тему Операционная система Линукс и её приложения
Презентация на тему Операционная система Линукс и её приложения  Своя игра (игра-тест)
Своя игра (игра-тест) Премущества Интернета
Премущества Интернета Методологические аспекты эволюции информационных технологий
Методологические аспекты эволюции информационных технологий Экспресс блоки
Экспресс блоки Основные устройства компьютера
Основные устройства компьютера IFS Applications • Компонентная ERP-система • Поддержка 22 языков • Доступна для работы с планшетов и смартфонов
IFS Applications • Компонентная ERP-система • Поддержка 22 языков • Доступна для работы с планшетов и смартфонов Smartnet 24: Продвижение товаров и услуг в интернете
Smartnet 24: Продвижение товаров и услуг в интернете Закономерность. 3 класс
Закономерность. 3 класс Программа Воркшопа. Как подготовить публичное выступление
Программа Воркшопа. Как подготовить публичное выступление Ребенок в интернете. Правила безопасности
Ребенок в интернете. Правила безопасности Федеральный реестр сведений о документах об образовании и о квалификации, документах об обучении
Федеральный реестр сведений о документах об образовании и о квалификации, документах об обучении Знатоки глобальной сети
Знатоки глобальной сети Работа с матрицами и решение СЛАУ в пакете Matlab
Работа с матрицами и решение СЛАУ в пакете Matlab Не SQL’ом единым
Не SQL’ом единым Что такое документ?
Что такое документ? История развития информационных технологий
История развития информационных технологий